计算机视觉竞赛技巧总结(一):目标检测篇

作者简介: 大数据专业硕士在读,CSDN人工智能领域博客专家,阿里云专家博主,专注大数据与人工智能知识分享。公众号:GoAI的学习小屋 ,免费分享书籍、简历、导图等资料,更有交流群分享AI和大数据,加群方式公众号回复“加群”或➡️点击链接。
专栏推荐: 目前在写一个CV方向专栏,后期会更新不限于目标检测、OCR、图像分类、图像分割等方向,目前活动仅19.9,虽然付费但会长期更新且价格便宜,感兴趣的小伙伴可以关注下,有擅长CV的大佬可以联系我合作一起写。➡️专栏地址
学习者福利: 强烈推荐一个优秀AI学习网站,包括机器学习、深度学习等理论与实战教程,非常适合AI学习者。➡️网站链接。
技术控福利: 程序员兼职社区招募!技术范围广,CV、NLP方向均可,要求有一定基础,最好是研究生及以上或有工作经验,也欢迎有能力本科大佬加入!群内Python、c++、Matlab等各类编程单应有尽有, 资源靠谱、费用自谈,有意向者直接访问➡️链接。
导读:本系列主要面向计算机视觉目标检测、图像分割及OCR等领域,每章将分别从最新方法、开源框架、数据、模型、常用Tricks等方面展开介绍,主要面向深度学习CV方向同学学习,希望大家能够多多交流,欢迎订阅本专栏,如有错误请大家在评论区指正,如有侵权联系删除。同时也欢迎大家加入文章最上方交流群,群内将分享更多大数据与人工智能方向知识资料,会有一些学习及其他福利!
目标检测竞赛总结
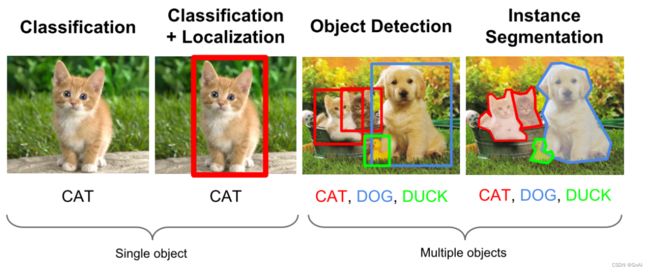
在计算机视觉中,图像分类、目标检测和图像分割都属于最基础、也是目前发展最为迅速的3个领域,我们可以看一下这几个任务之间的区别。
- 图像分类:输入图像往往仅包含一个物体,目的是判断每张图像是什么物体,是图像级别的任务,相对简单,发展也最快。
- 目标检测:输入图像中往往有很多物体,目的是判断出物体出现的位置与类别,是计算机视觉中非常核心的一个任务。·
- 图像分割:输入与物体检测类似,但是要判断出每一个像素属于哪一个类别,属于像素级的分类。图像分割与物体检测任务之间有很多联系,模型也可以相互借鉴。
目标检测技术,通常是指在一张图像中检测出物体出现的位置及对应的类比,我们要求检测器输出5个value:物体类别class、bounding box左上角x坐标x、bounding box左上角y坐标y、bounding box右下角x坐标x、bounding box右下角y坐标y。实际上,不管是传统算法还是深度检测算法,它们的流程都可以概括为以下三步:
- 1.区域选取:首先选取图像中可能出现物体的位置,由于物体位置、大小都不固定,因此传统算法通常使用滑动窗口(Sliding Windows)算法,但这种算法会存在大量的冗余框,并且计算复杂度高。深度算法大多使用RoI先进行区域选择再判别(Two-stage),或将目标检测问题转换为直接从图像中提取bounding boxes和类别概率的单个回归问题(One-stage)。
- 2.特征提取:在得到物体位置后,通常使用人工精心设计的提取器进行特征提取,如SIFT和HOG等。由于提取器包含的参数较少,并且人工设计的鲁棒性较低,因此特征提取的质量并不高,而这也是深度算法提升最明显的一个步骤。
- 3.特征分类:最后,对上一步得到的特征进行分类,传统通常使用如SVM、AdaBoost的分类器,而深度算法一般通过全连接层与正则化层、池化层的组合实现。
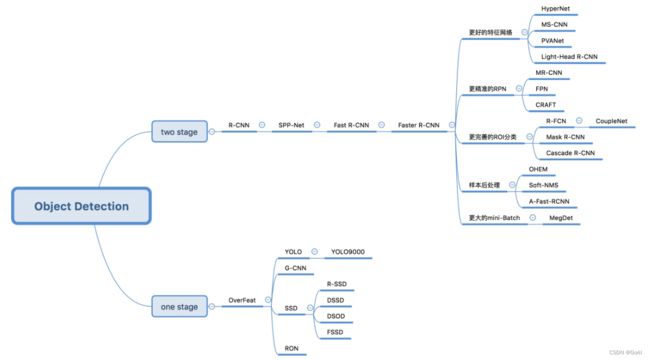
目标检测算法分类
基于深度学习的目标检测算法主要分为两类:
1.Two stage目标检测算法
先进行区域生成(region proposal,RP)(一个有可能包含待检物体的预选框),再通过卷积神经网络进行样本分类。
任务:特征提取—>生成RP—>分类/定位回归。
常见的two stage目标检测算法有:R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN和R-FCN等。
2.One stage目标检测算法
不用RP,直接在网络中提取特征来预测物体分类和位置。
任务:特征提取—>分类/定位回归。
常见的one stage目标检测算法有:OverFeat、YOLOv1、YOLOv2、YOLOv3、SSD和RetinaNet等。
随着目标检测算法的深入研究,它们所依赖的代码框架也呈现出越来越多样化的趋势。为了在竞赛中取得一个好成绩,在上述基础认识的基础上,我们首先需要结合竞赛要求选择合适的代码框架,并结合自身所拥有的计算条件选择合适的算法模型并设计相应的损失函数,最终,针对竞赛数据集、任务或算法模型的特殊性选择合适的Trick实现性能涨点。
1️⃣目标检测框架选型
1.1. PaddleDetection
PaddleDetection为基于飞桨PaddlePaddle的端到端目标检测套件,内置30+模型算法及250+预训练模型,覆盖目标检测、实例分割、跟踪、关键点检测等方向,其中包括服务器端和移动端高精度、轻量级产业级SOTA模型、冠军方案和学术前沿算法,并提供配置化的网络模块组件、十余种数据增强策略和损失函数等高阶优化支持和多种部署方案,在打通数据处理、模型开发、训练、压缩、部署全流程的基础上,提供丰富的案例及教程,加速算法产业落地应用。
PaddleDetection的安装和配置可具体安装步骤大家可以参考官方文档,同时,官方提供了利用PaddleDetection部署项目的案例:
- 如何利用PaddleDetection做一个完整的项目(一)
- 如何利用PaddleDetection做一个完整的项目(二)
- 如何利用PaddleDetection做一个完整的项目(三)
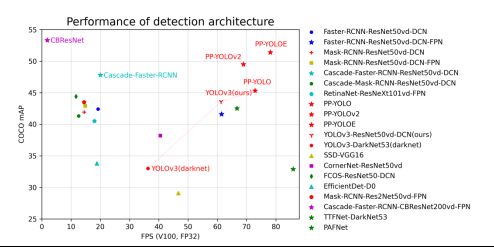
下图展示了各模型结构和骨干网络的代表模型在COCO数据集上精度mAP和单卡Tesla V100上预测速度(FPS)对比图。
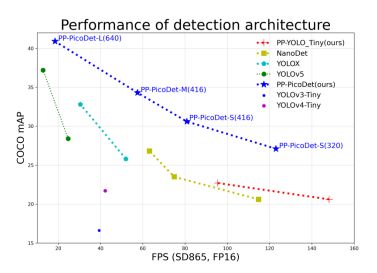
下图展示了各移动端模型在COCO数据集上精度mAP和高通骁龙865处理器上预测速度(FPS)对比图。
1.2. MMdetection
MMDectection是商汤公司推出的OpenMMLab系列代码中的检测项目。OpenMMLab现在也基本囊括了所有计算机视觉任务。OpenMMlab系列的开源项目,代码模块化、抽象做得比较好,容易拓展,对新手不太友好,但是对相对资深的从业者,无论是学术研究还是打比赛,比较友好。OpenMMLab将MMDetection打造成了一个爆款,目标检测在所有计算机视觉任务中是重要性和难度结合得最好的任务。分类很重要,但是分类非常简单,实现起来难度不大;实例分割实现起来难度较大,但是却没那么重要。MMDetection紧跟学术前沿,基本所有目标检测模型都能在MMDetection中找到。
MMDetection 是一个基于 PyTorch 的目标检测开源工具箱,主分支代码目前支持 PyTorch1.5以上的版本。读者可以通过官方提供的文档和实例进行更为详细的了解。
- 官网:https://github.com/open-mmlab/mmdetection
- 中文解读文案汇总:https://github.com/open-mmlab/mmdetection/blob/master/docs/zh_cn/article.md
以MMDetection 2.7为例,其核心组件可以总结如下图:
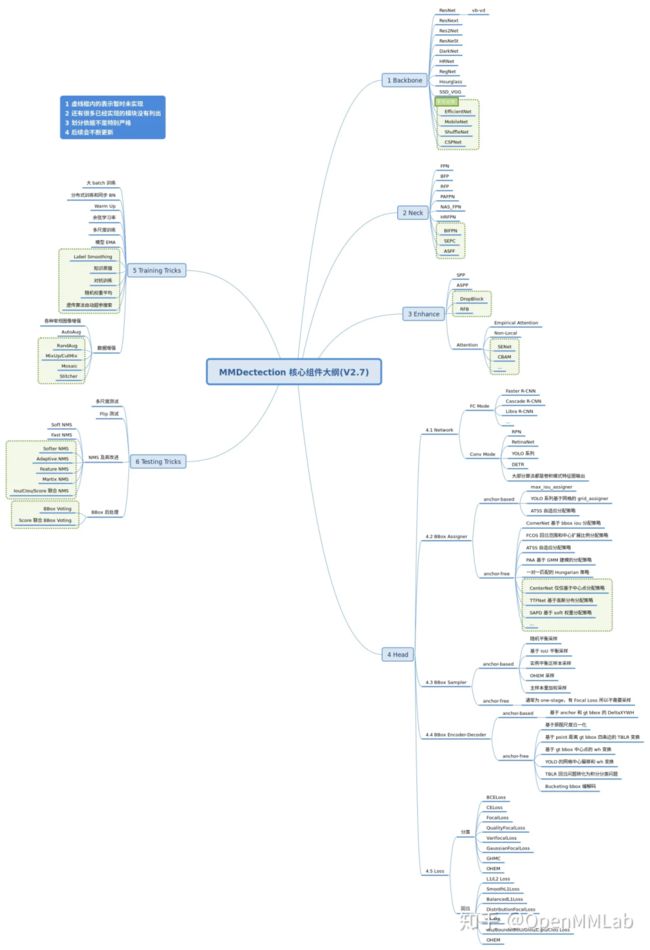
其代码部分一般包括8个核心组件:
- 任何一个 batch 的图片先输入到 backbone 中进行特征提取,典型的骨干网络是 ResNet;
- 输出的单尺度或者多尺度特征图输入到 neck 模块中进行特征融合或者增强,典型的 neck 是 FPN;
- 上述多尺度特征最终输入到 head 部分,一般都会包括分类和回归分支输出;
- 在整个网络构建阶段都可以引入一些即插即用增强算子来增加提取提取能力,典型的例如 SPP、DCN 等等;
- 目标检测 head 输出一般是特征图,对于分类任务存在严重的正负样本不平衡,可以通过正负样本属性分配和采样控制;
- 为了方便收敛和平衡多分支,一般都会对 gt bbox 进行编码;
- 最后一步是计算分类和回归 loss,进行训练
- 在训练过程中也包括非常多的 trick,例如优化器选择等,参数调节也非常关键。
- MMDetection 已支持的backbone网络:

- neck 可以认为是 backbone 和 head 的连接层,主要负责对 backbone 的特征进行高效融合和增强,能够对输入的单尺度或者多尺度特征进行融合、增强输出等。
- 目标检测算法输出一般包括分类和框坐标回归两个分支,不同算法 head 模块复杂程度不一样,灵活度比较高。在网络构建方面,理解目标检测算法主要是要理解 head 模块。
- enhance 是即插即用、能够对特征进行增强的模块,其具体代码可以通过 dict 形式注册到 backbone、neck 和 head 中,非常方便(目前还不完善)。常用的 enhance 模块是 SPP、ASPP、RFB、Dropout、Dropblock、DCN 和各种注意力模块 SeNet、Non_Local、CBA 等。目前 MMDetection 中部分模块支持 enhance 的接入,例如 ResNet 骨架中的 plugins,
- Loss 通常都分为分类和回归 loss,其对网络 head 输出的预测值和 bbox encoder 得到的 targets 进行梯度下降迭代训练。
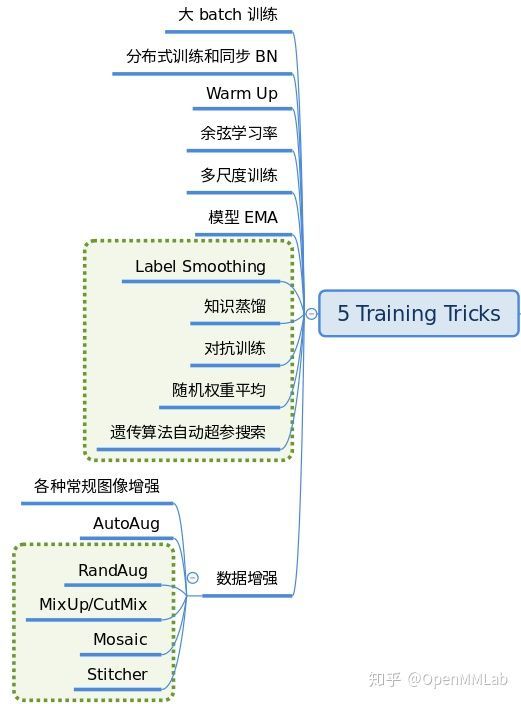
- 训练技巧非常多,常说的调参很大一部分工作都是在设置这部分超参。这部分内容比较杂乱,很难做到完全统一,目前主流的 tricks 如下所示。
MMDetection 已支持的算法架构:

2️⃣模型选型
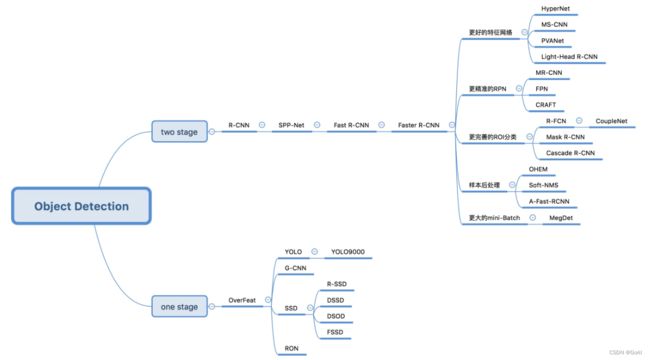
在竞赛中挑选一个合适的神经网络模型,首先要对竞赛要求有充分的掌握,例如有的竞赛是以检测精度为目标的,有的竞赛是以检测速度为第一指标的,只有确定竞赛要求后,我们才能从海量的检测模型中挑选合适的网络结构。搭建检测模型必然要求我们对相关的检测模型有所了解,简单来说目标检测算法可以按照 3 个维度划分:
- 按照 stage 个数划分,常规是 one-stage 和 two-stage,但是实际上界限不是特别清晰,例如带 refine 阶段的算法 RepPoints,实际上可以认为是1.5 stage 算法,而 Cascade R-CNN 可以认为是多阶段算法,为了简单,上面图示没有划分如此细致;
- 按照是否需要预定义 anchor 划分,常规是 anchor-based 和 anchor-free,当然也有些算法是两者混合的;
- 按照是否采用了 transformer 结构划分,目前基于 transformer 结构的目标检测算法发展迅速,也引起了极大的关注,所以这里特意增加了这个类别的划分。
不管哪种划分方式,其实都可以分成若干固定模块,然后通过模块堆叠来构建整个检测算法体系。读者可参照如下链接获取论文合集: 链接。

总的来说,可以将检测网络的发展历程总结如上图。值得一提的是,尽管基于Transformer的检测网络能够在竞赛数据集、科研数据集上取得更好的效果,但它们对计算资源和训练数据具有更高的要求。因此,在大部分竞赛中,目前主流的模型仍集中在R-CNN和Yolo两个系列:
- 没有速度要求的话,通用就是Cascade R-CNN + Big backbone + FPN (Bbox长宽比例极端的话考虑加入DCN以及修改anchor的比例值,默认是0.5,1,2,比如可以修改为[0.2, 0.5, 1, 2, 5]);
- 有速度要求就可以尝试YOLO系列(听说YOLO v5在kaggle的小麦检测上霸榜,可以看看他们的notebook),anchor的比例设置还是要多EDA分析得到一个合适的选择。
3️⃣常用trick介绍
目标检测中可以用到的涨点Trick大致可以分为:
- 数据,即使用数据增广的方式提升训练集质量和模型训练质量;
- 模型,包括两种思路:一是改进模型的结构或bbox的生成进行改进,二是进行多模型聚合;
- 损失,主要是针对性地在模型训练过程中调用损失函数。
1.数据
数据增强是增加深度模型鲁棒性和泛化性能的常用手段,随机翻转、随机裁剪、添加噪声等也被引入到检测任务的训练中来,个人认为数据(监督信息)的适时传入可能是更有潜力的方向。
数据增强常用手段包括随机翻转、随机裁剪、添加噪声等也被引入到检测任务的训练中来,其信念是通过数据的一般性来迫使模型学习到诸如对称不变性、旋转不变性等更一般的表示。通常需要注意标注的相应变换,并且会大幅增加训练的时间。个人认为数据(监督信息)的适时传入可能是更有潜力的方向:
- 空间不变性: 神经网络模型具有空间不变性,为了解决它,一般需要采用一些空间增强手段例如平移、旋转、翻转、缩放、实例平衡增强等。
- 噪声: 神经网络模型有时候过于依赖训练数据,缺少推断能力而影响通用性,即使人眼能识别出噪声图片里的目标,但模型却不太行,所以为了让模型更加鲁棒,可以考虑在训练集内加入高斯噪声、椒盐噪声等对模型进行干扰。
- 目标遮挡或重叠: 如果数据研究时发现存在多框重叠现象,或者存在目标遮挡,可以试着采用Cutout或Mixup 等。
- 过采样: 有时候整体数据量过少,或某类别数少导致类别不平衡,可以考虑使用copy-paste、泊松融合等技巧,但要注意,增强的目标不要过于突兀,不然会造成模型过拟合。
- 图像模糊: 图像模糊的原因有很多,例如:镜头模糊,雾天图像,水下光线散射等,对此的数据增强手段有中值/高斯/动态模糊、去雾算法, MSRCR 等。
- 其它: 标签平滑, 色调归一化,Albumentation图片数据增强库 等。以上所有数据增强方法分线上和线下两种使用方式,不同数据增强方法之间存在功能重叠,基本都能在一定程度上减少模型过拟合,但也可以会有过拟合的可能(例如copy-paste和实例平衡增强等会重复部分数据集的可能)。
- 输入图片的尺寸对检测模型的性能影响相当明显,事实上,多尺度是提升精度最明显的技巧之一。在基础网络部分常常会生成比原图小数十倍的特征图,导致小物体的特征描述不容易被检测网络捕捉。通过输入更大、更多尺寸的图片进行训练,能够在一定程度上提高检测模型对物体大小的鲁棒性,仅在测试阶段引入多尺度,也可享受大尺寸和多尺寸带来的增益。
谷歌、UC伯克利与康奈尔大学的研究人员曾在《 Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation 》中提出的策略,其最好模型在COCO数据集上实例分割和目标检测任务中分别达到49.1 mask AP 和 57.3 box AP,比之前最好结果分别高0.6 和1.5 个点!该文主要使用了训练集中实例分割对象复制粘贴实现训练阶段的数据增广,其增广方法三个字概括为“无限制”:
-
随机选择两幅训练图像
-
随机尺度抖动缩放
-
随机水平翻转
-
随机选择一幅图像中的目标子集
-
粘贴在另一幅图像中随机的位置
目标检测常用数据集
-
[PASCAL VOC] The PASCAL Visual Object Classes (VOC) Challenge | [IJCV’ 10] | [pdf]
-
[PASCAL VOC] The PASCAL Visual Object Classes Challenge: A Retrospective | [IJCV’ 15] | [pdf] | [link]
-
[ImageNet] ImageNet: A Large-Scale Hierarchical Image Database| [CVPR’ 09] | [pdf]
-
[ImageNet] ImageNet Large Scale Visual Recognition Challenge | [IJCV’ 15] | [pdf] | [link]
-
[COCO] Microsoft COCO: Common Objects in Context | [ECCV’ 14] | [pdf] | [link]
-
[Open Images] The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale | [arXiv’ 18] | [pdf] | [link]
-
[DOTA] DOTA: A Large-scale Dataset for Object Detection in Aerial Images | [CVPR’ 18] | [pdf] | [link]
-
[Objects365] Objects365: A Large-Scale, High-Quality Dataset for Object Detection | [ICCV’ 19] | [link]
2.模型
对于模型结构的改进实际上是科研时需要关注的重点问题,这里我们不再赘述。而在竞赛过程中,仍存可以调节如下可能的参数或方法:
- 训练尺度: 根据显存和时间安排设置训练是否采取多尺度,正常来说,尺度越大越好,小目标能更好的被检测到,但也存在尺度调整过大,图片失真。在设置尺度上,我一般是放开Resize对长边的依赖(即长边至少为:训练原图尺寸最大长短比 * Resize短边上限),mmdetection论文提到提高短边上限能带来提升。
- **测试尺度:**取训练尺度的中间值即可。假设训练多尺度设置是[(4096, 600), (4096, 1000)],那么测试尺度如果你想设为单尺度,可以是(4096, 800),如果是多尺度,可以是[(4096, 600), (4096, 800), (4096, 1000)]。测试多尺度会更好些,但推理速度会变慢。
- Anchor (scales & ratios):正常来说,锚点框的设置保持默认配置就好,但是如果遇到某类别目标是极端长宽比,则可能需要根据数据研究的结果适当调整下锚点框宽高比率,而锚点框大小scale相对来说不太需要对其进行过多调整。我之前试过使用YOLOv2中提到的K-means来获取Anchor聚类结果,进而调整Anchor的设置,但是结果不太理想,实际感受野是一个超参,无法准确求出,K- means聚类Anchor得到的范围实际上不一定有默认Anchor的广。简而言之,就是不要乱动默认的配置,可以添加多一个Anchor Ratio,但不建议自行胡乱调参。
- Backbone:目标检测的主干网络很多,选择主干网络的第一要素就是得先确认模型的感受野是否尽可能大于数据集多数标注框的长边。当你确定了训练尺度,选择最大Resize比例去绘制标注框宽高散点图,然后选取合适的模型Backbone。如果模型感受野太小,只能观察到局部特征,不足以得到整个目标的信息;如果感受野过大,则会引入过多的无效信息。现在计算感受野有两种方法:(1)从上往下法:即从低层到高层,这种方法计算更便捷些,但只适用于比较有限的卷积,且由于没有处理由Stride引起的抽取像素重叠的问题,使得计算的感受野会偏大些;(2)从下往上法:即从高层到低层,计算感受野是通过递推计算,它很准确。限制一些SOTA的主干模型有:ResNet, ResNeXt, DenseNet, SENet等。此外,如果存在极端宽高比的目标,可以使用可变形卷积网络(Deformable Convolution Net, DCN)。
- Neck: 用的比较多的就特征金字塔网络(Feature Pyramid Networks, FPN),对于小目标检测非常好用。
- ROIHead:在mmdetection里RoIHead的作用是帮助模型基于RoI进行预测,现在比较受欢迎的模型是Cascade R-CNN,它级联三个不同IOU阈值(0.5,0.6,0.7)的头,但在2019广东工业智造创新大赛决赛上,某团队针对评测mAP要求的IOU阈值0.1、0.3和0.5,降低了级联的阈值至0.4、0.5和0.6,从而获得了提升,说明宽松评测下,级联头阈值可适当减低以获取更多的预测框,这种方式可能会提升性能。另外,在天池”重庆大赛-瓶装白酒疵品质检”里,好像也还有选手通过增加多一个head,在某种程度上帮助模型更好的拟合数据,但不一定在每个赛题数据上都起作用。
- 混合精度训练: 开启fp16能加快模型运算速度。
- **学习率:**学习率的设置应参考论文《https://arxiv.org/abs/1706.02677》. 该论文提到在使用多GPU并行进行Minibatch SGD的行为被称作Large Minibatch SGD。假设有k个GPUs,那么Large Minibatch size =k * Minibatch size(即mmdetection中的img_per_batch),此时多GPU下学习率 = 单GPU 下的Lr * k。总结来说,Lr = GPU数量 * Minibatch Size * 0.00125。
- 学习率在衰退前使用warmup会好些,衰退策略使用Cosine会比Step更快帮助模型拟合数据。此外,mmdetection作者认为像多尺度训练这样的训练增强应该需要24epoch数进行训练,但一般来说1x的训练epoch数就能应付较多的场景。个人认为,1x(2epochs)和2x(24epochs)的选择得看训练后的损失曲线或mAP曲线的表现来决定。
在模型融合这一点上,我们可以考虑两种方式:
- 直接合并: 就是根据验证集的表现,选取不同模型设置下,最好表现的类别结果进行合并,例如有2个不同的模型设置(设置1和2)且预测类别有2个(类别A和B),类别A在模型设置2下表现最好,而类别B在模型设置1下表现最好,那么最后的提交结果应该由模型设置2下的类别A结果和模型设置1下的类别B结果合并组成。优点是该合并比较简单快速,缺点是它要求验证集的真实反应能力强,比如之前宫颈癌细胞检测比赛,数据集很大,验证集表现和线上测试集表现基本一致,它就很适合直接合并模型结果。
- WBF: 权重框融合Weighted Boxes Fusion也是比较受欢迎的模型集成方法,它将同类下达到某IoU的框们,进行加权平均得到最终的框,权重为各预测框上预测类别的分数。WBF有两种融合思路: 不同backbone的融合和不同结构的模型的融合,据论文所述这种方法比前者提升更大。在使用中要注意,Soft NMS输出结果要搭配max的置信度融合方法(即在两个模型预测结果中选择其中最大的置信度作为平均融合框的置信度,避免平均融合后的结果不会受冗余低分框影响),而普通NMS输出结果搭配avg融合方式即可。
值得一提的是,对于模型融合,其子模型的选择非常重要,一般有四种选择方式:a. 同样的参数,不同的初始化方式;b. 不同的参数,通过交叉验证,选取最好几组;c. 同样的参数,不同迭代次数训练下的模型(可以参照《SWA Object Detection》中的研究成果);d. 不同的模型,线性融合,例如RNN和传统模型。
3.损失

OHEM(Online Hard negative Example Mining,在线难例挖掘)。两阶段检测模型中,提出的RoI Proposal在输入R-CNN子网络前,我们有机会对正负样本(背景类和前景类)的比例进行调整。通常,背景类的RoI Proposal个数要远远多于前景类,Fast R-CNN的处理方式是随机对两种样本进行上采样和下采样,以使每一batch的正负样本比例保持在1:3,这一做法缓解了类别比例不均衡的问题,是两阶段方法相比单阶段方法具有优势的地方,也被后来的大多数工作沿用。
png)
NMS

NMS(Non-Maximum Suppression,非极大抑制)是检测模型的标准后处理操作,用于去除重合度(IoU)较高的预测框,只保留预测分数最高的预测框作为检测输出。在传统的NMS中,跟最高预测分数预测框重合度超出一定阈值的预测框会被直接舍弃,作者认为这样不利于相邻物体的检测。提出的改进方法是根据IoU将预测框的预测分数进行惩罚,最后再按分数过滤。配合Deformable Convnets(将在之后的文章介绍),Soft NMS在MS COCO上取得了当时最佳的表现。
更多介绍参考:NMS技术总结
GIoU
GIoU是源自IoU的一种边框预测的损失计算方法,在目标检测等领域,需要对预测边框(pre BBox)与实际标注边框(ground truth BBox)进行对比,计算损失。在Yolo算法中,给定预测值与ground truth的(x, y, w, h)进行预测,采用回归损失。但实际上,回归损失并不是该问题的最好损失函数,因为其只关注(x, y, w, h)对应的“距离”,而本质上我们想要得到 IoU 值比较大的预测框,两者联系并不大。那么为什么不直接采用IoU值作为损失函数呢?因为一旦预测框与真实框不相交,那么IoU都为0,也就是说,在很大的范围内(不相交的区域),损失函数是没有梯度的,因此才有了GIoU Loss(Generalized Intersection over Union)。一般情况下,用GIoULoss代替L1Loss后会涨点。
更多介绍参考 IOU、GIOU、DIOU、CIOU损失函数详解
文章未更新完整,后续系列敬请期待!