02百万架构师核心技术设计实践
本文包括:高可用设计、无状态化与冗余设计、负载均衡设计、幂等设计、分布式锁设计
一、互联网高可用设计:
1.高可用的定义:
高可用针对的对象是服务与架构,高可用是什么?它表示任何人、任何时间、任何地点、任何方式、访问服务、返回正确结果。

2.高可用评估方式:
传统评估方式是用停机时间,如满足几个9的时间不停机,不合理,因为时间分为高峰期与低峰期,高可用的目的是产生最大效益,如果服务在高峰期不可用(如天!!!猫双11)可能停机时间不长,但会对企业造成严重的损失,所以不能用停机时间来评估高可用,那问题来了用什么?用流量
3.不高可用的原因:
- 硬件不可靠,硬件故障、硬件生命周期
X86,32C 128G 2T 12000转,4-5万,3-5年退役
解决方案,主从、备份、无状态化集群部署、两地三中心,同城双活等。 - 软件不可靠,潜在bug、性能极限
如我们的系统可以支持1万qps,突然来2万,系统可能挂
4.架构高可用:
上面说了那么多都是针对服务的,那为什么架构要做到高可用呢?
因为如果高可用从架构方面得到解决,避免code body自己思考,写高可用,不然影响code body开发效率,不合适,另外高可用在每个系统都可以用,所以高可用这样的公用的东西抽出来,可以进行复用,成为高可用架构。
5.微博高可用案例:
场景:14年M鹿M发了一条微博,然后微!!!博挂了!
 分析下我们需要处理的问题:
分析下我们需要处理的问题:
5.1.鹿晗这个信息(大家好,给大家介绍一下,这是我女朋友@关晓彤),粉丝数量大,要将这条信息短时间内展示给粉丝,对系统压力很大
5.2.另外,评论、点赞、转发,这几个按钮短时间内点击率大。
首先第一个问题,微博是一个feed流系统,好友是单向好友,这条信息是推给粉丝,还是粉丝自己拉?推是tps,拉是qps,针对此场景肯定要采用拉的手段。但是拉影响及时性,所以针对粉丝量极其少的小散户为了让粉丝及时看到消息,则采用推的手段。(推特也是使用推拉结合的手段)
那么针对M鹿M这条信息,采用拉的手段,抗qps一般思路就两条,第一增加抗的能力,第二限流;下面我们层层加码,优化系统,达到高可用
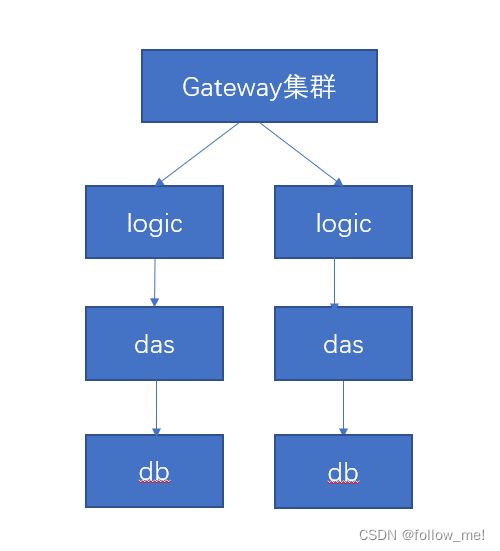
针对上面的架构,最先扛不住的是哪里,是DB,因为DB最接近磁盘IO,越往下性能越差。除了db以外,每个微服务对外提供的也有瓶颈,据说,网易考拉大概每个微服务抗1500qps左右。
- +,我们的首先撑不住的是DB,常规的我们遇到系统瓶颈会采用一主多从,写主读从,假定一主三从,如主键%3,0读0库,1读1库,2读2库,行不行? (不行,由于信息主键取余确定的库始终不变,所以多从对此案例(热点key问题)无用) //这里可能有人有疑问了,用userid取模不就可以分散到不同的db了么?是,这样可以提高部分性能,但是仍然扛不住。
- ++,引cache,上redis,上redis cluster,直接读redis行不行?(不行,redis cluster对于热点key问题,也存在上面所说的问题,只有单个节点的单个槽点起作用, redis单个槽位最大10wqps,也根本扛不住)
- +++,上云,云原生,让云厂商承担服务扩充的代价行不行?(不行,云厂商不可能在短时间内给你分出那么多机器)
- ++++,用cdn行不行?(不行,cdn是预先配置的,根本来不及)
- +++++,多级缓存+热点机制,监听热key,采用多级缓存,热key放在das层的cache上,das去哪里读热key?【DB(不行,增加db压力),mq(可以)】(可行,因为我们的瓶颈主要在DB,这时我们将问题上移到了das层,das原本能抗多少qps,这时就能抗多少,扛不住就扩容,只要能无限扩容,就能抗住,微博采用这套机制后,后来出现赵丽颖事件,微博又崩了,因为啥?roi投资回报率,因为das不可能无限扩容,没那么多资源,比如正常情况下100万台机器可以,突发200万台,不可能时刻准备100万台机器,不划算,云厂商一时间也无法提供那么多,而且das扩容需要时间,大部分在秒级别,但是可能跟不上流量上升的速度,所以我们要做降级、流控,先拒绝,保证系统不挂,扩容一点放一点进来,),
针对评论、点赞、转发数是统计值,实时性要求不高,可以异步写+批量写,所以我们可以先写mq,一段时间后,进行批量操作。
多级缓存的实现:
用算法监控热key,比如将按粉丝量大的KOL(Key Opinion Leader的简称,意思是关键意见领袖)、qps短时间内的上升速度等手段,定位到热key,将热key的消息写入mq,然后各das将消息从mq拿出,放入本地缓存。热key不是永久的,如设置一个小时,一个小时以后移除。
6.高可用架构设计实现:
- 服务冗余设计:可以启多个服务,这个不行了,上另一个
- 服务无状态化设计:abc三个服务对外提供服务的能力需要相同(都处理一样的事,要做到服务无状态化)
- 负载均衡设计:所有的流量不能都打在一个服务上。
- 幂等设计:当网络抖动,retry的时候,需要幂等设计,不然可能新增多条数据,所以无论retry到谁,处理的结果都一样。
- 超时设计:缓存超时了清除,请求超时了
- 异步设计:异步解耦,削峰平谷
- 服务自我保护:限流、降级、熔断
- 存储方面,存储冗余(如:1主从,2newSql保证高可用是采用副本机制)/存储Sharding(数据分治)/缓存
- 架构拆分/服务治理:API垂直拆分,读写分离,提高扩容速度;(全系统的服务治理)

7.各架构实现高可用:
- 单体架构高可用实践:
DB主从;应用灾备;lvs+keepalive,自动切换 - soa架构高可用实践:
soa每个也是大单体,用上面单体的方式一样,db主从,应用灾备,;lvs+keepalive,自动切换 - 水平分层架构高可用实践:
水平分层架构与业务关联不大,用DB主从;应用灾备;lvs+keepalive,自动切换 - 微服务架构高可用实践:
到了微服务时代,用上面的那些已经不行了; - 服务网格架构高可用实践:
- 中台架构高可用实践:
组织架构先行,接着业务架构,最后技术架构;以上的架构都可以用来做用 - 云原生架构高可用实践:
侧重云端,运维侧,微服务用到的,它都要用
8.如何优雅停机保证高可用:
流量控制,流量只出不进;
- 网关可以不?观测业务层有无业务日志(除了一些心跳,定时任务等),优雅停机,运用钩子函数,一个服务一个服务的释放资源,避免kill -9;这是网关有流控能力的。
- 如果是linux系统可以用防火墙做到只出不进。
- lvs\ng都可以做到,流量只出不进;
二、无状态化设计与实践:
加载热点数据进缓存、静态数据可能造成服务的短暂不一致;无伤大雅,影响不大,还是无状态化。做无状态化是为了快速扩容,弹性缩容,如原来10个用户服务、40个订单、50个商品,有一天做用户活动,这用户扩到30,订单缩到30,商品缩到40即可。
且现在都上云,如果不无状态化,怎么上云?
2.1案例:
登录,网关存session,影响效率且无法扩容,我们扩容一般会数据分治,1-1000存gw1,1001-2000存gw2,有了状态。
解决:
session外置出去,存缓存,如redis
session存app,每次访问带着session,jwt(java web token)
2.2mysql如何无状态化:
mysql天生有状态化,我们将mysql的存储外置,外挂磁盘,外挂存储
三、服务负载均衡设计:
负载均衡是服务治理的一部分
1.狭义负载均衡:
1.1负载均衡的技术有哪些:
- 硬件:F5、A10、Radware
- 软件:lvs(4层)、Nginx(7层,4层)、HAProxy(4层或7层)
所谓的四到七层负载均衡,就是在对后台的服务器进行负载均衡时,依据osi协议第四层(传输层)或第七层(应用层)的信息来决定怎么样转发流量。
所谓四层负载均衡,也就是主要通过报文中的ip+端口,再加上负载均衡设备设置的服务器选择方式,决定最终选择的内部服务器。
所谓七层负载均衡,也称为“内容交换”,除了ip+端口外还有应用层的信息,如url、浏览器、语言类别等,再加上负载均衡设备设置的服务器选择方式,决定最终选择的内部服务器。
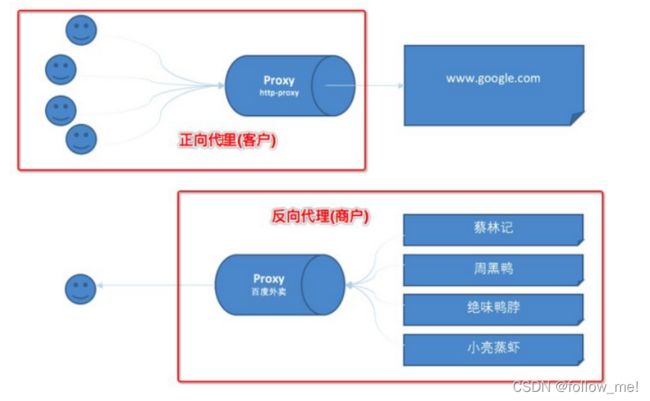
- 反向代理 vs 正向代理
正向代理与反向代理的区别是,客户端知不知道有代理人的存在,知不知道自己被代理了?如果知道就是正向代理,代理的客户端(如翻!!!墙,VPN),如果不知道就是反向代理,代理的服务器(如nginx,客户不知道nginx的存在)。
作用:负载均衡、流量分配(负载均衡可以路由到不同的服务器)、地址路由(改写url,路由到特定服务器)
 1.2负载均衡算法:
1.2负载均衡算法: - 随机
- 轮询
- 一致性hash(相同参数的请求总发到同一提供者)
- 加权轮询
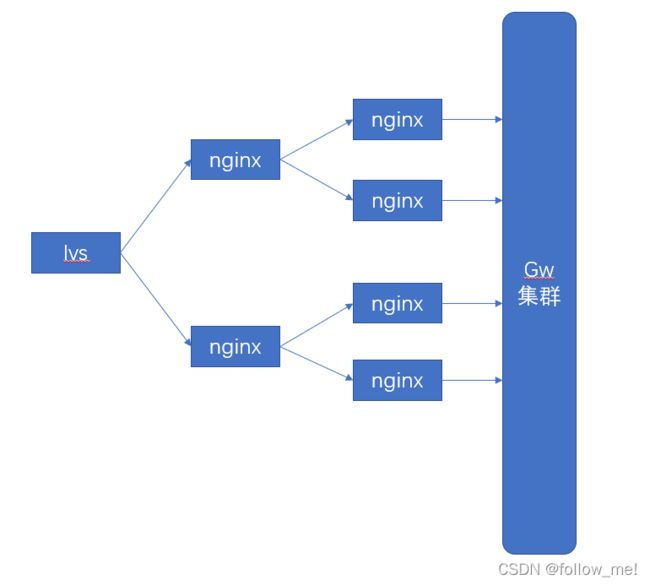
目前主流的负载均衡是:lvs+nginx,nginx可能是多层,其中nginx大约10万并发,lvs大约10-50w并发,有钱人直接用硬件如f5,2G的f5单机400万并发,是lvs的10倍。偏运维与网络规划
2.广义负载均衡:
2.1广义负载均衡与狭义负载均衡的区别:
广义上的负载均衡除了负载以外还会进行故障的发现、摘机,重试与恢复自动发现等操作。
- 故障自动发现(如请求路由到a1实例,能发现a1实例的异常)
- 故障服务的摘除(当a1异常时可以将a1摘除)
- 请求自动重试(请求失败后自动重试)
- 服务恢复自动发现(a1实例异常恢复后自动发现)
2.1.1故障自动发现:
故障自动发现可能有些注册中心支持,有的不支持。
微服务需要进项业务探活操作,如果使用心跳的话可能存在假死状态。
如何实现?写一个默认的简单查询,在配置中心进行配置,然后探活线程定时去注册中心拉取此服务所有的实例进行探活,偶尔单次异常不能直接判断其异常,如一分钟内连续探活失败才能判定其失活。
2.1.2故障服务的摘除:
服务摘机,注册中心是否支持自动摘机,如果不支持就加上自动摘机的功能;
保留事故现场,dump jvm以后,sleep 3/10/30秒,再dump一次(dump两次是为了对比);
优雅停机 kill -15(kill -9是操作系统强制关闭应用,kill -15是通知应用自行关闭,会释放资源后再关闭);
重启服务;
注:问题? 有人说除了注册中心以外,k8s不是也有自动恢复么,为什么还要在负载均衡这里做呢?因为k8s的自动恢复是根据pod的硬件资源来判断的,当服务假死时,资源使用正常,k8s是发现不了的,另外k8s也不会保留事故现场。
2.2广义负载均衡每一层都需要做:
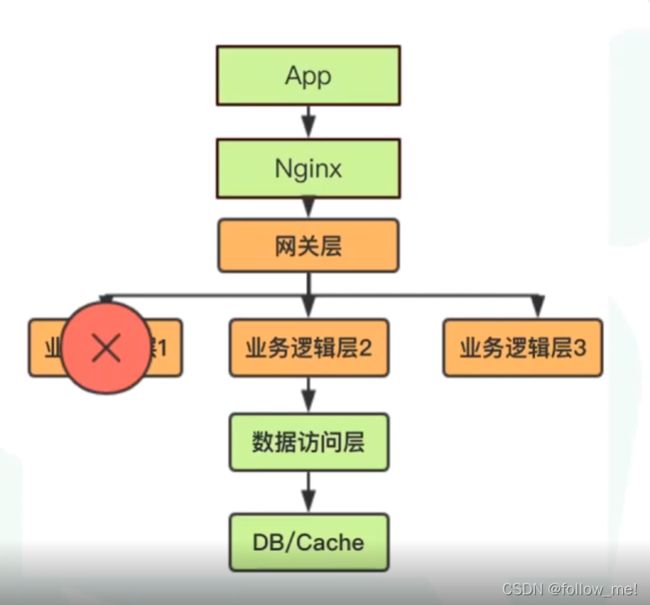
nginx探活谁来做?可以用keepalive
业务逻辑层探活谁来做?注册中心,gateway来做
四、服务幂等设计:
1.服务幂等出现的原因:
水平分层以后,请求链路很长,由于网络通信不可靠,请求可能延迟/丢失,所以会用请求重试来进行网络容错。
2.幂等的分类:
请求幂等与服务幂等


3.请求幂等与服务幂等的区别:
幂等就是无论请求多少次,产生的结果都是一样的。请求幂等与服务幂等的区别,请求幂等是一次请求,重试多少,结果一致;业务幂等多次请求,结果一致。
@单体时代处理幂等的方式:利用token来处理 [删除、查询天然幂等不必处理;对于新增与修改操作,用打开form表单时,获取一个唯一token放入redis中,并放入请求的header中,传给后端,后端收到请求首先去redis删除此token,如果删除成功判定为正常请求,如果删除失败,则提示不要重复提交],[新增,也可以预生成唯一键;非计算型修改天然幂等,避免计算型修改,在业务代码里处理]
@微服务时代的请求幂等:利用token就处理不了了【因为有请求间的retry】
4.请求幂等:
我们来看一下SQL相关业务是否幂等?
a、查询,不会对数据产生任何变化,具备幂等性。
b、新增,
如唯一主键,即重复操作上面的业务,只会插入一条用户数据,具备幂等性。
如不是唯一主键,可以重复,那上面业务多次操作,数据都会新增多条,不具备幂等性。
c、修改,区分直接赋值和计算赋值。
1、直接赋值,update user set point = 20 where userid=1,不管执行多少次,point都一样,具备幂等性。
2、计算赋值,update user set point = point + 20 where userid=1,每次操作point数据都不一样,不具备幂等性。
d、删除,delete from user where userid=1,多次操作,结果一样,具备幂等性。
上面场景中,我们发现新增没有唯一主键约束的数据,和修改计算赋值型操作都不具备幂等性,因此需要单独处理此两种情况:
1.针对计算赋值的修改:避免sql计算,计算放在业务中处理;
2.针对新增:处理insert操作幂等,最简单的是前端提交表单时通过业务逻辑层进行id预生成,form表单带id提交;
5.业务幂等:
5.1. 对于避免短时间内避免重复提交的问题,前端临时限制即可。
5.2. 对于用户一天内只能下一单的问题,可以使用分布式锁处理。
五、分布式锁设计:
1.CAP理论:
cap只可同时满足两者,但不代表要舍弃另一个,在CP\AP\CA中,对于分布式系统应取CP\AP,CA放弃了网络分区容错性,在分布式系统中是不可以的,网络不分区,那就是单体了。
C:即更新操作成功后,所有节点在同一时间的数据完全一致。
A:系统是否能在正常响应时间返回结果。
P:分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
2.案例:
案例1:如茅台一周一个人只能抢一次

3.锁的本质:
锁的本质,是对共享资源的竞争,共享资源如用户、订单;
解决方案,共享资源互斥,共享资源串行化;
问题落地,锁;本地锁or分布式锁?本地锁只是单线程的锁,我们分布式系统,需要用分布式锁。

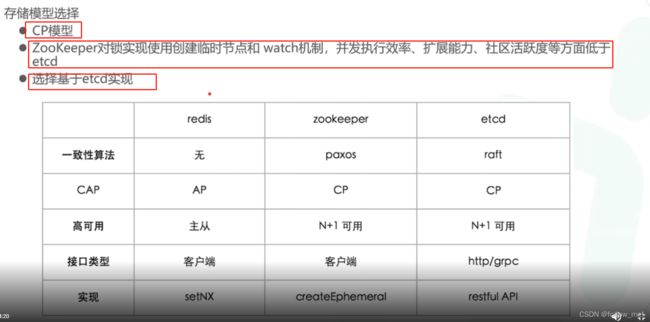
4.分布式锁的实现方式及原理:
- 数据库:db性能局限,大致思路是利用db的唯一键。利用插入唯一键数据是否成功。
- 缓存如redis:分布式锁是CP模型,redis集群是AP模型;利用redis写操作串行化 ,setnx keyx “999”
#不存在时设置,返回1,存在时不设置返回0(set if not exist),或者(set keyx “999” px 1000 nx );存在问题:redis集群异步复制数据,主挂了,数据未同步,则可能多线程获得锁。(数据未同步主挂了,重新选主,导致多线程获取到锁) - zookeeper: 在zookeeper临时有序节点中写,序号最小的一个获得锁
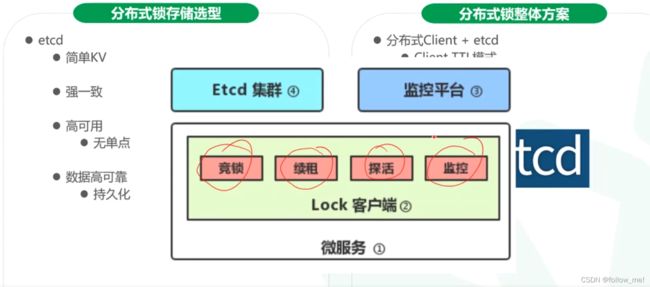
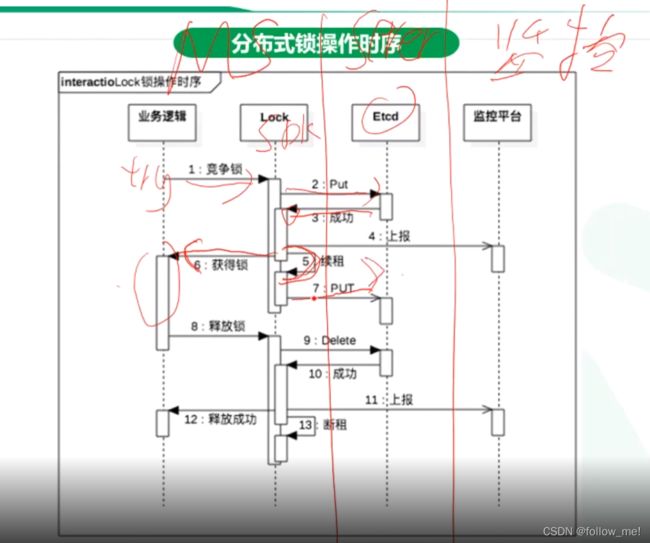
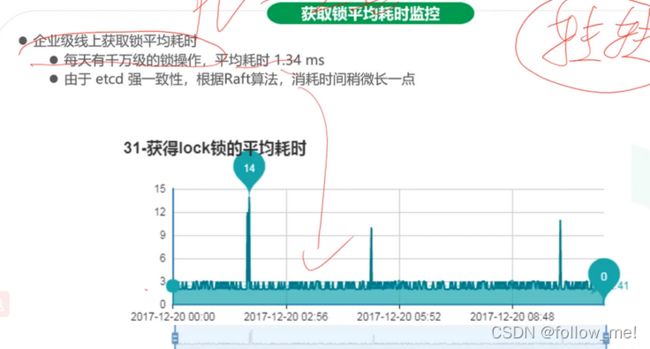
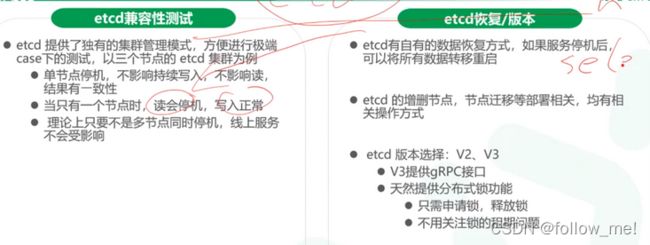
- etcd:raft;往etcd上写
5.设计目标:

6.etcd: