大数据flink框架入门分享(起源与发展、实时与离线计算、场景、处理流程、相关概念、特性普及、入门Demo)
文章目录
-
- 起源与发展
- flink在github上的现状
- 实时计算VS离线计算
-
- 实时计算
- 离线计算
- 实时计算常用的场景
- 框架流处理流程
- flink电商场景下的业务图示例
- flink中一些重要特性
- 有界数据和无界数据
- 时间语义、水位线
-
- 事件时间
- 处理时间
- 水位线
- flink窗口
-
- 概念
-
- 理想中的数据处理
- 含有延迟数据的数据处理
- Flink存储桶概念
- 窗口类型
-
- 滚动窗口
- 滑动窗口
- 会话窗口
- 全局窗口
- flink状态管理
-
- 检查点(Checkpoint)
- 检查点恢复数据过程
- 下载安装
- 入门Demo示例
-
- pom配置
- Demo代码
- 打包到集群
- 流运行时执行环境
- 任务槽Slot
- 扩展Demo
-
- 时间窗口Demo
- Table Api Demo
- 对迟到数据处理Demo
起源与发展
Flink 起源于一个叫作 Stratosphere 的项目,它是由 3 所地处柏林的大学和欧洲其他一些大学在 2010~2014 年共同进行的研究项目,由柏林理工大学的教授沃克尔·马尔科(Volker Markl)领衔开发。2014 年 4 月,Stratosphere 的代码被复制并捐赠给了 Apache 软件基金会,Flink 就是在此基础上被重新设计出来的。
在德语中,“flink”一词表示“快速、灵巧”。项目的 logo 是一只彩色的松鼠,当然了,这不仅是因为 Apache 大数据项目对动物的喜好(是否联想到了 Hadoop、Hive?),更是因为松鼠这种小动物完美地体现了“快速、灵巧”的特点。关于 logo 的颜色,还一个有趣的缘由:柏林当地的松鼠非常漂亮,颜色是迷人的红棕色;而 Apache 软件基金会的 logo,刚好也是一根以红棕色为主的渐变色羽毛。于是,Flink 的松鼠 Logo 就设计成了红棕色,而且拥有一个漂亮的渐变色尾巴,尾巴的配色与 Apache 软件基金会的 logo 一致。这只松鼠色彩炫目,既呼应了 Apache 的风格,似乎也预示着 Flink 未来将要大放异彩。
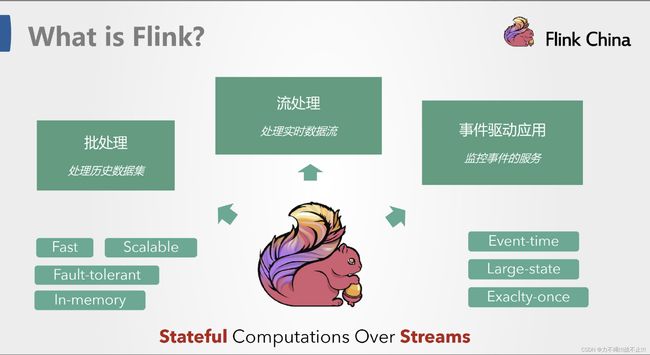

从命名上,我们也可以看出
Flink项目对于自身特点的定位,那就是对于大数据处理,要做到快速和灵活。
- 2014 年 8 月,
Flink第一个版本 0.6 正式发布(至于 0.5 之前的版本,那就是在Stratosphere 名下的了)。与此同时 Fink 的几位核心开发者创办了 Data Artisans 公司,主要做 Fink 的商业应用,帮助企业部署大规模数据处理解决方案。 - 2014 年 12 月,
Flink项目完成了孵化,一跃成为 Apache 软件基金会的顶级项目。 - 2015 年 4 月,
Flink发布了里程碑式的重要版本 0.9.0,很多国内外大公司也正是从这时开始关注、并参与到Flink社区建设的。 - 2019 年 1 月,长期对
Flink投入研发的阿里巴巴,以 9000 万欧元的价格收购了 Data Artisans 公司;之后又将自己的内部版本 Blink 开源,继而与 8 月份发布的Flink1.9.0版本进行了合并。自此之后,Flink被越来越多的人所熟知,成为当前最火的新一代大数据处理框架。 - 2020年:
Flink Forward Asia和Flink Forward Europe两个Flink社区活动成功举办。 - 2021年:
Flink与 ClickHouse 成为 Apache 流式处理项目的顶级项目。 - 2022年:
Flink 1.15 和 1.16版本相继发布,引入了许多新特性和改进。
flink在github上的现状
目前已经到了1.16.1的release版本

实时计算VS离线计算
实时计算
- 数据实时到达
- 数据到达次序独立,不受应用系统所控制
- 数据规模大且无法预知容量
- 原始数据一经处理,除非特意保存,否则不能被再次取出处理,或者再次提取数据代价昂贵
离线计算
- 数据量大且时间周期长(一天、一星期、一个月、半年、一年)
- 在大量数据上进行复杂的批量计算操作
- 数据在计算之前已经固定,不再会发生变化
- 能够方便的查询批量计算的结果
实时计算常用的场景
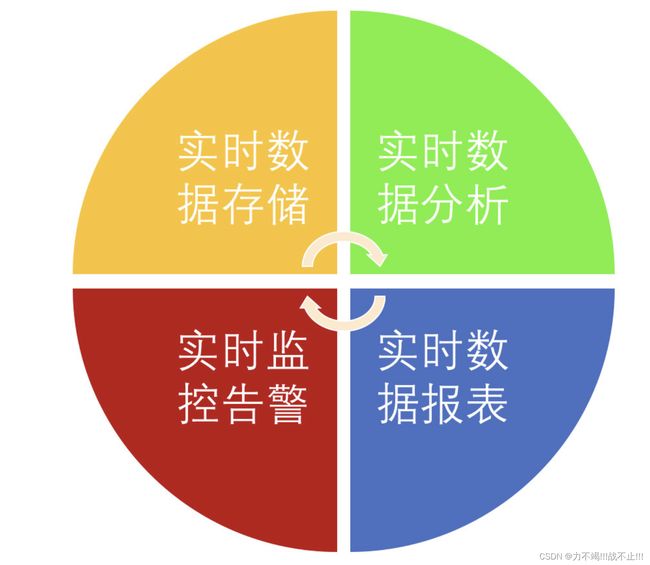
- 实时数据存储:实时数据存储的时候做一些微聚合、过滤某些字段、数据脱敏,组建数据仓库,实时 ETL等
- 实时数据分析:实时数据接入机器学习框架(TensorFlow)或者一些算法进行数据建模、分析,然后动态的给出商品推荐、广告推荐等
- 实时监控告警:金融相关涉及交易、实时风控、行车流量预警、服务器监控告警、应用日志告警等
- 实时数据报表:活动营销时销售额/销售量大屏,TopN 商品等
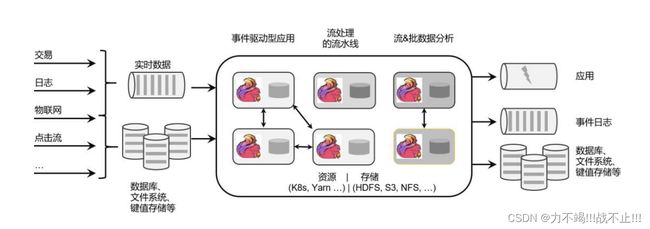
框架流处理流程
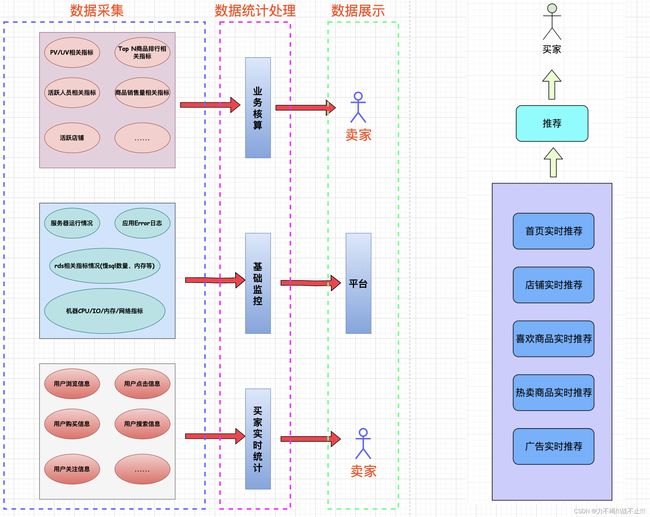
flink电商场景下的业务图示例
flink中一些重要特性
Apache Flink 是一个功能强大的流处理引擎,如果你要在 Flink 上进行研发,下面是一些你必须了解的重要特性:
- 数据流处理和批处理统一:Flink 支持将批处理和流处理统一到一个编程模型中,这使得 Flink 应用程序可以同时处理无界和有界数据集。
- 事件时间处理:Flink 引入了基于事件时间的处理模式,这使得 Flink 应用程序可以处理无序事件数据,并且可以处理延迟事件。
- 窗口操作:Flink 可以对无界数据流进行窗口操作,例如滑动窗口、会话窗口、全局窗口等等。
- 状态管理:Flink 提供了高效的状态管理,可以轻松地维护和访问应用程序的状态。
- 高可用性:Flink 提供了可靠的容错机制,以保证 Flink 应用程序的高可用性和数据完整性。
- 数据源集成:Flink 提供了对多种数据源的支持,例如 Mysql HBase、Elasticsearch、Hive、Kafka、Redis 等等。
- Flink SQL:Flink SQL 允许用户使用 SQL 语言来进行 Flink 应用程序的编写,这使得 Flink 应用程序的编写变得更加简单和直观。
- 深度学习支持:Flink 提供了对深度学习的支持,可以将 TensorFlow、PyTorch 等深度学习框架与 Flink 结合使用,以便在流处理中进行模型训练和推理。
- 可扩展性:Flink 可以轻松地水平扩展,以处理大规模数据集,同时还能保持低延迟。
有界数据和无界数据
Flink 则认为,流处理才是最基本的操作,批处理也可以统一为流处理。在 Flink 的世界观中,万物皆流,实时数据是标准的、没有界限的流,而离线数据则是有界限的流。
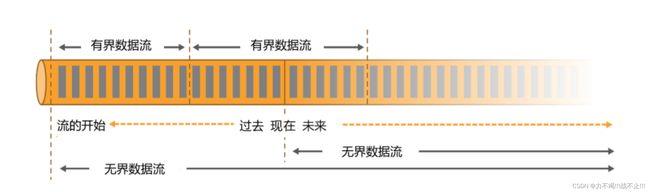
- 无界数据流(Unbounded Data Stream)
所谓无界数据流,就是有头没尾,数据的生成和传递会开始但永远不会结束,如上图所示。我们无法等待所有数据都到达,因为输入是无界的,永无止境,数据没有“都到达”的时候。所以对于无界数据流,必须连续处理,也就是说必须在获取数据后立即处理。在处理无界流时,为了保证结果的正确性,我们必须能够做到按照顺序处理数据。
- 有界数据流(Bounded Data Stream)
有界数据流有明确定义的开始和结束,如上图所示,所以我们可以通过获取所有数据来处理有界流。处理有界流就不需要严格保证数据的顺序了,因为总可以对有界数据集进行排序。有界流的处理也就是批处理。
时间语义、水位线
在讲解flink的窗口之前,需要先了解一下flink的时间语义中的处理时间、事件时间以及水位线,
事件时间
事件时间,是指每个事件在对应的设备上发生的时间,也就是数据生成的时间。
处理时间
处理时间的概念非常简单,就是指执行处理操作的机器的系统时间。
当然处理时间和时间时间可能在处理事件的时候不一样,因网络波动或者其他因素影响到数据的传输导致在事件处理时不一致,如8点产生的数据在8点01s到达,迟到了一秒,当前系统时间为8:01,而事件时间却是8:00
水位线
水位线可以看作一条特殊的数据记录,它是插入到数据流中的一个标记点,主要内容就是一个时间戳,用来指示当前的事件时间。而它插入流中的位置,就应该是在某个数据到来之后;这样就可以从这个数据中提取时间戳,作为当前水位线的时间戳了。
flink窗口
概念
Flink 是一种流式计算引擎,主要是来处理无界数据流的,数据源源不断、无穷无尽。想要更加方便高效地处理无界流,一种方式就是将无限数据切割成有限的“数据块”进行处理,这就是所谓的“窗口”(Window)。
在 Flink 中, 窗口就是用来处理无界流的核心。我们很容易把窗口想象成一个固定位置的“框”,数据源源不断地流过来,到某个时间点窗口该关闭了,就停止收集数据、触发计算并输出结果。
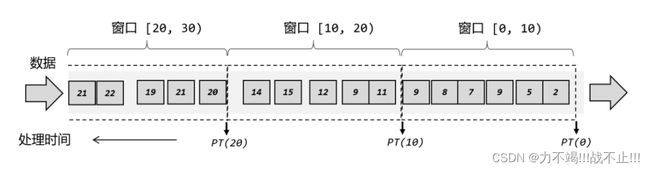
理想中的数据处理
如下图所示,到到达间隔时间时,触发这个窗口里所有数据的计算
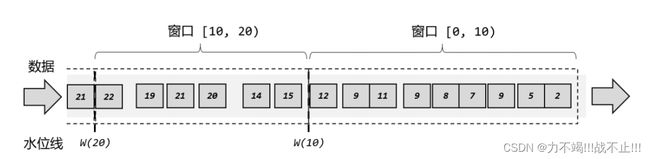
含有延迟数据的数据处理
如下图所示,显示情况中一定会出现因为网络问题数据迟到的问题,下面定义了一个延迟时间为2s的窗口,这样 0~10 秒的窗口会在时间戳为 12 秒的数据到来之后,才真正关闭计算输出结果,这样就可以正常包含迟到的 9 秒数据了。但是这样一来,0~10 秒的窗口不光包含了迟到的 9 秒数据,连 11 秒和 12 秒的数据也包含进去了。我们为了正确处理迟到数据,结果把早到的数据划分到了错误的窗口——最终结果都是错误的。
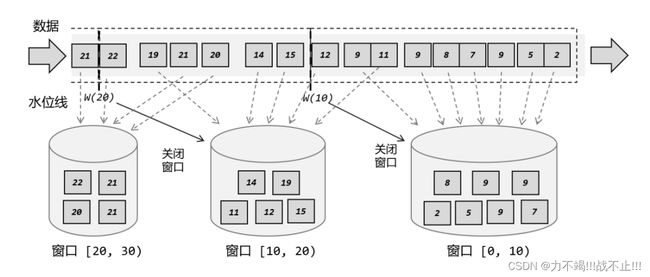
Flink存储桶概念
在 Flink 中,窗口其实并不是一个“框”,流进来的数据被框住了就只能进这一个窗口。相比之下,我们应该把窗口理解成一个“桶”,如下图所示。在 Flink 中,窗口可以把流切割成有限大小的多个“存储桶”(bucket);每个数据都会分发到对应的桶中,当到达窗口结束时间时,就对每个桶中收集的数据进行计算处理。
窗口类型
滚动窗口
滚动窗口有固定的大小,是一种对数据进行“均匀切片”的划分方式。窗口之间没有重叠,也不会有间隔,是“首尾相接”的状态。如果我们把多个窗口的创建,看作一个窗口的运动,那就好像它在不停地向前“翻滚”一样。
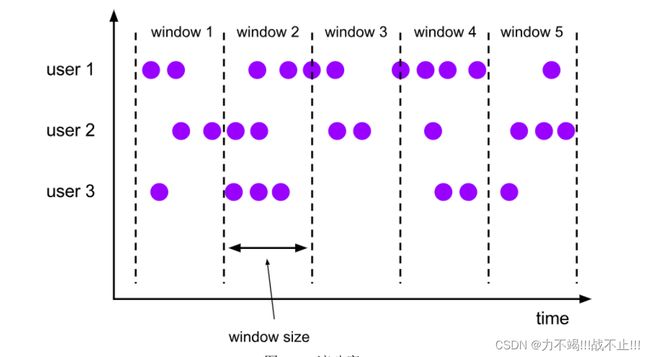
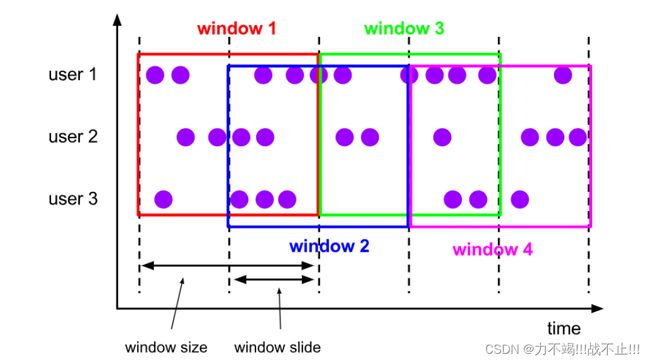
滑动窗口
与滚动窗口类似,滑动窗口的大小也是固定的。区别在于,窗口之间并不是首尾相接的,而是可以“错开”一定的位置。如果看作一个窗口的运动,那么就像是向前小步“滑动”一样。
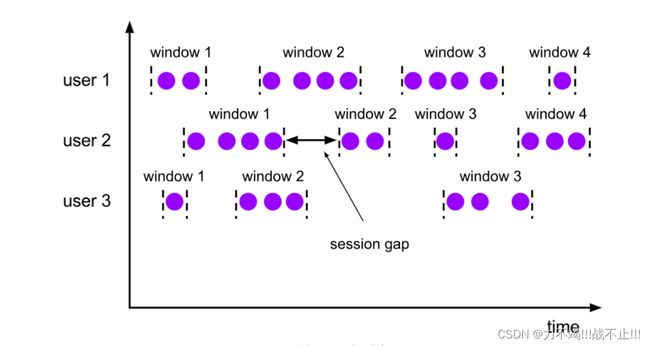
会话窗口
会话窗口顾名思义,是基于“会话”(session)来来对数据进行分组的。这里的会话类似Web 应用中 session 的概念,不过并不表示两端的通讯过程,而是借用会话超时失效的机制来描述窗口。简单来说,就是数据来了之后就开启一个会话窗口,如果接下来还有数据陆续到来,那么就一直保持会话;如果一段时间一直没收到数据,那就认为会话超时失效,窗口自动关闭。
全局窗口
这种窗口全局有效,会把相同 key 的所有数据都分配到同一个窗口中;说直白一点,就跟没分窗口一样。无界流的数据永无止尽,所以这种窗口也没有结束的时候,默认是不会做触发计算的。

flink状态管理
状态的存储和管理是由 Flink Runtime 负责的,Flink 提供了多种状态后端来存储和管理状态数据,例如内存状态后端、文件系统状态后端、RocksDB 状态后端等等。Flink 还提供了可插拔的状态后端接口,可以自定义状态后端来满足特定的需求。Flink 还提供了高效的状态快照机制,可以在应用程序故障时对状态进行快速恢复,以保证应用程序的正确性和数据的完整性。
检查点(Checkpoint)
有状态流应用中的检查点(checkpoint),其实就是所有任务的状态在某个时间点的一个快照(一份拷贝)。简单来讲,就是一次“存盘”,让我们之前处理数据的进度不要丢掉。在一个流应用程序运行时,Flink 会定期保存检查点,在检查点中会记录每个算子的 id 和状态;如果发生故障,Flink 就会用最近一次成功保存的检查点来恢复应用的状态,重新启动处理流程,就如同“读档”一样。
检查点恢复数据过程
这里 Source 任务已经处理完毕,所以偏移量为 5;Map 任务也处理完成了。而 Sum 任务在处理中发生了故障,此时状态并未保存。
1、在算子计算时发生故障
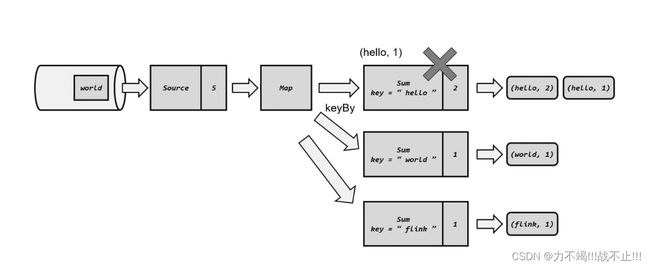
2、应用重启
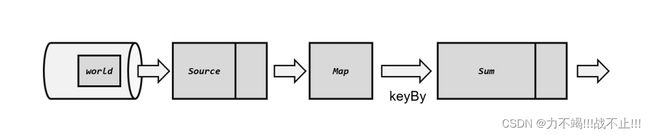
3、读取检查点,重置状态
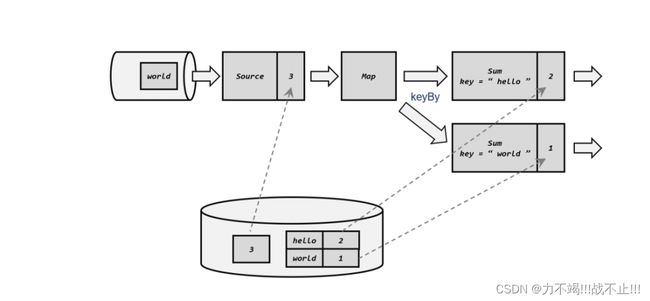
4、读取检查点,重制偏移量
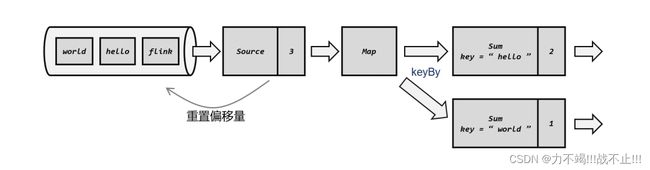
5、继续处理数据
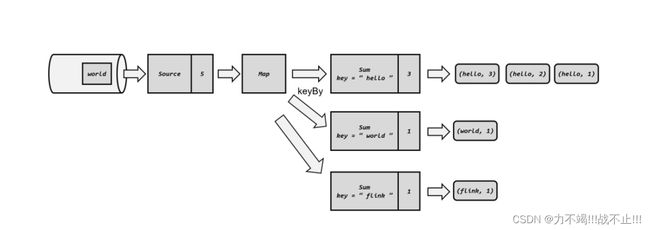
下载安装
flink下载页:点击跳转
flink官方文档地址:点击跳转
安装后启动bin目录下./start-cluster.sh文件(⚠️:需要配置java环境变量),访问地址:localhost:8081
入门Demo示例
pom配置
8
8
UTF-8
1.13.0
1.8
2.12
1.7.30
org.apache.flink
flink-java
${flink.version}
org.apache.flink
flink-streaming-java_${scala.binary.version}
${flink.version}
org.apache.flink
flink-clients_${scala.binary.version}
${flink.version}
org.slf4j
slf4j-api
${slf4j.version}
org.slf4j
slf4j-log4j12
${slf4j.version}
org.apache.logging.log4j
log4j-to-slf4j
2.14.0
org.projectlombok
lombok
1.18.22
compile
com.alibaba
fastjson
1.2.58
org.apache.flink
flink-table-api-java-bridge_${scala.binary.version}
${flink.version}
org.apache.flink
flink-table-planner-blink_${scala.binary.version}
${flink.version}
org.apache.flink
flink-streaming-scala_${scala.binary.version}
${flink.version}
org.apache.flink
flink-table-common
${flink.version}
org.apache.maven.plugins
maven-assembly-plugin
3.0.0
jar-with-dependencies
make-assembly
package
single
net.alchim31.maven
scala-maven-plugin
3.2.2
scala-compile-first
process-resources
add-source
compile
scala-test-compile
process-test-resources
testCompile
org.apache.maven.plugins
maven-compiler-plugin
1.8
1.8
Demo代码
import com.alibaba.fastjson.JSON;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class FlinkExampleWordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment executionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
executionEnvironment.setParallelism(4);
//使用nc -lk 9999,进行数据流输入,如hello word hello flink
DataStream<String> dataStream = executionEnvironment.socketTextStream("localhost", 9999);
dataStream
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String data, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] split = data.split("\\s");
System.out.println(JSON.toJSON(split));
for (String word : split) {
collector.collect(Tuple2.of(word, 1));
}
}
}
)
.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return stringIntegerTuple2.f0;
}
})
.sum(1)
.print();
executionEnvironment.execute();
}
}
打包到集群
使用maven对项目package打包,将打好的jar包上传到集群中,可以通过界面上传或者拷贝到机器上直接用指令进行运行
界面上传
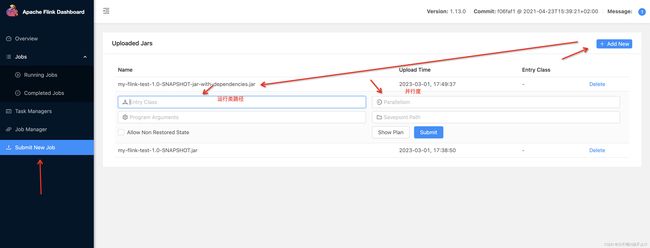
点击Submit之后可以取相应位置看输出日志
日志查看

流运行时执行环境
每个 Flink 应用程序都需要一个执行环境
env。流媒体应用程序需要使用StreamExecutionEnvironment.应用程序中进行的DataStream API调用构建了一个附加到StreamExecutionEnvironment. 当env.execute()被调用时,这个图被打包并发送到JobManager,JobManager将作业并行化并将它的切片分配给任务管理器以供执行。您的作业的每个并行切片都将在 任务槽中执行。

任务槽Slot
每个worker(TaskManager)都是一个
JVM进程,可以在不同的线程中执行一个或多个子任务。为了控制TaskManager接受多少任务,它有所谓的任务槽(至少一个)。每个TaskManager有一个插槽意味着每个任务组都在单独的 JVM 中运行(例如,可以在单独的容器中启动)。拥有多个槽意味着更多的子任务共享同一个 JVM。同一个 JVM 中的任务共享TCP 连接(通过多路复用)和心跳消息。它们还可以共享数据集和数据结构,从而减少每个任务的开销。
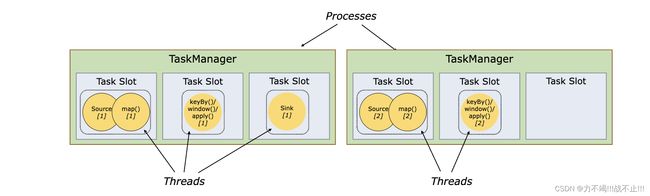
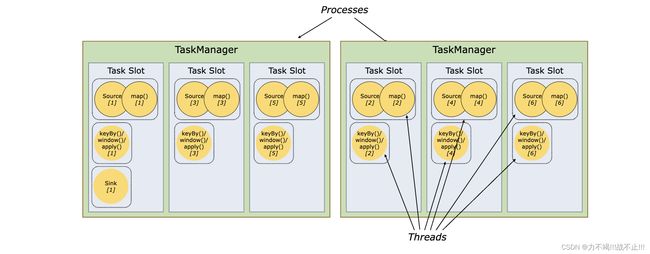
扩展Demo
时间窗口Demo
import lombok.*;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import java.util.ArrayList;
import java.util.Calendar;
import java.util.Comparator;
import java.util.Random;
import java.sql.Timestamp;
public class FlinkWindowTopNDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setAutoWatermarkInterval(100);
SingleOutputStreamOperator<UserEvent> eventStream = env.addSource(new CustomSouce())
.assignTimestampsAndWatermarks(WatermarkStrategy.<UserEvent>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<UserEvent>() {
@Override
public long extractTimestamp(UserEvent element, long
recordTimestamp) {
return element.getTimestemp();
}
}));
//按照访问url分区,求出每个 url 的访问量
SingleOutputStreamOperator<UserViewCount> urlCountStream = eventStream
.keyBy(data -> data.getUrl())
//滚动窗口:5s间隔
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
//自定义聚合函数
.aggregate(new NewUrlViewCountAgg(), new NewUrlViewCountResult());
// 对结果中同一个窗口的统计数据,进行排序处理
SingleOutputStreamOperator<String> result = urlCountStream
.keyBy(data -> data.windowEnd)
.process(new TopN(3));
result.print("result");
env.execute();
}
//自定义增量聚合
public static class NewUrlViewCountAgg implements AggregateFunction<UserEvent, Long, Long> {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(UserEvent value, Long accumulator) {
return accumulator + 1L;
}
@Override
public Long getResult(Long accumulator) {
return accumulator;
}
@Override
public Long merge(Long a, Long b) {
return null;
}
}
//自定义全窗口函数,只需要包装窗口信息
public static class NewUrlViewCountResult extends ProcessWindowFunction<Long, UserViewCount, String, TimeWindow> {
@Override
public void process(String url, ProcessWindowFunction<Long, UserViewCount, String, TimeWindow>.Context context, Iterable<Long> elements, Collector<UserViewCount> out) throws Exception {
// 结合窗口信息,包装输出内容
long currentWindowStartTimeStemp = context.window().getStart();
long currentWindowEndTimeStemp = context.window().getEnd();
out.collect(new UserViewCount(url, elements.iterator().next(), currentWindowStartTimeStemp, currentWindowEndTimeStemp));
}
}
// 自定义处理函数,排序取 top n
public static class TopN extends KeyedProcessFunction<Long, UserViewCount, String> {
// 将 n 作为属性
private Integer n;
// 定义一个列表状态
private ListState<UserViewCount> urlViewCountListState;
public TopN(Integer n) {
this.n = n;
}
public TopN() {
super();
}
@Override
public void open(Configuration parameters) throws Exception {
// 从环境中获取列表状态句柄
urlViewCountListState = getRuntimeContext().getListState(
new ListStateDescriptor<UserViewCount>("url-view-count-list",
Types.POJO(UserViewCount.class)));
}
@Override
public void processElement(UserViewCount value, KeyedProcessFunction<Long, UserViewCount, String>.Context ctx, Collector<String> out) throws Exception {
// 将 count 数据添加到列表状态中,保存起来
urlViewCountListState.add(value);
// 注册 window end + 1ms 后的定时器,等待所有数据到齐开始排序
ctx.timerService().registerEventTimeTimer(ctx.getCurrentKey() + 1);
}
@Override
public void onTimer(long timestamp, KeyedProcessFunction<Long, UserViewCount, String>.OnTimerContext ctx, Collector<String> out) throws Exception {
// 将数据从列表状态变量中取出,放入 ArrayList,方便排序
ArrayList<UserViewCount> urlViewCountArrayList = new ArrayList<>();
for (UserViewCount urlViewCount : urlViewCountListState.get()) {
urlViewCountArrayList.add(urlViewCount);
}
// 清空状态,释放资源
urlViewCountListState.clear();
// 排序
urlViewCountArrayList.sort(new Comparator<UserViewCount>() {
@Override
public int compare(UserViewCount o1, UserViewCount o2) {
return o2.count.intValue() - o1.count.intValue();
}
});
// 提取前n名(由函数入口提供),构建输出结果
StringBuilder result = new StringBuilder();
result.append("========================================\n");
result.append("窗口结束时间:" + new Timestamp(timestamp - 1) + "\n");
for (int i = 0; i < this.n; i++) {
UserViewCount userViewCount = urlViewCountArrayList.get(i);
if (null == userViewCount) {
break;
}
result.append("处理数据所在窗口:" + new Timestamp(userViewCount.getWindowStart()) + "~" + new Timestamp(userViewCount.getWindowEnd()));
UserViewCount needUserView = userViewCount;
String info = " No." + (i + 1) + " "
+ "url:" + userViewCount.url + " "
+ "浏览量:" + userViewCount.count + "\n";
result.append(info);
}
result.append("========================================\n");
out.collect(result.toString());
}
}
@Data
@NoArgsConstructor
@ToString
@AllArgsConstructor
public static class UserEvent {
private String userName;
private String url;
private Long timestemp;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public static class UserViewCount {
public String url;
public Long count;
public Long windowStart;
public Long windowEnd;
@Override
public String toString() {
return "UserViewCount{" +
"url='" + url + '\'' +
", count=" + count +
", windowStart=" + new Timestamp(windowStart) +
", windowEnd=" + new Timestamp(windowEnd) +
'}';
}
}
public static class CustomSouce implements SourceFunction<UserEvent> {
// 声明一个布尔变量,作为控制数据生成的标识位
private Boolean running = true;
@Override
public void run(SourceContext<UserEvent> ctx) throws Exception {
Random random = new Random(); // 在指定的数据集中随机选取数据
String[] users = {"Mary", "Alice", "Bob", "Cary"};
String[] urls = {"./home", "./cart", "./fav", "./prod?id=1",
"./prod?id=2"};
while (running) {
ctx.collect(new UserEvent(
users[random.nextInt(users.length)],
urls[random.nextInt(urls.length)],
Calendar .getInstance().getTimeInMillis()
));
// 隔 200 ms生成一个点击事件,方便观测
Thread.sleep(200);
}
}
@Override
public void cancel() {
running = false;
}
}
}
运行结果
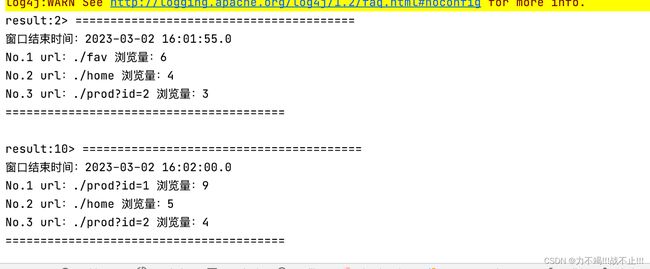
Table Api Demo
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.ToString;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class TableApiDemo {
public static void main(String[] args) throws Exception {
// 获取流执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源
SingleOutputStreamOperator<UserEvent> eventStream = env
.fromElements(
new UserEvent("Alice", "./home", 1000L),
new UserEvent("Bob", "./cart", 1000L),
new UserEvent("Alice", "./prod?id=1", 5 * 1000L),
new UserEvent("Cary", "./home", 60 * 1000L),
new UserEvent("Bob", "./prod?id=3", 90 * 1000L),
new UserEvent("Alice", "./prod?id=7", 105 * 1000L)
);
// 获取表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 将数据流转换成表
Table eventTable = tableEnv.fromDataStream(eventStream);
// 用执行 SQL 的方式提取数据
Table visitTable = tableEnv.sqlQuery("select url, userName from " + eventTable);
// 将表转换成数据流,打印输出
tableEnv.toDataStream(visitTable).print();
// 执行程序
env.execute();
}
@Data
@NoArgsConstructor
@ToString
@AllArgsConstructor
public static class UserEvent {
private String userName;
private String url;
private Long timestemp;
}
}
运行结果
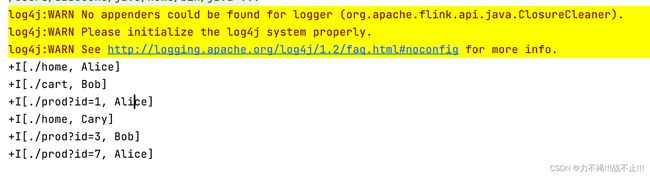
对迟到数据处理Demo
import com.alibaba.fastjson.JSON;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import org.example.entity.Event;
import java.sql.Timestamp;
import java.time.Duration;
public class LateDataProcessExampleDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取 socket 文本流
/** 样例数据
* Alice ./home 1000
* Alice ./home 2000
* Alice ./home 10000
* Alice ./home 9000
* Alice ./cart 12000
* Alice ./prod?id=100 15000
* Alice ./home 9000
* Alice ./home 8000
* Alice ./prod?id=200 70000
* Alice ./home 8000
* Alice ./prod?id=300 72000
* Alice ./home 8000
*/
SingleOutputStreamOperator<Event> stream =
env.socketTextStream("localhost", 9999)
.map(new MapFunction<String, Event>() {
@Override
public Event map(String value) throws Exception {
String[] fields = value.split("\\s");
return new Event(fields[0].trim(), fields[1].trim(),
Long.valueOf(fields[2].trim()));
}
})
// 方式一:设置 watermark 延迟时间,2 秒钟
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long
recordTimestamp) {
return element.getTimestamp();
}
}));
// 定义侧输出流标签
OutputTag<Event> outputTag = new OutputTag<Event>("late") {};
SingleOutputStreamOperator<UrlViewCount> result = stream
.keyBy(data -> data.getUrl())
//设置10s的时间窗口
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
// 方式二:允许窗口处理迟到数据,设置 1 分钟的等待时间
.allowedLateness(Time.minutes(1))
// 方式三:将最后的迟到数据输出到侧输出流
.sideOutputLateData(outputTag)
.aggregate(new UrlViewCountAgg(), new UrlViewCountResult());
result.print("result");
/**
* 输出数据
* origin data input> Event(user=Alice, url=./prod?id=300, timestamp=72000)
* origin data input> Event(user=Alice, url=./home, timestamp=8000)
* late data result> Event(user=Alice, url=./home, timestamp=8000)
*
* 我们设置窗口等待的时间为 1 分钟,所以当时间推进到 10000 + 60 * 1000 = 70000 时,窗
* 口就会真正被销毁。此前的所有迟到数据可以直接更新窗口的计算结果,而之后的迟到数据已
* 经无法整合进窗口,就只能用侧输出流来捕获了。需要注意的是,这里的“时间”依然是由水
* 位线来指示的,所以时间戳为 70000 的数据到来,并不会触发窗口的销毁;当时间戳为 72000
* 的数据到来,水位线推进到了 72000 – 2 * 1000 = 70000,此时窗口真正销毁关闭,之后再来的
* 迟到数据就会输出到侧输出流了:
*/
result.getSideOutput(outputTag).print("late data result");
// 为方便观察,可以将原始数据也输出
stream.print("origin data input");
env.execute();
}
public static class UrlViewCountAgg implements AggregateFunction<Event, Long,
Long> {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(Event value, Long accumulator) {
return accumulator + 1;
}
@Override
public Long getResult(Long accumulator) {
return accumulator;
}
@Override
public Long merge(Long a, Long b) {
return null;
}
}
public static class UrlViewCountResult extends ProcessWindowFunction<Long, UrlViewCount, String, TimeWindow> {
@Override
public void process(String url, Context context, Iterable<Long> elements,
Collector<UrlViewCount> out) throws Exception {
// 结合窗口信息,包装输出内容
Long start = context.window().getStart();
Long end = context.window().getEnd();
out.collect(new UrlViewCount(url, elements.iterator().next(), start,
end));
}
}
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public static class UrlViewCount {
public String url;
public Long count;
public Long windowStart;
public Long windowEnd;
@Override
public String toString() {
return "UrlViewCount{" +
"url='" + url + '\'' +
", count=" + count +
", windowStart=" + new Timestamp(windowStart) +
", windowEnd=" + new Timestamp(windowEnd) +
'}';
}
}
}