Playwright 简明入门教程:录制自动化测试用例,结合 Docker 使用
本篇文章聊聊如何使用 Playwright 进行测试用例的录制生成,以及如何在Docker 容器运行测试用例,或许是网上最简单的入门教程。
写在前面
Playwright 是微软出品的 Web 自动化测试工具和框架,和 Google Puppeteer 有着千丝万缕的关系。前一阵答应了小伙伴,要做一些自动化测试相关的分享。本篇作为第一篇,聊聊怎么简单的玩 Playwright 。
在 playwright 或者 puppeteer 的开源项目中,不论是文档还是示例,有不少内容倾向于编写代码的方式(Coding)来进行自动化测试相关的动作。
然而,需要和页面打交道的前端交互测试,有一个麻烦的事儿,就是我们需要不停在浏览器和代码编辑器中进行切换,定位要交互的元素,把要操作的元素的路径、位置拿到,思考要怎么模拟用户的操作,触发页面的事件或者程序中内置钩子方法,然后切换到代码编辑器里,再编写胶水逻辑,往复循环数次,完成基础的测试程序。接下来,还要和写被测试代码一样,验证程序运行是否正确等等,整个操作流程其实还是挺麻烦的。
但这就完事了嘛?并没有,面向用户的界面的迭代变化频率是非常高的,基于界面元素构建的测试程序自然也要跟着变,那么我们面临的就是不停的折腾自己,有没有省事儿一点的方法呢?
好在我们还有另外一种选择,通过“录制为主,编写为辅”的方式来完成测试程序,而不是用上面的方式循环的折腾自己,毕竟偷懒是工程师的美德嘛。
搞定 Playwright 本地录制环境
我们可以使用 Playwright Python 来完成简单的测试用例录制,关于 Python 的安装, 就不多赘述了,在 macOS 和 Ubuntu 等操作系统中是内置的 Runtime(也可以使用 brew 或者 apt 来安装或者进行升级),在 Windows 中,我们可以通过非常多的方式来完成安装。
如果你希望更快的完成 Playwright 的 Python PyPI 软件包的下载安装,可以执行下面的命令,替换软件源为清华源:
pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
下载基础软件工具
接着,我们执行 pip3 install playwright 就能够完成 playwright Python 版基础程序的安装了啦:
...
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting playwright
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/97/35/28f880594a6e0b89475e21073b83ab374e522ab1fbf86849585ecc4a4e19/playwright-1.28.0-py3-none-macosx_11_0_universal2.whl (30.6 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 30.6/30.6 MB 255.8 kB/s eta 0:00:00
...
...
Installing collected packages: typing-extensions, greenlet, pyee, playwright
...
...
Successfully installed greenlet-2.0.1 playwright-1.28.0 pyee-9.0.4 typing-extensions-4.4.0
完成基础软件的安装之后,我们执行 playwright 能够看到程序 CLI 的基本用法。
Usage: playwright [options] [command]
Options:
-V, --version output the version number
-h, --help display help for command
Commands:
open [options] [url] open page in browser specified via -b, --browser
codegen [options] [url] open page and generate code for user actions
install [options] [browser...] ensure browsers necessary for this version of Playwright are installed
install-deps [options] [browser...] install dependencies necessary to run browsers (will ask for sudo permissions)
cr [options] [url] open page in Chromium
ff [options] [url] open page in Firefox
wk [options] [url] open page in WebKit
screenshot [options] <url> <filename> capture a page screenshot
pdf [options] <url> <filename> save page as pdf
show-trace [options] [trace...] show trace viewer
help [command] display help for command
到现在为止,我们距离完成本地环境的安装还差一步,因为现在我们只有软件基础框架,并没有要进行测试的浏览器环境(Chrome、Firefox 等等),所以我们还要进行浏览器环境下载。
下载需要的浏览器环境
浏览器环境的下载需要使用 playwright install 命令,目前支持通过命令下载下面的浏览器:chromium、chrome、chrome-beta、msedge、msedge-beta、msedge-dev、firefox、webkit。
当然,不同版本的 playwright 可能支持的浏览器列表是不同的,我们可以通过 playwright install --help 来查看下载的 playwright 到底支持什么浏览器。
playwright install --help
Usage: playwright install [options] [browser...]
ensure browsers necessary for this version of Playwright are installed
Options:
--with-deps install system dependencies for browsers
--dry-run do not execute installation, only print information
--force force reinstall of stable browser channels
-h, --help display help for command
Examples:
- $ install
Install default browsers.
- $ install chrome firefox
Install custom browsers, supports chromium, chrome, chrome-beta, msedge, msedge-beta, msedge-dev, firefox, webkit.
比如,我们只需要测试 Chrome 环境下的程序表现,那么可以执行下面的命令:
playwright install chrome
完成第一个测试用例
当我们完成 Playwright 的环境安装和配置之后,我们就可以进行第一个测试用例的录制了。
“搜索”需求是一个有趣的例子,可以覆盖用户在页面中常见的交互动作,包含:打开页面、选择可交互的页面替换元素(Input)、跳转新页面等等。
前一阵“宝可梦”发布了新版本,作为一个还没开始玩的用户,难免对这款游戏心心念念。那么测试用例,就选择通过录制用户在搜索引擎中搜索“宝可梦”新游戏百科词条,在新窗口中打开词条中游戏的第一条宣传视频,来解解馋吧。
自动化录制完成测试用例初版
接下来,我们先来创建一个目录,用于保存接下来生成的测试程序文件:
mkdir -p playwright
cd playwright
接着,执行下面的命令,程序将自动打开两个窗口,包含一个浏览器窗口(起始页面是 https://cn.bing.com,当我们完成录制,结果将保存在 pokemon.js 文件中):
playwright codegen -o pokemon.js --target javascript https://cn.bing.com
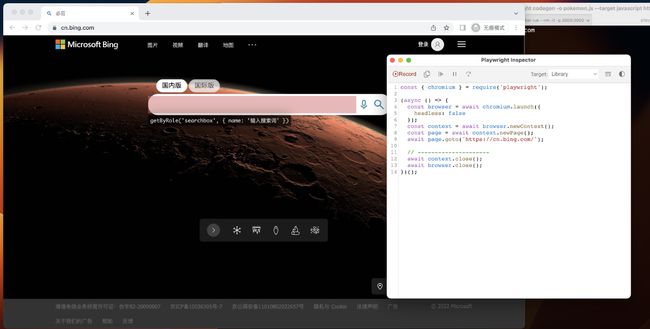
我们在搜索框中输入“宝可梦朱紫”,然后和平时一样敲击回车键(也可以戳搜索按钮),页面会来到搜索结果页。同时,Playwright Inspector 窗口中,会生成模拟我们交互行为的代码。

我们点击第一条搜索结果:“百科内容”,将打开一个新的窗口。

接着,我们选择页面中的第一个视频元素,将出现一个视频播放器。如果浏览器的解码器正常的话,我们将能够顺利得到播放的视频画面。这里因为默认启动的浏览器环境中,缺少一些解码器,所以无法进行播放。后续的文章中我将介绍如何解决这个问题,因为不是本篇文章的重点,所以就不展开啦。

目前为止,我们已经完成了本小节设置的测试目标,所以可以关闭窗口,完成录制。当我们关闭测试使用的浏览器窗口之后,录制代码将自动保存在我们的文件夹中。
使用 cat pokemon.js 命令查看代码,可以看到类似下面的内容:
const { chromium } = require('playwright');
(async () => {
const browser = await chromium.launch({
headless: false
});
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('https://cn.bing.com/');
await page.getByRole('searchbox', { name: '输入搜索词' }).click();
await page.getByRole('searchbox', { name: '输入搜索词' }).fill('宝可梦朱紫');
await page.getByRole('searchbox', { name: '输入搜索词' }).press('Enter');
const [page1] = await Promise.all([
page.waitForEvent('popup'),
page.getByRole('link', { name: '宝可梦朱·紫_百度百科' }).click()
]);
await page1.locator('#J-video-list div').filter({ hasText: '一分钟了解游戏宝可梦朱·紫 00:55' }).nth(2).click();
await page1.locator('svg').filter({ hasText: '.st0{fill:none;}' }).click();
await page1.close();
await page.close();
// ---------------------
await context.close();
await browser.close();
})();
使用 Node.js 来验证测试用例是否可用
通过 Playwright 生成的代码很多时候并不是完全“work”的,我们可以在完成录制之后,通过 Node.js 来进行测试用例的验证。(你也可以切换为程序支持的、你喜欢的其他语言)
通过 Node 执行我们生成的代码文件:
node pokemon.js
运行我们在文字上面小节中生成的代码,将会自动打开一个新的浏览器窗口,然后在百科页面不停的上下滚动,好像在寻找着什么东西。不久之后,我们将得到一个执行超时报错:
node:internal/process/promises:246
triggerUncaughtException(err, true /* fromPromise */);
^
locator.click: Timeout 30000ms exceeded.
=========================== logs ===========================
waiting for locator('#J-video-list div').filter({ hasText: '一分钟了解游戏宝可梦朱·紫 00:55' }).nth(2)
locator resolved to visible <div class="second-video-item-mask">…</div>
attempting click action
waiting for element to be visible, enabled and stable
element is visible, enabled and stable
scrolling into view if needed
done scrolling
<div class="second-video-item-player J-second-player-…></div> intercepts pointer events
retrying click action, attempt #1
waiting for element to be visible, enabled and stable
element is visible, enabled and stable
scrolling into view if needed
done scrolling
...
...
============================================================
at /Users/soulteary/Lab/playwright/pokemon.js:17:149 {
name: 'TimeoutError'
}
出现这个错误的原因,是因为我们在录制的时候,可能选择到了因为一些特殊条件才会出现的元素路径,或者浏览器中的 JavaScript 随机生成的 HTML Elements 标识(ID、Class 等等)。
这个时候,需要我们打开有问题的页面,手动调整需要交互的元素的“定位方式”或者交互方式。比如,这里出现问题的是这一行代码:
await page1.locator('#J-video-list div').filter({ hasText: '一分钟了解游戏宝可梦朱·紫 00:55' }).nth(2).click();
它告诉 Playwright 在新打开的页面 page1 中先找到 #J-video-list 下所有的 div 然后找到包含“一分钟了解游戏宝可梦朱·紫 00:55”文本内容的元素,然后选择这个元素中的第二个(nth(2))子元素,点击它,唤起视频播放器。
这里先不必纠结程序为什么会生成这样一个错误的路由规则,来看看如何简单的解决这个问题吧。后面有机会可以分享下几年前我做自动化测试时,关于页面唯一路径生成的算法实践。
我们可以手动打开一个相同的页面,然后打开页面调试工具,选择一个我们认为合适的有辨识度的元素标识,比如:.J-second-video-item-player-container。
在完成选择之后,我们可以通过在浏览器控制台通过执行下面的代码,来验证查找定位的元素是否和我们预期中的一样(相同且唯一):
Array.from(document.querySelectorAll('.J-second-video-item-player-container')).filter((item)=>item.innerText.includes('一分钟了解游戏宝可梦朱·紫'))
这里有一个小技巧,我们在验证任意子元素中“包含文本内容”的时候,可以把空格之后的内容删除掉,不影响最终结果。
验证元素标识完毕之后,我们来调整生成的代码:
const { chromium } = require('playwright');
(async () => {
const browser = await chromium.launch({
headless: false
});
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('https://cn.bing.com/');
await page.getByRole('searchbox', { name: '输入搜索词' }).click();
await page.getByRole('searchbox', { name: '输入搜索词' }).fill('宝可梦朱紫');
await page.getByRole('searchbox', { name: '输入搜索词' }).press('Enter');
const [page1] = await Promise.all([
page.waitForEvent('popup'),
page.getByRole('link', { name: '宝可梦朱·紫_百度百科' }).click()
]);
await page1.locator('.J-second-video-item-player-container').filter({ hasText: '一分钟了解游戏宝可梦朱·紫 00:55' }).click();
await page1.locator('svg').filter({ hasText: '.st0{fill:none;}' }).click();
await page1.close();
await page.close();
// ---------------------
await context.close();
await browser.close();
})();
接着,我们再次执行 node pokemon.js,这次浏览器将符合我们的预期执行:打开搜索引擎,输入要搜索的内容,点击搜索结果的百科条目,然后在新窗口中打开视频播放页面。
当程序执行完毕,也不会再有任何报错信息,我们的第一个“自动化测试”也就搞定啦。
将测试用例迁移到 Docker 容器中
在上面的文章内容中,我们完成了本地的测试和交互验证。如果我们将需要测试的应用的交互功能都进行录制,并且在代码提交的时候、版本发布的时候调用 Playwright 进行测试用例的执行,只把运行结果发送给我们,随着测试测试次数的积累,那么将能节省非常多不必要的“人力成本”。
毕竟偷懒是工程师的美德嘛。
不过总是拿我们自己的设备来进行测试,其实并不现实:除非你舍得自己的设备 7x24 小时开机跑执行程序,并且能够确保这台供电和网络非常稳定,以及你的电脑真的可以只做这一件事。所以,我们一般会考虑使用云服务器、结合 CI 来完成这些工作。
为了稳定、高效地进行测试用例的回归验证,我们可以选择使用稳定的 Docker 容器来作为测试用例的执行环境,这样一台服务器上实际可以同时运行非常多的测试用例,并且测试用例之间彼此互相隔离,不会影响和干预执行过程和结果。
启动一个容器“浏览器”服务
想要在容器中稳定的运行 Chrome ,将 Chrome 作为服务提供给其他的应用使用,推荐使用 Browserless 这个开源项目。

如果你在本地或者云服务器安装了 Docker,那么可以通过下面的命令,快速启动一个包含了 Chrome 的容器实例,用于测试验证测试程序是否正常:
docker run --rm -it -p 3000:3000 -e "MAX_CONCURRENT_SESSIONS=10" browserless/chrome:1-puppeteer-19.2.2
如果你想作为服务运行,可以去掉 --rm -it,替换为 -d 参数,或者使用 compose 编排文件,搭配更多参数来执行。Browserless 支持的完整的配置项目可以在 Browserless 文档 中找到,在命令执行完毕,我们将得到类似下面的日志。
browserless:server {
browserless:server CONNECTION_TIMEOUT: 60000,
browserless:server MAX_CONCURRENT_SESSIONS: 10,
browserless:server QUEUE_LENGTH: 10,
browserless:server SINGLE_RUN: false,
browserless:server CHROME_REFRESH_TIME: 1800000,
...
调整测试用例程序代码
搞定了测试环境之后,我们对之前调整过的自动生成的测试做一个“副本”:
cp pokemon.js pokemon-in-docker.js
然后找到代码中的启动浏览器的代码:
const browser = await chromium.launch({
headless: false
});
将其替换为调用 CDP 协议启动 Docker 中的浏览器( localhost 这个地址需要调整为你启动服务的可访问地址):
const browser = await chromium.connectOverCDP("ws://localhost:3000");
保存代码,执行 node pokemon-in-docker.js 稍等片刻,程序就顺利执行完毕了,因为实际的执行过程在远端(容器中),所以这次不会弹出任何浏览器窗口。
在 Docker 容器的日志中,我们将看到类似下面的输出:
browserless:job W18CF0FKU0R4YUPZ7NDMZ864B11FJ41O: /: Inbound WebSocket request. +3h
browserless:hardware Checking overload status: CPU 1% Memory 12% +3h
browserless:job W18CF0FKU0R4YUPZ7NDMZ864B11FJ41O: Adding new job to queue. +3ms
browserless:server Starting new job +4m
browserless:system Generating fresh chrome browser +3h
browserless:job W18CF0FKU0R4YUPZ7NDMZ864B11FJ41O: Getting browser. +0ms
browserless:chrome-helper Launching Chrome with args: {
browserless:chrome-helper "args": [
...
...
browserless:chrome-helper } +3h
browserless:chrome-helper Chrome PID: 482 +124ms
browserless:chrome-helper Finding prior pages +1ms
browserless:chrome-helper Found 1 pages +16ms
browserless:chrome-helper Setting up page Unknown +0ms
browserless:chrome-helper Injecting download dir "/usr/src/app/workspace" +0ms
browserless:system Chrome launched 142ms +142ms
browserless:system Got chrome instance +0ms
browserless:job W18CF0FKU0R4YUPZ7NDMZ864B11FJ41O: Starting session. +142ms
browserless:job W18CF0FKU0R4YUPZ7NDMZ864B11FJ41O: Proxying request to /devtools/browser route: ws://127.0.0.1:39839/devtools/browser/5453abb9-b24e-4302-9212-e227749c5d79. +0ms
browserless:chrome-helper Setting up file:// protocol request rejection +2ms
browserless:chrome-helper Setting up page Unknown +246ms
browserless:chrome-helper Injecting download dir "/usr/src/app/workspace" +0ms
browserless:chrome-helper Setting up file:// protocol request rejection +1ms
browserless:chrome-helper Setting up page Unknown +2s
browserless:chrome-helper Injecting download dir "/usr/src/app/workspace" +0ms
browserless:chrome-helper Setting up file:// protocol request rejection +2ms
browserless:server W18CF0FKU0R4YUPZ7NDMZ864B11FJ41O: Recording successful stat and cleaning up. +6s
browserless:job W18CF0FKU0R4YUPZ7NDMZ864B11FJ41O: Cleaning up job +6s
browserless:job W18CF0FKU0R4YUPZ7NDMZ864B11FJ41O: Browser not needed, closing +0ms
browserless:chrome-helper Shutting down browser with close command +4s
browserless:job W18CF0FKU0R4YUPZ7NDMZ864B11FJ41O: Browser cleanup complete. +1ms
browserless:server Current workload complete. +1ms
browserless:chrome-helper Sending SIGKILL signal to browser process 482 +1ms
browserless:chrome-helper Removing temp data-dir /tmp/browserless-data-dir-eEZKKT +18ms
browserless:chrome-helper Garbage collecting and removing listeners +40ms
browserless:chrome-helper Temp dir /tmp/browserless-data-dir-eEZKKT removed successfully +11ms
browserless:server Health check stats: CPU 3%,0 MEM: 11%,11% +28s
browserless:server Current period usage: {"date":1669647780850,"error":0,"rejected":0,"successful":1,"timedout":0,"totalTime":5959,"maxTime":5959,"minTime":5959,"meanTime":5959,"maxConcurrent":1} +0ms
如果你希望执行结果的成功/失败,展示的更明显一些,我们可以根据自己的实际情况,添加一些“成功/失败通知”(比如微信、飞书的通知 WebHook、PushOver 的服务等)。
或者索性借助 CI 工具对 CI 任务执行情况统计能力,进行任务执行情况汇总统计,也未尝不可。
其他
Playwright 和它的好兄弟 Puppeteer,以及 Browserless 除了进行自动化测试之外,其实还能做很多有趣的东西。
比如,在比较早的时候,我曾经分享了过一个用在运营场景的玩法《使用 Node.js 生成方便传播的图片》。你也可以拿它来生成招聘海报等等你能想到的东西,或者任何你觉得用 HTML、CSS、JS 或者浏览器端能力做起来比较省力的活儿。
毕竟偷懒是工程师的美德嘛(重要的话要说三遍)。
最后
时间不早啦,本篇文章先写到这里吧。
后面有机会我将会继续展开本文中尚未聊到,但是在生产过程中非常重要的:如何优化测试服务稳定性、如何提升测试程序的执行性能、如何和 CI/CD 基础技术设施结合使用,以及在折腾过程中的踩坑实战细节。
–EOF
我们有一个小小的折腾群,里面聚集了一些喜欢折腾的小伙伴。
在不发广告的情况下,我们在里面会一起聊聊软硬件、HomeLab、编程上的一些问题,也会在群里不定期的分享一些技术沙龙的资料。
喜欢折腾的小伙伴,欢迎阅读下面的内容,扫码添加好友。
- 关于“交友”的一些建议和看法
- 添加好友,请备注实名和公司或学校、注明来源和目的,否则不会通过审核。
- 关于折腾群入群的那些事
本文使用「署名 4.0 国际 (CC BY 4.0)」许可协议,欢迎转载、或重新修改使用,但需要注明来源。 署名 4.0 国际 (CC BY 4.0)
本文作者: 苏洋
创建时间: 2022年11月28日
统计字数: 5849字
阅读时间: 12分钟阅读
本文链接: https://soulteary.com/2022/11/28/playwrights-concise-introductory-tutorial-recording-automated-test-cases-and-using-it-with-docker.html