DolphinScheduler——流程调度工具
目录
一、平台简介
二、竞品软件分析
三、安装部署
3.1 基础环境
3.2 安装前操作
3.3具体安装操作步骤
3.4 名词解释
四.功能介绍
4.1 首页&项目管理
4.1.1 首页
4.1.2 项目管理
4.1.3 任务节点类型和参数设置
4.2 资源中心
4.2.1文件管理
4.2.2 UDF管理
4.3 数据源中心
4.4 监控中心
4.5 安全中心
4.5.1 租户管理
4.5.2 用户管理
4.5.3 告警组管理
4.5.4 Worker分组管理
4.5.5 队列管理
4.5.6 令牌管理
五、参数设置
5.1系统参数
5.2 时间自定义参数
5.3 用户自定义参数
六、平台升级
6.1 升级流程
6.2 升级内容
6.3 新版本问题
七、常见问题
7.1 jar包问题
7.2 权限问题
附录:平台元数据表信息
原创声明:本创作是本人的原创内容,未经授权及禁止肆意转载。此外并未与任何机构合作,原创不易,尊重原创
一、平台简介
- Apache DolphinScheduler(目前处在孵化阶段)是一个分布式、去中心化、易扩展的可视化DAG工作流任务调度系统,其致力于解决数据处理流程中错综复杂的依赖关系,使易于使用,开发人员可以通过非常简单的拖拽操作构建ETL过程。不仅对于ETL开发人员,无法编写代码的人也可以使用此工具进行ETL操作,例如系统管理员和分析师;
- 解决“复杂任务依赖”问题,并且可以实时监视ETL运行状态;
- 支持多租户;
- 支持许多任务类型:Shell,MR,Spark,SQL(mysql,postgresql,hive,sparksql),Python,Sub_Process,Procedure等;
- 支持HA和线性可扩展性
调度系统在数据处理流程中开箱即用。
二、竞品软件分析
| DolphinScheduler |
Azkaban |
Oozie |
|
| 定位 |
解决数据处理流程中错综复杂的依赖关系 |
为了解决Hadoop的任务依赖关系问题 |
管理Hdoop作业(job)的工作流程调度管理系统 |
| 任务类型支持 |
支持传统的shell任务,同时支持大数据平台任务调度:MR、Spark、SQL(mysql、postgresql、hive/sparksql)、python、procedure、sub_process |
ommand、HadoopShell、Java、HadoopJava、Pig、Hive等,支持插件式扩展 |
统一调度hadoop系统中常见的mr任务启动、Java MR、Streaming MR、Pig、Hive、Sqoop、Spark、Shell等 |
| 可视化流程定义 |
所有流、定时操作都是可视化的,通过拖拽来绘制DAG,配置数据源及资源,同时对于第三方系统,提供api方式的操作。 |
通过自定义DSL绘制DAG并打包上传 |
配置相关的调度任务复杂,依赖关系、时间触发、事件触发使用xml语言进行表达 |
| 任务监控支持 |
任务状态、任务类型、重试次数、任务运行机器、可视化变量,以及任务流执行日志 |
只能看到任务状态 |
任务状态、任务类型、任务运行机器、创建时间、启动时间、完成时间等。 |
| 暂停/恢复/补数 |
支持暂停、恢复 补数操作 |
只能先将工作流杀死在重新运行 |
支持启动/停止/暂停/恢复/重新运行:支持启动/停止/暂停/恢复/重新运行: Oozie支持Web,RestApi,Java API操作 |
| 高可用支持 |
支持HA,去中心化的多Master和多Worker |
通过DB支持HA,-但Web Server存在单点故障风险 |
通过DB支持HA |
| 多租户支持 |
dolphinscheduler上的用户可以通过租户和hadoop用户实现多对一或一对一的映射关系。无法做到细节的权限管控。 |
—— |
—— |
| 过载处理能力 |
任务队列机制,单个机器上可调度的任务数量可以灵活配置,当任务过多时会缓存在任务队列中,不会操作机器卡死 |
任务太多时会卡死服务器 |
调度任务时可能出现死锁 |
| 集群扩展支持 |
调度器使用分布式调度,整体的调度能力会随集群的规模线性正常,Master和Worker支持动态上下线,可以自由进行配置 |
只Executor水平扩展 |
参照集群标准 |
| 文件管理 |
支持,可视化管理文件,及相关udf函数等。 |
—— |
—— |
| 邮件报警 |
支持 |
支持 |
支持 |
| 权限控制 |
可以通过对用户进行资源、项目、数据源的访问授权 |
—— |
—— |
| 版本更新迭代 |
持续发展中,升级不会影响当前集群,升级方式操作简单 |
—— |
依赖当前集群版本,如更新最新版,易于现阶段集群不兼容 |
三、安装部署
安装部署文档使用的dolphinscheduler版本为1.3.8,如需升级至最新版2.0以上版本可参照官网升级操作。upgrade
3.1 基础环境
MySQL5.7以上
JDK1.8
zookeeper
Python
其余配置要求参照官网内容即可。
3.2 安装前操作
- 建议直接使用root用户进行安装部署,如使用普通用户部署,需将该用户开启sudo免密及集群内免密。
- 配置/etc/hosts文件,集群内主机名及IP之间映射
- 安装ds的各台机器须配置部署用户免密登录
- ds的安装节点与hdfs和yarn所在节点没有关系,只须要保证ds的worker所在节点有hadoop、hive的安装目录并配置环境变量便可,由于要做为客户端提交命令
3.3具体安装操作步骤
0.下载安装包
可以在官网下载安装包(https://dolphinscheduler.apache.org/zh-cn/download/download.html)此处选择1.3.8版本
- 修改源码中配置文件信息

1)点开根目录下的pom文件,修改里面的集群版本信息,修改为现有集群的信息。
主要修改集群版本、Hadoop及hive版本信息
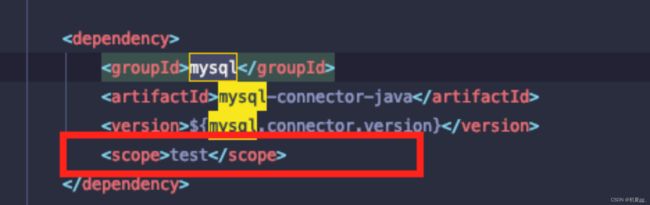
2)去除MySQL包的scope
3) 编译
可以通过服务器进行编译,也可以通过idea编译。
mvn -U clean package -Prelease -Dmaven.test.skip=true
编译后的包如下:
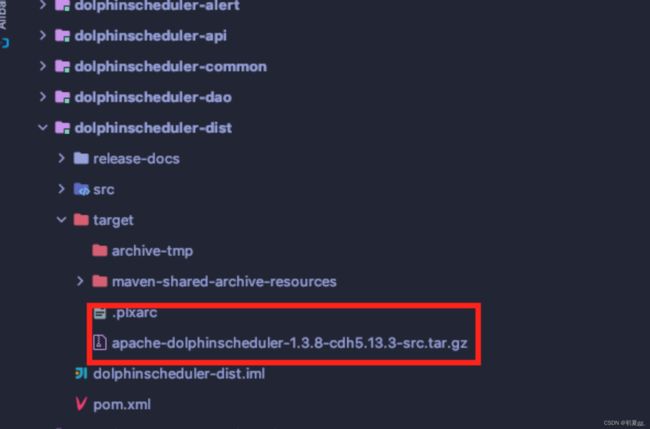
4)将安装包上传至服务器相关目录解压。
tar -zxvf apache-dolphinscheduler-1.3.8-cdh5.13.3-src.tar.gz
修改文件夹权限
chmod -R 755 apache-dolphinscheduler-1.3.8-cdh5.13.3-src
chown -R root:root apache-dolphinscheduler-1.3.8-cdh5.13.3-src
5)使用高权限用户(建议直接使用root),并配置ssh免密。
6)创建dolphinscheduler元数据库-MySQL(用户名及密码可以进行修改)
CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
CREATE USER 'dscheduler'@'%' IDENTIFIED BY 'dscheduler';
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dscheduler'@'%' IDENTIFIED BY 'dscheduler';
flush privileges;
7)初始化数据库连接
vi apache-dolphinscheduler-1.3.8-cdh5.13.3-src/conf/datasource.properties
spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.datasource.url=jdbc:mysql://MySQL连接名:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true
spring.datasource.username=dscheduler
spring.datasource.password=dscheduler
注意:需将postgresql模块屏蔽,将MySQL模块打开,修改MySQL模块信息。
8)在ds的安装目录下执行数据库初始化脚本
./script/create-dolphinscheduler.sh
9)配置ds所需的环境变量
vi apache-dolphinscheduler-1.3.8-cdh5.13.3-src/conf/env/dolphinscheduler_env.sh
注:根据集群上具有的环境进行配置,无用的建议屏蔽掉,也可进行删除。
10)修改配置文件conf/config/install_config.conf相关参数,以下为参考,详细可见配置文件均有标识。
# --------# INSTALL MACHINE# --------#
#因为是在单节点上部署master、worker、API server,所以服务器的IP均为机器IP或者localhost ips="localhost"
masters="localhost"
workers="localhost:default"
alertServer="localhost"
apiServers="localhost"
# DolphinScheduler安装路径,如果不存在会创建
installPath="~/dolphinscheduler"
# 部署用户,填写在 **配置用户免密及权限** 中创建的用户
deployUser="dolphinscheduler"
# -----------------# DolphinScheduler ENV# --------------#
#JAVA_HOME 的路径,是在 **前置准备工作** 安装的JDK中 JAVA_HOME 所在的位置 javaHome="/your/java/home/here"
# ----------------# Database# ---------------------#
#数据库的类型,用户名,密码,IP,端口。其中dbtype目前支持 mysql 和 postgresql
dbtype="mysql" dbhost="localhost:3306"
# 如果你不是以 dolphinscheduler/dolphinscheduler 作为用户名和密码的,需要进行修改 username="dolphinscheduler"
password="dolphinscheduler"
dbname="dolphinscheduler"
# ----------------------# Registry Server# -----------------#
#注册中心地址,zookeeper服务的地址
registryServers="localhost:2181"
11)添加集群配置文件
- 如果集群未启用HA,直接在install_config.conf文件中进行编写
- 如果集群启用了HA,请将hadoop的hdfs-site.xml和core-site.xml拷贝到/conf目录下
12)一键部署
sh install.sh
13) 进程检查
LoggerServer
WorkerServer
MasterServer
14) 服务启停
# 一键停止 sh ./bin/stop-all.sh
# 一键开启 sh ./bin/start-all.sh
# 启停master
sh ./bin/dolphinscheduler-daemon.sh start master-server
sh ./bin/dolphinscheduler-daemon.sh stop master-server
# 启停worker
sh ./bin/dolphinscheduler-daemon.sh start worker-server
sh ./bin/dolphinscheduler-daemon.sh stop worker-server
# 启停api-server
sh ./bin/dolphinscheduler-daemon.sh start api-server
sh ./bin/dolphinscheduler-daemon.sh stop api-server
# 启停logger
sh ./bin/dolphinscheduler-daemon.sh start logger-server
sh ./bin/dolphinscheduler-daemon.sh stop logger-server
# 启停alert
sh ./bin/dolphinscheduler-daemon.sh start alert-server
sh ./bin/dolphinscheduler-daemon.sh stop alert-server
15)前端访问(红色标记为替换实际内容)
apiserver:12345/dolphinscheduler
账户:admin
密码:dolphinscheduler123
3.4 名词解释
- 租户:对应linux系统的用户,平台内一个租户对应很多用户。
- DAG: 全称 Directed Acyclic Graph,简称 DAG。工作流中的 Task 任务以有向无环图的形式组装起来,从入度为零的节点进行拓扑遍历,直到无后继节点为止
- 流程定义:通过拖拽任务节点并建立任务节点的关联所形成的可视化 DAG
- 流程实例:流程实例是流程定义的实例化,可以通过手动启动或定时调度生成。流程定义每运行一次,产生一个流程实例
- 任务实例:任务实例是流程定义中任务节点的实例化,标识着具体的任务执行状态
- 任务类型: 目前支持有 SHELL、SQL、SUB_PROCESS(子流程)、PROCEDURE、MR、SPARK、PYTHON、DEPENDENT(依赖)等,同时计划支持动态插件扩展,注意:其中子 SUB_PROCESS 也是一个单独的流程定义,是可以单独启动执行的
- 调度方式: 系统支持基于 cron 表达式的定时调度和手动调度。命令类型支持:启动工作流、从当前节点开始执行、恢复被容错的工作流、恢复暂停流程、从失败节点开始执行、补数、定时、重跑、暂停、停止、恢复等待线程。其中 恢复被容错的工作流 和 恢复等待线程 两种命令类型是由调度内部控制使用,外部无法调用
- 定时调度:系统采用 quartz 分布式调度器,并同时支持 cron 表达式可视化的生成
- 依赖:系统不单单支持 DAG 简单的前驱和后继节点之间的依赖,同时还提供 任务依赖 节点,支持 流程间的自定义任务依赖
- 优先级 :支持流程实例和任务实例的优先级,如果流程实例和任务实例的优先级不设置,则默认是先进先出
- 邮件告警:支持 SQL任务 查询结果邮件发送,流程实例运行结果邮件告警及容错告警通知
- 失败策略:对于并行运行的任务,如果有任务失败,提供两种失败策略处理方式,继续 是指不管并行运行任务的状态,直到流程失败结束。结束 是指一旦发现失败任务,则同时Kill掉正在运行的并行任务,流程失败结束
- 补数:补历史数据,支持 区间并行和串行 两种补数方式
四.功能介绍
4.1 首页&项目管理
4.1.1 首页
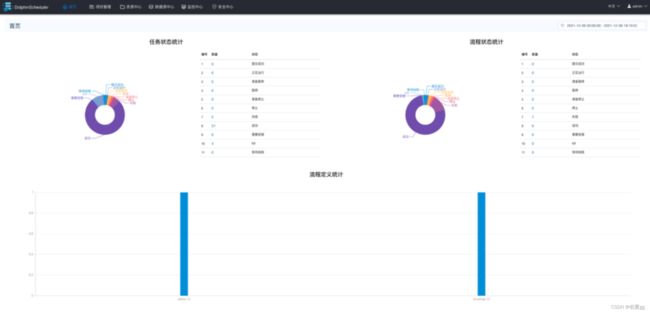
首页包含用户所有项目的任务状态统计、流程状态统计、工程流定义统计。
4.1.2 项目管理
点击项目管理模块下的创建项目进行项目创建。

项目管理包括以下模块:项目首页、工作流(工作流定义、工作流实例、任务实例)
4.1.2.1 项目首页
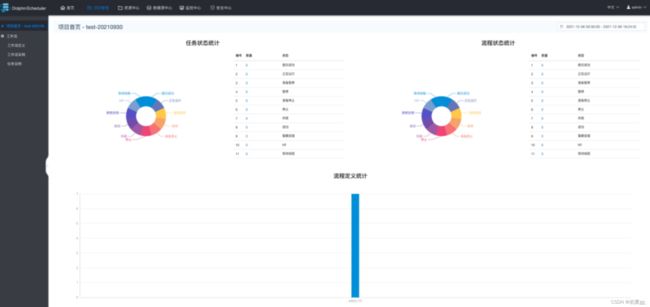
- 项目首页包含该项目的任务状态统计、流程状态统计、工作流定义统计。
- 任务状态统计:是指在指定时间范围内,统计 任务实例 中的待运行、失败、运行中、完成、成功的个数
- 流程状态统计:是指在指定时间范围内,统计 工作流实例 中的待运行、失败、运行中、完成、成功的个数
- 流程定义统计:是统计当前用户有权限的项目的 工作流定义 总数
- 注意:工作流定义的工作流每执行一次,就产生一个工作流实例。一个工作流实例包含一到多个任务实例。
4.1.2.2 工作流定义
- 定义工作流
工作流定义可以在画板中创建任务的执行流程,此处以shell任务为例。配置如下:
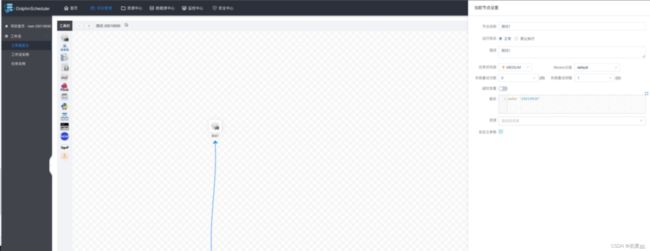
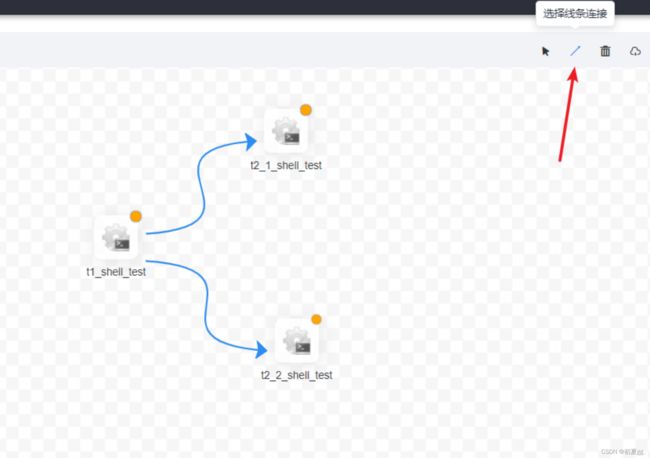
点击连接线添加任务依赖关系:
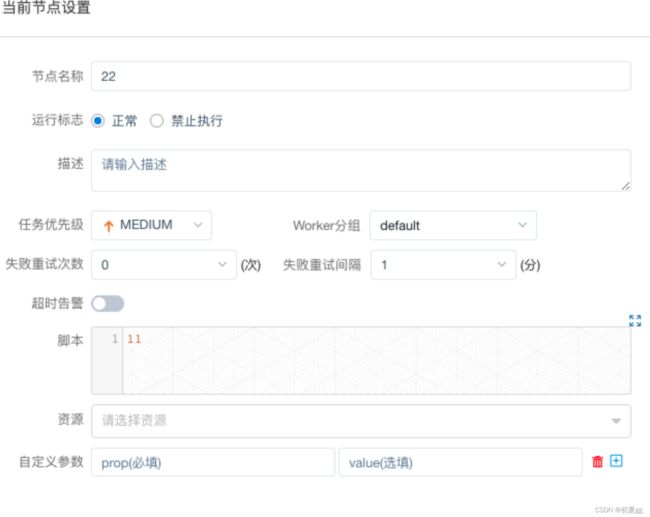
当任务实例定义完成后,点击保存,设置相关参数:

完成以上操作即成功创建一个工作流,可以对工作流进行编辑、上下线、添加定时任务、查看属性图等操作。
步骤中涉及到的一些名词解释:
- 运行标志
正常:运行工作流时正常执行该任务
禁止执行:运行工作流不会执行该任务
- 任务优先级:当 worker 线程数不足时,级别高的任务在执行队列中会优先执行,相同优先级的任务按照先进先出的顺序执行
- 超时告警:
- 超时告警:当任务执行时间超过超时时长,会发送告警邮件,且任务运行不会停止
- 超时失败:当任务执行时间超过超时时长,任务超时失败。若有重试次数,则会重新运行当前任务
- 上述两个选项可同时勾选,则任务超时后,会发送告警邮件且任务超时失败
- 资源:资源文件是
资源中心 ->文件管理页面
创建或上传的文件,如文件名为
test.sh
,脚本中调用资源命令为
sh test.sh(如果脚本是在相应创建目录下,则应带入文件夹名称。)例如:创建test.sh在文件夹test_2021下,调用资源命令为sh test/test.sh

在操作工作流时注意:
- 上线: 工作流状态为 "下线" 时,上线工作流,只有 "上线" 状态的工作流能运行,但不能编辑。
- 下线: 工作流状态为 "上线" 时,下线工作流,下线状态的工作流可以编辑,但不能运行。
- 运行: 只有上线的工作流能运行。
- 定时: 只有上线的工作流能设置定时,系统自动定时调度工作流运行。创建定时后的状态为"下线",需在定时管理页面上线定时才生效。
- 运行工作流
当工作流上线后可以手动运行或定时运行。当工作流开始运行,工作流实例页面回生成一条工作流实例。
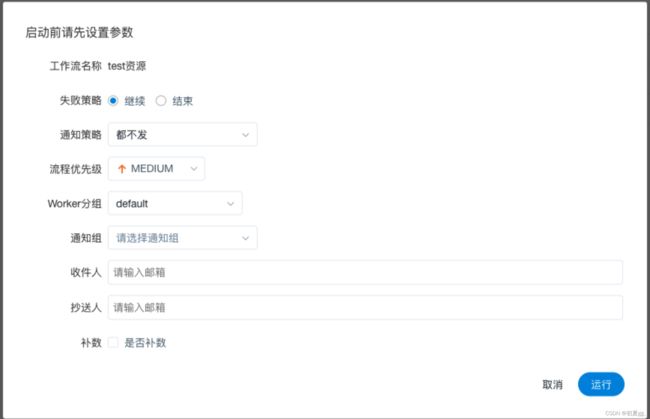
工作流运行参数说明:
- 失败策略 :当某一个任务节点执行失败时,其他并行的任务节点需要执行的策略。
-
- 继续:某一任务失败后,其他任务节点正常执行;
-
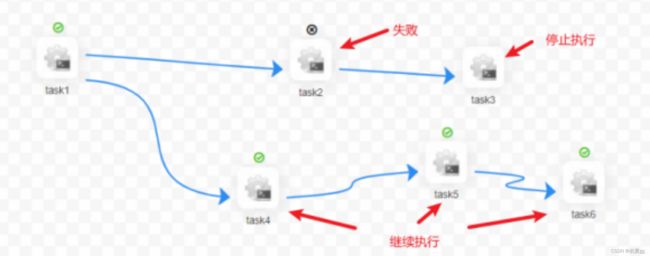
结束:终止所有正在执行的任务,并终止整个流程。
- 通知策略:当流程结束,根据流程状态发送流程执行信息通知邮件,包含任何状态都不发,成功发,失败发,成功或失败都发。
- 流程优先级:流程运行的优先级,分五个等级:最高(HIGHEST),高(HIGH),中(MEDIUM),低(LOW),最低(LOWEST)。
当 master 线程数不足时,级别高的流程在执行队列中会优先执行,相同优先级的流程按照先进先出的顺序执行。
- Worker分组:该流程只能在指定的 worker 机器组里执行。默认是 Default,可以在任一 worker 上执行。如果需要调用具体worker机器上的脚本,需在worker指定具体的worker机器
- 通知组:发送流程信息或邮件到通知组里的所有成员。
- 收件人:发送流程信息或告警邮件到收件人列表。
- 抄送人:抄送流程信息或告警邮件到抄送人列表。
- 补数:执行指定日期的工作流定义,可以选择补数时间范围包括
- 串行补数:指定时间范围内,从开始日期至结束日期依次执行补数,只生成一条流程实例;
- 并行补数:指定时间范围内,多天同时进行补数,生成 N 条流程实例。
注:
补数目前只支持针对连续的天进行补数,比如需要补 11月1号 到 11月10号 的数据:
- 串行模式:补数从 11月1号到11月10号 依次执行,流程实例页面生成一条流程实例;
- 并行模式:同时执行11月1号到11月10号 的任务,流程实例页面生成十条流程实例。
- 定时配置
![]()
工作流完成上线操作后可以设置定时运行。
点击定时按钮,选择起止时间。在起止时间范围内,定时运行工作流;不在起止时间范围内,不再产生定时工作流实例。例如配置自 2020-09-01 到 2020-09-30,每 10分钟 运行一次,设置通知策略为失败发,并添加告警组,此处配置示例如下:

点击 "创建" 按钮,创建定时成功,此时定时状态为 "下线",定时需上线才生效。
点击 "定时管理" 按钮
![]()
点击 "上线" 按钮,工作流定时生效。
![]()
定时上线成功。
![]()
当状态、定时状态都为上线时,代表任务流可以按时调度。
注意:当将工作流下线后,定时任务调度会跟着下线,而再次上线工作流时,里面定时任务调度不会跟着上线,需手动将定时任务调度上线。
- 导入工作流
实际生产中可以将测试环境中完成的工作流进行导出,并在生产环境中导入工作流。工作流导入后默认为下线状态,需要手动上线。
4.1.2.3 工作流实例

工作流实例操作功能:
- 编辑:可以对 已经终止 的流程进行编辑,编辑后保存的时候,可以选择 是否更新到工作流定义
- 重跑:可以对 已经终止 的流程进行重新执行
- 恢复失败:针对失败的流程,可以执行恢复失败操作,从失败的节点开始执行
- 停止:对正在运行的流程进行 停止 操作,后台会先 kill worker 进程,再执行kill -9操作
- 暂停:可以对正在运行的流程进行 暂停 操作,系统状态变为 等待执行,会等待正在执行的任务结束,暂停下一个要执行的任务
- 恢复暂停:可以对暂停的流程恢复,直接从暂停的节点开始运行
- 删除:删除工作流实例及工作流实例下的任务实例
- 甘特图:Gantt 图纵轴是某个工作流实例下的任务实例的拓扑排序,横轴是任务实例的运行时间
4.1.2.4 任务实例
右侧可以查看日志,点击工作流实例名称,可以跳转到工作流实例DAG图查看任务状态。
4.1.3 任务节点类型和参数设置
DolphinScheduler 支持:Shell、SUB_PROCESS、PROCEDURE、SQL、SPARK、FLINK、MR、PYTHON、DEPENDENT、HTTP、DATAX、SQOOP、CONDITIONS 等任务类型。
4.1.3.1 Shell
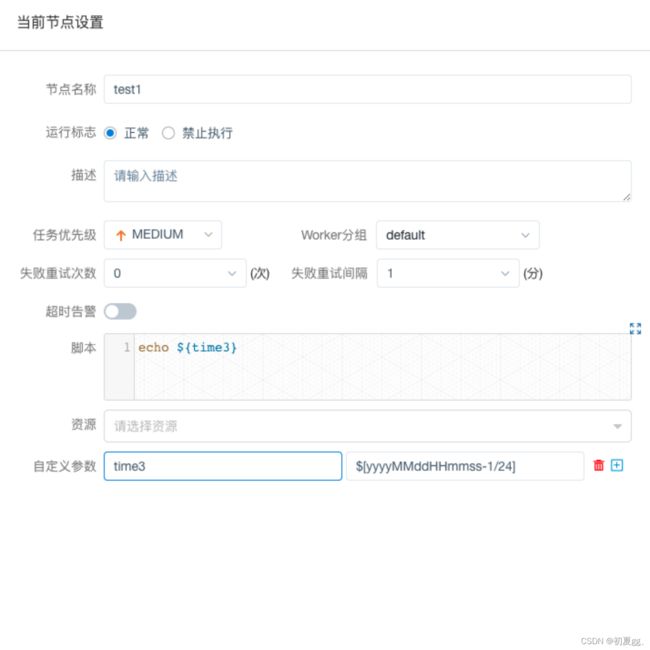
注意:
用shell脚本封装的hql里面必定不能用--来写注释,可能碰到任务一直处于运行状态,一直卡在那里。
在shell节点内需要调用其他内容时,建议创建多个shell节点来进行分别调用,方便出现问题时日志排查。
4.1.3.2 SUB_PROCESS(子流程)
子流程节点,就是把外部的某个工作流定义当做一个任务节点去执行。
创建工作流,在工作流中创建SUB_PROCESS任务:

右上角进入子流程需该任务已经执行一次后才可以进入相应的子流程内,否则显示为空白内容。
在使用中,当B工做流依赖于A这个子工做流时,咱们执行B工做流便可,它会先执行A工做流,只有A工做流执行成功,才会继续执行B工做流.注意:不要先把A工做流本身执行一遍,而后再去执行B工做流,这样的话A工做流会被执行2次,会致使错误的结果.
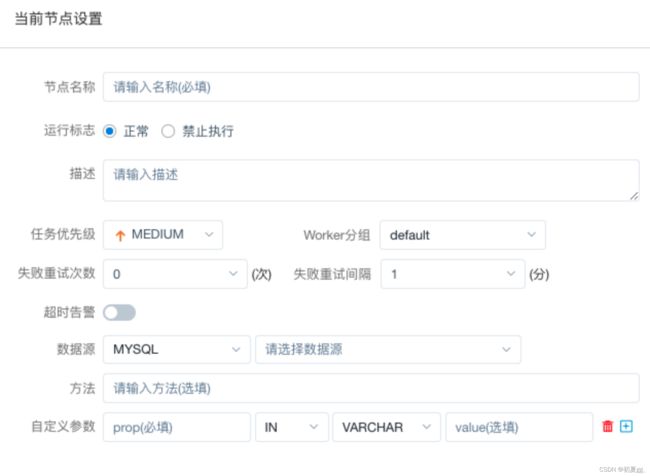
4.1.3.3 PROCEDURE(存储过程)
存储过程节点根据选择的数据源,执行存储过程。
主要参数说明:
- 数据源:存储过程的数据源类型支持MySQL、postgresql、clickhouse、oracle、SQLserver。选择对应的数据源即可。
- 方法:存储过程的方法名称
- 自定义参数:存储过程的自定义参数类型支持IN、OUT两种,数据类型支持 VARCHAR、INTEGER、LONG、FLOAT、DOUBLE、DATE、TIME、TIMESTAMP、BOOLEAN 九种数据类型
4.1.3.4 SQL
主要参数说明:
- sql 类型:支持查询和非查询两种
- 查询:是 select 类型的查询,是有结果集返回的,可以指定邮件通知为 表格、附件 或 表格附件 三种模板。
- 非查询是没有结果集返回的,是针对 update、delete、insert 三种类型的操作
- UDF 函数:对于 HIVE 类型的数据源,可以引用资源中心中创建的 UDF 函数,其他类型的数据源暂不支持 UDF 函数。
- 自定义参数:
- SQL 任务类型 和 存储过程是 自定义参数顺序的给方法设置值。
- 自定义参数类型和数据类型同存储过程任务类型相同。
- 区别在于 SQL 任务类型自定义参数会替换 sql 语句中 ${变量}
- 前置 sql:在 sql 语句之前执行
- 后置 sql:在 sql 语句之后执行

4.1.3.5 SPARK
通过 SPARK 节点,可以直接直接执行 SPARK 程序,对于 spark 节点,worker 会使用 spark-submit 方式提交任务。
主要参数说明:
- 程序类型:支持 JAVA、Scala 和 Python 三种语言
- JAVA 和 Scala 只是用来标识,没有区别,如果是 Python 开发的 Spark 则没有主函数的 class,其他都是一样
- 主函数的 class:是 Spark 程序的入口 Main Class 的全路径
- 主 jar 包:是 Spark 的 jar 包
- 部署方式:支持 yarn-cluster、yarn-client 和 local 三种模式
- Driver 内核数:可以设置 Driver 内核数及内存数
- Executor 数量:可以设置 Executor 数量、Executor 内存数和 Executor 内核数
- 命令行参数:是设置 Spark 程序的输入参数,支持自定义参数变量的替换。
- 其他参数:支持 --jars、--files、--archives、--conf 格式
- 资源:如果其他参数中引用了资源文件,需要在资源中选择指定
- 自定义参数:是 MR 局部的用户自定义参数,会替换脚本中以 ${变量} 的内容

4.1.3.6 FLINK
flink只作为参数说明,具体使用后续同步。
主要参数说明:
- 部署方式:支持 cluster、local 模式
- slot 数量:可以设置 slot 数
- taskManage 数量:可以设置 taskManage 数
- jobManager 内存数:可以设置 jobManager 内存数
- taskManager 内存数:可以设置 taskManager 内存数
- 命令行参数:是设置 Spark 程序的输入参数,支持自定义参数变量的替换。
- 其他参数:支持 --jars、--files、--archives、--conf格式
- 资源:如果其他参数中引用了资源文件,需要在资源中选择指定
- 自定义参数:是 Flink 局部的用户自定义参数,会替换脚本中以 ${变量} 的内容
若使用的时 Flink local 模式,可以正常运行;若使用前文中源码编译方式部署,且注释了相关参数,则不支持 Flink local 模式,仅能使用 Flink cluster 的模式进行提交。
4.1.3.7 MAPREDUCE
主要参数说明:
- 命令行参数:是设置 MR 程序的输入参数,支持自定义参数变量的替换
- 其他参数:支持 –D、-files、-libjars、-archives 格式
4.1.3.8 Python
与shell同理。
4.1.3.9 DEPENDENT(依赖节点)
依赖节点,就是依赖检查节点,,提供了逻辑判断功能。比如 A 流程依赖昨天的 B 流程执行成功,依赖节点会去检查 B 流程在昨天是否有执行成功的实例。
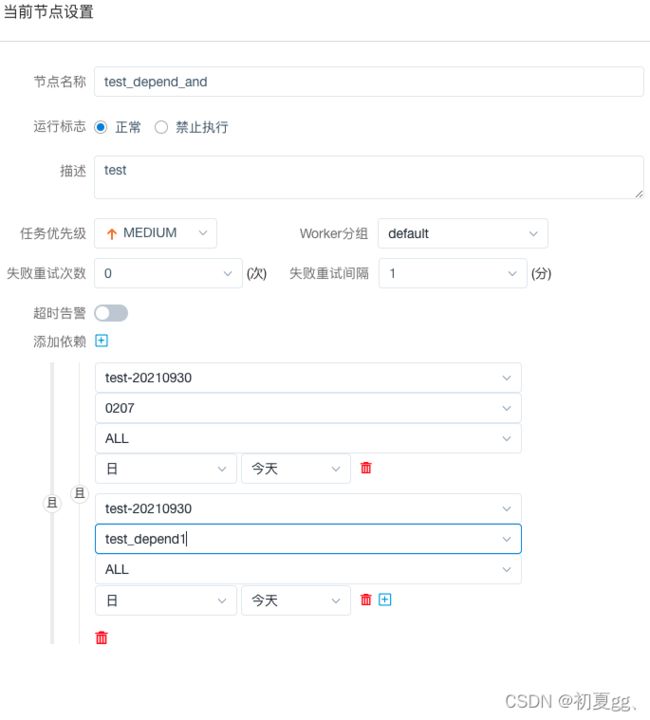
4.1.3.10 HTTP
主要参数说明:
- 请求地址:http 请求 URL。
- 请求类型:支持 GET、POSt、HEAD、PUT、DELETE。
- 请求参数:支持 Parameter、Body、Headers。
- 校验条件:支持默认响应码、自定义响应码、内容包含、内容不包含。
- 校验内容:当校验条件选择自定义响应码、内容包含、内容不包含时,需填写校验内容。
- 自定义参数:是 http 局部的用户自定义参数,会替换脚本中以 ${变量} 的内容。
4.1.3.11 DATAX
4.1.3.12SQOOP
Sqoop 是 Hadoop 和关系数据库服务器之间传送数据的一种工具。它是用来从关系数据库如:MySQL,Oracle 到Hadoop 的 HDFS,并从 Hadoop 的文件系统导出数据到关系数据库。
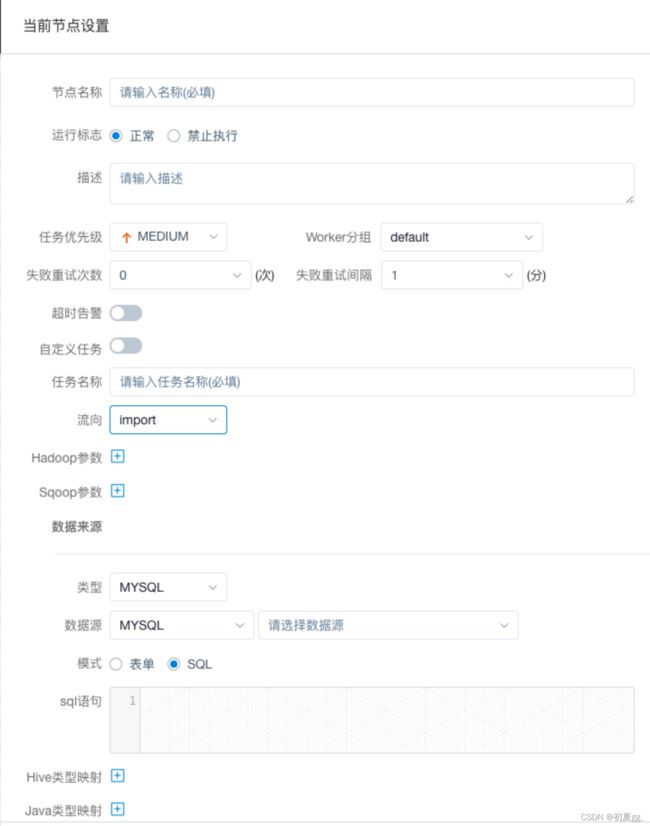
4.1.3.13 CONDITIONS
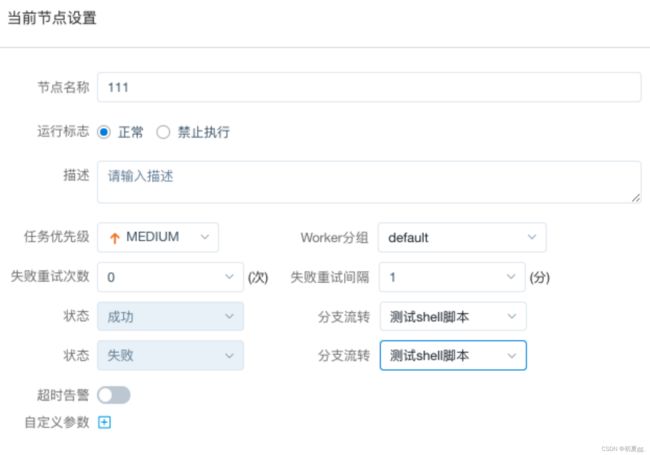
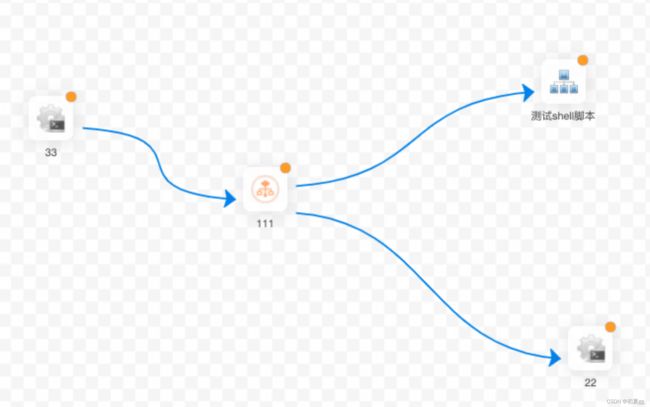
CONDITIONS 用于判断上个作业执行结果,根据成功或失败继续后面不同的流程。
注意:使用此节点应先将此节点 保存添加后,即可选择分支流转内容,否则无法选择分支流转内容。
4.2 资源中心
4.2.1文件管理
是对各种资源文件的管理,包括创建文件夹、创建文件、上传文件等操作。
文件格式支持以下几种类型:txt、log、sh、conf、cfg、py、java、sql、xml、hql、properties
文件可在线编辑、重命名、下载、删除。
4.2.2 UDF管理
1)资源管理
资源管理和文件管理功能类似,不同之处是专门上传UDF函数
2)函数管理
可以创建临时UDF函数。
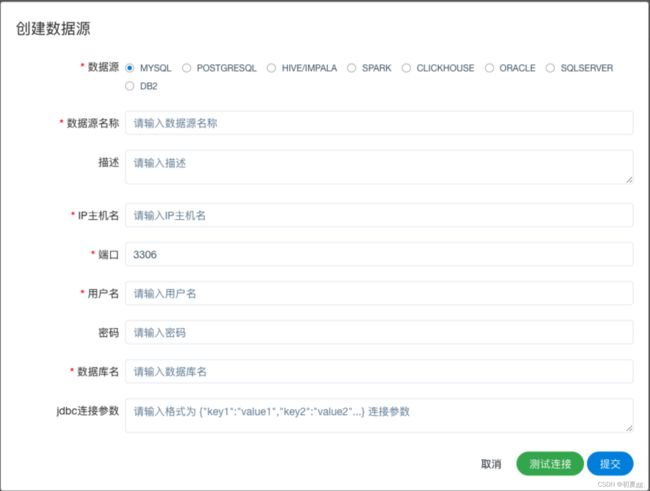
4.3 数据源中心
数据源中心支持 MySQL、POSTGRESQL、HIVE/IMPALA、SPARK、CLICKHOUSE、ORACLE、SQLSERVER 等数据源。
4.4 监控中心
包含以下功能:
服务管理
- master 监控
- worker 监控
- Zookeeper 监控
- DB 监控
4.5 安全中心
4.5.1 租户管理
租户:对应的linux系统的用户,用于worker提交作业锁使用的用户。如果Linux没有这个用户,worker会在执行脚本时自动创建用户(在部署时使用的高权限linux用户)。
租户编码:与租户填写一致。
新建租户会在HDFS上/user目录下创建租户目录,租户目录下为改租户上传的文件和UDF函数。文件夹名称为home、resources、udfs。
租户名称:租户编码的别名。
4.5.2 用户管理
安全中心—>用户管理—>创建用户
用户分为管理员用户和普通用户。在创建用户时根据需要,给予用户相应租户权限。
通过管理员用户,对相应普通用户授予权限,包括:项目权限、资源权限、数据源权限、udf函数权限。
实际使用中,若需要删除用户,需将该用户所建立项目内的任务删除----》删除项目------》删除用户,否则会出现任务无法运行,项目不可见等情况。
4.5.3 告警组管理
安全中心—>告警组管理—>创建告警组 (目前仅支持邮件告警)
告警组根据需要进行创建,创建后可以添加项目组内成员及部门邮箱。
4.5.4 Worker分组管理
安全中心—>worker管理—>创建worker分组
4.5.5 队列管理
安全中心—>队列管理—>创建队列
队列是在执行spark、MR任务等程序,需要指定“队列”参数时使用
4.5.6 令牌管理
安全中心—>令牌管理—>创建令牌
可以对相关用户创建token,便于后端调用平台相关任务。
五、参数设置
5.1系统参数
(2.0.2版本已经优化补数时存在的问题)
${system.biz.date}
日常调度实例定时的定时时间前一天,格式为 yyyyMMdd,补数据时,该日期 +1
${system.biz.curdate}
日常调度实例定时的定时时间,格式为 yyyyMMdd,补数据时,该日期 +1
${system.datetime}
日常调度实例定时的定时时间,格式为 yyyyMMddHHmmss,补数据时,该日期 +1
5.2 时间自定义参数
例:当前时间为20211207111418
| 序号 |
表达式 |
结果 |
| 1 |
后 N 年:$[add_months(yyyyMMdd,12*N)] |
echo "后 1 年:" 20221207 |
| 2 |
前 N 年:$[add_months(yyyyMMdd,-12*N)] |
echo "前 1 年:" 20201207 |
| 3 |
后 N 月:$[add_months(yyyyMMdd,N)] |
echo "后 1 月:" 20220107 |
| 4 |
前 N 月:$[add_months(yyyyMMdd,-N)] |
echo "前 1 月:" 20211107 |
| 5 |
后 N 周:$[yyyyMMdd+7*N] |
echo "后 1 周:" 20211214 |
| 6 |
前 N 周:$[yyyyMMdd-7*N] |
echo "前 1 周:" 20211130 |
| 7 |
后 N 天:$[yyyyMMdd+N] |
echo "后 1 天:" 20211208 |
| 8 |
前 N 天:$[yyyyMMdd-N] |
echo "前 1 天:" 20211206 |
| 9 |
后 N 小时:$[HHmmss+N/24] |
echo "后 1 小时:" 121418 |
| 10 |
前 N 小时:$[HHmmss-N/24] |
echo "前 1 小时:" 101418 |
| 11 |
后 N 分钟:$[HHmmss+N/24/60] |
echo "后 1 分钟:" 111518 |
| 12 |
前 N 分钟:$[HHmmss-N/24/60] |
echo "前 1 分钟:" 111318 |
| 13 |
前一小时:$[yyyyMMddHHmmss-1/24] |
echo”前 1 小时:“20211207101418 |
5.3 用户自定义参数
用户自定义参数分为 全局参数 和 局部参数。
- 全局参数:保存 工作流定义 时传递的参数,全局参数可以在整个流程中的任何一个任务节点的 局部参数 中引用。

- 局部参数:保存 工作流实例 时传递的参数
六、平台升级
6.1 升级流程
1、下载新版本源码包(2.0.3)
- 参照生产环境部署内容进行修改源码内信息,使根pom文件内版本信息与集群环境版本相匹配。
- 对源码进行编译打包、上传至相关服务器
2、修改新版本配置文件内容 conf/config/install_config.conf
注意点:所有修改的配置信息应在引号内进行填写,多余的引用字符需去除。
相关配置信息可以参照老版本的install_config.conf进行修改配置
配置安装目录建议新建目录
3、需将新版本文件夹在每个服务器进行上传,需注意创建的目录用户权限问题,注意安装目录下data目录的创建及权限
4、将mysql的jar包上传至新版本目录、lib下,并设置权限
5、将hadoop配置文件上传至、conf文件夹下 包括:core-site.xml 和hdfs-site.xml
6、conf/env下的环境变量可以在配置文件中设置,也可以后期通过平台进行设置
7、在升级平台后,会短暂出现数据访问不到的问题,大约过十分钟左右数据加载上即可展示。
6.2 升级内容
1、相关配置信息进行可配置化管理,例如环境变量、告警组等信息
2、工作流新增版本信息,可记录工作流中个版本内容,方便进行工作流的版本控制工作。注意:针对于已上线工作流,如需切换版本,需将任务流进行下线操作,
3、优化页面内容,使任务流绘制更易操作,减去上一版本的重复操作内容。
6.3 新版本问题
有部分内容显示存在异常问题,需对源码进行调整。
七、常见问题
7.1 jar包问题
在sqoop目录lib下,添加MySQL的jdbc连接jar包即可(版本至少为5.1.35,同时确认jar包权限)。
7.2 权限问题
确认执行脚本的平台租户是否具有权限访问hive相关数据表。在平台创建租户时注意租户应与服务器用户对应。
由于平台并没有过多设计权限管理的工作,如需详细的权限管理需进行二次开发。
排查日志
查看worker 日志
tail -f /opt/soft/dolphinscheduler/logs/dolphinscheduler-worker.log
查看master日志
tail -f /opt/soft/dolphinscheduler/logs/dolphinscheduler-master.log
查看api 日志
tail -f /opt/soft/dolphinscheduler/logs/dolphinscheduler-api-server.log
查看告警alert日志
tail -f /opt/soft/dolphinscheduler/logs/dolphinscheduler-alert.log
查看日志服务logger日志
tail -f dolphinscheduler-worker-server-rh-hadoop02-n011-011.out
tail -f dolphinscheduler-worker-server-rh-hadoop02-n013-013.out
附录:平台元数据表信息
平台元数据MySQL说明
| 表名 |
表信息 |
| t_ds_access_token |
访问 ds 后端的 token |
| t_ds_alert |
告警信息 |
| t_ds_alertgroup |
告警组 |
| t_ds_command |
执行命令 |
| t_ds_datasource |
数据源 |
| t_ds_error_command |
错误命令 |
| t_ds_process_definition |
流程定义 |
| t_ds_process_instance |
流程实例 |
| t_ds_project |
项目 |
| t_ds_queue |
队列 |
| t_ds_relation_datasource_user |
用户关联数据源 |
| t_ds_relation_process_instance |
子流程 |
| t_ds_relation_project_user |
用户关联项目 |
| t_ds_relation_resources_user |
用户关联资源 |
| t_ds_relation_udfs_user |
用户关联 UDF 函数 |
| t_ds_relation_user_alertgroup |
用户关联告警组 |
| t_ds_resources |
资源文件 |
| t_ds_schedules |
流程定时调度 |
| t_ds_session |
用户登录的 session |
| t_ds_task_instance |
任务实例 |
| t_ds_tenant |
租户 |
| t_ds_udfs |
UDF 资源 |
| t_ds_user |
用户 |
| t_ds_version |
ds 版本信息 |
相关表内字段信息参照官网链接:
https://dolphinscheduler.apache.org/zh-cn/docs/1.3.2/user_doc/metadata-1.3.html