[Pytorch系列-25]:神经网络基础 - 单个无激活函数的神经元实现简单线性回归 - 2
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/120600611
目录
前言 深度学习模型框架
第1章 业务领域分析
1.1 步骤1-1:业务领域分析
1.2 步骤1-2:业务建模
1.3 代码实例前置条件
第2章 前向运算模型定义
2.1 步骤2-1:数据集选择
2.2 步骤2-2:数据预处理
2.3 步骤2-3:神经网络建模
2.4 步骤2-4:神经网络输出
第3章 后向运算模型定义
3.1 步骤3-1:定义loss函数
3.2 步骤3-2:定义优化器
3.3 步骤3-3:模型训练
3.4 步骤3-4:模型验证
3.5 步骤3-5:模型可视化
第4章 模型部署
4.1 步骤4-1:模型部署
前言 深度学习模型框架
[人工智能-深度学习-8]:神经网络基础 - 机器学习、深度学习模型、模型训练_文火冰糖(王文兵)的博客-CSDN博客_神经网络与深度学习第1章 白话机器学习[人工智能-综述-4]:白话深度学习-- 无基础小白都能理解机器学习的核心概念_文火冰糖(王文兵)的博客-CSDN博客[人工智能-深度学习-7]:神经网络基础 - 人工神经网络ANN_文火冰糖(王文兵)的博客-CSDN博客第2章 机器学习的模型与步骤2.1深度学习与机器学习上述三个概念中:人工智能的概念最广泛,所以有能机器具有类”人“一样智能的技术、非技术(如伦理)的领域,都是人工智能。机器获取“智能”的一个重要手段是,机器具备“自我学习”的能力,...https://blog.csdn.net/HiWangWenBing/article/details/120462734
第1章 业务领域分析
1.1 步骤1-1:业务领域分析
![[Pytorch系列-25]:神经网络基础 - 单个无激活函数的神经元实现简单线性回归 - 2_第1张图片](http://img.e-com-net.com/image/info8/8c490db54e8b454c8114809daba9d690.jpg)
1.2 步骤1-2:业务建模
![[Pytorch系列-25]:神经网络基础 - 单个无激活函数的神经元实现简单线性回归 - 2_第2张图片](http://img.e-com-net.com/image/info8/e9075eb1e637472f98926ac94c5fc83c.jpg)
1.3 代码实例前置条件
#环境准备
import numpy as np # numpy数组库
import math # 数学运算库
import matplotlib.pyplot as plt # 画图库
import torch # torch基础库
import torch.nn as nn # torch神经网络库
print("Hello World")
print(torch.__version__)
print(torch.cuda.is_available())Hello World 1.8.0 False
第2章 前向运算模型定义
2.1 步骤2-1:数据集选择
![[Pytorch系列-25]:神经网络基础 - 单个无激活函数的神经元实现简单线性回归 - 2_第3张图片](http://img.e-com-net.com/image/info8/3826d3999f3547528005728701586402.jpg)
这里不需要采用已有的开源数据集,只需要自己构建数据集即可。
![[Pytorch系列-25]:神经网络基础 - 单个无激活函数的神经元实现简单线性回归 - 2_第4张图片](http://img.e-com-net.com/image/info8/a086ce66fa8b4a27a93cc3a2c4613c04.jpg)
#2-1 准备数据集
x_sample = np.linspace(0, 5, 64)
noise = np.random.randn(64)
y_sample = 2 * x_sample + 1 + noise
y_line = 2 * x_sample + 1
#可视化数据
plt.scatter(x_sample, y_sample)
plt.plot(x_sample, y_line,'red')![[Pytorch系列-25]:神经网络基础 - 单个无激活函数的神经元实现简单线性回归 - 2_第5张图片](http://img.e-com-net.com/image/info8/57832de765f447e5a1b763995bbffe16.jpg)
2.2 步骤2-2:数据预处理
(1)把numpy一维数据转换成二维样本数据
(2)把numpy样本数据转换成torch样本数据
# 2-2 对数据预处理
print("Numpy原始样本的形状")
print(x_sample.shape)
print(y_sample.shape)
# 把一维线性数据转换成二维样本数据,每个样本数据为一维
print("\nNumpy训练样本的形状")
x_numpy = x_sample.reshape(-1, 1).astype('float32')
y_numpy = y_sample.reshape(-1, 1).astype('float32')
print(x_numpy.shape)
print(y_numpy.shape)
# numpy样本数据转换成pytorch样本数据
print("\ntorch训练样本的形状")
x_train = torch.from_numpy(x_numpy)
y_train = torch.from_numpy(y_numpy)
print(x_train.shape)
print(y_train.shape)
plt.scatter(x_train, y_train)Numpy原始样本的形状 (64,) (64,) Numpy训练样本的形状 (64, 1) (64, 1) torch训练样本的形状 torch.Size([64, 1]) torch.Size([64, 1])
Out[3]:
![[Pytorch系列-25]:神经网络基础 - 单个无激活函数的神经元实现简单线性回归 - 2_第6张图片](http://img.e-com-net.com/image/info8/69dd6ae4ab3a4fbead3b5a6eaa7bdb1a.jpg)
2.3 步骤2-3:神经网络建模
这里的神经网络模型是单输入(size=1)、单输出(size=1)、无激活函数的线性神经元。
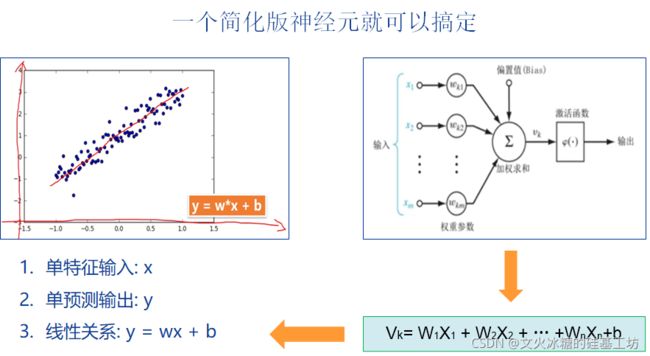
# 2-3 定义网络模型
print("定义并初始化模型")
w = Variable(torch.randn(1), requires_grad=True)
b = Variable(torch.randn(1), requires_grad=True)
print(w, w.data)
print(b, b.data)
def linear_mode(x):
return (w * x + b)
model = linear_mode定义并初始化模型 tensor([0.1358], requires_grad=True) tensor([0.1358]) tensor([0.4257], requires_grad=True) tensor([0.4257])
2.4 步骤2-4:神经网络输出
# 2-4 定义网络预测输出
y_pred = linear_mode(x_train)
print(y_pred.shape)torch.Size([64, 1])
备注:输出是64个样本的一维数据
第3章 后向运算模型定义
3.1 步骤3-1:定义loss函数
这里采用的MSE loss函数
# 3-1 定义loss函数:
# loss_fn= MSE loss
def MSELoss(y_, y):
return (torch.mean((y_ - y)**2))
loss_fn = MSELoss
print(loss_fn)3.2 步骤3-2:定义优化器
# 3-2 定义优化器
Learning_rate = 0.01 #学习率
# lr:指明学习率
def optimizer_SGD_step(lr):
w.data = w.data - lr * w.grad.data
b.data = b.data - lr * b.grad.data
optimizer = optimizer_SGD_step
print(optimizer)3.3 步骤3-3:模型训练
# 3-3 模型训练
w = Variable(torch.randn(1), requires_grad=True)
b = Variable(torch.randn(1), requires_grad=True)
# 定义迭代次数
epochs = 500
loss_history = [] #训练过程中的loss数据
w_history = [] #训练过程中的w参数值
b_history = [] #训练过程中的b参数值
for i in range(0, epochs):
#(1) 前向计算
y_pred = model(x_train)
#(2) 计算loss
loss = loss_fn(y_pred, y_train)
#(3) 反向求导
loss.backward(retain_graph=True)
#(4) 反向迭代
optimizer_SGD_step(Learning_rate)
#(5) 复位优化器的梯度
#optimizer.zero_grad()
w.grad.zero_()
b.grad.zero_()
#记录迭代数据
loss_history.append(loss.data)
w_history.append(w.data)
b_history.append(b.data)
if(i % 100 == 0):
print('epoch {} loss {:.4f}'.format(i, loss.item()))
print("\n迭代完成")
print("\n训练后w参数值:", w)
print("\n训练后b参数值:", b)
print("\n最小损失数值 :", loss)
print(len(loss_history))
print(len(w_history))
print(len(b_history))epoch 0 loss 42.0689 epoch 100 loss 1.0441 epoch 200 loss 1.0440 epoch 300 loss 1.0439 epoch 400 loss 1.0439 迭代完成 训练后w参数值: Parameter containing: tensor([[1.8530]], requires_grad=True) 1.8529784679412842 训练后b参数值: Parameter containing: tensor([1.2702], requires_grad=True) 1.2701895236968994 最小损失数值 : tensor(1.0439, grad_fn=) 1.0438624620437622 500 500 500
3.4 步骤3-4:模型验证
NA
3.5 步骤3-5:模型可视化
# 3-4 可视化模型数据
#model返回的是总tensor,包含grad_fn,用data提取出的tensor是纯tensor
y_pred = model(x_train).data.numpy().squeeze()
print(x_train.shape)
print(y_pred.shape)
print(y_line.shape)
plt.scatter(x_train, y_train, label='SampleLabel')
plt.plot(x_train, y_pred, label='Predicted')
plt.plot(x_train, y_line, label='Line')
plt.legend()
plt.show()torch.Size([64, 1]) (64,) (64,)
![[Pytorch系列-25]:神经网络基础 - 单个无激活函数的神经元实现简单线性回归 - 2_第7张图片](http://img.e-com-net.com/image/info8/8bb131524c914e339ba4076f7de7ba50.jpg)
#显示loss的历史数据
plt.plot(loss_history, "r+")
plt.title("loss value")![[Pytorch系列-25]:神经网络基础 - 单个无激活函数的神经元实现简单线性回归 - 2_第8张图片](http://img.e-com-net.com/image/info8/d285d5b466984258b5596d370e87fa35.jpg)
#显示w参数的历史数据
plt.plot(w_history, "r+")
plt.title("w value")![[Pytorch系列-25]:神经网络基础 - 单个无激活函数的神经元实现简单线性回归 - 2_第9张图片](http://img.e-com-net.com/image/info8/30e90298993447fe9996978274201111.png)
#显示b参数的历史数据
plt.plot(b_history, "r+")
plt.title("b value")![[Pytorch系列-25]:神经网络基础 - 单个无激活函数的神经元实现简单线性回归 - 2_第10张图片](http://img.e-com-net.com/image/info8/c9c5e7c01238479fb66f697a9f817a01.jpg)
第4章 模型部署
4.1 步骤4-1:模型部署
NA
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/120600611