Git常用命令底层实现机制
1 Git简介
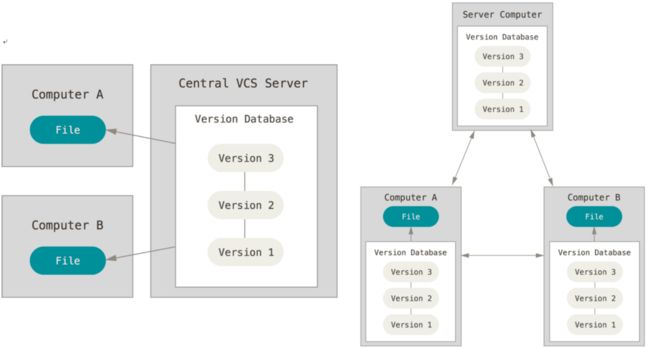
Git 是一个开源的分布式版本控制系统,是 Linus Torvalds 为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。其分布式特性主要体现为每一次的克隆操作,都是一次对代码仓库的完整备份,也就是在每个开发者本地都保存了整个项目开发迭代的完整备份,因此避免了集中式架构下中心服务器故障可能带来的数据丢失。下图分别为集中式(左)与分布式(右)系统示意图。
2 Git工作区、暂存区和版本库
首先先来理解下 Git 工作区、暂存区和版本库概念:
- 工作区: 就是工作目录下我们直接进行添加或修改等操作的文件目录;
- 暂存区: 英文叫 stage 或 index,一般存放在 .git 目录下的 index 文件中,有时也叫作索引,用于存放临时改动,保存即将提交的文件列表信息;
- 版本库: 工作区有一个隐藏目录 .git,这个不算工作区,而是 Git 的版本库,这里保存了我们提交的所有版本的数据。
下图描述了Git工作区、暂存区和版本库之间的关系:

2.1 Git一般工作流程
- 在工作目录中添加、修改文件;
- 将需要进行版本管理的文件放入暂存区域;
- 将暂存区域的文件提交到Git仓库。
2.2 Git管理文件的三种状态
- 已修改(modified)
- 已暂存(staged)
- 已提交(committed)
3 Git对象
要想熟练使用Git各种命令,必须对Git存储实现原理有所了解。Git中以存储键值对(key-value)的方式来存储文件,它允许插入任意类型的内容,并会返回一个键值,通过该键值可以在任何时候再取出该内容。Git中,key是通过SHA-1算法(一种哈希函数)获得,是一串40位十六进制标识符,根据文件内容或目录计算得出的全局唯一标识符,每一个value对应着一个唯一的key;value代表存储对象,共有三种类型,即Git的三种对象,分别为blob,tree和commit.下面来探索这三种对象分别存储什么内容,以及这样设计所带来的好处。探讨之前,首先介绍一个重量级武器:git cat-file命令。这个命令可以帮助我们查看指定key的对象类型及内容,下面我们会频繁使用此命令。
注:**$**符号表示终端中执行的命令。
3.1 blob对象
首先,初始化一个工作目录作为Git仓库,以demo文件夹为例,在**~/Desktop/demo**路径下执行:
$ git init
添加文件a.txt到工作目录:
$ echo ‘This is a.txt.’ > a.txt
将a.txt添加至暂存区:
$ git add a.txt
此时,你可以发现在工作目录下./git/objects下多了一个文件71/b864af8bb72492e3d6a76db552bb8b1fff0a3d,这一串数字即为由SHA-1算法根据文件a.txt内容外加一个头部信息计算得出的,为40位十六进制数字,其中,前两位用于命名子目录,余下38位则用作文件名。下面通过git cat-file命令查看该文件的类型及内容(后跟的key值不必全输入,不与其他key相冲突即可):
$ git cat-file -t 71b864
$ git cat-file -p 71b864
输出如下图:

可以看到,执行完git add命令后,我们得到了一个类型为blob的对象,其中存储的内容就是加入暂存区的a.txt文件中的内容。那么,如果git add加入暂存区的是一个目录结构呢?此时所创建的对象类型又是什么?下面来实践一下:
$ mkdir subDir
$ echo ‘This is sub.txt.’ > subDir/sub.txt
此时,./git/objects下仅仅是多了一个文件13/56e9dc234d3a3d269da8a470c0b879ffa21d8d,除了这串数字不同外,和上面git add a.txt后创建的对象没什么不同,我们依然通过git cat-file命令查看该文件的类型及内容:
$ git cat-file -t 1356e9
$ git cat-file -p 1356e9
输出如下图:

通过上面的输出我们发现,该文件中没有存储任何关于目录subDir的信息,而只是创建了subDir目录下文件sub.txt的blob对象,那目录结构要怎样表示呢?下面来看Git第二种对象类型——tree.
3.2 tree对象
上面的探讨中,我们发现blob对象只保存了文件的内容,而不涉及如何保存目录结构等信息。接下来,我们来探讨Git中的tree对象,它能解决文件名保存的问题,也允许我们将多个文件组织到一起,由此可记录目录结构信息。
首先,通过git commit命令将暂存区中内容做一次提交:
$ git commit -m “This is the first commit”
提交之后我们再次观察./git/objects目录下的内容:
$ find .git/objects/
输出如下图:
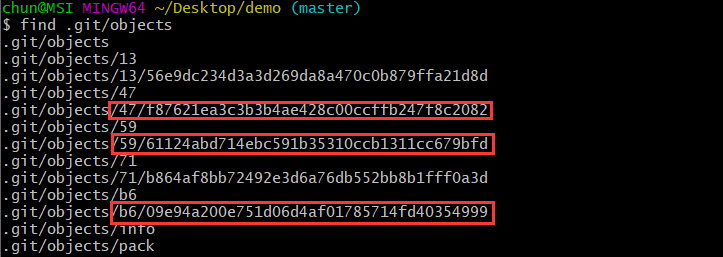
我们可以看到这里面多了三个文件,如红框中所示,在本节下面的探讨中,我们主要分析47f876和b609e9,而596112则属于commit对象类型,留至下节分析。下面,我们依然用git cat-file命令查看47f876和b609e9文件类型和内容:
$ git cat-file -t 47f876
$ git cat-file -t b609e9
$ git cat-file -p 47f876
$ git cat-file -p b609e9
输出如下图:
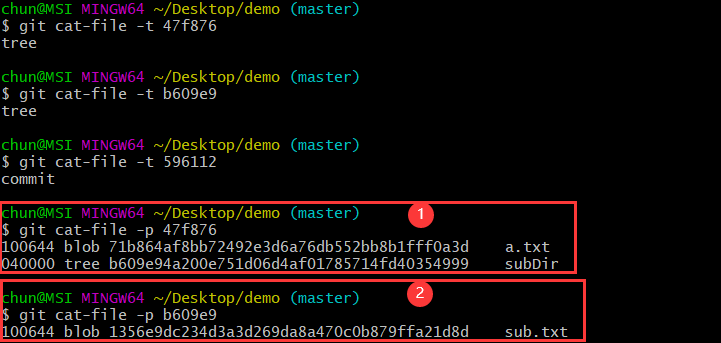
通过上图,对于目录结构是如何存储的这个疑问就可以解开了。执行git commit后,创建了两个tree对象类型的对象,此处即47f876和b609e9,tree的哈希值是由SHA-1算法根据文件名和/或目录名生成。查看47f876对应的文件,这个文件中包含了一条tree对象记录和一个blob对象记录(对应a.txt文件),其中每条记录都指向一个数据对象(blob)或者是子树对象(tree)的SHA-1指针以及相应的模式、类型、文件名。查看b609e9对应的文件,这个文件中包含了一条blob对象记录,对应sub.txt文件。由此,即通过tree对象实现了目录结构的表示。用一个结构图表示如下:
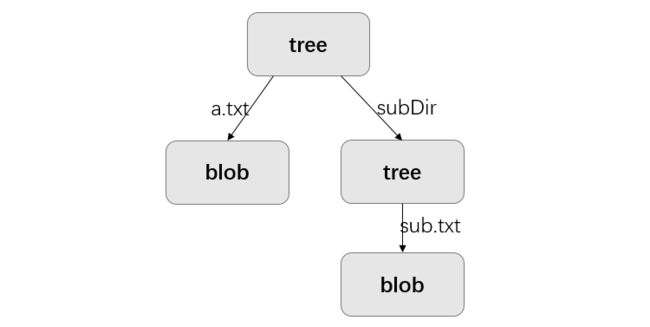
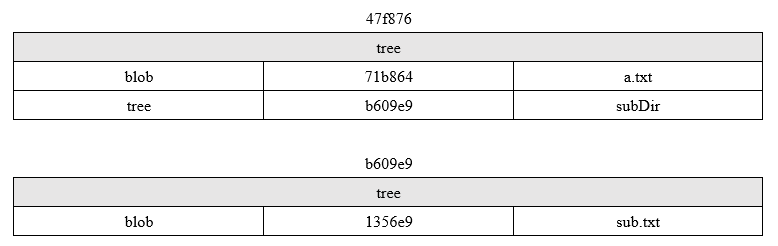
也就是说,执行完git commit后,路径下所有内容都被一个类型为tree的对象组织起来,若路径下都是文件,则tree中为这些文件对应的blob对象,若路径下存在子目录,则该子目录由另一个tree对象保存,依此类推…
问题:
若某次在工作目录下,只修改了某文件的文件名(此处假设将a.c文件名修改为b.c),而未修改其中的内容,此时执行git add && git commit,是否会额外申请一块空间用于存储a.c改名后的拷贝?答:通过分析执行git add 和 git commit后分别发生的事情,进而来判断是否会发生数据拷贝。
**执行git add:**SHA-1算法根据b.c内容生成哈希值,由于b.c内容与a.c内容相同,故哈希值不变,即该文件的索引不变,可以将哈希值理解为指向存储改文件的一个指针,内容不变则指针指向不变,还是指向存储a.c的位置。
执行git commit:执行git commit后,首先生成一个tree对象,该对象的哈希值由工作目录下文件名/目录名决定,因为修改了文件名,即a.c文件改名为b.c文件,所以git commit后,会创建一个新的tree对象,其中包含b.c文件对应的blob对象。因为blob对象及其哈希值仅取决于文件内容,所以此处不会发生改变,而由于文件名发生了变化,所以tree对象中会将原来存储的文件名a.c改为b.c.也就是说文件的内容存储在blob对象中,而文件名存储在tree对象中(可以通过git cat-file -p命令验证),所以只改文件名不会拷贝新的文件对象,而只需要新建一个tree对象即可,在新的tree对象中将原来的a.c字段改为b.c。因为tree对象中所存的内容可以理解为很多指针,相比于拷贝一份数据对象,新建一个tree对象的代价是很小的(若数据对象很大)。
在问题板块中,我们引出了Git存储文件的方式,即通过全局唯一的哈希值作为key,对象作为value,通过key就可以找到与其对应的对象。因此,对于每一次commit,对于那些没有发生改变的文件,我们不必提交一次拷贝一次,而只需要将文件对应的key记录下来,即可实现Git的每一次提交都对应一次完整快照的特性,否则,每提交一次快照都将所有文件全部拷贝一遍,效率将极其低下…
3.3 commit对象
接下来我们分析3.2节遗留的commit对象,即596112文件。我们依然用git cat-file命令查看文件类型及内容:
$ git cat-file -t 596112
$ git cat-file -p 596112
输出如下图:

可以发现,commit对象中包含一个tree对象条目,代表当前项目的快照,根据这个tree对象,我们就能找到当前快照下所有的blob对象,即数据对象,从而形成一个Git版本。此外,commit对象中还包含一些作者/提交者信息及提交注释。
到现在为止我们只提交过一次,下面我们试着再做一次提交:
$ echo ‘This is b.txt.’ > b.txt
$ git add b.txt
$ git commit -m “This is the second commit”
我们知道,执行完git commit命令后,会创建一个新的快照,即commit对象,下面我们来查看该commit对象的内容:
$ git cat-file -p 37e844
输出如下图:

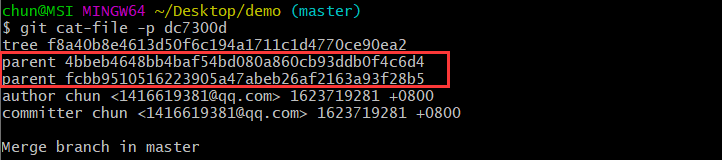
对比第一次提交的commit对象,可以发现其中多了一个parent记录,而该纪录所存储的key恰好为上一次提交的commit对象对应的哈希值,也就是说后面的版本快照记录了指向其父提交的指针,这样也就可以方便的实现版本回退等功能了。可将版本迭代记录用下图表示,其中,每一次commit创建一个版本快照,其中存储了tree对象以及其他相关信息。

若版本迭代中存在分支合并的操作,则合并后的commit对象中将保存多个parent指针,如下图所示(分支相关命令留至下节探讨):
4 Git分支
Git分支可以使开发者从开发主线上分离开来,然后在不影响主线的同时继续工作。本节将主要介绍Git分支相关命令及其实现原理。
4.1 创建分支
创建分支命令:
$ git branch branch_name
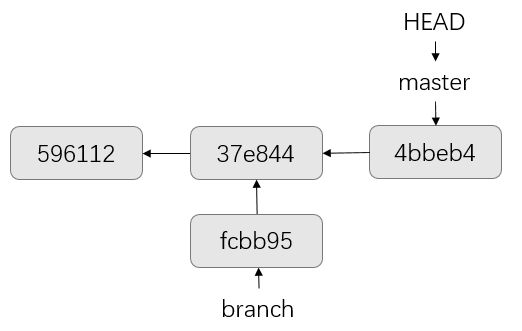
要搞清楚上面的命令做了什么事情,我们首先需要知道什么是分支,以及创建一个分支的本质是什么。对于Git,当我们做了第一次commit时,实际上Git默认就为我们创建了一个名为master的分支,也就是主分支。我们可以将master理解为一个指针,指向当前版本快照。当我们通过git branch命令创建新的分支时,实际上就是创建一个新的指针,同样指向当前版本快照,因为创建一个指针的成本是很小的,因此Git创建分支的速度是很快的。为了指示我们当前所处的分支,于是有了HEAD指针,如下图所示:

上图中,master和branch分支都指向ID为37e844的版本快照。我们可以通过下面的命令切换分支到branch:
$ git checkout branch
此时,我们再新建一个文件,并做一次提交:
$ echo ‘This is c.txt.’ > c.txt
$ git add c.txt
$ git commit -m “This is the third commit”
接下来,切回master分支,再新建一个文件并提交:
$ echo ‘This is d.txt.’ > d.txt
$ git add d.txt
$ git commit -m “This is the forth commit”
此时,版本迭代记录将变为下面的样子:
通过分支操作,我们就可以从主线上分离开来了,使我们可以在不影响主线的前提下进行开发。
4.2 分支合并
当需要时,可以通过merge命令进行分支合并。在master分支下执行如下命令:
$ git merge branch
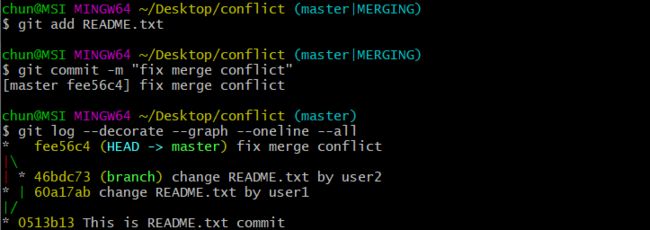
为了查看此时分支结构图,这里再介绍一个很好用的命令:git log --decorate --oneline --graph --all. 运行这条命令,输出如下图:
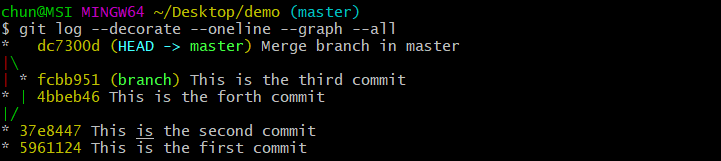
我们可以看到,执行git merge后,产生了一个新的快照dc7300,这个快照合并了branch到master分支上,进而实现对主线开发任务的更新。
4.3 merge冲突
如果两个(或者多个,这里只介绍两个)用户user1/user2各自的本地提交中修改的是不同的文件,那么第二次进行合并推送的提交将能正确合并并提交,不会遇到任何麻烦。但如果两个用户同时修改同一个文件的相同区域的内容时,就会发生冲突事件了。下面我们通过实际例子进行测试。
首先,新建一个工作目录,名为conflict,执行git init初始化,创建文件README.txt并提交:
$ echo ‘This is README.txt’ > README.txt
$ git add README.txt
$ git commit -m “This is README.txt commit”
为了执行merge,我们创建一个分支branch:
$ git branch branch
接下来,我们分别在master和branch分支下修改README.txt内容如下,修改方式为在README.txt第二行分别新增"Change in master/branch branch. ",并分别提交。此时,版本记录图如下所示:

接下来,我们在master分支下执行merge命令:
$ git merge branch
由于两个分支中README.txt文件产生冲突,输出如下图:

通过git status命令查看当前状态,会发现输出的日志告诉我们同时修改了一个文件README.txt并:
我们还可以通过命令git ls-files -s查看到底是哪些文件发生了合并冲突,该命令输出的第三列的值如果为0表示对应的文件没有冲突,合并成功,如果不为0,则表示产生了合并的冲突,其中具体的值对应的意义是:1表示两个用户之前一个共同版本的对应文件内容;2表示当前用户对应的文件版本;3表示合并后的文件对应的远程版本。通过命令git show :n:filename可以查看对应文件的对应版本的内容:

在知道了三个版本的文件内容之后,我们就可以手动的对冲突的文件进行手动修改操作了。这里需要注意的是,对应的冲突文件的内容已经发生了改变,里面对应的冲突区域的内容将会同时存在当前分支(master)的内容和被合并分支(branch)的内容,如下图:

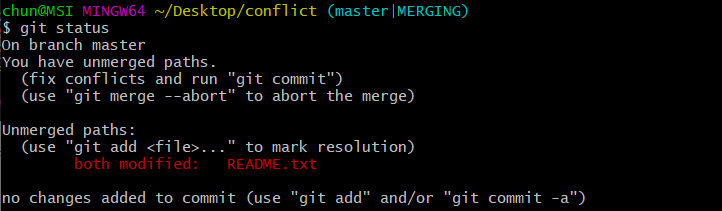
我们可以手动对该文件进行修改操作,然后再手动add、commit就可以了,修改README.txt并add/commit后,可以发现分支已成功被合并:
5 版本回退
5.1 修改上次提交
git commit -m提交之后,发现-m的说明文字写的有问题,亦或者发现少提交了一个文件,修改后想要重新提交一次,也就是想撤销上次的提交动作,这个时候可以用命令:
$ git commit --amend
这个命令可以让我们修改上次提交记录,而不会产生新的commit记录。
如果是想修改描述信息,则只需要执行git commit --amend命令即可,在弹出的界面中修改描述信息后保存;如果是提交之后发现有文件需要修改或漏了文件未提交,则只需先将修改后或漏提交的文件加入暂存区,再执行git commit --amend.
5.2 git reset 命令
git reset命令用于将当前HEAD复位到指定状态,一般用于撤消之前的一些操作。根据其后面选项不同,功能会有较大不同,**且操作不慎可能会带来危险后果。**下面来探讨几种带不同参数的功能。
git reset (–mixed)
执行git reset命令时,默认选项为–mixed。下面以几个具体命令为例进行分析:
$ git reset HEAD~
该命令会进行如下两步操作:
- 移动HEAD的指向,将其指向上一个快照;
- 将HEAD移动后指向的快照回滚到暂存区。
其中,HEAD表示向上回滚一次,若想回滚n次,可用HEADn表示。为了测试该命令,我们新建一个工作目录reset/,初始化后,在其中创建一个文件text.txt,提交后,修改,再提交,再修改,再提交。至此,版本库中就存在三个版本快照,通过git log --decorate --online --graph --all命令查看版本记录,如下图所示:

执行命令git reset HEAD~,再执行git log --decorate --online --graph --all查看,如下图所示:
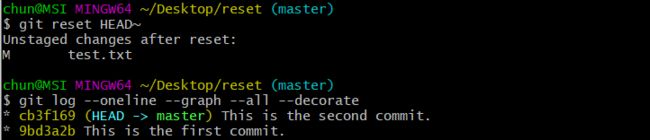
可以发现,HEAD指针已经回退到第二次提交的版本,并且在提交日志中已经不再有第三次提交的记录。此时我们执行git status命令查看缓存区状态,输出如下图:
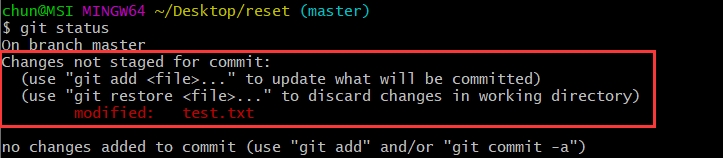
那么红色框中的信息是什么意思呢?因为git reset HEAD~不仅让HEAD指针向前回滚一次到第二个版本,还将此时指向的第二个版本回滚到暂存区,所以此时暂存区存储的是第二个版本,而此时工作目录中存储的是第三个版本,也就是说工作目录中文件内容新于暂存区内容,所以会提示我们修改未提交,这也印证了上述执行git reset HEAD~所做的两件事情。
那么,我们如果想让HEAD指针重新指向第三版快照,该怎么办呢?只需要执行:
$ git reset 版本ID
而当我们将HEAD指针向前回滚时,无法通过git log命令查看版本ID怎么办?有办法,只需要执行下面的命令即可查看所有快照ID:
$ git reflog
git reset --hard
默认的git reset HEAD~命令做两个操作,首先将HEAD指向上一个快照,再将HEAD移动后指向的快照回滚到暂存区。而如果加上–hard选项,则会在git reset所做的两个操作基础上,再加上另外一个操作,即将暂存区的文件还原到工作目录。总结如下:
- 移动HEAD的指向,将其指向上一个快照;
- 将HEAD移动后指向的快照回滚到暂存区;
- 将暂存区的文件还原到工作目录。
由此可见,git reset --hard是一个危险的命令,因为其有可能会将我们还未提交的本地修改覆盖掉!
git reset --soft
执行git reset --soft HEAD~选项只会做一个操作,即:移动HEAD的指向,将其指向上一个快照,并不会改变暂存区及工作目录中的内容,这也就相当于撤销了一次提交。
5.3 git checkout 命令
在Git分支中,曾经出现过git checkout 命令,后跟分支名进行分支切换。这里,我们看一看它另一种用法。
注意:checkout命令同样可能导致本地工作目录被覆盖,操作需谨慎!
$ git checkout HEAD~
上面这个命令和git reset命令所做的操作看似有些相似,但却截然不同。一句话概括就是git checkout HEAD~会将HEAD指针向前回滚一次,但master指向不变,也就是创建了一个匿名分支,同时,将HEAD新的指向的快照回滚到暂存区和当前工作目录。总结如下:
- 将HEAD指针向前回滚一次,master指向保持不变;
- 将HEAD新的指向的快照回滚到暂存区和当前工作目录。
下面通过实例来说明:
首先初始化一个工作目录,分别进行三次提交,执行git log --decorate --oneline --graph --all查看提交记录,如下图:

此时,执行git checkout HEAD~,再次执行git log --decorate --oneline --graph --all查看提交记录,如下图:

根据上图圈1,可知,执行git checkout HEAD~后,HEAD向前回滚一次,但master指向不变,所以HEAD为匿名分支,此时可以在该分支上做一些实验性操作,而不会影响到现有分支。根据提示信息,我们也可以选择创建新分支来保存匿名分支上的修改。此时,暂存区和工作目录中,3.txt也消失不见了,原因相信大家已经知道了。
**总结:**上面讨论了关于git reset和git checkout命令对版本快照的操作,同时这两个命令还可针对文件进行回滚,这里不再赘述。
6 git rebase 命令
git rebase命令用于把一个分支的修改合并到当前分支。假设你现在基于远程分支"origin",创建一个叫"mywork"的分支:
$ git checkout -b mywork origin
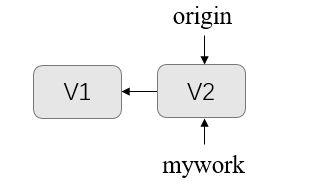
假设远程分支"origin"已经有了2个提交,如图:
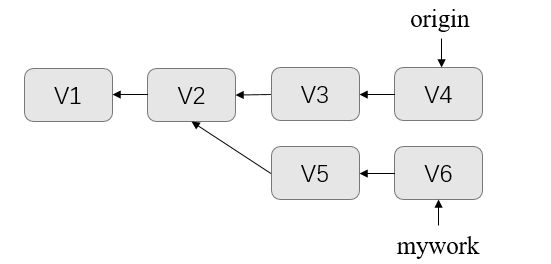
现在我们在这个分支做一些修改,然后生成两个提交(commit)。但是与此同时,其他开发人员也在"origin"分支上做了一些修改并且做了提交。这就意味着"origin"和"mywork"这两个分支各自"前进"了,它们之间"分叉"了,如下图所示:
此时,如果想让"mywork"分支历史看起来像没有经过任何合并一样(不采用git pull等包含merge的命令),就可以用 git rebase命令来实现:
$ git checkout mywork
$ git rebase origin
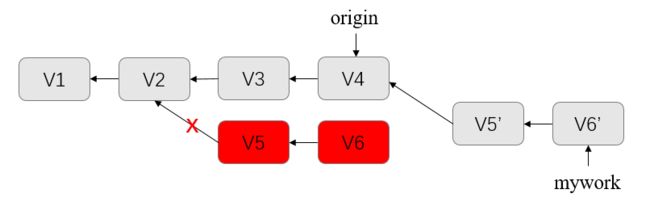
这些命令会把你的"mywork"分支里的每个提交(commit)取消掉,并且把它们临时保存为补丁(patch)(这些补丁放到".git/rebase"目录中),然后把"mywork"分支更新 为最新的"origin"分支,最后把保存的这些补丁应用到"mywork"分支上,如下图所示:

当“mywork”分支更新之后,它会指向这些新创建的提交(commit),而那些老的提交会被丢弃。 如果运行垃圾收集命令(pruning garbage collection), 这些被丢弃的提交就会删除,如下图:
在rebase的过程中,也许会出现冲突(conflict)。在这种情况,Git会停止rebase并会让你去解决冲突,在解决完冲突后,用git add命令去更新这些内容的索引(index),,然后,无需执行 git commit,只要执行:
$ git rebase --continue
这样git会继续应用(apply)余下的补丁。
7 git stash 系列命令
作用:
git stash命令的作用就是将目前还不想提交的但是已经修改的内容进行保存至堆栈中,后续可以在某个分支上恢复出堆栈中的内容。这也就是说,stash中的内容不仅仅可以恢复到原先开发的分支,也可以恢复到其他任意指定的分支上。git stash作用的范围包括工作区和暂存区中的内容,也就是说没有提交的内容都会保存至堆栈中。
应用场景:
- 当正在dev分支上开发某个项目,这时项目中出现一个bug,需要紧急修复,但是正在开发的内容只是完成一半,还不想提交,这时可以用git stash命令将修改的内容保存至堆栈区,然后顺利切换到hotfix分支进行bug修复,修复完成后,再次切回到dev分支,从堆栈中恢复刚刚保存的内容。
- 由于疏忽,本应该在dev分支开发的内容,却在master上进行了开发,需要重新切回到dev分支上进行开发,可以用git stash将内容保存至堆栈中,切回到dev分支后,再次恢复内容即可。
7.1 git stash
能够将所有未提交的修改(工作区和暂存区)保存至堆栈中,用于后续恢复当前工作目录。
7.2 git stash save
作用等同于git stash,区别是可以加一些注释。
7.3 git stash list
查看当前stash中的内容。
7.4 git stash pop
将当前stash中的内容弹出,并应用到当前分支对应的工作目录上。
**注:**该命令将堆栈中最近保存的内容弹出(栈是后进先出)。
7.5 git stash apply
将堆栈中的内容应用到当前目录,不同于git stash pop,该命令不会将内容从堆栈中删除,也就说该命令能够将堆栈的内容多次应用到工作目录中,适应于多个分支的情况。
关于git stash系列命令还有很多,此处不再赘述,有需要可以查看Git相关文档。
8 Git其他常用命令
至此,本文列出了Git部分具有代表性的命令,实际工作中还有很多其他常用命令,本文将不再赘述,有需要可以查看Git相关文档。