机器学习实战_Kaggle泰坦尼克号(1探索及特征工程)
Titanic 作为经典的入门二分类Kaggle比赛,最近抽时间对这个比赛重新再做了一遍数量。
一、 数据探索
思维导图
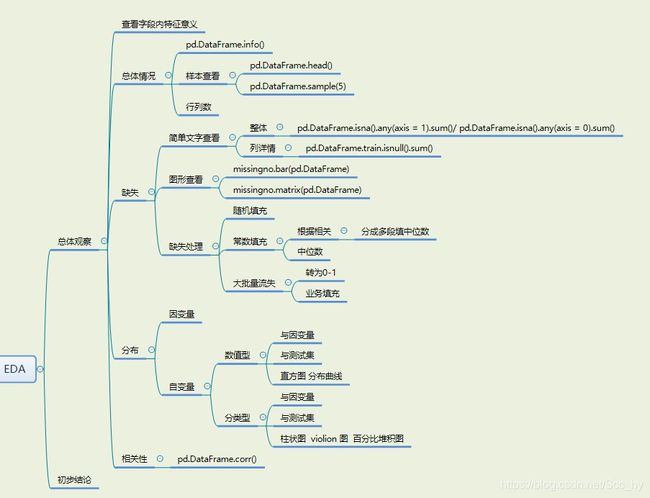
0- 总体情况 & 字段特征意义
print("train {}行 {}列".format(train.shape[0], train.shape[1]))
print("test {}行 {}列".format(test.shape[0], test.shape[1]))
df_all.info()
"""
PassengerId 乘客ID 唯一编码
Survived 是否生存 1/0 是 否
Pclass 乘客等级 1/2/3 upper class/ middle class / lower class
Name 乘客名字
Sex 性别 male/female
Age 年龄
SibSp 乘客的兄弟姐妹和配偶的总数
Parch 乘客父母和孩子的总数
Ticket 乘客的票证号码
Fare 乘客票价
Cabin 乘客的机舱号
Embarked 登船的港口
### 可生成家庭大小
SibSp 乘客的兄弟姐妹和配偶的总数
Parch 乘客父母和孩子的总数
### 和客户等级相关的因素
Pclass Ticket Fare Cabin Embarked
"""
1- 缺失
print('训练集缺失 {}行, {}列\n'.format(train.isna().any(axis=1).sum(), train.isna().any(axis=0).sum()),
'测试集缺失 {}行, {}列\n'.format(test.isna().any(axis=1).sum(),test.isna().any(axis=0).sum()))
print("训练集:\n",train.isna().sum(),'\n=============\n', "\n测试集:\n",test.isna().sum())
"""
训练集缺失 708行, 3列
测试集缺失 331行, 3列
训练集:
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
=============
测试集:
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 86
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 327
Embarked 0
"""
# 图像查看
msno.bar(train, figsize=(8, 6), fontsize=12, color = 'steelblue')
plt.title('train data set')
msno.bar(test, figsize=(8, 6), fontsize=12, color = 'steelblue')
plt.title('test data set')
plt.show()

- 1_1 缺失处理
### 2.3.1 Age
"""
根据字段与Age的相关性做,细分中位数填充
"""
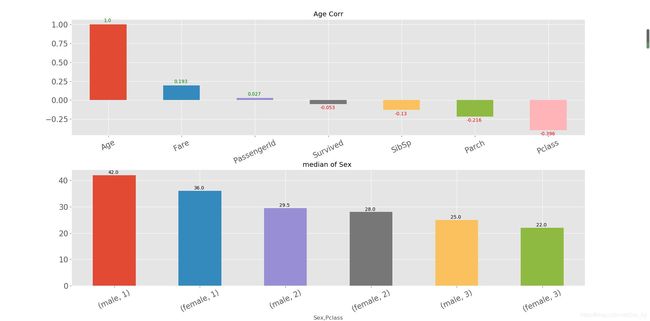
age_corr = df_all.corr(method = 'spearman').loc[:, 'Age'].sort_values(kind="quicksort", ascending=False)
plt.subplot(211)
age_corr.plot(kind = 'bar', title = 'Age Corr', rot = 25
, label = True)
for x, y, tex in zip(range(len(age_corr.index)), age_corr,age_corr):
t = plt.text(x - 0.01, y - 0.05 if y < 0 else y + 0.05, round(tex, 3)
,ha = 'center', va = 'center'
, fontdict = {'color' : 'red' if y < 0 else 'green', 'size': 10})
# plt.show()
"""
Pclass -0.396相关性最高 以这个为分类 + 性别 进行细分 填
"""
plt.subplot(212)
age_median = df_all.groupby(by = ['Sex', 'Pclass']).agg('median').Age.sort_values(kind="quicksort", ascending=False)
age_median.plot(kind = 'bar', rot = 25, title = 'median of Sex ')
for x, y, tex in zip(range(len(age_median.index)), age_median,age_median):
t = plt.text(x - 0.01, y + 1, round(tex, 2)
,ha = 'center', va = 'center')
plt.show()
#### 2.3.1.2 Age 填补缺失 (goupy fillna)
df_all['Age'] = df_all.groupby(by = ['Sex', 'Pclass']).Age.apply(lambda x: x.fillna(x.median()))
### 2.3.2 Fare & Embarked
### == Embarked ==
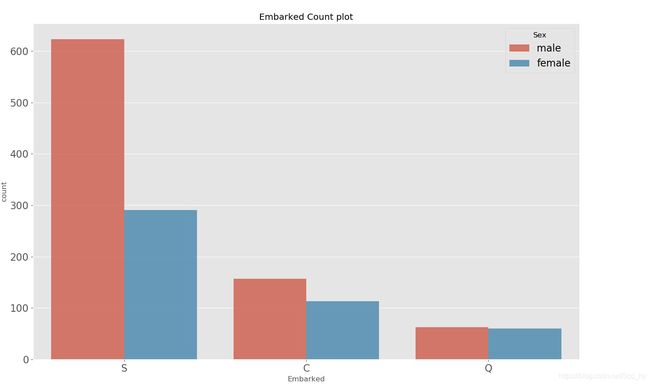
sns.countplot(x='Embarked', hue= 'Sex', data = df_all, alpha = 0.8)
plt.title('Embarked Count plot')
plt.show()
"""
Embarked 缺失两个
不论在male还是female中 S 均占比最高 所以用 S 填补
"""
df_all['Embarked'].fillna('S', inplace = True)
### == Fare ==
# Fare 缺失一个
df_all.loc[df_all.Fare.isna(), :] # 3701
"""
方法一:细类中位数
Fare_fill = df_all.groupby(['Pclass', 'Parch', 'SibSp', 'Sex']).Fare.median()[3][0][0]['male']
df_all['Fare'].fillna(Fare_fill, inplace=True)
方法二:联票的可能
>>> df_all.loc[df_all.Ticket.apply(lambda x:x[:4]) == '3701', ['Ticket', 'Fare']].Fare.value_counts()
20.2125 3
Name: Fare, dtype: int64
>>> df_all.loc[df_all.Ticket.apply(lambda x:x[:4]) == '3701', :]
Age Cabin Embarked Fare ... Sex SibSp Survived Ticket
254 41.0 NaN S 20.2125 ... female 0 0.0 370129
424 18.0 NaN S 20.2125 ... male 1 0.0 370129
1043 60.5 NaN S NaN ... male 0 NaN 3701
1175 2.0 NaN S 20.2125 ... female 1 NaN 370129
"""
# 很有可能 Ticket 记录错误 查看数据 为2岁的婴儿 应该是一家人
df_all.loc[df_all.Ticket.apply(lambda x:x[:4]) == '3701', ['Ticket', 'Fare']].Fare.value_counts()
df_all.loc[df_all.Ticket.apply(lambda x:x[:4]) == '3701', :]
## 修正
df_all.loc[df_all.Fare.isna(), 'Ticket'] = '370129'
df_all.loc[df_all.Fare.isna(), 'Fare'] = 20.2125
2- 分布
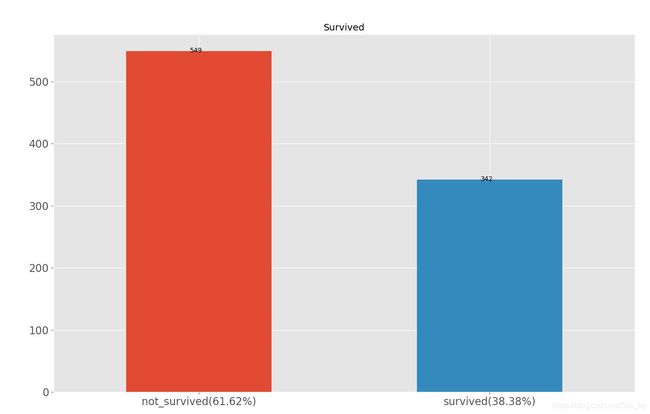
## -------------------- 查看因变量 --------------------
Sur_dt = df_all.Survived.value_counts()
not_survived_per = Sur_dt[0] / sum(Sur_dt)* 100
survived_per = Sur_dt[1] / sum(Sur_dt)* 100
Sur_dt.plot(kind='bar', label=True, title = 'Survived')
for x, y, tex in zip(Sur_dt.index , Sur_dt, Sur_dt):
t = plt.text(x - 0.01, y + 1, round(tex, 2)
,ha = 'center', va = 'center')
plt.xticks((0,1), ['not_survived({:.2f}%)'.format(not_survived_per), 'survived({:.2f}%)'.format(survived_per)]
,rotation = 0)
plt.show()
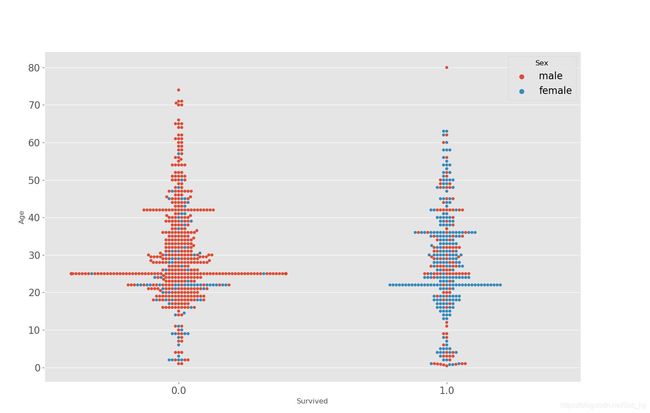
年龄在15以下的人群的存活率更高,在25-30之间存活率低, 可能原因是带孩子的家庭买的票价都较贵,所在的位置比较好逃生,
可以将 年龄的分段倒序 和 等级 相结合 用除法
年龄越小父母保护的越多 再加上 等级的因素 比如 3岁 1等级的 属于 10 / 1 = 10 该值越高理论生存概率越高
60岁 3等级 属于 1 / 3
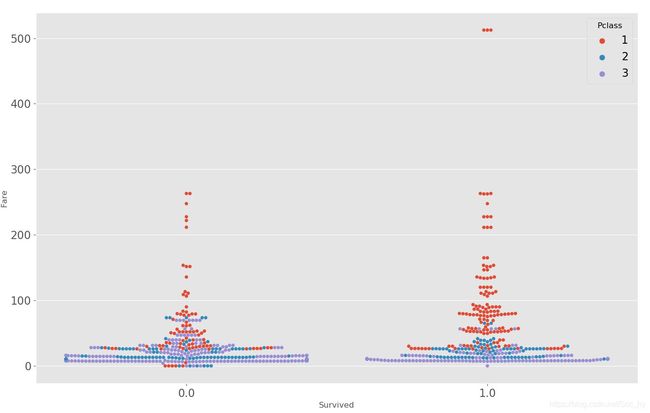
票价高的人的生存率高
画图函数参考: advanced-feature-engineering-tutorial-with-titanic.

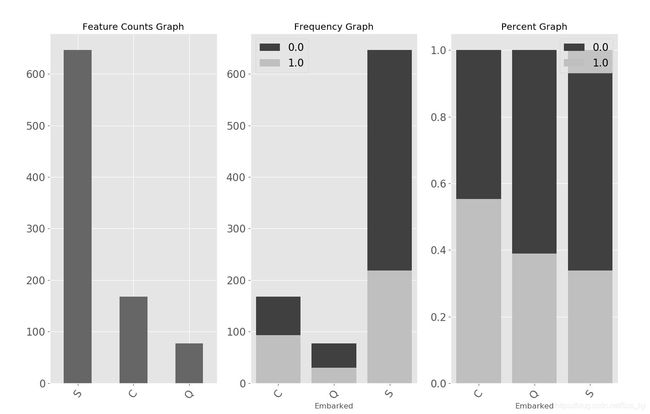
对分类变量进行遍历,用百分比堆积图
## 2- swarmplot 看票价 乘客等级与生还率
sns.swarmplot(x="Survived", y="Fare", hue="Pclass",data=df_all[ ~df_all.Survived.isna()])
plt.show()
# Age & Sex
sns.swarmplot(x="Survived", y="Age", hue="Sex",data=df_all)
plt.show()
## 女性生还率较高