spark_hive_hbase
Spark_Hive
1.需要的依赖
<properties>
<scala.version>2.11.8scala.version>
<hadoop.version>2.7.4hadoop.version>
<spark.version>2.0.2spark.version>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>${hadoop.version}version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.32version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
<version>2.0.2version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_2.11artifactId>
<version>2.0.2version>
dependency>
dependencies>
<build>
<sourceDirectory>src/main/scalasourceDirectory>
<testSourceDirectory>src/test/scalatestSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.0version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
<configuration>
<args>
<arg>-dependencyfilearg>
<arg>${project.build.directory}/.scala_dependenciesarg>
args>
configuration>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<configuration>
<source>1.8source>
<target>1.8target>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>2.3version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<filters>
<filter>
<artifact>*:*artifact>
<excludes>
<exclude>META-INF/*.SFexclude>
<exclude>META-INF/*.DSAexclude>
<exclude>META-INF/*.RSAexclude>
excludes>
filter>
filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.bridge.spark_hive.Spark2HivemainClass>
transformer>
transformers>
configuration>
execution>
executions>
plugin>
plugins>
build>
2.对Hive仓库中数据的读取:
package com.bridge.spark_hive
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.{SparkConf, SparkContext}
object Spark2Hive {
def main(args: Array[String]): Unit = {
//表名
val table_name= "test_data.test_lateral_view"
//val table_name= args(0)
//列名
val lie = "id"
//val lie = args(1)
//val time = new DataFrame()
val spark: SparkSession = SparkSession.builder().appName("Spark2Hive").master("local[2]").config(new SparkConf()).enableHiveSupport().getOrCreate()
//将读取到的表注册成为一张临时表
spark.table(table_name).createOrReplaceTempView("person")
//查询数据
val sql = "select p."+ lie +" from person p "
//展示数据
spark.sql(sql).show()
//关闭资源
spark.stop()
}
}
3.遇到的问题
3.1 打包的问题
IDEA自带的打包工具打出来的jar包直接放在集群上跑的话会出现找不到类的一个错误
正确打包方式:
第一步: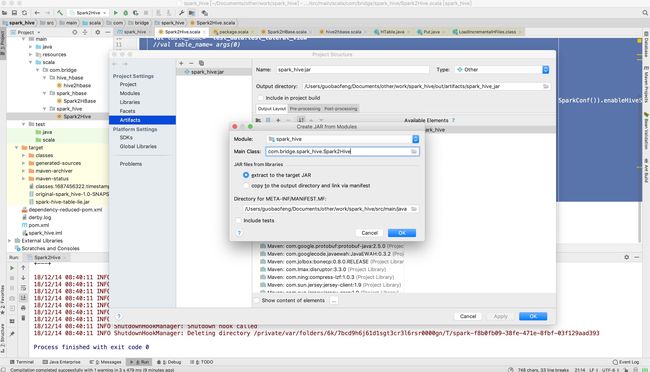
第二步:选择好模板之后,用maven自带的packege
Spark_Hbase
1.需要的依赖
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-serverartifactId>
<version>1.2.6version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-clientartifactId>
<version>1.2.6version>
dependency>
2.读取HBase中的数据
package com.bridge.spark_hbase
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.hadoop.hbase.client._
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SQLContext, SparkSession}
object Spark2HBase {
def main(args: Array[String]): Unit = {
// 本地模式运行,便于测试
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("HBaseTest")
// 创建hbase configuration
val hBaseConf = HBaseConfiguration.create()
hBaseConf.set("hbase.zookeeper.property.clientPort", "2181");
hBaseConf.set("hbase.zookeeper.quorum", "192.168.116.121");
hBaseConf.set(TableInputFormat.INPUT_TABLE,"tb_user")
// 创建 spark context
val sc = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
val sqlContext = new SQLContext(sc)
import sqlContext.implicits._
// 从数据源获取数据
val hbaseRDD = sc.newAPIHadoopRDD(hBaseConf,classOf[TableInputFormat],classOf[ImmutableBytesWritable],classOf[Result])
// 将数据映射为表 也就是将 RDD转化为 dataframe schema
val shop = hbaseRDD.map(r=>(
Bytes.toString(r._2.getValue(Bytes.toBytes("login_info"),Bytes.toBytes("password"))),
Bytes.toString(r._2.getValue(Bytes.toBytes("login_info"),Bytes.toBytes("username"))),
Bytes.toString(r._2.getValue(Bytes.toBytes("user_info"),Bytes.toBytes("address"))),
Bytes.toString(r._2.getValue(Bytes.toBytes("user_info"),Bytes.toBytes("name")))
)).toDF("password","username","address","name")
shop.registerTempTable("user")
// 测试
val df2 = sqlContext.sql("SELECT * FROM user")
println(df2.count())
df2.collect().foreach(print(_))
//关闭资源
sc.stop()
}
}
3.打包同上
Hive_Hbase
1.需要的依赖
(前边两个的结合)
2.读取hive中的数据并写到hbase中
package com.bridge.hive_hbase
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.{HBaseConfiguration, HColumnDescriptor, HTableDescriptor, TableName}
import org.apache.hadoop.hbase.client._
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{DataFrame, SparkSession}
object hive2hbase extends Serializable {
//创建HBase表
def createTable(hconf: Configuration, tableName: String) = {
val connection: Connection = ConnectionFactory.createConnection(hconf)
val hbTable: TableName = TableName.valueOf(tableName)
val admin: Admin = connection.getAdmin
if (!admin.tableExists(hbTable)) {
val tableDesc = new HTableDescriptor(hbTable)
tableDesc.addFamily(new HColumnDescriptor("info".getBytes))
admin.createTable(tableDesc)
}
connection.close()
}
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("hive2hbase").setMaster("local[2]")
//conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val spark: SparkSession = SparkSession.builder().config(conf).enableHiveSupport().getOrCreate()
spark.table("test_data.test_lateral_view").createOrReplaceTempView("user")
val df: DataFrame = spark.sql("select * from user")
// val schema: StructType = df.schema
//
// println(schema)
df.rdd.map(row=>{
// val c1: Int = row(0).asInstanceOf[Int]
val c2: String = row(1).asInstanceOf[String] //zhi
// println(row)
// println(c1)
// println(c2)
val p = new Put(Bytes.toBytes("row4"))
p.addColumn(Bytes.toBytes("info"),Bytes.toBytes("address"),Bytes.toBytes(c2))
val hconf: Configuration = HBaseConfiguration.create()
hconf.set("hbase.zookeeper.property.clientPort", "2181");
hconf.set("hbase.zookeeper.quorum", "192.168.116.121");
createTable(hconf,"test1")
val htable = new HTable(hconf,"test1")
htable.setAutoFlush(false)
htable.setWriteBufferSize(10 * 1024 * 1024)
htable.put(p)
htable.flushCommits()
}).collect()
println("程序结束")
// 插入数据
// val put = new Put(Bytes.toBytes("row3"))
// put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("address"),Bytes.toBytes("33333"))
// htable.put(put)
// htable.flushCommits()
spark.stop()
}
}