弱监督实例分割 Box2Mask: Box-supervised Instance Segmentation via Level-set Evolution 论文笔记
弱监督实例分割 Box2Mask: Box-supervised Instance Segmentation via Level-set Evolution 论文笔记
- 一、Abstract
- 二、引言
- 三、相关工作
-
- 3.1 全监督的实例分割
- 3.2 基于 Box 的实例分割
- 3.3 基于层级的分割
- 四、提出的方法
-
- 4.1 模型总览
- 4.2 实例感知解码器 IAD
-
- 基于 CNN 的 IAD
- 基于 Transformer 的 IAD
- 4.2 Box 层级匹配赋值
- 4.4 层级进化
-
- 4.4.1 层级模型
- 4.4.2 在 Bounding Box 内的层级进化
-
- 层级进化
- 输入的数据格式
- 层级初始化
- 4.4.3 局部一致性模块
- 4.5 训练损失和推理
-
- 损失函数
- 推理
- 五、实验
-
- 5.1 数据集
- 5.2 实施细节
- 5.3 主要结果
-
- 5.3.1 一般场景下的实例分割
-
- Pascal VOC 上的结果
- COCO 上的结果
- 5.3.2 俯拍图像上的实例分割
-
- iSAID 上的结果
- DOTA-v1.0 上的结果
- 5.3.3 医学图像上的实例分割
- 5.3.4 字符实例分割
- 5.4 基于变分的深度实例分割
- 5.5 推理速度
- 5.6 消融实验
-
- 层级能量
- 局部一致性模块
- 训练计划
- 匹配损失的平衡权重
- MSDeformAtten 层的数量
- 六、结论
写在前面
这同样是一篇弱监督实例分割论文,出自上一篇博文(弱监督实例分割 Box-supervised Instance Segmentation with Level Set Evolution 论文笔记)原班人马再加一位作者,核心思想都差不多,利用能量函数来执行弱监督。大部分相同的东西,论文也提到是将会议转期刊了。
- 论文地址:Box2Mask: Box-supervised Instance Segmentation via Level-set Evolution
- 代码地址:https://github.com/LiWentomng/boxlevelset
- 暂未收录,不知道投的哪个顶刊
- 2023年每周一篇博文,欢迎关注,长年稳定更新,目前还差 6 篇未补~
一、Abstract
本文提出一种 single-shot 的基于 box 监督的实例分割方法 Box2Mask,致力于整合传统的能量函数模型以及深度神经网络。具体来说,输入图像及其深度特征用来隐式地进化层级曲线,一个基于像素相似性动态卷积核的局部一致性模块用于挖掘局部上下文和空间关联。两种类型的单阶段框架:基于 CNN 和 Transformer,用来增强基于 box 的弱监督实例分割下的层级进化,其中每一个框架都由三个部件组成:实例感知解码器、box 级别的匹配赋值、层级进化。通过最小化可微分的能量函数,每个实例的层级在其对应的 box 标注框内被迭代地优化,实验结果很牛皮。
二、引言
第一段实例分割的目的,应用,之前方法对于标注的依赖。
第二段介绍现有的基于 Box 的方法,基于伪标签的以及颜色相似度的,即 BBTP 和 Boxinst。本文指出这两种方法过于简化了一个假设:像素或者颜色对被强制共享相同的颜色,于是来自相似形状目标和背景的噪声上下文无可避免地会影响训练,使得性能不太好。
本文提出两种类型的单阶段框架来执行层级进化,一个基于 CNN 的框架和一个基于 Transformer 的框架。此外,每一个框架由另外两个部件构成:实例感知解码器 instance-aware decoder(IAD)和 box 级别的匹配赋值。IAD 模块学习嵌入每个实例的特性,从而动态生成全实例感知的 mask 来作为基于输入目标实例的层级预测。基于 box 级别的匹配赋值旨在 GT bounding box 的引导下学习赋值高质量的 mask 来作为正样本。通过最小化可微分的层级能量函数,每个实例的层级在其对应的 box 标注框内被迭代地优化。
相比于之前的会议版本,此文章将基于 CNN 的框架拓展到基于 Transformer 的框架上。具体来说,使用 Transformer 解码器来嵌入每个实例的特征用于动态核的学习,引入一个 box 级别的双匹配计划用于标签赋值。此外,为了避免基于区域的层级进化出现强烈的不一致性问题,提出了一种基于相似动态卷积核函数的局部一致性模块,而这进一步挖掘了邻居节点的像素相似性和空间关系。
实验结果很牛皮。此外还多加了一个场景文本图像数据集。示例图如下:

三、相关工作
3.1 全监督的实例分割
三大类:Mask R-CNN 家族、ROI-free 框架、Transformer 框架。由于标注昂贵而限制了实际的部署,于是弱监督实例分割方法崛起。
3.2 基于 Box 的实例分割
讲一下最近的方法,首先介绍了 BBTP 和 Boxinst。DiscoBox 引入内部图像对和外部图像对来建立一个自嵌入的教师网络,其中由教师网络生成的伪标签用来训练学生网络从而减小不确定性。这些方法过于简化了一个假设:像素或者颜色对被强制共享相同的颜色,因此来自相似形状目标和背景的噪声上下文无可避免地会影响训练,使得性能不太好。
除了这两个外,最近的 BBAM、BoxCaseg 关注于多训练阶段或额外的显著性数据。而本文提出的基于层级方法以一种端到端的隐含方式通过优化 box 区域内的能量函数来迭代地分割出实例边界。
3.3 基于层级的分割
主要划分为两类:基于区域和边缘的方法。核心理念是在一个高维度通过一个能量函数来展现隐藏的曲线,而这能够用梯度下降来优化。接下来是一些举例并指出他们的不足:全监督方式训练网络去预测不同的子区域并得到目标的边界,而本文提出的是 box 级别的监督。
四、提出的方法
4.1 模型总览
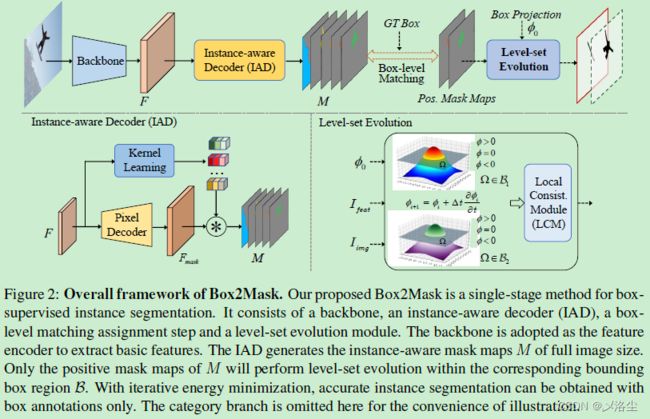
4.2 实例感知解码器 IAD
IAD 旨在学习嵌入每个实例的独特特征来产生实例感知 mask。主要由一个逐像素解码器和一个动态卷积核学习网络组成,作用是将实例感知 mask 解耦为生成统一的 mask 特征以及相应的生成统一动态卷积核。
基于 CNN 的 IAD
采用 SOLOv2 中的动态卷积方法。从 backbone 中提取基础的特征 F F F,动态卷积核学习模块首先利用一些卷积层来嵌入每个实例的特征并生成特定实例动态卷积核 K i , j K_{i,j} Ki,j。同时,一个并行分支,逐像素的解码器采用 FPN 结构来提取多尺度的特征:基于特征聚合的方法将特征图变化为同一分辨率来得到统一的特征表示 F m a s k F_{mask} Fmask。之后可学习的动态卷积核 K i , j K_{i,j} Ki,j 在统一的 mask 特征图 F m a s k F_{mask} Fmask 上执行动态卷积操作来生成每个实例的 mask M M M,即 M i , j = K i , j ∗ F m a s k M_{i,j}=K_{i,j}*F_{mask} Mi,j=Ki,j∗Fmask,其中 M i , j M_{i,j} Mi,j 是中心在位置 ( i , j ) (i,j) (i,j) 处的仅包含一个实例原图大小的 mask。
基于 Transformer 的 IAD
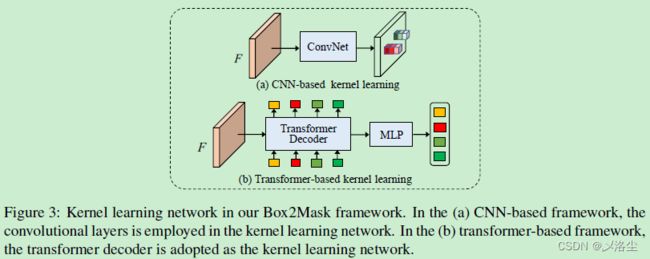
在 MaskFormer 中,每个实例的分割图可以由 D 维特征向量来表示,而这能够通过一个 Transformer 解码器输出:采用 N N N 个可学习的,使用集合预测机制的逐个实例序列。图 3 中,采用一个 Transformer 解码器来计算 N N N 个实例感知的动态卷积核向量 K ∈ R N × C K\in\mathbb{R}^{N\times C} K∈RN×C。同时,一个像素解码器用于逐渐从 backbone 中的输出来上采样低分辨的特征,从而得到高分辨率的 mask 特征 F m a s k ∈ R C × H × W F_{mask}\in\mathbb{R}^{C\times H\times W} Fmask∈RC×H×W。特别的,采用多尺度可变形注意力 Transformer 来提取长范围上下文特征表示。之后可学习的实例感知动态卷积核与目标 query 执行点积操作来得到最后的实例感知 mask,即 M N × H × W = K N × C ⋅ F m a s k C × H × W M^{N\times H\times W}=K^{N\times C}\cdot{F_{mask}^{C\times H\times W}} MN×H×W=KN×C⋅FmaskC×H×W,其中 N = 100 N=100 N=100,目标 query 为集合了可学习的位置编码的零向量。
4.2 Box 层级匹配赋值
对于 CNN 和 Transformer 采用两种不同的标签赋值方式。
基于 CNN 的框架,任意位置 ( i , j ) (i,j) (i,j) 处都会产生稠密的实例感知候选图,采用基于 box 的中心采样计划来确保每个可能的实例感知图仅包含一个目标实例,其中心位于 ( i , j ) (i,j) (i,j)。如果相应的 ( i , j ) (i,j) (i,j) 落在任意预设的 GT box 的中心区域,那么这一 mask 即被认定为是一个正样本,反之被视为负样本。中心区域的面积控制在某个尺度范围内来确保每个 GT box 平均有 3 个正样本与其对应。
对于 Transformer 的框架,采用基于二分图匹配赋值计划的匈牙利算法,这能匹配上 GT box 与 IAD 生成的实例感知 mask。匹配损失由类别损失和空间位置差异损失 C i n s t \mathcal{C}_{inst} Cinst 构成(计算 GT box 和每一类别的 mask 预测)。对于 C i n s t \mathcal{C}_{inst} Cinst,利用在 x 和 y 轴上的投影坐标 P \mathcal{P} P 来计算预测的实例感知图 m p m^p mp 和 GT mask m b m^b mb 上的空间差异,具体则是采用 1-D dice 系数,即 C i n s t = P d i c e ( m x p , m x b ) + P d i c e ( m y p , m y b ) {\mathcal{C}}_{i n s t}={\mathcal{P}}_{d i c e}(m_{x}^{p},m_{x}^{b})+{\mathcal{P}_{d i c e}}(m_{y}^{p},m_{y}^{b}) Cinst=Pdice(mxp,mxb)+Pdice(myp,myb)
采用 cross entropy 损失来计算类别损失 C c o s t \mathcal{C}_{cost} Ccost。于是整体匹配损失 C \mathcal{C} C:
C = β 1 C i n s t + β 2 C c a t e \mathcal{C}=\beta_1\mathcal{C}_{inst}+\beta_2\mathcal{C}_{cate} C=β1Cinst+β2Ccate如果没有匹配的实例感知图则会产生 “no object” 的目标类别标签 ϕ \phi ϕ。
4.4 层级进化
4.4.1 层级模型
层级方法旨在将图像分割视为一种连续的能量最小化问题。
Mumford-Shah 层级模型:给定一图像 I I I,找到一组参数化的轮廓 C C C,将图像层级 Ω ∈ R 2 \Omega\in\mathbb{R}^2 Ω∈R2 划分为 N N N 个不联通的区域 Ω 1 , ⋯ , Ω N \Omega_1, \cdots, \Omega_N Ω1,⋯,ΩN。Mumford-Shah 能量函数 F M S \mathcal F^{MS} FMS 定义如下:
F M S ( u 1 , ⋯ , u N , Ω 1 , ⋯ , Ω N ) = ∑ i = 1 N ( ∫ Ω i ( I − u i ) 2 d x d y + μ ∫ Ω i ∣ ∇ u i ∣ 2 d x d y + γ ∣ C i ∣ ) , \mathcal F^{MS}(u_1,\cdots,u_N,\Omega_1,\cdots,\Omega_N)=\sum\limits_{i=1}^{N}(\int\limits_{\Omega_i}(I-u_i)^2dxdy+\mu\int\limits_{\Omega_i}|\nabla u_i|^2dxdy+\gamma|C_i|), FMS(u1,⋯,uN,Ω1,⋯,ΩN)=i=1∑N(Ωi∫(I−ui)2dxdy+μΩi∫∣∇ui∣2dxdy+γ∣Ci∣),其中 u i u_i ui 为接近于输入 I I I 的光滑分段函数,目的是确保每个区域 Ω i \Omega_i Ωi 内的光滑。 μ \mu μ, γ \gamma γ 为加权系数。
之后 Chan 和 Vese 简化了这一能量函数:
F CV ( ϕ , x , c 2 ) = ∫ Q ∣ I ( x , y ) − c 1 ∣ 2 H ( ϕ ( x , y ) ) d x d y + ∫ Q ∣ I ( x , y ) − c 2 ∣ 2 ( 1 − H ( ϕ ( x , y ) ) ) d x d y + γ ∫ Q ∣ ∇ H ( ϕ ( x , y ) ) ∣ d x d y \begin{aligned}\mathcal{F}^{\text{CV}}(\phi,x,c_2)&=\int\limits_{Q}\left|I(x,y)-c_1\right|^2H(\phi(x,y))dxdy\\ &+\int\limits_{Q}\left|I(x,y)-c_2\right|^2(1-H(\phi(x,y)))dxdy+\gamma\int\limits_{Q}\left|\nabla H(\phi(x,y))\right|dxdy\end{aligned} FCV(ϕ,x,c2)=Q∫∣I(x,y)−c1∣2H(ϕ(x,y))dxdy+Q∫∣I(x,y)−c2∣2(1−H(ϕ(x,y)))dxdy+γQ∫∣∇H(ϕ(x,y))∣dxdy其中 H H H 为 Heaviside 海塞函数, ϕ ( x , y ) \phi(x,y) ϕ(x,y) 为层级函数,如果为 0 则表示轮廓 C = { ( x , y ) : ϕ ( x , y ) = 0 } C=\{(x,y):\phi(x,y)=0\} C={(x,y):ϕ(x,y)=0} 将图像空间 Ω \Omega Ω 划为两个不连通区域,内部轮廓为 C : Ω 1 = { ( x , y ) : ϕ ( x , y ) > 0 } C\colon\Omega_1=\{(x,y):\phi(x,y)>0\} C:Ω1={(x,y):ϕ(x,y)>0}外部轮廓为 C : Ω 2 = { ( x , y ) : ϕ ( x , y ) < 0 } C\colon\Omega_2=\{(x,y):\phi(x,y)<0\} C:Ω2={(x,y):ϕ(x,y)<0} F CV \mathcal{F}^{\text{CV}} FCV 式子中右边一二项倾向于拟合数据,第三项用一个非负系数 γ \gamma γ 归一化 0 0 0 层级轮廓。 c 1 c_1 c1, c 2 c_2 c2 分别为 C C C 内部和 C C C 外部的输入 I ( x , y ) I(x,y) I(x,y) 的均值。
于是通过 c 1 c_1 c1 和 c 2 c_2 c2 找到一个层级函数 ϕ ( x , y ) = 0 \phi(x,y)=0 ϕ(x,y)=0 来优化能量函数 F CV \mathcal{F}^{\text{CV}} FCV,从而得到图像的分割结果。
4.4.2 在 Bounding Box 内的层级进化
本文提出的方法采用 Chan-Vese 提出的基于能量的层级进化模型。首先将每个正样本实例感知 mask 作为其在 bounding box 标注下所赋值目标的层级函数 ϕ \phi ϕ。所有的输入图像及提取的特征都用来进化层级曲线,其中一个 box 投影函数用来估计一个初始的边界 ϕ 0 \phi_0 ϕ0。每个实例的层级在其对应的 box 标注框内被迭代地优化从而获得高质量的 mask 预测。
层级进化
给定输入图像 I ( x , y ) I(x,y) I(x,y),旨在标注的 bounding box B \mathcal{B} B 区域内隐式地进化出一组层级来预测目标边界曲线。实例感知 mask M ∈ R H × W × S 2 M\in\mathbb{R}^{H\times W\times S^2} M∈RH×W×S2 包含 N N N 个尺寸为 H × W H\times W H×W 的可能实例图。在 box 水平的匹配赋值完毕后,正样本和负样本 mask 被分离开。将 box B \mathcal{B} B 内的每个正样本图作为层级 ϕ ( x , y ) \phi(x,y) ϕ(x,y),其输入图像 I ( x , y ) I(x,y) I(x,y) 相应的像素空间被视为 Ω \Omega Ω,即 Ω ∈ B \Omega\in\mathcal{B} Ω∈B。当 C = { ( x , y ) : ϕ ( x , y ) = 0 } C=\{(x,y):\phi(x,y)=0\} C={(x,y):ϕ(x,y)=0} 时,对应的 C C C 为分割出的边界,此时 box 区域被划分为不相连的前景和背景区域。
通过优化下面的能量函数来学习一系列的层级 ϕ ( x , y ) \phi(x,y) ϕ(x,y):
F ( ϕ , I , c 1 , c 2 , B ) = ∫ Ω ∈ B ∣ I ∗ ( x , y ) − c 1 ∣ 2 σ ( ϕ ( x , y ) ) d x d y + ∫ Ω ∈ B ∣ I ∗ ( x , y ) − c 2 ∣ 2 ( 1 − σ ( ϕ ( x , y ) ) ) d x d y + γ ∫ Ω ∈ B ∣ ∇ σ ( ϕ ( x , y ) ) ∣ d x d y \begin{aligned} \mathcal{F}\left(\phi, I, c_{1}, c_{2}, \mathcal{B}\right) & =\int_{\Omega \in \mathcal{B}}\left|I^{*}(x, y)-c_{1}\right|^{2} \sigma(\phi(x, y)) d x d y \\ & +\int_{\Omega \in \mathcal{B}}\left|I^{*}(x, y)-c_{2}\right|^{2}(1-\sigma(\phi(x, y))) d x d y+\gamma \int_{\Omega \in \mathcal{B}}|\nabla \sigma(\phi(x, y))| d x d y \end{aligned} F(ϕ,I,c1,c2,B)=∫Ω∈B∣I∗(x,y)−c1∣2σ(ϕ(x,y))dxdy+∫Ω∈B∣I∗(x,y)−c2∣2(1−σ(ϕ(x,y)))dxdy+γ∫Ω∈B∣∇σ(ϕ(x,y))∣dxdy其中 I ∗ ( x , y ) I^{*}(x,y) I∗(x,y) 表示归一化后的图像 I ( x , y ) I(x,y) I(x,y), γ \gamma γ 为非负系数, σ \sigma σ 为 s i g m o i d sigmoid sigmoid 函数,其被视为层级 ϕ ( x , y ) \phi(x, y) ϕ(x,y) 的特征函数。相比于传统的 Heaviside 海塞函数, s i g m o i d sigmoid sigmoid 更为光滑,能够更好地表示预测实例的特征以及提高层级进化在训练过程中的收敛。上式右边一二项旨在强制预测的 ϕ ( x , y ) \phi(x, y) ϕ(x,y) 统一内部区域 Ω \Omega Ω 和外部区域 Ω ˉ \bar\Omega Ωˉ。 c 1 c_1 c1, c 2 c_2 c2 为 Ω \Omega Ω 和 Ω ˉ \bar\Omega Ωˉ 的均值,定义如下:
c 1 ( ϕ ) = ∫ Ω ∈ B I ∗ ( x , y ) σ ( ϕ ( x , y ) ) d x d y ∫ Ω ∈ B σ ( ϕ ( x , y ) ) d x d y , c 2 ( ϕ ) = ∫ Ω ∈ B I ∗ ( x , y ) ( 1 − σ ( ϕ ( x , y ) ) ) d x d y ∫ Ω ∈ B ( 1 − σ ( ϕ ( x , y ) ) ) d x d y c_1(\phi)=\dfrac{\int\limits_{\Omega\in\mathbb{B}}I^*(x,y)\sigma(\phi(x,y))dxdy}{\int\limits_{\Omega\in\mathbb{B}}\sigma(\phi(x,y))dxdy},~~c_2(\phi)=\dfrac{\int\limits_{\Omega\in\mathcal{B}}I^*(x,y)(1-\sigma(\phi(x,y)))dxdy}{\int\limits_{\Omega\in\mathcal{B}}(1-\sigma(\phi(x,y)))dxdy} c1(ϕ)=Ω∈B∫σ(ϕ(x,y))dxdyΩ∈B∫I∗(x,y)σ(ϕ(x,y))dxdy, c2(ϕ)=Ω∈B∫(1−σ(ϕ(x,y)))dxdyΩ∈B∫I∗(x,y)(1−σ(ϕ(x,y)))dxdy能量函数 F \mathcal{F} F 可以在训练过程中利用梯度反向传播来优化。当时间步 t ≥ 0 t\ge0 t≥0 时,能量函数 F \mathcal{F} F 对 ϕ \phi ϕ 的微分可表示为:
∂ ϕ ∂ t = − ∂ F ∂ ϕ = − ∇ σ ( ϕ ) [ ( I ∗ ( x , y ) − c 1 ) 2 − ( I ∗ ( x , y ) − c 2 ) 2 + γ d i v ( ∇ ϕ ∣ ∇ ϕ ∣ ) ] \dfrac{\partial\phi}{\partial t}=-\dfrac{\partial F}{\partial\phi}=-\nabla\sigma(\phi)[(I^*(x,y)-c_1)^2-(I^*(x,y)-c_2)^2+\gamma div\left(\dfrac{\nabla\phi}{|\nabla\phi|}\right)] ∂t∂ϕ=−∂ϕ∂F=−∇σ(ϕ)[(I∗(x,y)−c1)2−(I∗(x,y)−c2)2+γdiv(∣∇ϕ∣∇ϕ)]其中 ∇ \nabla ∇ 和 d i v div div 分别为空间求导以及散度算子。于是 ϕ \phi ϕ 的更新为:
ϕ i = ϕ i − 1 + Δ t ∂ ϕ i − 1 ∂ t \phi_i=\phi_{i-1}+\Delta t\dfrac{\partial\phi_{i-1}}{\partial t} ϕi=ϕi−1+Δt∂t∂ϕi−1上式可以视为沿着能量函数下降方向的一个隐式的曲线进化,而最优的实例边界 C C C 可以借助迭代拟合 ϕ i − 1 \phi_{i-1} ϕi−1,从而最小化能量函数 F \mathcal{F} F 获得:
inf Ω ∈ B { F ( ϕ ) } ≈ 0 ≈ F ( ϕ i ) \operatorname*{inf}_{\Omega\in\mathcal{B}}\{\mathcal{F}(\phi)\}\approx0\approx\mathcal{F}(\phi_i) Ω∈Binf{F(ϕ)}≈0≈F(ϕi)
输入的数据格式
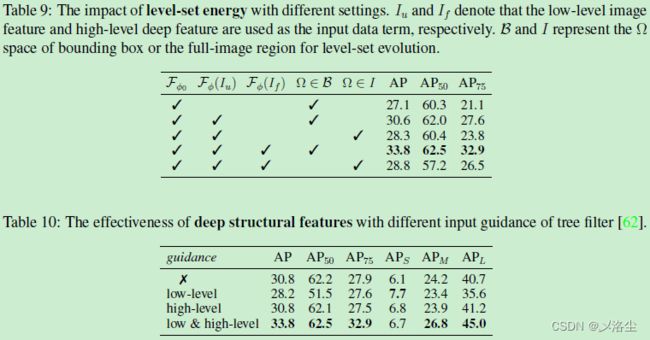
除输入低水平的图像特征 I u I_u Iu 外,还采用嵌入了图像语言信息的高层深度特征 I f I_f If 来获得更加鲁棒的结果。将 IAD 中所有尺度的形成的统一 mask 特征 F m a s k F_{\text mask} Fmask 送入到一个卷积层来提取高层特征 I f I_f If。此外,还通过树滤波器来增强 I f I_f If,这利用了最小跨越树(minimal spanning tree MST?)来建模长距离依赖并保存目标结构。为层级进化构建的整体能量函数为:
F ( ϕ ) = λ 1 ∗ F ( ϕ , I u , c u 1 , c u 2 , B ) + λ 2 ∗ F ( ϕ , I f , c f 1 , c f 2 , B ) , \mathcal F(\phi)=\lambda_1*\mathcal F(\phi,I_u,c_{u_1},c_{u_2},\mathcal B)+\lambda_2*\mathcal F(\phi,I_f,c_{f_1},c_{f_2},\mathcal B),\quad\text{} F(ϕ)=λ1∗F(ϕ,Iu,cu1,cu2,B)+λ2∗F(ϕ,If,cf1,cf2,B),其中 λ 1 \lambda_1 λ1 和 λ 2 \lambda_2 λ2 分别为平衡两种特征的权重, c u 1 c_{u_1} cu1、 c u 2 c_{u_2} cu2、 c f 1 c_{f_1} cf1、 c f 2 c_{f_2} cf2 分别为输入 I u I_u Iu 和 I f I_f If 的均值。
层级初始化
利用 box 投影函数来促进模型自动地生成一个粗糙估计的初始层级 ϕ 0 \phi_0 ϕ0。
具体的,利用相同的坐标投影函数 P d i c e \mathcal{P}_{dice} Pdice 作为 box 水平的匹配赋值,计算预测的 mask 和 GT box 在 x 和 y 轴上的投影差异。
通过赋值 GT box 上的每个位置来得到二值化的区域 m b ∈ { 0 , 1 } H × W m^b\in\{0,1\}^{H\times W} mb∈{0,1}H×W,其中 1 为前景,0 为背景。每一个实例预测的 mask 得分 m p ∈ { 0 , 1 } H × W m^p\in\{0,1\}^{H\times W} mp∈{0,1}H×W 被视为前景概率。box 投影函数 F ( ϕ 0 ) b o x \mathcal{F}(\phi_0)_{box} F(ϕ0)box 定义如下:
F ( ϕ 0 ) b o x = P d i c e ( m x p , m x b ) + P d i c e ( m y p , m y b ) \mathcal{F}(\phi_0)_{box}=\mathcal{P}_{dice}(m_x^p,m_x^b)+\mathcal{P}_{dice}(m_y^p,m_y^b) F(ϕ0)box=Pdice(mxp,mxb)+Pdice(myp,myb)其中 m x p m_x^p mxp、 m x b m_x^b mxb、 m y p m_y^p myp、 m y b m_y^b myb 分别为 x x x 和 y y y 坐标轴上mask 预测值 m p m^p mp 和二值化 GT 区域 m b m^b mb 的投影。
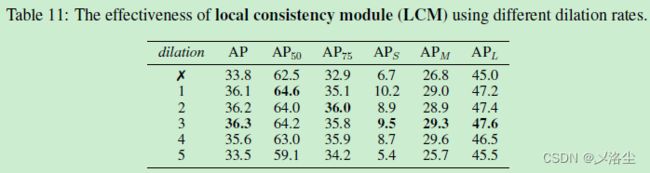
4.4.3 局部一致性模块
基于区域的层级通常依赖于输入数据的强烈一致性。为了缓解这一现象,提出了一种相似卷积核函数来确保层级 ϕ \phi ϕ 的局部一致性。
首先在像素点 p i , j p_{i,j} pi,j 及其周围 8 个邻居点上定义一个卷积核函数 A \mathcal{A} A:
A i , j p = A ( p i , j , p l , k ) ( l , k ) ∈ N 8 ( i , j ) = − ( ∥ p i , j − p l , k ∥ σ i , j p ) 2 \mathcal{A}^p_{i,j}=\begin{matrix}\mathcal{A}(p_{i,j},p_{l,k})\\ (l,k)\in\mathcal{N}_8(i,j)\end{matrix}=-\left(\frac{\|p_{i,j}-p_{l,k}\|\\}{\sigma^p_{i,j}}\right)^2 Ai,jp=A(pi,j,pl,k)(l,k)∈N8(i,j)=−(σi,jp∥pi,j−pl,k∥)2其中 σ i , j \sigma_{i,j} σi,j 为像素区域的标准微分来计算局部的一致性卷积核。之后采用 Softmax 函数来计算像素一致性上的归一化变换距离 A i , j p \mathcal{A}^p_{i,j} Ai,jp:
A i , j p ∗ = exp ( A i , j , l , k p ) ∑ ( l , k ) ∈ N 8 ( i , j ) exp ( A l , j , l , k p ) {\cal A}_{i,j}^{p}{}^{*}=\frac{\exp({\cal A}_{i,j,l,k}^{p})}{\sum\limits_{(l,k)\in{\cal N}_{8}(i,j)}\exp({\cal A}_{l,j,l,k}^p)} Ai,jp∗=(l,k)∈N8(i,j)∑exp(Al,j,l,kp)exp(Ai,j,l,kp)
此外,在空间位置上利用这一变换函数来编码邻居内的空间关联 A s i , j ∗ {{\cal A}^{s}}_{i,j}^* Asi,j∗,于是变换卷积核函数定义为:
A i , j ∗ = A p i , j ∗ + η A s i , j ∗ {{\cal A}_{i,j}}^*={{\cal A}^{p}}_{i,j}^*+\eta{{\cal A}^{s}}_{i,j}^* Ai,j∗=Api,j∗+ηAsi,j∗其中 η \eta η 为平衡系数。
为充分利用像素和空间变换来保持层级预测的局部一致性,在每一时间步 t t t 上的预测层级 ϕ n \phi_n ϕn 执行这一操作 k k k 次:
ϕ i , j k = ∑ Ω ∈ B A i , j ∗ ∗ ϕ i , j k − 1 \phi_{i,j}^k=\sum_{\Omega\in\mathcal{B}}{\mathcal{A}_{i,j}}^**\phi_{i,j}^{k-1} ϕi,jk=Ω∈B∑Ai,j∗∗ϕi,jk−1
实验中设 k = 10 k=10 k=10。在预测的层级 ϕ n \phi_n ϕn 和细化的 ϕ k n \phi_k^n ϕkn 上使用 L 1 L_1 L1 距离来确保 ϕ n \phi_n ϕn 更加稳定且适合拟合目标边界。
4.5 训练损失和推理
损失函数
损失函数 L L L 包含两部分,分类损失 L c a t e L_{cate} Lcate 和 实例分割损失 L i n s t L_{inst} Linst: L = ω L c a t e + L i n s t L= \omega L_{cate}+L_{inst} L=ωLcate+Linst,其中 ω \omega ω 为平衡系数, L c a t e L_{cate} Lcate 为 Focal 损失, L i n s t L_{inst} Linst 为可微分的层级能量函数:
L i n s t = 1 N p o s ∑ k 1 { c o n d } { α F ( ϕ 0 ) b o x + F ( ϕ ) } L_{inst}=\dfrac{1}{N_{pos}}\sum_k\mathbb{1}_{\{\text cond\}}\{\alpha\mathcal{F}(\phi_0)_{box}+\mathcal{F}(\phi)\} Linst=Npos1k∑1{cond}{αF(ϕ0)box+F(ϕ)}其中 N p o s N_{pos} Npos 表示正样本的索引, α \alpha α 为平衡系数, 1 { c o n d } \mathbb{1}_{\{\text cond\}} 1{cond} 为目标位置 ( i , j ) (i,j) (i,j) 上的索引函数,这能确保仅有正的实例 mask 样本才能执行层级进化。在 CNN 框架上, p i , j ∗ {p_{i,j}^{*}} pi,j∗ 为目标位置 ( i , j ) (i,j) (i,j) 上的类别概率。当 p i , j ∗ > 0 p_{i,j}^{*}>0 pi,j∗>0 时,能过滤掉低质量候选目标。在 Transformer 框架上,目标类别 c i c_i ci 不可能为空,因此条件函数 c j g t ≠ ϕ c_{j}^{gt}{\ne \phi} cjgt=ϕ
推理
推理过程无需层级进化参与:输入图像,产生逐个 mask 预测。对于 CNN 框架,利用 NMS 作为后处理。对于 Transformer 框架,无需后处理,直接输出实例 mask。
五、实验
5.1 数据集
Pascal VOC、COCO、iSAID、LiTS,另外增加了一个 场景文本数据集 ICDAR2019 ReCTS。
5.2 实施细节
AdamW 优化器,8 块 V100(还是够壕~),采用 mmdetection 库,ResNet 以及 Swin-Transformer 作为 backbone,预训练 ImageNet-1K 的权重。CNN 模型简记为 Box2Mask-C,初始学习率 1 0 − 4 10^{-4} 10−4,权重衰减 0.1,batch 16,12 或 36 个 epochs。非负权重 α = 3.0 \alpha=3.0 α=3.0。
Transformer 模型简记为 Box2Mask-T,初始学习率 5 × 1 0 − 5 5\times10^{-5} 5×10−5,权重衰减 0.05,batch 8, 50 个 epochs。大尺度抖动增强,随机采样范围 [ 0.1 , 2.0 ] [0.1,2.0] [0.1,2.0],固定尺寸裁剪到 1024 × 1024 1024\times1024 1024×1024, α = 5.0 \alpha=5.0 α=5.0, γ \gamma γ 设为 1 0 − 4 10^{-4} 10−4。 λ 1 = 0.05 \lambda_1=0.05 λ1=0.05、 λ 1 = 5.0 \lambda_1=5.0 λ1=5.0。
在 COCO 和 Pascal VOC 数据集上,使用尺度抖动,短边被随机采样,从 640-800个像素。在 iSAID 数据集上,所有模型输入尺寸为 800 × 800 800\times800 800×800。在 LiTS 数据集上,所有模型输入尺寸为 640 × 640 640\times640 640×640。在 ICDAR 2019 ReCTS 数据集上,所有训练设置同 COCO 数据集。COCO AP 作为评估指标。
5.3 主要结果
5.3.1 一般场景下的实例分割
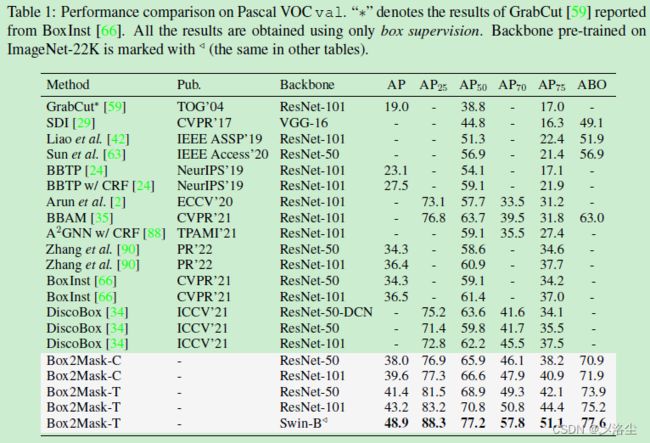
Pascal VOC 上的结果
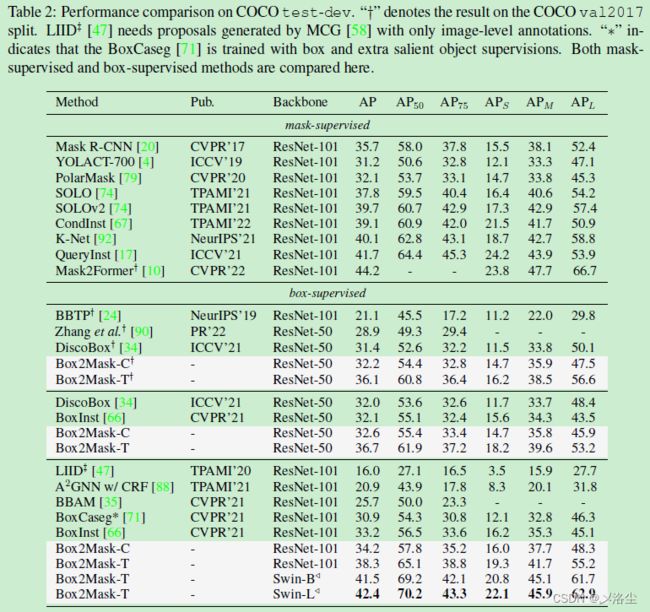
COCO 上的结果
5.3.2 俯拍图像上的实例分割
iSAID 上的结果
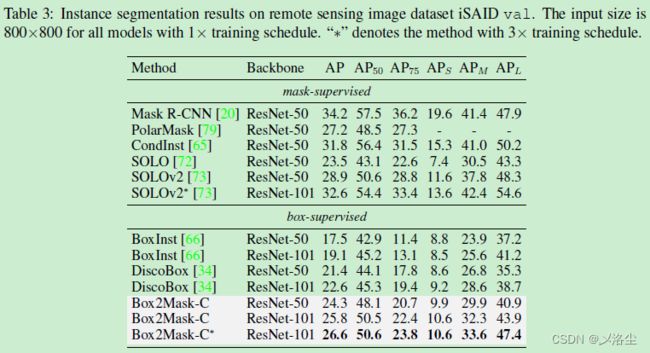

DOTA-v1.0 上的结果
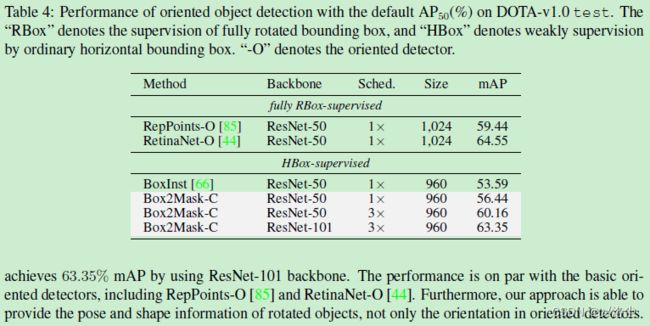
5.3.3 医学图像上的实例分割
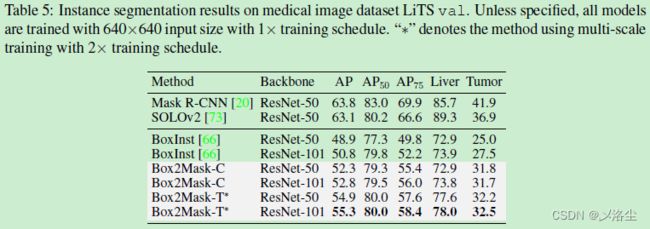
5.3.4 字符实例分割
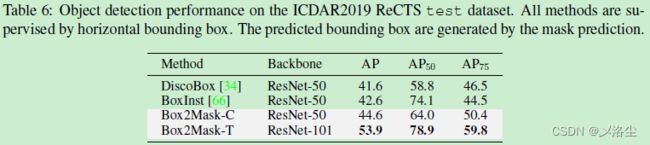

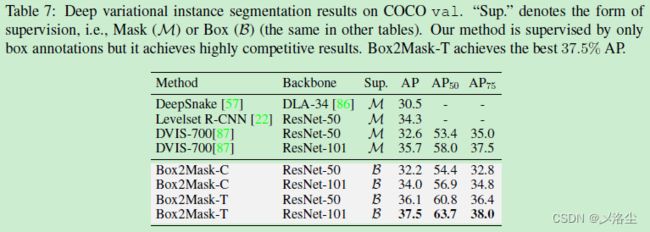
5.4 基于变分的深度实例分割
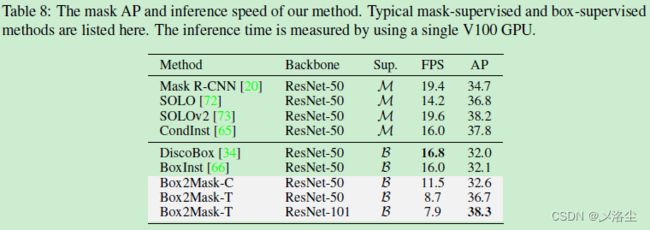
5.5 推理速度
5.6 消融实验
消融实验在 Pascal VOC 数据集上进行。
层级能量
局部一致性模块
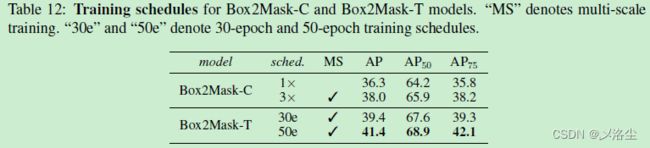
训练计划
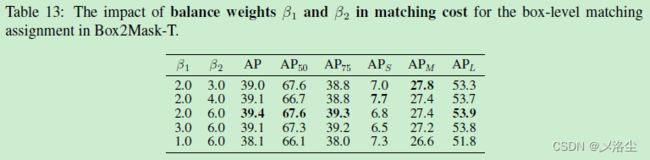
匹配损失的平衡权重
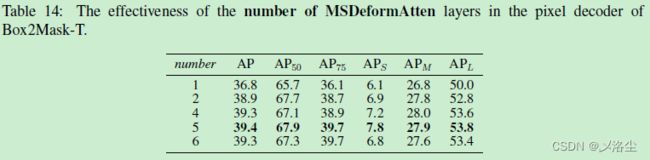
MSDeformAtten 层的数量
六、结论
本文提出了一种高效的 box 的弱监督实例分割方法 Box2Mask,通过迭代地学习一系列层级函数来获得精确的分割 mask:基于 CNN 和 Transformer 的 Box2Mask 分别以一种单阶段的框架来执行层级进化。输入的图像和提取的深度特征用于进化层级曲线,其中一个投影损失函数用于获得初始的边界。通过最小化可微分的能量函数,每个实例的层级能够在相应的 bounding box 标注内迭代地优化,大量的实验表明方法很牛。
写在后面
总算把这篇博文写完了,只想感叹一下,这工作量绝对够够的,应该小修下就录用了。