golang笔记16--go语言并发版爬虫
golang笔记16--go语言并发版爬虫
- 1 介绍
- 2 并发版爬虫
-
- 2.1 并发版爬虫架构
- 2.2 简单调度器
- 2.3 并发调度器
- 2.4 队列实现调度器
- 2.5 重构和总结
- 2.6 更多城市
- 2.7 更多用户与去重
- 3 注意事项
- 4 说明
1 介绍
本文继上文 golang笔记15-go 语言单任务版爬虫, 进一步了解 go 语言并发版爬虫项目,以及相应注意事项。
具体包括: 并发版爬虫架构、简单调度器、并发调度器、队列实现调度器、重构和总结、更多城市、更多用户与去重 等内容。
2 并发版爬虫
2.1 并发版爬虫架构
在 golang笔记15-go 语言单任务版爬虫 中已经通过iftop 初步得出了单任务爬虫性能低的结论,因此本节将在此基础上优化为并发版本的爬虫。
优化后的爬虫架构如下图所示:
在单任务中,很明显可以发现Fetcher 是影响效率的主要因素,因此可以考虑将Fetcher改动为并发模块;实际中Fetcher 获取数据后被Praser 消费了,因此可以考虑把Fetcher 和 Parser 封装为一个Worker 模块,将Worker 作为一个并发的模块。

为了后续优化,需要抽象出一个Scheduler,且Engine、Scheduler和Worker 直接通过chan 来实现数据传输。如下图所示:
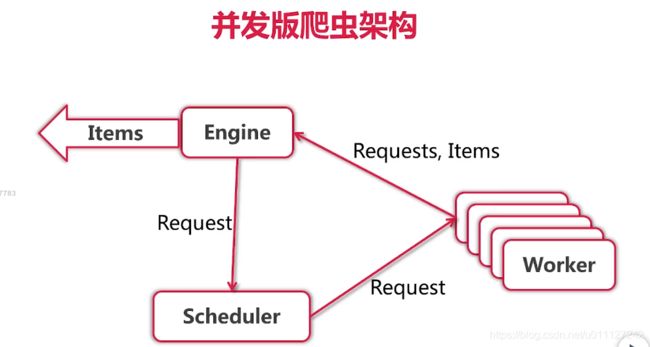
Scheduler 的一个简单实现是:Engine 获取的Request 都送到Scheduler, 然后Worker 完成任务后从Scheduler 的chan 中抢数据,如此循环的进行调度;其流程如下图所示:
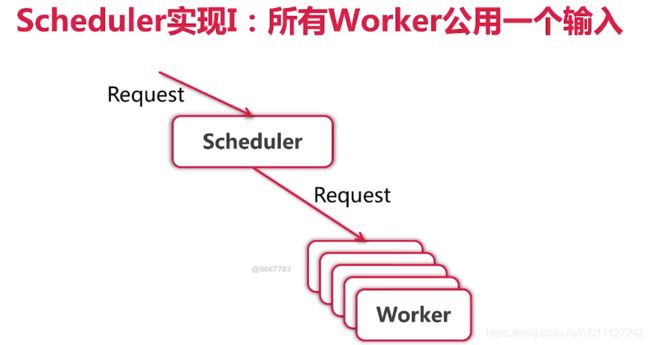
2.2 简单调度器
将第一版的Engine 更改为simple.go, 并新加一个concurrent.go 专门用来来实现并发版本Engine,同时抽象出 Worker.go 专用与接收请求并解析相关数据。
具体实现如下:
learngo/crawler$ tree -L 2
.
├── engine
│ ├── concurrent.go
│ ├── simple.go
│ ├── types.go
│ └── worker.go
├── fetcher
│ └── fetcher.go
├── mian.go
├── scheduler
│ └── simple.go
└── zhenai
└── parser
5 directories, 7 files
vim engine/concurrent.go
package engine
import "fmt"
type ConcurrentEngine struct {
Scheduler Scheduler
WorkerCount int
}
type Scheduler interface {
Submit(Request)
ConfigureMasterWorkerChan(chan Request)
}
func (e *ConcurrentEngine) Run(seeds ...Request) {
in := make(chan Request)
out := make(chan ParseResult)
e.Scheduler.ConfigureMasterWorkerChan(in)
for i := 0; i < e.WorkerCount; i++ {
createWorker(in, out)
}
for _, r := range seeds {
e.Scheduler.Submit(r)
}
for {
result := <-out
for _, item := range result.Items {
fmt.Printf("Got item: %v\n", item)
}
for _, request := range result.Requests {
e.Scheduler.Submit(request)
}
}
}
func createWorker(in chan Request, out chan ParseResult) {
go func() {
for {
request := <-in
result, err := Worker(request)
if err != nil {
continue
}
out <- result
}
}()
}
vim engine/worker.go
package engine
import (
"learngo/crawler/fetcher"
"log"
)
func Worker(r Request) (ParseResult, error) {
log.Printf("Fetching %s", r.Url)
body, err := fetcher.Fetch(r.Url)
if err != nil {
log.Printf("Fetcher: error,fetching url %s: %v", r.Url, err)
return ParseResult{}, err
}
return r.ParserFunc(body), nil
}
vim scheduler/simple.go
package scheduler
import "learngo/crawler/engine"
type SimpleScheduler struct {
workerChan chan engine.Request
}
func (s *SimpleScheduler) ConfigureMasterWorkerChan(c chan engine.Request) {
s.workerChan = c
}
func (s *SimpleScheduler) Submit(r engine.Request) {
s.workerChan <- r
}
vim main.go
package main
import (
"learngo/crawler/engine"
"learngo/crawler/scheduler"
"learngo/crawler/zhenai/parser"
)
func main() {
url := "http://www.zhenai.com/zhenghun"
//engine.SimpleEngine{}.Run(engine.Request{Url: url, ParserFunc: parser.ParseCityList})
e := engine.ConcurrentEngine{Scheduler: &scheduler.SimpleScheduler{}, WorkerCount: 10}
e.Run(engine.Request{Url: url, ParserFunc: parser.ParseCityList})
}
输出:
2021/02/27 11:05:25 Fetching http://www.zhenai.com/zhenghun
Got item: City 阿坝
......
Got item: City 资阳
Got item: City 遵义
2021/02/27 11:05:25 Fetching http://www.zhenai.com/zhenghun/anshun
2021/02/27 11:05:25 Fetching http://www.zhenai.com/zhenghun/akesu
2021/02/27 11:05:25 Fetching http://www.zhenai.com/zhenghun/aba
2021/02/27 11:05:25 Fetching http://www.zhenai.com/zhenghun/ali
2021/02/27 11:05:25 Fetching http://www.zhenai.com/zhenghun/alashanmeng
2021/02/27 11:05:25 Fetching http://www.zhenai.com/zhenghun/ankang
2021/02/27 11:05:25 Fetching http://www.zhenai.com/zhenghun/aletai
2021/02/27 11:05:25 Fetching http://www.zhenai.com/zhenghun/anhui
2021/02/27 11:05:25 Fetching http://www.zhenai.com/zhenghun/anqing
2021/02/27 11:05:25 Fetching http://www.zhenai.com/zhenghun/anshan
此时刚好获取10个城市后就会处于等待,其原因为Scheduler 通过 Scheduler.Submit 来提交数据给worker,前提是有空闲的worker 来接收数据,若worker 都是忙的装填就会导致卡死。
2.3 并发调度器
由于2.2 小节中worker 都在工作状态存在卡死的问题解,因此可以通过goroutine 来防止卡死;决卡死后,使用10个worker 发现网速能达到220KB作用,基本提高了10倍的样子。
解决卡死后,其访问效率大大提高,但是有可能触发网站的放爬虫机制,因此可以添加 rateLimiter 防止爬取太快;具体实施方法为:去掉原有city.go 中的sleep, 更改为 time.Tick 的方式。
第二版的调度结构如下图所示,其为每个request 创建一个 goroutine,然后将请求转发给 Worker处理,从而能规避卡死问题。
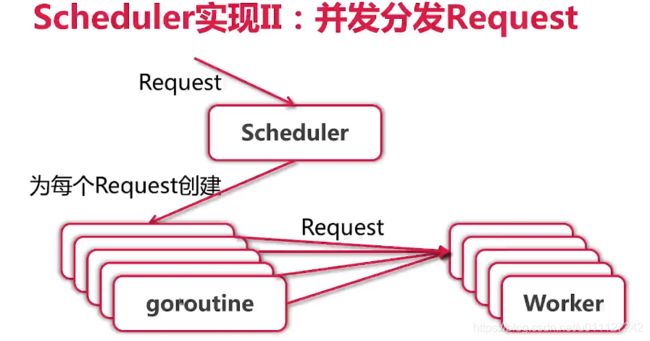
具体代码改动如下:
1) 去掉city.go 中的 sleep
time.Sleep(time.Duration(time.Millisecond * 100))
2) vim fetcher/fetcher.go
var rateLimiter = time.Tick(100 * time.Millisecond)
func Fetch(url string) ([]byte, error) {
<-rateLimiter
request, err := http.NewRequest(http.MethodGet, url, nil)
......
}
3) vim scheduler/simple.go
func (s *SimpleScheduler) Submit(r engine.Request) {
// goroutine 来submit,防止卡死
go func() {
s.workerChan <- r
}()
}
执行main.go 输出:
......
Got item 9782: 1306029314,等待那份爱,49,男士,未婚,四川资阳,172,null,3001-5000元,http://album.zhenai.com/u/1306029314, https://photo.zastatic.com/images/photo/326508/13048442696655.jpg
Got item 9783: 1068899110,良子,25,男士,未婚,四川资阳,172,null,8001-12000元,http://album.zhenai.com/u/1068899110, https://photo.zastatic.com/images/photo/267225/10688991897189073.jpg
Got item 9784: 1934996202,蓝色初恋,33,女士,未婚,四川资阳,160,中专,null,http://album.zhenai.com/u/1934996202, https://photo.zastatic.com/images/photo/483750/1934996202/487.jpg
......
此时可以正常输出,直到所有Request 解析完后才会卡住
具体代码见:具体代码见:crawler-v1
2.4 队列实现调度器
上一节中通过 goroutine 来防止Scheduler卡死,本节像对其进一步优化,通过队列的方式实现资源调度。
具体调度器结构如下所示,Scheduler 将所有request都放在request队列中,然后从 request 中拿请求给 worker 队列中的 worker 处理。
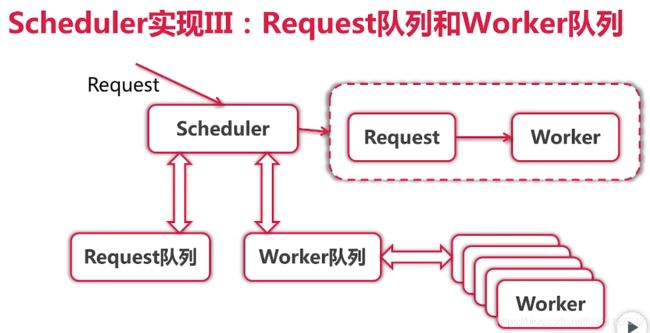
改动代码如下:
learngo/crawler$ tree -L 2
.
├── engine
│ ├── concurrent.go
│ ├── simple.go
│ ├── types.go
│ └── worker.go
├── fetcher
│ └── fetcher.go
├── mian.go
├── scheduler
│ ├── queued.go
│ └── simple.go
└── zhenai
└── parser
5 directories, 8 files
vim engine/concurrent.go
package engine
import "fmt"
type ConcurrentEngine struct {
Scheduler Scheduler
WorkerCount int
}
type Scheduler interface {
Submit(Request)
ConfigureMasterWorkerChan(chan Request)
WorkerReady(chan Request)
Run()
}
func (e *ConcurrentEngine) Run(seeds ...Request) {
out := make(chan ParseResult)
e.Scheduler.Run()
for i := 0; i < e.WorkerCount; i++ {
createWorker(out, e.Scheduler)
}
for _, r := range seeds {
e.Scheduler.Submit(r)
}
itemCount := 0
for {
result := <-out
for _, item := range result.Items {
fmt.Printf("Got item %d: %v\n", itemCount, item)
itemCount++
}
for _, request := range result.Requests {
e.Scheduler.Submit(request)
}
}
}
func createWorker(out chan ParseResult, s Scheduler) {
in := make(chan Request)
go func() {
for {
// tell scheduler worker ready
s.WorkerReady(in)
request := <-in
result, err := Worker(request)
if err != nil {
continue
}
out <- result
}
}()
}
vim scheduler/queued.go
package scheduler
import "learngo/crawler/engine"
type QueueScheduler struct {
requestChan chan engine.Request
workerChan chan chan engine.Request
}
func (s *QueueScheduler) ConfigureMasterWorkerChan(c chan engine.Request) {
s.requestChan = c
}
func (s *QueueScheduler) WorkerReady(w chan engine.Request) {
s.workerChan <- w
}
func (s *QueueScheduler) Submit(r engine.Request) {
s.requestChan <- r
}
func (s *QueueScheduler) Run() {
s.workerChan = make(chan chan engine.Request)
s.requestChan = make(chan engine.Request)
go func() {
var requestQ []engine.Request
var workerQ []chan engine.Request
for {
var activeRequest engine.Request
var activeWorker chan engine.Request
if len(requestQ) > 0 && len(workerQ) > 0 {
activeWorker = workerQ[0]
activeRequest = requestQ[0]
}
select {
case r := <-s.requestChan:
requestQ = append(requestQ, r)
case w := <-s.workerChan:
workerQ = append(workerQ, w)
case activeWorker <- activeRequest:
workerQ = workerQ[1:]
requestQ = requestQ[1:]
}
}
}()
}
vim mian.go
package main
import (
"learngo/crawler/engine"
"learngo/crawler/scheduler"
"learngo/crawler/zhenai/parser"
)
func main() {
url := "http://www.zhenai.com/zhenghun"
e := engine.ConcurrentEngine{Scheduler: &scheduler.QueueScheduler{}, WorkerCount: 10}
e.Run(engine.Request{Url: url, ParserFunc: parser.ParseCityList})
}
执行结果同上一小节
具体代码见:crawler-v2
2.5 重构和总结
重构说明:
由于Scheduler 知道worker 是共用 chan 还是每个都分配一个 chan,因此可以考虑调整代码使其同时兼容 simple.go 和queued.go。
总结:
本章节中主要使用三种方式实现并发爬虫,首先使用最普通的方式提交任务给worker(该版本存在卡死的问题) ,其次通过goroutine + 多worker 的方式实现调度,最后通过 request+worker 双队列的方式实现调度。
除此之外,进一步优化代码,使之能够同时兼容两种模式下的调度器;通过下一页的功能来获取更多request 资源,期间通过记录 url 对重复的请求进行了适当过滤。
具体代码见:crawler-v3
2.6 更多城市
上述并发爬虫只爬取了每个城市额第一页用户,但是实际中还存在下一页,因此可以通过下一页获取继续数据,直到没有下一页为止。
具体方式为:在city.go 中通过正则获取下一页对应的链接,并设置返回request的 ParserFunc 为 ParseCity, 即:继续通过ParseCity 来解析下一页的内容。
vim city.go
const (
cityRe = `]*>([^<]+)`
......
imageRe = `?.+) `
nextPageRe = `下一页`
)
unc ParseCity(contents []byte) engine.ParseResult {
// 先从网页中取出所有用户相关的html信息,然后通过特有字段list-item切割,最后再解析每一个用户的信息
re := regexp.MustCompile(`)`)
matches := re.FindAllSubmatch(contents, -1)
var listStr string
for _, m := range matches {
listStr = string(m[0])
}
users := strings.Split(listStr, "list-item")
result := engine.ParseResult{}
for i, user := range users {
if i == 0 {
} else {
userInfo := getUserInfo(user)
result.Items = append(result.Items, userInfo)
}
}
// 每解析一个页面都会确认是否存在下一页,存在则加入到其Request.Url 中可以作为新的爬取的种子
nextPageUrl := extractString(string(contents), 1, regexp.MustCompile(nextPageRe))
if nextPageUrl == "null" {
} else {
result.Requests = append(result.Requests, engine.Request{
Url: nextPageUrl,
ParserFunc: ParseCity,
})
}
// time.Sleep(time.Duration(time.Millisecond * 100))
return result
}
执行main函数输出:
......
2021/02/27 15:11:08 Fetching http://www.zhenai.com/zhenghun/xiangxi/2
Got item 16104: 1435923150,一分钟的情绪,39,女士,离异,重庆,158,大专,null,http://album.zhenai.com/u/1435923150, https://photo.zastatic.com/images/photo/358981/1435923150/555.jpg
Got item 16105: 1636254473,喜欢运动,32,男士,离异,重庆,170,null,5001-8000元,http://album.zhenai.com/u/1636254473, https://photo.zastatic.com/images/photo/409064/16362544931991331
......
Got item 16108: 1888774315,未知的未来,32,女士,未婚,重庆,167,大专,null,http://album.zhenai.com/u/1888774315, https://photo.zastatic.com/images/photo/472194/1888774315/3274.png
.....
正常情况下 470个城市每个前 20个用户,约 9400条信息,此时已经明显超过第一页总用户数据量了。
`
nextPageRe = `下一页`
)
unc ParseCity(contents []byte) engine.ParseResult {
// 先从网页中取出所有用户相关的html信息,然后通过特有字段list-item切割,最后再解析每一个用户的信息
re := regexp.MustCompile(`)`)
matches := re.FindAllSubmatch(contents, -1)
var listStr string
for _, m := range matches {
listStr = string(m[0])
}
users := strings.Split(listStr, "list-item")
result := engine.ParseResult{}
for i, user := range users {
if i == 0 {
} else {
userInfo := getUserInfo(user)
result.Items = append(result.Items, userInfo)
}
}
// 每解析一个页面都会确认是否存在下一页,存在则加入到其Request.Url 中可以作为新的爬取的种子
nextPageUrl := extractString(string(contents), 1, regexp.MustCompile(nextPageRe))
if nextPageUrl == "null" {
} else {
result.Requests = append(result.Requests, engine.Request{
Url: nextPageUrl,
ParserFunc: ParseCity,
})
}
// time.Sleep(time.Duration(time.Millisecond * 100))
return result
}
执行main函数输出:
......
2021/02/27 15:11:08 Fetching http://www.zhenai.com/zhenghun/xiangxi/2
Got item 16104: 1435923150,一分钟的情绪,39,女士,离异,重庆,158,大专,null,http://album.zhenai.com/u/1435923150, https://photo.zastatic.com/images/photo/358981/1435923150/555.jpg
Got item 16105: 1636254473,喜欢运动,32,男士,离异,重庆,170,null,5001-8000元,http://album.zhenai.com/u/1636254473, https://photo.zastatic.com/images/photo/409064/16362544931991331
......
Got item 16108: 1888774315,未知的未来,32,女士,未婚,重庆,167,大专,null,http://album.zhenai.com/u/1888774315, https://photo.zastatic.com/images/photo/472194/1888774315/3274.png
.....
正常情况下 470个城市每个前 20个用户,约 9400条信息,此时已经明显超过第一页总用户数据量了。
2.7 更多用户与去重
若通过网页上更多网页来形成目标输入数据,那么可能存在城市重复和用户重复的信息,此时有必要对一些重复的数据进行去重操作。
由于笔者只通过城市信息获取用户数据,而不是通过用户主页获取每个的数据,因此实际上只对城市信息进行过滤。
常见 URL 去重方法:
- 哈希表;
- 计算 MD5 等哈希,再存哈希表;
- 使用 bloom filter 多重哈希结构;
- 使用 Redis 的 key-value存储系统实时分布式去重;
本案例中主要实现并发爬虫,降低其它模块的复杂度,直接通过最简单的哈希表去重。具体代码实现如下所示:
vim engine/concurrent.go
......
func (e *ConcurrentEngine) Run(seeds ...Request) {
out := make(chan ParseResult)
e.Scheduler.Run()
for i := 0; i < e.WorkerCount; i++ {
createWorker(e.Scheduler.WorkerChan(), out, e.Scheduler)
}
for _, r := range seeds {
if isDuplicate(r.Url) {
fmt.Printf("Duplicate request: %s\n", r.Url)
continue
}
e.Scheduler.Submit(r)
}
itemCount := 0
for {
result := <-out
for _, item := range result.Items {
fmt.Printf("Got item %d: %v\n", itemCount, item)
itemCount++
}
for _, request := range result.Requests {
if isDuplicate(request.Url) {
fmt.Printf("Duplicate request: %s\n", request.Url)
continue
}
e.Scheduler.Submit(request)
}
}
}
var visitedUrls = make(map[string]bool)
func isDuplicate(url string) bool {
if visitedUrls[url] {
return true
}
visitedUrls[url] = true
return false
}
注:此处只填写改动部分
具体代码见:crawler-v4
3 注意事项
- 本章节中的案例已经上传到 csdn go语言单并发版爬虫–crawler-v1-v4, 欢迎有需要的读者下载。
- 本案例中通过三种方式实现并发版本的爬虫,但是最终版本暂未实现保存现有爬取内容的功能,因此重启后需要全部重新从头爬取,该部分内容会在下一章节进行完善。
4 说明
- 软件环境
go版本:go1.15.8
操作系统:Ubuntu 20.04 Desktop
Idea:2020.01.04 - 参考文档
由浅入深掌握Go语言 --慕课网