Web数据流的一生——从前端界面到后端数据,以及万级QPS的后台服务搭建
0. 目标读者
本文目标读者是熟悉Linux开发的初级后端/嵌入式开发工程师,熟悉TCP/IP协议,对HTTP协议有一定的了解和认知。
1. 知识背景
1.1 HTTP协议
这里不做展开的解释,这里需要注意以下几点
a.1 HTTP协议是在TCP协议框架上进行的封装。
a.2 HTTP协议版本与特性很多,大概至少有0.9、1.0、1.1、2.0。目前使用较多的是HTTP 1.1,有兴趣的同学可以爬爬 RFC 2616。这里为标准委员会为HTTP协议定了各种 纯协议层面,与某个具体业务层面关联不大 的泛化通用通信规则。但请记住,我们具体的业务逻辑虽然和这些协议层面的东西不大,但这块依旧会有一定的逻辑处理和开发量存在,往往这部分是由CGI(Common Gateway Interface)服务器承担的。
1.2 XML结构
这里不展开,直接可以查看另一篇博客里有详细的解释。
基于Vue的快速入门web开发————0.1 预备知识:Html 结构
1.3 静态资源与动态资源
静态资源:⼀般客户端发送请求到web服务器,web服务器从硬盘在取到相应的⽂件,返回给客户端,客户端解析并渲染显示出来。
动态资源:⼀般客户端请求的动态资源,先将请求交于web容器,web容器连接数据库,数据库处理数据之后,将内容交给web服务器,web服务器返回给客户端解析渲染处理。
1.4 VPS? ECS? DNS? NGINX?
VPS(Virtual Private Server):利用虚拟服务器软件在一台物理服务器上创建多个相互隔离的小服务器,一般来说,我们目前能买到的服务器基本上都是VPS,直接整台物理服务器买的市场已经越来越少。但从使用感受上来说,VPS和真实的物理服务器没体验上的差别,
ECS(Elastic Compute Service):顾名思义,弹性服务器。啥能弹呢,CPU,带宽,内存都能弹。ECS是基于VPS的一种特殊服务器,相当于把物理上的服务器资源池化泛化了,做了一个抽象层,让所有硬件资源可以动态分配和扩容。最开始起源于Amazon,那时候为了对抗黑五(国外的双11,618),Amazon搞了很多服务器来保证用户体验,黑五的时候不崩溃。后来发现,不是黑五的时候,这些服务器都给闲置了,太浪费了。就想着怎么利用这些硬件资源搞点事情,ECS就应运而生了。自己Amazon的主营业务层支持弹性分配,在平常的时候压少一些,把闲置硬件在非高峰期的时候,租出去。开源节流,创收了!如今这个商业模式走通后,基本上所有的VPS都是ECS了。根据这个背景,也能理解为什么现在国内运营ECS做的比较大的厂,都是自身原有业务量存在一定高峰期和非高峰期特性的厂家了(例如阿里,阿里的业务流量特点和Amazon就几乎完全一样)。
DNS(Domain Name System):域名系统,这系统也是运行在一个服务器上。简单的说就是在域名和IP地址之间建立起映射关系。虽然简单说来,只是一个映射关系,但当域名这玩意足够庞大的时候,这个系统实际上并没有那么简单了,会存在一个层级关系的分层查找,类似查字典一样逐步缩小范围。不关注的时候,可以简单的认为本质就是一个映射。需要注意的是,这个映射往往不是1对1,而是1对N。
Nginx(engine x):一个高性能的HTTP和反向代理web服务器。简单说来,浏览器上的地址,http:// 之后到第一个/之前的部分是属于DNS解析的范畴。后面的部分则是依靠Nginx去解析定位到具体的服务器上。聪明如你,这里需要注意的是,这个映射往往也不是1对1,而是1对N。
2. 从浏览器输入网址开始看
我们用这样虚假的URL的解析开始:
http://aiyanzielf.cn/api/auth/13456789123
2.1 当我们往浏览器里输入了一串地址,后面发生了什么?
让我们用一张图开始这里的讲解:
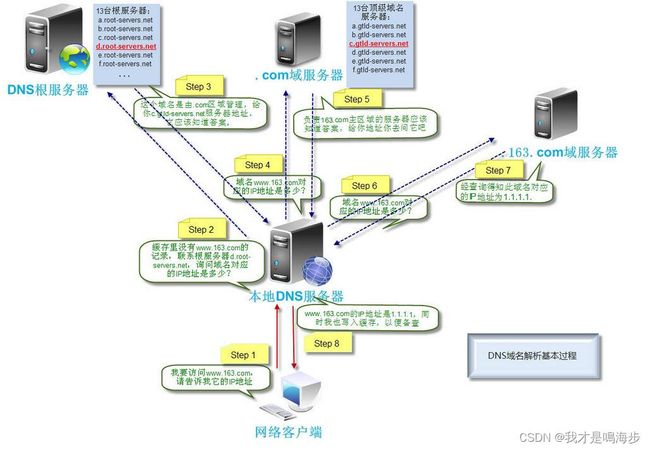
整个过程大概流程是先问本地的DNS服务器,我要访问的这个地址IP多少,如果本地DNS服务器前阵子刚刚查过这事儿,就直接返回给你了。本地DNS不知道的时候,就去问DNS根服务器,然后DNS根服务器查自己的表,找到的话告诉你可以再去问哪个对应的域服务器,然后逐层的问下去。
这里需要注意这种机制,和编程中的函数缓存 (Function caching) 机制有异曲同工之处,而且这种简单的手法几乎遍布了整个Web技术栈,下面讲的几乎每一步都多少能看到这种机制存在的影子,也是一种典型的 以空间换时间 手法。编程的哲学里,空间和时间一直是无法两全的。
假设我们已经为我们的虚假地址购买了DNS解析服务,那么对应的配置关系已经缓存到了我们运营商的DNS服务器中,我们问到了IP地址是 1.2.3.4。一般这一步也是无需我们有相关开发任务的,只需要找VPS的提供商购买DNS解析服务,并且支付费用后将购买的域名和对应的VPS IP地址配置好关联即可。
这里同样需要注意,在大型后台环境中,这里的关联关系会复杂很多,一个域名可能会跟上几十上百个IP地址。但即便很多,对于某个固定时刻的数据流,这个关系是固定的。我们常听到的DNS负载均衡,就是指的有一些算法,能够根据IP或者其他信息,将连接者分配到合适的服务器里去,这里最简单的方式就是轮流分配。
假设一切顺利,到这里,浏览器已经把我们的虚假URL已经变成了:
http://1.2.3.4/api/auth/13456789123
数据流向:
PS. 实际实现上并没有这种替换,只是为了便于理解。如果熟悉TCP协议,则可以通过抓包发现,只是这个HTTP请求包的目的IP地址换成了DNS服务器拿到的地址,但报文中的URL还是原URL,这里为了方便讲解,做这样的替换。
2.2 反向代理服务器上场
一般来说,大型网站在DNS服务器中存放的IP地址,往往不是真实的WEB应用地址,而是存放了他们的反向代理服务器的IP地址。当然,在简单部署的时候,反向代理服务器和WEB应用服务可以在同一个IP里,甚至简单的时候,放在一个系统里也没问题的。
2.2.1 正向代理与反向代理
这里简单讲一下正向代理与反向代理的区别,一般正向代理是和客户端在同一网络中的,如下图所示,目的是将本局域网内的所有访问地址进行筛选,然后访问不同的服务器。
正向代理:
而反向代理则是和服务器程序出于一个局域网内,将客户端的请求分发到特定的服务器中。如下图所示。
反向代理:
2.2.2 Nginx在Web数据流的一生中的角色
了解了正向代理和反向代理,我们的Nginx一般处于反向代理的位置,他的作用是将不同的URL分配给不同的服务IP或者端口上。是一个高性能的静态URL反向代理服务器,由于其开箱即用,性能搞,配置极为简单,所以广泛应用在WEB服务中。
这里以一个真实的nginx.conf文件进行简单的和本文业务相关的部分进行讲解。
# 全局块
------------------------------------------------------------------------------
worker_processes 1;
------------------------------------------------------------------------------
# events块
events {
worker_connections 1024;
}
# http块
http {
------------------------------------------------------------------------------# http全局块
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
#gzip on;
------------------------------------------------------------------------------
# server块
server {
# server全局块
listen 80;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
# location块
location / {
root html;
index index.html index.htm;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
# proxy the PHP scripts to Apache listening on 127.0.0.1:80
#
#location ~ \.php$ {
# proxy_pass http://127.0.0.1;
#}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
#
#location ~ \.php$ {
# root html;
# fastcgi_pass 127.0.0.1:9000;
# fastcgi_index index.php;
# fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
# include fastcgi_params;
#}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
#location ~ /\.ht {
# deny all;
#}
}
# 可以配置多个server块
}
这里我们主要需要关注的是,nginx.conf中的location块。这块主要的作用目标是URL中,http:// 开始到第一个 / 之后的部分,也就是我们样例中的/api/auth/13456789123 这块,这段会被
location之后是类似于正则匹配的逻辑,之后对应的 {}中跟随的,就是满足正则匹配命中之后,这个连接应该被导向的位置。具体的location语法不是本文的重点内容。只要理解可以配置多个location,并且有多种正则匹配规则,然后按照顺序依次匹配即可。
这里Nginx会根据location的配置,将URL进行一定的修改,例如如果配置了下图中的流向规则,数据流向:
那么浏览器传来的URL原样可能是这样:
http://1.2.3.4/api/auth/13456789123
但在后端服务器看来,已经改成了:
http://127.0.0.1:8090/auth/13456789123
这里需要注意,被Nginx解析的api和原IP地址已经被吞掉,换成了location中的配置,然后剩下没匹配中的则继续参与后续逻辑。而这个数据包也被Nginx发到了本地的8090端口中,到了下一站。
2.3 WSGI / Servlet / FastCGI 等通用网关服务器
一般来说,超级轻量的DEMO后端,实际上到这一步就可以直接解析HTTP报文并进行回复了。但这里工程应用上,一般又多了一层。这里先说明一下当下比较流行的web服务部署形式,引用一段博客的话是这样的:
在Web部署的方案上,有一个方案是目前应用最广泛的:
首先,部署一个Web服务器专门用来处理HTTP协议层面相关的事情,比如如何在一个物理机上提供多个不同的Web服务(单IP多域名,单IP多端口等)这种事情。
然后,部署一个用各种语言编写(Java, PHP, Python, Ruby等)的应用程序,这个应用程序会从Web服务器上接收客户端的请求,处理完成后,再返回响应给Web服务器,最后由Web服务器返回给客户端。
那么这两步实际上对应了两个部分,这里以Python为例,处理第一部分业务的就属于WSGI,常见的轮子有uWSGI和gunicorn,以下援引gunicorn官网的一张结构图来简单示例整体方式。

图中示例的是一个动静分离的架构,也是目前的主流WEB服务架构。一个外部请求来了之后,先到达反向代理服务器,大多数时候是Nginx,然后将静态资源请求分离出来给对应的静态资源服务器,或者是CDN(内容分发服务器)。对于动态主演资源则转发给WSGI,然后由WSGI将对应请求发送给具体的应用框架,图中的牛角杯(不少人会认为是个辣椒)也是一个流行的Python Web应用框架Flask。
2.3.1 这里先讲解一下最古老的最低效但最容易理解的CGI交互
拿一个最简单的HTML的表单做为例子讲解:
<div style="font-weight:bold; font-size:15px">Method: GETdiv>
<div>please input two number:<div>
<form method="get" action="./cgi-bin/get.cgi">
<input type="txt" size="3" name="a">+
<input type="txt" size="3" name="b">=
<input type="submit" value="sum">
form>
这段代码在web中展示的效果如下:
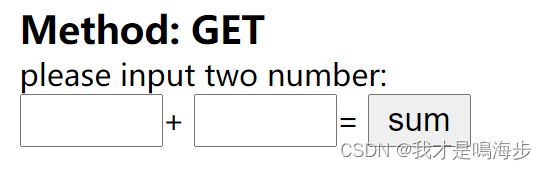
当我们第一个框输入2,第二个框输入3的时候,点sum,可以观察到浏览器的地址栏实际上会变成这样:
…省略不表…/cgi-bin/get?a=2&b=3
实际上,在点击sum按钮后,前端会给HTTP服务器发送一个cgi请求,找到cgi-bin路径下的get.cgi程序进行运行。然后前端会将页面上的一些固有HTTP协议相关的信息,还有我们输入的 两个待相加的数字对应的name变量(放在URL中)一并传输过去。
这个时候HTTP服务器会根据URL的路径和对应配置文件找到后端的对应CGI程序,那么对于这个最简单的求+法运算,这里的CGI程序样例如下(C语言开发):
int main(void)
{
char *data;
char a[10],b[10];
printf("Content-Type:text/html\n\n");
printf("\n");
printf("");
printf("\nGet Method \n\n");
printf("\n");
printf("\n");
data = getenv("QUERY_STRING");
if(sscanf(data,"a=%[^&]&b=%s",a,b)!=2){
printf("Error parameters should be entered!\n");
}else{
printf("a + b = %d\n",atoi(a)+atoi(b));
}
time_t timep;
time (&timep);
printf("Current Time: %s",ctime(&timep));
printf("
");
printf("");
printf("\n");
printf("\n");
printf("\n");
return 0;
}
实际上后端的CGI程序主要依靠一些固定的环境变量去提取对应HTTP服务器拿到的数据,例如这个场景了就是将a,b两个变量放到了请求串中,然后CGI程序通过读取程序启动时候拿到的环境变量"QUERY_STRING",即可拿到了前端请求的数据,那么最后进行对应的业务处理即可。
疑问来了,拿到数据后怎么返回呢?实际上那些看似调试代码的printf即是CGI程序返回给前端的信息,CGI标准规定通过程序的标准输出与前端交互。
2.3.2 梳理一下CGI的数据流
CGI的交互数据流大体上是如下的样子:
其中URL请求变量到HTTP服务器这一部交互的协议形式是HTTP协议,HTTP服务器到CGI应用之间使用的实际上是CGI规范,说成是一个广义的协议也可以。
熟悉Linux C开发的小伙伴可能已经通过 getenv 这个函数看到了一些端倪。没错,整个交互过程 HTTP服务器到CGI应用实际上是通过HTTP服务器主动启动了一个CGI应用的程序,并且通过传递环境变量的方式交互的,学术上说的话,就叫 fork-and-execute 模式。这种模式显而易见能够看到一些问题,频繁的请求会导致上面简短的CGI程序反复被 fork-and-execute,整体性能很差。后续各类优化这里不展开,这里的核心是讲明数据流的走向。
FastCGI 优化了这个步骤,将不会反复 fork CGI程序,而是通过进程间通信的方式,将想要传递的环境变量,给了CGI程序,CGI程序拿到这些变量处理完后,也是通过进程间通信的方式还给 HTTP服务器。没有了反复的fork,性能是显然会提升很多的。
而理解了 FastCGI 的流程,再来看现代的 WSGI 和 Servlet 就容易的多。
2.3.3 目前业务上主流的 WSGI 和 Servlet
理解了FastCGI后,其实 WSGI 和 Servlet 就是 Python版本(WSGI)和Java版本(Servlet)的 FastCGI。
Python 和 Java 各自规定了自己的 HTTP服务器和业务应用对应的交互规则,结合 CGI的数据流 来看,就是定了一套交互效率更高的getenv接口罢了,这里也不细细展开。
重要的是,讲一下为什么要多出一个HTTP服务器这个角色。
CGI的数据流 这里有一个特点,getenv之后的数据实际上已经和HTTP协议几乎解耦了,只有纯粹业务相关的数据,而实际业务的开发过程中,我们也只是希望借用HTTP这个载体,将业务的数据传给业务处理模块罢了,至于是HTTP还是PTTH协议,我们压根不care。HTTP服务器这一层就是为了消化HTTP协议的逻辑,将真实的业务相关数据还原给用户存在的。也就如同最开头讲解的背景知识a.2 HTTP协议版本很多,我们不希望自己花过多的精力放在理解协议上,我们只希望使用它达成自己的目的。
2.4 WEB数据流总结回顾
对于一个成熟的架构来说,整体数据流是浏览器先访问逐级DNS服务器,拿到域名对应的IP地址后,根据IP地址进行访问对应的应用。这个IP地址可能根据请求的IP地址不同而会返回不同的IP地址。而后,DNS服务器返回的目标IP地址后面第一个往往是反向代理服务器,这个服务器会将请求分配到多个HTTP服务器上,以达到负载均衡的效果。而每个HTTP服务器背后一般也对应多个应用实例。
3. 从数据流的一生分析如何简单搭一个承受万级QPS的后台
目前我们可以看到整体数据流实际上已经被分散到多个应用实例上去了,那么整体上思路有两种:
a. 提升应用实例的数量
b,降低每个应用实例处理耗时
3.1 提升应用实例的数量
对于提升实例的数量可以通过启动多个HTTP服务器,生成更多实例的方式,或者部署更多反向代理服务器,关联更多的HTTP服务器的方式,都可以增加末端实例的数量。但在不购买更多VPS的情况下,这种QPS的提升实际上会受到硬件具体CPU核数的限制,可以简单的把应用实例想象成一个独立的线程,线程数量增大的确会提高并发量,但是过多的线程同样会造成上下文切换的开销变大,整体的数量一定会存在一个合理的峰值,高于峰值的单机实例数造成的会是降低的QPS。
一般来说,这里需要一定的调优和测压,我们可以通过JMeter等工具去测试API的平均耗时。在单一变量法则的情况下,测出最优的实例部署数量。
3.2 降低每个应用实例处理耗时
第一个方法从某种程度上来说,谁钱多买多个服务器就可以理论上处理好全世界人的问题。但钱总不是无限的,那么尽可能降低每个应用实例的处理耗时,就是一种更加优秀的方式了。而目前的绝大多数技术栈和新框架也都是围绕着这一点展开的。以下说几个目前已经主流很常用的方式:
3.2.1 动静分离
细细想一下,我们大多数的网页中元素,有很多是固定不变的,例如你登陆百度首页,那个爪子就是不变的,那个搜索框也是不变的。但是右上角的登陆,每个账号实际上又都不一样。
这里就大概能分解出动态资源和静态资源的差异了,大多数静态资源的数据流实际上在反向代理服务器那一层就直接被导向到CDN服务器中了,而CDN服务器大多数部署在访问者物理位置比较近的地方,并且会全世界部署很多。这样,实际不是所有的请求都会到末端的应用实例上,变相也提高了QPS。只有动态资源,才需要真的达到应用实例中,进行处理。
3.2.2 内存数据库
动静分离从某种意义上来说,还是和提升应用实例的数量类似。没有真的减少每个实例的处理耗时,这里内存数据库就不一样,这是一个缓存的机制。原理上和2.1 缓存函数的机制类似,一般需要访问实例的连接无非是要进行一些增删改查的动作,那么对于查这个动作而言,我们没必要每次都真的问数据库要。要知道访问硬盘和访问内存的速度差异可是天差地别了。我们可以提前将访问过的查询数据进行缓存,再次有同样的请求过来,直接回复过去就好。这里比较常用的就是大名鼎鼎的Redis了。而我们常听到的Redis击穿,雪崩实际上也是Redis这家伙和背后数据库的爱恨情仇,这里不详细展开。
4. 目前大潮流中的技术
相信到这里,也慢慢能理解为什么分布式数据库,分布式缓存会这么流行了。毕竟单个实例的处理能力总是有限,不得已为之整个系统需要每个地方处理好的数据能够进行同步,能够保证不出问题。在大数据和目前WEB技术的背景下,再复杂的技术到最后也是通过某一个实例完成,然后后续会有一些复杂的同步机制和算法确保我们的访问,秒杀,购买等东西能确确实实的正确发生。
x. 相关知识
如果后端开发对前端开发有一定兴趣并且想快速上手前端页面开发,可参考如下文章
a. 基于Vue的快速入门web开发
本文参考文章如下:
b. 一张图看懂DNS域名解析全过程
c. Nginx 配置详解
d. Nginx配置使用详解
e. python wsgi 规范 与java的servlet规范