Spark---RDD序列化----宽窄依赖----RDD持久化----RDD广播变量
目录
一、RDD序列化
二、宽窄依赖
1、RDD窄依赖
2、RDD宽依赖
三、RDD持久化
1、大概解释图
2、代码解决
3、 存储级别
4、关于 checkpoint 检查点
5、缓存和检查点的区别
四、广播变量
1、实现原理
2、代码实现
一、RDD序列化
从计算的角度, 算子以外的代码都是在Driver端执行, 算子里面的代码都是在Executor端执行。那么在scala的函数式编程中,就会导致算子内经常会用到算子外的数据,这样就形成了闭包的效果,如果使用的算子外的数据无法序列化,就意味着无法传值给Executor端执行,就会发生错误,所以需要在执行任务计算前,检测闭包内的对象是否可以进行序列化,这个操作我们称之为闭包检测。
二、宽窄依赖
1、RDD窄依赖
窄依赖表示每一个父RDD的Partition最多被子RDD的一个Partition使用,窄依赖我们形象的比喻为独生子女。

2、RDD宽依赖
宽依赖表示同一个父RDD的Partition被多个子RDD的Partition依赖,会引起Shuffle,总结:宽依赖我们形象的比喻为超生。

三、RDD持久化
1、大概解释图
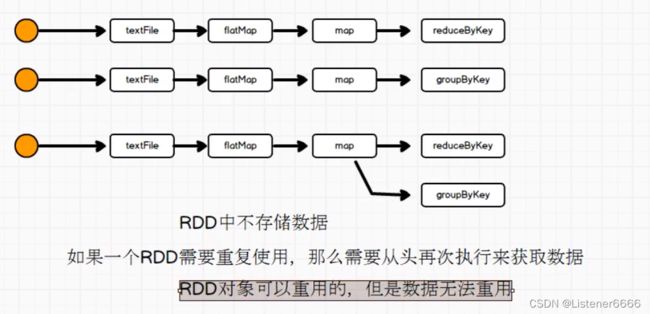
解决办法
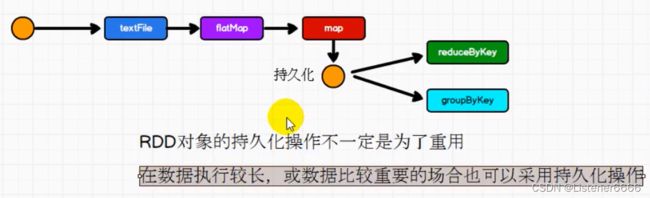
2、代码解决
package com.test
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val list = List("Hello spark","Hello spark")
val rdd = sc.makeRDD(list)
val flatRDD = rdd.flatMap(_.split(" "))
val mapRDD = flatRDD.map(
word => {
println("@@@@@@@")
(word, 1)
}
)
// 持久化操作
//cache 默认持久化的操作,只能将数据保存到内存中
//如果想要保存到磁盘中,需要更改存储级别
//mapRDD.cache()
mapRDD.persist(StorageLevel.DISK_ONLY)
//持久化操作必须在执行算子执行时完成
val reduceRDD = mapRDD.reduceByKey(_ + _)
reduceRDD.collect().foreach(println)
println("**************************")
val groupRDD = mapRDD.groupByKey()
groupRDD.collect().foreach(println)
sc.stop()
}
}
3、 存储级别
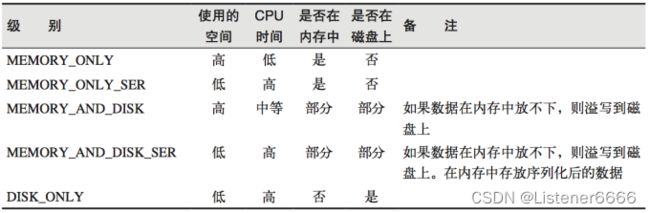
4、关于 checkpoint 检查点
package com.test
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
sc.setCheckpointDir("path")
val list = List("Hello spark","Hello spark")
val rdd = sc.makeRDD(list)
val flatRDD = rdd.flatMap(_.split(" "))
val mapRDD = flatRDD.map(
word => {
println("@@@@@@@")
(word, 1)
}
)
// checkpoint 检查点 需要落盘,需要指定检查点保存的路径
// 检查点路径保存的文件 当作业执行完毕后,不会被删除
// 一般保存路径都是保存在分布式存储系统:HDFS
mapRDD.checkpoint()
val reduceRDD = mapRDD.reduceByKey(_ + _)
reduceRDD.collect().foreach(println)
println("**************************")
val groupRDD = mapRDD.groupByKey()
groupRDD.collect().foreach(println)
sc.stop()
}
}
5、缓存和检查点的区别
(1)Cache缓存只是将数据保存起来,不切断血缘依赖。Checkpoint检查点切断血缘依赖。
(2)Cache缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint的数据通常存储在HDFS等容错、高可用的文件系统,可靠性高。
(3)建议对checkpoint()的RDD使用Cache缓存,这样checkpoint的job只需从Cache缓存中读取数据即可,否则需要再从头计算一次RDD。
四、广播变量
1、实现原理
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个Spark操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,广播变量用起来都很顺手。在多个并行操作中使用同一个变量,但是 Spark会为每个任务分别发送。
2、代码实现
package com.test
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
object Test2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("my app")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(List(
("a", 1), ("b", 2), ("c", 3)
))
val rdd2 = sc.makeRDD(List(
("a", 4), ("b", 5), ("c", 6)
))
val map = mutable.Map(("a", 4), ("b", 5), ("c", 6))
//封装广播变量
val bc = sc.broadcast(map)
// //操作1 将相同的key连接在一起
// //join 会导致数据量几何增长,并且会影响shuffle的性能,不推荐使用
// val joinRDD = rdd1.join(rdd2)
// joinRDD.collect().foreach(println)
//操作2
rdd1.map {
case (w,c) => {
//访问广播变量
val i = bc.value.getOrElse(w, 0)
(w,(c,i))
}
}.collect().foreach(println)
sc.stop()
}
}