ChatGPT研究(二)——ChatGPT助力跨模态AI生成应用
✏️写作:个人博客,InfoQ,掘金,知乎,CSDN
公众号:进击的Matrix
特别声明:创作不易,未经授权不得转载或抄袭,如需转载可联系小编授权。
前言
最近ChatGPT,想必大家已经是耳熟能详了,一度认为ChatGPT的到来是人工智能的奇点到来,那么到底ChatGPT是什么?为什么ChatGPT为代表的人工智能技术不仅受到平民用户的喜爱,还受到资本市场追捧呢?
上篇文章《ChatGPT研究(一)——AI平民化的里程碑》中初步讲解了ChatGPT的发展里程碑和各大科技公司的AI投入,本篇文章将会更多的从技术角度,解读ChatGPT的AI发展和应用。本公众号计划出三期,多维度研究分析ChatGPT,敬请期待。
基于人类反馈系统,ChatGPT助力跨模态AI生成应用
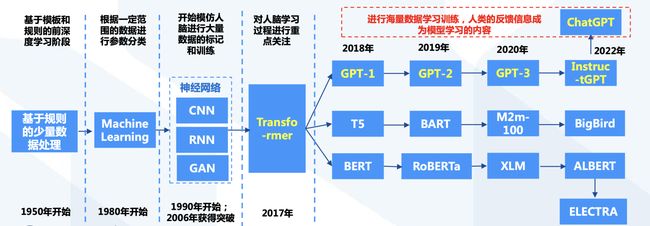
ChatGPT经历多类技术路线演化,逐步成熟与完善
- ChatGPT所能实现的人类意图,来自于机器学习,神经网络以及Transformer模型的多种技术模型积累
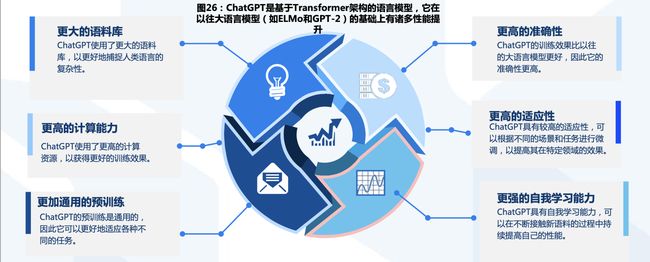
ChatGPT模型在以往的基础上有了多方面的显著提升
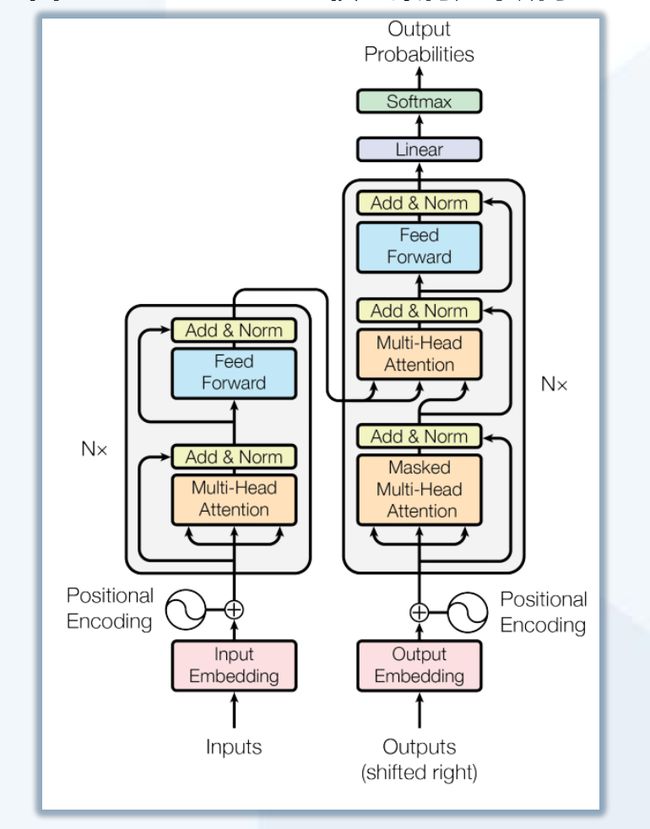
Transformer的应用标志着基础模型时代的开始
- 转移学习(Transfer Learning)使基础模型成为可能
✔️ 技术层面上,基础模型通过转移学习(Transfer Learning)(Thrun 1998)和规模(scale)得以实现。转移学习的思想是将从一项任务中学习到的“知识”(例如,图像中的对象识别)应用于另一
项任务(例如:视频中的活动识别)。
✔️ 在深度学习中,预训练又是转移学习的主要方法:在替代任务上训练模型(通常只是达到目的的一种手段),然后通过微调来适应感兴趣的下游任务,转移学习(Transfer Learning)使基础模
型成为可能。
- 大规模化(scale)使基础模型更强大,因而GPT模型得以形成
✔️ 大规模需要三个要素:
- 计算机硬件的改进——例如,CPU吞吐量和内存在过去四年中增加了10倍;
- Transformer模型架构的开发(Vaswani et al.2017),该架构利用硬件的并行性来训练比以前更具表现力的模型;
- 更多训练数据的可用性
✔️ 基于Transformer的序列建模方法现在应用于文本、图像、语音、表格数据、蛋白质序列、有机分子和强化学习等,这些例子的逐步形成使得使用一套统一的工具来开发各种模态的基础模
**型这种理念得以成熟。**例如,GPT-3( Brown et al. 2020 )与GPT-2的15亿参数相比, GPT-3具有1750亿个参数,允许上下文学习,在上下文学习中,只需向下游任务提供提示(任务的自然
语言描述),语言模型就可以适应下 游任务,这是产生的一种新兴属性。
Trasnsformer奠定了生成式AI领域的游戏规则
- Transformer摆脱了人工标注数据集的缺陷,模型在质量上更优、 更易于并行化,所需训练时间明显更少
- Transformer通过成功地将其应用于具有大量和有限训练数据的分析,可以很好的推广到其他任务。
✔️ 2017年在Ashish Vaswani et.al 的论文《Attention Is All You Need》 中,考虑到主导序列转导模型基于编码器-解码器配置中的复杂递归或卷积 神经网络,性能最好的模型被证明还是
通过注意力机制(attention mechanism)连接编码器和解码器,因而《Attention Is All You Need》 中提出了一种新的简单架构——Transformer,它完全基于注意力机制, 完全不用重复和
卷积,因而这些模型在质量上更优,同时更易于并行化,并且需要的训练时间明显更少。
✔️ Transformer出现以后,迅速取代了RNN系列变种,跻身主流模型架构基础。(RNN缺陷正在于流水线式的顺序计算)
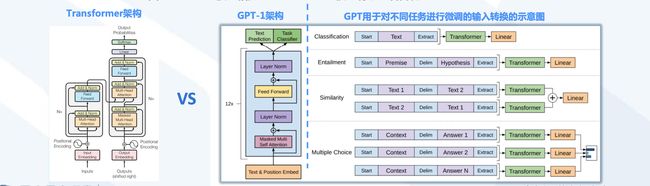
GPT-1:借助预训练,进行无监督训练和有监督微调
- GPT-1模型基于Transformer解除了顺序关联和依赖性的前提,采用生成式模型方式,重点考虑了从原始文本中有效学习的能力,这对于减轻自然语言处理(NLP)中对监督学习的依赖至关重要
✔️ GPT(Generative Pre-training Transformer)于2018年6月由OpenAI首次提出。GPT模型考虑到在自然语言理解中有大量不同的任务,尽管大量的未标记文本语料库非常丰富,但用于学
习这些特定任务的标记数据却很少,这使得经过区分训练的模型很难充分执行。同时,大多数深度学习方法需要大量手动标记的数据,这限制了它们在许多缺少注释资源的领域的适用性。
✔️ 在考虑以上局限性的前提下,GPT论文中证明,通过对未标记文本的不同语料库进行语言模型的生成性预训练,然后对每个特定任务 进行区分性微调,可以实现这些任务上的巨大收益。
和之前方法不同,GPT在微调期间使用任务感知输入转换,以实现有效的传输,同时对模型架构的更改最小。

GPT-1:模型更简化、计算加速,更适合自然语言生成任务(NLG)
- GPT相比于Transformer等模型进行了显著简化
✔️ 相比于Transformer,GPT训练了一个12层仅decoder的编解码器(原Transformer模型中包含Encoder和Decoder两部分)
✔️ 相比于Google的BERT(Bidirectional Encoder Representations from Transformers,双向编码生成Transformer),GPT仅采用上文预测单词(BERT采用了基于上下文双向的预
测手段)
注:ChatGPT的表现更贴近人类意图,部分因为一开始GPT是基于上文的预测,这更贴近人类的话语模式,因为人类语言无法基于将来的话来做分析。
GPT-2:采用多任务系统,基于CPT-1进行优化
- GPT-2在GPT-1的基础上进行诸多改进,实现执行任务多样性,开始学习在不需要明确监督的情况下执行数量惊人的任务
✔️ 在GPT-2阶段,OpenAI去掉了GPT-1阶段的有监督微调(fine-tuning),成为无监督模型。
✔️ 大模型GPT-2是1.5B参数的Transformer,在其相关论文中它在8个测试语言建模数据集中的7个数据集上实现了当时最先进的结果。 模型中,Transfomer堆叠至48层。GPT-2的数据集
增加到8 million的网页、大小40GB的文本。
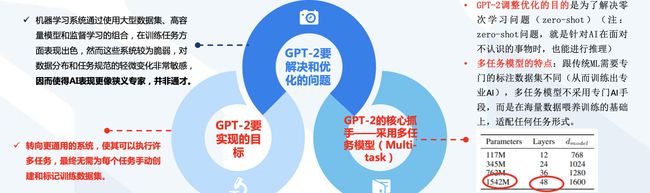
GPT-2仍未解决应用中的诸多瓶颈
- GPT-2聚焦在无监督、zero-shot(零次学习)上,然而GPT-2训练结果也有不达预期之处,所存在的问题也亟待优化。
✔️ 在GPT-2阶段,尽管体系结构是任务无关的,但仍然需要任务特定的数据集和任务特定的微调:要在所需任务上实现强大的性能,通常需要对特定于该任务的数千到数十万个示例的数据集
进行微调。
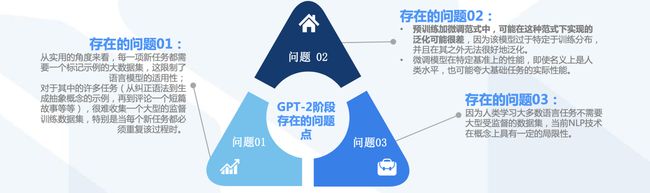
GPT-3取得突破性进展,任务结果难以与人类作品区分开来
- GPT-3对GPT-2追求无监督与零次学习的特征进行了改进
- GPT-3利用了过滤前45TB的压缩文本,在诸多NLP数据集中实现了强大性能
✔️ GPT-3是一个具有1750亿个参数的自回归语言模型,比之前的任何非稀疏语言模型多10倍。对于所有任务(在few-shot设置下测试其性能),GPT-3都是在没有任何梯度更新或微调的情况
下应用的,仅通过与模型的文本交互来指定任务和few-shot演示。
✔️ GPT-3在许多NLP数据集上都有很强的性能(包括翻译、问题解答和完形填空任务),以及一些需要动态推理或领域适应的任务(如解译单词、在句子中使用一个新单词或执行三位数算术)。
GPT-3可以生成新闻文章样本(已很难将其与人类撰写的文章区分开来)。
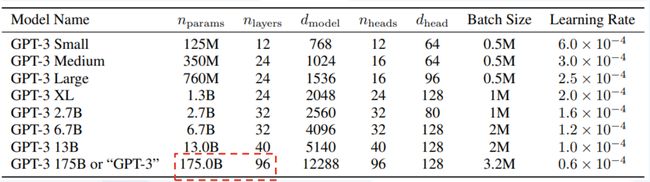
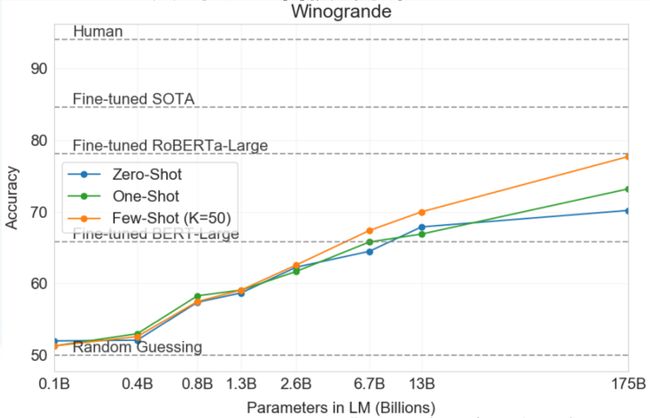
InstructGPT模型在GPT-3基础上进一步强化
- InstructGPT使用来自人类反馈的强化学习方案RLHF(reinforcement learning from human feedback), 通过对大语言模型进行微调,从而能够在参数减少的情况下,实现优于GPT-3的功能。
✔️ InstructGPT提出的背景:使语言模型更大并不意味着它们能够更好地遵循用户的意图,例如大型语言模型可以生成不真实、有毒或对 用户毫无帮助的输出,即这些模型与其用户不一致。另外,GPT-3虽然选择了少样本学习(few-shot)和继续坚持了GPT-2的无监督学习,但基于few-shot的效果,其稍逊于监督微调(fine-tuning)的方式
✔️ 基于以上背景,OpenAI在GPT-3基础上根据人类反馈的强化学习方案RHLF,训练出奖励模型(reward model)去训练学习模型(即:用AI训练AI的思路)
✔️ InstructGPT的训练步骤为:**对GPT-3监督微调——训练奖励模型(rewardmodel)——增强学习优化SFT(第二、第三步可以迭代循环多次) **
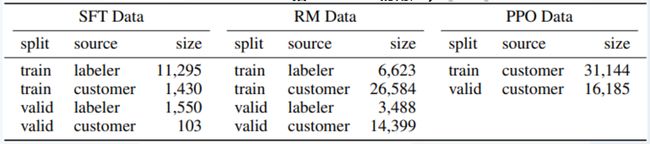
ChatGPT核心技术优势:提升了理解人类思维的准确性
- InstructGPT与ChatGPT属于相同代际的模型,ChatGPT只是在InstructGPT的基础上增加了Chat属性,且开放了公众测试
- ChatGPT提升了理解人类思维的准确性的原因在于利用了基于人类反馈数据的系统进行了模型训练
注:根据 官网介绍,ChatGPT也是基于InstructGPT构建,因而可以从InstructGPT来理解CharGPT利用人类意图来增强模型效果
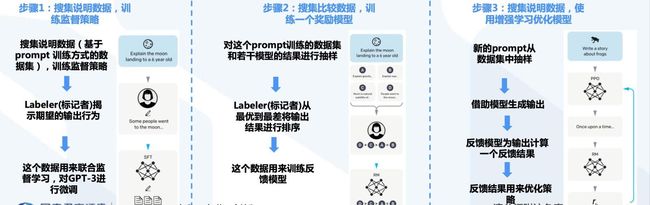
ChatGPT得益于通用(基础)模型所构建AI系统的新范式
- 基础模型(Foundation Model)在广泛的应用中整合构建机器学习系统的方法,它为许多任务提供了强大的杠杆作用
✔️ 基础模型是在深度神经网络和自我监督学习的基础上演化而来。基础模型基于广泛数据(通常使用大规模自我监督) 训练的任何模型,可以适应(例如微调)广泛的下游任务,目前例子包扩
BERT( Devlin et al.)、GPT-3(Brown et al. 2020)和CLIP(Radford et al. 2021) 。
✔️ 机器学习使用学习算法同质化(例如,逻辑回归),深度学习使模型架构同质化(如卷积神经网络),而基础模型使模型本身同质化(比如,GPT-3)
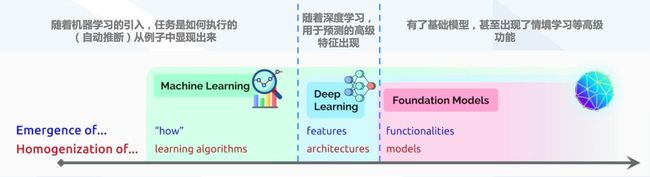
ChatGPT以基础模型为杠杆,可适用多类下游任务
- ChatGPT采用了GPT3.5(InstructGPT)大规模预训练模型,在自然语言理解和作品生成上取得极大性能提升
✔️ 鉴于传统NLP技术的局限问题,基于大语言模型(LLM)有助于充分利 用海量无标注文本预训练,从而文本大模型在较小的数据集和零数据集 场景下可以有较好的理解和生成能力。基于大模型
的无标准文本书收集,ChatGPT得以在情感分析、信息钻取、理解阅读等文本场景中优势突出。
✔️ 随着训练模型数据量的增加,数据种类逐步丰富,模型规模以及参数量 的增加,会进一步促进模型语义理解能力以及抽象学习能力的极大提升, 实现ChatGPT的数据飞轮效应(用更多数据可
以训练出更好的模型, 吸引更多用户,从而产生更多用户数据用于训练,形成良性循环)。
✔️ 研究发现,每增加参数都带来了文本合成和/或下游NLP任务的改进, 有证据表明,日志丢失与许多下游任务密切相关,随着规模的增长,日志丢失呈现平稳的改善趋势。
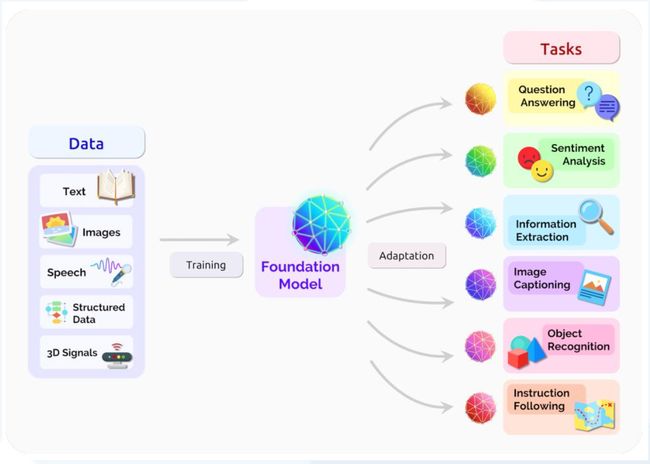
ChatGPT大模型架构也是ML发展到第三阶段的必然产物
- ML中的计算历史分为三个时代:前深度学习时代、深度学习时代和大规模时代,在大规模时代,训练高级ML系统的需求快速增长
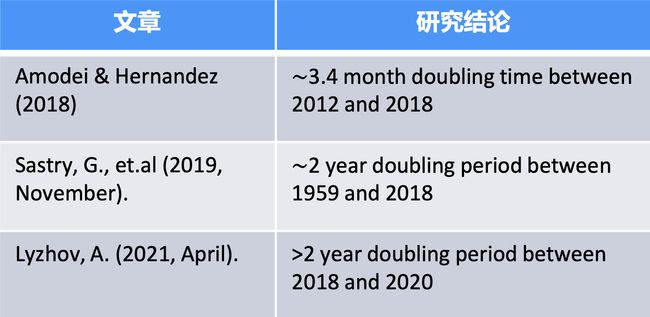
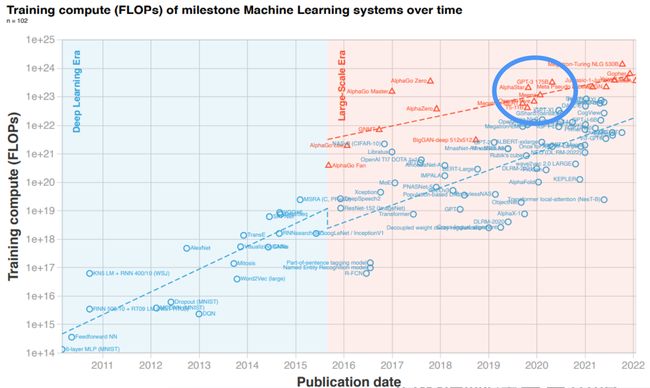
✔️ 计算、数据和算法的进步是指导现代机器学习(ML)进步的三个基本因素。在2010年之前,训练计算的增长符合摩尔定律,大约每20个 月翻一番。自2010年代早期深度学习(Deep Learning)问
世以来,训练计算的规模已经加快,大约每6个月翻一番。2015年末,随着公 司开发大规模ML模型,训练计算需求增加10至100倍,出现了一种新趋势——训练高级ML系统的需求快速增长。
✔️ 2015-2016年左右,出现了大规模模型的新趋势。这一新趋势始于2015年末的AlphaGo,并持续至今( GPT-3于2020年出现)
本文正在参加 ✍ 技术视角深入 ChatGPT 征文活动
最后欢迎大家点赞、收藏、评论,转发!