【Java知识点大全】
文章目录
- 前言
- Java基础知识点
-
- 计算机基础问题
-
- 深拷贝和浅拷贝
- 伪共享的概念以及如何避免
- 网络四元组
- TCP协议为什么要设计三次握手?
- HashMap
-
- HashMap底层实现
- 1.7版本和1.8版本的差异
- 并发修改异常解决方案
- 加载因子
- 长度恒定为2的n次方
- 散列均匀分布
- hashmap优化
- Fail-safe机制/Fail-fast机制
- Synchronized
-
- 定义
- 应用场景
- 对象加锁实现原理
-
- JDK6以前
- 实现步骤
- JDK6版本及以后
-
- 对象从无锁到偏向锁转化的过程
- 轻量级锁升级
- 自旋锁
- 重量级锁
- 引入偏向锁的好处
- 引入轻量级的好处
- ThreadLocal
-
- 定义
- ThreadLocal与Synchronized的区别
- 底层实现
-
- ThreadLocalMap底层结构
- ThreadLocalMap存储元素的过程
- ThreadLocal实现线程隔离的原理
- AQS
-
- 独占锁举例
- 底层实现独占锁
- 超时获取锁
- 共享锁举例
- 共享锁实现原理
- AQS为什么要使用双向链表
- 线程池
-
- 底层运行原理
- 七大核心参数
- 如何合理的配置核心线程数?
- 拒绝策略
- 实际创建线程池
- 内存模型
-
- JDK1.6、JDK1.7、JDK1.8 内存模型演变
- Java虚拟机栈
- 堆和元空间
- 内存屏障
- Class文件结构
- 类加载机制和双亲委派机制
- 垃圾回收器、垃圾回收算法、空间分配担保
-
- Serial
- ParNew
- Parallel scavenge
- 复制算法
- 分代收集算法
- 进入老年代的几种情况
-
- 空间分配担保
- Serial Old
- Parallel old
- 标记整理算法
- CMS
- 标记清除算法
- G1
- 安全点
- JIT技术
- 可达性分析
- 四种引用类型
-
- 强引用
- 软引用
- 弱引用
- 虚引用
- gc的过程中对象是否能回收
- 三色标记
- 跨代引用
- 逃逸分析
- 内存泄漏
- 内存堆积
- JVM调优
- CPU飙高系统反应慢怎么排查?
- MySQL知识点
-
- 隔离级别
-
- Read Uncommitted(读未提交)
-
- 脏读(Drity Read):
- Read Committed(读已提交)
-
- 不可重复读(Non-repeatable read):
- Repeatable Read(可重读)
-
- 幻读(Phantom Read):
- Serializable(可串行化)(更高级别隔离,避免脏读,避免不可重复读,避免幻读)
- ACID底层实现原理
-
- 原子性底层实现原理
- 一致性实现原理
- 持久性底层实现原理
- 隔离性实现原理(一致性非锁定读(MVCC的原理))
- BufferPool缓存机制
- 重做日志刷新到磁盘的策略
- filesort的过程
- 离散读
- 优化器如何优化离散读?你是如何避免离散读的
- ICP优化
- 全文检索
- 行锁、表锁、间隙锁、死锁
-
- 行锁的算法
- 行锁的表现
- 表锁的表现
- 间隙锁的表现
- 死锁
- 主键自增长实现原理
- 索引数据结构
-
- 磁盘存储
- 假设每条sql信息为1kb,主键ID为bigint型,一颗高度为2,3,4高度的B+树分别可以存储多少行数据?
- 为什么选用B+树做索引而不选用二叉树或者B树?
- 为什么用 B+ 树做索引而不用哈希表做索引?
- SQL优化
- 索引失效的几种情况
- 聚集索引
- 辅助索引
- 覆盖索引,什么情况下优化器会选择使用覆盖索引
- 联合索引
- 索引总结
- redo log 和bin log有什么区别?binlog做什么用的
- 什么是undolog,有什么用?
- 分布式事务
-
- CAP理论
- BASE理论
- 两阶段提交(2PC)
- 三阶段提交(3PC)
- 补偿事务(TCC)
- MQ 事务消息
- 最大努力通知
- SQL的执行流程
- Mysql调优
- 分库分表
-
- 数据分片主要流程
-
- sql解析整体结构
- 路由引擎
- 改写引擎
- 执行引擎
- 归并引擎
- 源码流程
- 分库分表的的分片算法
-
- NoneShardingStrategy
- InlineShardingStrategy
- StandardShardingStrategy
- ComplexShardingStrategy
- HintShardingStrategy
- 分库分表带来的问题
- 主从复制
-
- 主从复制(replication)的工作原理
- 主从复制bin log 日志有几种记录方式,说说各自的优缺点
- 主从复制有几种方式?
-
- 异步复制
- 半同步复制
- 增强半同步复制
- 读写分离
-
- 读写分离延时导致的数据不一致解决方案
-
- 数据同步
- 中间件路由
- 缓存路由
- mysql数据库集群高可用
-
- MMM
- MHA
- MGR
- Redis知识点
-
- 多路复用
-
- redis的多路复用模式
-
- 应用对外提供服务的过程
- select
- epoll
- 多路复用的定义
- 多路复用的举例
- 多路复用的实现
-
- 过程一:数据未就绪
- 过程二:数据就绪
- 单线程模型
-
- 为什么redis使用单线程模型还能保证高性能?
- 你是如何理解redis单线程模型的?
- Redis底层数据结构
-
- 简单字符串
- 链表
- 跳跃表
- 字典
- 压缩列表
- Redis五大数据类型的应用场景
-
-
- 各数据类型应用场景
-
- Redis五大数据类型实现原理
-
- redisObject属性
-
- type属性
- prt和encoding属性
- refcount 属性
- lru 属性
- encoding属性
-
- String类型编码
- List集合对象编码
- Hash对象编码
- Set集合对象编码
- Zset有序集合对象编码
- Redis持久化
-
- RDB持久化
- AOF持久化
- 混合持久化
- 持久化底层实现原理
-
- RDB持久化底层实现原理
- AOF持久化底层实现原理
- 混合持久化底层实现原理
- save与bgsave
- 缓存雪崩
- 缓存穿透
- 缓存击穿
- 布隆过滤器
-
- 布隆过滤器定义
- 布隆过滤器判断数据是否存在?
- 布隆过滤器优缺点
- 布隆过滤器的实现
- Redis分布式寻址算法
-
- hash 算法
- 一致性 hash 算法
- hash slot 算法
- Redis过期策略
-
- 惰性删除流程
- 定期删除流程
- 内存淘汰机制
- RDB对过期key的处理
- AOF对过期key的处理
- Redis与数据库的数据一致性
-
- 双删策略
- 延时双删策略
- 异步延时删除策略
- Redis分布式锁底层实现
-
- 如何实现
- 使用redis锁会有很多异常情况,如何处理这些异常呢
-
- 1.redis服务挂掉了,抛出异常了,锁不会被释放掉,新的请求无法进来,出现死锁问题
- 2.服务器果宕机了,导致锁不能被释放的现象
- 3.锁的过期时间比业务执行时间短,会存在多个线程拥有同一把锁的现象
- 4.锁的过期时间比业务执行时间短,锁永久失效
- Redis热点数据缓存
-
- 互斥锁(mutex)
- 永远不过期
- 高并发
- 高可用
- 哨兵机制
-
- Redis 哨兵主备切换的数据丢失问题
-
- 异步复制导致的数据丢失
- 集群模式
-
- 集群协议
-
- 集中式
- gossip 协议
- 多级缓存架构
- 并发竞争
- Redis cluster 的高可用与主备切换原理
- 主从架构下的数据同步
-
- 主从复制/数据同步
- 主从架构下的数据部分复制(断点续传)
- 数据丢失发生的场景以及解决方案
- 主从/哨兵/集群区别
-
- 主从架构
- 哨兵
- 集群
- 高可用/哨兵集群/主备切换
- MQ知识点(RabbitMQ/RocketMQ/Kafka)
-
- 三种mq对比
- 消息丢失
- 消息重复消费
- 消息顺序
- 消息积压
- 延迟队列
- 消息队列高可用
- RabbitMQ的工作模式
-
- 简单模式
- Work queues 工作队列模式
- Pub/Sub 订阅模式
- Routing 路由模式
- Topics 通配符模式
- RocketMQ的消息类型
-
- 同步发送、异步发送以及单向发送
-
- 1、同步发送消息的样例见:org.apache.rocketmq.example.simple.Producer
- 2、异步发送消息的样例见:org.apache.rocketmq.example.simple.AsyncProducer
- 3、单向发送消息的样例:
- 4、使用消费者消费消息
-
- 拉模式的样例见:org.apache.rocketmq.example.simple.PullConsumer
- 推模式的样例见:org.apache.rocketmq.example.simple.PushConsumer
- 顺序消息
- 广播消息
- 延迟消息
- 批量消息
- 过滤消息
- 事务消息
- ACL权限控制
- 消息存储机制
-
- CommitLog文件
- ConsumerQueue消费逻辑队列
- IndexFile索引文件
- 页缓存与内存映射
- Kafka相关知识点
-
- 消费模式
-
- 单播消费
- 多播消费
- 主题/分区/日志的概念
-
- 主题
- 分区
- 日志
- Kafka核心总控制器Controller
- Controller选举机制
- Partition副本选举Leader机制
- 消费者消费消息的offset记录机制
- 消费者Rebalance机制
- 消费者Rebalance分区分配策略
- Rebalance过程
-
- 第一阶段:选择组协调器
-
- 组协调器GroupCoordinator
- 组协调器选择方式
- 第三阶段( SYNC GROUP)
- producer发布消息机制
-
- 写入方式
- 消息路由
- 写入流程
- HW与LEO
- 日志分段存储
- 十亿消息数据线上环境规划
- JVM参数设置
- Spring知识点
-
- Spring Bean的生命周期
-
- Bean创建前的准备阶段
- 创建Bean的实例
- 开始依赖注入
- 缓存到Spring容器
- 销毁Bean的实例
- Spring循环依赖
-
- 什么是循环依赖?
- 循环依赖会导致什么问题的出现?
- Spring是怎么解决循环依赖导致的问题的?
- Spring容器启动执行流程
- Spring事务底层实现原理
- Spring IOC容器加载过程
-
- 资源文件定位
- 解析DefaultBeanDefinitionDocumentReader
- 注册
- 实例化
- SpringAOP实现原理
- Spring的自动装配
- Spring Boot自动装配
- Spring Boot启动过程
- Spring MVC的工作原理
- Mybatis的缓存机制
- Spring Cloud知识点
-
- 微服务构建
-
- 微服务架构设计原则
- 微服务构建技术选型
- 前后端分离架构
- 项目部署安全方面
- 客户端负载均衡
-
- 负载均衡(服务端/客户端)
- 实现Ribbon
-
- 底层实现
- 快速集成
- Ribbon负载均衡策略
- 脱离Eureka使用Ribbon
- 服务治理
-
- 为什么需要服务治理
- 服务治理的解决方案
- 服务治理的技术选型
- Eureka
-
- 自我保护机制产生的原因
- 自我保护机制
- 在什么环境下开启自我保护机制
-
- 本地环境
- 生产环境
- Nacos
-
- Nacos的动态更新如何实现?什么是长轮询/如何实现长轮询?配置和服务器之间的配置变更整个方案如何实现?Nacos如何实现配置的变更和对比?
- 基于HTTP的长轮询简单实现
- Nacos、Eureka与Zookeeper区别
- 服务容错保护
-
- 服务雪崩
- Hystrix
-
- Hystrix容错机制:
- 熔断器的工作原理
- 信号量隔离
-
- 实现方式
- 线程池隔离
-
- 优缺点
- 实现方式
- 服务熔断
-
- 实现方式
- 服务降级
-
- 方法服务降级
- Feign中使用断路器
- 服务监控
-
- 实现方式
-
- 添加依赖
- 添加配置
- 启动类
- 访问
- 查看数据
- 监控中心
-
- 实现过程
-
- 添加依赖
- 启动类添加注解@EnableHystrixDashboard
- 聚合监控中心
-
- 实现过程
- Hystrix工作流程
- 声明式服务调用
- API网关服务
- 分布式配置中心
- 消息总线
- 消息驱动
-
- 基础组件
- 分布式服务追踪
- 分布式事务
-
- Seata 的架构
- 存在的问题
-
- 性能损耗
- 性价比
- 全局锁
-
- 热点数据
- 回滚锁释放时间
- 死锁问题
- 事务模式
-
- XA 事务模式
- AT事务模式
-
- 第一阶段
- 第二阶段
- 优点
- AT 如何保证分布式事务一致性?
- Seata-AT 是怎么做到无侵入的呢?
- 流量控制
-
- 实现原理
-
- 启动并且初始化Sentinel
- 获取主服务器信息
- 获取从服务器信息
- 向主服务器和从服务器发送信息,接收来自主服务器和从服务器的频道信息
- 检测主观下线状态
- 检查客观下线状态
- 选举领头的Sentinel
- 故障转移
- 致歉
- 作者求关注
前言
作者简介:我是廖志伟,一名Java资深开发工程师、Java领域优质创作者、CSDN博客专家、51CTO专家博主、幕后大佬社区创始人等头衔。拥有多年一线研发和团队管理经验,研究过主流框架的底层源码(Spring、SpringBoot、Spring MVC、SpringCould、Mybatis、Dubbo、Zookeeper),消息中间件底层架构原理(RabbitMQ、RockerMQ、Kafka)、Redis缓存、MySQL关系型数据库、 ElasticSearch全文搜索、MongoDB非关系型数据库、Apache ShardingSphere分库分表读写分离、设计模式、领域驱动DDD。
文章背景:大概几年前吧,一次在Boss上面找工作的时候发现了一些企业招聘的时候,发现招聘要求上面写了有个人技术博客和开源项目的优先,后面我也是慢慢的积累Java面试相关的知识点,不仅限于网上千篇一律的八股文,也有很多实战面试被问到过的,后面还组了一个百来号人的微信群,大家相互面试,加上前一段时间也面试过几家公司(每家二轮技术面试都是三个小时以上,面试比工作更心累),所以将自己的面试备战的知识点罗列分享出来给大家。
读者需知:全文总字数近二十五万字,阅读时间过长,建议收藏起来,方便下次查找。当然如果大家觉得我写的还不错的话,给文章点一下赞,让文章上热榜,那就更好了,嘿嘿。
文章更新:这篇文章是我前前后后大概花了好几个月时间累积的写出来的,文章性质还是有些偏向面试相关的,有很多底层细节知识点,未来也会继续添加新内容,如果文章中出现知识点不对的情况,欢迎大家在评论区矫正。
个人技术博客主页:欢迎大家来关注我哟:https://blog.csdn.net/java_wxid
个人开源项目主页:欢迎大家来评价(Star) :https://gitee.com/java_wxid/java_wxid

前期java_wxid项目可能会以博文总结为主,后期会录制视频投放到哔哩哔哩上面去
该项目专栏地址:https://blog.csdn.net/java_wxid/category_11976766.html
希望这个项目到后期可以成功加入GVP计划

好了,废话不多说,正文开始
Java基础知识点
计算机基础问题
深拷贝和浅拷贝
深拷贝和浅拷贝是用来描述对象或者对象数组这种引用数据类型的复制场景的。
浅拷贝就是只复制某个对象的指针,而不复制对象本身。
这种复制方式意味着两个引用指针指向被复制对象的同一块内存地址。
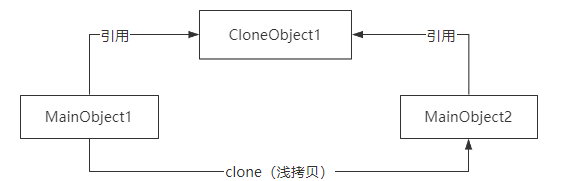
深拷贝会完全创建一个一模一样的新对象,新对象和老对象不共享内存,也就意味着对新对象的修改不会影响老对象的值。
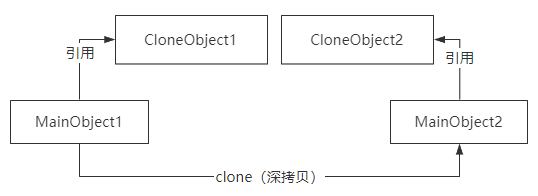
在Java里面,无论是深拷贝还是浅拷贝,都需要通过实现Cloneable接口,并实现clone()方法。
然后我们可以在clone()方法里面实现浅拷贝或者深拷贝的逻辑。
实现深拷贝的方法有很多,比如
-
通过序列化的方式实现,也就是把一个对象先序列化一遍,然后再反序列化回来,就会得到一个完整的新对象。
-
在clone()方法里面重写克隆逻辑,也就是对克隆对象内部的引用变量再进行一次克隆。
伪共享的概念以及如何避免
首先,计算机工程师为了提高CPU的利用率,平衡CPU和内存之间的速度差异,在CPU里面设计了三级缓存。
CPU在向内存发起IO操作的时候,一次性会读取64个字节的数据作为一个缓存行,缓存到CPU的高速缓存里面。
在Java中一个long类型是8个字节,意味着一个缓存行可以存储8个long类型的变量。
这个设计是基于空间局部性原理来实现的,也就是说,如果一个存储器的位置被引用,那么将来它附近的位置也会被引用。
所以缓存行的设计对于CPU来说,可以有效的减少和内存的交互次数,从而避免了CPU的IO等待,以提升CPU的利用率。
正是因为这种缓存行的设计,导致如果多个线程修改同一个缓存行里面的多个独立变量的时候,基于缓存一致性协议,就会无意中影响了彼此的性能,这就是伪共享的问题。
像这样一种情况,CPU0上运行的线程想要更新变量X、CPU1上的线程想要更新变量Y,而X/Y/Z都在同一个缓存行里面。
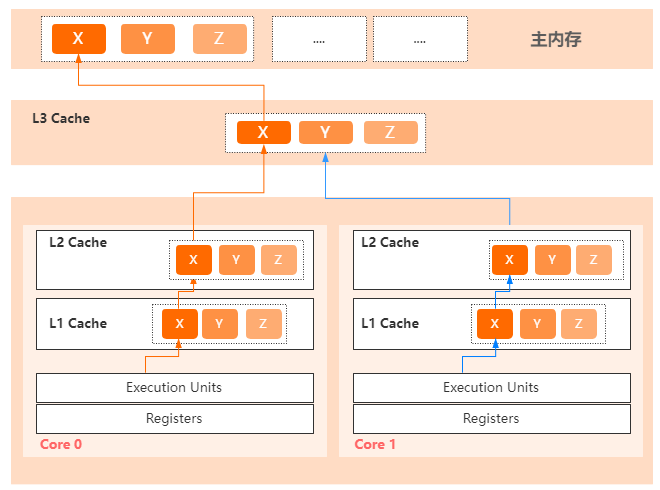
每个线程都需要去竞争缓存行的所有权对变量做更新,基于缓存一致性协议。
一旦运行在某个CPU上的线程获得了所有权并执行了修改,就会导致其他CPU中的缓存行失效。
这就是伪共享问题的原理。
因为伪共享会问题导致缓存锁的竞争,所以在并发场景中的程序执行效率一定会收到较大的影响。
这个问题的解决办法有两个:
-
使用对齐填充,因为一个缓存行大小是64个字节,如果读取的目标数据小于64个字节,可以增加一些无意义的成员变量来填充。
-
在Java8里面,提供了@Contented注解,它也是通过缓存行填充来解决伪共享问题的,被@Contented注解声明的类或者字段,会被加载到独立的缓存行上。
在Netty里面,有大量用到对齐填充的方式来避免伪共享问题。
网络四元组
四元组,简单理解就是在TCP协议中,去确定一个客户端连接的组成要素,它包括源IP地址、目标IP地址、源端口号、目标端口号。
正常情况下,我们对于网络通信的认识可能是这样

服务端通过ServerSocket建立一个对指定端口号的监听,比如8080。 客户端通过目标ip和端口就可以和服务端建立一个连接,然后进行数据传输。
但是我们知道的是,一个Server端可以接收多个客户端的连接,比如像这种情况
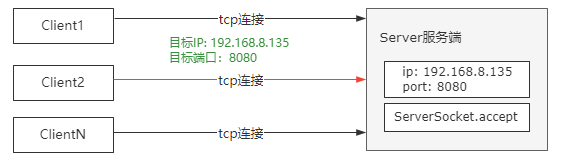
那,当多个客户端连接到服务端的时候,服务端需要去识别每一个连接。
并且TCP是全双工协议,也就是说数据允许在连接的两个方向上同时传输,因此这里的客户端,如果是反向通信,它又变成了服务端。

所以基于这两个原因,就引入了四元组的设计,也就是说,当一个客户端和服务端建立一个TCP连接的时候,通过源IP地址、目标IP地址、源端口号、目标端口号来确定一个唯一的TCP连接。因为服务器的IP和端口是不变的,只要客户端的IP和端口彼此不同就OK了。
比如像这种情况

同一个客户端主机上有三个连接连到Server端,那么这个时候源IP相同,源端口号不同。此时建立的四元组就是(10.23.15.3,59461 , 192.168.8.135,8080)
其中,源端口号是每次建立连接的时候系统自动分配的。
TCP协议为什么要设计三次握手?
关于这个问题,我会从下面3个方面来回答。
1.TCP协议,是一种可靠的,基于字节流的,面向连接的传输层协议。
-
可靠性体现在TCP协议通信双方的数据传输是稳定的,即便是在网络不好的情况下,TCP都能够保证数据传输到目标端,而这个可靠性是基于数据包确认机制来实现的。
-
TCP通信双方的数据传输是通过字节流来实现传输的
-
面向连接,是说数据传输之前,必须要建立一个连接,然后基于这个连接进行数据传输
2.因为TCP是面向连接的协议,所以在进行数据通信之前,需要建立一个可靠的连接,TCP采用了三次握手的方式来实现连接的建立。所谓的三次握手,就是通信双方一共需要发送三次请求,才能确保这个连接的建立。
- 客户端向服务端发送连接请求并携带同步序列号SYN。
- 服务端收到请求后,发送SYN和ACK, 这里的SYN表示服务端的同步序列号,ACK表示对前面收到请求的一个确认,表示告诉客户端,我收到了你的请求。
- 客户端收到服务端的请求后,再次发送ACK,这个ACK是针对服务端连接的一个确认,表示告诉服务端,我收到了你的请求。
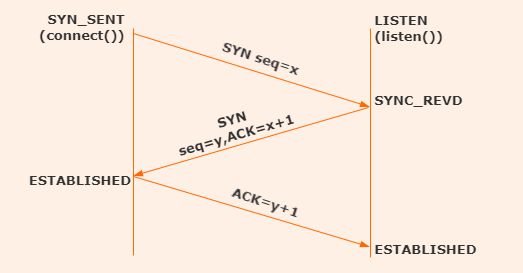
3.之所以TCP要设计三次握手,我认为有三个方面的原因:
-
TCP是可靠性通信协议,所以TCP协议的通信双方都必须要维护一个序列号,去标记已经发送出去的数据包,哪些是已经被对方签收的。而三次握手就是通信双方相互告知序列号的起始值,为了确保这个序列号被收到,所以双方都需要有一个确认的操作。
-
TCP协议需要在一个不可靠的网络环境下实现可靠的数据传输,意味着通信双方必须要通过某种手段来实现一个可靠的数据传输通道,而三次通信是建立这样一个通道的最小值。当然还可以四次、五次,只是没必要浪费这个资源。
-
防止历史的重复连接初始化造成的混乱问题,比如说在网络比较差的情况下,客户端连续多次发送建立连接的请求,假设只有两次握手,那么服务端只能选择接受或者拒绝这个连接请求,但是服务端不知道这次请求是不是之前因为网络堵塞而过期的请求,也就是说服务端不知道当前客户端的连接是有效还是无效。
HashMap
hashmap几乎是Java面试必问题,相关的知识点其实有很多,更为详细的hashmap知识点,我也有写,全部讲一遍,差不多要一个小时以上,有时间的同学可以去看看,这里提供地址:https://blog.csdn.net/java_wxid/article/details/124788118,面试官想问的可能就那么几个,另外还需要控制hashmap讲解的时长,挑几个比较重要的,进行讲解即可,下面由浅到深讲解,专门针对面试题,归总的知识点列举出来。
HashMap底层实现
向HashMap中添加一个元素时,当前元素的key会调用hashCode方法来决定它在数组中存放的位置。如果这个位置没有其他元素,会把这个键值对直接放到一个node类型的数组中,这个数组就是hashmap底层基础的数据结构。如果这个位置有其他元素,会继续拿着这个key调用equals方法和这个位置已存在的元素key进行对比,对比二个元素的key。key一样,返回true,原来的value值会被替换成新的value。key不一样,返回flase,这个位置就用链表的形式把多个元素串起来存放。
jdk1.7版本的HashMap数据结构就是数组加链表的形式存储元素的,但是会有弊端,当链表中的数据较多时,查询的效率会下降。所以JDK1.8版本做了一个升级,当链表长度大于8,并且数组长度大于64时,会转换为红黑树。因为红黑树需要进行左旋,右旋,变色操作来保持平衡,如果当数组长度小于64,使用数组加链表比使用红黑树查询速度要更快、效率更高。
在HashMap源码有这样一段描述,大致意思是说在理想状态下受随机分布的hashCode影响,链表中的节点遵循泊松分布,节点数是8的概率接近千分之一,这个时候链表的性能很差,所以在这种比较罕见和极端的情况下才会把链表转变为红黑树,大部分情况下HashMap还是使用链表,如果理想情况下,均匀分布,节点数不到8就已经自动扩容了。
1.7版本和1.8版本的差异
jdk1.7的hashmap有二个无法忽略的问题。
-
第一个是扩容的时候需要rehash操作,将所有的数据重新计算HashCode,然后赋给新的HashMap,rehash的过程是非常耗费时间和空间的。
-
第二个是当并发执行扩容操作时会造成环形链和数据丢失的情况,开多个线程不断进行put操作,当旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,就是因为头插法,所以最后的结果打乱了插入的顺序,就有可能发生环形链和数据丢失的问题,引起死循环,导致CPU利用率接近100%。
在JDK1.8中,对HashMap这二点进行了优化。
-
第一点是经过rehash之后元素的位置,要么是在原位置,要么是原位置+原数组长度。不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了。在数组的长度扩大到原来的2倍, 4倍,8倍时,在resize(也就是length - 1)这部分,相当于在高位新增一个或多个1bit。
举个例子,hashmap默认的初始长度是16,负载因子是0.75,当元素被使用75%以上时,触发扩容操作,并且每次扩容一倍。扩容时:将旧数组中的元素转换后,填充到新数组中。通过底层获取索引indexfor方法里面有个(length -1)公式,取它的二进制,它的二进制位后八位是0000 1111,扩容二倍到32,通过公式(length -1)取31的二进制,它的后八位0001 1111,可以发现它的高位进的是1,然后和原来的hash码进行与操作,这样元素在数组中映射的位置要么不变,要不就是在原位置再移动2次幂的位置。
高位上新增的是1的话索引变成原位置+原数组长度,是0的话索引没变。这样既省去了重新计算hash值的时间,而且由于高位上新增的1bit是0还是1,可以认为是随机的,复杂度更高,从而让分布性更高些。
-
第二点,发生hash碰撞,不再采用头插法方式,而是直接插入链表尾部,因此不会出现环形链表的情况,但是在多线程环境下,会发生数据覆盖的情况。
举个例子,如果没有hash碰撞的时候,它会直接插入元素。如果线程A和线程B同时进行put操作,刚好这两条不同的数据hash值一样,并且该位置数据为null,线程A进入后还未进行数据插入时挂起,而线程B正常执行,从而正常插入数据,然后线程A获取CPU时间片,此时线程A不用再进行hash判断了,线程A会把线程B插入的数据给覆盖,导致数据发生覆盖的情况,发生线程不安全。
并发修改异常解决方案
HashMap在高并发场景下会出现并发修改异常,导致原因:并发争取修改导致,一个线程正在写,一个线程过来争抢,导致线程写的过程被其他线程打断,导致数据不一致。
-
第一种解决方案:使用HashTable:HashTable是线程安全的,只不过实现代价却太大了,简单粗暴,get/put所有相关操作都是synchronized的,这相当于给整个哈希表加了一把大锁。多线程访问时候,只要有一个线程访问或操作该对象,那其他线程只能阻塞,相当于将所有的操作串行化,在竞争激烈的并发场景中性能就会非常差。
-
第二种解决方案:使用工具类
Collections.synchronizedMap(new HashMap<>());和Hashtable一样,实现上在操作HashMap时自动添加了synchronized来实现线程同步,都对整个map进行同步,在性能以及安全性方面不如ConcurrentHashMap。 -
第三种解决方案:使用写时复制(CopyOnWrite):往一个容器里面加元素的时候,不直接往当前容器添加,而是先将当前容器的元素复制出来放到一个新的容器中,然后新的元素添加元素,添加完之后,再将原来容器的引用指向新的容器,这样就可以对它进行并发的读,不需要加锁,因为当前容器不添加任何元素。利用了读写分离的思想,读和写是不同的容器。缺点也很明显,会有内存占用问题,在复制的时候只是复制容器里的引用,只是在写的时候会创建新对象添加到新容器里,而旧容器的对象还在使用,所以有两份对象内存。会有数据一致性问题,CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。
-
第四种解决方案:使用ConcurrentHashMap:ConcurrentHashMap大量的利用了volatile,CAS等技术来减少锁竞争对于性能的影响。在JDK1.7版本中ConcurrentHashMap避免了对全局加锁,改成了局部加锁(分段锁),分段锁技术,将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问。不过这种结构的带来的副作用是Hash的过程要比普通的HashMap要长。所以在JDK1.8版本中CurrentHashMap内部中的value使用volatile修饰,保证并发的可见性以及禁止指令重排,只不过volatile不保证原子性,使用为了确保原子性,采用CAS(比较交换)这种乐观锁来解决。
加载因子
加载因子是用来判断当前HashMap
加载因子比较大,扩容发生的频率比较低,浪费的空间比较小,发生hash冲突的几率比较大。
- 比如,加载因子是1的时候,hashmap长度为128,实际存储元素的数量在64至128之间时间段比较多,这个时间段发生hash冲突比较多,造成数组中其中一条链表比较长,会影响性能。
加载因子比较小,扩容发生的频率比较高,浪费的空间比较多,发生hash冲突的几率比较小。
- 比如,加载因子是0.5的时候,hashmap长度为128,当数量达到65的时候会触发扩容,扩容后为原理的256,256里面只存储了65个,浪费了。综合了一下,取了一个平均数0.75作为加载因子。
长度恒定为2的n次方
HashMap的数组长度恒定为2的n次方,也就是说只会为16,32,64这种数。即便你给的初始值是13,最后数组长度也会变成16,它会取你传进来的数,最近一个2的n次方的数。这么设计的目的主要是为了解决底层运算后的值可以落到数组的每个下标上面。
hashMap获取索引的方法:
//indexFor中的h是hashCode通过变换之后的值,是一个32位的二进制数
public static int indexFor(int h, int length) {
return h & (length-1);
}
HashMap中运算数组的位置,使用的是length-1,每次扩容会把原数组的长度*2,在二进制上的表现就是高位进1,并且后四位始终都是1111。
初始长度为16的数组,对应的length-1就是15,原数组15二进制后八位为0000 1111。
扩容后的长度为32的数组,对应的length-1就是31,二进制就变成了0001 1111。
再次扩容长度为64的数组,对应的length-1就是63,二进制是0011 1111。
假设hashMap容量为16
hash值&运算:
11001110 11001111 00010011 11110001(hash值)
&
00000000 00000000 00000000 00001111(16-1的2进制)
=
00000000 00000000 00000000 00000001
hash的2进制的后4位和1111比较,hash值的后4位范围是0000-1111之间,与上1111,最后的值是在0000-1111,也就是0-15之间。这样就保证运算后的值可以落到数组的每一个下标。
如果数组长度不是2的幂次,后四位就不可能是1111,0000~1111的一个数和有可能不是1111的数进行&运算,数组的某几位下标就有可能永远不会有值,这就没法保证运算后的值可以落到数组的每个下标上面。
散列均匀分布
hashMap获取索引的indexFor方法里面的h是hashCode通过变换之后的值,是一个32位的二进制数,如果直接用如此长的二进制数和目标length-1直接进行与运算,结果会导致高位会大量丢失。
假如我们以16位为划分,任何两个高16位不一样,低16位一样的数。这两个数的hashCode与length-1做与运算(hashCode & length-1),结果会是一样的,这样的两个数,却产生了相同的hash结果,发生hash冲突。
于是hashMap想到了一种处理方式:底层算法通过让32位hashcode中保持高16位不变,高16与低16异或结果,作为新的低16位,然后用hash得到的结果(int h)传入方法indexFor获取到hashMap的索引。
计算中只有低位16位参与&运算,计算效率高,同时也保证的hash的高16位参与了索引运算,这样得到的索引能呈较为理想的散列分布,在将条目放入hashMap中时,最大限度避免hash碰撞。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);//把hash值异或了hash值右移16位,即取高16位
}
绝大多数情况下length一般都小于2^16即小于65536,所以indexFor方法中return h & (length-1)的结果始终是h的低16位与(length-1)进行&运算。hashmap为了考虑性能的设计还是非常精妙的。
hashmap优化
对hashmap使用的优化,我个人看法有五点。
-
第一点,建议采用短String,Integer这样的类作为键。特别是String,他是不可变的,也是final的,而且已经重写了equals和hashCode方法,契合HashMap要求的计算hashCode的不可变性要求,核心思想就是保证键值的唯一性,不变性,其次是不可变性还有诸如线程安全的问题,这么定义键,可以最大限度的减少碰撞的出现。如果hashCode不冲突,那查找效率很高,但是如果hashCode一旦冲突,要调用equals一个字节一个自己的去比较,key越短效率越高。
-
第二点不使用for循环遍历map,而是使用迭代器遍历Map,使用迭代器遍历entrySet在各个数量级别效率都比较高。
-
第三点使用线程安全的ConcurrentHashMap来删除Map中的元素,或者在迭代器Iterator遍历时,使用迭代器iterator.remove()来删除元素。不可以for循环遍历删除,否则会产生并发修改异常CME。
-
第四点考虑加载因子地设定初始大小,设定时一定要考虑加载因子的存在,使用的时候最好估算存储的大小。可以使用
Maps.newHashMapWithExpectedSize(预期大小)来创建一个HashMap,计算的过程guava会帮我们完成,Guava的做法是把默认容量的数字设置成预期大小 / 0.75F + 1.0F。 -
第五点减小加载因子,如果Map是一个长期存在而不是每次动态生成的,而里面的key又是没法预估的,那可以适当加大初始大小,同时减少加载因子,降低冲突的机率。毕竟如果是长期存在的map,浪费点数组大小不算啥,降低冲突概率,减少比较的次数更重要。
Fail-safe机制/Fail-fast机制
Fail-safe和Fail-fast,是多线程并发操作集合时的一种失败处理机制。
Fail-fast : 表示快速失败,在集合遍历过程中,一旦发现容器中的数据被修改了,会立刻抛出ConcurrentModificationException异常,从而导致遍历失败,像这种情况
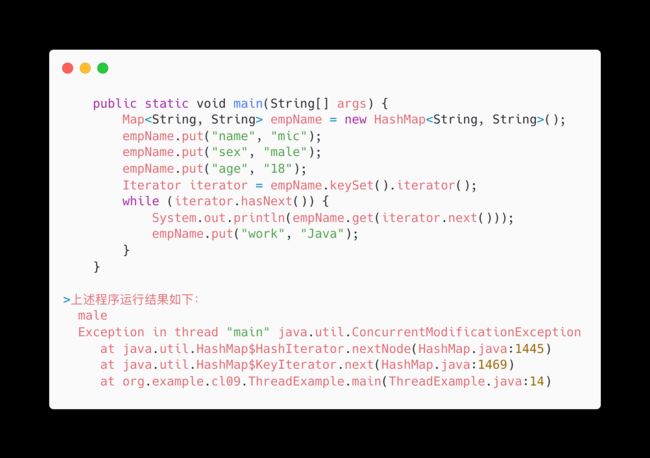 定义一个Map集合,使用Iterator迭代器进行数据遍历,在遍历过程中,对集合数据做变更时,就会发生Fail-fast。
定义一个Map集合,使用Iterator迭代器进行数据遍历,在遍历过程中,对集合数据做变更时,就会发生Fail-fast。
java.util包下的集合类都是快速失败机制的, 常见的的使用Fail-fast方式遍历的容器有HashMap和ArrayList等。
Fail-safe:表示失败安全,也就是在这种机制下,出现集合元素的修改,不会抛出ConcurrentModificationException。
原因是采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,
在拷贝的集合上进行遍历。由于迭代时是对原集合的拷贝进行遍历,所以在遍历过程中对原集合所作的修改并不能被迭代器检测到
比如这种情况
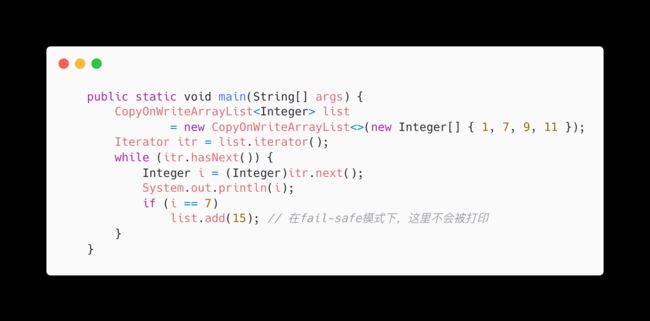
定义了一个CopyOnWriteArrayList,在对这个集合遍历过程中,对集合元素做修改后,不会抛出异常,但同时也不会打印出增加的元素。
java.util.concurrent包下的容器都是安全失败的,可以在多线程下并发使用,并发修改。
常见的的使用Fail-safe方式遍历的容器有ConcerrentHashMap和CopyOnWriteArrayList等。
Synchronized
Synchronized是Java高频面试题,相关的知识点其实有很多,更为详细的Synchronized知识点,我也有写,全部讲一遍,差不多要一个小时以上,有时间的同学可以去看看,这里提供地址:https://liaozhiwei.blog.csdn.net/article/details/124900072,面试官想问的主要是锁的升级过程,下面由浅到深讲解,专门针对面试题,归总的知识点列举出来。
定义
Synchronized是Java语言的关键字,它保证同一时刻被Synchronized修饰的代码最多只有1个线程执行。
应用场景
synchronized如果加在方法上/对象上,那么,它作用的对象是非静态的,它取得的锁是对象锁;
synchronized如果作用的对象是一个静态方法或一个类,它取到的锁是类锁,这个类所有的对象用的是同一把锁。
每个对象只有一个锁,谁拿到这个锁,谁就可以运行它所控制的那段代码。
对象加锁实现原理
在Java的设计中,每一个Java对象就带了一把看不见的锁,可以叫做内部锁或者Monitor锁,Synchronized在JVM里的实现是基于进入和退出Monitor对象来实现方法同步和代码块同步的。Monitor可以把它理解为一个同步工具,所有的Java对象是天生的Monitor,Monitor监视器对象就是存在于每个Java对象的对象头MarkWord里面,也就是存储指针的指向,Synchronized锁便是通过这种方式获取锁的。
JDK6以前
Synchronized加锁是通过对象内部的监视器锁来实现的,监视器锁本质又是依赖于底层的操作系统的Mutex Lock来实现的,操作系统实现线程之间的切换这就需要从用户态转换到核心态,这个成本非常高,状态之间的转换需要比较长的时间。
实现步骤
第一步,当有二个线程A、线程B都要开始给变量+1,要进行操作的时候,发现方法上加了Synchronized锁,这时线程调度到A线程执行,A线程就抢先拿到了锁,当前已经获取到锁资源的线程被称为Owner,将MonitorObject中的_owner设置成A线程。
第二步,将mark word设置为Monitor对象地址,锁标志位改为10;
第三步,将B线程阻塞,放到ContentionList队列中。因为JVM每次从Waiting Queue的尾部取出一个线程放到OnDeck中,作为候选者,但是如果并发比较高,WaitingQueue会被大量线程执行CAS操作,为了降低对尾部元素的竞争,将WaitingQueue拆分成ContentionList和EntryList二个队列,所有请求锁的线程首先尝试自旋获取锁,如果获取不到,被放在ContentionList这个竞争队列中,ContentionList中那些有资格成为候选资源的线程被移动到EntryList中。ContentionList、EntryList、WaitSet中的线程都处于阻塞状态,该阻塞是由操作系统来完成的,Linux内核下采用pthread_mutex_lock内核函数实现的。
第四步,作为Owner的A线程执行过程中,可能调用wait释放锁,这个时候A线程进入WaitSet,等待被唤醒。
JDK6版本及以后
Sun程序员发现大部分程序大多数时间都不会发生多个线程同时访问竞态资源的情况,大多数对象的加锁和解锁都是在特定的线程中完成,出现线程竞争锁的情况概率比较低,比例非常高,所以引入了偏向锁和轻量级锁。
64位JVM下的对象结构描述:
 对象头的最后两位存储了锁的标志位
对象头的最后两位存储了锁的标志位
没加锁状态,锁标志位01,是否偏向是0,对象头里存储的是对象本身的哈希码。
偏向锁状态,锁标志位01,是否偏向是1,存储的是当前占用对象的线程ID。
轻量级锁状态,锁标志位00,存储指向线程栈中锁记录的指针。
重量级锁状态,锁标志位10,存储的就是重量级锁的指针了。
对象从无锁到偏向锁转化的过程
第一步,检测MarkWord是否为可偏向状态,是偏向锁是1,锁标识位是01。
第二步,如果是可偏向状态,测试线程ID是不是当前线程ID。如果是,就直接执行同步代码块。
第三步,如果测试线程ID不是当前线程ID,就通过CAS操作竞争锁,竞争成功,就把MarkWord的线程ID替换为当前线程ID。
第四步,如果CAS竞争锁失败,证明有别的线程持有锁,假设线程B来CAS失败了,这个时候启动偏向锁撤销(revokebias),让A线程在全局安全点阻塞,获得偏向锁的线程被挂起,有点类似于GC前线程在安全点阻塞。
第五步,接着遍历线程栈,查看有没有锁对象的锁记录LockRecord,如果有LockRecord,需要修复锁记录和Markword,让它变成无锁状态。恢复A线程,将是否为偏向锁状态改为0,偏向锁升级为轻量级锁,然后被阻塞在安全点的线程,继续往下执行同步代码块。
安全点是jvm为了保证在垃圾回收的过程中引用关系不会发生变化,设置的安全状态,在这个状态上会暂停所有线程工作。一般有循环的末尾,方法临返回前,调用方法的call指令后,可能抛异常的位置,这些位置都可以算是安全点。
轻量级锁升级
轻量级锁升级过程是,在当前线程的栈帧中建立一个名为锁记录的空间,用于存储锁对象目前的MarkWord的拷贝,拷贝无锁状态对象头中的MarkWord复制到锁记录中。
- 这么做是因为在申请对象锁时,需要以该值作为CAS的比较条件。
- 同时在升级到重量级锁的时候,能通过这个比较,判定是否在持有锁的过程中,这个锁被其他线程申请过,如果被其他线程申请了,在释放锁的时候要唤醒被挂起的线程。
- 无锁的markword中可能存有hashCode,锁撤销之后必须恢复,这个markword要用于锁撤销后的还原。如果轻量级锁解锁为无锁状态,直接将拷贝的markword CAS修改到锁对象的markword里面就可以了。
拷贝成功后,虚拟机将使用CAS操作把对象中对象头MarkWord替换为指向锁记录的指针,然后把锁记录空间里的owner指针指向加锁的对象,如果这个更新动作成功了,那么当前线程就拥有了该对象的锁,并且对象MarkWord的锁标志位设置为“00”,即表示此对象处于轻量级锁定状态。
如果这个更新操作失败了,虚拟机首先会检查对象MarkWord中的Lock Word是否指向当前线程的栈帧,如果是,就说明当前线程已经拥有了这个对象的锁,那就可以直接进入同步块继续执行。如果不是说明多个线程竞争锁,进入自旋,若自旋结束时仍未获得锁,轻量级锁就要膨胀为重量级锁,锁标志的状态值变为“10”,MarkWord中存储的就是指向重量级锁(互斥量)的指针,当前线程以及后面等待锁的线程也要进入阻塞状态。
当锁升级为轻量级锁之后,如果依然有新线程过来竞争锁,首先新线程会自旋尝试获取锁,尝试到一定次数(默认10次)依然没有拿到,锁就会升级成重量级锁。一般来说,同步代码块内的代码应该很快就执行结束,这时候线程B自旋一段时间是很容易拿到锁的,但是如果不巧,没拿到,自旋其实就是死循环,很耗CPU的,因此就直接转成重量级锁咯,这样就不用了线程一直自旋了。
自旋锁
自旋锁不是一种锁状态,而是一种策略。线程的阻塞和唤醒需要CPU从用户态转为核心态,频繁的阻塞和唤醒对CPU来说是一件负担很重的工作。
引入自旋锁,当一个线程尝试获取某个锁时,如果该锁已被其他线程占用,就一直循环检测锁是否被释放,而不是进入线程挂起或睡眠状态。自旋等待不能替代阻塞,虽然它可以避免线程切换带来的开销,但是它占用了CPU处理器的时间。
自旋锁适用于锁保护的临界区很小的情况,临界区很小的话,锁占用的时间就很短。如果持有锁的线程很快就释放了锁,那么自旋的效率就非常好。
自旋的次数必须要有一个限度,如果自旋超过了定义的限度仍然没有获取到锁,就应该被挂起。但是这个限度不能固定,程序锁的状况是不可预估的,所以JDK1.6引入自适应的自旋锁,线程如果自旋成功了,那么下次自旋的次数会更加多,因为虚拟机认为既然上次成功了,那么此次自旋也很有可能会再次成功,那么它就会允许自旋等待持续的次数更多。如果对于某个锁,很少有自旋能够成功,那么在以后要或者这个锁的时候自旋的次数会减少,甚至省略掉自旋过程,以免浪费处理器资源。
通过–XX:+UseSpinning参数来开启自旋(JDK1.6之前默认关闭自旋)。
通过–XX:PreBlockSpin修改自旋次数,默认值是10次。
重量级锁
当一个线程在等锁时会不停的自旋(底层就是一个while循环),当自旋的线程达到CPU核数的1/2时,就会升级为重量级锁。
将锁标志为置为10,将MarkWord中指针指向重量级的monitor,阻塞所有没有获取到锁的线程。
Synchronized是通过对象内部的监视器锁(Monitor)来实现的,监视器锁本质又是依赖于底层的操作系统的MutexLock来实现的,操作系统实现线程之间的切换这就需要从用户态转换到核心态,状态之间的转换需要比较长的时间,这就是为什么Synchronized效率低的原因,这种依赖于操作系统MutexLock所实现的锁我们称之为“重量级锁”。
重量级锁的加锁-等待-撤销流程:
曾经获得过锁的线程,被唤醒后,优先得到锁。
举个例子,假设有A,B,C三个线程依次进入synchronized区,并且A已经膨胀成重量级锁。如果有一个线程 a 先进入 synchronized , 但是调用了 wait释放锁,这是线程 b 进入了 synchronized,b还在synchronized中执行,c线程又进来了。此时 a 在 wait_set ,b 不在任何队列,c 在 cxq_list ,假如 b 调用 notify唤醒线程,会把 a 插到 c 前面,也就是 b 退出synchronized的时候,会唤醒 a,a退出之后再唤醒 c。
重量级锁撤销之后是无锁状态,撤销锁之后会清除创建的monitor对象并修改markword,这个过程需要一段时间。Monitor对象是通过GC来清除的。GC清除掉monitor对象之后,就会撤销为无锁状态。
引入偏向锁的好处
-
偏向锁的好处是并发度很低的情况下,同一个线程获取锁不需要内存拷贝的操作,免去了轻量级锁的在线程栈中建LockRecord,拷贝MarkDown的内容。
-
免了重量级锁的底层操作系统用户态到内核态的切换,节省毫无意义的请求锁的时间。
-
另外Hotspot也做了另一项优化,基于锁对象的epoch批量偏移和批量撤销偏移,这样大大降低了偏向锁的CAS和锁撤销带来的损耗。因为基于epoch批量撤销偏向锁和批量加偏向锁能大幅提升吞吐量,但是并发量特别大的时候性能就没有什么特别的提升了。
-
偏向锁减少CAS操作,降低Cache一致性流量,CAS操作会延迟本地调用。
为什么这么说呢?这要从SMP(对称多处理器)架构说起,所有的CPU会共享一条系统总线BUS,靠此总线连接主内存,每个核都有自己的一级缓存,每个核相对于BUS对称分布。
举个例子,我电脑是六核的,假设一个核是Core1,一个核是Core2,这二个核可能会同时把主存中某个位置的值Load到自己的一级缓存中。当Core1在自己的L1Cache中修改这个位置的值时,会通过总线,使Core2中L1Cache对应的值“失效”,而Core2一旦发现自己L1Cache中的值失效,也就是所谓的Cache命中缺失,一旦发现失效就会通过总线从内存中加载该地址最新的值,大家通过总线的来回通信叫做“Cache一致性流量”。如果Cache一致性流量过大,总线将成为瓶颈。而当Core1和Core2中的值再次一致时,称为“Cache一致性”,从这个层面来说,锁设计的终极目标便是减少Cache一致性流量。而CAS恰好会导致Cache一致性流量,如果有很多线程都共享同一个对象,当某个CoreCAS成功时必然会引起总线风暴,这就是所谓的本地延迟。
所以偏向锁比较适用于只有一个线程访问同步块场景。
引入轻量级的好处
对于绝大部分的锁,在整个同步周期内都是不存在竞争的。如果没有竞争,轻量级锁通过CAS操作成功,避免了使用互斥量的开销。
对于竞争的线程不会阻塞,提高了程序的响应速度。
如果确实存在锁竞争,始终得不到锁竞争的线程使用自旋会消耗CPU,除了互斥量的本身开销外,还额外发生了CAS操作的开销,轻量级锁反而会比传统的重量级锁更慢。
所以轻量级追求的是响应时间,同步块执行速度非常快的场景。
ThreadLocal
定义
ThreadLocal叫做线程变量,这个变量对其他线程而言是隔离的,是当前线程独有的变量。ThreadLocal为变量在每个线程中都创建了一个副本,每个线程可以访问自己内部的副本变量。
ThreadLocal与Synchronized的区别
1、Synchronized用于线程间的数据共享,ThreadLocal用于线程间的数据隔离。
2、Synchronized是利用锁的机制,让变量或代码块在某一时该只能被一个线程访问,用于在多个线程间通信时能够获得数据共享。ThreadLocal为每一个线程都提供了变量的副本,让每个线程在某一时间访问到的并不是同一个对象,这样就隔离了多个线程对数据的数据共享。
底层实现
在 Thread 类中嵌入一个 ThreadLocalMap,ThreadLocalMap 就是一个容器,存储的就是这个 Thread 类专享的数据。
ThreadLocalMap底层结构
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
……
}
ThreadLocal在保存的时候会把自己当做Key存在ThreadLocalMap中,key被设计成WeakReference弱引用了。
ThreadLocalMap的key设计成弱引用,主要是为了避免内存泄漏的情况。如果 threadlocalmap 的 key 是强引用, 那么只要线程存在, threadlocalmap 就存在, 而 threadlocalmap 结构就是 entry 数组. 即对应的 entry 数组就存在, 而 entry 数组元素的 key 是 threadLocal.即便我们在代码中显式赋值 threadlocal 为 null, 告诉 gc 要垃圾回收该对象. 由于上面的强引用存在, threadlocal 即便赋值为 null, 只要线程存在, threadlocal 并不会被回收。
而设置为弱引用, gc 扫描到时, 发现ThreadLocal在没有外部强引用时,发生GC时会被回收,如果创建ThreadLocal的线程一直持续运行,那么这个Entry对象中的value就有可能一直得不到回收,发生内存泄露。所以在代码最后都需要用remove把值清空。
remove的源码很简单,找到对应的值全部置空,这样在垃圾回收器回收的时候,会自动把他们回收掉。
并且 threadlocal 的 set get remove 都会判断是否 key 为 null, 如果为 null, 那么 value 的也会移除, 之后会被 gc 回收。
结构大致这样:
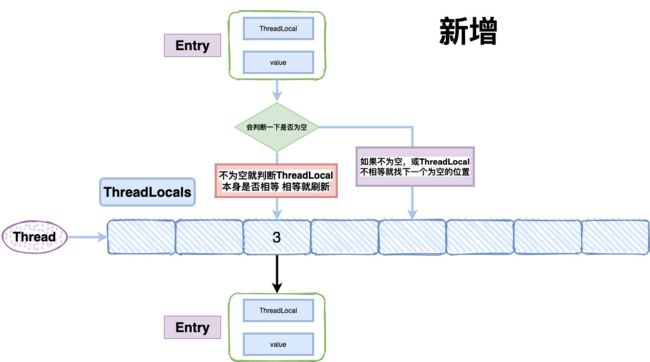
ThreadLocalMap存储元素的过程
ThreadLocalMap在存储的时候会给每一个ThreadLocal对象一个threadLocalHashCode,在插入过程中,根据ThreadLocal对象的hash值,定位到table中的位置,如果当前位置是空的,就初始化一个Entry对象放在位置上。如果位置不为空,如果这个Entry对象的key正好是即将设置的key,那么就刷新Entry中的value。如果位置不为空,而且key不等于entry,那就找下一个空位置,直到为空为止。在get的时候,也会根据ThreadLocal对象的hash值,定位到table中的位置,然后判断该位置Entry对象中的key是否和get的key一致,如果不一致,就判断下一个位置。这种方式在不使用链表的情况下,解决了hash冲突。
ThreadLocal实现线程隔离的原理
ThreadLocal实现线程隔离主要是设置值和获取值的时候,就已经保证了它是线程隔离了。
设置值的代码:
public void set(T value) {
Thread t = Thread.currentThread();// 获取当前线程
ThreadLocalMap map = getMap(t);// 获取ThreadLocalMap对象
if (map != null) // 校验对象是否为空
map.set(this, value); // 不为空set
else
createMap(t, value); // 为空创建一个map对象
}
设置值先是获取当前线程对象,然后从当前线程中获取线程的ThreadLocalMap,判断这个对象是不是空的,如果是空的,就创建一个空的map对象,如果不为空,就重新设值。key就是当前ThreadLocal 的对象,值是添加到这个ThreadLocalMap中的,它是存储在线程内部,然后关联了对应的ThreadLocal。
ThreadLocalMap是当前线程Thread一个叫threadLocals的变量中获取的
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
public class Thread implements Runnable {
……
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;
/*
* InheritableThreadLocal values pertaining to this thread. This map is
* maintained by the InheritableThreadLocal class.
*/
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
……
每个线程Thread都维护了自己的threadLocals变量,所以在每个线程创建ThreadLocal的时候,实际上数据是存在自己线程Thread的threadLocals变量里面的,别人没办法拿到,从而实现了隔离。
通过ThreadLocal.get 时就能获取到对应的值。
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
AQS
AQS的全称是AbstractQueuedSynchronizer,也就是抽象队列同步器,它是在java.util.concurrent.locks包下的,也就是JUC并发包。java提供了synchronized关键字内置锁,还提供了显示锁,而大部分的显示锁的底层都用到了AQS,比如只有一个线程能执行ReentrantLock独占锁,又比如多个线程可以同时执行共享锁Semaphore、CountDownLatch、ReadWriteLock、CyclicBarrier。
同步器自身没有实现任何同步接口,它仅仅是定义了同步状态获取和释放的方法,提供自定义同步组件使用,子类通过继承同步器,实现它的抽象方法来管理同步状态。使用模板方法模式,使用者继承AbstractQueuedSynchronizer,重写指定的方法,重写的方法就是对于共享资源state的获取和释放,在自定义同步组件里调用它的模板方法,这些模板方法会调用使用者重写的方法,这是模板方法模式很经典的一个运用。
同步器依赖内部的一个FIFO双向同步队列来完成同步状态的管理,当前线程获取同步状态失败时,同步器会将当前线程以及等待状态等信息构造成为一个节点并将其加入同步队列,同时会阻塞当前线程。当同步状态释放时,会把首节点中的线程唤醒,使其再次尝试获取同步状态。
同步器拥有首节点和尾节点,首节点是获取同步状态成功的节点,首节点的线程在释放同步状态时,将会唤醒后继节点, 而后继节点将会在获取同步状态成功时将自己设置为首节点,没有成功获取同步状态的线程会成为节点,加入该队列的尾部。
独占锁举例
拿ReentrantLock加锁举例,线程调用ReentrantLock的lock()方法进行加锁,这个加锁的过程,用CAS将state值从0变为1。一旦线程加锁成功了之后,就可以设置当前加锁线程是自己。ReentrantLock通过多次执行lock()加锁和unlock()释放锁,对一个锁加多次,从而实现可重入锁,每次线程可重入加锁一次,判断一下当前加锁线程是不是自己,如果是他自己就可以可重入多次加锁,每次加锁,就是把state的值给累加1。
当state=1时代表当前对象锁已经被占用,其他线程来加锁时则会失败,然后再去看加锁线程的变量里面是不是自己之前占用过这把锁,如果不是就说明有其他线程占用了这个锁,失败的线程被放入一个等待队列中,在等待唤醒的时候,经常会使用自旋(while(!cas()))的方式,不停地尝试获取锁,等待已经获得锁的线程,释放锁才能被唤醒。
当它释放锁的时候,将AQS内的state变量的值减1,如果state值为0,就彻底释放锁,会将“加锁线程”变量设置为null。这个时候,会从等待队列的队头唤醒其他线程重新尝试加锁,获得锁成功之后,会把“加锁线程”设置为线程自己,同时线程自己就从等待队列中出队。
底层实现独占锁
public final void acquice(int arg){
//同步状态获取、节点构造、加入同步队列以及在同步队列中自旋等待
if(!tryAcquirce(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE),arg)){
selfInterrupt();
}
}
首先调用自定义同步器实现的tryAcquire方法,保证线程安全的获取同步状态。
如果同步状态获取成功直接退出返回。
如果同步状态获取失败,就构造同步节点,通过addWaiter方法把这个节点加入到同步队列的尾部。
最后调用acquireQueued方法,让节点自旋的获取同步状态。
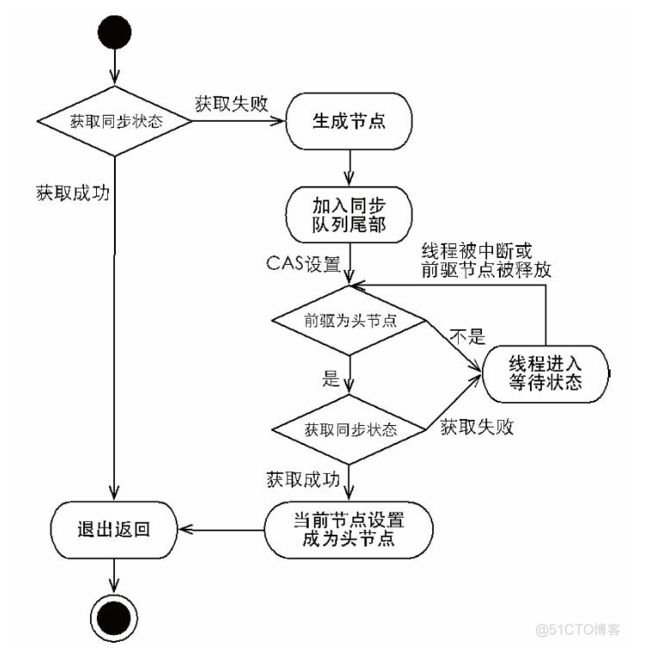
这个就是aqs实现独占锁的底层实现。
超时获取锁
在Java 5之前,当一个线程获取不到锁而被阻塞在synchronized之外时,对该线程进行中断操作,此时这个线程的中断标志位会被修改,但线程依旧会阻塞在synchronized上,等待着获取锁。
Java 5中,在等待获取同步状态时,如果当前线程被中断,会立刻返回,并抛出InterruptedException。
后续的版本又进行了优化,提供了超时获取同步状态过程,可以被当作响应中断,是获取同步状态过程的“增强版”, doAcquireNanos方法在支持响应中断的基础上,增加了超时获取的特性。
针对超时获取,主要需要计算出需要睡眠的时间间隔nanosTimeout,为了防止过早通知, nanosTimeout计算公式为:
nanosTimeout = now-lastTime,其中now为当前唤醒时间,lastTime为上次唤醒时间。
如果 nanosTimeout大于0则表示超时时间未到,需要继续睡眠nanosTimeout纳秒, 否则,表示已经超时。
如果nanosTimeout小于等于1000纳秒时, 将不会使该线程进行超时等待,而是进入快速的自旋过程。
原因在于,非常短的超时等待,无法做到十分精确,如果这时再进行超时等待,相反会让nanosTimeout的超时从整体上表现得反而不精确。因此,在超时非常短的场景下,同步器会进入无条件的快速自旋。
共享锁举例
拿CountDownLatch举例,任务分为5个子线程去执行,state也初始化为5。这5个子线程是并行执行的,每个子线程执行完后countDown()一次,state会CAS减1,等到所有子线程都执行完后,state=0,会unpark()主调用线程,然后主调用线程就会从await()函数返回,继续后余动作。
共享锁实现原理
共享式获取与独占式获取最主要的区别在于同一时刻能否有多个线程同时获取到同步状态。通过调用同步器的acquireShared方法可以共享式地获取同步状态,只要方法里面的tryAcquireShared方法返回值大于等于0,就可以成功获取到同步状态并退出自旋。对于能够支持多个线程同时访问的并发组件,它和独占式主要区别在于 tryReleaseShared方法必须确保同步状态线程安全释放,一般是通过循环和CAS来保证的,因为释放同步状态的操作可能会同时来自多个线程。
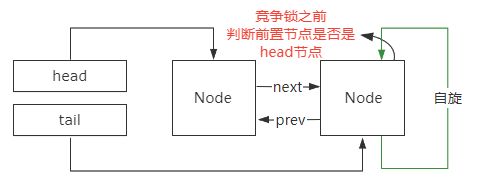
AQS为什么要使用双向链表
首先,双向链表的特点是它有两个指针,一个指针指向前置节点,一个指针指向后继节点。
所以,双向链表可以支持 常量O(1) 时间复杂度的情况下找到前驱结点,基于这样的特点。
双向链表在插入和删除操作的时候,要比单向链表简单、高效。
因此,从双向链表的特性来看,我认为AQS使用双向链表有三个方面的考虑。
-
第一个方面,没有竞争到锁的线程加入到阻塞队列,并且阻塞等待的前提是,当前线程所在节点的前置节点是正常状态,
这样设计是为了避免链表中存在异常线程导致无法唤醒后续线程的问题。
所以线程阻塞之前需要判断前置节点的状态,如果没有指针指向前置节点,就需要从head节点开始遍历,性能非常低。
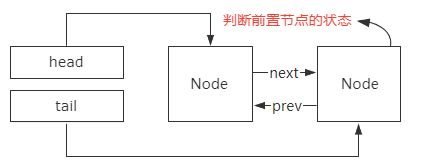
-
第二个方面,在Lock接口里面有一个,lockInterruptibly()方法,这个方法表示处于锁阻塞的线程允许被中断。也就是说,没有竞争到锁的线程加入到同步队列等待以后,是允许外部线程通过interrupt()方法触发唤醒并中断的。
这个时候,被中断的线程的状态会修改成CANCELLED。被标记为CANCELLED状态的线程,是不需要去竞争锁的,但是它仍然存在于双向链表里面。意味着在后续的锁竞争中,需要把这个节点从链表里面移除,否则会导致锁阻塞的线程无法被正常唤醒。在这种情况下,如果是单向链表,就需要从Head节点开始往下逐个遍历,找到并移除异常状态的节点。同样效率也比较低,还会导致锁唤醒的操作和遍历操作之间的竞争。
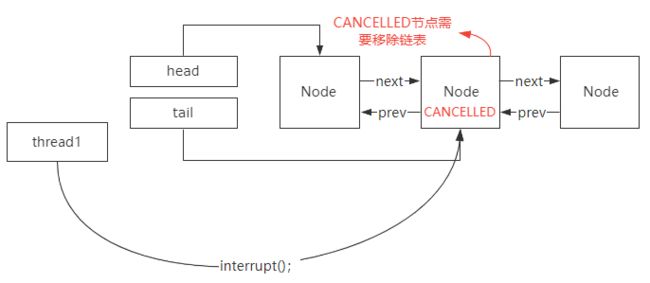
-
第三个方面,为了避免线程阻塞和唤醒的开销,所以刚加入到链表的线程,首先会通过自旋的方式尝试去竞争锁。但是实际上按照公平锁的设计,只有头节点的下一个节点才有必要去竞争锁,后续的节点竞争锁的意义不大。否则,就会造成羊群效应,也就是大量的线程在阻塞之前尝试去竞争锁带来比较大的性能开销。所以为了避免这个问题,加入到链表中的节点在尝试竞争锁之前,需要判断前置节点是不是头节点,如果不是头节点,就没必要再去触发锁竞争的动作。所以这里会涉及到前置节点的查找,如果是单向链表,那么这个功能的实现会非常复杂。
线程池
底层运行原理
线程池就是控制运行的线程数量,处理过程中将任务放到队列,然后在线程创建后启动这些任务,如果线程数量超出了最大数量就排队等候,等其他线程执行完毕再从队列中取出任务执行。
线程池相当于银行网点,常驻核心数相当于今日当值窗口,线程池能够同时执行的最大线程数相当于银行所有的窗口,任务队列相当于银行的候客区,当今日当值窗口满了,多出来的客户去候客区等待,当候客区满了,银行加开窗口,候客区先来的客户去加班窗口,当银行所有的窗口满了,其他客户在候客区等待,同时拒绝其他客户进入银行。当用户少了,加班的窗口等待时间(相当于多余线程存活的时间)(等待时间的单位相当于unit参数)假设超过一个小时还是没有人来,就取消加班的窗口。
七大核心参数
底层在创建线程池的时候有七个参数:核心线程数,同时执行的最大线程数,多余线程存活时间,单位时间秒,任务队列,默认线程工厂,拒绝策略
maximumPoolsize:同时执行的最大线程数
keepAliveTime:多余线程存活时间,当前线程池数量超过核心线程数时,当前空闲时间达到多余线程存活时间的值的时候,多余空闲线程会被销毁到只剩核心线程数为止
unit:多余线程存活时间的单位
workQueue:任务队列,被提交但尚未被执行的任务
threadFactory:生成线程池的线程工厂
handler:拒绝策略,当队列满了并且工作线程数量大于线程池的最大线程数时,提供拒绝策略。
如何合理的配置核心线程数?
对于CPU密集型任务,由于CPU密集型任务的性质,导致CPU的使用率很高,如果线程池中的核心线程数量过多,会增加上下文切换的次数,带来额外的开销。因此,考虑到CPU密集型任务因为某些原因而暂停,这个时候有额外的线程能确保CPU这个时刻不会浪费,还可以增加一个CPU上下文切换。一般情况下:线程池的核心线程数量等于CPU核心数+1。例如需要大量的计算,视频渲染啊,仿真啊之类的。这个时候CPU就卯足了劲在运行,这个时候切换线程,反而浪费了切换的时间,效率不高。打个比方,你的大脑是CPU,你本来就在一本心思地写作业,多线程这时候就是要你写会作业,然后立刻敲一会代码,然后在P个图,然后在看个视频,然后再切换回作业。emmmm,过程中你还需要切换(收起来作业,拿出电脑,打开VS…)那你的作业怕是要写到挂科。这个时候你就该一门心思地写作业。
对于I/O密集型任务,由于I/O密集型任务CPU使用率并不是很高,可以让CPU在等待I/O操作的时去处理别的任务,充分利用CPU。一般情况下:线程的核心线程数等于2*CPU核心数。例如你需要陪小姐姐或者小哥哥聊天,还需要下载一个VS,还需要看博客。打个比方,小姐姐给你发消息了,回一下她,然后呢?她给你回消息肯定需要时间,这个时候你就可以搜索VS的网站,先下安装包,然后一看,哎呦,她还没给你回消息,然后看会自己的博客。小姐姐终于回你了,你回一下她,接着看我的博客,这就是类似于IO密集型。你可以在不同的“不烧脑”的工作之间切换,来达到更高的效率。而不是小姐姐不回我的信息,我就干等,啥都不干,就等,这个效率可想而知,也许,小姐姐根本就不会回复你。
对于混合型任务,由于包含2种类型的任务,故混合型任务的线程数与线程时间有关。在某种特定的情况下还可以将任务分为I/O密集型任务和CPU密集型任务,分别让不同的线程池去处理。一般情况下:线程池的核心线程数=(线程等待时间/线程CPU时间+1)*CPU核心数;
并发高、业务执行时间长,解决这种类型任务的关键不在于线程池而在于整体架构的设计,看看这些业务里面某些数据是否能做缓存是第一步,我们的项目使用的时redis作为缓存(这类非关系型数据库还是挺好的)。增加服务器是第二步(一般政府项目的首先,因为不用对项目技术做大改动,求一个稳,但前提是资金充足),至于线程池的设置,设置参考 2 。最后,业务执行时间长的问题,也可能需要分析一下,看看能不能使用中间件(任务时间过长的可以考虑拆分逻辑放入队列等操作)对任务进行拆分和解耦。
拒绝策略
第一种拒绝策略:AbortPolicy:超出最大线程数,直接抛出RejectedExecutionException异常阻止系统正常运行。可以感知到任务被拒绝了,于是你便可以根据业务逻辑选择重试或者放弃提交等策略。
第二种拒绝策略:该策略既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者,相当于当线程池无能力处理当前任务时,会将这个任务的执行权交予提交任务的线程来执行,也就是谁提交谁负责,从而降低新任务的流量。(谁调用了你,到达最大线程数时,你回去找调用你的人,然后听从调用你的人安排)(超出的我们能办的给你办,不能办的给你回退 )这样的话提交的任务就不会被丢弃而造成业务损失,如果任务比较耗时,那么这段时间内提交任务的线程也会处于忙碌状态而无法继续提交任务,这样也就减缓了任务的提交速度,这相当于一个负反馈,也有利于线程池中的线程来消化任务。这种策略算是最完善的相对于其他三个。
第三拒绝策略:DiscardOldestPolicy:抛弃队列中等待最久的任务,也就是它丢弃的是队列中的头节点,然后把当前任务加入队列中尝试再次提交当前任务。
第四种拒绝策略:DiscardPolicy:直接丢弃任务,不予任何处理也不抛异常,当任务提交时直接将刚提交的任务丢弃,而且不会给与任何提示通知。
实际创建线程池
java.util.concurrent 包里提供的 Executors 也可以用来创建线程池
- newSingleThreadExecutos 单线程线程池,也就是线程池只有一个任务,这个我偶尔用一用
- newFixedThreadPool(int nThreads) 固定大小线程的线程池
- newCachedThreadPool() 无界线程池,这个就是无论多少任务,都创建线程来运行,所以队列相当于没用。
在实际使用的时候,选择线程池的时候尽量不用JDK提供的三种常见的创建方式
第一是 Executors 提供的线程池使用场景很有限,一般场景很难用到
第二他们也都是通过 ThreadPoolExecutor 创建的线程池,我直接用 ThreadPoolExecutor 创建线程池,可以理解原理,灵活度更高。
第三因为它的底层队列是Linked这个接近于无界,非常大,这样会堆积大量的请求,从而导致OOM,阿里巴巴开发手册推荐我们使用ThreadPoolExecutor去创建线程池。
内存模型
JDK1.6、JDK1.7、JDK1.8 内存模型演变
JDK 1.6:有永久代,静态变量存放在永久代上。
JDK 1.7:有永久代,但已经把字符串常量池、静态变量,存放在堆上。逐渐的减少永久代的使用。
JDK 1.8:无永久代,运行时常量池、类常量池,都保存在元数据区,也就是常说的元空间。但字符串常量池仍然存放在堆上。

Java虚拟机栈
每一个方法在执行的同时,都会创建出一个栈帧,用于存放局部变量表、操作数栈、动态链接、方法出口、线程等信息。方法从调用到执行完成,都对应着栈帧从虚拟机中入栈和出栈的过程。最终,栈帧会随着方法的创建到结束而销毁。

堆和元空间
在 JDK 1.8 之后就不在堆上分配方法区了,元空间从虚拟机Java堆中转移到本地内存,默认情况下,元空间的大小仅受本地内存的限制,说白了也就是以后不会因为永久代空间不够而抛出OOM异常出现了。jdk1.8以前版本的 class和JAR包数据存储在 PermGen下面 ,PermGen 大小是固定的,而且项目之间无法共用,公有的 class,所以比较容易出现OOM异常。

内存屏障
什么是内存屏障:内存屏障是一条指令,该指令可以对编译器和处理器的指令重排做出一定的限制,比如,一条内存屏障指令可以禁止编译器和处理器将其后面的指令移到内存屏障指令之前。
为什么需要内存屏障:编译器和处理器指令重排只能保证在单线程执行下逻辑正确,在多个线程同时读写多个变量的情况下,如果不对指令重排作出一定限制,代码的执行结果会根据指令重排后的顺序产生不同的结果。指令重排后的顺序每次执行时都可能不一样,显然我们希望我们的代码执行结果与代码顺序是逻辑一致的,所以我们需要内存屏障。
Class文件结构
字节码结构有:魔数,副版本号,主版本号,常量池容量计数器,访问标志,类索引,父类索引,接口索引集合,字段表,方法表,属性表等。
拿魔数来说,它是用来区分文件类型的一种标志,会占用开头的4个字节,之所以需要魔数来区分文件类型,是因为文件名后缀容易被修改,所以为了保证文件的安全性,将文件类型写在文件内部可以保证不被篡改。
魔数后面的4位就是版本号,也是4个字节,前2个字节表示次版本号,后2个字节表示主版本号,这二个版本号是为了标注jdk的一个版本,起到一个jdk版本兼容性的一个作用,比如说高版本的jdk代码不能使用低版本的jdk运行,这个时候主次版本号就起到这个作用。
版本号后二个字节就是常量池容量计数器,写代码时都是从0开始的,但是这里的常量池却是从1开始,因为它把第0项常量空出来了,这是为了满足不引用任何一个常量池的项目,比如说匿名内部类,它没有类名,但是它的类名也需要存储到常量池里面,那只能指向常量池的第0号位置,又比如说Object类,它是所有类的父类,那它的父类指向的是常量池中的0的位置。
常量池后面就是访问标志,用两个字节来表示,其标识了类或者接口的访问信息,比如:这个.Class文件是类还是接口,是不是被定义成public,是不是abstract,如果是类,是不是被声明成final等。
访问标志后的两个字节就是类索引,通过类索引我们可以确定到类的全限定名。类索引后的两个字节就是父类索引,通过父类索引可以确定到父类的全限定名,通过这二个全限定名可以获取到类路径。
父类索引后的两个字节是接口索引计数器,接口索引计数器表示接口索引集合中接口的数量。
接口索引计数器后边二个字节是接口索引集合,它是按照当前类实现的接口顺序,从左到右依次排列在接口索引集合中。
接口索引集合后边二个字节是字段表计数器,用来表示字段表的容量,字段表计数器后边是字段表。我们知道,一个字段可以被各种关键字去修饰,比如:作用域修饰符(public、private、protected)、static修饰符、final修饰符、volatile修饰符等,所以也可以像类的访问标志那样,使用一些标识来标记字段。字段表作为一个表,同样他也有自己的结构,比如说访问标志,字段名索引,描述符索引,属性计数器,属性集合。在Java语言中字段是无法重载的,两个字段的数据类型,修饰符不管是否相同,都必须要有不一样的名称,但是对于字节码文件来说,如果两个字段的描述符不一致,那这二个字段重名就是合法的。
字段表后边二个字节是方法表计数器,表示方法表的容量,方法表计数器后边紧跟的是方法表。
和字段表类似,方法表里面也有自己的结构,比如说访问标志,方法名索引,描述符索引,属性计数器,属性集合。
方法表后边紧跟的是属性表计数器,属性表计数器后边紧跟的结构为属性表。
属性表的两大特点:一个是限制比较宽松,没有顺序长度要求;一个是开发者可以根据自己的需求,向属性表中添加不重复的属性。
类加载机制和双亲委派机制
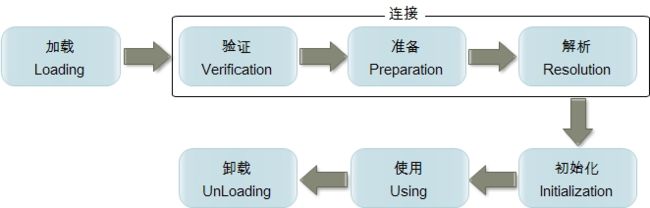
第一步,加载,一个Java源文件进行编译之后,成为一个class字节码文件存储在磁盘上面,这个时候jvm需要读取这个字节码文件,通过通过IO流读取字节码文件,这一步就是加载。
类加载器将.class文件加载到JVM,首先是看当前类是不是使用自定义加载类加载的,如果不是,就委派应用类加载器加载,如果有加载过这个class文件,那就不用再加载了。如果没有,那么会拿到父加载器,然后调用父加载器的loadClass方法。父类的扩展类加载器同理也会先检查自己是不是已经加载过,如果没有再往上,看看启动类加载器。到启动类加载器,已经没有父加载器了,这时候开始考虑自己是否能加载了,如果自己加载不了,就会下沉到子加载器去加载,一直到最底层,如果没有任何加载器能加载,就会抛出ClassNotFoundException找不到类异常,这就是所谓的双亲委派机制。
这种机制可以避免,同路径下的同文件名的类,比如,自己写了一个java.lang.obejct,这个类和jdk里面的object路径相同,文件名也一样,这个时候,如果不使用双亲委派机制的话,就会出现不知道使用哪个类的情况,而使用了双亲委派机制,它就委派给父类加载器就找这个文件是不是被加载过,从而避免了上面这种情况的发生。

第二步,验证,JVM读到文件也不是直接运行,还需要校验加载进来的字节码文件是不是符合JVM规范
-
验证的第一步就是文件的格式验证,验证class文件里面的魔数和主次版本号,发现它是一个jvm可以支持的class文件并且它的主次版本号符合兼容性要求,所以验证通过。
-
然后又回到了加载,它会将class文件这个二进制静态文件转化到方法区里面,转化为方法区的时候,会有一个结构的调整,将静态的存储文件转化为运行时数据区,这个转化等于说又回到了加载。
-
接着到了方法区的运行时数据区以后,在java堆内存里面生成一个当前类的class对象,作为方法区里面这个类,被各种访问的一个入口。比如说object类,它是所有类都继承它,访问它,所以它也需要一个被各种类访问的入口。object类先加载,加载完成之后,它经过这一系列的操作,把自己java.lang.object放到这个堆里面,要让其他的类进行访问,这个也是加载。
-
接着到了验证里面的第二步元数据验证,它会对字节码描述的信息进行语义分析,比如:这个类是不是有父类,是不是实现了父类的抽象方法,是不是重写了父类的final方法,是不是继承了被final修饰的类等等。
-
第三步,字节码验证,通过数据流和控制流分析,确定程序语义是合法的、符合逻辑的,比如:操作数栈的数据类型与指令代码序列是不是可以配合工作,方法中的类型转换是不是有效等等。
-
第四步,符号引用验证:确保解析动作可以正确执行,比如说:通过符号引用是不是可以找到对应的类和方法,符号引用中类、属性、方法的访问性是不是能被当前类访问等,验证完成之后,需要做准备。
准备就是给类的静态变量分配内存,并赋予默认值。我们的类里,可能会包含一些静态变量, 比如说public static int a = 12; 得给a这个变量分配个默认值 0,再比如public static User user = new User(); 给 static的变量User分配内存,并赋默认值null。如果是final修饰的常量,就不需要给默认值了,直接赋值就可以了。
然后就是解析,解析就是将符号引用变为直接引用,该阶段会把一些静态方法替换为指向数据储存在内存中的指针或者句柄,也就是所谓的直接引用,这个就是静态链接过程,是在初始化之前完成。有静态链接就有动态链接,动态链接是在程序运行期间完成将符号引用替换为直接引用,比如静态方法里面有个方法,在运行的时候,方法是存放在常量池中的符号,运行到这个符号,就是找这个符号对应的方法区,因为代码的指令是加载到方法区里面去的,最后把方法对应代码的地址放到栈帧中的动态链接里。
后面就是初始化了,初始化就是对类的静态变量初始化为指定的值并且会执行静态代码块。比如准备阶段的public static final int a = 12;这个变量,就是准备阶段给static变量a赋了默认值0,这一步就该把12赋值给它了。还有static的User public static User user = new User(); 把User进行实例化。
最后就是使用和卸载了,到此整个加载流程就走完了。
垃圾回收器、垃圾回收算法、空间分配担保
垃圾回收器有多个,先说新生代的三个垃圾回收器,serial,parnew,parallel scavenge,然后再说老年代的serial old,parallel old,cms,最后在说一下新生代和老年代都使用的垃圾回收器G1吧。
Serial
Serial是新生代下使用复制算法,单线程运行的垃圾回收器,简单高效,没有线程交互开销,专注于GC,这个垃圾回收器工作的时候会将所有应用线程全部冻结,而且是单核cpu,所以基本不会考虑使用它。
ParNew
ParNew是新生代下使用复制算法,多线程运行的垃圾回收器,可以并行并发GC,和serial对比,除了多核cpu并行gc其他基本相同。
Parallel scavenge
Parallel scavenge也是新生代下使用复制算法,可以进行吞吐量控制的多线程回收器,主要关注吞吐量,通过吞吐量的设置控制停顿时间,适应不同的场景。可以发现新生代的垃圾回收器都使用,复制算法进行gc。
复制算法
新生代中每次垃圾回收都要回收大部分对象,所以为了避免内存碎片化的缺陷,这个算法按内存容量将内存划分为大小相等的两块,每次只使用其中一块,当这一块存活区内存满后将gc之后还存活的对象复制到另一块存活区上去,把已使用的内存清掉。
分代收集算法
按照分代收集算法的思想,把应用程序可用的堆空间分为年轻代,老年代,永久代,然后年轻代有被分为Eden区和二个Survivor存活区,这个比例又可以分为8比1比1。当第一次eden区发生minor gc,会把存活的对象复制到其中的一个Survivor区,然后eden区继续放对象,直到触发gc,会把eden区和之前存放对象的Survivor区一起gc,二个区存活下来的对象,复制到另一个空的Survivor里面,这二个区就清空,然后将二个存活区角色互换。
进入老年代的几种情况
当对象在Survivor区躲过一次GC 后,年龄就会+1,存活的对象在二个Survivor区不停的移动,默认情况下年龄到达15的对象会被移到老生代中,这是对象进入到老年代的第一种情况。
这里就会有个问题,JVM分代年龄为什么是15次?
一个对象的GC年龄,是存储在对象头里面的,一个Java对象在JVM内存中的布局由三个部分组成,分别是对象头、实例数据、对齐填充。而对象头里面有4个bit位来存储GC年龄。

4个bit位能够存储的最大数值是15,所以从这个角度来说,JVM分代年龄之所以设置成15次是因为它最大能够存储的数值就是15。虽然JVM提供了参数来设置分代年龄的大小,但是这个大小不能超过15。从设计角度来看,当一个对象触发了最大值15次gc,还没有办法被回收,就只能移动到old generation了。另外,设计者还引入了动态对象年龄判断的方式来决定把对象转移到old generation,也就是说不管这个对象的gc年龄是否达到了15次,只要满足动态年龄判断的依据,也同样会转移到old generation。
第二种情况就是,创建了一个很大的对象,这个对象的大小超过了jvm里面的一个参数max tenuring thread hold值,这个时候不会创建在eden区,新对象直接进入老年代。
第三种情况,如果在Survivor区里面,同一年龄的所有对象大小的总和大于Survivor区大小的一半,年龄大于等于这个年龄对象的,就可以直接进入老年代,举个例子,存活区只能容纳5个对象,有五个对象,1岁,2岁,2岁,2岁,3岁,3个2岁的对象占了存活区空间的5分之三,大于这个空间的一半了,这个时候大于等于2岁的对象,需要移动到老年代里面,也就是3个2岁的,一个3岁的对象移动到老年代里面。
空间分配担保
第四种情况就是eden区存活的对象,超过了存活区的大小,会直接进入老年代里面。另外在发生minor gc之前,必须检查老年代最大可用连续空间,是不是大于新生代所有对象的总空间,如果大于,这一次的minor gc可以确保是安全的,如果不成立,jvm会检查自己的handlepromotionfailure这个值是true还是false。true表示运行担保失败,false则表示不允许担保失败。如果允许,就会检查老年代最大可用连续空间是不是大于历次晋升到老年代平均对象大小,如果大于就尝试一次有风险的minorgc,如果小于或者不允许担保失败,那就直接进行fgc了。
举个例子,在minorgc发生之前,年轻代里面有1g的对象,这个时候,老年代瑟瑟发抖,jvm为了安慰这个老年代,它在minor gc之前,检查一下老年代最大可用连续空间,假设老年代最大可用连续空间是2g,jvm就会拍拍老年代的肩膀说,放心,哪怕年轻代里面这1g的对象全部给你,你也吃的下,你的空间非常充足,这个时候,老年代就放心了。
但是大部分情况下,在minor gc发生之前,jvm检查完老年代最大可用连续空间以后,发现只有500M,这个时候虚拟机不会直接告诉老年代你的空间不够,这个时候会进行第二次检查,检查自己的一个参数handlepromotionfailure的值是不是允许担保失败,如果允许担保失败,就进行第三次检查。
检查老年代最大可用连续空间是不是大于历次晋升到老年代平均对象大小,假设历次晋升到老年代平均对象大小是300M,现在老年代最大可用连续空间只有500M,很明显是大于的,那么它会进行一次有风险的minorgc,如果gc之后还是大于500M,那么就会引发fgc了,但是根据以往的一些经验,问题不大,这个就是允许担保失败。
假设历次晋升到老年代平均对象大小是700M,现在老年代最大可用连续空间只有500M,很明显是小于的,minorgc风险太大,这个时候就直接进行fgc了,这就是我们所说的空间分配担保。
Serial Old
Serial Old就是老年代下使用标记整理算法,单线程运行的垃圾回收器。
Parallel old
Parallel old也是老年代下使用标记整理算法,可以进行吞吐量控制的多线程回收器,在JDK1.6才开始提供,在JDK1.6之前,新生代使用ParallelScavenge 收集器只能搭配年老代的Serial Old收集器,只能保证新生代的吞吐量优先,无法保证整体的吞吐量,Parallel Old 正是为了在年老代同样提供吞吐量优先的垃圾收集器而出现的。
上面的Serial Old,Parallel Old这二个垃圾回收器使用的是标记整理算法.
标记整理算法
标记整理算法是标记后将存活对象移向内存的一端,然后清除端边界外的对象。标记整理算法可以弥补标记清除算法当中,内存碎片的缺点,也消除了复制算法当中,内存使用率只有90%的现象,不过也有缺点,就是效率也不高,它不仅要标记所有存活对象,还要整理所有存活对象的引用地址。从效率上来说,标记整理算法要低于复制算法。
CMS
CMS是老年代使用标记清除算法,并发收集低停顿的多线程垃圾回收器。这个垃圾回收器可以重点讲一下,CMS 工作机制相比其他的垃圾收集器来说更复杂,整个过程分为以下4个阶段:
初始标记,只是标记一下GC Roots,能直接关联的对象,速度很快,需要暂停所有的工作线程。
并发标记,进行GC Roots跟踪的过程,和用户线程一起工作,不需要暂停工作线程。
重新标记,为了修正在并发标记期间,因为用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,需要暂停所有的工作线程。
并发清除,清除 GC Roots 不可达对象,和用户线程一起工作,不需要暂停工作线程。由于耗时最长的并发标记和并发清除过程中,垃圾收集线程可以和用户现在一起并发工作,所以总体上来看CMS 收集器的内存回收和用户线程是一起并发地执行。
但是很明显无法处理浮动垃圾,就是已经标记过的对象,开始进行并发清除的时候,这个时候又有垃圾对象产生,这个时候,没办法清除这部分的浮动垃圾了,还有一个问题就是容易产生大量内存碎片,这和它的算法特性相关。
标记清除算法
标记清除算法分为两个阶段,标注和清除。标记阶段标记出所有需要回收的对象,清除阶段回收被标记的对象所占用的空间。
CMS使用标记清除算法看中的就是它的效率高,只不过内存碎片化严重,后续可能发生大对象不能找到可利用空间的问题。
G1
G1 收集器避免全区域垃圾收集,它把堆内存划分为大小固定的几个独立区域,每个区域又可以根据分代理论分为eden区,Survivor区,只要这个区域里面出现了一个对象,超过了这个区域空间的一半就可以把它当作大对象,g1专门开辟了一块空间用来存储大对象,这个区域的大小,可以通过jvm的参数去设置,取值范围是1~32mb之间,那么如果有一个对象超过了32mb,那么jvm会分配二个连续的区域,用来存储这个大对象。
跟踪这些区域的垃圾收集进度,同时在后台维护一个优先级列表,每次根据所允许的收集时间,优先回收垃圾最多的区域。区域划分和优先级区域回收机制,保证了G1 收集器可以在有限时间获得最高的垃圾收集效率。而且基于标记整理算法,不产生内存碎片。可以非常精确控制停顿时间,在不牺牲吞吐量前提下,实现低停顿垃圾回收。在jdk1.9的时候,被设置成默认的垃圾回收器了。
安全点
目前Java虚拟机都是采用准确是GC,当执行系统停下来之后,并不需要一个不漏的检查完所有执行上下文和全局的引用位置,虚拟机有办法直接得到哪些地方存放在对象的引用。在HotSpot中,使用了一组OopMap数据结构来实现这个功能。
当一个类加载完之后,HotSpot就把对象是什么类型数据计算出来,在JIT(即时编译)的时候也记录下栈和寄存器哪些位置是引用,这样GC时就可以直接得到有哪些对象的引用。
OopMap不可能为每一条指令都创建一个OopMap只能在特定的位置记录一下,这些位置称为安全点。也就是说程序并非在任何地方都可以进行GC,只有到达安全点之后才可以GC。
安全点的选择不能太少,不能让GC等待的时间太长,也不能太多而影响正常的程序运行速度。所以安全点的选定基本是以程序“是否具有让程序长时间运行的特征”为标准,例如方法调用、循环跳转、异常跳转等地方,具有这些基本功能的指令才产生安全点。
更具体点在HotSpot中,安全点的位置:
- 方法返回之前
- 调用某个方法之后
- 抛出异常的位置
- 循环的末尾
另外在垃圾收集发生时,多线程的程序要所有的线程都跑到安全点都停下来
如何在垃圾收集发生时让所有线程都跑到最近的安全点?
有两种方案可供选择:抢先式中断(Preemptive Suspension)和主动式中断(Voluntary Suspension)
抢先式中断不需要线程的执行代码主动去配合,在垃圾收集发生时,系统首先把所有用户线程全部中断,如果发现有 用户线程中断的地方不在安全点上,就恢复这条线程执行,让它一会再重新中断,直到跑到安全点上。现在几乎 没有虚拟机实现采用抢先式中断来暂停线程响应GC事件。
主动式中断的思想是当垃圾收集需要中断线程的时候,不直接对线程操作,仅仅简单地设置一个标志位,各个 线程执行过程时会不停地主动去轮询这个标志,一旦发现中断标志为真时就自己在最近的安全点上主动中断挂起。 轮询标志的地方和安全点是重合的,另外还要加上所有创建对象和其他需要在Java堆上分配内存的地方,这是为 了检查是否即将要发生垃圾收集,避免没有足够内存分配新对象。
程序“不执行”的时候线程如何达到安全点?
安全点机制保证了程序执行时,在不太长的时间内就会遇到可进入垃圾收集过程的安全点。但是,程序“不执行” 的时候呢?所谓的程序不执行就是没有分配处理器时间,典型的场景便是用户线程处于Sleep状态或者Blocked状态,这时候线程无法响应虚拟机的中断请求,不能再走到安全的地方去中断挂起自己,虚拟机也显然不可能持续 等待线程重新被激活分配处理器时间。
对于这种情况,就必须引入安全区域来解决。 安全区域是指能够确保在某一段代码片段之中,引用关系不会发生变化,因此,在这个区域中任意地方开始垃圾收集都是安全的。我们也可以把安全区域看作被扩展拉伸了的安全点。
当用户线程执行到安全区域里面的代码时,首先会标识自己已经进入了安全区域,那样当这段时间里虚拟机要发起垃圾收集时就不必去管这些已声明自己在安全区域内的线程了。
当线程要离开安全区域时,它要检查虚拟机是否已经完成了根节点枚举(或者垃圾收集过程中其他需要暂停用户线程的阶段),如果完成了,那线程就当作没事发生过,继续执行;否则它就必须一直等待,直到收到可以离开安全区域的信号为止。
JIT技术
提出疑问:为什么应用刚启动的时候比较卡,过一会就好了?
解答:
JVM 中内置了解释器,在运行时对字节码进行解释翻译成机器码,然后再执行。
解释器的执行方式是一边翻译,一边执行,因此执行效率很低。为了解决这样的低效问题,HotSpot 引入了JIT 技术。
有了 JIT 技术之后,JVM 虽然还是通过解释器进行解释执行,但是,当 JVM 发现某个方法或代码块运行时执行的特别频繁的时候,就会认为这是“热点代码”,然后 JIT 会把部分“热点代码”翻译成本地机器相关的机器码,并进行优化,然后再把翻译后的机器码缓存起来,以备下次使用,这也是 HotSpot 虚拟机的名字的由来。
JIT 优化是在运行期进行的,并且也不是 Java 进程刚一启动就能优化的,是需要先执行一段时间的,因为他需要先知道哪些是热点代码。
所以,在 JIT 优化开始之前,我们的所有请求,都是要经过解释执行的,这个过程就会相对慢一些。
如果请求量比较大的的话,这种问题就会更加明显,在应用启动过程中,会有大量的请求过来,这就会导致解释器持续的在努力工作。一旦解释器对 CPU 资源占用比较大的话,就会间接的导致 CPU、LOAD 等飙高,导致应用的性能进一步下降。
这也是为什么很多应用在发布过程中,会出现刚刚重启好的应用会发生大量的超时问题了。而随着请求的不断增多,JIT 优化就会被触发,这就是使得后续的热点请求的执行可能就不需要在通过解释执行了,直接运行 JIT 优化后缓存的机器码就行了。
解决思路:
1、提升 JIT 优化的效率
2、降低瞬时请求量
在提升 JIT 优化效率的设计上,大家可以了解一下阿里研发的 JDK——Dragonwell。
这个相比 OpenJDK 提供了一些专有特性,其中一项叫做JwarmUp的技术就是解决 JIT 优化效率的问题的。
这个技术主要是通过记录 Java 应用上一次运行时候的编译信息到文件中,在下次应用启动时,读取该文件,从而在流量进来之前,提前完成类的加载、初始化和方法编译,从而跳过解释阶段,直接执行编译好的机器码。
除了针对 JDK 做优化之外,还可以采用另外一种方式来解决这个问题,那就是做预热。
很多人都听说过缓存预热,其实思想是类似的。
就是说在应用刚刚启动的时候,通过调节负载均衡,不要很快的把大流量分发给他,而是先分给他一小部分流量,通过这部分流量来触发 JIT 优化,等优化好了之后,再把流量调大。
可达性分析
在可达性分析法中,可以作为GCRoots节点的,一般内容都会很大(方法区有时候就有数百M),要想检查完所有符合要求的对象,必定很费时间。另外可达性分析应当是对某瞬间的程序快照进行的,不然一边进行可达性分析,一边程序运行,最后出的结果肯定是牛头不对马尾。这个时间点导致GC进行时必须停顿所有Java执行的线程。
通过gc root根节点,从跟节点开始进行引用链的搜索,如果对象搜索不到,就证明这个对象是不可达的,就会在三色标记算法把这个对象标记为白色不可达,最终引发垃圾回收。
gc root是可达性分析的起点,gc root有几种,第一种,虚拟机栈里面引用的对象,也就是栈帧中的本地变量,第二种,本地方法栈里面的引用对象,第三种,方法区里面的静态属性引用的对象,第四种,方法区里面的常量引用对象,第五种,java虚拟机内部也有引用,这个也需要作为gc root,第六种,锁,锁的获取和释放,获取的话会持有对象,这些都是作为gc root的引用点。
四种引用类型
强引用
强引用就是最常见的Object a = new Object();这种就是最强的一个引用,只要这个关系还在,就不会被垃圾回收掉。
软引用
软引用就是描述这个对象还有用,但是它不是一个必须回收的对象,只有系统即将要发送内存溢出的情况下,会把这些对象列入回收的范围里面,进行第二次垃圾回收,如果回收之后,还是没有足够的内存,才会抛出异常。
弱引用
弱引用,被弱引用引用的对象,只能生存到下一次垃圾回收器进行垃圾收集。
虚引用
虚引用,它是最弱的一种引用,可以称为幽灵引用,它的存在不会对结构造成任何的影响,没法通过虚引用找到这个对象的实例。
gc的过程中对象是否能回收
当对象不可达就意味着这个对象要被回收,但是它不会立马就回收,对象不可达会把它放到一个F-Queue的队列里面,这个队列里面会启用一个低优先级的线程,去读取这些不可达的对象,然后一个一个的调用对象的finalize方法,如果对象的finalize方法被覆盖过,被调用过,这个时候虚拟机将这两种情况都视为“没有必要执行”。
这个时候这个不可达对象逃过了垃圾回收,稍后会由一条由虚拟机自动建立的、低调度优先级的 Finalizer线程去执行F-Queue中对象的finalize()方法。
finalize()方法是对象逃脱死亡命运的最后一次机会,收集器将对F-Queue中的对象进行第二次小规模的标记。
如果对象重新与引用链上的任何一个对象建立关联,那在第二次标记时它将被移出“即将回收”的集合。
如果对象这时候还没有逃脱,那基本上它就真的要被回收了。
三色标记
三色标记,这三色就是白黑灰,白色表示对象不可达,黑色表示已经被访问过了,它关联的对象也扫描了,灰色就是还有一部分对象没有被扫描过。
跨代引用
跨代引用,年轻代中有一个对象被老年代的对象引用了,这个时候进行minor gc。正常我们的思路是,年轻代里面的对象被老年代里面的对象引用的话,就进行一个遍历,遍历老年代里面的对象。但是老年代里面的对象是很多的,遍历这个是很消耗性能的,这个时候jvm引入了一个记忆集的抽象数据结构。它用于记录从非收集区域指向收集区域的一个指针集合的抽象数据结构。比如说,我们在年轻代里面进行minor gc,它里面有一个记忆集,记录了老年代引用年轻代的对象的指针。如果记忆集里面有当前对象的引用,那么这个对象就不能被回收。
逃逸分析
逃逸分析原理:
逃逸分析有三种程度,从不逃逸,方法逃逸,线程逃逸,这三个由低到高表示不同逃逸的程度。
方法逃逸:分析对象动态作用域,当一个对象在方法里面定义之后,可能会被外部方法引用,比如作为参数传到其他方法里面去,这个叫方法逃逸。
线程逃逸:一个对象可能被外部线程访问到,比如可以赋值给其他线程能访问的实例变量,这个叫线程逃逸。
优化手段有三种:第一种是栈上分配,标量替换,锁清除(同步清除)。
栈上分配,java堆中的对象,对于各个线程都是共享可见的,只要持有这个对象的引用,就可以访问到堆中存储的对象数据。虚拟机的垃圾收集子系统会回收堆中不再使用的对象,但是回收动作无论是标记筛选出可回收对象, 还是回收和整理内存,都需要耗费大量资源。如果确定一个对象不会逃逸出线程之外,那让这个对象在栈上分 配内存将会是一个很不错的主意,对象所占用的内存空间就可以随栈帧出栈而销毁。在一般应用中,完全不会 逃逸的局部对象和不会逃逸出线程的对象所占的比例是很大的,如果能使用栈上分配,那大量的对象就会随着 方法的结束而自动销毁了,垃圾收集子系统的压力将会下降很多。栈上分配可以支持方法逃逸,但不能支持线 程逃逸。
标量替换:一个数据已经无法再分解成更小的数据来表示了,Java虚拟机中的原始数据类型 (int、long等数值类型及reference类型等)都不能再进一步分解了,那么这些数据就可以被称为标量。
一个数据可以继续分解,那它就被称为聚合量,Java中的对象就是典型的聚合量。如果把一个Java对象拆散,根据程序访问的情况,将其用到的成员变量恢复为原始类型来访问,这个过程就称为标量替换。
假如逃逸分析能够证明一个对象不会被方法外部访问,并且这个对象可以被拆散,那么程序真正执行的时候将可能不去创建这个对象,而改为直接创建它的若干个被这个方法使用的成员变量来代替。
将对象拆分后,除了可以让对象的成员变量在栈上(栈上存储的数据,很大机会被虚拟机分配至物理机器的高速寄存器中存储)分配和读写之外,还可以为后续进一 步的优化手段创建条件。标量替换可以视作栈上分配的一种特例,实现更简单(不用考虑整个对象完整结构的分配), 但对逃逸程度的要求更高,它不允许对象逃逸出方法范围内。
同步消除:线程同步本身是一个相对耗时的过程,如果逃逸分析能够确定一个变量不 会逃逸出线程,无法被其他线程访问,那么这个变量的读写肯定就不会有竞争,对这个变量实施的同步措施也就可以 安全地消除掉。
public String concatString(String s1,String s2,String s3){
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
sb.append(s3);
return sb.toString();
}
每个StringBuffer.append()方法中都有一个同步块,锁就是sb对象。 虚拟机观察变量sb,经过逃逸分析后会发现它的动态作用域被限 制在concatString()方法内部。也就是sb的所有引用都永远不会逃 逸到concatString()方法之外,其他线程无法访问到它,所以这里 虽然有锁,但是可以被安全地消除掉。在解释执行时这里仍然会 加锁,但在经过服务端编译器的即时编译之后,这段代码就会忽 略所有的同步措施而直接执行。
内存泄漏
内存泄漏:是指创建的对象已经没有用处,正常情况下应该会被垃圾收集器回收,但是由于该对象仍然 被其他对象进行了无效引用,导致不能够被垃圾收集器及时清理,这种现象称之为内存泄漏。
内存堆积
内存泄漏会导致内存堆积,最终发生内存溢出,导致OOM。 发生内存泄漏大部分是由于程序代码导致的,排查方法一般是使用 visualVM 进行heap dump,查看占用 空间比较多的 class 对象,然后检查该对象的instances 以及 reference引用,最终定位到程序代码。 如果堆内存比较大,进行head dump 产生的资源消耗不可接受,可以尝试使用轻量级的jmap生成堆转储快照 分析,思路与使用可视化工具一样。
JVM调优
JVM调优情况十分复杂,各种情况都可能导致垃圾回收不能够达到预想的效果。对于场景问题,可以从如下几个大方向进行设计:
- 大访问压力下,MGC 频繁一些是正常的,只要MGC 延迟不导致停顿时间过长或者引发FGC ,那可以适当的增大Eden 空间大小,降低频繁程度,同时要保证,空间增大对垃圾回收产生的停顿时间增长是可以接受的。
- 如果MinorGC 频繁,且容易引发 Full GC。需要从如下几个角度进行分析。
a:每次MGC存活的对象的大小,是否能够全部移动到 S1区,如果S1 区大小 < MGC 存活的对象大小,这批对象会直接进入老年代。注意 了,这批对象的年龄才1岁,很有可能再多等1次MGC 就能被回收了,可是却进入了老年代,只能等到Full GC 进行回收,很可怕。这种情况下,应该在系统压测的情况下,实时监控MGC存活的对象大小,并合理调整eden和s 区的大小以及比例。
b:还有一种情况会导致对象在未达到15岁之前,直接进入老年代,就是S1区的对象,相同年龄的对象所占总空间大小>s1区空间大小的一半,所以为了应对这种情况,对于S区的大小的调整就要考虑:尽量保证峰值状态下,S1区的对象所占空间能够在MGC的过程中,相同对象年龄所占空间不大于S1区空间的一半, 因此对于S1空间大小的调整,也是十分重要的。 - 由于大对象创建频繁,导致Full GC 频繁。对于大对象,JVM专门有参数进行控制,-XX: PretenureSizeThreshold。超过这个参数值的对象,会直接进入老年代,只能等到full GC 进行回收,所以在系统压测过程中,要重点监测大对象的产生。如果能够优化对象大小,则进行代码层面的优化,优化如:根据业务需求看是否可以将该大对象设置为单例模式下的对象,或者该大对象是否可以进行拆分使用,或者如果大对象确定使用完成后,将该对象赋值为null,方便垃圾回收。
如果代码层面无法优化,则需要考虑:
a:调高-XX: PretenureSizeThreshold参数的大小,使对象有机会在eden区创建,有机会经历MGC以被回收。但是这个参数的调整要结合MGC过程中Eden区的大小是否能够承载,包括S1区的大小承载问题。
b:这是最不希望发生的情况, 如果必须要进入老年代,也要尽量保证,该对象确实是长时间使用的对象,放入老年代的总对象创建量不会造成老年代的内存空间迅速长满发生Full GC,在这种情况下,可以通过定时脚本,在业务系统不繁忙情况下,主动触发full gc。 - MGC 与 FGC 停顿时间长导致影响用户体验。其实对于停顿时间长的问题无非就两种情况:
a:gc 真实回收过程时间长,即real time时间长。这种时间长大部分是因为内存过大导致,从标记到清理的过程中需要对很大的空间进行操作,导致停顿时间长。这种情况,要考虑减少堆内存大 小,包括新生代和老年代,比如之前使用16G的堆内存,可以考虑将16G 内存拆分为4个4G的内存区域,可以单台机器部署JVM逻辑集群,也可以为了降低GC回收时间,进行4节点的分布式部署,这里的分布式部署是为了降低 GC垃圾回收时间。
b:gc真实回收时间 real time 并不长,但是user time(用户态执行时间) 和 sys time(核心态执行时间)时间长,导致从客户角度来看,停顿时间过长。这种情况,要考虑线程是否及时达到了安全点,通过-XX:+PrintSafepointStatistics和-XX: PrintSafepointStatisticsCount=1去查看安全点日志,如果有长时间未达到安全点的线程,再通过参数-XX: +SafepointTimeout和-XX:SafepointTimeoutDelay=2000两个参数来找到大于2000ms到达安全点的线程,这里 的2000ms可以根据情况自己设置,然后对代码进行针对的调整。除了安全点问题,也有可能是操作系统本身负载比较高,导致处理速度过慢,线程达到安全点时间长,因此需要同时检测操作系统自身的运行情况。 - 内存泄漏导致的MGC和FGC频繁,最终引发oom。纯代码级别导致的MGC和FGC频繁。如果是这种情况,那就只能对代码进行大范围的调整,这种情况就非常多了,而且会很糟糕。如大循环体中的new 对象,未使用合理容器进行对象托管导致对象创建频繁,不合理的数据结构使用等等。 总之,JVM的调优无非就一个目的,在系统可接受的情况下达到一个合理的MGC和FGC的频率以及可接受的回收时间
CPU飙高系统反应慢怎么排查?
1.CPU是整个电脑的核心计算资源,对于一个应用进程来说,CPU的最小执行单元是线程。
2.导致CPU飙高的原因有几个方面
-
CPU上下文切换过多,对于CPU来说,同一时刻下每个CPU核心只能运行一个线程,如果有多个线程要执行,CPU只能通过上下文切换的方式来执行不同的线程。上下文切换需要做两个事情
- 保存运行线程的执行状态
- 让处于等待中的线程执行
这两个过程需要CPU执行内核相关指令实现状态保存,如果较多的上下文切换会占据大量CPU资源,从而使得cpu无法去执行用户进程中的指令,导致响应速度下降。在Java中,文件IO、网络IO、锁等待、线程阻塞等操作都会造成线程阻塞从而触发上下文切换
-
CPU资源过度消耗,也就是在程序中创建了大量的线程,或者有线程一直占用CPU资源无法被释放,比如死循环!
CPU利用率过高之后,导致应用中的线程无法获得CPU的调度,从而影响程序的执行效率!
3.既然是这两个问题导致的CPU利用率较高,于是我们可以通过top命令,找到CPU利用率较高的进程,在通过Shift+H找到进程中CPU消耗过高的线程,这里有两种情况。
- CPU利用率过高的线程一直是同一个,说明程序中存在线程长期占用CPU没有释放的情况,这种情况直接通过jstack获得线程的Dump日志,定位到线程日志后就可以找到问题的代码。
- CPU利用率过高的线程id不断变化,说明线程创建过多,需要挑选几个线程id,通过jstack去线程dump日志中排查。
4.最后有可能定位的结果是程序正常,只是在CPU飙高的那一刻,用户访问量较大,导致系统资源不够。
MySQL知识点
隔离级别
数据库隔离的四个级别分别为:
Read Uncommitted(读未提交)
在一个事务处理过程里读取了另一个未提交的事务中的数据。会导致脏读。
脏读(Drity Read):
某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个回滚了操作,则后一个事务所读取的数据就会是不正确的。
举个例子,公司发工资了,领导把四万块钱打到我的账号上,但是该事务并未提交,而我正好去查看账户,发现工资已经到账,是四万,非常高兴。可是不幸的是,领导发现发给我的工资金额不对,是三万五元,于是迅速修改金额,将事务提交,最后我实际的工资只有三万五元,我就白高兴一场。
Read Committed(读已提交)
这是大多数数据库系统的默认隔离级别,但不是MySQL默认的。会导致不可重复读,事务a读取数据,事务b立马修改了这个数据并且提交事务给数据库,事务a再次读取这个数据就得到了不同的结果。
不可重复读(Non-repeatable read):
在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间更新了原有的数据。
举个例子,我拿着工资卡去消费,系统读取到卡里确实有一百块钱,这个时候我的女朋友刚好用我的工资卡在网上转账,把我工资卡的一百块钱转到另一账户,并在我之前提交了事务,当我扣款时,系统检查到我的工资卡已经没有钱,扣款失败,廖志伟十分纳闷,明明卡里有钱的。
Repeatable Read(可重读)
这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。会导致幻读,InnoDB和Falcon存储引擎通过多版本并发控制机制解决了该问题。
幻读(Phantom Read):
在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的。
举个例子,当我拿着工资卡去消费时,一旦系统开始读取工资卡信息,这个时候事务开始,我的女朋友就不可能对该记录进行修改,也就是我的女朋友不能在这个时候转账。这就避免了不可重复读。假设我的女朋友在银行部门工作,她时常通过银行内部系统查看我的工资卡消费记录。有一天,她正在查询到我当月信用卡的总消费金额(select sum(amount) from transaction where month = 本月)为80元,而我此时正好在外面胡吃海喝后在收银台买单,消费1000元,即新增了一条1000元的消费记录(insert transaction … ),并提交了事务,随后我的女朋友把我当月工资卡消费的明细打印到A4纸上,却发现消费总额为1080元,我女朋友很诧异,以为出现了幻觉,幻读就这样产生了。
Serializable(可串行化)(更高级别隔离,避免脏读,避免不可重复读,避免幻读)
这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
ACID底层实现原理
原子性底层实现原理
A(原子性),要么全部完成,要么完全不起作用。底层实现是通过undo log日志去实现的,当这个事务对数据库进行修改的时候,innodb 生成对应undo log,undolog有多个版本,并且存放的是与上一个版本相反的操作,他会记录这个SQL执行的相关信息,如果SQL执行失败发生回滚,innodb 根据这个undo log内容去做相反的工作,比如说我执行了一个insert 操作,那么回滚的时候,就会执行一个相反的操作,就是delete,对应update,回滚的时候也是执行相反的update。这就是原子性的底层实现。
一致性实现原理
一旦事务完成,不管成功还是失败,数据处于一致的状态,而不会是部分完成,部分失败。事务执行前后,数据库的完整约束没有遭受破坏,事务执行前后都是合法的一个数据状态。事务的AID是数据库的特征,也就是依赖数据库的具体实现。而唯独这个C,实际上它依赖于应用层,也就是依赖于开发者。这里的一致性,是指数据从一种正确的状态,跳转到另一种正确的状态。
举例:账户A转1000到账户B,A转账的金额,必须小于等于自己的账户余额,即事务提交时,A的账户余额不能为负数,可以通过数据库约束,保证账户金额的字段值大于等于0。
持久性底层实现原理
一旦事务完成,无论发生什么系统错误,它的结果都不会受到影响,事务的结果被写到持久化存储器中。
底层实现原理是:redo log机制去实现的,mysql 的数据是存放在这个磁盘上的,但是每次去读数据都需要通过这个磁盘io,效率就很低,使用 innodb 提供了一个缓存 buffer,这个 buffer 中包含了磁盘部分数据页的一个映射,作为访问数据库的一个缓冲,从数据库读取一个数据,就会先从这个 buffer 中获取,如果 buffer 中没有,就从这个磁盘中获取,读取完再放到这个 buffer 缓冲中,当数据库写入数据的时候,也会首先向这个 buffer 中写入数据,定期将 buffer 中的数据刷新到磁盘中,进行持久化的一个操作。如果 buffer 中的数据还没来得及同步到这个磁盘上,这个时候 MySQL 宕机了,buffer 里面的数据就会丢失,造成数据丢失的情况,持久性就无法保证了。使用 redolog 解决这个问题,当数据库的数据要进行新增或者是修改的时候,除了修改这个 buffer 中的数据,还会把这次的操作写入到这个 redolog 中,如果 msyql 宕机了,就可以通过 redolog 去恢复数据,redolog 是预写式日志,会先将所有的修改写入到日志里面,然后再更新到 buffer 里面,保证了这个数据不会丢失,保证了数据的持久性,redolog 属于记录修改的操作,主要为了提交或者恢复数据使用!
事务隔离性由之前讲述的锁来实现。redo log称为重做日志,用来保证事务的持久性。redo通常是物理日志,记录的是页的物理修改操作。重做日志用来实现事务的持久性,即事务ACID中的D。其由两部分组成:一是内存中的重做日志缓冲,是易丢失的;二是重做日志文件,是持久的。
MySQL中把对底层页面的一次原子访问的过程称之为一个Mini-Transaction(MTR),这里的原子操作,指的是要么全部成功,要么全部失败,不存在中间状态。
Mini-Transaction一般遵循三条原则:
1、the fix rules:修改一个数据页,需要获得这个数据页的x-latch;访问一个页是需要获得s-latch或者x-latch;持有该页的latch直到修改或者访问该页的操作完成才释放。(latch是一种轻量级的锁,它锁定的时间特别短,在innodb中,latch又可以分为mutex(互斥量)和rwlock(读写锁)2种,它的目的在于保证并发线程操作临界资源的正确性。)
2、WAL:持久化一个数据页之前,需要将内存中响应的日志页先持久化
3、force-log-at-commit:在事务提交的时候,其产生的所有MTR日志都要刷到持久化设备中,从而保证崩溃恢复的逻辑。
InnoDB是事务的存储引擎,通过Force Log at Commit机制实现事务的持久性。当事务提交时,必须先将该事务的所有日志写入到重做日志文件进行持久化,待事务的COMMIT操作完成才算完成。为了确保每次日志都写入重做日志文件,在每次将重做日志缓冲写入重做日志文件后,InnoDB存储引擎都需要调用一次fsync操作。
由于重做日志文件打开并没有使用O_DIRECT选项,因此重做日志缓冲先写入文件系统缓存。为了确保重做日志写入磁盘,必须进行一次fsync操作。由于fsync的效率取决于磁盘的性能,因此磁盘的性能决定了事务提交的性能,也就是数据库的性能。
隔离性实现原理(一致性非锁定读(MVCC的原理))
多事务会同时处理相同的数据,因此每个事务都应该与其他事务隔离开来,防止数据损坏。
底层实现原理:
写-写操作:通过加锁,原理和 java 里面的锁机制是一样的。
写-读操作:MVCC多版本并发控制,对一行数据的读和写两个操作默认是不会通过加锁互斥来保证隔离性,避免了频繁加锁互斥。
一行数据被多个事务依次修改过后,在每个事务修改完后,Mysql会保留修改前的数据undo回滚日志,并且用两个隐藏字段trx_id和roll_pointer把这些undo日志串联起来形成一个历史记录版本链。
在可重复读隔离级别,事务开启的时候,执行任何查询sql会生成当前事务的一致性视图read-view,也就是第一次select生成一个版本,read-view视图在事务结束之前都不会变化。
如果是读已提交隔离级别,在每次执行查询sql时都会重新生成视图read-view,也就是每次select生成一个版本。
执行查询时,从对应版本链里的最新数据开始逐条跟read-view做比,会拿着当前事务的id和readview视图数组里面的已创建的最小事务id和已创建的最大事务id进行比较,这里面分为三种情况:
第一种,当前事务的id小于数组里面最小的id,说明这个版本是已提交的事务生成的,表示这个数据可见。
第二种,当前事务比已创建的最大事务id还要大,说明这个版本还没开启事务,表示不可见。
第三种,如果刚好在这个区间,被访问的事务id在最小事务id与最大事务id之间,又有二种情况:
第一种,这个版本是由还没提交的事务生成的,不可见,
第二种,表示这个版本是已经提交了的事务生成的,可见。
做比对,得到最终的快照结果,通过这种机制保证了隔离性。
对于删除的情况可以认为是update的特殊情况,会将版本链上最新的数据复制一份,然后将trx_id修改成删除操作的 trx_id,同时在该条记录的头信息(record header)里的(deleted_flag)标记位写上true,来表示当前记录已经被 删除,在查询时按照上面的规则查到对应的记录如果delete_flag标记位为true,意味着记录已被删除,则不返回数 据。
注意:begin/start transaction 命令并不是一个事务的起点,在执行到它们之后的第一个修改操作InnoDB表的语句, 事务才真正启动,才会向mysql申请事务id,mysql内部是严格按照事务的启动顺序来分配事务id的。
总结: MVCC机制的实现就是通过read-view机制与undo版本链比对机制,使得不同的事务会根据数据版本链对比规则读取同一条数据在版本链上的不同版本数据。
BufferPool缓存机制
mysql 的数据是存放在磁盘上的,但是每次去读数据都需要通过这个磁盘io,效率就很低,使用 innodb 提供了一个缓存 buffer,这个 buffer 中包含了磁盘部分数据页的一个映射,作为访问数据库的一个缓冲,从数据库读取一个数据,就会先从这个 buffer 中获取,如果 buffer 中没有,就从这个磁盘中获取,读取完再放到这个 buffer 缓冲中,当数据库写入数据的时候,也会首先向这个 buffer 中写入数据,定期将 buffer 中的数据刷新到磁盘中,进行持久化的一个操作。

为什么Mysql不能直接更新磁盘上的数据而且设置这么一套复杂的机制来执行SQL了?
因为来一个请求就直接对磁盘文件进行随机读写,然后更新磁盘文件里的数据性能可能相当差。
因为磁盘随机读写的性能是非常差的,所以直接更新磁盘文件是不能让数据库抗住很高并发的。 Mysql这套机制看起来复杂,但它可以保证每个更新请求都是更新内存BufferPool,然后顺序写日志文件,同时还能保证各种异常情况下的数据一致性。 更新内存的性能是极高的,然后顺序写磁盘上的日志文件的性能也是非常高的,要远高于随机读写磁盘文件。 正是通过这套机制,才能让我们的MySQL数据库在较高配置的机器上每秒可以抗下几干的读写请求。
重做日志刷新到磁盘的策略
通过参数innodb_flush_log_at_trx_commit用来控制重做日志刷新到磁盘的策略。
该参数的默认值为1,表示事务提交时必须调用一次fsync操作。
0表示事务提交时不进行写入重做日志操作,这个操作仅在master thread中完成,而在master thread中每1秒会进行一次重做日志文件的fsync操作。
2表示事务提交时将重做日志写入重做日志文件,但仅写入文件系统的缓存中,不进行fsync操作。在这个设置下,当MySQL数据库发生宕机而操作系统不发生宕机时,并不会导致事务的丢失。而当操作系统宕机时,重启数据库后会丢失未从文件系统缓存刷新到重做日志文件那部分事务。
举例:逐条插入50万条数据。
innodb_flush_log_at_trx_commit = 1时: 用时 2 分 13 秒。50 万次写入重做日志;fsync操作50万次。
innodb_flush_log_at_trx_commit = 0时: 用时 23 秒。约23次写如重做日志;fsync操作约23次。
innodb_flush_log_at_trx_commit = 2时: 用时 35 秒。50万次写入重做日志(仅缓存);fsync操作0次。
虽然用户可以通过设置参数innodb_flush_log_at_trx_commit为0或2来提高事务提交的性能,但是需要牢记的是,这种设置方法丧失了事务的ACID特性。而针对上述存储过程,为了提高事务的提交性能,应该在将50万行记录插入表后进行一次的COMMIT操作,而不是在每插入一条记录后进行一次COMMIT操作。这样做的好处是还可以使事务方法在回滚时回滚到事务最开始的确定状态。
正确方法:innodb_flush_log_at_trx_commit = 1,将50万条数据在一个事务或者多个事务中分派提交,减少fsync次数。
filesort的过程
filesort的过程是这样的:
第一步先根据表的索引或者全表扫描,读取所有满足条件的记录。
第二步,存储每一行排序列,就是order by用到的列值,还有行记录指针,就是指向该行数据的行指针,把这二个存储到缓冲区。
第三步,当缓冲区满后,运行一个快速排序来将缓冲区中数据排序,将排序完的数据存储到一个临时文件,保存一个存储块的指针,当然如果缓冲区不满,则不会重建临时文件了。直到将所有行读完,建立相应有序的临时文件。
第四步,对块级进行排序,这个类似归并排序算法,只通过两个临时文件的指针来不断交换数据,最终达到两个文件,都是有序的,直到所有的数据都排序完毕。
第五步,采取顺序读的方式,将每行数据读入内存,取出数据传到客户端。
为什么要说这个filesort呢?
举二个场景,第一个,如果order by的条件不在索引列上会产生filesort,第二个,排序的字段不在where的条件中,没有办法走索引排序Index,而是走的文件排序filesort 。
这种概率其实还是挺高的。这个时候就需要看文件排序用的是单路排序还是双路排序,单路排序会把所有需要查询的字段都放到 sort buffer 中,而双路排序只会把主键和需要排序的字段放到 sort buffer 中进行排序,然后再通过主键回到原表查询需要的字段。
mysql优化器使用双路排序还是单路排序是有自己的算法判断的,如果查询的列字段大于max_length_for_sort_data变量,则会使用双路排序,反之则会使用单路排序,单路排序速度是更快的,不过比较占据内存,如果在内存空间允许的情况下想要使用单路排序的话,可以增加max_length_for_sort_data变量的大小,max_length_for_sort_data变量默认为1024字节。
离散读
在某些情况下,当执行EXPLAIN命令进行SQL语句的分析时,会发现优化器并没有选择索引去查找数据,而是通过扫描聚集索引,也就是直接进行全表的扫描来得到数据。
这种情况多发生于范围查找、JOIN链接操作等情况下。
假设表:t_index 。其中 id 为主键;c1 与 c2 组成了联合索引(c1,c2);此外,c1还是一个单独索引。
进行如下查询操作:SELECT * FROM t_index WHERE c1 > 1 and c1 < 100000;
可以看到表t_index有(c1,c2)的联合主键,此外还有对于列c1的单个索引。
上述这句SQL显然是可以通过扫描OrderID上的索引进行数据的查找。然而通过EXPLAIN命令,用户会发现优化器并没有按照OrderID上的索引来查找数据。在最后的索引使用中,优化器选择了PRIMARY id 聚集索引,也就是表扫描,而非c1辅助索引扫描。
这是因为如果强制使用c1索引,就会造成离散读。具体原因在于用户要选取的数据是整行信息,而c1作为辅助索引不能覆盖到我们要查询的信息,因此在对c1索引查询到指定数据后,还需要一次书签访问来查找整行数据的信息。
虽然c1索引中数据是顺序存放的,但是再一次进行书签查找的数据则是无序的,因此变为了磁盘上的离散读操作。如果要求访问的数据量很小,则优化器还是会选择辅助索引,但是当访问的数据占整个表中数据的蛮大一部分时(一般是20%左右),优化器会选择通过聚集索引来查找数据。
优化器如何优化离散读?你是如何避免离散读的
MySQL 5.6之前,优化器在进行离散读决策的时候,如果数据量比较大,会选择使用聚集索引,全表扫描。
MySQL5.6版本开始支持Multi-Range Read(MRR)优化。
Multi-Range Read优化的目的就是为了减少磁盘的随机访问,并且将随机访问转化为较为顺序的数据访问,这对于IO-bound类型的SQL查询语句可带来性能极大的提升。
Multi-Range Read优化可适用于range,ref,eq_ref类型的查询。
MRR优化有以下几个好处:
❑MRR使数据访问变得较为顺序。在查询辅助索引时,首先根据得到的查询结果,按照主键进行排序,并按照主键排序的顺序进行书签查找。
❑减少缓冲池中页被替换的次数。(顺序查找可以对一个页进行顺序查找,无需离散加载数据页)
❑批量处理对键值的查询操作。对于InnoDB和MyISAM存储引擎的范围查询和JOIN查询操作
MRR的工作方式如下:
❑将查询得到的辅助索引键值存放于一个缓存中,这时缓存中的数据是根据辅助索引键值排序的。
❑将缓存中的键值根据RowID进行排序。
❑根据RowID的排序顺序来访问实际的数据文件。
举例说明:SELECT * FROM salaries WHERE salary >10000 AND salary< 40000;
salary上有一个辅助索引idx_s,因此除了通过辅助索引查找键值外,还需要通过书签查找来进行对整行数据的查询。
Multi-Range Read还可以将某些范围查询,拆分为键值对,以此来进行批量的数据查询。这样做的好处是可以在 拆分过程中,直接过滤一些不符合查询条件的数据
例如:SELECT * FROM t WHERE key_part1 >=1000 AND key_part1 < 2000 AND key_part2 = 10000;
表t有(key_part1,key_part2)的联合索引,因此索引根据key_part1,key_part2的位置关系进行排序。
若没有Multi-Read Range,此时查询类型为Range,SQL优化器会先将key_part1大于1000且小于2000的数据都取出,即使key_part2不等于1000。待取出行数据后再根据key_part2的条件进行过滤。这会导致无用数据被取出。如果有大量的数据且其key_part2不等于1000,则启用Mulit-Range Read优化会使性能有巨大的提升。
倘若启用了Multi-Range Read优化,优化器会先将查询条件进行拆分,然后再进行数据查询。就上述查询语句而言,优化器会将查询条件拆分为(1000,10000),(1001,10000),(1002,10000),…,(1999,10000),最后再根据这些拆分出的条件进行数据的查询。
我是如何优化的:
- 在非必要的情况下,拒绝使用 select * ;
- 在必须 select * 的情况下,尽量使用MySQL5.6+的版本开启MRR;
- 在必须 select * 的情况下且MySQL 小于 5.6版本下,可以根据数据量进行离散读和聚集索引两种情况下的性能进行对比,必要时采用force index语句强制指定索引。
ICP优化
和Multi-Range Read一样,Index Condition Pushdown同样是MySQL 5.6开始支持的一种根据索引进行查询的优化方式。
之前的MySQL数据库版本不支持Index Condition Pushdown,当进行索引查询时,首先根据索引来查找记录,然后再根据WHERE条件来过滤记录。
在支持Index Condition Pushdown后,MySQL数据库会在取出索引的同时,判断是否可以进行WHERE条件的过滤,也就是将WHERE的部分过滤操作放在了存储引擎层。
在某些查询下,可以大大减少上层SQL层对记录的索取(fetch),从而提高数据库的整体性能。
Index Condition Pushdown优化支持range、ref、eq_ref、ref_or_null类型的查询,当前支持MyISAM和InnoDB存储引擎。
当优化器选择Index Condition Pushdown优化时,可在执行计划的列Extra看到Usingindexcondition提示。
全文检索
例:SELECT * FROM blog WHERE content like '%xxx%'
根据B+树索引的特性,上述SQL语句即便添加了B+树索引也是需要进行索引的扫描来得到结果。
类似这样的需求在互联网应用中还有很多。例如,搜索引擎需要根据用户输入的关键字进行全文查找,电子商务网站需要根据用户的查询条件,在可能需要在商品的详细介绍中进行查找,这些都不是B+树索引所能很好地完成的工作。
全文检索(Full-Text Search)是将存储于数据库中的整本书或整篇文章中的任意内容信息查找出来的技术。它可以根据需要获得全文中有关章、节、段、句、词等信息,也可以进行各种统计和分析。
在之前的MySQL数据库中,InnoDB存储引擎并不支持全文检索技术。大多数的用户转向MyISAM存储引擎,这可能需要进行表的拆分,并将需要进行全文检索的数据存储为MyISAM表。这样的确能够解决逻辑业务的需求,但是却丧失了InnoDB存储引擎的事务性,而这在生产环境应用中同样是非常关键的。
从InnoDB 1.2.x版本开始,InnoDB存储引擎开始支持全文检索,其支持MyISAM存储引擎的全部功能,并且还支持其他的一些特性。InnoDB存储引擎从1.2.x版本开始支持全文检索的技术,其采用full inverted index的方式。
在InnoDB存储引擎中,将(DocumentId,Position)视为一个“ilist”。因此在全文检索的表中,有两个列,一个是word字段,一个是ilist字段,并且在word字段上有设有索引。
全文检索通常使用倒排索引来实现。倒排索引同B+树索引一样,也是一种索引结构。它在辅助表中存储了单词与单词自身在一个或多个文档中所在位置之间的映射。
这通常利用关联数组实现,其拥有两种表现形式:
❑inverted file index,其表现形式为{单词,单词所在文档的ID}
❑full invertedindex,其表现形式为{单词,(单词所在文档的ID,在具体文档中的位置)}
MySQL数据库通过MATCH()…AGAINST()语法支持全文检索的查询,MATCH指定了需要被查询的列,AGAINST指定了使用何种方法去进行查询。
- NATURALLANGUAGEMODE全文检索通过MATCH函数进行查询,默认采用Natural Language模式,其表示查询带有指定word的文档。
- BOOLEANMODEMySQL数据库允许使用IN BOOLEAN MODE修饰符来进行全文检索。当使用该修饰符时,查询字符串的前后字符 会有特殊的含义,例如下面的语句要求查询有字符串Pease但没有hot的文档,其中+和-分别表示这个单词必须出现,或者一定不存在。
- WITH QUERY EXPANSION 或 IN NATURAL LANGUAGE MODE WITHQUERYEXPANSIONMySQL数据库还支持全文检索的扩展查询。这种查询通常在查询的关键词太短,用户需要impliedknowledge(隐含知识)时进行。例如,对于单词database的查询,用户可能希望查询的不仅仅是包含database的文档,可能还指那些包含MySQL、Oracle、DB2、RDBMS的单词。而这时可以使用Query Expansion模式来开启全文检索的impliedknowledge。
行锁、表锁、间隙锁、死锁
行锁的算法
InnoDB存储引擎有3种行锁的算法,其分别是:
❑Record Lock:锁定单个行记录的锁,防止其他事务对此行进行update和delete。在读已提交、可重复读隔离级别下都支持。
❑Gap Lock:间隙锁,锁定索引记录间隙(不含该记录),确保索引记录间隙不变,防止其他事务在这个间隙进行insert,产生幻读。在可重复读隔离级别下支持。
❑Next-Key Lock∶锁和间隙锁组合,同时锁住数据,并锁住数据前面的间隙Gap。在可重复读隔离级别下支持。
行锁的表现
将mysql数据库改为手动提交
步骤1:
打开窗口1:更新数据,update test_innodb_lock set a = 1 where b = 2;然后查询select * from test_innodb_lock where b = 2;,发现a已经改为1了。
由于还没有提交事务,所以b=2这行数据还是被update持有锁,对于其他事务是不可见的,避免了脏读。
打开窗口2:查询select * from test_innodb_lock where b = 2;发现a的值还是没变。更新数据,update test_innodb_lock set a = 2 where b = 2;发现一直阻塞,没有继续往下执行。
由于第一个会话持有了这一行的锁,第二个窗口的会话就对这一行进行修改。
步骤2:
窗口1:提交事务
窗口2:查询select * from test_innodb_lock where b = 2;发现a的值改为1了。更新数据,update test_innodb_lock set a = 2 where b = 2;发现可以更新成功。
表锁的表现
将mysql数据库改为手动提交
步骤1:
窗口1:更新数据,update test_innodb_lock set b = 0 where a = 1 or a = 2
窗口2:更新数据,update test_innodb_lock set b = 3 where a = 3,发现阻塞,没有继续往下执行
由于还没有提交事务,并且使用了or导致索引失效,行级锁升级为表锁,窗口1只要没有提交事务,那么窗口2任何对test_innodb_lock表的操作都会阻塞,直到窗口1提交事务,窗口2才可以继续执行下去。
间隙锁的表现
假设有一张表,test_innodb_lock表有a和b二个字段,a字段里面的数据缺了2,4,6,8,这些就是间隙,这个间隙引发的锁就叫做间隙锁,一般发生在范围查询里面。

将mysql数据库改为手动提交
步骤1:
窗口1:更新数据,update test_innodb_lock set b = 5 where a >1 and a < 9
窗口2:更新数据,insert into test_innodb_lock values(4,4)发现阻塞了,没有继续往下执行。
窗口1进行了一个范围查询,会把a >1 and a < 9加上锁,窗口2这个会话想插入2,4,6,8是无法插入的,因为它已经被窗口1的会话持有了锁。
死锁
死锁是指两个或两个以上的事务在执行过程中,因争夺锁资源而造成的一种互相等待的现象。若无外力作用,事务都将无法推进下去。
解决死锁问题最简单的方式是不要有等待,将任何的等待都转化为回滚,并且事务重新开始。但是在线上环境中,这可能导致并发性能的下降,甚至任何一 个事务都不能进行。而这所带来的问题远比死锁问题更为严重,因为这很难被发现并且浪费资源。
解决死锁问题的另一种方法是超时,即当两个事务互相等待时,当一个等待时间超过设置的某一阈值时,其中一个事务进行回滚,另一个等待的事务就能继续进行。
在InnoDB存储引擎中,参数innodb_lock_wait_timeout用来设置超时的时间。 超时机制虽然简单,但是其仅通过超时后对事务进行回滚的方式来处理,或者说其是根据FIFO的顺序选择回滚对象。但若超时的事务所占权重比较大,如事务操作更新了很多行,占用了较多的undo log,这时采用FIFO的方式, 就显得不合适了,因为回滚这个事务的时间相对另一个事务所占用的时间可能会很多。
因此,除了超时机制,当前数据库还都普遍采用wait-for graph(等待图)的方式来进行死锁检测。较之超时的解决方案,这是一种更为主动的死锁检测方式。InnoDB存储引擎也采用的这种方式。wait-for graph要求数据库保存以下两种信息: 锁的信息链表和事务等待链表。
wait-for graph是一种较为主动的死锁检测机制,在每个事务请求锁并发生等待时都会判断是否存在回路,若存在则有死锁,通常来说InnoDB存储引擎选择回滚undo量最小的事务。
主键自增长实现原理
自增长在数据库中是非常常见的一种属性,也是很多DBA或开发人员首选的主键方式。在InnoDB存储引擎的内存结构中,对每个含有自增长值的表都有一个自增长计数器。
当对含有自增长的计数器的表进行插入操作时,这个计数器会被初始化,执行如下的语句来得到计数器的值:
SELECT MAX(auto_inc_col)FROM t FOR UPDATE;
插入操作会依据这个自增长的计数器值加1赋予自增长列。这个实现方式称做AUTO-INC Locking。
这种锁其实是采用一种特殊的表锁机制,为了提高插入的性能,锁不是在一个事务完成后才释放,而是在完成对自增长值插入的SQL语句后立即释放。
虽然AUTO-INCLocking从一定程度上提高了并发插入的效率,但还是存在一些性能上的问题。
首先,对于有自增长值的列的并发插入性能较差,事务必须等待前一个插入的完成(虽然不用等待事务的完成)。
其次,对于 INSERT…SELECT的大数据量的插入会影响插入的性能,因为另一个事务中的插入会被阻塞。
从MySQL5.1.22版本开始,InnoDB存储引擎中提供了一种轻量级互斥量的自增长实现机制,这种机制大大提高了自增长值插入的性能。并且从该版本开始,InnoDB存储引擎提供了一个参数innodb_autoinc_lock_mode来控制自增长的模式,该参数的默认值为1。
innodb_autoinc_lock_mode有三个选项:
0:是mysql5.1.22版本之前自增长的实现方式,通过表锁的AUTO-INCLocking方式实现的。
1:是默认值,对于简单的插入(插入之前就可以确定插入的行数),这个值会用互斥量去对内存中的计数器进行累加操作。对于批量插入(插入之前就不确定插入的行数),还是通过表锁的AUTO-INCLocking方式实现。在这种配置下,如果不考虑回滚操作,对于自增值的列,它的增长还是连续的,而且statemment-based方式的replication还是很好的工作。但是如果使用了AUTO-INCLocking方式去产生自增长的值,这个时候再进行简单插入操作,就需要等待AUTO-INCLocking释放。
2:在这个模式下,对于所有的插入的语句,它自增长值的产生都是通过互斥量,不是通过AUTO-INCLocking方式,这是性能最高的方式,但是如果是并发插入,在每次插入的时候,自增长的值就不是连续的,而且基于statemment-based replication会出现问题,所以在这个模式下,任何时候都要用row-base replication,这样才可以保证最大的并发性能和replication主从数据的一致。
statemment-based replication(SBR)和row-base replication(RBR)是主从复制的方式。
使用mysql自增长的坏处:
-
强依赖DB。不同数据库语法和实现不同,数据库迁移的时候、多数据库版本支持的时候、或分表分库的时候需要处理,会比较麻烦。当DB异常时整个系统不可用,属于致命问题。
-
单点故障。在单个数据库或读写分离或一主多从的情况下,只有一个主库可以生成。有单点故障的风险。
-
数据一致性问题。配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证。主从切换时的不一致可能会导致重复发号。
-
难于扩展。在性能达不到要求的情况下,比较难于扩展。ID发号性能瓶颈限制在单台MySQL的读写性能。
索引数据结构
磁盘存储
mysql是从磁盘读取数据到内存的,是以磁盘块为基本单位的,位于同一磁盘块中的数据会被一次性读取出来,不是按需读取。以InnoDB存储引擎来说,它使用页作为数据读取单位,页是其磁盘管理的最小单位,默认大小是16kb。系统的一个磁盘块的存储空间往往没有这么大,所以InnoDB每次申请磁盘空间时都会是多个地址连续磁盘块来达到页的大小16KB。假设一行数据的大小是 1k,那么一个页可以存放 16 行这样的数据。那如果想查找某个页里面的一个数据的话,得首先找到他所在的页。
在查询数据时一个页中的每条数据都能定位数据记录的位置,这会减少磁盘 I/O 的次数,提高查询效率。InnoDB存储引擎在设计时是将根节点常驻内存的,力求达到树的深度不超过 3,也就是说I/O不超过3次。
树形结构的数据可以让系统高效的找到数据所在的磁盘块,这里就可以说一下这个b树和b+树了
B树的结构是每个节点中有key也有value,而每一个页的存储空间是16kb,如果数据较大时将会导致一页能存储数据量的数量很小。
B+Tree的结构是将所有数据记录节点按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储 key 值信息,这样可以大大加大每个节点存储的key 值数量,降低B+Tree的高度。B+树是为磁盘或其他直接存取辅助设备设计的一种平衡查找树。在B+树中,所有记录节点都是按键值的大小顺序存放在同一层的叶子节点上,由各叶子节点指针进行连接。 B+索引在数据库中有一个特点是高扇出性,因此在数据库中,B+树的高度一般都在2~4层,这也就是说查找某一键值的行记录时最多只需要2到4次IO,这倒不错。因为当前一般的机械磁盘每秒至少可以做100次IO, 2~4次的IO意味着查询时间只需0.02~0.04秒。 数据库中的B+树索引可以分为聚集索引和辅助索引。
假设每条sql信息为1kb,主键ID为bigint型,一颗高度为2,3,4高度的B+树分别可以存储多少行数据?
因为单个页的大小为 16kb,而一行数据的大小为 1kb,也就是说一页可以存 放 16 行数据。然后因为非叶子节点的结构是:“页指针 + 键值”,我们假设主键ID 为 bigint 类型,长度为 8 字节(byte),而指针大小在 InnoDB 源码中设置为 6 字节(byte),这样一共 14 字节(byte),因为一个页可以存放 16k 个 byte,所以一个页可以存放的指针个数为 16384/14=1170 个。因此一个两层的 B + 树可 以存放的数据行的个数为:1170*16=18720(行)。
也就是说第一层的页,即根页可以存放 1170 个指针,然后第二层的每个页也可以 存放 1170 个指针。这样一共可以存放 1170*1170 个指针,所以一共可以存放 1170*1170*16=21902400(2千万 左右) 行记录。也就是说一个三层的 B + 树就可以存放千万级别的数据了。
高度为4的B+树则是 1170*1170*1170*16 约等于 2000万*1000,1000个 2000 万就是 200亿行的数据了。
为什么选用B+树做索引而不选用二叉树或者B树?
b 树和 b + 树应用在数据库索引,可以认为是 m 叉的多路平衡查找树,但是从理论上讲,二叉树查找速度和比较次数都是最小的,为什么不用二叉树呢? 因为我们要考虑磁盘 IO 的影响,它相对于内存来说是很慢的。数据库索引是存储在磁盘上的,当数据量大时, 就不能把整个索引全部加载到内存了,只能逐一加载每一个磁盘页(对应索引树的节点)。所以我们要减少 IO 次数,对于树来说,IO 次数就是树的高度,而 “矮胖” 就是 b 树的特征之一,它的每个节点最多包含 m 个孩子, m 称为 b 树的阶。 为什么不用B树呢? b + 树,是 b 树的一种变体,查询性能更好。 b + 树相比于 b 树的查询优势:
1.b + 树的中间节点不保存数据,所以磁盘页能容纳更多节点元素,更 “矮胖”。B 树不管叶子节点还是非叶子节 点,都会保存数据,这样导致在非叶子节点中能保存的指针数量变少(有些资料也称为扇出),指针少的情况 下要保存大量数据,只能增加树的高度,导致 IO 操作变多,查询性能变低;
2.b + 树查询必须查找到叶子节点,b 树只要匹配到即可直接返回。因此 b + 树查找更稳定(并不慢),必须查 找到叶子节点;而B树,如果数据在根节点,最快,在叶子节点最慢,查询效率不稳定。
3.对于范围查找来说,b + 树只需遍历叶子节点链表即可,并且不需要排序操作,因为叶子节点已经对索引进行 了排序操作。b 树却需要重复地中序遍历,找到所有的范围内的节点。
为什么用 B+ 树做索引而不用哈希表做索引?
1、模糊查找不支持:哈希表是把索引字段映射成对应的哈希码然后再存放在对应的位置, 这样的话,如果我们要进行模糊查找的话,显然哈希表这种结构是不支持的,只能遍历这个 表。而 B + 树则可以通过最左前缀原则快速找到对应的数据。
2、范围查找不支持:如果我们要进行范围查找,例如查找 ID 为 100 ~ 400 的人,哈希表同 样不支持,只能遍历全表。
3、哈希冲突问题:索引字段通过哈希映射成哈希码,如果很多字段都刚好映射到相同值的 哈希码的话,那么形成的索引结构将会是一条很长的链表,这样的话,查找的时间就会大大增加。
SQL优化
-
针对SQL进行调整,在写SQL的时候遵循最左前缀原则,向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,范围列可以用到索引,但是范围列后面的列无法用到索引。
-
like以通配符%开头索引失效会变成全表扫描的操作。
-
如果查询条件中含有函数或表达式,将导致索引失效而进行全表扫描。
-
只要列中包含有 NULL 值都将不会被包含在索引中,复合索引中只要有一列含有 NULL 值,那么这一列对于此复合索引就是无效的。
-
不要使用select *,改用select加字段名称,因为select *走的聚集索引,会进行全表扫描,如果一定要使用select *的话,mysql至少使用5.6版本,这个版本有一个离散读的优化,离散读的优化是将离散度大的列放到联合索引的前面,举个例子,select * from user where staff_id = 2 and customer_id = 584,这个时候索引优化会将customer_id放到前面,因为它的离散度更高,可以通过select count(distinct customer_id),count(distinct staff_id) from user查看列的离散度。
5.6版本有一个ICP的优化,以往根据索引查找记录,再根据WHERE条件来过滤记录。使用ICP优化后,会在取出索引的同时,直接根据WHERE条件过滤,将WHERE的部分过滤操作放在了存储引擎层。在某些查询下可以大大减少上层SQL层对记录的索取,从而提高性能。
5.6版本还有一个MRR优化,是批量处理对键值的查询操作ICP优化,减少缓冲池中页被替换的次数,使数据访问变得较为顺序。辅助索引查询得到书签后,先对主键进行排序,再按序进行查找。
- 另外在写sql的时候,尽量使用它的一个执行计划,去看我们的索引是不是失效了。
索引失效的几种情况
-
如果条件中有or,即使其中有部分条件带索引也不会使用。
-
对于复合索引,如果不使用前列,后续列也将无法使用。
-
like以%开头。列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引。
-
where中索引列有运算,有函数的,不使用索引。
-
如果mysql觉得全表扫描更快的时候,数据少的情况下,不使用索引。
聚集索引
InnoDB存储引擎表是索引组织表,即表中数据按照主键顺序存放。而聚集索引(clusteredindex)就是按照每张表的主键构造一棵B+树,同时叶子节点中存放的即为整张表的行记录数据,也将聚集索引的叶子节点称为数据页。每个数据页都通过一个双向链表来进行链接由于实际的数据页只能按照一棵B+树进行排序,因此每张表只能拥有一个聚集索引。在多数情况下,查询优化器倾向于采用聚集索引。因为聚集索引能够在B+树索引的叶子节点上直接找到数据。此外,由于定义了数据的逻辑顺序,它对于主键的排序查找和范围查找速度非常快。叶子节点的数据就是用户所要查询的数据如:用户需要查询一张注册用户的表,查询最后注册的10位用户,由于B+树索引是双向链表的,用户可以快速找到最后一个数据页,并取出10条记录SELECT * FROM Profile ORDER BY id LIMIT 10;虽然使用ORDER BY对主键id记录进行排序,但是在实际过程中并没有进行所谓的filesort操作,而这就是因为聚集索引的特点。另一个是范围查询(range query),即如果要查找主键某一范围内的数据,通过叶子节点的上层中间节点就可以得到页的范围,之后直接读取数据页即可。如:SELECT * FROM Profile where id>1 and id < 100;
辅助索引
对于辅助索引(Secondary Index,也称非聚集索引),叶子节点并不包含行记录的全部数据。叶子节点除了包含键值以外,每个叶子节点中的索引行中还包含了一个书签(bookmark)。该书签用来告诉InnoDB存储引擎哪里可以找到与索引相对应的行数据。由于InnoDB存储引擎表是索引组织表,因此InnoDB存储引擎的辅助索引的书签就是相应行数据的聚集索引键。辅助索引的存在并不影响数据在聚集索引中的组织,因此每张表上可以有多个辅助索引。当通过辅助索引来寻找数据时,InnoDB存储引擎会遍历辅助索引并通过叶级别的指针获得指向主键索引的主键,然后再通过主键索引来找到一个完整的行记录。举例来说,如果在一棵高度为3的辅助索引树中查找数据,那需要对这棵辅助索引树遍历3次找到指定主键,如果聚集索引树的高度同样为3,那么还需要对聚集索引树进行3次查找,最终找到一个完整的行数据所在的页,因此一共需要6次逻辑IO访问以得到最终的一个数据页。
覆盖索引,什么情况下优化器会选择使用覆盖索引
InnoDB存储引擎支持覆盖索引(covering index,或称索引覆盖),即从辅助索引中就可以得到查询的记录(此时不能够使用select * 操作,只能对特定的索引字段进行select),而不需要查询聚集索引中的记录。使用覆盖
索引的一个好处是辅助索引不包含整行记录的所有信息,故其大小要远小于聚集索引,因此可以减少大量的IO操作。对于InnoDB存储引擎的辅助索引而言,由于其包含了主键信息,因此其叶子节点存放的数据为(primarykey1,primary key2,…,key1,key2,…)。例如,下列语句都可仅使用一次辅助联合索引来完成查询:
SELECT key2 FROM table WHERE key1=xxx;
SELECT primary key2,key2 FROM table WHERE key1=xxx;
SELECT primary key1,key2 FROM table WHERE key1=xxx;
SELECT primary key1,primary key2,key2 FROM table WHERE key1=xxx;
CREATETABLEbuy_log(
userid INT UNSIGNED NOT NULL,
buy_date DATE
)ENGINE=InnoDB;
ALTER TABLE buy_log ADD KEY (userid);
ALTER TABLE buy_log ADD KEY (userid,buy_date);
覆盖索引的另一个好处是对某些统计问题而言的。还是对于上题创建的表buy_log,要进行举例说明。
SELECT COUNT(*) FROM buy_log;InnoDB存储引擎并不会选择通过查询聚集索引来进行统计。由于buy_log表上还有辅助索引,而辅助索引远小于聚集索引,选择辅助索引可以减少IO操作。
在通常情况下,诸如(a,b)的联合索引,一般是不可以选择列b中所谓的查询条件。但是如果是统计操作,并且是覆盖索引的,则优化器会进行选择,如下述语句:SELECT COUNT(*)FROM buy_log WHERE buy_date>=‘2011-01-01’ANDbuy_date<’2011-02-01’
表buy_log有(userid,buy_date)的联合索引,这里只根据列b进行条件查询,一般情况下是不能进行该联合索引的,但是这句SQL查询是统计操作,并且可以利用到覆盖索引的信息,因此优化器会选择该联合索引.
联合索引
联合索引是指对表上的多个列进行索引。
CREATE TABLE buy_log(
userid INT UNSIGNED NOT NULL,
buy_date DATE
)ENGINE=InnoDB;
ALTER TABLE buy_log ADD KEY (userid);
ALTER TABLE buy_log ADD KEY (userid,buy_date);
以上代码建立了两个索引来进行比较。两个索引都包含了userid字段。
情况1: 如果只对于userid进行查询,如:SELECT * FROM buy_log WHERE userid=2;索引选择:优化器最终的选择是索引userid,因为该索引的叶子节点包含单个键值,所以理论上一个页能存放的记录应该更多。
情况2:SELECT * FROM buy_log WHERE userid=1 ORDER BY buy_date DESC LIMIT 3;索引选择:优化器使用了(userid,buy_date)的联合索引userid_2,因为在这个联合索引中buy_date已经排序好了。根据该联合索引取出数据,无须再对buy_date做一次额外的排序操作。
情况 3:假如三个字段的联合索引。如:对于联合索引(a,b,c)来说,下列语句同样可以直接通过联合索引得到结果,不需要filesort的排序操作:
SELECT...FROM TABLE WHERE a=xxx ORDER BY b
SELECT...FROM TABLE WHERE a=xxx AND b=xxx ORDER BY c
但是对于下面的语句,联合索引不能直接得到结果,其还需要执行一次filesort排序操作,因为索引(a,c)并未排序:
SELECT...FROM TABLE WHERE a=xxx ORDER BY c
索引总结
聚集索引的叶子节点称为数据页,每个数据页通过一个双向链表来进行链接,而且数据页按照主键的顺序进行排列。每个数据页上存放的是完整的行记录,而在非数据页的索引页中,存放的仅仅是键值及指向数据页的偏移量,而不是一个完整的行记录。如果定义了主键,InnoDB会自动使用主键来创建聚集索引。如果没有定义主键,InnoDB会选择一个唯一的非空索引代替主键。如果没有唯一的非空索引,InnoDB会隐式定义一个主键来作为聚集索引。
辅助索引它叶子节点中没有行记录的全部数据,叶子节点除了包含键值以外,每个叶子节点的索引行还包含了一个书签,该书签用来告诉InnoDB哪里可以找到与索引相对应的行数据。
覆盖索引先遍历辅助索引,再遍历聚集索引,而如果要查询的字段值在辅助索引上就有,就不用再查聚集索引了,这显然会减少IO操作。
联合索引,它是对表上的多个列进行索引,键值都是排序的,通过叶子节点可以顺序的读出所有数据,联合索引的好处在于能起到"一个顶三个"的作用。比如建了一个(a,b,c)的复合索引,那么实际等于建了(a),(a,b),(a,b,c)三个索引,每多一个索引,都会增加写操作的开销和磁盘空间的开销,对于大数据的表,这是不小的开销。另外它还可以避免filesort排序,因为filesort的过程,一行数据会被读两次,第一次是where条件过滤时,第二个是排完序后还得用行指针去读一次。
redo log 和bin log有什么区别?binlog做什么用的
在MySQL数据库中有一种二进制日志(binlog),其用来进行POINT-IN-TIME(PIT)的恢复及主从复制(Replication)环境的建立。从表面上看其和重做日志非常相似,都是记录了对于数据库操作的日志。然而,从本质上来看,两者有着非常大的不同。首先,重做日志是在InnoDB存储引擎层产生,而二进制日志是在MySQL数据库的上层产生的,并且二进制日志不仅仅针对于InnoDB存储引擎,MySQL数据库中的任何存储引擎对于数据库的更改都会产生二进制日志。其次,两种日志记录的内容形式不同。MySQL数据库上层的二进制日志bin log是一种逻辑日志,其记录的是对应的SQL语句。而InnoDB存储引擎层面的重做日志是物理格式日志,其记录的是对于每个页的修改。
什么是undolog,有什么用?
重做日志记录了事务的行为,可以很好地通过其对页进行“重做”操作。但是事务有时还需要进行回滚操作,这时就需要undo。因此在对数据库进行修改时,InnoDB存储引擎不但会产生redo,还会产生一定量的undo。这样如果用户执行的事务或语句由于某种原因失败了,又或者用户用一条ROLLBACK语句请求回滚,就可以利用这些undo信息将数据回滚到修改之前的样子。redo存放在重做日志文件中,与redo不同,undo存放在数据库内部的一个特殊段(segment)中,这个段称为undo段(undo segment)。undo段位于共享表空间内。可以通过py_innodb_page_info.py工具来查看当前共享表空间中undo的数量除了回滚操作,undo的另一个作用是MVCC,即在InnoDB存储引擎中MVCC的实现是通过undo来完成。当用户读取一行记录时,若该记录已经被其他事务占用,当前事务可以通过undo读取之前的行版本信息,以此实现非锁定读取。最后也是最为重要的一点是,undo log会产生redo log,也就是undo log的产生会伴随着redolog的产生,这是因为undo log也需要持久性的保护。
分布式事务
InnoDB存储引擎提供了对XA事务的支持,并通过XA事务来支持分布式事务的实现。分布式事务指的是允许多个独立的事务资源(transactional resources)参与到一个全局的事务中。事务资源通常是关系型数据库系统,但也可以是其他类型的资源。全局事务要求在其中的所有参与的事务要么都提交,要么都回滚,这对于事务原有的ACID要求又有了提高。另外,在使用分布式事务时,InnoDB存储引擎的事务隔离级别必须设置为SERIALIZABLE。XA事务允许不同数据库之间的分布式事务,如一台服务器是MySQL数据库的,另一台是Oracle数据库的,又可能还有一台服务器是SQL Server数据库的,只要参与在全局事务中的每个节点都支持XA事务。分布式事务可能在银行系统的转账中比较常见,如用户David需要从上海转10 000元到北京的用户Mariah的银行卡中:
#Bank@Shanghai:
UPDATE account SET money=money-10000WHEREuser='David';
#Bank@Beijing
UPDATE account SET money=money+10000WHEREuser='Mariah';
在这种情况下,一定需要使用分布式事务来保证数据的安全。如果发生的操作不能全部提交或回滚,那么任何一个结点出现问题都会导致严重的结果。要么是David的账户被扣款,但是Mariah没收到,又或者是David的账户没有扣款,Mariah却收到钱了。
XA事务由一个或多个资源管理器(Resource Managers)、一个事务管理器(TransactionManager)以 及一个应用程序(ApplicationProgram)组成。❑资源管理器:提供访问事务资源的方法。通常一个数据库就是一个资源管理器。❑事务管理器:协调参与全局事务中的各个事务。需要和参与全局事务的所有资源管理器进行通信。❑应用程序:定义事务的边界,指定全局事务中的操作。在MySQL数据库的分布式事务中,资源管理器就是MySQL数据库,事务管理器为连接MySQL服务器的客户端。
分布式事务使用两段式提交(two-phasecommit)的方式。在第一阶段,所有参与全局事务的节点都开始准备(PREPARE),告诉事务管理器它们准备好提交了。在第二阶段,事务管理器告诉资源管理器执行ROLLBACK还是COMMIT。如果任何一个节点显示不能提交,则所有的节点都被告知需要回滚。可见与本地事务不同的是,分布式事务需要多一次的PREPARE操作,待收到所有节点的同意信息后,再进行COMMIT或是ROLLBACK操作。
最为常见的内部XA事务存在于binlog与InnoDB存储引擎之间。由于复制的需要,因此目前绝大多数的数据库都开启了binlog功能。在事务提交时,先写二进制日志,再写InnoDB存储引擎的重做日志。对上述两个操作的要求,也是原子的,即二进制日志和重做日志必须同时写入。若二进制日志先写了,而在写入InnoDB存储引擎时发生了宕机,那么slave可能会接收到master传过去的二进制日志并执行,最终导致了主从不一致的情况。
CAP理论
分布式环境下(数据分布)要任何时刻保证数据一致性是不可能的,只能采取妥协的方案来保证数据最终一致性。这个也就是著名的CAP定理。
C一致性:对于指定的客户端来说,读操作保证能够返回最新的写操作结果。
A可用性:非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。
P分区容错性:当出现网络分区后,系统能够继续“履行职责”。
对于一个分布式系统而言,网络失效一定会发生,分区容错性P其实就是每个服务都会有多个节点(一般都是主从),这样就可以保证此服务的一个节点挂了之后,此服务的其他节点依然可以响应,其实这就是分区容错性。
但是一个服务有多个节点之后,一个服务的多个节点之间的数据为了保持一致性就要进行的数据复制,在此过程中就会出现数据一致性C(强一致性)的问题。也就是说,分区耐受性是必须要保证的,那么在可用性和一致性就必须二选一。网络不可用的时候,如果选择了一致性,系统就可能返回一个错误码或者干脆超时,即系统不可用。如果选择了可用性,那么系统总是可以返回一个数据,但是并不能保证这个数据是最新的。
BASE理论
BASE 理论是对 CAP 理论的延伸,核心思想是即使无法做到强一致性,但应用可以采用适合的方式达到最终一致性。
基本可用: 基本可用是指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。电商大促时,为了应对访问量激增,部分用户可能会被引导到降级页面,服务层也可能只提供降级服务。这就是损失部分可用性的体现。
软状态: 软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据至少会有三个副本,允许不同节点间副本同步的延时就是软状态的体现。MySQL Replication 的异步复制也是一种体现。
最终一致性: 最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。
应用场景:
Erueka:erueka是SpringCloud系列用来做服务注册和发现的组件,作为服务发现的一个实现,在设计的时候就更考虑了可用性,保证了AP。
Zookeeper:Zookeeper在实现上牺牲了可用性,保证了一致性(单调一致性)和分区容错性,也即:CP。所以这也是SpringCloud抛弃了zookeeper而选择Erueka的原因。
具体根据各自业务场景所需来制定相应的策略而选择适合的产品服务等。例如:支付订单场景中,由于分布式本身就在数据一致性上面很难保证,从A服务到B服务的订单数据有可能由于服务宕机或其他原因而造成数据不一致性。因此此类场景会酌情考虑:AP,不强制保证数据一致性,但保证数据最终一致性。
分布式事务指事务的操作位于不同的节点上,需要保证事务的 AICD 特性,在下单场景下,库存和订单如果不在同一个节点上,就涉及分布式事务。
两阶段提交(2PC)
第一阶段:协调者询问参与者事务是否执行成功,参与者发回事务执行结果。这一阶段的协调者有超时机制,假设因为网络原因没有收到某参与者的响应或某参与者挂了,那么超时后就会判断事务失败,向所有参与者发送回滚命令。
第二阶段:如果事务在每个参与者上都执行成功,事务协调者才发送通知让参与者提交事务;否则,协调者发送通知让参与者回滚事务。这一阶段的协调者的没法超时,只能不断重试。
协调者是一个单点,存在单点故障问题。
假设协调者在发送准备命令之前挂了,还行等于事务还没开始。
假设协调者在发送准备命令之后挂了,这就不太行了,有些参与者等于都执行了处于事务资源锁定的状态。不仅事务执行不下去,还会因为锁定了一些公共资源而阻塞系统其它操作。
假设协调者在发送回滚事务命令之前挂了,那么事务也是执行不下去,且在第一阶段那些准备成功参与者都阻塞着。
假设协调者在发送回滚事务命令之后挂了,这个还行,至少命令发出去了,很大的概率都会回滚成功,资源都会释放。但是如果出现网络分区问题,某些参与者将因为收不到命令而阻塞着。
假设协调者在发送提交事务命令之前挂了,这个不行,傻了!这下是所有资源都阻塞着。
假设协调者在发送提交事务命令之后挂了,这个还行,也是至少命令发出去了,很大概率都会提交成功,然后释放资源,但是如果出现网络分区问题某些参与者将因为收不到命令而阻塞着。
存在的缺点:
同步阻塞 所有事务参与者在等待其它参与者响应的时候都处于同步阻塞状态,无法进行其它操作。
单点问题 协调者在 2PC 中起到非常大的作用,发生故障将会造成很大影响。特别是在阶段二发生故障,所有参与者会一直等待状态,无法完成其它操作。
数据不一致 在阶段二,如果协调者只发送了部分 Commit 消息,此时网络发生异常,那么只有部分参与者接收到 Commit 消息,也就是说只有部分参与者提交了事务,使得系统数据不一致。
太过保守 任意一个节点失败就会导致整个事务失败,没有完善的容错机制。
三阶段提交(3PC)
相比于 2PC 它在参与者中也引入了超时机制,并且新增了一个阶段使得参与者可以利用这一个阶段统一各自的状态,3PC 包含了三个阶段,分别是准备阶段、预提交阶段和提交阶段
准备阶段的变更成不会直接执行事务,而是会先去询问此时的参与者是否有条件接这个事务,因此不会一来就干活直接锁资源,使得在某些资源不可用的情况下所有参与者都阻塞着。
而预提交阶段的引入起到了一个统一状态的作用,它像一道栅栏,表明在预提交阶段前所有参与者其实还未都回应,在预处理阶段表明所有参与者都已经回应了。
假如你是一位参与者,你知道自己进入了预提交状态那你就可以推断出来其他参与者也都进入了预提交状态。
缺点:
多引入一个阶段也多一个交互,因此性能会差一些,而且绝大部分的情况下资源应该都是可用的,这样等于每次明知可用执行还得询问一次。
和2PC对比:
2PC 是同步阻塞的,协调者挂在了提交请求还未发出去的时候是最伤的,所有参与者都已经锁定资源并且阻塞等待着,提交阶段 2PC 协调者和某参与者都挂了之后新选举的协调者不知道当前应该提交还是回滚
改进的优势:
新协调者来的时候发现有一个参与者处于预提交或者提交阶段,那么表明已经经过了所有参与者的确认了,所以此时执行的就是提交命令。
所以说 3PC 就是通过引入预提交阶段来使得参与者之间的状态得到统一,也就是留了一个阶段让大家同步一下。
但是这也只能让协调者知道该如果做,但不能保证这样做一定对,这其实和上面 2PC 分析一致,因为挂了的参与者到底有没有执行事务无法断定。
所以说 3PC 通过预提交阶段可以减少故障恢复时候的复杂性,但是不能保证数据一致,除非挂了的那个参与者恢复。
总结一下
3PC 相对于 2PC 做了一定的改进:引入了参与者超时机制,并且增加了预提交阶段使得故障恢复之后协调者的决策复杂度降低,但整体的交互过程更长了,性能有所下降,并且还是会存在数据不一致问题。
2PC 和 3PC 都不能保证数据100%一致,因此一般都需要有定时扫描补偿机制
补偿事务(TCC)
针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。它分为三个阶段:
Try 阶段主要是对业务系统做检测及资源预留
Confirm 阶段主要是对业务系统做确认提交,Try阶段执行成功并开始执行 Confirm阶段时,默认 Confirm阶段是不会出错的。即:只要Try成功,Confirm一定成功。
Cancel 阶段主要是在业务执行错误,需要回滚的状态下执行的业务取消,预留资源释放。
举个例子,假入 Bob 要向 Smith 转账,思路大概是:我们有一个本地方法,里面依次调用
首先在 Try 阶段,要先调用远程接口把 Smith 和 Bob 的钱给冻结起来。
在 Confirm 阶段,执行远程调用的转账的操作,转账成功进行解冻。
如果第2步执行成功,那么转账成功,如果第二步执行失败,则调用远程冻结接口对应的解冻方法 (Cancel)。
优点: 跟2PC比起来,实现以及流程相对简单了一些,但数据的一致性比2PC也要差一些
缺点: 缺点还是比较明显的,在2,3步中都有可能失败。TCC属于应用层的一种补偿方式,所以需要程序员在实现的时候多写很多补偿的代码,在一些场景中,一些业务流程可能用TCC不太好定义及处理
MQ 事务消息
有一些第三方的MQ是支持事务消息的,比如RocketMQ,他们支持事务消息的方式也是类似于采用的二阶段提交,但是市面上一些主流的MQ都是不支持事务消息的,比如 RabbitMQ 和 Kafka 都不支持。
第一阶段Prepared消息,会拿到消息的地址。第二阶段执行本地事务,第三阶段通过第一阶段拿到的地址去访问消息,并修改状态。也就是说在业务方法内要想消息队列提交两次请求,一次发送消息和一次确认消息。如果确认消息发送失败了RocketMQ会定期扫描消息集群中的事务消息,这时候发现了Prepared消息,它会向消息发送者确认,所以生产方需要实现一个check接口,RocketMQ会根据发送端设置的策略来决定是回滚还是继续发送确认消息。这样就保证了消息发送与本地事务同时成功或同时失败。
优点: 实现了最终一致性,不需要依赖本地数据库事务。
缺点: 实现难度大,主流MQ不支持,RocketMQ事务消息部分代码也未开源。
最大努力通知
其实我觉得本地消息表也可以算最大努力,事务消息也可以算最大努力。
就本地消息表来说会有后台任务定时去查看未完成的消息,然后去调用对应的服务,当一个消息多次调用都失败的时候可以记录下然后引入人工,或者直接舍弃。这其实算是最大努力了。
事务消息也是一样,当半消息被commit了之后确实就是普通消息了,如果订阅者一直不消费或者消费不了则会一直重试,到最后进入死信队列。其实这也算最大努力。
所以最大努力通知其实只是表明了一种柔性事务的思想:我已经尽力我最大的努力想达成事务的最终一致了。适用于对时间不敏感的业务,例如短信通知。
各个场景对比的解决方案:
2PC 和 3PC 是一种强一致性事务,不过还是有数据不一致,阻塞等风险,而且只能用在数据库层面。
而 TCC 是一种补偿性事务思想,适用的范围更广,在业务层面实现,因此对业务的侵入性较大,每一个操作都需要实现对应的三个方法。
本地消息、事务消息和最大努力通知其实都是最终一致性事务,因此适用于一些对时间不敏感的业务。
SQL的执行流程
第一步,先连接到这个数据库上,这时候接待你的就是连接器。连接器负责跟客户端建立连接、获取权限、维持和管理连接。用户名密码认证通过,连接器会到权限表里面查出你拥有的权限。一个用户成功建立连接后,即使你用管理员账号对这个用户的权限做了修改,也不会影响已经存在连接的权限。修改完成后,只有再新建的连接才会使用新的权限设置。连接完成后,如果你没有后续的动作,这个连接就处于空闲状态,你可以在 show processlist 命令中看到它。客户端如果长时间不发送command到Server端,连接器就会自动将它断开。这个时间是由参数 wait_timeout 控制的,默认值是 8 小时。
第二步:查询缓存。MySQL 拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。之前执行过的语句及其结果可能会以 key-value对的形式,被直接缓存在内存中。key 是查询的语句,value 是查询的结果。如果你的查询能够直接在这个缓存中找到 key,那么这个value就会被直接返回给客户端。如果语句不在查询缓存中,就会继续后面的执行阶段。执行完成后,执行结果会被存入查询缓存中。你可以看到,如果查询命中缓存,MySQL不需要执行后面的复杂操作,就可以直接返回结果,这个效率会很高。大多数情况查询缓存就是个鸡肋,为什么呢?因为查询缓存往往弊大于利。查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。因此很可能你费劲地把结果存起来,还没使用呢,就被一个更新全清空了。对于更新压力大的数据库来说,查询缓存的命中率会非常低。这个鸡肋也有地方可以去使用它,比如说不会改变的表数据,极少更新的表,像一些系统配置表、字典表,全国的省份之类的表,这些表上的查询适合使用查询缓存。MySQL提供了这种“按需使用”的方式,可以将my.cnf参数query_cache_type 设置成2,query_cache_type有3个值:0代表关闭查询缓存,1代表开启,2代表当sql语句中有SQL_CACHE关键词时才缓存。确定要使用查询缓存的语句,用 SQL_CACHE显式指定,比如,select SQL_CACHE * from user where ID=5;
第三步,如果没有命中查询缓存,就要开始真正执行语句了。MySQL 需要知道你要做什么,需要对 SQL 语句做解析。
分析器先会做“词法分析”,你输入的一条 SQL 语句,MySQL需要识别出里面的字符串分别是什么,代表什么。MySQL从你输入的"select"这个关键字识别出来,这是一个查询语句。它也要把字符串“user”识别成“表名 user”,把字符串“ID”识别成“列 ID”。做完了这些识别以后,就要做“语法分析”。根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL语句是否满足MySQL语法。如果你的语句不对,就会收到“您的SQL语法有错误”的错误提醒。语句正确之后,会丢到分析机里面执行分析,语法分析由Bison生成,经过bison语法分析之后,会生成一个语法树。比如,你的操作是select还是insert,你需要对那些字段进行操作,作用在哪张表上面,条件是什么。
 经过了分析器,MySQL就知道这些字符串代表什么,要做什么了。在开始执行之前,还要先经过优化器的处理。
经过了分析器,MySQL就知道这些字符串代表什么,要做什么了。在开始执行之前,还要先经过优化器的处理。
第四步,优化器,在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联的时候,优化器可以决定各个表的连接顺序,同一条多表查询的sql,执行的方案会有多种,比如,select * from user1 join user2 on user1.id = user2.id where user1.name=liaozhiwei and user2.name=haoshuai;既可以先从表user1 里面取出 name=liaozhiwei的 ID 值,再根据 ID 值关联到表user2,再判断user2 里面 name的值是否等于liaozhiwei。也可以先从表user2 里面取出 name=haoshuai的 ID 值,再根据 ID 值关联到user1,再判断user1 里面 name 的值是否等于haoshuai。这两种执行方法的逻辑结果是一样的,但是执行的效率会有不同,而优化器的作用就是决定选择使用哪一个方案。执行方案就确定下来了,然后进入执行器阶段。
第五步,开始执行的时候,要先判断一下你对这个表有没有执行查询的权限,如果没有,就会返回没有权限的错误。如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。比如,我有一条sql:select * from user where id=10;执行器调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是10,如果不是则跳过, 调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行,如果是将这行保存在结果集中。执行器将遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。到这一步,这个语句就执行完成了。
Mysql调优
第一步,从初期的一个需求规划,也就是对表的设计就开始了,先从底层开始说吧,mysql底层的页的大小是16kb,假如,我有一张表对单行数据量就有16kb,那么这张表就只能存储1条数据了,这是非常恐怖的。mysql是从磁盘读取数据到内存的,是以磁盘块为基本单位的,位于同一磁盘块中的数据会被一次性读取出来,不是按需读取。以InnoDB存储引擎来说,它使用页作为数据读取单位,页是其磁盘管理的最小单位,默认大小是16kb。系统的一个磁盘块的存储空间往往没有这么大,所以InnoDB每次申请磁盘空间时都会是多个地址连续磁盘块来达到页的大小16KB。在查询数据时一个页中的每条数据都能定位数据记录的位置,这会减少磁盘 I/O 的次数,提高查询效率。InnoDB存储引擎在设计时是将根节点常驻内存的,力求达到树的深度不超过 3,也就是说I/O不超过3次。树形结构的数据可以让系统高效的找到数据所在的磁盘块,这里就可以说一下这个b树和b+树了,B树的结构是每个节点中有key也有value,而每一个页的存储空间是16kb,如果数据较大时将会导致一页能存储数据量的数量很小。B+Tree的结构是将所有数据记录节点按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储 key 值信息,这样可以大大加大每个节点存储的key 值数量,降低B+Tree的高度。所以通过mysql的底层存储的原理和数据结构,我们在设计表的时候,尽量减少单行数据的大小,字段的宽度设得尽可能小,尽可能不用text、Blob、Clob等类型,它会增加存储空间的占用,读取速度较慢。能用数字型字段就不要设计为字符型,因为字符型锁占的存储空间更大,比如,性别这个字段不用男女进行存储,改为0/1的方式,这样不仅可以控制数据量的大小,增加了同一高度下的B+树容纳的数据量,还能提高检索速度。尽量使用varchar/nvarchar代替char/nchar,因为变长字段空间小,可以节省存储空间。不在数据库中存储图片、文件等大数据,可以通过第三方云存储,存放图片或者文件地址。金额用decimal,注意长度和精度。如果存储的数据范围超过decimal的范围,建议将数据拆成整数和小树分开存储。尽可能不要给数据库留null值,尤其是时间、整数等类型,可以在建表的时候就给非空设置,NULL的列会使用更多的存储空间,在Mysql中也需要特殊处理,为NULL的列会使索引统计和值比较都更复杂,当可为NULL的列被索引时,每个索引记录需要一个额外的字节,在MyISAM里甚至还可能导致固定大小的索引(例如只有一个整数列的索引)变成可变大小的索引。
第二步,就是建索引,当对表中的数据进⾏增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度,所以不是所有字段都适合创建索引的,比如要频繁更改数据不建议使⽤索引,又或者对于关于区分度不高的字段,比如性别,状态字段,就不适合创建索引,只有几种取值的字段,建了索引,数据库也不一定会用,只会白白增加索引维护的额外开销,因为索引也是需要存储的,所以插入和更新的写入操作,需要插入和更新这个字段的索引的。一般需要查询排序,分组和联合操作的字段适合建⽴索引,另外索引多,数据更新表越慢,所以尽量使⽤字段值不重复的字段创建索引。
mysql有聚簇索引,辅助索引,覆盖索引。聚集索引的叶子节点称为数据页,每个数据页通过一个双向链表来进行链接,而且数据页按照主键的顺序进行排列。每个数据页上存放的是完整的行记录,而在非数据页的索引页中,存放的仅仅是键值及指向数据页的偏移量,而不是一个完整的行记录。如果定义了主键,InnoDB会自动使用主键来创建聚集索引。如果没有定义主键,InnoDB会选择一个唯一的非空索引代替主键。如果没有唯一的非空索引,InnoDB会隐式定义一个主键来作为聚集索引。辅助索引它叶子节点中没有行记录的全部数据,叶子节点除了包含键值以外,每个叶子节点的索引行还包含了一个书签,该书签用来告诉InnoDB哪里可以找到与索引相对应的行数据。覆盖索引先遍历辅助索引,再遍历聚集索引,而如果要查询的字段值在辅助索引上就有,就不用再查聚集索引了,这显然会减少IO操作。除了这三种索引,还有一种联合索引,它是对表上的多个列进行索引,键值都是排序的,通过叶子节点可以顺序的读出所有数据,联合索引的好处在于能起到"一个顶三个"的作用。比如建了一个(a,b,c)的复合索引,那么实际等于建了(a),(a,b),(a,b,c)三个索引,每多一个索引,都会增加写操作的开销和磁盘空间的开销,对于大数据的表,这是不小的开销。另外它还可以避免filesort排序,因为filesort的过程,一行数据会被读两次,第一次是where条件过滤时,第二个是排完序后还得用行指针去读一次。filesort的过程是这样的:第一步先根据表的索引或者全表扫描,读取所有满足条件的记录。第二步,存储每一行排序列,就是order by用到的列值,还有行记录指针,就是指向该行数据的行指针,把这二个存储到缓冲区。第三步,当缓冲区满后,运行一个快速排序来将缓冲区中数据排序,将排序完的数据存储到一个临时文件,保存一个存储块的指针,当然如果缓冲区不满,则不会重建临时文件了。直到将所有行读完,建立相应有序的临时文件。第四步,对块级进行排序,这个类似归并排序算法,只通过两个临时文件的指针来不断交换数据,最终达到两个文件,都是有序的,直到所有的数据都排序完毕。第五步,采取顺序读的方式,将每行数据读入内存,取出数据传到客户端。为什么要说这个filesort呢?举二个场景,第一个,如果order by的条件不在索引列上会产生filesort,第二个,排序的字段不在where的条件中,没有办法走索引排序Index,而是走的文件排序filesort 。这种概率其实还是挺高的。这个时候就需要看文件排序用的是单路排序还是双路排序,单路排序会把所有需要查询的字段都放到 sort buffer 中,而双路排序只会把主键 和需要排序的字段放到 sort buffer 中进行排序,然后再通过主键回到原表查询需要的字段。mysql优化器使用双路排序还是单路排序是有自己的算法判断的,如果查询的列字段大于max_length_for_sort_data变量,则会使用双路排序,反之则会使用单路排序。单路排序速度是更快的,不过比较占据内存,如果在内存空间允许的情况下想要使用单路排序的话,可以增加max_length_for_sort_data变量的大小,max_length_for_sort_data变量默认为1024字节。另外sort_buffer_size参数修改为2M,减少在排序过程中对须要排序的数据进行分段,尽量不使用临时表来进行交换排序。这个参数如果超过 2M 的时候,就会使用 mmap(),而不是 malloc() 来进行内存分配,会导致效率降低。这个参数如果过小的话,再加上max_length_for_sort_data变大,一次返回的条数过多,那么很可能就会分很多次进行排序,然后最后将每次的排序结果再串联起来,这样就会更慢。最后read_buffer_size参数也可以根据实际情况调整,它是MySQL读入缓冲区大小,对表进行顺序扫描的请求将分配一个读入缓冲区,MySQL会为它分配一段内存缓冲区。read_buffer_size变量控制这一缓冲区的大小,默认是1M。如果对表的顺序扫描请求非常频繁,并且你认为频繁扫描进行得太慢,可以通过增加该变量值以及内存缓冲区大小提高其性能。
第三步,针对SQL进行调整,在写SQL的时候遵循最左前缀原则,向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,范围列可以用到索引,但是范围列后面的列无法用到索引。like以通配符%开头索引失效会变成全表扫描的操作。如果查询条件中含有函数或表达式,将导致索引失效而进行全表扫描。只要列中包含有 NULL 值都将不会被包含在索引中,复合索引中只要有一列含有 NULL 值,那么这一列对于此复合索引就是无效的。不要使用select *,改用select加字段名称,因为select *走的聚集索引,会进行全表扫描,如果一定要使用select *的话,mysql至少使用5.6版本,这个版本有一个离散读的优化,离散读的优化是将离散度大的列放到联合索引的前面,举个例子,
select * from user where staff_id = 2 and customer_id = 584,这个时候索引优化会将customer_id放到前面,因为它的离散度更高,可以通过select count(distinct customer_id),count(distinct staff_id) from user查看列的离散度。有一个ICP的优化,以往,根据索引查找记录,再根据WHERE条件来过滤记录。使用ICP优化后,会在取出索引的同时,直接根据WHERE条件过滤,将WHERE的部分过滤操作放在了存储引擎层。在某些查询下可以大大减少上层SQL层对记录的索取,从而提高性能。还有一个MRR优化,它是减少磁盘的随机访问,并且将随机访问转化为较为顺序的数据访问,在查询辅助索引时,首先根据得到的查询结果,将查询得到的辅助索引键值存放于一个缓存中,这时缓存中的数据是根据辅助索引键值排序的,然后按照主键进行排序,并按照主键排序的顺序进行书签查找。顺序查找可以对一个页进行顺序查找,无需离散加载数据页,可以减少缓冲池中页被替换的次数,能够批量处理对键值的查询操作。另外在写sql的时候,尽量使用它的一个explain执行计划,去看我们的索引是不是失效了。索引失效有这么几种情况,上面也提到过几个,如果条件中有or,即使其中有部分条件带索引也不会使用。对于复合索引,如果不使用前列,后续列也将无法使用。like以%开头。列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引。where中索引列有运算,有函数的,不使用索引。如果mysql觉得全表扫描更快的时候,数据少的情况下,不使用索引。
第四步,随着数据量的增涨之后,会考虑一个数据的分区,Partition分区,表分区必须在表建立的时候创建规则,而已经存在的没有创建过表分区规则的表需要重新做导入处理。如果想修改有规则的表分区,只能新增,不要随意删除,删除表分区会造成该表分区内部数据也一起被删除掉。除此之外,分区也需要结合实际场景进行分区,而且Partition分区也是有一个局限性,因为单台的mysql服务器支持1024个分区,一旦达到这个分区上限,考虑垂直拆分和水平拆分了。垂直分区,它是将单表变多表,这样也是有些优点的,一条数据存储的数据量越小,三层b+所容纳的数据量是更多的,这样一个分区就可以承载多个数据,多个分区它承载的数据就会更多,这是一个累加的效果,不过也有缺点,就是进行表的垂直划分的时候,还需要考虑它的一个关联性,在进行sql查询的情况下,需要反复测试,考虑它的一个性能问题,最好的结果就是拆分出来的表还是能够支持铁定的业务线。比如一个包含了大text和BLOB列的表,这些text和BLOB列又不经常被访问,这时候就要把这些不经常使用的text和BLOB了划分到另一个分区,在保证它们数据相关性的同时还能提高访问速度。随着数据量持续的增涨,这个时候就需要考虑水平分区了,水平分区有多种模式,Range(范围)模式:允许DBA将数据划分不同范围。比如DBA可以将一个表通过年份划分成三个分区,80年代的数据,90年代的数据以及任何在2000年之后的数据。Hash(哈希)模式允许DBA通过对表的一个或多个列的Hash Key进行计算,最后通过这个Hash码不同数值对应的数据区域进行分区,比如DBA可以建立一个,对表的主键进行分区的表。List(预定义列表)模式:允许系统通过DBA定义列表的值所对应的行数据进行分割。例如:DBA建立了一个横跨三个分区的表,分别根据2004年,2005年,2006年值对应数据。Composite(复合模式),就是多模式的组合使用,在初始化已经进行了Range范围分区的表上,我们可以对其中一个分区再进行hash哈希分区。
第五步,就是冷热备份,对于一些无用的数据,这个时候根据实际的需求,对数据进行一个实时的备份,保证MySQL的数据保持在一个比较稳定的情况。
分库分表
对于分库分表,目前主流的是ShardingSphere,起源于当当网内部的应用框架。
shardingJDBC定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。它使⽤客户端直连数据库,以 jar 包形式提供服务,⽆需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
ShardingProxy定位为透明化的数据库代理端,提供封装了数据库⼆进制协议的服务端版本,⽤于完成对异构语⾔的⽀持。⽬前提供 MySQL 和 PostgreSQL 版本,它可以使⽤任何兼容 MySQL/PostgreSQL 协议的访问客⼾端。
ShardingJDBC只是客户端的一个工具包,可以理解为一个特殊的JDBC驱动包,所有分库分表逻辑均由业务方自己控制,所以他的功能相对灵活,支持的数据库也非常多,但是对业务侵入大,需要业务方自己定制所有的分库分表逻辑。而ShardingProxy是一个独立部署的服务,对业务方无侵入,业务方可以像用一个普通的MySQL服务一样进行数据交互,基本上感觉不到后端分库分表逻辑的存在,但是这也意味着功能会比较固定,能够支持的数据库也比较少。这两者各有优劣。
数据分片主要流程
sql解析整体结构
路由引擎

改写引擎

执行引擎
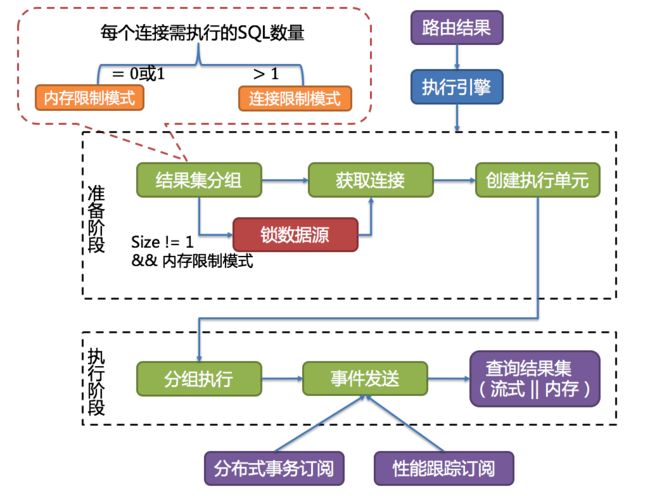
归并引擎
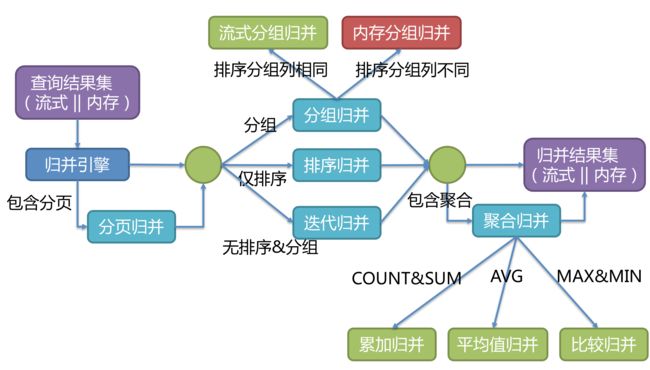
源码流程
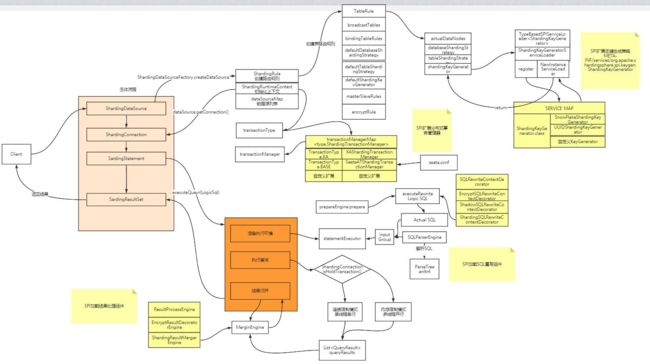
分库分表的的分片算法
提供一个分片键和一个分片表达式来制定分片算法
NoneShardingStrategy
- 不分片。这种严格来说不算是一种分片策略了。只是ShardingSphere也提供了这么一个配置。
InlineShardingStrategy
最常用的分片方式
- 配置参数: inline.shardingColumn 分片键;inline.algorithmExpression 分片表达式
- 实现方式: 按照分片表达式来进行分片。
StandardShardingStrategy
只支持单分片键的标准分片策略。
-
配置参数:standard.sharding-column 分片键;standard.precise-algorithm-class-name 精确分片算法类名;standard.range-algorithm-class-name 范围分片算法类名
-
实现方式:shardingColumn指定分片算法。preciseAlgorithmClassName 指向一个实现了io.shardingsphere.api.algorithm.sharding.standard.PreciseShardingAlgorithm接口的java类名,提供按照 = 或者 IN 逻辑的精确分片 示例:com.roy.shardingDemo.algorithm.MyPreciseShardingAlgorithm。rangeAlgorithmClassName 指向一个实现了 io.shardingsphere.api.algorithm.sharding.standard.RangeShardingAlgorithm接口的java类名,提供按照Between 条件进行的范围分片。示例:com.roy.shardingDemo.algorithm.MyRangeShardingAlgorithm
-
说明: 其中精确分片算法是必须提供的,而范围分片算法则是可选的。
ComplexShardingStrategy
支持多分片键的复杂分片策略。
-
配置参数:complex.sharding-columns 分片键(多个); complex.algorithm-class-name 分片算法实现类。
-
实现方式:shardingColumn指定多个分片列。algorithmClassName指向一个实现了org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingAlgorithm接口的java类名。提供按照多个分片列进行综合分片的算法。示例:com.roy.shardingDemo.algorithm.MyComplexKeysShardingAlgorithm
HintShardingStrategy
不需要分片键的强制分片策略。这个分片策略,简单来理解就是说,他的分片键不再跟SQL语句相关联,而是用程序另行指定。对于一些复杂的情况,例如select count(*) from (select userid from t_user where userid in (1,3,5,7,9)) 这样的SQL语句,就没法通过SQL语句来指定一个分片键。这个时候就可以通过程序,给他另行执行一个分片键,例如在按userid奇偶分片的策略下,可以指定1作为分片键,然后自行指定他的分片策略。
-
配置参数:hint.algorithm-class-name 分片算法实现类。
-
实现方式:algorithmClassName指向一个实现了org.apache.shardingsphere.api.sharding.hint.HintShardingAlgorithm接口的java类名。 示例:com.roy.shardingDemo.algorithm.MyHintShardingAlgorithm。在这个算法类中,同样是需要分片键的。而分片键的指定是通过HintManager.addDatabaseShardingValue方法(分库)和HintManager.addTableShardingValue(分表)来指定。使用时要注意,这个分片键是线程隔离的,只在当前线程有效,所以通常建议使用之后立即关闭,或者用try资源方式打开。
而Hint分片策略并没有完全按照SQL解析树来构建分片策略,是绕开了SQL解析的,所有对某些比较复杂的语句,Hint分片策略性能有可能会比较好(情况太多了,无法一一分析)。
但是要注意,Hint强制路由在使用时有非常多的限制:
– 不支持UNION SELECT * FROM t_order1 UNION SELECT * FROM t_order2 INSERT INTO tbl_name (col1, col2, …) SELECT col1, col2, … FROM tbl_name WHERE col3 = ?
– 不支持多层子查询 SELECT COUNT(*) FROM (SELECT * FROM t_order o WHERE o.id IN (SELECT id FROM t_order WHERE status = ?))
– 不支持函数计算。ShardingSphere只能通过SQL字面提取用于分片的值 SELECT * FROM t_order WHERE to_date(create_time, ‘yyyy-mm-dd’) = ‘2019-01-01’;
从这里也能看出,即便有了ShardingSphere框架,分库分表后对于SQL语句的支持依然是非常脆弱的。
分库分表带来的问题
1、分库分表,其实围绕的都是一个核心问题,就是单机数据库容量的问题。我们要了解,在面对这个问题时,解决方案是很多的,并不止分库分表这一种。但是ShardingSphere的这种分库分表,是希望在软件层面对硬件资源进行管理,从而便于对数据库的横向扩展,这无疑是成本很小的一种方式。
2、一般情况下,如果单机数据库容量撑不住了,应先从缓存技术着手降低对数据库的访问压力。如果缓存使用过后,数据库访问量还是非常大,可以考虑数据库读写分离策略。如果数据库压力依然非常大,且业务数据持续增长无法估量,最后才考虑分库分表,单表拆分数据应控制在1000万以内。
当然,随着互联网技术的不断发展,处理海量数据的选择也越来越多。在实际进行系统设计时,最好是用MySQL数据库只用来存储关系性较强的热点数据,而对海量数据采取另外的一些分布式存储产品。例如PostGreSQL、VoltDB甚至HBase、Hive、ES等这些大数据组件来存储。
3、从ShardingJDBC的分片算法中我们可以看到,由于SQL语句的功能实在太多太全面了,所以分库分表后,对SQL语句的支持,其实是步步为艰的,稍不小心,就会造成SQL语句不支持、业务数据混乱等很多很多问题。所以,实际使用时,我们会建议这个分库分表,能不用就尽量不要用。
如果要使用优先在OLTP场景下使用,优先解决大量数据下的查询速度问题。而在OLAP场景中,通常涉及到非常多复杂的SQL,分库分表的限制就会更加明显。当然,这也是ShardingSphere以后改进的一个方向。
4、如果确定要使用分库分表,就应该在系统设计之初开始对业务数据的耦合程度和使用情况进行考量,尽量控制业务SQL语句的使用范围,将数据库往简单的增删改查的数据存储层方向进行弱化。并首先详细规划垂直拆分的策略,使数据层架构清晰明了。而至于水平拆分,会给后期带来非常非常多的数据问题,所以应该谨慎、谨慎再谨慎。一般也就在日志表、操作记录表等很少的一些边缘场景才偶尔用用。
主从复制
主从复制(replication)的工作原理
1)主服务器(master)把数据更改记录到二进制日志(binlog)中。
2)从服务器(slave)把主服务器的二进制日志复制到自己的中继日志(relaylog)中。
3)从服务器重做中继日志中的日志,把更改数据到自己的数据库上,以达到数据的最终一致性。
复制的工作原理并不复杂,其实就是一个完全备份加上二进制日志备份的还原。不同的是这个二进制日志的还原操作基本上实时在进行中。这里特别需要注意的是,复制不是完全实时地进行同步,而是异步实时。这中间存在主从服务器之间的执行延时,如果主服务器的压力很大,则可能导致主从服务器延时较大。
主从复制bin log 日志有几种记录方式,说说各自的优缺点
Replication之所以能够工作,主要还是归结于binlog(binary log),所以在 Replication 模式下必须开启binlog功能。slave从masters 上增量获取 binlog 信息,并在本地应用日志中的变更操作,变更操作根据选择的格式类型写入binlog文件,目前支持三种格式:
statement-based Replication(SBR) :master将SQL statements语句写入binlog,slave 也将statements 复制到本地执行;简单而言,就是在 master 上执行的 SQL 变更语句,也同样在 slaves 上执行。SBR 模式是 MySQL 最早支持的类型,也是Replication默认类型。
row-based Replication(RBR): master将每行数据的变更信息写入binlog,每条 binlog 信息表示一行(row)数据的变更内容,对于 slaves 而言将会复制 binlog 信息,然后单条或者批量执行变更操作;
mix-format Replication:混合模式,在这种模式下,master将根据根据存储引擎、变更操作类型等,从SBR、RBR中来选择更合适的日志格式,默认为 SBR;具体选择那种格式,这取决于变更操作发生的存储引擎、statement 的类型以及特征,优先选择“数据一致性” 最好的方式(RBR),然后才兼顾性能,比如 statement 中含有 “不确定性” 方法或者批量变更,那么将选择RBR方式,其他的将选择 SBR 以减少binlog 的大小。我们建议使用mix方式。SBR 和 RBR 都有各自的优缺点,对于大部分用而言,mix 方式在兼顾数据完整性和性能方面是最佳的选择。
SBR的优点:
- 因为 binlog 中只写入了变更操作的statements,所以日志量将会很小;
- 当使用 SQL 语句批量更新、删除数据时,只需要在 binlog 中记录 statement 即可,可以大大减少log文件对磁盘的使用
- 当然这也意味着 slave 复制信息量也更少,以及通过binlog恢复数据更加快速;
SBR的缺点 :有些变更操作使用 SBR 方式会带来数据不一致的问题,一些结果具有不确定性的操作使用SBR将会引入数据不一致的问题。
- statement 中如果使用了 UDF(User Defination Fuction),UDF 的计算结果可能依赖于SQL 执行的时机和系统变量,这可能在 slave 上执行的结果与 master 不同,此外如果使用了trigger,也会带来同样的问题;
- statement 中如果使用了如下函数的(举例):UUID(),SYSDATE(),RAND() 等,不过NOW() 函数可以正确的被Replication(但在 UDF 或者触发器中则不行);这些函数的特点就是它们的值依赖于本地系统,RAND() 本身就是随机所以值是不确定的。如果 statement 中使用了上述函数,那么将会在日志中输出warning信息;
- 对于 “INSERT … SELECT” 语句,SBR 将比 RBR 需要更多的行锁。(主要是为了保障数据一致性,需要同时锁定受影响的所有的行,而RBR则不必要);
- 对于 InnoDB,使用 “AUTO_INCREMENT” 的 insert 语句,将会阻塞其他 “非冲突” 的INSERT。(因为AUTO_INCREMENT,为了避免并发导致的数据一致性问题,只能串行,但 RBR 则不需要);
- 对于复杂的SQL语句,在 slaves 上仍然需要评估(解析)然后才能执行,而对于RBR,SQL 语句只需要直接更新相应的行数据即可;在 slave 上评估、执行 SQL 时可能会发生错误,这种错误会随着时间的推移而不断累加,数据一致性的问题或许会不断增加。
RBR的优点:
- 所有的变更操作,都可以被正确的Replication,这事最安全的方式;
- 对于 “INSERT … SELECT”、包含 “AUTO_INCREMENT” 的 inserts、没有使用索引的UPDATE/DELETE,相对于SBR 将需要更少的行锁。(意味着并发能力更强);
RBR的缺点: - 最大的缺点:就是 RBR 需要更多的日志量。任何数据变更操作都将被写入log,受影响的每行都要写入日志,日志包含此行所有列的值(即使没有值变更的列);因此RBR 的日志条数和尺寸都将会远大于SBR,特别是在批量的 UPDATE/DELETE 时,可能会产生巨大的 log 量,反而对性能带来影响,尽管这确实保障了数据一致性,确导致Replication的效率较低;
主从复制有几种方式?
异步复制
MySQL主从集群默认采用的是一种异步复制的机制。Master处理事务过程中,将其写入Binlog就会通知Dumpthread线程处理,然后完成事务的提交,不会关心是否成功发送到任意一个slave中。主服务在执行用户提交的事务后,写入binlog日志,然后就给客户端返回一个成功的响应了。而binlog会由一个dump线程异步发送给Slave从服务,由于这个发送binlog的过程是异步的。主服务在向客户端反馈执行结果时,是不知道binlog是否同步成功了的。这时候如果主服务宕机了,而从服务还没有备份到新执行的binlog,那就有可能会丢数据。

半同步复制
半同步复制机制是一种介于异步复制和全同步复制之前的机制。主库在执行完客户端提交的事务后,并不是立即返回客户端响应,而是等待至少一个从库接收并写到relay log中,才会返回给客户端。MySQL在等待确认时,默认会等10秒,如果超过10秒没有收到ack,就会降级成为异步复制。

这种半同步复制相比异步复制,能够有效的提高数据的安全性。但是这种安全性也不是绝对的,他只保证事务提交后的binlog至少传输到了一个从库,并且并不保证从库应用这个事务的binlog是成功的。另一方面,半同步复制机制也会造成一定程度的延迟,这个延迟时间最少是一个TCP/IP请求往返的时间。整个服务的性能是会有所下降的。而当从服务出现问题时,主服务需要等待的时间就会更长,要等到从服务的服务恢复或者请求超时才能给用户响应。
Master 处理事务过程中,提交完事务后,必须等至少一个Slave 将收到的binlog写入relaylog返回ack 才能继续执行处理用户的事务。相关配置rpl_semi_sync_master_wait_point=AFTER_COMMIT【这里MySQL5.5并没有这个配置,MySQL5.7 为了解决半同步的问题而设置的】rpl_semi_sync_master_wait_for_slave_count=1 (最低必须收到多少个slave的ack)rpl_semi_sync_master_timeout=100(等待ack的超时时间)
半同步复制需要基于特定的扩展模块来实现。mysql从5.5版本开始,往上的版本都默认自带了这个模块。这个模块包含在mysql安装目录下的lib/plugin目录下的semisync_master.so和semisync_slave.so两个文件中。需要在主服务上安装semisync_master模块,在从服务上安装semisync_slave模块。
增强半同步复制
增强半同步和半同步不同是,等待ACK时间不同rpl_semi_sync_master_wait_point=AFTER_SYNC(唯一区别)半同步的问题是因为等待ACK的点是Commit 之后,此时Master已经完成数据变更,用户已经可以看到最新数据,当Binlog 还未同步到Slave时,发生主从切换,那么此时从库是没有这个最新数据的,用户又看到老数据。增强半同步将等待ACK的点放在提交Commit 之前,此时数据还未被提交,外界看不到数据变更,此时如果发送主从切换,新库依然还是老数据,不存在数据不一致的问题。
读写分离
为了保证数据一致,通常会需要保证数据只在主服务上写,而从服务只进行数据读取。这个功能就是读写分离。mysql主从本身是无法提供读写分离的服务的,需要由业务自己来实现,这也是ShardingSphere的一个重要功能。
在MySQL主从架构中,是需要严格限制从服务的数据写入的,一旦从服务有数据写入,就会造成数据不一致。并且从服务在执行事务期间还很容易造成数据同步失败。如果需要限制用户写数据,我们可以在从服务中将read_only参数的值设为1( set global read_only=1; )。这样就可以限制用户写入数据。
read_only=1设置的只读模式,不会影响slave同步复制的功能。限定的是普通用户进行数据修改的操作,但不会限定具有super权限的用户的数据修改操作。
如果需要限定super权限的用户写数据,可以设置super_read_only=0。另外如果要想连super权限用户的写操作也禁止,就使用"flush tables with read lock;",这样设置也会阻止主从同步复制!
读写分离延时导致的数据不一致解决方案
数据同步
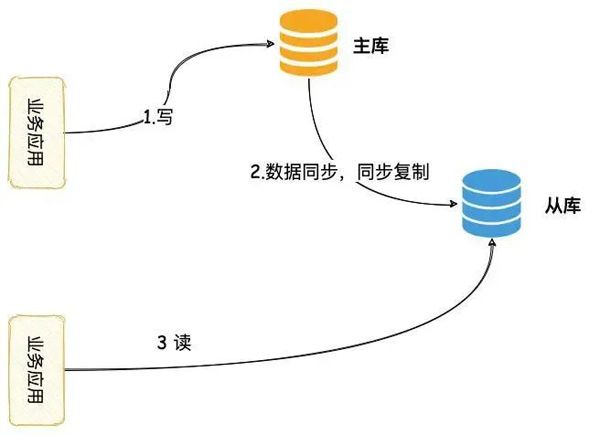
主从数据同步方案,一般都是采用的异步方式同步给备库。
我们可以将其修改为同步方案,主从同步完成,主库上的写才能返回。
- 业务系统发起写操作,数据写主库;
- 写请求需要等待主从同步完成才能返回;
- 数据读从库,主从同步完成就能读到最新数据。
缺点:主库写需要等待主从完成,写请求的时延将会增加,吞吐量将会降低
中间件路由
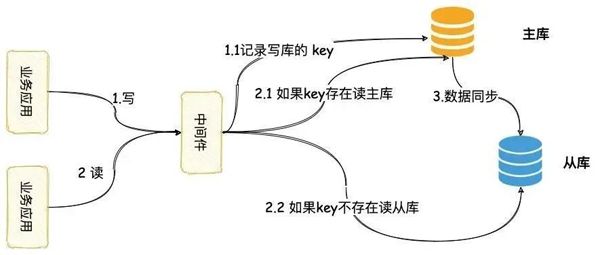
写请求,中间件将会发到主库,同时记录一下此时写请求的 key(操作表加主键等);
读请求,如果此时 key 存在,将会路由到主库;
一定时间后(经验值),中间件认为主从同步完成,删除这个 key,后续读将会读从库。
缺点:系统架构增加了一个中间件,整体复杂度变高,业务开发也变得复杂,学习成本也比较高
缓存路由
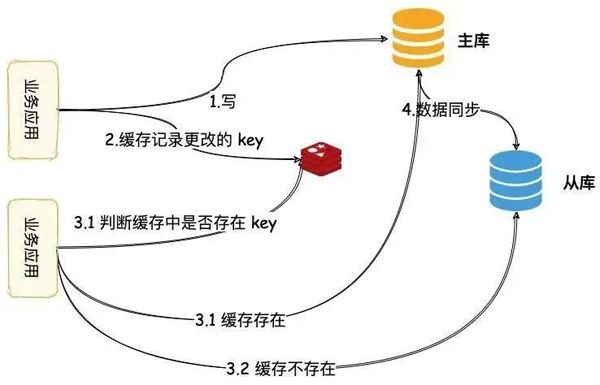
写请求发往主库,同时缓存记录操作的 key,缓存的失效时间设置为主从的延时;
读请求首先判断缓存是否存在:
-
若存在,代表刚发生过写操作,读请求操作主库;
-
若不存在,代表近期没发生写操作,读请求操作从库。
优缺点:成本较低,但是呢我们此时又引入一个缓存组件,所有读写之间就又多了一步缓存操作
mysql数据库集群高可用
使用MySQL自身的功能来搭建的集群,这样的集群,不具备高可用的功能。即如果是MySQL主服务挂了,从服务是没办法自动切换成主服务的。常见的MySQL集群方案有三种: MMM、MHA、MGR。
对主从复制集群中的Master节点进行监控。
自动的对Master进行迁移,通过VIP。
重新配置集群中的其它slave对新的Master进行同步。
MMM
MMM是一套由Perl语言实现的脚本程序,可以对mysql集群进行监控和故障迁移。他需要两个Master,同一时间只有一个Master对外提供服务,可以说是主备模式。他是通过一个VIP(虚拟IP)的机制来保证集群的高可用。整个集群中,在主节点上会通过一个VIP地址来提供数据读写服务,而当出现故障时,VIP就会从原来的主节点漂移到其他节点,由其他节点提供服务。
优点:
提供了读写VIP的配置,使读写请求都可以达到高可用
工具包相对比较完善,不需要额外的开发脚本
完成故障转移之后可以对MySQL集群进行高可用监控
缺点:
故障简单粗暴,容易丢失事务,建议采用半同步复制方式,减少失败的概率
目前MMM社区已经缺少维护,不支持基于GTID的复制
适用场景:
读写都需要高可用的
基于日志点的复制方式
MHA
由日本人开发的一个基于Perl脚本写的工具。这个工具专门用于监控主库的状态,当发现master节点故障时,会提升其中拥有新数据的slave节点成为新的master节点,在此期间,MHA会通过其他从节点获取额外的信息来避免数据一致性方面的问题。MHA还提供了mater节点的在线切换功能,即按需切换master-slave节点。MHA能够在30秒内实现故障切换,并能在故障切换过程中,最大程度的保证数据一致性。在淘宝内部,也有一个相似的TMHA产品。
MHA是需要单独部署的,分为Manager节点和Node节点,两种节点。其中Manager节点一般是单独部署的一台机器。而Node节点一般是部署在每台MySQL机器上的。 Node节点得通过解析各个MySQL的日志来进行一些操作。
Manager节点会通过探测集群里的Node节点去判断各个Node所在机器上的MySQL运行是否正常,如果发现某个Master故障了,就直接把他的一个Slave提升为Master,然后让其他Slave都挂到新的Master上去,完全透明。
优点:
MHA除了支持日志点的复制还支持GTID的方式
同MMM相比,MHA会尝试从旧的Master中恢复旧的二进制日志,只是未必每次都能成功。如果希望更少的数据丢失场景,建议使用MHA架构。
缺点:
MHA需要自行开发VIP转移脚本。
MHA只监控Master的状态,未监控Slave的状态
MGR
MGR:MySQL Group Replication。 是MySQL官方在5.7.17版本正式推出的一种组复制机制。主要是解决传统异步复制和半同步复制的数据一致性问题。
由若干个节点共同组成一个复制组,一个事务提交后,必须经过超过半数节点的决议并通过后,才可以提交。引入组复制,主要是为了解决传统异步复制和半同步复制可能产生数据不一致的问题。MGR依靠分布式一致性协议(Paxos协议的一个变体),实现了分布式下数据的最终一致性,提供了真正的数据高可用方案(方案落地后是否可靠还有待商榷)。
支持多主模式,但官方推荐单主模式:
多主模式下,客户端可以随机向MySQL节点写入数据
单主模式下,MGR集群会选出primary节点负责写请求,primary节点与其它节点都可以进行读请求处理.
优点:
基本无延迟,延迟比异步的小很多
支持多写模式,但是目前还不是很成熟
数据的强一致性,可以保证数据事务不丢失
缺点:
仅支持innodb,且每个表必须提供主键。
只能用在GTID模式下,且日志格式为row格式。
Redis知识点
多路复用
redis的多路复用模式
redis使用模型有:select、poll、epoll。这里简单讲二种。
应用对外提供服务的过程
一个应用程序, 想对外提供服务, 一般都是通过建立套接字监听端口来实现, 也就是socket。
应用对外提供服务的过程:
- 创建套接字
- 绑定端口号
- 开始监听
- 当监听到连接时, 调用系统read去读取内容,但是读取操作是阻塞的。
select
问题:如果主线程处理read,就不能接收其他连接了, 所以只能开新的线程去处理这个事情。而且read操作是调用系统函数, 需要进行进程的切换, 从用户进程切换到系统进程,连接少还好,连接多的话,无疑降低了性能。
解决方案:用户线程批量将要查询的连接发给操作系统,这个过程只发生一次进程的切换,用户线程告诉操作系统,需要哪些数据, 它遍历查找,然后将结果返回给用户线程,这就是select。
操作系统接收到一组文件描述符,然后批量处理这些文件描述符,有顺序的循环检查有没有数据,然后返回结果。无论是监听端口还是建立了连接,程序拿到的都是一个文件描述符,将这些文件描述符批量查询就是了。

epoll
问题:有10万个连接,其中有数据的只有一个,那就回有9999次无效的操作,每次查询都要把所有的都传过去, 10万个就要传10万。
解决方案:直接知道哪些连接是有数据的,然后操作系统通知用户线程,那个连接是可以直接拿到数据的,用户线程就直接通过这个连接去读数据就好了,不需要遍历,这就是epoll。
建立一个需要回调的连接, 将需要监听的文件描述符都扔给操作系统,当有新数据到达时,会直接返回给用户线程。用户线程将监听的列表交给操作系统维护,这样当有新数据来的时候,操作系统知道这是你要的,等你下次来拿的时候,直接给你了,少去了上面的遍历。
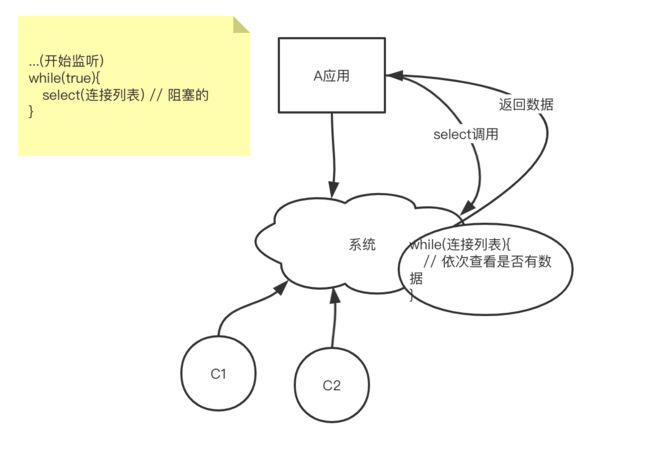
多路复用的定义
“多路”指的是多个网络连接,“复用”指的是复用同一个线程。
采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗)。
多路复用的举例
redis 需要处理 3 个 IO 请求,同时把 3 个请求的结果返回给客户端,所以总共需要处理 6 个 IO 事件, 由于 Redis服务端对于命令的处理是单线程的,同一时间只能处理一个 IO 事件。于是 redis 需要在合适的时间暂停对某个 IO 事件的处理,转而去处理另一个 IO 事件, 这样 redis 就好比一个开关,当开关拨到哪个 IO 事件这个电路上,就处理哪个 IO 事件,其他 IO 事件就暂停处理了。这就是IO多路复用技术。用一句话总结就是,一个客户端建立好连接后,就可以立刻等待新的客户端连接,而不用阻塞在原客户端的 read 请求上。
多路复用的实现
select, poll, epoll 都是I/O多路复用的具体的实现。epoll性能比其他几者要好。redis中的I/O多路复用的所有功能通过包装常见的select、epoll、evport和kqueue这些I/O多路复用函数库来实现的。 redis的io模型主要是基于epoll实现的,不过它也提供了 select和poll的实现,默认采用epoll。
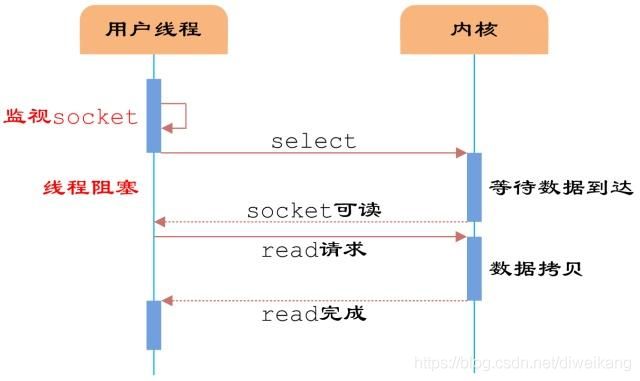
过程一:数据未就绪
多个客户端并发请求时,用户线程发起请求的时候,首先会将socket监听列表添加到select中,让select调用操作系统的API,这个过程就是从用户态到内核态,由于当前请求是交给了操作系统去处理,现在的用户线程这时候就空闲了,可以重新接收新的客户端请求。
操作系统等待select调用,当数据到达时,select函数被激活,操作系统将select函数的结果socket监听结果为可读,返回给用户线程,告诉用户线程这个连接可以读取数据了,这个时候用户线程才正式发起read请求,读取数据,这个读取数据的过程也是非阻塞的。
过程二:数据就绪
read 函数的效果是,如果没有数据到达时(到达网卡并拷贝到了内核缓冲区),立刻返回一个错误值(-1),而不是阻塞地等待。只有当操作系统告诉用户线程数据已经准备就绪的时候,数据从内核缓冲区拷贝到用户缓冲区才通知用户进程调用完成,返回结果,这个过程是阻塞的。

对于用户线程来说,它可以注册多个socket监听,然后不断地调用select读取,操作系统找到用户线程需要的连接,这个连接里面监听到有用户线程所需要的数据,就会激活socket把结果返回给用户线程。
单线程模型
为什么redis使用单线程模型还能保证高性能?
第一个是因为redis 是纯内存操作,内存的响应时长是 100 纳秒左右,这是 redis 的 QPS 过万的重要基础。
第二个是因为redis 的核心是基于非阻塞的IO多路复用机制,单线程模型避免了线程切换和竞态产生的消耗,解决了多线程的切换性能损耗问题。
第三个是因为redis底层使用C语言实现,一般来说,C 语言实现的程序"距离"操作系统更近,执行速度相对会更快。
你是如何理解redis单线程模型的?
Redis 里面的单线程主要是 Redis 的网络 IO 和键值对读写,它是由一个线程来完成的,但是 Redis 的其他功能, 比如说持久化、异步删除、集群数据同步等等,这些其实是由额外的线程执行的,这里的单线程主要是Redis 对外提供键值存储服务来说的。
主要流程是这样的:redis 会将每个客户端都关联一个指令队列,客户端的指令通过队列来按顺序处理,先到先处理,一个客户端指令队列中的指令是按顺序执行的。 redis 的每个客户端都关联一个响应队列,通过响应队列有顺序地将指令的返回结果返回给客户端,并且redis 同一时间每次都只能处理一个客户端队列中的指令或者响应。
Redis底层数据结构
简单字符串
先简单了解一下C语言是怎么处理字符串的:
在C语言中,字符串结束的标识是空字符,也就是’’,这会有一个问题,就是字符串的内容可能包括空字符串,这个时候是不是就没办法正确存取字符串的内容了,它有可能中途读取一半就完了。
除此之外,它还不记录字符串的长度,这也会有一系列问题,
如果需要获取字符串的长度通过遍历计数来获取的,这会导致它的时间复杂度会比较高。
如果需要修改字符串,就要重新分配内存,不重新分配的话,字符串长度增大,超出给定的长度,这个时候会造成内存缓冲区溢出,字符串长度减小还会造成内存泄露。
如果需要对两个字符串进行拼接,是通过调用strcat函数来实现的,如果没有给它分配足够长度的内存空间,就会直接导致缓冲区溢出。
既然C语言处理字符串有这么多的弊端,那么Redis它是怎么处理字符串的呢?
Redis专门创建了一种数据结构SDS,什么意思呢?simple dynamic string,简单字符串。
官方代码:
struct sdshdr{
int len;
int free;
char buf[];
}
这个对象有三个属性:
- len表示字符串的长度
- free表示还有多少长度剩余,就是下面buf数组中还有多少字符串未使用的字节数量
- buf[]表示存储的字符串
问题一:这种数据结构有什么优势呢?跟C语言相比,改进了哪些问题?
长度和内存重新分配问题,C语言是不记录长度,而SDS它有len属性和free属性。
len记录了字符串的长度,直接取值就可以了,不像C语言需要遍历。 如果需要对字符串进行修改的话,也不需要像C语言一样,直接重新分配内存,
它可以通过len 属性检查内存空间是不是需要进行扩展内存,如果字符串长度增加,长度超过了len,就会增加相应的内存,接着修改。
如果字符串长度缩短了,它也不会立马就重新分配内存,而是有一个free属性记录下来,等你后面什么时候用了,重新计算或者分配内存。
结尾标识问题,C语言是以空字符串结尾标识的,而SDS是以len长度作为结尾标识的,避免了C语言无法正确读取字符串的问题。
链表
Redis的list类型的键值对底层数据结构是由链表构成的,那么链表是什么呢?
它是由一连串节点组成,没有顺序,不是连续的,每个节点由数据和一或两个用来指向上一个或下一个节点位置的链接组成,在每一个节点里存到下一个节点的指针,通过链表中的指针链接次序可以实现逻辑顺序。
链表也分好几种:单向链表、双端链表、双向链表、有序链表以及有迭代器的链表
单向链表:用户的操作(添加、删除、遍历)只能从链表头开始。向一个方向遍历,查找一个节点的时候从第一个节点开始访问下一个节点,一直访问到需要的位置,最后一个节点存储地址的部分指向空值。
双端链表:双端链表相对于单端链表多了一个特性:对最后一个链接点的引用
双向链表:单端链表只能从链表头开始正向遍历,双向链表可以逆向遍历,每个节点需要保存前一个节点和后一个节点的引用
有序链表:插入元素时,将插入的元素与头结点及其后面的结点比较,找到合适的位置插入。
有迭代器的链表:单链表的基本操作中,大部分要用到依次遍历单链表中的每一个元素。当你新增一个对单链表的操作并需要使用遍历时,你就得重新写一个for循环而实现遍历。所以将迭代(遍历)作为一种基本的ADT(抽象数据类型)操作。链表中用于处理遍历、访问和更新的方法封装到一个新的迭代器类中。
跳跃表
跳跃表:跳跃表基于有序链表的扩展,在链表上建索引,每两个结点提取一个结点到上一级,我们把抽出来的那一级叫作索引,每个跳跃表节点的层高都是1至32之间的随机数。
举例说明:
比如给一个长度为7的有序链表,节点值依次是1->3->4->5。取出所有值为奇数的节点作为关键节点(索引),这个时候要插入一个值是2的新节点,就不需要将节点一个个比较,只要比较1,3,5,确定了值在1和3之间,就可以快速插入。
加一层索引之后,查找一个结点需要遍历的结点个数减少了,虽然增加了50%的额外空间,但是查找效率提高了,同理再加一级索引,这种链表加多级索引的结构,就是跳跃表。
索引是占内存的,原始链表中存储的可能是大的对象,索引结点只要存储关键值和几个指针,并不需要存储对象,当节点本身比较大或者元素数量比较多的时候,优势必然会被放大,而缺点则可以忽略。
问题:当大量的新节点通过逐层比较,最终插入到原链表之后,上层的索引节点会慢慢的不够用,那么这个时候要怎么选取一部分节点提到上一层呢?
抛硬币法:随机决定新节点是否选拔,每向上提拔一层的几率是50%。
原因:跳跃表的删除和添加节点是无法预测的,不能保证索引绝对分步均匀,不过可以让大体趋于均匀。
插入节点的工作流程:跳跃表插入操作的时间复杂度是O(logN),空间复杂度是 O(N)。
- 第一步:新节点和上层索引节点逐个比较,找到原链表的插入位置,时间复杂度为O(logN)
- 第二步:把索引插入到原链表,时间复杂度为O(1)
- 第三步:随机决定新节点是否提升为上一级索引,结果为"正面"则提升,继续抛硬币,结果为"反面"则停止,时间复杂度为O(logN)
删除节点的工作流程:跳跃表删除操作的时间复杂度是O(logN)
- 第一步:自上而下,查找第一次出现节点的索引,并逐层找到每一层对应的节点。时间复杂度为O(logN)
- 第二步:删除每一层查找到的节点,如果该层只剩下1个节点,删除整个一层(原链表除外)。时间复杂度为O(logN)
跳跃表由zskiplistNode和skiplist两个结构组成,zskiplistNode用于表示跳跃表节点,zskiplist用于保存跳跃表节点的相关信息,比如节点的数量,以及指向表头节点和表尾节点的指针等等。
字典
字典,顾名思义,通过字典(牛津字典等)前面的目录快速定位到所要查找的单词。
在C 语言中没有这种数据结构,所以这种数据结构是Redis自己创造的,字典中的键都是唯一的,通过键可以对值来进行查询或更改。
底层是通过哈希表实现的,而哈希表又基于数组,类似于key-value的结构形式进行存储的,它的值通过哈希函数映射为数组的下标。
那什么是哈希函数呢?不急,我们慢慢道来。
前面我们讲了通过数组的方式存储值,那么数组的值和数组的下标怎么建立关联关系呢?或者说,我们怎么通过数组的下标找到数组的值呢?
在学习 ASCII 编码的时候,我们知道,a可以用97这个数值表示,b可以用98这个数值表示,以此类推,我们就可以通过单个字母用数字表达。
有了字母,那么一个单词由多个字母组成,它又该如何表达呢?
假设我有一本字典,它有10000个单词,我其中一个单词就是ab,使用ASCII编码进行表达。
ab = 97 + 98 = 195
那么存储在数组中的下标为195,这就是字母表达的基本原理,但是如果只是这样还是远远不够的,因为会出现一个数组存储多个单词的情况。
举例说明:假设有个单词有 10 个字母,那么字典的某个单词为 zzzzzzzzzz ,转换为数字:zzzzzzzzzz = 26*10 = 260。
补充说明:这个时候会发现我一本字典里10000个单词,在260这个范围内肯定是不够存储10000个单词的,10000/260=39(38.4补一位),一个数组项它要存储39个单词。
解决方案:为了保证数值的唯一,让每个数组都能够只存储一个单词,进行升级, 将单词表示的数拆开,27 的幂乘以这些位数,有26个可能的字符,以及空格,一共27个。
ab = 97乘以27的一次幂加上98乘以27的零次幂 = 27*97 + 98 = 2717。解决了数组存储多个单词的问题,又引出新的问题数组分配大空间太多了。
举例说明:假设有个单词有 10 个字母,那么字典的某个单词为 zzzzzzzzzz ,转换为数字:zzzzzzzzzz = 26的9次幂 = 7000000000000
补充说明:数组中只有小部分存放了单词,其他空间都是空着的
解决方案:将巨大的整数范围压缩到可接受的数组范围内,可以通过取余解决,一个整数被另一个整数除后的余数。
举例说明:假设要把从0-99的数字(用large表示),压缩为从0-9的数字(用number表示),后者有10个数,所以变量range 的值为10,这个转换的表达式为:
补充说明:number = large % range。当一个整数被 10 整除时,余数是在0-9之间,把从0-99的数压缩为从0-9的数,压缩率为 10 :1。
使用哈希函数向数组插入数据后,这个数组就是哈希表,它的值就是通过上面这种方式映射到数组的下标上的。
这也就是哈希函数的工作模式,它把一个大范围的数字哈希转化成一个小范围的数字,这个小范围的数对应着数组的下标。
但是这种工作模式会有一点问题:把大的数字范围压缩到小的数字范围,会有几个不同的单词哈希化到同一个数组下标,这就是所谓的哈希冲突。
问题:那么如何解决哈希冲突呢?
开放地址法:指定的数组范围大小是存储数据的两倍,有一半的空间是空的。
当冲突产生时,通过(线性探测、二次探测以及再哈希法)方法找到数组的一个空位,把单词填入,不用哈希函数得到数组的下标。
线性探测中,如果哈希函数计算的原始下标是x, 线性探测就是x+1, x+2, x+3, 以此类推,而在二次探测中,探测的过程是x+1,
x+4, x+9, x+16。这二种方式都会有聚集情况。
什么是聚集呢?当哈希表快要满的时候,每插入新的数据,都要频繁的探测插入位置,很多位置都被前面插入的数据所占用了,这称为聚集。
再哈希法:依赖关键字的探测序列,把关键字用不同的哈希函数再做一遍哈希化,用这个结果作为步长,步长在整个探测中是不变的,不过不同的关键字使用不同的步长。
链地址法:数组的每个数据项都创建一个子链表或子数组,那么数组内不直接存放单词,当产生冲突时,新的数据项直接存放到这个数组下标表示的链表中。
整数集合:顾名思义,用来保存整数值类型的集合,保证元素不会重复。
定义:
typedef struct intset{
//编码方式
uint32_t encoding;
//集合包含的元素数量
uint32_t length;
//保存元素的数组
int8_t contents[];
}intset;
contents数组声明为int8_t类型,但是contents数组并不保存任何int8_t类型的值,真正类型由encoding决定。比如:
- encoding属性的值为INTSET_ENC_INT16,contents是int16_6类型的数组,数组里的每个项是int16_t类型的是整数值。
- encoding属性的值为INTSET_ENC_INT32,contents是int32_t类型的数组,数组里的每个项是int32_t类型的整数值。
- encoding属性的值为INTSET_ENC_INT64,contents是int64_t类型的数组,数组里的每个项是int64_t的整数值。
新增的元素类型比原集合元素类型的长度大的时候,根据新元素类型增加整数集合底层数组的容量,给新元素分配空间,
将底层数组现有的所有元素都转成与新元素相同类型的元素,把转换后的元素放到正确的位置,整个元素顺序是有序的,能极大地节省内存。
压缩列表
压缩列表,它是特殊编码的连续内存块组成的顺序型数据结构,压缩列表有任意多个节点(entry),每个节点有一个字节数组或者一个整数值。
压缩列表不是用某种算法对数据进行压缩,它将数据按照一定规则编码,放在一块连续的内存区域,目的是节省内存。
压缩列表包含以下:
zlbytes:记录整个压缩列表占用的内存字节数。
zltail:记录压缩列表表尾节点距离压缩列表的初始地址有多少字节。
zllen:记录压缩列表包含的节点数量。
zlend:用来标记压缩列表的末端。
entryX:列表的节点,包含
- previous_entry_ength:记录压缩列表前一个字节的长度。
- encoding:节点的encoding保存的是节点的content的内容类型以及长度。
- content:content区域用于保存节点的内容,节点内容类型和长度由encoding决定。
总结:
简单字符串:SDS作为redis专门为字符串存取开发的数据结构,有获取字符串长度快,杜绝了缓存区的溢出,减少了修改字符串长度时所需的内存重分配次数,二进制安全,兼容部分C函数
链表:用作列表键、发布与订阅、慢查询、监视器等功能实现。
字典:用哈希表实现,字典有两个哈希表,一个正常使用,另一个用于rehash时使用,链地址法解决哈希冲突。
跳跃表:表中的节点按照分值大小进行排序。
整数集合:底层由数组构成,升级特性能尽可能的节省内存。
压缩列表:顺序型数据结构。
Redis五大数据类型的应用场景
各数据类型应用场景
-
工作中有很多场景经常用到redis, 比如在使用String类型的时候,字符串的长度不能超过512M,可以set存储单个值,也可以把对象转成json字符串存储;还有我们经常说到的分布式锁,就是通过setnx实现的,返回结果是1就说明获取锁成功,返回0就是获取锁失败,这个值已经被设置过。又或者是网站访问次数,需要有一个计数器统计访问次数,就可以通过incr实现。
-
除了字符串类型,还有hash类型,它比string类型操作消耗内存和cpu更小,更节约空间。像我之前做过的电商项目里面,购物车实现场景可以通过hset添加商品,hlen获取商品总数,hdel删除商品,hgetall获取购物车所有商品。另外如果缓存对象的话,修改多个字段就不需要像String类型那样,取出值进行类型转换,然后设值进行类型转换,把它转成字符串缓存进行了。
-
还有列表list这种类型,是简单的字符串列表,按照插入顺序排序,可以添加一个元素到列表的头部或者尾部,它的底层实际上是个链表结构。这种类型更多的是用在文章发布上面,类似微博消息和微信公众号文章,在我之前的项目里面也有用到,比如说我关注了二个媒体,这二个媒体先后发了新闻,我就可以看到先发新闻那家媒体的文章,它可以通过lpush+rpop队列这种数据结构实现先进先出,当然也可以通过lpush+lpop实现栈这种数据结构来到达先进后出的功能。
-
然后就是集合set,底层是字典实现的,查找元素特别快,另外set 数据类型不允许重复,利用这两个特性我们可以进行全局去重,比如在用户注册模块,判断用户名是否注册。可以通过sadd、smembers等命令实现微信抽奖小程序,微信微博点赞,收藏,标签功能。还可以利用交集、并集、差集的特性实现微博微信的关注模型,交集和并集很好理解,差集可以解释一下,就是用第一个集合减去其他集合的并集,剩下的元素,就是差集。举个微博关注模型的例子,我关注了张三和李四,张三关注了李四和王五,李四关注了我和王五。
 我进入了张三的主页
我进入了张三的主页
查看共同关注的人(李四),取出我关注的人和张三关注的人,二个集合取交集得出结果是李四,就是通过SINTER交集实现的。
查看我可能认识的人(王五),取出我关注的人和张三关注的人,二个集合取并集得出结果是(张三,李四,王五),拿我关注的人(张三,李四)减去并集里的元素,剩下的王五就是我可能认识的人,可以通过并集和差集实现。
查看我关注的人也关注了他(王五),取出我关注的人他们关注的人,(李四,王五)(我,王五)的交集,就是王五。 -
最后就是有序集合zset,有序的集合,可以做范围查找,比如说排行榜,展示当日排行前十。
Redis五大数据类型实现原理
对于五大数据类型(String,list,Hash,Set,Zset)实现原理,Redis在底层用到了多种数据结构,通过数据结构来实现键值对,将数据结构创建了一个对象redisObject,根据对象的类型type,为对象设置多种不同的数据结构,对象可以执行特定的命令。
本章主要涉及到的知识点有:
- redisObject的属性
- 五大数据类型编码
注意:本章内容每一小节可单独学习,无论先后。
redisObject属性
学完本章中,读者需要回答:
1.Redis底层数据结构如何实现?
2.Redis是如何回收内存?
Redis的一个键值对,有两个对象,一个是键对象,一个是值对象,键总是一个字符串对象,而值可以是字符串、列表、集合等对象,Redis中的值对象都是由 redisObject 结构来表示:
typedef struct redisObject{
//表示类型:string,list,hash,set,zset
unsigned type:4;
//编码:比如字符串的编码有int编码,embstr编码,raw编码
unsigned encoding:4;
//指向底层数据结构的指针,prt是个指针变量,存放地址,指向数据存储的位置
void *ptr;
//引用计数,类似java里的引用计数
int refcount;
//记录最后一次被程序访问的时间
unsigned lru:22;
}robj
type属性
redisObject 对象的type属性记录了对象的类型(string,list,hash,set,zset),可以通过type key命令来判断对象类型,从而区分redis中key-value的类型
127.0.0.1:6379> set testString testValue
OK
127.0.0.1:6379> lpush testList testValue1 testValue2 testValue3
(integer) 3
127.0.0.1:6379> hmset testhash 1:testvalue 2:testvalue2
OK
127.0.0.1:6379> sadd testset testvalue
(integer) 1
127.0.0.1:6379> zadd testzset 1 testvalue
(integer) 1
127.0.0.1:6379> type testString
string
127.0.0.1:6379> type testList
list
127.0.0.1:6379> type testhash
hash
127.0.0.1:6379> type testset
set
127.0.0.1:6379> type testzset
zset
prt和encoding属性
redisObject 对象的 prt 指针,存放数据的地址,指向对象底层的数据结构,通过它可以找到数据的位置。
refcount 属性
由于C语言跟贴近操作系统,直接跟操作系统交互,命令执行响应比较快,所以Redis选择C语言进行编写可以提高性能,但是C 语言不具备自动回收内存功能,于是乎Redis自己构建了一个内存回收机制。
创建一个新对象,redisObject 对象中的refcount属性就会加1,对象被一个新程序使用,调用incrRefCount函数进行加 1,如果有对象不再被应用程序使用了,那么它就会调用decrRefCount函数进行减 1,当对象的引用计数值为 0 的时候,那么这个对象所占用的内存就会被释放。
从这里可以看出来,这其实就是Java虚拟机中引用计数的内存回收机制,在Java中这种回收机制不被使用,因为它不能解决循环引用的问题。
循环引用举例:A引用B,B引用C,C引用A。
Redis通过在配置文件中修改相关的配置,来达到解决循环引用的问题,在Redis的配置文件里,Windows的配置文件是redis.windows.conf,Linux系统的配置文件是redis.conf。
在配置文件中有一个配置:maxmemory-policy,当内存使用达到最大值时,redis使用的清楚策略,默认配置是noeviction
1)volatile-lru 删除已有的过期时间的key
2)allkeys-lru 删除所有的key
3)volatile-random 已有过期时间的key 随机删除
4)allkeys-random 随机删除key
5)volatile-ttl 删除即将过期的key
6)noeviction 不删除任何key,只是返回一个写错误,这个是默认选项 对于整数值的字符串对象(例如:1,2,3这种的)可实现内存共享。
问题:什么是内存共享?
定义:键不同,值相同。
举例:输入命令set key1 1024,键为 key1,值为1024的字符串对象,接着输入命令 set key2 1024 ,键为 key2,值为1024 的字符串对象。这个时候,有二个不同的键,一个相同的值。
实现原理:键的值,指针指向一个有值的对象,被共享的值对象引用refcount 加 1。
局限性:判断两个对象是否相等需要消耗运算的额外的时间。整数值,判断操作复杂度低;普通字符串,判断复杂度相比较而已是高的;哈希、列表、集合和有序集合,判断的复杂度更高,所以内存共享只适用于整数值的字符串。
lru 属性
Lru属性是redisObject 记录对象最后一次被命令程序访问的时间,用来辅助lru算法删除过期内存的。
在Redis 配置文件中有三个配置,最大内存配置 maxmemory,触发数据淘汰后的淘汰策略 maxmemory_policy,随机采样的精度maxmemory_samples。
当有条件符合配置文件中三个配置的时候,继续往Redis中加key时,会触发执行 lru 策略,进行内存清除。最近最少使用,lru算法根据数据的历史访问记录进行数据淘汰。
Lru策略的运行原理是数据插入到链表头部,当缓存数据被访问之后,数据会移到链表头,链表满的时候,链表尾部的数据会被丢弃。
redis配置中的淘汰策略(maxmemory_policy)对应的值:
- Noeviction:缓存里的数据超过maxmemory值,这个时候如果客户端正在执行命令,会让内存分配,给客户端返回错误响应
- allkeys-lru: 所有的key都用LRU进行淘汰。
- volatile-lru: LRU策略淘汰已经设置过过期时间的键。
- allkeys-random:随机淘汰使用的。
- key volatile-random:随机淘汰已设置过过期时间的key
- volatile-ttl:只回收设置了过期时间的key
从redis缓存中淘汰数据,我们的需求是淘汰一些不可能被使用的数据,保留有些以后可能会频繁访问的数据,频繁访问的数据,将来被访问的可能性大很多,所以redis它记录每个数据的最后一次访问时间(lru记录的时间),通过当前时间减去键值对象lru记录的时间,最后可以计算出最少空闲时间,最少空闲时间的数据是最有可能被访问到,这就是LRU淘汰策略的设计思想,是不是很棒。
举例说明:
A数据每10s访问一次,B数据每5s访问一次,C数据每50s访问一次,|代表计算空闲时间的截止点。

预测被访问的概率是B > A > C。
过期key的删除策略有两种:
惰性删除:每次获取键时,都检查键是否过期,过期的话,就删除该键;未过期,就返回该键。
定期删除:每隔一段时间,进行一次检查,删除里面的过期键。
encoding属性
数据结构由 encoding 属性,也就是编码,由它来决定,可以通过object encoding key命令查看一个值对象的编码。
127.0.0.1:6379> object encoding testString
"embstr"
127.0.0.1:6379> object encoding testList
"quicklist"
127.0.0.1:6379> object encoding testhash
"ziplist"
127.0.0.1:6379> object encoding testset
"hashtable"
127.0.0.1:6379> object encoding testzset
"ziplist"
String类型编码
我们最常使用的redis的一个数据类型就是String类型,实现单值缓存,分布式锁,计数器,分布式系统全局序列号等等功能。
它的底层编码分为三种,int,raw或者embstr。
int编码:存储整数值(例如:1,2,3),当 int 编码保存的值不再是整数值,又或者值的大小超过了long的范围,会自动转化成raw。例如:(1,2,3)->(a,b,c)
embstr编码:存储短字符串。
它只分配一次内存空间,redisObject和sds是连续的内存,查询效率会快很多,也正是因为redisObject和sds是连续在一起,伴随了一些缺点:当字符串增加的时候,它长度会增加,这个时候又需要重新分配内存,导致的结果就是整个redisObject和sds都需要重新分配空间,这样是会影响性能的,所以redis用embstr实现一次分配而后,只允许读,如果修改数据,那么它就会转成raw编码,不再用embstr编码了。
raw编码:用来存储长字符串。
它可以分配两次内存空间,一个是redisObject,一个是sds,二个内存空间不是连续的内存空间。和embstr编码相比,它创建的时候会多分配一次空间,删除时多释放一次空间。
版本区别:
embstr编码版本之间的区别:在redis3.2版本之前,用来存储39字节以内的数据,在这之后用来存储44字节以内的数据。
raw编码版本之间的区别:和embstr相反,redis3.2版本之前,可用来存储超过39字节的数据,3.2版本之后,它可以存储超过44字节的数据。
问题一:为什么是39字节?
从上面可以得知,embstr是一块连续的内存区域,由redisObject和sdshdr组成。
embstr最多占64字节场景:
redisObject占16个字节
struct RedisObject {
int4 type; // 4bits,不同的redis对象会有不同的数据类型(string、list、hash等),type记录类型,会用到4bits。
int4 encoding; // 4bits,存储编码形式,用4bits。
int24 lru; // 24bits,用24bits记录对象的LRU信息
int32 refcount; // 4bytes = 32bits,引用计数器,用到32bits
void *ptr; // 8bytes,64-bit system,指针指向对象的具体内容,需要64bits
}
计算: 4 + 4 + 24 + 32 + 64 = 128bits = 16bytes
sdshdr占48字节
struct sdshdr {
unsigned int len;//4个字节
unsigned int free;//4个字节
char buf[];//假设buf里面是39个字节
};
if (ptr) {
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\0';//一个字节
sdshdr的大小为8+39+1=48
那么一个embstr最多占64字节:16+48(4+4+1+39)=64
从2.4版本开始,redis用jemalloc内存分配器,比glibc的malloc要好一些,省内存,jemalloc会分配8,16,32,64等类型字节的内存。
embstr最小为33字节场景:
从上面我们可以得知redisObject占16个字节,现在buf中取8字节。
struct sdshdr {
unsigned int len;//4个字节
unsigned int free;//4个字节
char buf[];//假设buf里面是8个字节
};
if (ptr) {
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\0';//一个字节
sdshdr的大小为4+4+8+1=17
计算得出:16+17(4+4+1+8)=33
8,16,32都比33字节小,所以最小分配64字节。
通过对比:
16+17(4+4+1+8)=33
16+48(4+4+1+39)=64
当字符数大于8时,会分配64字节。当字符数小于39时,会分配64字节。这个默认39就是这样来的。
问题二:为什么分界值由39字节会变成44字节?
被暴打的回答是:REDIS_ENCODING_EMBSTR_SIZE_LIMIT值被换成了44了。
##define REDIS_ENCODING_EMBSTR_SIZE_LIMIT 39
##define REDIS_ENCODING_EMBSTR_SIZE_LIMIT 44
正经的回答是:
每个sds都有一个sdshdr,里面的len和free记录了这个sds的长度和空闲空间。
struct sdshdr {
unsigned int len;
unsigned int free;
用的unsigned int可以表示很大的范围,短的sds空间被浪费了(unsigned int len和unsigned int free 8个字节)
commit之后,unsigned int 变成了uint8_t,uint16_t,uint32_t
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
char flags; /* 2 lsb of type, and 6 msb of refcount */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
char flags; /* 2 lsb of type, and 6 msb of refcount */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
char flags; /* 2 lsb of type, and 6 msb of refcount */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
char flags; /* 2 lsb of type, and 6 msb of refcount */
除此之外还将原来的sdshdr改成了sdshdr16,sdshdr32,sdshdr64
sizes = sdscatprintf(sizes,"sdshdr:%d", (int)sizeof(struct sdshdr));
改成了
sizes = sdscatprintf(sizes,"sdshdr8:%d", (int)sizeof(struct sdshdr8));
sizes = sdscatprintf(sizes,"sdshdr16:%d", (int)sizeof(struct sdshdr16));
sizes = sdscatprintf(sizes,"sdshdr32:%d", (int)sizeof(struct sdshdr32));
sizes = sdscatprintf(sizes,"sdshdr64:%d", (int)sizeof(struct sdshdr64));
unsigned int占四个字节
uint8_t 占1个字节
Char 占一个字节
我们通过计算可以得出为什么优化之后会多出5个字节了,短字符串的embstr用最小的sdshdr8。
sdsdr8 = uint8_t _ 2 + char = 1_2+1 = 3
sdshdr = unsigned int _ 2 = 4 _ 2 = 8
这么一算是不是少了五个字节了,所以3.2版本更新之后,由于优化小sds的内存使用,使得原本39个字节可以多使用5个字节,这就变成了44字节了。
问题三:Redis字符串最大长度是多少?
512M,查看源码可知。
static int checkStringLength(redisClient *c, long long size) {
if (size > 512*1024*1024) {
addReplyError(c,"string exceeds maximum allowed size (512MB)");
return REDIS_ERR;
}
return REDIS_OK;
}
List集合对象编码
List类型可以实现栈,队列,阻塞队列等数据结构,底层是个链表结构,它的底层编码分二种:ziplist(压缩列表) 和 linkedlist(双端链表)。
超过配置的数量或者最大的元素超过临界值时,符合配置的值,触发机制会选择不同的编码。
列表保存元素个数小于512个,每个元素长度小于64字节的时候触发机制会使用ziplist(压缩列表)编码,否则使用linkedlist(双端链表)。
在redis.conf(linux系统)或者redis.windows.conf(windows系统)对应的配置:
list-max-ziplist-entries 512
list-max-ziplist-value 64
通过修改配置这二个配置,设置触发条件选择编码。比如我修改列表保存元素个数小于1024个并且每个元素长度小于128字节时使用ziplist(压缩列表)编码,否则使用linkedlist(双端链表)。修改配置如下:
list-max-ziplist-entries 1024
list-max-ziplist-value 128
list列表的编码,3.2之前最开始的时候是用ziplist压缩列表,当列表保存元素个数超过512个,每个元素长度超过64字节就会切换编码,改用linkedlist双端链表,ziplist会有级联更新的情况,时间复杂度高,除此之外链表需要维护额外的前后节点,占用内存,所以元素个数到达一定数量就不能再用ziplist了。
新版本的Redis对列表的数据结构进行了改造,使用quicklist代替了原有的数据几个,quicklist是ziplist和linkedlist的混合体,它让每段ziplist连接起来,对ziplist进行LZF算法压缩,默认每个ziplist长度8KB。
ziplist压缩列表是由一些连续的内存块组成的,有顺序的存储结构,是一种专门节约内存而开发的顺序型数据结构。在物理内存固定不变的情况下,随着内存慢慢增加会出现内存不够用的情况,这种情况可以通过调整配置文件中的二个参数,让list类型的对象尽可能的用压缩列表编码,从而达到节约内存的效果,但是也要均衡一下编码和解码对性能的影响,如果有一个几十万的列表长度进行列表压缩的话,在查询和插入的时候,进行编解码会对性能造成特别大的损耗。
如果有不可避免的长列表的存储的话,需要在代码层面配合降低redis存储的内存,在存储redis的key的时候,在保证唯一性和可读性的时候,尽量简化redis的key,可以比较直接的节约redis空间的一个作用,还有就是对长列表进行拆分,比如说有一万条数据,压缩列表的保存元素的个数配置的是2048,我们就可以将一万条数据拆分成五个列表进行缓存,将它的元素个数控制在压缩列表配置的2048以内,当然这么做需要对列表的key进行一定的控制,当要进行查询的时候,可以精准的查询到key存储的数据。
这是对元素个数的一个控制,元素的长度也类似,将每个大的元素,拆分成小的元素,保证不超过配置文件里面每个元素大小,符合压缩列表的条件就可以了,核心目标就是保证这二个参数在压缩列表以内,不让它转成双端列表,并且在编解码的过程中,性能也能得到均衡,达到节约内存的目的。
除了上面的优化可以进行内存优化以外,还可以看我们缓存的数据,是不是可以打包成二进制位和字节进行存储,比如用户的位置信息,以上海市黄浦区举例说明,可以把上海市,黄浦区弄到我们的数组或者list里面,然后只需要存储上海市的一个索引0和黄浦区的一个索引1,直接将01存储到redis里面即可,当我们从缓存拿出这个01信息去数组或者list里面取到真正的一个消息。
Hash对象编码
Hash类型比string类型消耗内存和cpu更小。Hash的编码有二种 ziplist编码 或者 hashtable。
超过指定的值,最大的元素超过临界值时,符合配置的值,触发机制选择不同的编码。列表保存元素个数小于512个,每个元素长度小于64字节的时候,使用ziplist(压缩列表)编码,否则使用hashtable 。
配置文件中可以通过修改set-max-intset-entries 1024达到改变列表保存元素个数小于1024个,原理类似。
hashtable 编码是字典作为底层实现,字典的键是字符串对象,值则全部设置为 null。在上面的字典也有详细介绍。
Set集合对象编码
Set类型可以实现抽奖小程序,点赞,收藏,加标签,关注模型等功能。Set的编码有二种intset 或者 hashtable。
超过指定的值,最大的元素超过临界值时,符合配置条件,触发机制选择不同的编码。集合对象中所有元素都是整数,对象元素数量不超过512时,使用intset编码,否则使用hashtable。原理大致和上面的类型相同。
列表保存元素个数的配置也是通过set-max-intset-entries进行修改的。
intset 编码用整数集合作为底层实现,hashtable编码可以类比HashMap的实现,HashTable类中存储的实际数据是Entry对象,数据结构与HashMap是相同的。
Zset有序集合对象编码
Zset适合做排序以及范围查询等功能,比如实现实现排行榜等。有序集合的编码有二种 ziplist 或者 skiplist。
保存的元素数量小于128,存储的所有元素长度小于64字节的时候,使用ziplist编码,否则用skiplist编码。修改配置如下:
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
ziplist 编码底层是用压缩列表实现的,集合元素是两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员,第二个节点保存元素的分值。 压缩列表的集合元素按照设置的分值从小到大的顺序进行排列,小的放置在靠近表头的位置,大的放置在靠近表尾的位置。
skiplist 编码的有序集合对象使用 zet 结构作为底层实现,一个 zset 结构同时包含一个字典和一个跳跃表。
当不满足这二个条件的时候,skiplist编码,skiplist编码的有序集合对象使用zet 结构作为底层实现,一个 zset 结构同时包含一个字典和一个跳跃表,字典的键保存元素的值,字典的值则保存元素的分值;跳跃表由zskiplistNode和skiplist两个结构,跳跃表skiplist中的object属性保存元素的成员,score 属性保存元素的分值。这两种数据结构会通过指针来共享相同元素的成员和分值,所以不会产生重复成员和分值,造成内存的浪费。
问题:为什么需要二种数据结构?
假如我们单独使用字典,虽然能直接通过字典的值查找成员的分值,但是因为字典是以无序的方式来保存集合元素,所以每次进行范围操作的时候都要进行排序;
假如我们单独使用跳跃表来实现,虽然能执行范围操作,但是查找操作就会变慢,所以Redis使用了两种数据结构来共同实现有序集合。
除了这二个属性之外,还有层属性,跳跃表基于有序链表的,在链表上建索引,每两个结点提取一个结点到上一级,我们把抽出来的那一级叫作索引,每个跳跃表节点的层高都是1至32之间的随机数。
比如有一个有序链表,节点值依次是1->3->4->5。取出所有值为奇数的节点作为索引,这个时候要插入一个值是2的新节点,就不需要将节点一个个比较,只要比较1,3,5,确定了值在1和3之间,就可以快速插入,加一层索引之后,查找一个结点需要遍历的结点个数减少了,虽然增加了50%的额外空间,但是查找效率提高了。
当大量的新节点通过逐层比较,最终插入到原链表之后,上层的索引节点会慢慢的不够用,由于跳跃表的删除和添加节点是无法预测的,不能保证索引绝对分步均匀,所以通过抛硬币法:随机决定新节点是否选拔,每向上提拔一层的几率是50%,让大体趋于均匀。
Redis持久化
面试题:Redis 的持久化有哪几种方式?不同的持久化机制都有什么优缺点?持久化机制具体底层是如何实现的?save与bgsave?
持久化主要是做灾难恢复、数据恢复,高可用。比如你 redis 整个挂了,然后 redis 就不可用了,我们要做的事情就是让 redis 变得可用,尽快变得可用。 重启 redis,尽快让它堆外提供服务,如果没做数据备份,这时候 redis 启动了,也不可用啊,数据都没了。把 redis 持久化做好, 那么即使 redis 故障了,也可以通过备份数据,快速恢复,一旦恢复立即对外提供服务。
redis持久化有三种方式:RDB,AOF,(RDB和AOF)混合持久化
默认情况下, Redis 将内存数据库快照保存在名字为 dump.rdb 的二进制文件中,也就是RDB快照。
RDB 持久化机制,是对 redis 中的数据执行周期性的持久化。
AOF 持久化机制,是对每条写入命令作为日志,重启的时候,可以通过回放日志中的写入指令来重新构建整个数据集。
不同的持久化机制都有什么优缺点?
RDB持久化
RDB会生成多个数据文件,每个数据文件都代表了某一个时刻中 redis 的数据。 redis 主进程只需要 fork一个子进程,让子进程执行磁盘 IO 操作来进行 RDB持久化,对外提供的读写服务,影响非常小。但是如果数据文件特别大,可能会导致对客户端提供的服务暂停数秒。 RDB 数据文件来重启和恢复 redis 进程更快 RDB会丢失某一时间段的数据,一般来说,RDB 数据快照文件,都是每隔 5分钟,或者更长时间生成一次,这个时候就得接受一旦 redis 进程宕机,那么会丢失最近 5 分钟的数据。
AOF持久化
AOF 可以更好的保护数据不丢失,一般 AOF 每隔 1 秒,通过一个后台线程执行一次fsync操作,最多丢失 1 秒钟的数据。 AOF日志文件以 append-only 模式写入,所以没有任何磁盘寻址的开销,写入性能很高,而且文件不容易破损。 AOF 日志文件即使过大的时候,可以进行后台重写操作,也不会影响客户端的读写。在重写的时候,会进行压缩,创建出一份最小恢复数据的日志出来。在创建新日志文件的时候,老的日志文件还是照常写入。新日志文件创建完成以后,再去读的时候,交换新老日志文件就可以了。某人不小心用 flushall 命令清空了所有数据,只要这个时候后台重写命令还没有发生,那么就可以立即拷贝 AOF 文件,将最后一 flushall 命令给删了,然后再将该 AOF 文件放回去,就可以通过恢复机制,自动恢复所有数据。 AOF 日志文件通常比 RDB数据快照文件更大。 支持的写 QPS 会比 RDB 支持的写 QPS 低,因为 AOF 一般会配置成每秒 fsync一次日志文件,当然,每秒一次 fsync,性能也还是很高的。
混合持久化
仅仅使用 RDB,会导致丢失很多数据 仅仅使用 AOF,速度慢,支持的QPS低,性能不高 开启开启两种持久化方式,用 AOF 来保证数据不丢失,作为数据恢复的第一选择; 在 AOF 文件都丢失或损坏不可用的时候,还可以使用 RDB 来进行快速的数据恢复。
持久化底层实现原理
持久化机制具体底层是如何实现的?
RDB持久化底层实现原理
RDB持久化可以通过配置与手动执行命令生成RDB文件。 可以对 Redis 进行设置, 让它在“ N 秒内数据集至少有 M个改动”这一条件被满足时, 自动保存一次数据集。比如说设置让 Redis 在满足“ 60 秒内有至少有 1000 个键被改动”,自动保存一次数据集。通过 save 60 1000 命令生成RDB快照,关闭RDB只需要将所有的save保存策略注释掉即可。手动执行命令生成RDB快照,进入redis客户端执行命令save或bgsave可以生成dump.rdb文件,每次命令执行都会将所有redis内存快照到一个新的rdb文件里,并覆盖原有rdb快照文件。
AOF持久化底层实现原理
AOF持久化可以通过配置与手动执行命令生成RDB文件。 通过配置# appendonly yes 开启AOF持久化, 每当 Redis 执行一个改变数据集的命令时, 这个命令就会被追加到 AOF 文件的末尾,当 Redis 重新启动时, 程序就可以通过重新执行 AOF 文件中的命令来达到重建数据集的目的,配置 Redis 多久才将数据 fsync 到磁盘一次,默认的措施为每秒 fsync 一次。AOF文件里可能有太多没用指令,所以AOF会定期根据内存的最新数据重新生成aof文件,可以通过配置文件达到64M才会自动重写,也可以配置aof文件自上一次重写后文件大小增长了100%则再次触发重写 手动执行命令bgrewriteaof重写AOF,AOF重写redis会fork出一个子进程去做(与bgsave命令类似),不会对redis正常命令处理有太多影响。
混合持久化底层实现原理
通过配置# aof-use-rdb-preamble yes 开启混合持久化,开启了混合持久化,AOF在重写时,不再是单纯将内存数据转换为RESP命令写入AOF文件,而是将重写这一刻之前的内存做RDB快照处理,并且将RDB快照内容和增量的AOF修改内存数据的命令存在一起,都写入新的AOF文件,新的文件一开始不叫appendonly.aof,等到重写完新的AOF文件才会进行改名,覆盖原有的AOF文件,完成新旧两个AOF文件的替换。于是在 Redis 重启的时候,可以先加载 RDB 的内容,然后再重放增量 AOF 日志就可以完全替代之前的 AOF 全量文件重放,因此重启效率大幅得到提升。
save与bgsave
bgsave 子进程是由主线程 fork 生成的,可以共享主线程的所有内存数据。bgsave 子进程运行后,开始读取主线程的内存数据,并把它们写入 RDB 文件。此时,如果主线程对这些数据也都是读操作,那么,主线程和 bgsave 子进程相互不影响。但是,如果主线程要修改一块数据,那么,这块数据就会被复制一份,生成该数据的副本。然后,bgsave 子进程会把这个副本数据写入 RDB 文件,而在这个过程中,主线程仍然可以直接修改原来的数据。 save 它是同步阻塞的,会阻塞客户端命令和redis其它命令,和bgsave相比不会消耗额外内存。
缓存雪崩
一个系统,高峰期请求为5000次/秒,4000次走了缓存,只有1000次落到了数据库上,数据库每秒1000的并发是一个正常的指标,完全可以正常工作,但如果缓存宕机了,或者缓存设置了相同的过期时间,导致缓存在同一时刻同时失效,每秒5000次的请求会全部落到数据库上,数据库立马就死掉了,因为数据库一秒最多抗2000个请求,如果DBA重启数据库,立马又会被新的请求打死了,这就是缓存雪崩。
解决方案:
事前:redis高可用,主从+哨兵,redis cluster,避免全盘崩溃 事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL被打死
事后:redis持久化RDB+AOF,快速恢复缓存数据 缓存的失效时间设置为随机值,避免同时失效
缓存穿透
客户端每秒发送5000个请求,其中4000个为黑客的恶意攻击,即在数据库中也查不到。举个例子,用户id为正数,黑客构造的用户id为负数,如果黑客每秒一直发送这4000个请求,缓存就不起作用,数据库也很快被打死。
解决方案:
对请求参数进行校验,不合理直接返回 查询不到的数据也放到缓存,value为空,如 set -999 “” 使用布隆过滤器,快速判断key是否在数据库中存在,不存在直接返回
缓存击穿
设置了过期时间的key,承载着高并发,是一种热点数据。从这个key过期到重新从MySQL加载数据放到缓存的一段时间,大量的请求有可能把数据库打死。缓存雪崩是指大量缓存失效,缓存击穿是指热点数据的缓存失效。
解决方案:
设置key永远不过期,或者快过期时,通过另一个异步线程重新设置key 当从缓存拿到的数据为null,重新从数据库加载数据的过程上分布式锁。
布隆过滤器
需求
①、原本有10亿个号码,现在又来了10万个号码,要快速准确判断这10万个号码是否在10亿个号码库中? 解决办法一:将10亿个号码存入数据库中,进行数据库查询,准确性有了,但是速度会比较慢。 解决办法二:将10亿号码放入内存中,比如Redis缓存中,这里我们算一下占用内存大小:10亿*8字节=8GB,通过内存查询,准确性和速度都有了,但是大约8gb的内存空间,挺浪费内存空间的。
②、接触过爬虫的,应该有这么一个需求,需要爬虫的网站千千万万,对于一个新的网站url,我们如何判断这个url我们是否已经爬过了? 解决办法还是上面的两种,很显然,都不太好。
③、同理还有垃圾邮箱的过滤 大数据量集合,如何准确快速的判断某个数据是否在大数据量集合中,并且不占用内存。
布隆过滤器定义
一种数据结构,是由一串很长的二进制向量组成,可以将其看成一个二进制数组。既然是二进制,那么里面存放的不是0,就是1,但是初始默认值都是0。将布隆过滤器看成一个容器,那么如何向布隆过滤器中添加一个数据呢?数组是从0开始计数的,当要向布隆过滤器中添加一个元素key时,我们通过多个hash函数,算出一个值,然后将这个值所在的方格置为1。
布隆过滤器判断数据是否存在?
将这个新的数据通过自定义的几个哈希函数,分别算出各个值,然后看其对应的地方是否都是1,如果存在一个不是1的情况,那么我们可以说,该新数据一定不存在于这个布隆过滤器中。多个不同的数据通过hash函数算出来的结果是会有重复的,所以会存在某个位置是别的数据通过hash函数置为的1。布隆过滤器可以判断某个数据一定不存在,但是无法判断一定存在。
布隆过滤器优缺点
优点:二进制组成的数组,占用内存极少,并且插入和查询速度都足够快。
缺点:随着数据的增加,误判率会增加,无法判断数据一定存在,无法删除数据。
布隆过滤器的实现
- guava 工具包提供了布隆过滤器的实现。
- Redis 实现布隆过滤器的底层就是通过 bitmap数据结构实现的,计算机以二进制位作为底层存储的基础单位,一个字节等于8位,可以通过修改二进制某个位置上的0或者1达到修改值的目的。比如:将big改为cig,"b"的二进制表示为0110 0010,我们将第7位(从0开始)设置为1,那0110 0011表示的就是字符“c”,所以最后的字符 “big”变成了“cig”。
Redis分布式寻址算法
在集群模式下,Redis 的 key 是如何寻址的?分布式寻址都有哪些算法?了解一致性 hash 算法吗?如何动态增加和删除一个节点?
hash 算法(大量缓存重建) 一致性 hash 算法(自动缓存迁移)+ 虚拟节点(自动负载均衡) Redis cluster 的 hash slot 算法
hash 算法
来了一个 key,首先计算 hash 值,然后对节点数取模,接着打在不同的 master 节点上。缺点也很明显:某一个 master 节点宕机,所有请求过来,都会基于最新的剩余 master 节点数去取模,尝试去库中取数据进行缓存。这会导致大部分的请求过来,全部无法拿到有效的缓存,导致大量的流量涌入数据库。
一致性 hash 算法
将整个 hash 值空间组织成一个虚拟的圆环,整个空间按顺时针方向组织,下一步将各个 master 节点(使用服务器的 ip 或主机名)进行 hash。来了一个 key,首先计算 hash 值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,遇到的第一个 master 节点就是 key 所在位置,这样就能确定每个节点在其哈希环上的位置。在一致性哈希算法中,如果一个节点挂了,受影响的数据仅仅是此节点到环空间前一个节点(沿着逆时针方向行走遇到的第一个节点)之间的数据,其它不受影响。增加一个节点也同理。 虚拟节点:一致性哈希算法在节点太少时,容易因为节点分布不均匀而造成缓存热点的问题。为了解决这种热点问题,一致性 hash 算法引入了虚拟节点机制,即对每一个节点计算多个 hash,每个计算结果位置都放置一个虚拟节点。这样就实现了数据的均匀分布,负载均衡。
hash slot 算法
Redis cluster 有固定的 16384 个 hash slot,slot是槽的概念(理解为数据管理和迁移的基本单位),所有的键根据哈希函数映射到 0~16383 整数槽内,每个节点负责维护一部分槽以及槽所映射的键值数据。 公式:slot = CRC16(key)& 16384。解释:对每个 key 计算 CRC16 值,然后对 16384 取模,可以获取 key 对应的 hash slot。hash slot可以像磁盘分区一样自由分配槽位,在配置文件里可以指定,也可以让redis自己选择分配,结果均匀,这种结构很容易添加或者删除节点。如果增加一个节点,就需要从节点已有的节点 获得部分槽分配到新的节点 上。如果想移除已有的一个节点,需要将节点中的槽移到其他节点上,然后将没有任何槽的节点从集群中移除就可以了。由于缓存的key hash结果是和slot绑定的,而不是和服务器节点绑定,所以节点的更替只需要迁移slot即可平滑过渡。从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态。
Redis过期策略
Redis采用的过期策略
惰性删除+定期删除
惰性删除流程
在进行get或setnx等操作时,先检查key是否过期,若过期,删除key,然后执行相应操作;若没过期,直接执行相应操作
定期删除流程
对指定个数个库的每一个库随机删除小于等于指定个数个过期key,遍历每个数据库(就是redis.conf中配置的"database"数量,默认为16),检查当前库中的指定个数个key(默认是每个库检查20个key,注意相当于该循环执行20次,循环体时下边的描述),如果当前库中没有一个key设置了过期时间,直接执行下一个库的遍历,随机获取一个设置了过期时间的key,检查该key是否过期,如果过期,删除key,判断定期删除操作是否已经达到指定时长,若已经达到,直接退出定期删除。
问题:定期删除漏掉了很多过期 key,然后你也没及时去查,也就没走惰性删除,此时会怎么样?如果大量过期 key 堆积在内存里,导致 Redis 内存块耗尽了,怎么解决呢?走内存淘汰机制。
内存淘汰机制
Redis 内存淘汰机制有以下几个:
noeviction: 当内存不足以容纳新写入数据时,新写入操作会报错,这个一般没人用吧,实在是太恶心了。
allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 key(这个是最常用的)。
allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个 key,这个一般没人用吧,为啥要随机,肯定是把最近最少使用的 key 给干掉啊。
volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的 key(这个一般不太合适)。
volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个 key。
volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的 key 优先移除。
默认就是如果满的话就拒绝抛异常,正常一般用LFU和LRU二种。LFU是基于梯形数组,每个数组上面就挂了一个Counter,Counter是用来统计它的服务次数的,通过访问次数来进行升级,LFU的LRU字段里面高16位存储一个分钟数级别的时间戳,低8位存储的是一个Counter访问计数。和LRU相比,LFU避免了LRU基于最近一段时间的访问没有访问数据,突然访问变成热点数据,导致内存淘汰,没有真正意义上达到冷数据的淘汰。
RDB对过期key的处理
过期key对RDB没有任何影响,从内存数据库持久化数据到RDB文件:持久化key之前,会检查是否过期,过期的key不进入RDB文件 从RDB文件恢复数据到内存数据库:数据载入数据库之前,会对key先进行过期检查,如果过期,不导入数据库(主库情况)
AOF对过期key的处理
过期key对AOF没有任何影响 从内存数据库持久化数据到AOF文件:当key过期后,还没有被删除,此时进行执行持久化操作(该key是不会进入aof文件的,因为没有发生修改命令)当key过期后,在发生删除操作时,程序会向aof文件追加一条del命令(在将来的以aof文件恢复数据的时候该过期的键就会被删掉) AOF重写:重写时,会先判断key是否过期,已过期的key不会重写到aof文件。
Redis与数据库的数据一致性
关于redis与数据库的数据一致性,业界使用最多的是数据同步问题(双删策略)
双删策略
先更新数据库,再更新缓存;
同时有请求A和请求B进行更新操作,那么会出现:
- 线程A更新了数据库;
- 线程B更新了数据库;
- 线程B更新了缓存;
- 线程A更新了缓存;
缺点
这就出现请求A更新缓存应该比请求B更新缓存早才对,但是因为网络等原因,B却比A更早更新了缓存。这就导致了脏数据,因此不考虑!
如果你是一个写数据库场景比较多,而读数据场景比较少的业务需求,采用这种方案就会导致,数据压根还没读到,缓存就被频繁的更新,浪费性能。
如果你写入数据库的值,并不是直接写入缓存的,而是要经过一系列复杂的计算再写入缓存。那么,每次写入数据库后,都再次计算写入缓存的值,无疑是浪费性能的。显然,删除缓存更为适合。
先删除缓存,再更新数据库;
同时有一个请求A进行更新操作,另一个请求B进行查询操作。那么会出现如下情形:
(1)请求A进行写操作,删除缓存;
(2)请求B查询发现缓存不存在;
(3)请求B去数据库查询得到旧值;
(4)请求B将旧值写入缓存;
(5)请求A将新值写入数据库;
导致数据不一致的情形出现,如果不采用给缓存设置过期时间策略,该数据永远都是脏数据。
延时双删策略
解决方案:延时双删策略
(1)先淘汰缓存;
(2)再写数据库(这两步和原来一样);
(3)休眠1秒,再次淘汰缓存;
这么做,可以将1秒内所造成的缓存脏数据,再次删除!这个一秒如何得出来的呢?评估自己的项目的读数据业务逻辑的耗时,在读数据业务逻辑的耗时基础上,加几百ms即可,确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
MySQL的读写分离架构中
一个请求A进行更新操作,另一个请求B进行查询操作。
(1)请求A进行写操作,删除缓存;
(2)请求A将数据写入数据库了;
(3)请求B查询缓存发现,缓存没有值;
(4)请求B去从库查询,这时,还没有完成主从同步,因此查询到的是旧值;
(5)请求B将旧值写入缓存;
(6)数据库完成主从同步,从库变为新值; 导致数据不一致,解决方案使用双删延时策略。只是,睡眠时间修改为在主从同步的延时时间基础上,加几百ms。
采用这种同步淘汰策略,吞吐量降低怎么办? ok,那就将第二次删除作为异步的。自己起一个线程,异步删除。这样,写的请求就不用沉睡一段时间后了,再返回。这么做,加大吞吐量。
异步延时删除策略
先更新数据库,再删除缓存; 一个请求A做查询操作,一个请求B做更新操作,那么会有如下情形产生:
(1)缓存刚好失效;
(2)请求A查询数据库,得一个旧值;
(3)请求B将新值写入数据库;
(4)请求B删除缓存;
(5)请求A将查到的旧值写入缓存;
问题:会发生脏数据,但是几率不大,因为步骤(3)的写数据库操作比步骤(2)的读数据库操作耗时更短,才有可能使得步骤(4)先于步骤(5)。可是,大家想想,数据库的读操作的速度远快于写操作的(不然做读写分离干嘛,做读写分离的意义就是因为读操作比较快,耗资源少),因此步骤(3)耗时比步骤(2)更短,这一情形很难出现。
如何解决脏数据呢?给缓存设有效时间是一种方案。其次,采用策略2(先删除缓存,再更新数据库)里给出的异步延时删除策略,保证读请求完成以后,再进行删除操作。
第二次删除,如果删除失败怎么办? 这是个非常好的问题,因为第二次删除失败,就会出现如下情形。还是有两个请求,一个请求A进行更新操作,另一个请求B进行查询操作,为了方便,假设是单库: (1)请求A进行写操作,删除缓存; (2)请求B查询发现缓存不存在; (3)请求B去数据库查询得到旧值; (4)请求B将旧值写入缓存; (5)请求A将新值写入数据库; (6)请求A试图去删除请求B写入对缓存值,结果失败了;ok,这也就是说。如果第二次删除缓存失败,会再次出现缓存和数据库不一致的问题。
解决方案一
(1)更新数据库数据;
(2)缓存因为种种问题删除失败;
(3)将需要删除的key发送至消息队列;
(4)自己消费消息,获得需要删除的key;
(5)继续重试删除操作,直到成功; 缺点:对业务线代码造成大量的侵入
解决方案二: 启动一个订阅程序去订阅数据库的binlog,获得需要操作的数据。在应用程序中,另起一段程序,获得这个订阅程序传来的信息,进行删除缓存操作。
(1)更新数据库数据;
(2)数据库会将操作信息写入binlog日志当中;
(3)订阅程序提取出所需要的数据以及key;
(4)另起一段非业务代码,获得该信息;
(5)尝试删除缓存操作,发现删除失败;
(6)将这些信息发送至消息队列;
(7)重新从消息队列中获得该数据,重试操作;
订阅binlog程序在mysql中有现成的中间件叫canal,可以完成订阅binlog日志的功能。重试机制,采用的是消息队列的方式。如果对一致性要求不是很高,直接在程序中另起一个线程,每隔一段时间去重试。
Redis分布式锁底层实现
如何实现
redis使用setnx作为分布式锁,在多线程环境下面,只有一个线程会拿到这把锁,拿到锁的线程执行业务代码,执行业务代码需要一点时间,所以这段时间拒绝了很多等待获取锁的请求,直到有锁的线程最后释放掉锁,其他线程才能获取锁,这个就是redis的分布式锁的使用。
使用redis锁会有很多异常情况,如何处理这些异常呢
1.redis服务挂掉了,抛出异常了,锁不会被释放掉,新的请求无法进来,出现死锁问题
添加try finally处理
2.服务器果宕机了,导致锁不能被释放的现象
设置超时时间
3.锁的过期时间比业务执行时间短,会存在多个线程拥有同一把锁的现象
如果有一个线程执行需要15s,过期时间只有10s,当执行到10s时第二个线程进来拿到这把锁,会出现多个线程拿到同一把锁执行。
续期超时时间,当一个线程执行5s后对超时时间续期10s,续期设置可以借助redission工具,加锁成功,后台新开一个线程,每隔10秒检查是否还持有锁,如果持有则延长锁的时间,如果加锁失败一直循环(自旋)加锁。
4.锁的过期时间比业务执行时间短,锁永久失效
如果有一个线程执行需要15s,过期时间只有10s,当执行到10s时第二个线程进来拿到这把锁,会出现多个线程拿到同一把锁执行,在第一个线程执行完时会释放掉第二个线程的锁,以此类推,导致锁的永久失效。
给每个线程都设置一个唯一标识,避免出现程序执行的时间超过设置的过期时间,导致其他线程删除了自己的锁,只允许自己删除自己线程的锁
Redis热点数据缓存
热点数据缓存
当前key是一个热点key(例如一个热门的娱乐新闻),并发量非常大重建缓存不能在短时间完成,可能是一个复杂计算,例如复杂的SQL、多次IO、多个依赖等在缓存失效的瞬间,有大量线程来重建缓存,造成后端负载加大,甚至可能会让应用崩溃。
互斥锁(mutex)
解决方案一:互斥锁(mutex)
只允许一个线程重建缓存,其他线程等待重建缓存的线程执行完,重新从缓存获取数据。
1)从Redis获取数据,如果值不为空,则直接返回值;否则执行下面的2.1)和2.2)步骤 2.1)如果set(nx和ex)结果为true,说明此时没有其他线程重建缓存, 那么当前线程执行缓存构建逻辑 2.2)如果set(nx和ex)结果为false,说明此时已经有其他线程正在执 行构建缓存的工作,那么当前线程将休息指定时间(例如这里是50毫秒,取决于构建缓存的速度)后,重新执行函数,直到获取到数据。
优缺点:如果构建缓存过程出现问题或者时间较长,可能会存在死锁和线程池阻塞的风险,但是这种方法能够较好地降低后端存储负载,并在一致性上做得比较好。
永远不过期
解决方案二:永远不过期
从缓存层面来看,确实没有设置过期时间,所以不会出现热点key过期 后产生的问题,也就是“物理”不过期。从功能层面来看,为每个value设置一个逻辑过期时间,当发现超过逻 辑过期时间后,会使用单独的线程去构建缓存。
优缺点:由于没有设置真正的过期时间,实际上已经不存在热点key产生的一系列危害,但是会存在数据不一致的情况,同时代码复杂度会增大。
问题:怎么知道哪些数据是热点数据?因为本地缓存资源有限,不可能把所有的商品数据进行缓存,它只会缓存热点的数据。那怎么知道数据是热点数据呢?
利用redis4.x自身特性,LFU机制发现热点数据。实现很简单,只要把redis内存淘汰机制设置为allkeys-lfu或者volatile-lfu方式,再执行
./redis-cli --hotkeys会返回访问频率高的key,并从高到底的排序,在设置key时,需要把商品id带上,这样就是知道是哪些商品了。
高并发
单机的 Redis,能够承载的 QPS大概就在上万到几万不等。对于缓存来说,一般都是用来支撑读高并发的。因此架构做成主从(master-slave)架构,一主多从,主负责写,并且将数据复制到其它的slave 节点,从节点负责读。所有的读请求全部走从节点。这样也可以很轻松实现水平扩容,支撑读高并发。
高可用
Redis哨兵集群实现高可用,哨兵是一个分布式系统,你可以在一个架构中运行多个哨兵进程,这些进程使用流言协议来接收关于主节点是否下线的信息,并使用投票协议来决定是否执行自动故障迁移,以及选择哪个备节点作为新的主节点。每个哨兵会向其它哨兵、主节点、备节点定时发送消息,以确认对方是否”活”着,如果发现对方在指定时间(可配置)内未回应,则暂时认为对方已挂.若“哨兵群”中的多数哨兵,都报告某一主节点没响应,系统才认为该主节点"彻底死亡",通过算法,从剩下的备节点中,选一台提升为主节点,然后自动修改相关配置。
哨兵机制
哨兵是一个分布式系统,你可以在一个架构中运行多个哨兵进程,这些进程使用流言协议来接收关于主节点是否下线的信息,并使用投票协议来决定是否执行自动故障迁移,以及选择哪个备节点作为新的主节点。每个哨兵会向其它哨兵、主节点、备节点定时发送消息,以确认对方是否”活”着,如果发现对方在指定时间(可配置)内未回应,则暂时认为对方已挂。
若“哨兵群”中的多数哨兵,都报告某一主节点没响应,系统才认为该主节点"彻底死亡",通过算法,从剩下的备节点中,选一台提升为主节点,然后自动修改相关配置。可以通过修改sentinel.conf配置文件,配置主节点名称,IP,端口号,选举次数,主服务器的密码,心跳检测毫秒数,做多少个节点等。
Redis 哨兵主备切换的数据丢失问题
异步复制导致的数据丢失
master->slave 的复制是异步的,所以可能有部分数据还没复制到 slave,master 就宕机了,此时这部分数据就丢失了。 脑裂导致的数据丢失:某个 master 所在机器突然脱离了正常的网络,跟其他 slave 机器不能连接,但是实际上 master还运行着。此时哨兵可能就会认为 master 宕机了,然后开启选举,将其他 slave 切换成了 master。这个时候,集群里就会有两个master ,也就是所谓的脑裂。 此时虽然某个 slave 被切换成了 master,但是可能 client 还没来得及切换到新的master,还继续向旧 master 写数据。因此旧 master 再次恢复的时候,会被作为一个 slave 挂到新的 master上去,自己的数据会清空,重新从新的 master 复制数据。而新的 master 并没有后来 client写入的数据,因此,这部分数据也就丢失了
解决方案:
进行配置:min-slaves-to-write 1 min-slaves-max-lag 10
通过配置至少有 1 个 slave,数据复制和同步的延迟不能超过 10 秒,超过了master 就不会再接收任何请求了。
减少异步复制数据的丢失
一旦 slave 复制数据和 ack 延时太长,就认为可能 master 宕机后损失的数据太多了,那么就拒绝写请求,这样可以把 master宕机时由于部分数据未同步到 slave 导致的数据丢失降低的可控范围内。 减少脑裂的数据丢失:如果一个 master 出现了脑裂,跟其他slave 丢了连接,如果不能继续给指定数量的slave 发送数据,而且 slave 超过10 秒没有给自己ack消息,那么就直接拒绝客户端的写请求。因此在脑裂场景下,最多就丢失10 秒的数据。
集群模式
数据量很少的情况下,比如你的缓存一般就几个 G,单机就足够了,可以使用 replication,一个 master 多个 slaves,要几个 slave 跟你要求的读吞吐量有关,然后自己搭建一个 sentinel 集群去保证 Redis 主从架构的高可用性。
海量数据+高并发+高可用的场景的情况下,使用Redis cluster ,自动将数据进行分片,每个 master 上放一部分数据,它支撑 N个 Redis master node,每个 master node 都可以挂载多个 slave node。 这样整个 Redis就可以横向扩容了,如果你要支撑更大数据量的缓存,那就横向扩容更多的 master 节点,每个 master节点就能存放更多的数据了。而且部分 master 不可用时,还是可以继续工作的。
在 Redis cluster 架构下,使用cluster bus 进行节点间通信,用来进行故障检测、配置更新、故障转移授权。cluster bus 用了一种二进制的协议, gossip 协议,用于节点间进行高效的数据交换,占用更少的网络带宽和处理时间。
集群协议
集群元数据的维护:集中式、Gossip 协议
集中式
集中式是将集群元数据(节点信息、故障等等)几种存储在某个节点上。集中式元数据集中存储的一个典型代表,就是大数据领域的 storm。它是分布式的大数据实时计算引擎,是集中式的元数据存储的结构,底层基于zookeeper对所有元数据进行存储维护。集中式的好处在于,元数据的读取和更新,时效性非常好,一旦元数据出现了变更,就立即更新到集中式的存储中,其它节点读取的时候就可以感知到;不好在于,所有的元数据的更新压力全部集中在一个地方,可能会导致元数据的存储有压力。
gossip 协议
gossip 协议,所有节点都持有一份元数据,不同的节点如果出现了元数据的变更,就不断将元数据发送给其它的节点,让其它节点也进行元数据的变更。gossip好处在于,元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续打到所有节点上去更新,降低了压力;不好在于,元数据的更新有延时,可能导致集群中的一些操作会有一些滞后。
在 Redis cluster 架构下,每个节点都有一个专门用于节点间通信的端口,就是自己提供服务的端口号+10000,每个 Redis 要放开两个端口号,比如 7001,那么用于节点间通信的就是 17001 端口,17001端口号是用来进行节点间通信的,也就是 cluster bus 的东西。每个节点每隔一段时间都会往另外几个节点发送 ping 消息,同时其它几个节点接收到 ping 之后返回 pong 。
多级缓存架构

并发竞争
Redis 的并发竞争问题是什么?如何解决这个问题?了解 Redis 事务的 CAS 方案吗?
多客户端同时并发写一个 key,可能本来应该先到的数据后到了,导致数据版本错了;或者是多客户端同时获取一个 key,修改值之后再写回去,只要顺序错了,数据就错了。
CAS 类的乐观锁方案:某个时刻,多个系统实例都去更新某个 key。可以基于 zookeeper 实现分布式锁。每个系统通过 zookeeper 获取分布式锁,确保同一时间,只能有一个系统实例在操作某个 key,别人都不允许读和写。
你要写入缓存的数据,都是从 mysql 里查出来的,都得写入 mysql 中,写入 mysql 中的时候必须保存一个时间戳,从 mysql 查出来的时候,时间戳也查出来。每次要写之前,先判断一下当前这个 value 的时间戳是否比缓存里的 value 的时间戳要新。如果是的话,那么可以写,否则,就不能用旧的数据覆盖新的数据。
Redis cluster 的高可用与主备切换原理
如果一个节点认为另外一个节点宕机,这是属于主观宕机。如果多个节点都认为另外一个节点宕机了,那么就是客观宕机,跟哨兵的原理几乎一样,sdown,odown。流程为:如果一个节点认为某个节点pfail 了,那么会在 gossip ping 消息中, ping 给其他节点,如果超过半数的节点都认为 pfail 了,那么就会变成fail 。 每个从节点,都根据自己对 master 复制数据的 offset,来设置一个选举时间,offset越大(复制数据越多)的从节点,选举时间越靠前,优先进行选举。所有的 master node 开始 slave 选举投票,给要进行选举的slave 进行投票,如果大部分 master node (N/2 + 1) 都投票给了某个从节点,那么选举通过,那个从节点可以切换成master。从节点执行主备切换,从节点切换为主节点。
主从架构下的数据同步
主从复制/数据同步
master会启动一个后台线程,开始生成一份RDB快照文件,同时还会将从客户端收到的所有写命令缓存在内存中。RDB文件生成完毕之后,master会将这个RDB发送给slave,slave会先写入本地磁盘,然后再从本地磁盘加载到内存中。然后master会将内存中缓存的写命令发送给slave,slave也会同步这些数据。
主从架构下的数据部分复制(断点续传)
当redis是主从架构时,主节点同步数据到从节点进行持久化,这个过程可能会因为网络/IO等原因,导致连接中断,当主节点和从节点断开重连后,一般都会对整份数据进行复制,这个过程是比较浪费性能的。从redis2.8版本开始,redis改用可以支持部分数据复制的命令去主节点同步数据,主节点会在内存中创建一个复制数据用的缓存队列,缓存最近一段时间的数据,主节点和它所有的从节点都维护复制的数据下标和主节点的进程id,当网络连接断开后,从节点会请求主节点继续进行数据同步,从记录数据的下标开始同步数据。如果主节点进程id变化了,或者从节点数据下标太旧,不在主节点的缓存队列里,会进行一次全量数据的复制。
数据丢失发生的场景以及解决方案
- 异步复制导致的数据丢失:主节点到从节点的复制是异步的,主节点有部分数据还没复制到从节点,主节点就宕机了。
- 脑裂导致的数据丢失:脑裂导致的数据丢失:某个 主节点 所在机器突然脱离了正常的网络,跟其他从节点机器不能连接,但是实际上 主节点还运行着,这个时候哨兵可能就会认为 主节点 宕机了,然后开启选举,将其他从节点切换成了 主节点,集群里就会有两个主节点 ,也就是所谓的脑裂。虽然某个从节点被切换成了 主节点,但是可能 client 还没来得及切换到新的主节点,还继续向旧的主节点写数据,当旧的主节点再次恢复的时候,会被作为一个从节点挂到新的 主节点上去,自己的数据会清空,从新的主节点复制数据,新的主节点并没有后来 client写入的数据,这部分数据也就丢失了。
解决方案:
- 针对异步复制导致的数据丢失,可以通过控制复制数据的时长和ack的时间来控制,一旦从节点复制数据和 ack 延时太长,就认为可能主节点宕机后损失的数据太多了,那么就拒绝写请求,这样可以把主节点宕机时由于部分数据未同步到从节点导致的数据丢失降低的可控范围内。
- 针对脑裂导致的数据丢失:如果一个主节点出现了脑裂,跟其他从节点断了连接,如果不能继续给从节点发送数据,而且从节点超过10 秒没有给自己ack消息,那么就直接拒绝客户端的写请求,这样即便在脑裂场景下,最多就丢失10 秒的数据。在redis的配置文件里面有二个参数,min-slaves-to-write 3表示连接到master的最少slave数量,min-slaves-max-lag 10表示slave连接到master的最大延迟时间,通过这二个参数可以把数据丢失控制在承受范围以内。
主从/哨兵/集群区别
主从架构
主数据库可以进行读写操作,当写操作导致数据变化的时候,会自动将数据同步给从数据库,从数据库一般是只读的,接受主数据库同步过来的数据。
哨兵
当主数据库遇到异常中断服务后,需要通过手动的方式选择一个从数据库来升格为主数据库,让系统能够继续提供服务,难以实现自动化。 Redis 2.8中提供了哨兵工具来实现自动化的系统监控和故障恢复功能,哨兵的作用就是监控redis主、从数据库是否正常运行,主数据库出现故障,自动将从数据库转换为主数据库。
集群
即使使用哨兵,redis每个实例也是全量存储,每个redis存储的内容都是完整的数据,浪费内存,有木桶效应。为了最大化利用内存,可以采用集群,就是分布式存储,每台redis存储不同的内容,Redis集群共有16384个槽,每个redis分得一些槽,客户端请求的key,根据公式,计算出映射到哪个分片上。
高可用/哨兵集群/主备切换
Redis哨兵集群实现高可用,哨兵是一个分布式系统,可以在一个架构中运行多个哨兵进程,这些进程使用流言协议来接收关于主节点是否下线的信息,并使用投票协议来决定是否进行自动故障迁移,选择哪个备节点作为新的主节点。每个哨兵会向其它哨兵、主节点、备节点定时发送消息,以确认对方是否”活”着,如果发现对方在指定时间内未回应,则暂时认为对方已挂。若“哨兵群”中的多数哨兵,都报告某一主节点没响应,系统才认为该主节点"彻底死亡",通过算法,从剩下的备节点中,选一台提升为主节点,然后自动修改相关配置,比如主节点名称,IP,端口号,选举次数,主服务器的密码,心跳检测毫秒数,做多少个节点等。
MQ知识点(RabbitMQ/RocketMQ/Kafka)
三种mq对比
使用消息队列有解耦,扩展性,削峰,异步等功能,市面上主流的几款mq,rabbitmq,rocketmq,kafka有各自的应用场景。kafka,有出色的吞吐量,比较强悍的性能,而且集群可以实现高可用,就是会丢数据,所以一般被用于日志分析和大数据采集。rabbitmq,消息可靠性比较高,支持六种工作模式,功能比较全面,但是由于吞吐量比较低,消息累积还会影响性能,加上erlang语言不好定制,所以一般使用于小规模的场景,大多数是中小企业用的比较多。rocketmq,高可用,高性能,高吞吐量,支持多种消息类型,比如同步,异步,顺序,广播,延迟,批量,过滤,事务等等消息,功能比较全面,只不过开源版本比不上商业版本的,加上开发这个中间件的大佬写的文档不多,文档不太全,这也是它的一个缺点,不过这个中间件可以作用于几乎全场景。
消息丢失
消息丢失,生产者往消息队列发送消息,消息队列往消费者发送消息,会有丢消息的可能,消息队列也有可能丢消息,通常MQ存盘时都会先写入操作系统的缓存页中,然后再由操作系统异步的将消息写入硬盘,这个中间有个时间差,就可能会造成消息丢失,如果服务挂了,缓存中还没有来得及写入硬盘的消息就会发生消息丢失。
不同的消息中间件对于消息丢失也有不同的解决方案,先说说最容易丢失消息的kafka吧。生产者发消息给Kafka Broker:消息写入Leader后,Follower是主动与Leader进行同步,然后发ack告诉生产者收到消息了,这个过程kafka提供了一个参数,request.required.acks属性来确认消息的生产,0表示不进行消息接收是否成功的确认,发生网络抖动消息丢了,生产者不校验ACK自然就不知道丢了。1表示当Leader接收成功时确认,只要Leader存活就可以保证不丢失,保证了吞吐量,但是如果leader挂了,恰好选了一个没有ACK的follower,那也丢了。-1或者all表示Leader和Follower都接收成功时确认,可以最大限度保证消息不丢失,但是吞吐量低,降低了kafka的性能。一般在不涉及金额的情况下,均衡考虑可以使用1,保证消息的发送和性能的一个平衡。Kafka Broker 消息同步和持久化:Kafka通过多分区多副本机制,可以最大限度保证数据不会丢失,如果数据已经写入系统缓存中,但是还没来得及刷入磁盘,这个时候机器宕机,或者没电了,那就丢消息了,当然这种情况很极端。Kafka Broker 将消息传递给消费者:如果消费这边配置的是自动提交,万一消费到数据还没处理完,就自动提交offset了,但是此时消费者直接宕机了,未处理完的数据丢失了,下次也消费不到了。所以为了避免这种情况,需要将配置改为,先消费处理数据,然后手动提交,这样消息处理失败,也不会提交成功,没有丢消息。
rabbitmq整个消息投递的路径是producer—>rabbitmq broker—>exchange—>queue—>consumer。
生产者将消息投递到Broker时产生confirm状态,会出现二种情况,ack:表示已经被Broker签收。nack:表示表示已经被Broker拒收,原因可能有队列满了,限流,IO异常等。生产者将消息投递到Broker,被Broker签收,但是没有对应的队列进行投递,将消息回退给生产者会产生return状态。这二种状态是rabbitmq提供的消息可靠投递机制,生产者开启确认模式和退回模式。使用rabbitTemplate.setConfirmCallback设置回调函数。当消息发送到exchange后回调confirm方法。在方法中判断ack,如果为true,则发送成功,如果为false,则发送失败,需要处理。使用rabbitTemplate.setReturnCallback设置退回函数,当消息从exchange路由到queue失败后,如果设置了rabbitTemplate.setMandatory(true)参数,则会将消息退回给producer。消费者在rabbit:listener-container标签中设置acknowledge属性,设置ack方式 none:自动确认,manual:手动确认。none自动确认模式很危险,当生产者发送多条消息,消费者接收到一条信息时,会自动认为当前发送的消息已经签收了,这个时候消费者进行业务处理时出现了异常情况,也会认为消息已经正常签收处理了,而队列里面显示都被消费掉了。所以真实开发都会改为手动签收,可以防止消息丢失。消费者如果在消费端没有出现异常,则调用channel.basicAck方法确认签收消息。消费者如果出现异常,则在catch中调用 basicNack或 basicReject,拒绝消息,让MQ重新发送消息。通过一系列的操作,可以保证消息的可靠投递以及防止消息丢失的情况。

然后说一下rocketmq,生产者使用事务消息机制保证消息零丢失,第一步就是确保Producer发送消息到了Broker这个过程不会丢消息。发送half消息给rocketmq,这个half消息是在生产者操作前发送的,对下游服务的消费者是不可见的。这个消息主要是确认RocketMQ的服务是否正常,通知RocketMQ,马上要发一个消息了,做好准备。half消息如果写入失败就认为MQ的服务是有问题的,这个时候就不能通知下游服务了,给生产者的操作加上一个状态标记,然后等待MQ服务正常后再进行补偿操作,等MQ服务正常后重新下单通知下游服务。然后执行本地事务,比如说下了个订单,把下单数据写入到mysql,返回本地事务状态给rocketmq,在这个过程中,如果写入数据库失败,可能是数据库崩了,需要等一段时间才能恢复,这个时候把订单一直标记为"新下单"的状态,订单的消息先缓存起来,比如Redis、文本或者其他方式,然后给RocketMQ返回一个未知状态,未知状态的事务状态回查是由RocketMQ的Broker主动发起的,RocketMQ过一段时间来回查事务状态,在回查事务状态的时候,再尝试把数据写入数据库,如果数据库这时候已经恢复了,继续后面的业务。而且即便这个时候half消息写入成功后RocketMQ挂了,只要存储的消息没有丢失,等RocketMQ恢复后,RocketMQ就会再次继续状态回查的流程。第二步就是确保Broker接收到的消息不会丢失,因为RocketMQ为了减少磁盘的IO,会先将消息写入到os缓存中,不是直接写入到磁盘里面,消费者从os缓存中获取消息,类似于从内存中获取消息,速度更快,过一段时间会由os线程异步的将消息刷入磁盘中,此时才算真正完成了消息的持久化。在这个过程中,如果消息还没有完成异步刷盘,RocketMQ中的Broker宕机的话,就会导致消息丢失。所以第二步,消息支持持久化到Commitlog里面,即使宕机后重启,未消费的消息也是可以加载出来的。把RocketMQ的刷盘方式 flushDiskType配置成同步刷盘,一旦同步刷盘返回成功,可以保证接收到的消息一定存储在本地的内存中。采用主从机构,集群部署,Leader中的数据在多个Follower中都存有备份,防止单点故障,同步复制可以保证即使Master 磁盘崩溃,消息仍然不会丢失。但是这里还会有一个问题,主从结构是只做数据备份,没有容灾功能的。也就是说当一个master节点挂了后,slave节点是无法切换成master节点继续提供服务的。所以在RocketMQ4.5以后的版本支持Dledge,DLedger是基于Raft协议选举Leader Broker的,当master节点挂了后,Dledger会接管Broker的CommitLog消息存储 ,在Raft协议中进行多台机器的Leader选举,发起一轮一轮的投票,通过多台机器互相投票选出来一个Leader,完成master节点往slave节点的消息同步。数据同步会通过两个阶段,一个是uncommitted阶段,一个是commited阶段。Leader Broker上的Dledger收到一条数据后,会标记为uncommitted状态,然后他通过自己的DledgerServer组件把这个uncommitted数据发给Follower Broker的DledgerServer组件。接着Follower Broker的DledgerServer收到uncommitted消息之后,必须返回一个ack给Leader Broker的Dledger。然后如果Leader Broker收到超过半数的Follower Broker返回的ack之后,就会把消息标记为committed状态。再接下来, Leader Broker上的DledgerServer就会发送committed消息给Follower Broker上的DledgerServer,让他们把消息也标记为committed状态。这样,就基于Raft协议完成了两阶段的数据同步。第三步,Cunmser确保拉取到的消息被成功消费,就需要消费者不要使用异步消费,有可能造成消息状态返回后消费者本地业务逻辑处理失败造成消息丢失的可能。用同步消费方式,消费者端先处理本地事务,然后再给MQ一个ACK响应,这时MQ就会修改Offset,将消息标记为已消费,不再往其他消费者推送消息,在Broker的这种重新推送机制下,消息是不会在传输过程中丢失的。
消息重复消费
消息重复消费的问题
第一种情况是发送时消息重复,当一条消息已被成功发送到服务端并完成持久化,此时出现了网络抖动或者客户端宕机,导致服务端对客户端应答失败。 如果此时生产者意识到消息发送失败并尝试再次发送消息,消费者后续会收到两条内容相同并且 Message ID 也相同的消息。
第二种情况是投递时消息重复,消息消费的场景下,消息已投递到消费者并完成业务处理,当客户端给服务端反馈应答的时候网络闪断。 为了保证消息至少被消费一次,tMQ 的服务端将在网络恢复后再次尝试投递之前已被处理过的消息,消费者后续会收到两条内容相同并且 Message ID 也相同的消息。
第三种情况是负载均衡时消息重复,比如网络抖动、Broker 重启以及订阅方应用重启,当MQ的Broker或客户端重启、扩容或缩容时,会触发Rebalance,此时消费者可能会收到重复消息。
那么怎么解决消息重复消费的问题呢?就是对消息进行幂等性处理。
在MQ中,是无法保证每个消息只被投递一次的,因为网络抖动或者客户端宕机等其他因素,基本都会配置重试机制,所以要在消费者端的业务上做消费幂等处理,MQ的每条消息都有一个唯一的MessageId,这个参数在多次投递的过程中是不会改变的,业务上可以用这个MessageId加上业务的唯一标识来作为判断幂等的关键依据,例如订单ID。而这个业务标识可以使用Message的Key来进行传递。消费者获取到消息后先根据id去查询redis/db是否存在该消息,如果不存在,则正常消费,消费完后写入redis/db。如果存在,则证明消息被消费过,直接丢弃。
消息顺序
消息顺序的问题,如果发送端配置了重试机制,mq不会等之前那条消息完全发送成功,才去发送下一条消息,这样可能会出现发送了1,2,3条消息,但是第1条超时了,后面两条发送成功,再重试发送第1条消息,这时消息在broker端的顺序就是2,3,1了。RocketMQ消息有序要保证最终消费到的消息是有序的,需要从Producer、Broker、Consumer三个步骤都保证消息有序才行。在发送者端:在默认情况下,消息发送者会采取Round Robin轮询方式把消息发送到不同的分区队列,而消费者消费的时候也从多个MessageQueue上拉取消息,这种情况下消息是不能保证顺序的。而只有当一组有序的消息发送到同一个MessageQueue上时,才能利用MessageQueue先进先出的特性保证这一组消息有序。而Broker中一个队列内的消息是可以保证有序的。在消费者端:消费者会从多个消息队列上去拿消息。这时虽然每个消息队列上的消息是有序的,但是多个队列之间的消息仍然是乱序的。消费者端要保证消息有序,就需要按队列一个一个来取消息,即取完一个队列的消息后,再去取下一个队列的消息。而给consumer注入的MessageListenerOrderly对象,在RocketMQ内部就会通过锁队列的方式保证消息是一个一个队列来取的。MessageListenerConcurrently这个消息监听器则不会锁队列,每次都是从多个Message中取一批数据,默认不超过32条。因此也无法保证消息有序。RocketMQ 在默认情况下不保证顺序,要保证全局顺序,需要把 Topic 的读写队列数设置为 1,然后生产者和消费者的并发设置也是 1,不能使用多线程。所以这样的话高并发,高吞吐量的功能完全用不上。全局有序就是无论发的是不是同一个分区,我都可以按照你生产的顺序来消费。分区有序就只针对发到同一个分区的消息可以顺序消费。kafka保证全链路消息顺序消费,需要从发送端开始,将所有有序消息发送到同一个分区,然后用一个消费者去消费,但是这种性能比较低,可以在消费者端接收到消息后将需要保证顺序消费的几条消费发到内存队列(可以搞多个),一个内存队列开启一个线程顺序处理消息。RabbitMq没有属性设置消息的顺序性,不过我们可以通过拆分为多个queue,每个queue由一个consumer消费。或者一个queue对应一个consumer,然后这个consumer内部用内存队列做排队,然后分发给底层不同的worker来处理,保证消息的顺序性。
消息积压
线上有时因为发送方发送消息速度过快,或者消费方处理消息过慢,可能会导致broker积压大量未消费消息。消息数据格式变动或消费者程序有bug,导致消费者一直消费不成功,也可能导致broker积压大量未消费消息。解决方案可以修改消费端程序,让其将收到的消息快速转发到其他主题,可以设置很多分区,然后再启动多个消费者同时消费新主题的不同分区。可以将这些消费不成功的消息转发到其它队列里去,类似死信队列,后面再慢慢分析死信队列里的消息处理问题。另外在RocketMQ官网中,还分析了一个特殊情况,如果RocketMQ原本是采用的普通方式搭建主从架构,而现在想要中途改为使用Dledger高可用集群,这时候如果不想历史消息丢失,就需要先将消息进行对齐,也就是要消费者把所有的消息都消费完,再来切换主从架构。因为Dledger集群会接管RocketMQ原有的CommitLog日志,所以切换主从架构时,如果有消息没有消费完,这些消息是存在旧的CommitLog中的,就无法再进行消费了。这个场景下也是需要尽快的处理掉积压的消息。
延迟队列
消息被发送以后,并不想让消费者立刻获取,而是等待特定的时间后,消费者才能获取这个消息进行消费。例如10分钟,内完成订单支付,支付完成后才会通知下游服务进行进一步的营销补偿。往MQ发一个延迟1分钟的消息,消费到这个消息后去检查订单的支付状态,如果订单已经支付,就往下游发送下单的通知。而如果没有支付,就再发一个延迟1分钟的消息。最终在第10个消息时把订单回收,就不用对全部的订单表进行扫描,而只需要每次处理一个单独的订单消息。这个就是延迟对列的应用场景。rabbittmq,rocketmq都可以通过设置ttl来设置延迟时间,kafka则是可以在发送延时消息的时候,先把消息按照不同的延迟时间段发送到指定的队列中,比如topic_1s,topic_5s,topic_10s,topic_2h,然后通过定时器进行轮训消费这些topic,查看消息是否到期,如果到期就把这个消息发送到具体业务处理的topic中,队列中消息越靠前的到期时间越早,具体来说就是定时器在一次消费过程中,对消息的发送时间做判断,看下是否延迟到对应时间了,如果到了就转发,如果还没到这一次定时任务就可以提前结束了。
mq设置过期时间,就会有消息失效的情况,如果消息在队列里积压超过指定的过期时间,就会被mq给清理掉,这个时候数据就没了。解决方案也有手动写程序,将丢失的那批数据,一点点地查出来,然后重新插入到 mq 里面去。
消息队列高可用
对于RocketMQ来说可以使用Dledger主从架构来保证消息队列的高可用,这个在上面也有提到过。然后在说说rabbitmq,它提供了一种叫镜像集群模式,在镜像集群模式下,你创建的 queue,无论元数据还是 queue 里的消息都会存在于多个实例上,就是说,每个 RabbitMQ 节点都有这个 queue 的一个完整镜像,包含 queue 的全部数据的意思。然后每次你写消息到 queue 的时候,都会自动把消息同步到多个实例的 queue 上。RabbitMQ 有很好的管理控制台,可以在后台新增一个策略,这个策略是镜像集群模式的策略,指定的时候是可以要求数据同步到所有节点的,也可以要求同步到指定数量的节点,再次创建 queue 的时候,应用这个策略,就会自动将数据同步到其他的节点上去了。只不过消息需要同步到所有机器上,导致网络带宽压力和消耗很重。最后再说说kafka,它是天然的分布式消息队列,在Kafka 0.8 以后,提供了副本机制,一个 topic要求指定partition数量,每个 partition的数据都会同步到其它机器上,形成自己的多个 replica 副本,所有 replica 会选举一个 leader 出来,其他 replica 就是 follower。写的时候,leader 会负责把数据同步到所有 follower 上去。如果某个 broker 宕机了,没事儿,那个 broker上面的 partition 在其他机器上都有副本的,如果这上面有某个 partition 的 leader,那么此时会从 follower 中重新选举一个新的 leader 出来。
RabbitMQ的工作模式
RabbitMQ 提供了 6 种工作模式,简单模式、work queues、Publish/Subscribe
发布与订阅模式、Routing 路由模式、Topics 主题模式、RPC 远程调用模式(远程调用,不太算消息队列)
简单模式
一个生产者生产消息发送到队列里面,一个消费者从队列里面拿消息,进行消费消息。一个生产者、一个消费者,不需要设置交换机(使用默认的交换机)
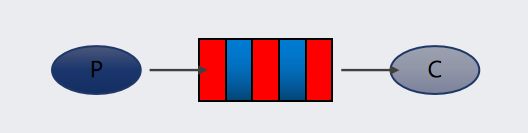
说明:类似一个邮箱,可以缓存消息;生产者向其中投递消息,消费者从其中取出消息。
Work queues 工作队列模式
一个生产者生产消息发送到队列里面,一个或者多个消费者从队列里面拿消息,进行消费消息。一个生产者、多个消费者(竞争关系),不需要设置交换机(使用默认的交换机)
说明:对于任务过重或任务较多情况使用工作队列可以提高任务处理的速度。应用场景:过年过节12306抢票,发短信给用户,可以接入多个短信服务进行发送,提供任务的处理速度。
Pub/Sub 订阅模式
一个生产者生产消息发送到交换机里面,由交换机处理消息,队列与交换机的任意绑定,将消息指派给某个队列,一个或者多个消费者从队列里面拿消息,进行消费消息。需要设置类型为 fanout 的交换机,并且交换机和队列进行绑定,当发送消息到交换机后,交换机会将消息发送到绑定的队列。
说明:Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与 Exchange 绑定,或者没有符合路由规则的队列,那么消息会丢失!
Routing 路由模式
一个生产者生产消息发送到交换机里面,并且指定一个路由key,队列与交换机的绑定是通过路由key进行绑定的,消费者在消费的时候需要根据路由key从交换机里面拿消息,进行消费消息。需要设置类型为 direct 的交换机,交换机和队列进行绑定,并且指定 routing key,当发送消息到交换机后,交换机会根据 routing key 将消息发送到对应的队列。
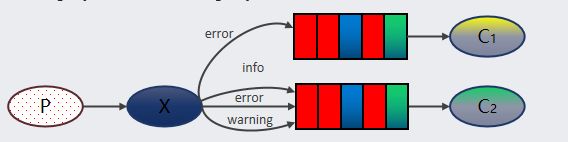
说明:Routing 模式要求队列在绑定交换机时要指定 routing key,消息会转发到符合 routing key 的队列。
Topics 通配符模式
一个生产者生产消息发送到交换机里面,并且使用通配符的形式(类似mysql里面的模糊查询,比如想获取一批带有item前缀的数据),队列与交换机的绑定是通过通配符进行绑定的,消费者在消费的时候需要根据根据通配符从交换机里面拿消息,进行消费消息。需要设置类型为 topic 的交换机,交换机和队列进行绑定,并且指定通配符方式的 routing key,当发送消息到交换机后,交换机会根据 routing key 将消息发送到对应的队列
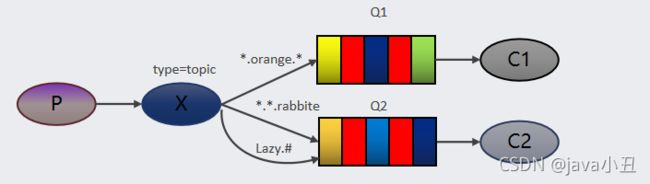
说明:通配符规则:# 匹配一个或多个词,* 匹配不多不少恰好1个词。例如:Lazy.# 能够匹配 Lazy.insert.content或者 Lazy.insert,Lazy.* 只能匹配Lazy.insert。
RocketMQ的消息类型
那我们来逐一连接下RocketMQ都支持哪些类型的消息:
同步发送、异步发送以及单向发送
基本样例部分我们使用消息生产者分别通过三种方式发送消息,同步发送、异步发送以及单向发送。
然后使用消费者来消费这些消息。
1、同步发送消息的样例见:org.apache.rocketmq.example.simple.Producer
发送完消息之后,等待消息返回后再继续进行下面的操作。(消息发送最慢)
package org.apache.rocketmq.example.simple;
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.client.producer.DefaultMQProducer;
import org.apache.rocketmq.client.producer.SendResult;
import org.apache.rocketmq.common.message.Message;
import org.apache.rocketmq.remoting.common.RemotingHelper;
//简单样例:同步发送消息
public class Producer {
public static void main(String[] args) throws MQClientException, InterruptedException {
DefaultMQProducer producer = new DefaultMQProducer("ProducerGroupName");
producer.setNamesrvAddr("ip:9876");
producer.start();
for (int i = 0; i < 20; i++)
try {
{
Message msg = new Message("TopicTest",
"TagA",
"OrderID188",
"Hello world".getBytes(RemotingHelper.DEFAULT_CHARSET));
//同步传递消息,消息会发给集群中的一个Broker节点。
SendResult sendResult = producer.send(msg);
System.out.printf("%s%n", sendResult);
}
} catch (Exception e) {
e.printStackTrace();
}
producer.shutdown();
}
}
2、异步发送消息的样例见:org.apache.rocketmq.example.simple.AsyncProducer
发完消息之后就去做自己的事情了,但是会给客户端一个回调方法,把消息发送的结果给到客户端。这里引入了一个countDownLatch来保证所有消息回调方法都执行完了再关闭Producer。 所以从这里可以看出,RocketMQ的Producer也是一个服务端,在往Broker发送消息的时候也要作为服务端提供服务。
package org.apache.rocketmq.example.simple;
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.client.producer.DefaultMQProducer;
import org.apache.rocketmq.client.producer.SendCallback;
import org.apache.rocketmq.client.producer.SendResult;
import org.apache.rocketmq.common.message.Message;
import org.apache.rocketmq.remoting.common.RemotingHelper;
import java.io.UnsupportedEncodingException;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
//简单样例:异步发送消息
public class AsyncProducer {
public static void main(String[] args) throws MQClientException, InterruptedException, UnsupportedEncodingException {
DefaultMQProducer producer = new DefaultMQProducer("Jodie_Daily_test");
producer.setNamesrvAddr("ip:9876");
producer.start();
producer.setRetryTimesWhenSendAsyncFailed(0);
int messageCount = 100;
//由于是异步发送,这里引入一个countDownLatch,保证所有Producer发送消息的回调方法都执行完了再停止Producer服务。
final CountDownLatch countDownLatch = new CountDownLatch(messageCount);
for (int i = 0; i < messageCount; i++) {
try {
final int index = i;
Message msg = new Message("TopicTest",
"TagA",
"OrderID188",
"Hello world".getBytes(RemotingHelper.DEFAULT_CHARSET));
producer.send(msg, new SendCallback() {
@Override
public void onSuccess(SendResult sendResult) {
countDownLatch.countDown();
System.out.printf("%-10d OK %s %n", index, sendResult.getMsgId());
}
@Override
public void onException(Throwable e) {
countDownLatch.countDown();
System.out.printf("%-10d Exception %s %n", index, e);
e.printStackTrace();
}
});
System.out.println("消息发送完成");
} catch (Exception e) {
e.printStackTrace();
}
}
countDownLatch.await(5, TimeUnit.SECONDS);
producer.shutdown();
}
}
3、单向发送消息的样例:
关键点就是使用producer.sendOneWay方式来发送消息,这个方法没有返回值,也没有回调。就是只管把消息发出去就行了。(消息发送最快)
public class OnewayProducer {
public static void main(String[] args) throws Exception{
//Instantiate with a producer group name.
DefaultMQProducer producer = new DefaultMQProducer("please_rename_unique_group_name");
// Specify name server addresses.可以在代码中指定,也可以在环境变量中配置,和jdk配置环境变量类似
producer.setNamesrvAddr("ip:9876");
//Launch the instance.
producer.start();
for (int i = 0; i < 100; i++) {
//Create a message instance, specifying topic, tag and message body.
Message msg = new Message("TopicTest" /* Topic */,
"TagA" /* Tag */,
("Hello RocketMQ " +
i).getBytes(RemotingHelper.DEFAULT_CHARSET) /* Message body */
);
//Call send message to deliver message to one of brokers.
//核心:发送消息。没有返回值,发完消息就不管了,不知道有没有发送消息成功
producer.sendOneway(msg);
}
//Wait for sending to complete
Thread.sleep(5000);
producer.shutdown();
}
}
4、使用消费者消费消息

消费者消费消息有两种模式
一种是消费者主动去Broker上拉取消息的拉模式。
一种是消费者等待Broker把消息推送过来的推模式。
拉模式的样例见:org.apache.rocketmq.example.simple.PullConsumer
package org.apache.rocketmq.example.simple;
import org.apache.rocketmq.client.consumer.DefaultMQPullConsumer;
import org.apache.rocketmq.client.consumer.PullResult;
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.common.message.MessageQueue;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class PullConsumer {
//偏移量
private static final Map<MessageQueue, Long> OFFSE_TABLE = new HashMap<MessageQueue, Long>();
public static void main(String[] args) throws MQClientException {
//过期的方法
DefaultMQPullConsumer consumer = new DefaultMQPullConsumer("PullConsumer_1");
consumer.setNamesrvAddr("ip:9876");
consumer.start();
Set<MessageQueue> mqs = consumer.fetchSubscribeMessageQueues("Topic_1");
for (MessageQueue mq : mqs) {
System.out.printf("Consume from the queue: %s%n", mq);
SINGLE_MQ:
while (true) {
try {
//第一个参数:mq的消息队列,第二个参数:过滤,第三个参数:偏移量,第四个参数:一次拉取多少条消息
PullResult pullResult =
consumer.pullBlockIfNotFound(mq, null, getMessageQueueOffset(mq), 32);
System.out.printf("%s%n", pullResult);
//自己维护偏移量
putMessageQueueOffset(mq, pullResult.getNextBeginOffset());
switch (pullResult.getPullStatus()) {
case FOUND:
break;
case NO_MATCHED_MSG:
break;
case NO_NEW_MSG:
break SINGLE_MQ;
case OFFSET_ILLEGAL:
break;
default:
break;
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
consumer.shutdown();
}
//获取偏移量
private static long getMessageQueueOffset(MessageQueue mq) {
Long offset = OFFSE_TABLE.get(mq);
if (offset != null)
return offset;
return 0;
}
//存储偏移量
private static void putMessageQueueOffset(MessageQueue mq, long offset) {
OFFSE_TABLE.put(mq, offset);
}
}
上面那种方式需要自己维护偏移量,不够友好,所以下面这种方式改进了
package org.apache.rocketmq.example.simple;
import org.apache.rocketmq.client.consumer.DefaultLitePullConsumer;
import org.apache.rocketmq.common.consumer.ConsumeFromWhere;
import org.apache.rocketmq.common.message.MessageExt;
import java.util.List;
public class LitePullConsumerSubscribe {
public static volatile boolean running = true;
public static void main(String[] args) throws Exception {
DefaultLitePullConsumer litePullConsumer = new DefaultLitePullConsumer("lite_pull_consumer_test");
litePullConsumer.setNamesrvAddr("ip:9876");
litePullConsumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
litePullConsumer.subscribe("TopicTest", "*");
litePullConsumer.start();
try {
while (running) {
//直接去拉就可以了
List<MessageExt> messageExts = litePullConsumer.poll();
System.out.printf("%s%n", messageExts);
}
} finally {
litePullConsumer.shutdown();
}
}
}
上面那种就是傻瓜式的一次拉取32条,无法定制化拉取指定某一个区间的消息,所以下面这种又进行了定制化调整
package org.apache.rocketmq.example.simple;
import org.apache.rocketmq.client.consumer.DefaultLitePullConsumer;
import org.apache.rocketmq.common.message.MessageExt;
import org.apache.rocketmq.common.message.MessageQueue;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
public class LitePullConsumerAssign {
public static volatile boolean running = true;
public static void main(String[] args) throws Exception {
DefaultLitePullConsumer litePullConsumer = new DefaultLitePullConsumer("PullConsumer_1");
litePullConsumer.setAutoCommit(false);
litePullConsumer.start();
//拉取这个主题里面的队列
Collection<MessageQueue> mqSet = litePullConsumer.fetchMessageQueues("Topic_1");
List<MessageQueue> list = new ArrayList<>(mqSet);
//这一步就是过滤一部分队列,取其中一部分的队列
List<MessageQueue> assignList = new ArrayList<>();
for (int i = 0; i < list.size() / 2; i++) {
assignList.add(list.get(i));
}
//把队列分配给这个消费者客户端
litePullConsumer.assign(assignList);
//取第一个队列,从偏移量为10的起点开始消费消息
litePullConsumer.seek(assignList.get(0), 10);
try {
while (running) {
//默认拉取32条
List<MessageExt> messageExts = litePullConsumer.poll();
System.out.printf("%s %n", messageExts);
litePullConsumer.commitSync();
}
} finally {
litePullConsumer.shutdown();
}
}
}
推模式的样例见:org.apache.rocketmq.example.simple.PushConsumer
package org.apache.rocketmq.example.simple;
import org.apache.rocketmq.client.consumer.DefaultMQPushConsumer;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyContext;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyStatus;
import org.apache.rocketmq.client.consumer.listener.MessageListenerConcurrently;
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.common.consumer.ConsumeFromWhere;
import org.apache.rocketmq.common.message.MessageExt;
import java.util.List;
public class PushConsumer {
public static void main(String[] args) throws InterruptedException, MQClientException {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("PushConsumer_1");
consumer.setNamesrvAddr("ip:9876");
consumer.subscribe("Topic_1", "*");//第二个参数就是过滤方式
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
//wrong time format 2018_0522_221800
consumer.setConsumeTimestamp("20220117221800");
//注册一个消息监听
consumer.registerMessageListener(new MessageListenerConcurrently() {
//消费消息,有消息来了之后就会由broker往这里面推消息
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
consumer.start();
System.out.printf("Consumer Started.%n");
}
}
通常情况下,用推模式比较简单。实际上RocketMQ的推模式也是由拉模式封装出来的。4.7.1版本中DefaultMQPullConsumerImpl这个消费者类已标记为过期,但是还是可以使用的。替换的类是DefaultLitePullConsumerImpl。
顺序消息
顺序消息生产者样例见:org.apache.rocketmq.example.ordermessage.Producer
package org.apache.rocketmq.example.ordermessage;
import org.apache.rocketmq.client.exception.MQBrokerException;
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.client.producer.DefaultMQProducer;
import org.apache.rocketmq.client.producer.MQProducer;
import org.apache.rocketmq.client.producer.MessageQueueSelector;
import org.apache.rocketmq.client.producer.SendResult;
import org.apache.rocketmq.common.message.Message;
import org.apache.rocketmq.common.message.MessageQueue;
import org.apache.rocketmq.remoting.common.RemotingHelper;
import org.apache.rocketmq.remoting.exception.RemotingException;
import java.io.UnsupportedEncodingException;
import java.util.List;
public class Producer {
public static void main(String[] args) throws UnsupportedEncodingException {
try {
DefaultMQProducer producer = new DefaultMQProducer("please_rename_unique_group_name");
producer.setNamesrvAddr("ip:9876");
producer.start();
//业务场景:我有十个订单,每个订单有六个步骤,现在需要按照固定的步骤一条条的发送消息
for (int i = 0; i < 10; i++) {
int orderId = i;
for(int j = 0 ; j <= 5 ; j ++){
Message msg =
new Message("OrderTopicTest", "order_"+orderId, "KEY" + orderId,
("order_"+orderId+" step " + j).getBytes(RemotingHelper.DEFAULT_CHARSET));
//消息队列的选择器
SendResult sendResult = producer.send(msg, new MessageQueueSelector() {
//第一个参数:所有的消息,第二个参数:发送的消息,第三个参数:根据什么发送,这里面传的是orderId
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
Integer id = (Integer) arg;
int index = id % mqs.size();
//获取订单id进行取模,取其中一个消息
return mqs.get(index);
}
//同一个订单id可以放到同一个队列里面去
}, orderId);
System.out.printf("%s%n", sendResult);
}
}
producer.shutdown();
} catch (MQClientException | RemotingException | MQBrokerException | InterruptedException e) {
e.printStackTrace();
}
}
}
顺序消息消费者样例见:org.apache.rocketmq.example.ordermessage.Consumer
package org.apache.rocketmq.example.ordermessage;
import org.apache.rocketmq.client.consumer.DefaultMQPushConsumer;
import org.apache.rocketmq.client.consumer.listener.*;
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.common.consumer.ConsumeFromWhere;
import org.apache.rocketmq.common.message.MessageExt;
import java.util.List;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicLong;
public class Consumer {
public static void main(String[] args) throws MQClientException {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("please_rename_unique_group_name_3");
consumer.setNamesrvAddr("ip:9876");
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_LAST_OFFSET);
consumer.subscribe("OrderTopicTest", "*");
//MessageListenerOrderly是可以保证消息顺序消费的,因为它是一个队列一个队列的去拿消息的
consumer.registerMessageListener(new MessageListenerOrderly() {
@Override
public ConsumeOrderlyStatus consumeMessage(List<MessageExt> msgs, ConsumeOrderlyContext context) {
//自动提交
context.setAutoCommit(true);
for(MessageExt msg:msgs){
System.out.println("收到消息内容 "+new String(msg.getBody()));
}
return ConsumeOrderlyStatus.SUCCESS;
}
});
// MessageListenerConcurrently是保证不了最终消费顺序的,因为他会出现同一个主题拿多个队列的消息,有可能第一个队列拿一大部分,第二个队列拿一小部分,这样是没法保证消息的顺序消费的
// 全局顺序可以通过一个主题里面只有一个队列,来保证在消费端队列里面的消息可以顺序消费。
// consumer.registerMessageListener(new MessageListenerConcurrently() {
// @Override
// public ConsumeConcurrentlyStatus consumeMessage(List msgs, ConsumeConcurrentlyContext context) {
// for(MessageExt msg:msgs){
// System.out.println("收到消息内容 "+new String(msg.getBody()));
// }
// return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
// }
// });
consumer.start();
System.out.printf("Consumer Started.%n");
}
}
验证时,可以启动多个Consumer实例,观察下每一个订单的消息分配以及每个订单下多个步骤的消费顺序。不管订单在多个Consumer实例之前是如何分配的,每个订单下的多条消息顺序都是固定从0~5的。RocketMQ保证的是消息的局部有序,而不是全局有序。
MessageListenerOrderly是可以保证最终消费顺序的,它是一个队列一个队列的去拿消息的
MessageListenerConcurrently是保证不了最终消费顺序的,不保证全局有序,只保证局部有序
先从控制台上看下List mqs是什么。再回看我们的样例,实际上,RocketMQ也只保证了每个OrderID的所有消息有序(发到了同一个queue),而并不能保证所有消息都有序。所以这就涉及到了RocketMQ消息有序的原理。要保证最终消费到的消息是有序的,需要从Producer、Broker、Consumer三个步骤都保证消息有序才行。
首先在发送者端:在默认情况下,消息发送者会采取Round Robin轮询方式把消息发送到不同的MessageQueue(分区队列),而消费者消费的时候也从多个MessageQueue上拉取消息,这种情况下消息是不能保证顺序的。而只有当一组有序的消息发送到同一个MessageQueue上时,才能利用MessageQueue先进先出的特性保证这一组消息有序。而Broker中一个队列内的消息是可以保证有序的。
然后在消费者端:消费者会从多个消息队列上去拿消息。这时虽然每个消息队列上的消息是有序的,但是多个队列之间的消息仍然是乱序的。消费者端要保证消息有序,就需要按队列一个一个来取消息,即取完一个队列的消息后,再去取下一个队列的消息。而给consumer注入的MessageListenerOrderly对象,在RocketMQ内部就会通过锁队列的方式保证消息是一个一个队列来取的。MessageListenerConcurrently这个消息监听器则不会锁队列,每次都是从多个Message中取一批数据(默认不超过32条)。因此也无法保证消息有序。
RocketMQ 在默认情况下不保证顺序,要保证全局顺序,需要把 Topic 的读写队列数设置为 1,然后生产者和消费者的并发设置也是 1,不能使用多线程。所以这样的话 高并发,高吞吐量的功能完全用不上。
全局顺序消息 对于指定的一个 Topic,所有消息按照严格的先入先出(FIFO)的顺序进行发布 和消费。 分区顺序消息 对于指定的一个 Topic,所有消息根据 Sharding Key 进行区块分区。同一个分 区内的消息按照严格的 FIFO 顺序进行发布和消费。Sharding Key 是顺序消息中用 来区分不同分区的关键字段,和普通消息的 Message Key 是完全不同的概念。
- 全局有序就是无论发的是不是同一个分区,我都可以按照你生产的顺序来消费
- 分区有序就只针对发到同一个分区的消息可以顺序消费
广播消息
广播消息的消息生产者样例见:org.apache.rocketmq.example.broadcast.PushConsumer
package org.apache.rocketmq.example.broadcast;
import org.apache.rocketmq.client.consumer.DefaultMQPushConsumer;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyContext;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyStatus;
import org.apache.rocketmq.client.consumer.listener.MessageListenerConcurrently;
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.common.consumer.ConsumeFromWhere;
import org.apache.rocketmq.common.message.MessageExt;
import org.apache.rocketmq.common.protocol.heartbeat.MessageModel;
import java.util.List;
public class PushConsumer {
public static void main(String[] args) throws InterruptedException, MQClientException {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("please_rename_unique_group_name_1");
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_LAST_OFFSET);
consumer.setNamesrvAddr("ip:9876");
//重点是这个消费模式
consumer.setMessageModel(MessageModel.BROADCASTING);
consumer.subscribe("TopicTest", "*");
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
consumer.start();
System.out.printf("Broadcast Consumer Started.%n");
}
}
广播消息并没有特定的消息消费者样例,这是因为这涉及到消费者的集群消费模式。在集群状态(MessageModel.CLUSTERING)下,每一条消息只会被同一个消费者组中的一个实例消费到(这跟kafka和rabbitMQ的集群模式是一样的)。而广播模式则是把消息发给了所有订阅了对应主题的消费者,而不管消费者是不是同一个消费者组。
延迟消息
延迟消息的生产者案例
public class ScheduledMessageProducer {
public static void main(String[] args) throws Exception {
// Instantiate a producer to send scheduled messages
DefaultMQProducer producer = new DefaultMQProducer("ExampleProducerGroup");
producer.setNamesrvAddr("ip:9876");
// Launch producer
producer.start();
int totalMessagesToSend = 100;
for (int i = 0; i < totalMessagesToSend; i++) {
Message message = new Message("TestTopic", ("Hello scheduled message " + i).getBytes());
// This message will be delivered to consumer 10 seconds later.
//消息的延迟级别,1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m
message.setDelayTimeLevel(3);
// Send the message
producer.send(message);
}
// Shutdown producer after use.
producer.shutdown();
}
}
延迟消息实现的效果就是在调用producer.send方法后,消息并不会立即发送出去,而是会等一段时间再发送出去。这是RocketMQ特有的一个功能。
那会延迟多久呢?延迟时间的设置就是在Message消息对象上设置一个延迟级别message.setDelayTimeLevel(3);
开源版本的RocketMQ中,对延迟消息并不支持任意时间的延迟设定(商业版本中支持),而是只支持18个固定的延迟级别,1到18分别对应messageDelayLevel=1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h。这从哪里看出来的?其实从rocketmq-console控制台就能看出来。而这18个延迟级别也支持自行定义,不过一般情况下最好不要自定义修改。开源版本只有18个级别,商业版本可以自定义级别
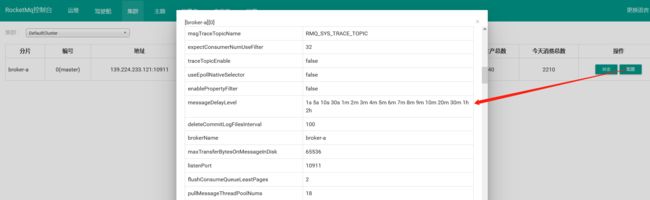
批量消息
批量消息是指将多条消息合并成一个批量消息,一次发送出去。这样的好处是可以减少网络IO,提升吞吐量。
批量消息的消息生产者样例见:
org.apache.rocketmq.example.batch.SimpleBatchProducer
package org.apache.rocketmq.example.batch;
import org.apache.rocketmq.client.producer.DefaultMQProducer;
import org.apache.rocketmq.common.message.Message;
import java.util.ArrayList;
import java.util.List;
public class SimpleBatchProducer {
public static void main(String[] args) throws Exception {
DefaultMQProducer producer = new DefaultMQProducer("BatchProducerGroupName");
producer.setNamesrvAddr("ip:9876");
producer.start();
//If you just send messages of no more than 1MiB at a time, it is easy to use batch
//Messages of the same batch should have: same topic, same waitStoreMsgOK and no schedule support
String topic = "BatchTest";
List<Message> messages = new ArrayList<>();
messages.add(new Message(topic, "Tag", "OrderID001", "Hello world 0".getBytes()));
messages.add(new Message(topic, "Tag", "OrderID002", "Hello world 1".getBytes()));
messages.add(new Message(topic, "Tag", "OrderID003", "Hello world 2".getBytes()));
//把三个消息当成一个消息发送出去
producer.send(messages);
producer.shutdown();
}
}
org.apache.rocketmq.example.batch.SplitBatchProducer
package org.apache.rocketmq.example.batch;
import org.apache.rocketmq.client.producer.DefaultMQProducer;
import org.apache.rocketmq.common.message.Message;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
public class SplitBatchProducer {
public static void main(String[] args) throws Exception {
DefaultMQProducer producer = new DefaultMQProducer("BatchProducerGroupName");
producer.start();
String topic = "BatchTest";
//这里一次发送十万条消息,rocketmq肯定接受不了
List<Message> messages = new ArrayList<>(100 * 1000);
for (int i = 0; i < 100 * 1000; i++) {
messages.add(new Message(topic, "Tag", "OrderID" + i, ("Hello world " + i).getBytes()));
}
//案例1:一次发送十万条消息,直接报错
//producer.send(messages);
//案例2:将十万条消息拆分,最大不能超过4M
ListSplitter splitter = new ListSplitter(messages);
while (splitter.hasNext()) {
List<Message> listItem = splitter.next();
producer.send(listItem);
}
producer.shutdown();
}
}
class ListSplitter implements Iterator<List<Message>> {
private int sizeLimit = 1000 * 1000;
private final List<Message> messages;
private int currIndex;
public ListSplitter(List<Message> messages) {
this.messages = messages;
}
@Override
public boolean hasNext() {
return currIndex < messages.size();
}
@Override
public List<Message> next() {
int nextIndex = currIndex;
int totalSize = 0;
for (; nextIndex < messages.size(); nextIndex++) {
Message message = messages.get(nextIndex);
int tmpSize = message.getTopic().length() + message.getBody().length;
Map<String, String> properties = message.getProperties();
for (Map.Entry<String, String> entry : properties.entrySet()) {
tmpSize += entry.getKey().length() + entry.getValue().length();
}
tmpSize = tmpSize + 20; //for log overhead
if (tmpSize > sizeLimit) {
//it is unexpected that single message exceeds the sizeLimit
//here just let it go, otherwise it will block the splitting process
if (nextIndex - currIndex == 0) {
//if the next sublist has no element, add this one and then break, otherwise just break
nextIndex++;
}
break;
}
if (tmpSize + totalSize > sizeLimit) {
break;
} else {
totalSize += tmpSize;
}
}
List<Message> subList = messages.subList(currIndex, nextIndex);
currIndex = nextIndex;
return subList;
}
@Override
public void remove() {
throw new UnsupportedOperationException("Not allowed to remove");
}
}
相信大家在官网以及测试代码中都看到了关键的注释:如果批量消息大于1MB就不要用一个批次发送,而要拆分成多个批次消息发送。也就是说,一个批次消息的大小不要超过1MB
实际使用时,这个1MB的限制可以稍微扩大点,实际最大的限制是4194304字节,大概4MB。但是使用批量消息时,这个消息长度确实是必须考虑的一个问题。而且批量消息的使用是有一定限制的,这些消息应该有相同的Topic,相同的waitStoreMsgOK。而且不能是延迟消息、事务消息等。
过滤消息
在大多数情况下,可以使用Message的Tag属性来简单快速的过滤信息。
使用Tag过滤消息的消息生产者案例见:org.apache.rocketmq.example.filter.TagFilterProducer
package org.apache.rocketmq.example.filter;
import org.apache.rocketmq.client.producer.DefaultMQProducer;
import org.apache.rocketmq.client.producer.SendResult;
import org.apache.rocketmq.common.message.Message;
import org.apache.rocketmq.remoting.common.RemotingHelper;
public class TagFilterProducer {
public static void main(String[] args) throws Exception {
DefaultMQProducer producer = new DefaultMQProducer("please_rename_unique_group_name");
producer.setNamesrvAddr("ip:9876");
producer.start();
//我们这里有三个tag,后续的消费,可以消费其中一部分的tag消息
String[] tags = new String[] {"TagA", "TagB", "TagC"};
for (int i = 0; i < 15; i++) {
Message msg = new Message("TagFilterTest",
tags[i % tags.length],
"Hello world".getBytes(RemotingHelper.DEFAULT_CHARSET));
SendResult sendResult = producer.send(msg);
System.out.printf("%s%n", sendResult);
}
producer.shutdown();
}
}
使用Tag过滤消息的消息消费者案例见:org.apache.rocketmq.example.filter.TagFilterConsumer
package org.apache.rocketmq.example.filter;
import org.apache.rocketmq.client.consumer.DefaultMQPushConsumer;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyContext;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyStatus;
import org.apache.rocketmq.client.consumer.listener.MessageListenerConcurrently;
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.common.message.MessageExt;
import java.io.IOException;
import java.util.List;
public class TagFilterConsumer {
public static void main(String[] args) throws InterruptedException, MQClientException, IOException {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("please_rename_unique_group_name");
consumer.setNamesrvAddr("ip:9876");
//这里我们只消费taga或者tagc的消息,borker也只会推送taga或者tagc的消息,这样就可以减少网络io
consumer.subscribe("TagFilterTest", "TagA || TagC");
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
consumer.start();
System.out.printf("Consumer Started.%n");
}
}
主要是看消息消费者。consumer.subscribe(“TagFilterTest”, “TagA || TagC”); 这句只订阅TagA和TagC的消息。
TAG是RocketMQ中特有的一个消息属性。RocketMQ的最佳实践中就建议,使用RocketMQ时,一个应用可以就用一个Topic,而应用中的不同业务就用TAG来区分。
但是,这种方式有一个很大的限制,就是一个消息只能有一个TAG,这在一些比较复杂的场景就有点不足了。 这时候,可以使用SQL表达式来对消息进行过滤。
SQL过滤的消息生产者案例见:org.apache.rocketmq.example.filter.SqlFilterProducer
package org.apache.rocketmq.example.filter;
import org.apache.rocketmq.client.producer.DefaultMQProducer;
import org.apache.rocketmq.client.producer.SendResult;
import org.apache.rocketmq.common.message.Message;
import org.apache.rocketmq.remoting.common.RemotingHelper;
public class SqlFilterProducer {
public static void main(String[] args) throws Exception {
DefaultMQProducer producer = new DefaultMQProducer("please_rename_unique_group_name");
producer.setNamesrvAddr("ip:9876");
producer.start();
String[] tags = new String[] {"TagA", "TagB", "TagC"};
for (int i = 0; i < 15; i++) {
Message msg = new Message("SqlFilterTest",
tags[i % tags.length],
("Hello RocketMQ " + i).getBytes(RemotingHelper.DEFAULT_CHARSET)
);
msg.putUserProperty("a", String.valueOf(i));
SendResult sendResult = producer.send(msg);
System.out.printf("%s%n", sendResult);
}
producer.shutdown();
}
}
SQL过滤的消息消费者案例见:org.apache.rocketmq.example.filter.SqlFilterConsumer
package org.apache.rocketmq.example.filter;
import org.apache.rocketmq.client.consumer.DefaultMQPushConsumer;
import org.apache.rocketmq.client.consumer.MessageSelector;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyContext;
import org.apache.rocketmq.client.consumer.listener.ConsumeConcurrentlyStatus;
import org.apache.rocketmq.client.consumer.listener.MessageListenerConcurrently;
import org.apache.rocketmq.common.message.MessageExt;
import java.util.List;
public class SqlFilterConsumer {
public static void main(String[] args) throws Exception {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("please_rename_unique_group_name");
// Don't forget to set enablePropertyFilter=true in broker
//tags在a或者b之间,a这个值不能为空,并且在0~3之间
consumer.subscribe("SqlFilterTest",
MessageSelector.bySql("(TAGS is not null and TAGS in ('TagA', 'TagB'))" +
"and (a is not null and a between 0 and 3)"));
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
consumer.start();
System.out.printf("Consumer Started.%n");
}
}
这个模式的关键是在消费者端使用MessageSelector.bySql(String sql)返回的一个MessageSelector。这里面的sql语句是按照SQL92标准来执行的。sql中可以使用的参数有默认的TAGS和一个在生产者中加入的a属性。
SQL92语法:
RocketMQ只定义了一些基本语法来支持这个特性。你也可以很容易地扩展它。
数值比较,比如:>,>=,<,<=,BETWEEN,=;
字符比较,比如:=,<>,IN;
IS NULL 或者 IS NOT NULL;
逻辑符号 AND,OR,NOT;常量支持类型为:
数值,比如:123,3.1415;
字符,比如:‘abc’,必须用单引号包裹起来;
NULL,特殊的常量
布尔值,TRUE 或 FALSE使用注意:只有推模式的消费者可以使用SQL过滤。拉模式是用不了的。
大家想一下,这个消息过滤是在Broker端进行的还是在Consumer端进行的?
在Broker端进行消息过滤,可以减少无效消息发送到_Consumer_,少占用网络带宽从而提高吞吐量
事务消息
官网的介绍是:事务消息是在分布式系统中保证最终一致性的两阶段提交的消息实现。他可以保证本地事务执行与消息发送两个操作的原子性,也就是这两个操作一起成功或者一起失败。
其次,我们来理解下事务消息的编程模型。事务消息只保证消息发送者的本地事务与发消息这两个操作的原子性,因此,事务消息的示例只涉及到消息发送者,对于消息消费者来说,并没有什么特别的。
事务消息生产者的案例见:org.apache.rocketmq.example.transaction.TransactionProducer
package org.apache.rocketmq.example.transaction;
import org.apache.rocketmq.client.exception.MQClientException;
import org.apache.rocketmq.client.producer.SendResult;
import org.apache.rocketmq.client.producer.TransactionListener;
import org.apache.rocketmq.client.producer.TransactionMQProducer;
import org.apache.rocketmq.common.message.Message;
import org.apache.rocketmq.remoting.common.RemotingHelper;
import java.io.UnsupportedEncodingException;
import java.util.concurrent.*;
public class TransactionProducer {
public static void main(String[] args) throws MQClientException, InterruptedException {
TransactionListener transactionListener = new TransactionListenerImpl();
TransactionMQProducer producer = new TransactionMQProducer("Transaction_1");
producer.setNamesrvAddr("ip:9876");
ExecutorService executorService = new ThreadPoolExecutor(2, 5, 100, TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(2000), new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r);
thread.setName("client-transaction-msg-check-thread");
return thread;
}
});
producer.setExecutorService(executorService);
producer.setTransactionListener(transactionListener);
producer.start();
String[] tags = new String[] {"TagA", "TagB", "TagC", "TagD", "TagE"};
for (int i = 0; i < 10; i++) {
try {
Message msg =
new Message("TopicTest", tags[i % tags.length], "KEY" + i,
("Hello RocketMQ " + i).getBytes(RemotingHelper.DEFAULT_CHARSET));
SendResult sendResult = producer.sendMessageInTransaction(msg, null);
System.out.printf("%s%n", sendResult);
Thread.sleep(10);
} catch (MQClientException | UnsupportedEncodingException e) {
e.printStackTrace();
}
}
for (int i = 0; i < 100000; i++) {
Thread.sleep(1000);
}
producer.shutdown();
}
}
事务消息的关键是在TransactionMQProducer中指定了一个TransactionListener事务监听器,这个事务监听器就是事务消息的关键控制器。源码中的案例有点复杂,我这里准备了一个更清晰明了的事务监听器示例。
public class TransactionListenerImpl implements TransactionListener {
//在提交完事务消息后执行。
//返回COMMIT_MESSAGE状态的消息会立即被消费者消费到。
//返回ROLLBACK_MESSAGE状态的消息会被丢弃。
//返回UNKNOWN状态的消息会由Broker过一段时间再来回查事务的状态。
@Override
public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
String tags = msg.getTags();
//TagA的消息会立即被消费者消费到
if(StringUtils.contains(tags,"TagA")){
return LocalTransactionState.COMMIT_MESSAGE;
//TagB的消息会被丢弃
}else if(StringUtils.contains(tags,"TagB")){
return LocalTransactionState.ROLLBACK_MESSAGE;
//其他消息会等待Broker进行事务状态回查。
}else{
return LocalTransactionState.UNKNOW;
}
}
//在对UNKNOWN状态的消息进行状态回查时执行。返回的结果是一样的。
@Override
public LocalTransactionState checkLocalTransaction(MessageExt msg) {
String tags = msg.getTags();
//TagC的消息过一段时间会被消费者消费到
if(StringUtils.contains(tags,"TagC")){
return LocalTransactionState.COMMIT_MESSAGE;
//TagD的消息也会在状态回查时被丢弃掉
}else if(StringUtils.contains(tags,"TagD")){
return LocalTransactionState.ROLLBACK_MESSAGE;
//剩下TagE的消息会在多次状态回查后最终丢弃
}else{
return LocalTransactionState.UNKNOW;
}
}
}
然后,我们要了解下事务消息的使用限制:
1、事务消息不支持延迟消息和批量消息。
2、为了避免单个消息被检查太多次而导致半队列消息累积,我们默认将单个消息的检查次数限制为 15 次,但是用户可以通过 Broker 配置文件的 transactionCheckMax参数来修改此限制。如果已经检查某条消息超过 N 次的话( N = transactionCheckMax ) 则 Broker 将丢弃此消息,并在默认情况下同时打印错误日志。用户可以通过重写 AbstractTransactionCheckListener 类来修改这个行为。
回查次数是由BrokerConfig.transactionCheckMax这个参数来配置的,默认15次,可以在broker.conf中覆盖。 然后实际的检查次数会在message中保存一个用户属性MessageConst.PROPERTY_TRANSACTION_CHECK_TIMES。这个属性值大于transactionCheckMax,就会丢弃。 这个用户属性值会按回查次数递增,也可以在Producer中自行覆盖这个属性。
3、事务消息将在 Broker 配置文件中的参数 transactionMsgTimeout 这样的特定时间长度之后被检查。当发送事务消息时,用户还可以通过设置用户属性 CHECK_IMMUNITY_TIME_IN_SECONDS 来改变这个限制,该参数优先于 transactionMsgTimeout 参数。
由BrokerConfig.transactionTimeOut这个参数来配置。默认6秒,可以在broker.conf中进行修改。 另外,也可以给消息配置一个MessageConst.PROPERTY_CHECK_IMMUNITY_TIME_IN_SECONDS属性来给消息指定一个特定的消息回查时间。 msg.putUserProperty(MessageConst.PROPERTY_CHECK_IMMUNITY_TIME_IN_SECONDS, “10000”); 这样就是10秒。
4、事务性消息可能不止一次被检查或消费。
5、提交给用户的目标主题消息可能会失败,目前这依日志的记录而定。它的高可用性通过 RocketMQ 本身的高可用性机制来保证,如果希望确保事务消息不丢失、并且事务完整性得到保证,建议使用同步的双重写入机制。
6、事务消息的生产者 ID 不能与其他类型消息的生产者 ID 共享。与其他类型的消息不同,事务消息允许反向查询、MQ服务器能通过它们的生产者 ID 查询到消费者。
接下来,我们还要了解下事务消息的实现机制,参见下图:

事务消息机制的关键是在发送消息时,会将消息转为一个half半消息,并存入RocketMQ内部的一个 RMQ_SYS_TRANS_HALF_TOPIC 这个Topic,这样对消费者是不可见的。再经过一系列事务检查通过后,再将消息转存到目标Topic,这样对消费者就可见了。
最后,我们还需要思考下事务消息的作用。
大家想一下这个事务消息跟分布式事务有什么关系?为什么扯到了分布式事务相关的两阶段提交上了?事务消息只保证了发送者本地事务和发送消息这两个操作的原子性,但是并不保证消费者本地事务的原子性,所以,事务消息只保证了分布式事务的一半。但是即使这样,对于复杂的分布式事务,RocketMQ提供的事务消息也是目前业内最佳的降级方案。
ACL权限控制
权限控制(ACL)主要为RocketMQ提供Topic资源级别的用户访问控制。用户在使用RocketMQ权限控制时,可以在Client客户端通过 RPCHook注入AccessKey和SecretKey签名;同时,将对应的权限控制属性(包括Topic访问权限、IP白名单和AccessKey和SecretKey签名等)设置在$ROCKETMQ_HOME/conf/plain_acl.yml的配置文件中。Broker端对AccessKey所拥有的权限进行校验,校验不过,抛出异常; ACL客户端可以参考:org.apache.rocketmq.example.simple包下面的AclClient代码。
注意,如果要在自己的客户端中使用RocketMQ的ACL功能,还需要引入一个单独的依赖包。
org.apache.rocketmq
rocketmq-acl
4.7.1
而Broker端具体的配置信息可以参见源码包下docs/cn/acl/user_guide.md。主要是在broker.conf中打开acl的标志:aclEnable=true。然后就可以用plain_acl.yml来进行权限配置了。并且这个配置文件是热加载的,也就是说要修改配置时,只要修改配置文件就可以了,不用重启Broker服务。我们来简单分析下源码中的plan_acl.yml的配置:
#全局白名单,不受ACL控制
#通常需要将主从架构中的所有节点加进来
globalWhiteRemoteAddresses:
- 10.10.103.*
- 192.168.0.*
accounts:
#第一个账户
- accessKey: RocketMQ
secretKey: 123456789
whiteRemoteAddress:
admin: false
defaultTopicPerm: DENY #默认Topic访问策略是拒绝
defaultGroupPerm: SUB #默认Group访问策略是只允许订阅
topicPerms:
- topicA=DENY #topicA拒绝
- topicB=PUB|SUB #topicB允许发布和订阅消息
- topicC=SUB #topicC只允许订阅
groupPerms:
# the group should convert to retry topic
- groupA=DENY
- groupB=PUB|SUB
- groupC=SUB
#第二个账户,只要是来自192.168.2.*的IP,就可以访问所有资源
- accessKey: rocketmq2
secretKey: 123456789
whiteRemoteAddress: 192.168.2.*
# if it is admin, it could access all resources
admin: true
消息存储机制
RocketMQ中的消息存储在本地文件系统中,主要是由ConsumeQueue和CommitLog配合完成的,消息真正的物理存储文件是CommitLog,ConsumeQueue是消息的逻辑队列,类似数据库的索引文件,存储的是指向物理存储的地址。每个Topic下的每个Message Queue都有一个对应的ConsumeQueue文件。
CommitLog文件
CommitLog是消息主体以及元数据的存储主体,存储Producer端写入的消息主体内容,消息内容不是定长的。单个文件大小默认1G, 文件名长度为20位,左边补零,剩余为起始偏移量,比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1073741824;当第一个文件写满了,第二个文件为00000000001073741824,起始偏移量为1073741824,以此类推。消息主要是顺序写入日志文件,当文件满了,写入下一个文件。

需要注意的是,一个Broker中仅包含一个commitlog目录,所有的mappedFile文件都是存放在该目录中 的。即无论当前Broker中存放着多少Topic的消息,这些消息都是被顺序写入到了mappedFile文件中。
RocketMQ利用“零拷贝”技术,提高消息存盘和网络发送的速度。这里需要注意的是,采用MappedByteBuffer这种内存映射的方式有几个限制,其中之一是一次只能映射1.5~2G 的文件至用户态的虚拟内存,这也是为何RocketMQ默认设置单个CommitLog日志数据文件为1G的原因。
ConsumerQueue消费逻辑队列
ConsumerQueue是消息消费队列,引入的目的主要是提高消息消费的性能,由于RocketMQ是基于主题topic的订阅模式,消息消费是针对主题进行的,如果要遍历commitlog文件中根据topic检索消息是非常低效的。Consumer即可根据ConsumeQueue来查找待消费的消息。其中,ConsumeQueue(逻辑消费队列)作为消费消息的索引,保存了指定Topic下的队列消息在CommitLog中的起始物理偏移量offset,消息大小size和消息Tag的HashCode值。consumequeue文件可以看成是基于topic的commitlog索引文件,故consumequeue文件夹的组织方式如下:topic/queue/file三层组织结构:
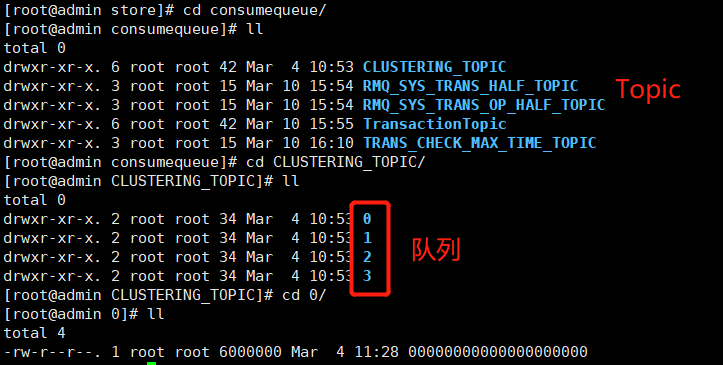
可以看到一个consumequeue中的索引条目结构为:
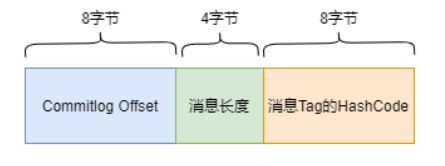
同样consumequeue文件采取定长设计,单个consumequeue文件由30W个索引条目组成。每一个索引条目包含了三个重要属性:消息在commitlog中的偏移量(8字节)、消息长度(4字节)、消息Tag的hashcode值(8字节)。可以像数组一样随机访问每一个索引条目,每个索引条目这三个属性占20个字节,所以每个ConsumeQueue文件的大小是固定的30w * 20字节,约5.72M。
IndexFile索引文件
除了通过通常的指定Topic进行消息消费外,RocketMQ还提供了根据key进行消息查询的功能。该查询是通过store目录中的index子目录中的indexFile进行索引实现的快速查询。当然,这个indexFile中的索引数据是在包含了key的消息被发送到Broker时写入的。如果消息中没有包含key,则不会写入。

RocketMQ的索引文件逻辑结构,类似JDK中HashMap的实现。
每个Broker中会包含一组indexFile,每个indexFile都是以一个时间戳命名的(这个indexFile被创建时的时间戳),文件大小是固定的。如果消息的properties中设置了UNIQ_KEY这个属性,就用 topic + “#” + UNIQ_KEY的value作为 key 来做写入操作。如果消息设置了KEYS属性(多个KEY以空格分隔),也会用 topic + “#” + KEY 来做索引。
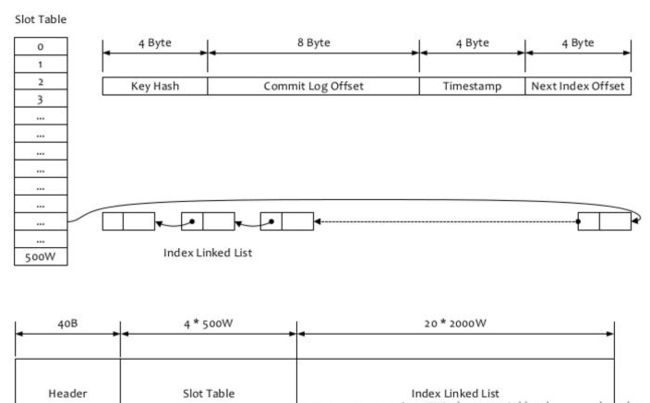
其中的索引数据包含了Key Hash、CommitLog Offset、Timestamp、NextIndex offset 这四个字段,一共20 字节。NextIndex offset 即前面读出来的slotValue,如果有 hash冲突,就可以用这个字段将所有冲突的索引用链表的方式串起来了。Timestamp记录的是消息storeTimestamp之间的差,并不是一个绝对的时间。整个Index File的结构如图,40 Byte 的Header用于保存一些总的统计信息,4500W的 Slot Table并不保存真正的索引数据,而是保存每个槽位对应的单向链表的头。202000W 是真正的索引数据,即一个 Index File 可以保存 2000W个索引。
页缓存与内存映射
页缓存(PageCache)是OS对文件的缓存,用于加速对文件的读写。一般来说,程序对文件进行顺序读写的速度几乎接近于内存的读写速度,主要原因就是由于OS使用PageCache机制对读写访问操作进行了性能优化,将一部分的内存用作PageCache。对于数据的写入,OS会先写入至Cache内,随后通过异步的方式由pdflush内核线程将Cache内的数据刷盘至物理磁盘上。对于数据的读取,如果一次读取文件时出现未命中PageCache的情况,OS从物理磁盘上访问读取文件的同时,会顺序对其他相邻块的数据文件进行预读取。
在RocketMQ中,ConsumeQueue逻辑消费队列存储的数据较少,并且是顺序读取,在page cache机制的预读取作用下,Consume Queue文件的读性能几乎接近读内存,即使在有消息堆积情况下也不会影响性能。而对于CommitLog消息存储的日志数据文件来说,读取CommitLog消息内容时候会产生较多的随机访问读取,严重影响性能。如果选择合适的系统IO调度算法,比如设置调度算法为“Deadline”(此时块存储采用SSD的话),随机读的性能也会有所提升。
另外,RocketMQ主要通过MappedByteBuffer(零拷贝)对文件进行读写操作。其中,利用了NIO中的FileChannel模型将磁盘上的物理文件直接映射到用户态的内存地址中(这种Mmap的方式减少了传统IO将磁盘文件数据在操作系统内核地址空间的缓冲区和用户应用程序地址空间的缓冲区之间来回进行拷贝的性能开销),将对文件的操作转化为直接对内存地址进行操作,从而极大地提高了文件的读写效率(正因为需要使用内存映射机制,故RocketMQ的文件存储都使用定长结构来存储,方便一次将整个文件映射至内存)。
Kafka相关知识点
消费模式
单播消费
一条消息只能被某一个消费者消费的模式,类似queue模式,只需让所有消费者在同一个消费组里即可。
分别在两个客户端执行如下消费命令,然后往主题里发送消息,结果只有一个客户端能收到消息。
多播消费
一条消息能被多个消费者消费的模式,类似publish-subscribe模式费,针对Kafka同一条消息只能被同一个消费组下的某一个消费者消费的特性,要实现多播只要保证这些消费者属于不同的消费组即可。我们再增加一个消费者,该消费者属于testGroup-2消费组,结果两个客户端都能收到消息。
主题/分区/日志的概念
主题
Topic是一个类别的名称,同类消息发送到同一个Topic下面。对于每一个Topic,下面可以有多个分区(Partition)日志文件。Topic是一个逻辑概念,真正落实的数据都在分区上面,一般每个主题至少有一个分区。这样可以通过多个分区,放在在不同的服务器上面去,达到分布式存储的功能,海量数据通过分区存储,切片存储解决单台机器无法存储海量数据的问题。
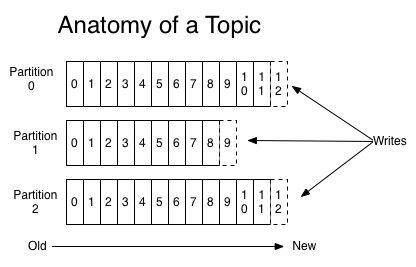
分区
分区是一个有序的消息序列,这些消息按顺序添加到一个叫做commit log的文件中。每个分区中的消息都有一个唯一的编号,称之为offset,用来唯一标示某个分区中的消息。 每个分区,都对应一个commit log文件。一个分区中的消息的offset都是唯一的,但是不同的分区中的消息的offset可能是相同的。
日志
kafka一般不会删除消息,不管这些消息有没有被消费。只会根据配置的日志保留时间(log.retention.hours)确认消息多久被删除,默认保留最近一周的日志消息。kafka的性能与保留的消息数据量大小没有关系,因此保存大量的数据消息日志信息不会有什么影响。
每个消费者是基于自己在commit log中的消费进度(offset)来进行工作的。在kafka中,消费offset由消费者自己来维护;一般情况下我们按照顺序逐条消费commit log中的消息,当然我可以通过指定offset来重复消费某些消息,或者跳过某些消息。这意味kafka中的消费者对集群的影响是非常小的,添加一个或者减少一个消费者,对于集群或者其他消费者来说,都是没有影响的,因为每个消费者维护各自的消费offset。
Kafka核心总控制器Controller
在Kafka集群中会有一个或者多个broker,其中有一个broker会被选举为控制器(Kafka Controller),它负责管理整个集群中所有分区和副本的状态。
- 当某个分区的leader副本出现故障时,由控制器负责为该分区选举新的leader副本。
- 当检测到某个分区的ISR集合发生变化时,由控制器负责通知所有broker更新其元数据信息。
- 当使用kafka-topics.sh脚本为某个topic增加分区数量时,同样还是由控制器负责让新分区被其他节点感知到。
Controller选举机制
在kafka集群启动的时候,会自动选举一台broker作为总控制器来管理整个集群,选举的过程是集群中每个broker都会尝试在zookeeper上创建一个/controller临时节点,zookeeper会保证只有一个broker能创建成功,这个broker就会成为集群的总控制器。当这个总控制器角色的broker宕机了,此时zookeeper临时节点会消失,集群里其他broker会一直监听这个临时节点,发现临时节点消失了,就竞争再次创建临时节点,就是我们上面说的选举机制,zookeeper又会保证有一个broker成为新的controller。
具备控制器身份的broker需要比其他普通的broker多一份职责,具体细节如下:
- 监听broker相关的变化。为Zookeeper中的/brokers/ids/节点添加BrokerChangeListener,用来处理broker增减的变化。
- 监听topic相关的变化。为Zookeeper中的/brokers/topics节点添加TopicChangeListener,用来处理topic增减的变化;为Zookeeper中的/admin/delete_topics节点添加TopicDeletionListener,用来处理删除topic的动作。
- 从Zookeeper中读取获取当前所有与topic、partition以及broker有关的信息并进行相应的管理。对于所有topic所对应的Zookeeper中的/brokers/topics/[topic]节点添加PartitionModificationsListener,用来监听topic中的分区分配变化。
- 更新集群的元数据信息,同步到其他普通的broker节点中。
Partition副本选举Leader机制
控制器感知到分区leader所在的broker挂了(控制器监听了很多zk节点可以感知到broker存活),控制器会从ISR列表(参数unclean.leader.election.enable=false的前提下)里挑第一个broker作为leader(第一个broker最先放进ISR列表,可能是同步数据最多的副本),如果参数unclean.leader.election.enable为true,代表在ISR列表里所有副本都挂了的时候可以在ISR列表以外的副本中选leader,这种设置,可以提高可用性,但是选出的新leader有可能数据少很多。
副本进入ISR列表有两个条件:
- 副本节点不能产生分区,必须能与zookeeper保持会话以及跟leader副本网络连通
- 副本能复制leader上的所有写操作,并且不能落后太多。(与leader副本同步滞后的副本,是由replica.lag.time.max.ms 配置决定的,超过这个时间都没有跟leader同步过的一次的副本会被移出ISR列表)
消费者消费消息的offset记录机制
每个消费者会定期将自己消费分区的offset提交给kafka内部topic:consumer_offsets,提交过去的时候,key是consumerGroupId+topic+分区号,value就是当前offset的值,kafka会定期清理topic里的消息,最后就保留最新的那条数据因为consumer_offsets可能会接收高并发的请求,kafka默认给其分配50个分区(可以通过offsets.topic.num.partitions设置),这样可以通过加机器的方式抗大并发。通过如下公式可以选出consumer消费的offset要提交到**consumer_offsets的哪个分区,公式:hash(consumerGroupId) % **consumer_offsets主题的分区数
消费者Rebalance机制
rebalance就是说如果消费组里的消费者数量有变化或消费的分区数有变化,kafka会重新分配消费者消费分区的关系。比如consumer
group中某个消费者挂了,此时会自动把分配给他的分区交给其他的消费者,如果他又重启了,那么又会把一些分区重新交还给他。
注意:rebalance只针对subscribe这种不指定分区消费的情况,如果通过assign这种消费方式指定了分区,kafka不会进行rebanlance。
如下情况可能会触发消费者rebalance:
- 消费组里的consumer增加或减少了。
- 动态给topic增加了分区
- 消费组订阅了更多的topic。
rebalance过程中,消费者无法从kafka消费消息,这对kafka的TPS会有影响,如果kafka集群内节点较多,比如数百个,那重平衡可能会耗时极多,所以应尽量避免在系统高峰期的重平衡发生。
消费者Rebalance分区分配策略
主要有三种rebalance的策略:range、round-robin、sticky。
Kafka 提供了消费者客户端参数partition.assignment.strategy 来设置消费者与订阅主题之间的分区分配策略。默认情况为range分配策略。
假设一个主题有10个分区(0-9),现在有三个consumer消费:
range策略就是按照分区序号排序,假设 n=分区数/消费者数量 = 3, m=分区数%消费者数量 = 1,那么前 m 个消费者每个分配 n+1 个分区,后面的(消费者数量-m )个消费者每个分配 n 个分区。
比如分区03给一个consumer,分区46给一个consumer,分区7~9给一个consumer。
round-robin策略就是轮询分配,比如分区0、3、6、9给一个consumer,分区1、4、7给一个consumer,分区2、5、8给一个consumer
sticky策略初始时分配策略与round-robin类似,但是在rebalance的时候,需要保证如下两个原则。
1)分区的分配要尽可能均匀 。
2)分区的分配尽可能与上次分配的保持相同。
当两者发生冲突时,第一个目标优先于第二个目标 。这样可以最大程度维持原来的分区分配的策略。
比如对于第一种range情况的分配,如果第三个consumer挂了,那么重新用sticky策略分配的结果如下:
consumer1除了原有的0~3,会再分配一个7
consumer2除了原有的4~6,会再分配8和9
Rebalance过程
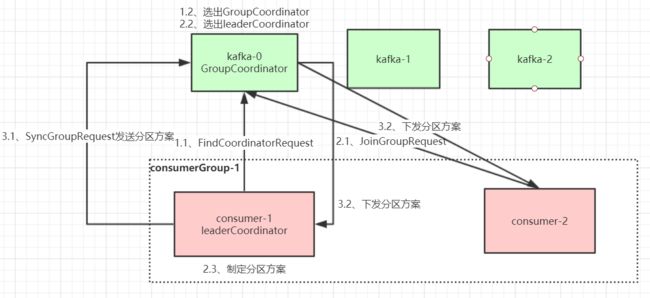
第一阶段:选择组协调器
组协调器GroupCoordinator
每个消费组都会选择一个broker作为自己的组协调器coordinator,负责监控这个消费组里的所有消费者的心跳,以及判断是否宕机,然后开启消费者rebalance。消费组中的每个消费者启动时会向kafka集群中的某个节点发送 FindCoordinatorRequest 请求来查找对应的组协调器GroupCoordinator,并跟其建立网络连接。
组协调器选择方式
消费者消费的offset要提交到__consumer_offsets的哪个分区,这个分区leader对应的broker就是这个消费组的coordinator
$#### 第二阶段:加入消费组JOIN GROUP
在成功找到消费组所对应的 GroupCoordinator 之后就进入加入消费组的阶段,在此阶段的消费者会向 GroupCoordinator 发送 JoinGroupRequest 请求,并处理响应。然后GroupCoordinator 从一个consumer group中选择第一个加入group的consumer作为leader(消费组协调器),把consumer group情况发送给这个leader,接着这个leader会负责制定分区方案。
第三阶段( SYNC GROUP)
consumer leader通过给GroupCoordinator发送SyncGroupRequest,接着GroupCoordinator就把分区方案下发给各个消费者,他们会根据指定分区的leader broker进行网络连接以及消息消费。
producer发布消息机制
写入方式
producer 采用 push 模式将消息发布到 broker,每条消息都被 append 到 patition 中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障 kafka 吞吐率)。
消息路由
producer 发送消息到 broker 时,会根据分区算法选择将其存储到哪一个 partition。其路由机制为:
- 指定了 patition,则直接使用;
- 未指定 patition 但指定 key,通过对 key 的 value 进行hash 选出一个 patition
- patition 和 key 都未指定,使用轮询选出一个 patition。
写入流程

- producer 先从 zookeeper 的 “/brokers/…/state” 节点找到该 partition 的 leader。
- producer 将消息发送给该 leader。
- leader 将消息写入本地 log。
- followers 从 leader pull 消息,写入本地 log 后 向leader 发送 ACK。
- leader 收到所有 ISR 中的 replica 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset) 并向 producer 发送 ACK。
HW与LEO
HW俗称高水位,HighWatermark的缩写,取一个partition对应的ISR中最小的LEO(log-end-offset)作为HW,consumer最多只能消费到HW所在的位置。另外每个replica都有HW,leader和follower各自负责更新自己的HW的状态。对于leader新写入的消息,consumer不能立刻消费,leader会等待该消息被所有ISR中的replicas同步后更新HW,此时消息才能被consumer消费。这样就保证了如果leader所在的broker失效,该消息仍然可以从新选举的leader中获取。对于来自内部broker的读取请求,没有HW的限制。
下图详细的说明了当producer生产消息至broker后,ISR以及HW和LEO的流转过程

由此可见,Kafka的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的follower都复制完,这条消息才会被commit,这种复制方式极大的影响了吞吐率。而异步复制方式下,follower异步的从leader复制数据,数据只要被leader写入log就被认为已经commit,这种情况下如果follower都还没有复制完,落后于leader时,突然leader宕机,则会丢失数据。而Kafka的这种使用ISR的方式则很好的均衡了确保数据不丢失以及吞吐率。再回顾下消息发送端对发出消息持久化机制参数acks的设置,我们结合HW和LEO来看下acks=1的情况。
结合HW和LEO看下 acks=1的情况
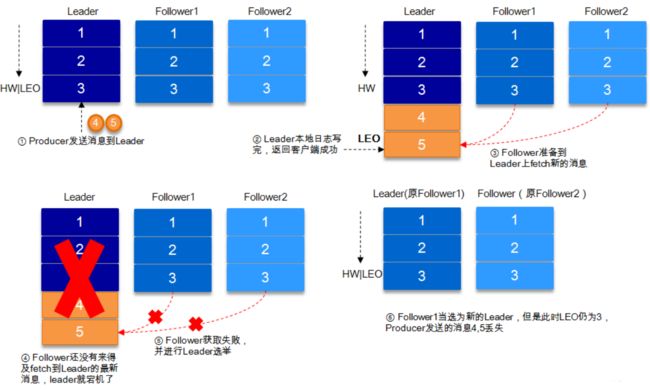
日志分段存储
Kafka 一个分区的消息数据对应存储在一个文件夹下,以topic名称+分区号命名,消息在分区内是分段(segment)存储,每个段的消息都存储在不一样的log文件里,这种特性方便oldsegment file快速被删除,kafka规定了一个段位的 log 文件最大为 1G,做这个限制目的是为了方便把 log文件加载到内存去操作。
# 部分消息的offset索引文件,kafka每次往分区发4K(可配置)消息就会记录一条当前消息的offset到index文件,
# 如果要定位消息的offset会先在这个文件里快速定位,再去log文件里找具体消息
00000000000000000000.index
# 消息存储文件,主要存offset和消息体
00000000000000000000.log
# 消息的发送时间索引文件,kafka每次往分区发4K(可配置)消息就会记录一条当前消息的发送时间戳与对应的offset到timeindex文件,
# 如果需要按照时间来定位消息的offset,会先在这个文件里查找
00000000000000000000.timeindex
00000000000005367851.index
00000000000005367851.log
00000000000005367851.timeindex
00000000000009936472.index
00000000000009936472.log
00000000000009936472.timeindex
这个 9936472 之类的数字,就是代表了这个日志段文件里包含的起始 Offset,也就说明这个分区里至少都写入了接近 1000万条数据了。Kafka Broker 有一个参数,log.segment.bytes,限定了每个日志段文件的大小,最大就是 1GB。一个日志段文件满了,就自动开一个新的日志段文件来写入,避免单个文件过大,影响文件的读写性能,这个过程叫做 log rolling,正在被写入的那个日志段文件,叫做 active log segment。
十亿消息数据线上环境规划

JVM参数设置
kafka是scala语言开发,运行在JVM上,需要对JVM参数合理设置,参看JVM调优专题
修改bin/kafka-start-server.sh中的jvm设置,假设机器是32G内存,可以如下设置:
export KAFKA_HEAP_OPTS="-Xmx16G -Xms16G -Xmn10G -XX:MetaspaceSize=256M
-XX:+UseG1GC -XX:MaxGCPauseMillis=50 -XX:G1HeapRegionSize=16M"
这种大内存的情况一般都要用G1垃圾收集器,因为年轻代内存比较大,用G1可以设置GC最大停顿时间,不至于一次minor gc就花费太长时间,当然,因为像kafka,rocketmq,es这些中间件,写数据到磁盘会用到操作系统的page cache,所以JVM内存不宜分配过大,需要给操作系统的缓存留出几个G。
Spring知识点
Spring Bean的生命周期
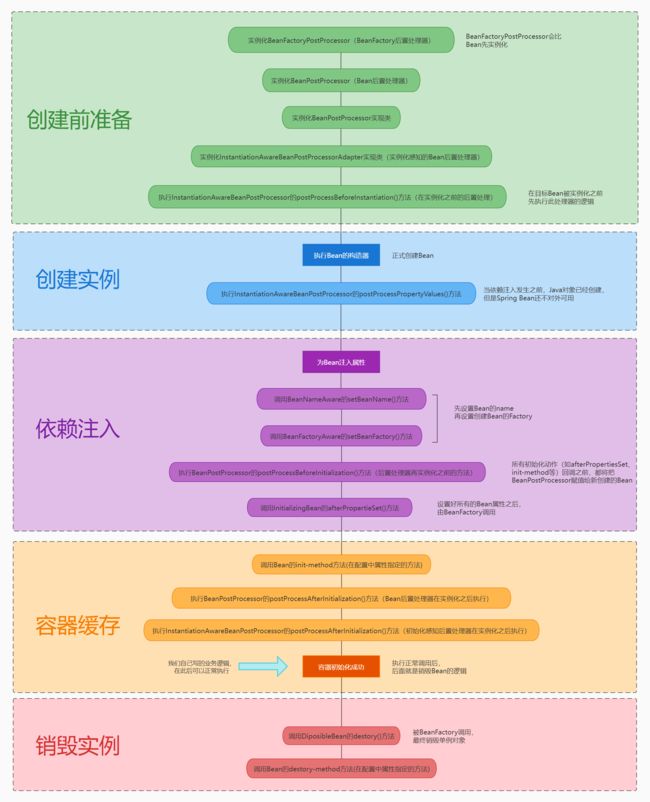 Spring Bean的生命周期管理的基本思路是:在Bean出现之前,先准备操作Bean的BeanFactory,然后操作完Bean,所有的Bean也还会交给BeanFactory进行管理。在所有Bean操作准备BeanPostProcessor作为回调。
Spring Bean的生命周期管理的基本思路是:在Bean出现之前,先准备操作Bean的BeanFactory,然后操作完Bean,所有的Bean也还会交给BeanFactory进行管理。在所有Bean操作准备BeanPostProcessor作为回调。
Bean创建前的准备阶段
步骤1: Bean容器在配置文件中找到Spring Bean的定义以及相关的配置,如init-method和destroy-method指定的方法。
步骤2: 实例化回调相关的后置处理器如BeanFactoryPostProcessor、BeanPostProcessor、InstantiationAwareBeanPostProcessor等
创建Bean的实例
步骤3: Srping 容器使用Java反射API创建Bean的实例。
步骤4:扫描Bean声明的属性并解析。
开始依赖注入
步骤5:开始依赖注入,解析所有需要赋值的属性并赋值。
步骤6:如果Bean类实现BeanNameAware接口,则将通过传递Bean的名称来调用setBeanName()方法。
步骤7:如果Bean类实现BeanFactoryAware接口,则将通过传递BeanFactory对象的实例来调用setBeanFactory()方法。
步骤8:如果有任何与BeanFactory关联的BeanPostProcessors对象已加载Bean,则将在设置Bean属性之前调用postProcessBeforeInitialization()方法。
步骤9:如果Bean类实现了InitializingBean接口,则在设置了配置文件中定义的所有Bean属性后,将调用afterPropertiesSet()方法。
缓存到Spring容器
步骤10: 如果配置文件中的Bean定义包含init-method属性,则该属性的值将解析为Bean类中的方法名称,并将调用该方法。
步骤11:如果为Bean Factory对象附加了任何Bean 后置处理器,则将调用postProcessAfterInitialization()方法。
销毁Bean的实例
步骤12:如果Bean类实现DisposableBean接口,则当Application不再需要Bean引用时,将调用destroy()方法。
步骤13:如果配置文件中的Bean定义包含destroy-method属性,那么将调用Bean类中的相应方法定义。
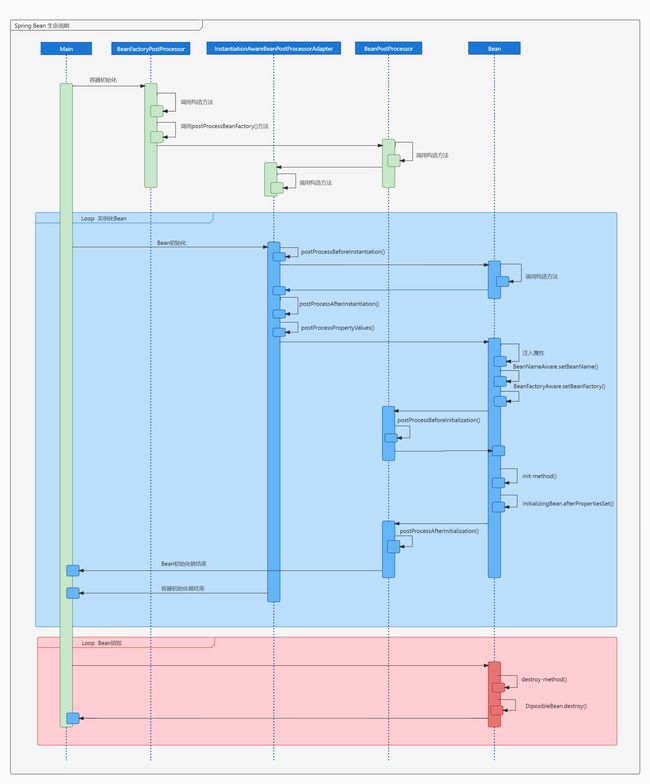 在一个Bean实例被初始化时,需要执行一系列初始化操作以使其达到可用的状态。同样,当一个Bean不再被调用时需要进行相关的析构操作,并从Bean容器中移除。
在一个Bean实例被初始化时,需要执行一系列初始化操作以使其达到可用的状态。同样,当一个Bean不再被调用时需要进行相关的析构操作,并从Bean容器中移除。
Spring Bean Factory 负责管理在Spring容器中被创建的Bean的生命周期。Bean的生命周期由两组回调方法组成。
(1)初始化之后调用的回调方法。
(2)销毁之前调用的回调方法。
Spring提供了以下4种方式来管理Bean的生命周期事件:
(1)InitializingBean和DisposableBean回调接口。
(2)针对特殊行为的其他Aware接口。
(3)Bean配置文件中的customInit()方法和customDestroy()方法。
(4)@PostConstruct和@PreDestroy注解方式。
使用customInit()和 customDestroy()方法管理Bean生命周期
想进一步了解代码实现的,这里分享一个地址:点击【java_wxid】进行查看。
Spring循环依赖
什么是循环依赖?

BeanA类依赖了BeanB类,BeanB类依赖了BeanC类,BeanC类依赖了BeanA类,形成了一个依赖闭环,我们把这种依赖关系就称之为循环依赖。
循环依赖会导致什么问题的出现?

 启动项目,我们发现只要是有循环依赖关系的属性并没有自动赋值,而没有循环依赖关系的属性均有自动赋值,如下图所示:
启动项目,我们发现只要是有循环依赖关系的属性并没有自动赋值,而没有循环依赖关系的属性均有自动赋值,如下图所示:

IoC容器对Bean的初始化是根据BeanDefinition循环迭代,有一定的顺序。这样,在执行依赖注入时,需要自动赋值的属性对应的对象有可能还没初始化,没有初始化也就没有对应的实例可以注入。
Spring是怎么解决循环依赖导致的问题的?
Spring使用三级缓存解决循环依赖的过程
- 一级缓存存放实例化对象 。
- 二级缓存存放已经在内存空间创建好但是还没有给属性赋值的对象。
- 三级缓存存放对象工厂,用来创建提前暴露到bean的对象。
代码举例:
@Service
public class TestService1 {
@Autowired
private TestService2 testService2;
public void test1() {
}
}
@Service
public class TestService2 {
@Autowired
private TestService1 testService1;
public void test2() {
}
}

testService1先去一级缓存看有没有实例,发现没有,继续去二级缓存查看,发现没有,去三级缓存查看,发现没有实例就创建实例,在创建的过程中,提前暴露,添加到三级缓存里。
这个时候进行属性赋值,发现还有一个testService2,它没有赋值,是一个空的,就从一级缓存中去看testSerivce2有没有实例,发现没有,去二级查看发现没有,去三级缓存查看,发现没有,就创建实例,也提前暴露,添加到三级缓存里面。
这个时候testSerivce2对象里面发现testService1里面没有赋值,然后对testService1进行赋值,从一级缓存去查看,发现没有,去二级查看,发现没有,去三级查看,发现有,就把实例testService1从三级缓存添加到二级缓存里面,把实例testService1三级缓存的实例删除,这个时候,testService2里面有实例对象,对象里面的testService1也有值了,就是一个可以使用的实例对象了,就把这个对象移动到一级缓存里面,把三级缓存里面的testService2删除。
这个时候testService1里面的testService2属性就可以从一级缓存里面获取这个testService2实例了,把它进行赋值填充,testService1也完成了实例化,把testService1从二级缓存移动到一级缓存里面,把testService1在二级缓存的实例也删除。

想进一步了解代码实现的,这里分享一个地址:点击【java_wxid】进行查看。
Spring容器启动执行流程
部署一个web应用在web容器中,它会提供一个全局的上下文环境,这个上下文就是ServletContext,它为后面的IoC容器提供宿主环境,当web容器启动的时候,会执行web.xml中的ContextLoaderListener监听器初始化contextInitialized方法,调用父类的initWebApplicationContext方法。
这个方法里面执行了三个任务:
1.创建WebApplicationContext容器
2.加载context-param中spring配置文件
3.初始化配置文件并且创建配置文件中的bean。
监听器初始化完毕后,开始初始化web.xml中配置的servlet ,用DispatcherServlet举例,它是一个前端控制器,用来转发、匹配、处理每个servlet 请求。
DispatcherServlet上下文在初始化的时候会建立自己的上下文,先从ServletContext 中获取之前的WebApplicationContext作为自己上下文的父类上下文,有了这个父类上下文之后,再初始化自己持有的上下文,创建springmvc相关的bean,初始化处理器映射、视图解析等等,初始化完后,spring把Servlet的相关的属性作为属性key,存到servletcontext中,方便后面使用。这样每个Servlet 都持有自己的上下文,拥有自己独立的bean 空间,各个servlet 共享相同的bean,也就是根上下文定义的那些bean。
web容器停止时候会执行ContextLoaderListener的contextDestroyed方法销毁context容器。
Spring事务底层实现原理
当在某个类或者方法上使用@Transactional注解后,spring会基于该类生成一个代理对象,并将这个代理对象作为bean。当调用这个代理对象的方法时,如果有事务处理,则会先关闭事务的自动功能,然后执行方法的具体业务逻辑,如果业务逻辑没有异常,那么代理逻辑就会直接提交,如果出现任何异常,那么直接进行回滚操作。当然我们也可以控制对哪些异常进行回滚操作。
一个Bean在执行Bean的创建生命周期时,会经过InfrastructureAdvisorAutoProxyCreator的初始化后的方法,会判断当前当前Bean对象是否和BeanFactoryTransactionAttributeSourceAdvisor匹配,匹配逻辑为判断该Bean的类上是否存在@Transactional注解,或者类中的某个方法上是否存在@Transactional注解,如果存在则表示该Bean需要进行动态代理产生一个代理对象作为Bean对象。
源码执行流程:
- 加了@Transactional注解的类,或者类中拥有@Transactional注解的方法,都会生成代理对象作为bean。
代理对象执行方法时。 - 获取当前正在执行的方法上的@Transactional注解的信息TransactionAttribute。
- 查看@Transactional注解上是否指定了TransactionManager,如果没有指定,则默认获取TransactionManager类型的bean作为TransactionManager。对于TransactionManager有一个限制,必须是PlatformTransactionManager。
- 生成一个joinpointIdentification,作为事务的名字。
- 开始创建事务。
- 创建事务成功后执行业务方法。
- 如果执行业务方法出现异常,则会进行回滚,然后执行完finally中的方法后再将异常抛出。
- 如果执行业务方法没有出现异常,那么则会执行完finally中的方法后再进行提交。
Spring IOC容器加载过程
spring ioc容器的加载,大体上经过以下几个过程:
资源文件定位、解析、注册、实例化
资源文件定位
资源文件定位,一般是在ApplicationContext的实现类里完成的,因为ApplicationContext接口继承ResourcePatternResolver 接口,ResourcePatternResolver接口继承ResourceLoader接口,ResourceLoader其中的getResource()方法,可以将外部的资源,读取为Resource类。
解析DefaultBeanDefinitionDocumentReader
解析主要是在BeanDefinitionReader中完成的,最常用的实现类是XmlBeanDefinitionReader,其中的loadBeanDefinitions()方法,负责读取Resource,并完成后续的步骤。ApplicationContext完成资源文件定位之后,是将解析工作委托给XmlBeanDefinitionReader来完成的
解析这里涉及到很多步骤,最常见的情况,资源文件来自一个XML配置文件。首先是BeanDefinitionReader,将XML文件读取成w3c的Document文档。
DefaultBeanDefinitionDocumentReader对Document进行进一步解析。然后DefaultBeanDefinitionDocumentReader又委托给BeanDefinitionParserDelegate进行解析。如果是标准的xml namespace元素,会在Delegate内部完成解析,如果是非标准的xml namespace元素,则会委托合适的NamespaceHandler进行解析最终解析的结果都封装为BeanDefinitionHolder,至此解析就算完成。
后续会进行细致讲解。
注册
然后bean的注册是在BeanFactory里完成的,BeanFactory接口最常见的一个实现类是DefaultListableBeanFactory,它实现了BeanDefinitionRegistry接口,所以其中的registerBeanDefinition()方法,可以对BeanDefinition进行注册这里附带一提,最常见的XmlWebApplicationContext不是自己持有BeanDefinition的,它继承自AbstractRefreshableApplicationContext,其持有一个DefaultListableBeanFactory的字段,就是用它来保存BeanDefinition。
所谓的注册,其实就是将BeanDefinition的name和实例,保存到一个Map中。刚才说到,最常用的实现DefaultListableBeanFactory,其中的字段就是beanDefinitionMap,是一个ConcurrentHashMap。
实例化
注册也完成之后,在BeanFactory的getBean()方法之中,会完成初始化,也就是依赖注入的过程。
想进一步了解代码实现的,这里分享一个地址:点击【java_wxid】进行查看。
SpringAOP实现原理
Spring的AOP的应用场景一般在日志记录、权限验证、事务管理等业务场景。
它是运行期进行织入,生成字节码,再加载到虚拟机中,JDK是利用反射原理,CGLIB使用了ASM原理。
初始化时会看目标类有没有实现InvocationHandler接口或者是Proxy类。
如果实现了接口,就使用JDK动态代理,通过反射来接收被代理的类。
如果没实现就利用cglib进行AOP动态代理,CGLIB是通过继承的方式做的动态代理,是一个代码生成的类库,可以在运行时动态的生成某个类的子类,将目标对象转变为代理对象对事务进行操作。
所以在初始化的时候,已经将目标对象进行代理,放入到spring 容器中。
想进一步了解代码实现的,这里分享一个地址:点击【java_wxid】进行查看。
Spring的自动装配
使用@Autowired注解自动装配指定的bean,在启动spring IoC时,容器自动加载了一个AutowiredAnnotationBeanPostProcessor后置处理器,当容器扫描到@Autowied的时候,就会在IoC容器自动查找需要的bean,并且注入对象的属性,使用@Autowired的时候,首先在容器中查询对应类型的bean,如果查询结果刚好为一个,就将这个bean装配给@Autowired指定的数据,如果查询的结果不止一个,那么@Autowired会根据名称来查找,如果上述查找的结果为空,那么会抛出异常,解决方法可以使用required=false。如果使用@Resource它默认是按照名称来装配注入的,只有当找不到与名称匹配的bean才会按照类型来装配注入。
在Spring中共有5种自动装配模式:
(1)no:这是Spring的默认设置,在该设置下自动装配是关闭的,开发者需要自行在Bean定义中用标签明确地设置依赖关系。
(2)byName:该模式可以根据Bean名称设置依赖关系。当向一个Bean中自动装配一个属性时,容器将根据Bean的名称自动在配置文件中查询一个匹配的Bean。如果找到就装配这个属性,如果没找到就报错。
(3)byType:该模式可以根据Bean类型设置依赖关系。当向一个Bean中自动装配一个属性时,容器将根据Bean的类型自动在配置文件中查询一个匹配的Bean。如果找到就装配这个属性,如果没找到就报错。
(4)constructor:和byType模式类似,但是仅适用于有与构造器相同参数类型的Bean,如果在容器中没有找到与构造器参数类型一致的Bean,那么将会抛出异常。
(5)autodetect:该模式自动探测使用constructor自动装配或者byType自动装配。首先会尝试找合适的带参数的构造器,如果找到就是用构造器自动装配,如果在Bean内部没有找到相应的构造器或者构造器是无参构造器,容器就会自动选择byType模式。
Spring Boot自动装配
Spring Boot启动的时候会通过@EnableAutoConfiguration注解找到META-INF/spring.factories配置文件中的所有自动配置类,并对其进行加载,而这些自动配置类都是以AutoConfiguration结尾来命名的,它实际上就是一个JavaConfig形式的Spring容器配置类,它能通过以Properties结尾命名的类中取得在全局配置文件中配置的属性如:server.port,而XxxxProperties类是通过@ConfigurationProperties注解与全局配置文件中对应的属性进行绑定的。
启动类的@SpringBootApplication注解由@SpringBootConfiguration,@EnableAutoConfiguration,@ComponentScan三个注解组成,三个注解共同完成自动装配;
- @SpringBootConfiguration 注解标记启动类为配置类
- @ComponentScan 注解实现启动时扫描启动类所在的包以及子包下所有标记为bean的类由IOC容器注册为bean
- @EnableAutoConfiguration通过 @Import 注解导入 AutoConfigurationImportSelector类,然后通过AutoConfigurationImportSelector 类的 selectImports 方法去读取需要被自动装配的组件依赖下的spring.factories文件配置的组件的类全名,并按照一定的规则过滤掉不符合要求的组件的类全名,将剩余读取到的各个组件的类全名集合返回给IOC容器并将这些组件注册为bean
Spring Boot启动过程
一、SpringBoot启动的时候,会构造一个SpringApplication的实例,构造SpringApplication的时候会进行初始化的工作,初始化的时候会做以下几件事:
1、把参数sources设置到SpringApplication属性中,这个sources可以是任何类型的参数.
2、判断是否是web程序,并设置到webEnvironment的boolean属性中.
3、创建并初始化ApplicationInitializer,设置到initializers属性中 。
4、创建并初始化ApplicationListener,设置到listeners属性中 。
5、初始化主类mainApplicatioClass。
二、SpringApplication构造完成之后调用run方法,启动SpringApplication,run方法执行的时候会做以下几件事:
1、构造一个StopWatch计时器,用来记录SpringBoot的启动时间 。
2、初始化监听器,获取SpringApplicationRunListeners并启动监听,用于监听run方法的执行。
3、创建并初始化ApplicationArguments,获取run方法传递的args参数。
4、创建并初始化ConfigurableEnvironment(环境配置)。封装main方法的参数,初始化参数,写入到 Environment中,发布 ApplicationEnvironmentPreparedEvent(环境事件),做一些绑定后返回Environment。
5、打印banner和版本。
6、构造Spring容器(ApplicationContext)上下文。先填充Environment环境和设置的参数,如果application有设置beanNameGenerator(bean)、resourceLoader(加载器)就将其注入到上下文中。调用初始化的切面,发布ApplicationContextInitializedEvent(上下文初始化)事件。
7、SpringApplicationRunListeners发布finish事件。
8、StopWatch计时器停止计时,日志打印总共启动的时间。
9、发布SpringBoot程序已启动事件(started())
10、调用ApplicationRunner和CommandLineRunner
11、最后发布就绪事件ApplicationReadyEvent,标志着SpringBoot可以处理就收的请求了(running())
Spring MVC的工作原理
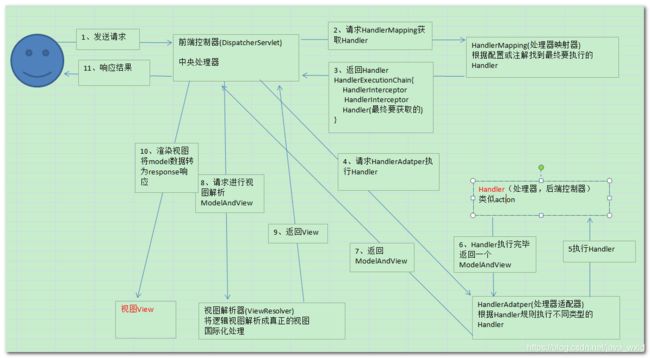
1、用户向服务器发送请求,请求被SpringMVC的前端控制器DispatcherServlet截获。
2、DispatcherServlet对请求的URL(统一资源定位符)进行解析,得到URI(请求资源标识符),然后根据该URI,调用HandlerMapping获得该Handler配置的所有相关的对象,包括Handler对象以及Handler对象对应的拦截器,这些对象都会被封装到一个HandlerExecutionChain对象当中返回。
3、DispatcherServlet根据获得的Handler,选择一个合适的HandlerAdapter。HandlerAdapter的设计符合面向对象中的单一职责原则,代码结构清晰,便于维护,最为重要的是,代码的可复制性高。HandlerAdapter会被用于处理多种Handler,调用Handler实际处理请求的方法。
4、提取请求中的模型数据,开始执行Handler(Controller)。在填充Handler的入参过程中,根据配置,spring将帮助做一些额外的工作消息转换:将请求的消息,如json、xml等数据转换成一个对象,将对象转换为指定的响应信息。数据转换:对请求消息进行数据转换,如String转换成Integer、Double等。 数据格式化:对请求的消息进行数据格式化,如将字符串转换为格式化数字或格式化日期等。数据验证:验证数据的有效性如长度、格式等,验证结果存储到BindingResult或Error中。
5、Handler执行完成后,向DispatcherServlet返回一个ModelAndView对象,ModelAndView对象中应该包含视图名或视图模型。
6、根据返回的ModelAndView对象,选择一个合适的ViewResolver(视图解析器)返回给DispatcherServlet。
7、ViewResolver结合Model和View来渲染视图。
8、将视图渲染结果返回给客户端。
Mybatis的缓存机制
首先,Mybatis里面设计了二级缓存来提升数据的检索效率,避免每次数据的访问都需要去查询数据库。
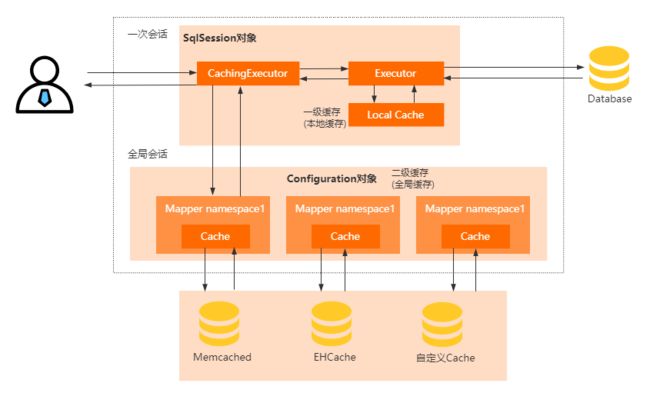
一级缓存,是SqlSession级别的缓存,也叫本地缓存,因为每个用户在执行查询的时候都需要使用SqlSession来执行,
为了避免每次都去查数据库,Mybatis把查询出来的数据保存到SqlSession的本地缓存中,后续的SQL如果命中缓存,就可以直接从本地缓存读取了。
如果想要实现跨SqlSession级别的缓存?那么一级缓存就无法实现了,因此在Mybatis里面引入了二级缓存,就是当多个用户
在查询数据的时候,只有有任何一个SqlSession拿到了数据就会放入到二级缓存里面,其他的SqlSession就可以从二级缓存加载数据。
每个一级缓存的具体实现原理是:

在SqlSession 里面持有一个Executor,每个Executor中有一个LocalCache对象。
当用户发起查询的时候,Mybatis会根据执行语句在Local Cache里面查询,如果没命中,再去查询数据库并写入到LocalCache,否则直接返回。
所以,以及缓存的生命周期是SqlSessiion,而且在多个Sqlsession或者分布式环境下,可能会导致数据库写操作出现脏数据。
二级缓存的具体实现原理是:
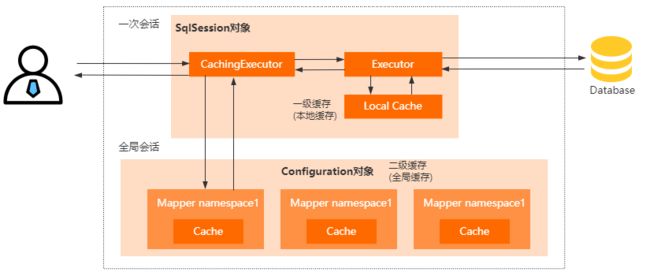
使用CachingExecutor装饰了Executor,所以在进入一级缓存的查询流程之前,会先通过CachingExecutor进行二级缓存的查询。
开启二级缓存以后,会被多个SqlSession共享,所以它是一个全局缓存。因此它的查询流程是先查二级缓存,再查一级缓存,最后再查数据库。
另外,MyBatis 的二级缓存相对于一级缓存来说,实现了 SqlSession 之间缓存数据的共享,同时缓存粒度也能够到 namespace 级别,并且还可以通过 Cache 接口实现类不同的组合,对 Cache 的可控性也更强。
Spring Cloud知识点
微服务构建
微服务架构设计原则
一般来说,在设计微服务体系结构的时候,遵循业务边界的概念,按照业务进行拆分、同时隐藏实现细节、把内容组件化模块化、可伸缩性可扩展性要求较高、并且可以实现隔离应用故障,避免整体系统不可用、要求独立部署,持续交付。
对于用户激增、并发量较高、数据量较大还得考虑:
- 水平复制因素,就是单个服务多运行几个实例。
- 数据分区因素,按照用户区域进行数据分区,比如北京、上海、广州等多建几个集群。
- 并发请求因素,如果产品数量多,用户群体多的情况下,使用多级缓存处理高并发,数据量小,数据访问很高,适合存储热点数据的,可以用Nignx缓存、数据量一般,访问量大,比较热门的数据,比如首页这种的,可以使用本地缓存、数据量很大,访问量一般,比如一般的商品这种,可以使用Redis缓存。产品数量不多,用户群体大,可以考虑将页面静态化,把页面放到CDN里面,图片放到云存储里面。
微服务构建技术选型
一般来说,利用Spring Boot快速构建应用,利用Spring Cloud Alibaba Nacos实现动态服务发现、服务配置管理、服务及流量管理,利用Open feign实现与其他系统进行交互,利用Hystrix 实现熔断和错误处理,利用Ribbon实现客户端负载均衡,利用 Nginx 实现服务端负载均衡,利用 Gateway管理外部系统访问、利用Spring Security Oauth2作为权限框架进行请求校验,权限拦截、利用Seata作为分布式事务组件、利用Zipkin/Skywalking作为链路追踪、利用Sentinel作为服务降级、使用arthas/VM作为Java诊断工具、引入swagger作为在线文档、使用Redis作为分布式缓存、使用MySQL作为关系型数据库、使用MongoDB作为非关系型数据库、使用ElasticSearch作为全文搜索、有大数据的情况下使用Spark或者炎凰数仓进行读时建模。
前后端分离架构
对于一些老的项目或者特定业务的项目可能还是没有分离前后端,不过目前主流基本都是前后端分离,前后端交互更清晰,就剩下了接口模型,后端的接口更简洁明了,更容易维护,前端多渠道集成场景更容易。
后端采用统一的数据模型,支持多个前端,比如:H5前端、PC前端、安卓前端、IOS前端。
对于请求方式,比如GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源,当然也需要根据自己项目的实际情况出发,请求方式尽量统一起来。另外需要考虑后期接口参数是否会新增,如果后期参数不确定,尽量使用POST,方便后期扩展参数。
对于返回响应的实体类,后端响应统一起来,不能每个后端都用自己的响应实体类,这样前端会炸的。另外对于后端抛出来的错也需要拦截封装,给到前端一个友好的响应,而不是直接抛出去,这样前端那边的感知不友好。
对于前端请求,一般会携带几个校验参数放到请求头中,比如:App私钥(前后端约定好)、时间戳、Token令牌、校验码等等,后端一般会在网关服务或者权限服务里面,将更新数据的请求,比如POST,PUT,DELETE请求方式,对这些请求进行校验,请求头里App私钥、时间戳、Token令牌通过某种运算或者算法计算出结果,最后通过加密的方式加密这个结果,作为最终的校验码,对比前后端的校验码是否一致,判断这个请求是否合法、请求的Token是否过期/失效。
项目部署安全方面
对于项目系统部署安全方面,建议改私有网络+堡垒机+密码复杂度,建立锁机机制使用第三方知名云厂商托管数据库,降低运维复杂度,将项目部署在VPC私网内,使用cloudwatch Log+lambda+Network Firewall服务,检查mysql连续登录失败的IP次数,触发lambda执行脚本更新Network Firewall规则,禁用该IP访问。出于安全考虑,服务器只允许通过堡垒机进行运维。在没有提供安全访问策略表的情况下,除了被堡垒机访问之外,所有虚拟机无法访问任何主机,也无法被任何主机访问。
客户端负载均衡
负载均衡(服务端/客户端)
一般我们所说的负载均衡通常都是服务器端负载均衡,服务器端负载均衡又分为两种,一种是硬件负载均衡,还有一种是软件负载均衡。
硬件负载均衡主要通过在服务器节点之前安装专门用于负载均衡的设备,常见的如:F5。
软件负载均衡则主要是在服务器上安装一些具有负载均衡功能的软件来完成请求分发进而实现负载均衡,常见的如:LVS 、 Nginx 。
微服务为负载均衡的实现提供了另外一种思路:把负载均衡的功能以库的方式集成到服务的消费方,不再是由一台指定的负载均衡设备集中提供。这种方案称为软负载均衡客户端负载均衡。常见的如:Spring Cloud中的 Ribbon。
当我们将Ribbon和Eureka一起使用时,Ribbon会到Eureka注册中心去获取服务端列表,然后进行轮询访问以到达负载均衡的作用,客户端负载均衡也需要心跳机制去维护服务端清单的有效性,当然这个过程需要配合服务注册中心一起完成。
实现Ribbon
底层实现
Ribbon的负载均衡,主要通过LoadBalancerClient来实现的,而LoadBalancerClient具体交给了ILoadBalancer来处理,ILoadBalancer通过配置IRule、IPing等信息,并向EurekaClient获取注册列表的信息,并默认10秒一次向EurekaClient发送“ping”,进而检查是否更新服务列表,最后,得到注册列表后,ILoadBalancer根据IRule的策略进行负载均衡。
而RestTemplate 被@LoadBalance注解后,能过用负载均衡,主要是维护了一个被@LoadBalance注解的RestTemplate列表,并给列表中的RestTemplate添加拦截器,进而交给负载均衡器去处理。
快速集成
在 pom.xml 文件中引入依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.6.RELEASE</version>
</parent>
<properties>
<spring-cloud.version>Finchley.SR2</spring-cloud.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Eureka-Client 依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<!-- SpringCloud 版本控制依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
然后在启动类里面向Spring容器中注入一个带有@LoadBalanced注解的RestTemplate Bean
import org.springframework.boot.WebApplicationType;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.builder.SpringApplicationBuilder;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate;
@SpringBootApplication
@EnableEurekaClient
public class MessageCenterApplication {
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
public static void main(String[] args) {
new SpringApplicationBuilder(MessageCenterApplication.class).web(WebApplicationType.SERVLET).run(args);
}
}
调用那些需要做负载均衡的服务时,用上面注入的RestTemplate Bean进行调用就可以了
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
@RestController
@RequestMapping("/api/v1/center")
public class MessageCenterController {
@Autowired
private RestTemplate restTemplate;
@GetMapping("/msg/get")
public Object getMsg() {
String msg = restTemplate.getForObject("http://message-service/api/v1/msg/get", String.class);
return msg;
}
}
在application.yml配置文件里添加好配置,比如:
spring:
application:
name: message-service
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
启动的时候,Run As --> Run Configurations->VM arguments,分别使用 8771、8772、8773 三个端口各启动一个MessageApplication应用。
-Dserver.port=8771
-Dserver.port=8772
-Dserver.port=8773
三个服务启动完成后,浏览器输入:http://localhost:8761/
应用启动之后,连续三次请求地址 http://localhost:8781/api/v1/center/msg/get



Ribbon负载均衡策略
-
RoundRobinRule: 轮询策略,Ribbon以轮询的方式选择服务器,这个是默认值。启动的服务会被循环访问。
-
RandomRule: 随机策略,也就是说Ribbon会随机从服务器列表中选择一个进行访问。
-
BestAvailableRule: 最大可用策略,先过滤出故障服务器后,选择一个当前并发请求数最小的。
-
WeightedResponseTimeRule: 带有加权的轮询策略,对各个服务器响应时间进行加权处理,然后在采用轮询的方式来获取相应的服务器。
-
AvailabilityFilteringRule: 可用过滤策略,先过滤出故障的或并发请求大于阈值的一部分服务实例,然后再以线性轮询的方式从过滤后的实例清单中选出一个。
-
ZoneAvoidanceRule: 区域感知策略,先使用主过滤条件(区域负载器,选择最优区域)对所有实例过滤并返回过滤后的实例清单,依次使用次过滤条件列表中的过滤条件对主过滤条件的结果进行过滤,判断最小过滤数(默认1)和最小过滤百分比(默认0),最后对满足条件的服务器则使用RoundRobinRule(轮询方式)选择一个服务器实例。
例如,message-service的负载均衡策略设置为随机访问RandomRule,application.yml配置如下
message-service:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
脱离Eureka使用Ribbon
如果你不用Eureka,也可以继续使用Ribbon和Feign。
假设不使用Eureka,通过将ribbon.eureka.enabled 属性设置为 false, 可以在Ribbon中禁用Eureka,用@RibbonClient声明了一个"stores"服务,这个时候Ribbon Client 默认会引用一个配置好的服务列表,你可以在application.yml进行配置:
ribbon:
eureka:
enabled: false
stores:
ribbon:
listOfServers: example.com,google.com
服务治理
为什么需要服务治理
公司的系统是由几百个微服务构成的,每一个微服务又有多个实例,服务数量较多,服务之间的相互依赖成网状,所以微服务系统需要服务注册中心来统一管理微服务实例,方便查看每一个微服务实例的健康状态。
服务治理的解决方案
- 服务注册:服务提供者主动自报家门
服务提供者将自己的服务信息(比如服务名、IP地址等)告诉服务注册中心。
- 服务发现:服务消费者拉取注册数据
当服务消费者需要消费另外一个服务时,服务注册中心需要告诉服务消费者它所要消费服务的实例信息(如服务名、IP地址等)。
- 心跳检测、服务续约和服务剔除
服务注册中心会检查注册的服务是否可用,通常一个服务实例注册后,会定时向服务注册中心提供“心跳”,以表明自己还处于可用的状态。如果一个服务实例停止向服务注册中心提供心跳一段时间后,服务注册中心会认为这个服务实例不可用,会把这个服务实例从服务注册列表中剔除。如果这个被剔除掉的服务实例过一段时间后继续向注册中心提供心跳,那么服务注册中心会把这个服务实例重新加入服务注册中心的列表中。
- 服务下线:服务提供者主动发起下线
服务治理的技术选型
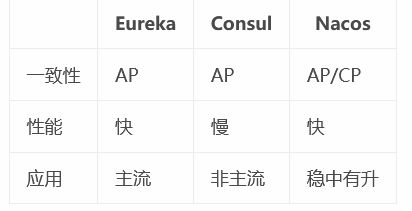
Eureka
Eureka Client:负责将这个服务的信息注册到Eureka Server中
Eureka Server:注册中心,里面有一个注册表,保存了各个服务所在的机器和端口号
自我保护机制产生的原因
Eureka的自我保护特性主要用于减少在网络分区或者不稳定状况下的不一致性问题,默认情况下,如果Server在一定时间内没有接收到某个服务实例的心跳(默认周期为30秒),Server将会注销该实例。如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,启动自我保护机制。
自我保护机制
- Eureka不再从注册表中移除因为长时间没有收到心跳而过期的服务。
- Eureka仍然能够接受新服务注册和查询请求,但是不会被同步到其它节点上,保证当前节点依然可用。
- 当网络稳定时,当前实例新注册的信息会被同步到其它节点中。
在什么环境下开启自我保护机制
本地环境
建议关闭自我保护机制。因为在本地开发环境中,EurekaServer端相对来说重启频率不高,但是在EurekaClient端,可能改动代码之后需要重启,频率相对来说比较高;那么EurekaClient端重启之后就不会及时去向EurekaServer端发送心跳包,EurekaServer端就会认为是网络延迟或者其他原因,不会剔除服务,这样的话就会影响开发效率。
生产环境
建议开启自我保护机制。因为生产环境不会频繁重启服务器,并且EurekaClient端与EurekaServer端存在网络延迟的几率较高,所以需要开启自我保护机制避免误删服务。
Eureka Server端:配置关闭自我保护,并按需配置Eureka Server清理无效节点的时间间隔。
eureka.server.enable-self-preservation # 设为false,关闭自我保护
eureka.server.eviction-interval-timer-in-ms # 清理间隔(单位毫秒,默认是60*1000)
Eureka Client端:配置开启健康检查,并按需配置续约更新时间和到期时间
eureka.instance.lease-renewal-interval-in-seconds # 续约更新时间间隔(默认30秒)
eureka.instance.lease-expiration-duration-in-seconds # 续约到期时间(默认90秒)
公司client 的配置:
eureka:
instance:
prefer-ip-address: true
instance-id: ${spring.application.name}:${spring.client.ipAdress}:${server.port}
lease-expiration-duration-in-seconds: 30 #服务过期时间配置,超过这个时间没有接收到心跳EurekaServer就会将这个实例剔除
lease-renewal-interval-in-seconds: 10 #服务刷新时间配置,每隔这个时间会主动心跳一次
Nacos
Nacos的动态更新如何实现?什么是长轮询/如何实现长轮询?配置和服务器之间的配置变更整个方案如何实现?Nacos如何实现配置的变更和对比?
Nacos采用长轮训机制来实现数据变更的同步
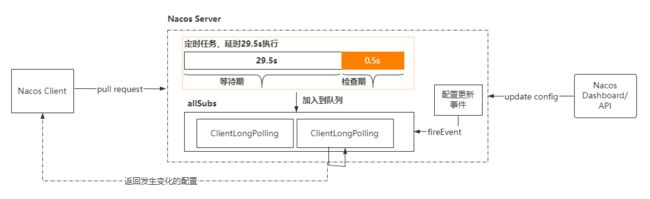
Nacos是采用长轮训的方式向Nacos Server端发起配置更新查询的功能。所谓长轮训就是客户端发起一次轮训请求到服务端,当服务端配置没有任何变更的时候,这个连接一直打开,直到服务端有配置或者连接超时后返回。Nacos Client端需要获取服务端变更的配置,前提是要有一个比较,也就是拿客户端本地的配置信息和服务端的配置信息进行比较。
一旦发现和服务端的配置有差异,就表示服务端配置有更新,于是把更新的配置拉到本地。在这个过程中,有可能因为客户端配置比较多,导致比较的时间较长,使得配置同步较慢的问题。于是Nacos针对这个场景,做了两个方面的优化。
-
减少网络通信的数据量,客户端把需要进行比较的配置进行分片,每一个分片大小是3000,也就是说,每次最多拿3000个配置去Nacos Server端进行比较。
-
分阶段进行比较和更新,
第一阶段,客户端把这3000个配置的key以及对应的value值的md5拼接成一个字符串,然后发送到Nacos Server端
进行判断,服务端会逐个比较这些配置中md5不同的key,把存在更新的key返回给客户端。
第二阶段,客户端拿到这些变更的key,循环逐个去调用服务单获取这些key 的value值。
这两个优化,核心目的是减少网络通信数据包的大小,把一次大的数据包通信拆分成了多次小的数据包通信。虽然会增加网络通信次数,但是对整体的性能有较大的提升。最后,再采用长连接这种方式,既减少了pull轮询次数,又利用了长连接的优势,很好的实现了配置的动态更新同步功能。
基于HTTP的长轮询简单实现
web客户端代码
//向后台长轮询消息
function longPolling(){
$.ajax({
async : true,//异步
url : 'longPollingAction!getMessages.action',
type : 'post',
dataType : 'json',
data :{},
timeout : 30000,//超时时间设定30秒
error : function(xhr, textStatus, thrownError) {
longPolling();//发生异常错误后再次发起请求
},
success : function(response) {
message = response.data.message;
if(message!="timeout"){
broadcast();//收到消息后发布消息
}
longPolling();
}
});
}
web服务器端代码
public class LongPollingAction extends BaseAction {
private static final long serialVersionUID = 1L;
private LongPollingService longPollingService;
private static final long TIMEOUT = 20000;// 超时时间设置为20秒
public String getMessages() {
long requestTime = System.currentTimeMillis();
result.clear();
try {
String msg = null;
while ((System.currentTimeMillis() - requestTime) < TIMEOUT) {
msg = longPollingService.getMessages();
if (msg != null) {
break; // 跳出循环,返回数据
} else {
Thread.sleep(1000);// 休眠1秒
}
}
if (msg == null) {
result.addData("message", "timeout");// 超时
} else {
result.addData("message", msg);
}
} catch (Exception e) {
e.printStackTrace();
}
return SUCCESS;
}
public LongPollingService getLongPollingService() {
return longPollingService;
}
public void setLongPollingService(LongPollingService longPollingService) {
this.longPollingService = longPollingService;
}
}
Nacos、Eureka与Zookeeper区别
相同点:
- 都可以实现分布式注册中心框架
不同点:
-
Zookeeper采用CP保证数据的一致性的问题,原理是采用ZAB原子广播协议。当我们ZK领导者宕机或出现了故障,会自动重新实现选举新的领导角色,整个选举的过程中为了保证数据一致性的问题,整个微服务无法实现通讯,可运行的节点必须满足过半机制,整个zk才可以使用,要不然会奔溃。
-
Eureka采用AP设计理念架构注册中心,相互注册完全去中心化,也就是没有主从之分,只要有一台Eureka节点存在整个微服务就可以实现通讯。Eureka中会定时向注册中心发送心跳,如果在短期内没有发送心跳,则就会直接剔除。会定时向注册中心定时拉去服务,如果不主动拉去服务,注册中心不会主动推送。
-
Nacos中注册中心会定时向消费者主动推送信息 ,这样就会保持数据的准时性。它会向注册中心发送心跳,但是它的频率要比Eureka快。Nacos从1.0版本选择Ap和CP混合形式实现注册中心,默认情况下采用Ap保证服务可用性,CP形式底层采用Raft协议保证数据的一致性问题。默认采用AP方式,当集群中存在非临时实例时,采用CP模式。选择Ap模式,在网络分区的的情况允许注册服务实例。选择CP模式,在网络分区的产生了抖动情况下不允许注册服务实例。
服务容错保护
服务雪崩
在微服务架构中,一个请求要调用多个服务是非常常见的。如客户端访问A服务,A服务访问B服务,B服务调用C服务,由于网络原因或者自身的原因,如果B服务或者C服务不能及时响应,A服务将处于阻塞状态,直到B服务C服务响应。此时若有大量的请求涌入,容器的线程资源会被消耗完毕,导致服务瘫痪。服务与服务之间的依赖性,故障会传播,造成连锁反应,会对整个微服务系统造成灾难性的严重后果,这就是服务故障的“雪崩效应”。
在高并发的情况下,一个服务的延迟可能导致所有服务器上的所有资源在数秒内饱和。比起服务故障,更糟糕的是这些应用程序还可能导致服务之间的延迟增加,导致整个系统出现更多级联故障。
造成服务雪崩的原因可以归结为以下三点:
- 服务提供者不可用(硬件故障,程序bug,缓存击穿,用户大量请求等)
- 重试加大流量(用户重试,代码逻辑重试)
- 服务消费者不可用(同步等待造成的资源耗尽)
解决方案:
- 服务隔离:限制调用分布式服务的资源,某一个调用的服务出现问题不会影响到其他服务调用
- 服务熔断:牺牲局部服务,保全整体系统稳定性
- 服务降级:服务熔断以后,客户端调用自己本地方法返回缺省值
所谓的容错处理其实就是捕获异常了,不让异常影响系统的正常运行,正如java中的try catch一样。在微服务调用中,自身异常可自行处理外,对于依赖的服务发生错误,或者调用异常,或者调用时间过长等原因时,为了避免长时间等待,造成系统资源耗尽, 一般上都会通过设置请求的超时时间,如http请求中的ConnectTimeout和ReadTimeout;而微服务提供了Hystrix熔断器,隔离问题服务,防止级联错误的发生。
Hystrix
Hystrix是一个实现了超时机制和断路器模式的工具类库,用于隔离访问远程系统、服务或第三方库,提升系统的可用性和容错性。
Hystrix容错机制:
- 包裹请求:使用HystrixCommand包裹对依赖的调用逻辑,每个命令在独立线程中执行,这是用到了设计模式“命令模式”。
- 跳闸机制:当某服务的错误率超过一定阈值时,Hystrix可以自动或手动跳闸,停止请求该服务一段时间。
- 资源隔离:Hystrix为每个依赖都维护了一个小型的线程池,如果该线程池已满,发往该依赖的请求就被立即拒绝,而不是排队等候,从而加速判定失败。
- 监控:Hystrix可以近乎实时的监控运行指标和配置的变化。如成功、失败、超时、被拒绝的请求等。
- 回退机制:当请求失败、超时、被拒绝,或当断路器打开时,可以执行回退逻辑。
- 自我修复:断路器打开一段时间后,会自动进入半开状态,断路器打开、关闭、半开的逻辑转换。
熔断器的工作原理
每个请求都会在 hystrix 超时之后返回 fallback,每个请求时间延迟就是近似 hystrix 的超时时间,假设是 5 秒,那么每个请求都要延迟 5 秒后才返回。当熔断器在 10 秒内发现请求总数超过 20,并且错误百分比超过 50%,此时熔断打开。
熔断打开之后,再有请求调用的时候,将不会调用主逻辑,而是直接调用降级逻辑,这个时候就会快速返回,而不是等待 5 秒才返回 fallback。通过断路器,实现了自动发现错误并将降级逻辑切为主逻辑,减少响应延迟。
当断路器打开,主逻辑被熔断后,hystrix 会启动一个休眠时间窗,在这个时间窗内,降级逻辑就是主逻辑;当休眠时间窗到期,断路器进入半开状态,释放一次请求到原来的主逻辑上,如果此次请求返回正常,那么断路器将闭合,主逻辑恢复,如果这次请求依然失败,断路器继续打开,休眠时间窗重新计时。
信号量隔离
请求并发大,耗时短,采用信号量隔离,因为这类服务的返回通常很快,不会占用线程太长时间,而且也减少了线程切换的开销。
每个请求线程通过计数信号进行限制,当信号量大于了最大请求数maxConcurrentRequest时,调用fallback接口快速返回。另外由于通过信号量计数器进行隔离,它只是个计数器,资源消耗小。
信号量的调用是同步的,每次调用都得阻塞调用方的线程,直到有结果才返回,这样就导致了无法对访问做超时处理,只能依靠协议超时,无法主动释放。
实现方式
@HystrixCommand注解实现线程池隔离,通过配置超时时间,信号量隔离,信号量最大并发,以及回退方法,基于注解就可以对方法实现服务隔离。
// 信号量隔离
@HystrixCommand(
commandProperties = {
// 超时时间,默认1000ms
@HystrixProperty(name = HystrixPropertiesManager.
EXECUTION_ISOLATION_THREAD_TIMEOUT_IN_MILLISECONDS, value = "5000"),
// 信号量隔离
@HystrixProperty(name = HystrixPropertiesManager.
EXECUTION_ISOLATION_STRATEGY, value = "SEMAPHORE"),
// 信号量最大并发
@HystrixProperty(name = HystrixPropertiesManager.
EXECUTION_ISOLATION_SEMAPHORE_MAX_CONCURRENT_REQUESTS, value = "5")
},
fallbackMethod = "selectProductByIdFallBack"
)
@Override
public Product selectProductById(Integer id) {
System.out.println(Thread.currentThread().getName());
return productClient.selectProductById(id);
}
线程池隔离
请求并发大,耗时长,采用线程池隔离策略。这样可以保证大量的线程可用,不会由于服务原因一直处于阻塞或等待状态,快速失败返回。还有就是对依赖服务的网络请求涉及超时问题的都使用线程隔离。
优缺点
优点:
- 使用线程池隔离可以安全隔离依赖的服务,减少所依赖的服务发生故障时的影响。比如A服务发生异常,导致请求大量超时,对应的线程池被打满,这时并不影响在其他线程池中的C、D服务的调用。
- 当失败的服务再次变得可用时,线程池将清理并立即恢复,而不需要一个长时间的恢复。
- 独立的线程池提高了并发性。
缺点:
- 请求在线程池中执行,肯定会带来任务调度、排队个上下文切换带来的CPU开销。
- 因为涉及到跨线程,那么就存在ThreadLocal数据传递的问题,比如在主线程初始化的ThreadLocal变量,在线程池中无法获取。
实现方式
@HystrixCommand注解实现线程池隔离,通过配置服务名称,接口名称,线程池,以及回退方法,基于注解就可以对接口实现服务隔离。
// 线程池隔离
@HystrixCommand(groupKey = "productServiceSinglePool", // 服务名称,相同名称使用同一个线程池
commandKey = "selectProductById", // 接口名称,默认为方法名
threadPoolKey = "productServiceSinglePool", // 线程池名称,相同名称使用同一个线程池
commandProperties = {
// 超时时间,默认1000ms
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "5000")
},
threadPoolProperties = {
// 线程池大小
@HystrixProperty(name = "coreSize", value = "10"),
// 等待队列长度(最大队列长度,默认值-1)
@HystrixProperty(name = "maxQueueSize", value = "100"),
// 线程存活时间,默认1min
@HystrixProperty(name = "keepAliveTimeMinutes", value = "2"),
// 超出等待队列阈值执行拒绝策略
@HystrixProperty(name = "queueSizeRejectionThreshold", value = "100")
},
fallbackMethod = "selectProductByIdFallBack"
)
@Override
public Product selectProductById(Integer id) {
System.out.println(Thread.currentThread().getName());
return productClient.selectProductById(id);
}
private Product selectProductByIdFallBack(Integer id) {
return new Product(888, "未知商品", 0, 0d);
}
// 线程池隔离
@HystrixCommand(groupKey = "productServiceListPool", // 服务名称,相同名称使用同一个线程池
commandKey = "selectByIds", // 接口名称,默认为方法名
threadPoolKey = "productServiceListPool", // 线程池名称,相同名称使用同一个线程池
commandProperties = {
// 超时时间,默认1000ms
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "5000")
},
threadPoolProperties = {
// 线程池大小
@HystrixProperty(name = "coreSize", value = "5"),
// 等待队列长度(最大队列长度,默认值-1)
@HystrixProperty(name = "maxQueueSize", value = "100"),
// 线程存活时间,默认1min
@HystrixProperty(name = "keepAliveTimeMinutes", value = "2"),
// 超出等待队列阈值执行拒绝策略
@HystrixProperty(name = "queueSizeRejectionThreshold", value = "100")
},
fallbackMethod = "selectByIdsFallback"
)
@Override
public List<Product> selectByIds(List<Integer> ids) {
System.out.println(Thread.currentThread().getName());
return productClient.selectPhoneList(ids);
}
private List<Product> selectByIdsFallback(List<Integer> ids) {
System.out.println("==call method selectByIdsFallback==");
return Arrays.asList(new Product(999, "未知商品", 0, 0d));
}
服务熔断
服务熔断一般是指软件系统中,由于某些原因使得服务出现了过载现象,为了防止造成整个系统故障,从而采用的一种保护措施,所以很多地方也把熔断称为过载保护。
实现方式
使用@HystrixProperty注解,通过配置请求数阈值、错误百分比阈值、快照时间窗口,基于注解就可以对方法实现服务熔断。
// 服务熔断
@HystrixCommand(
commandProperties = {
// 请求数阈值:在快照时间窗口内,必须满足请求阈值数才有资格熔断。打开断路器的最少请求数,默认20个请求。
//意味着在时间窗口内,如果调用次数少于20次,即使所有的请求都超时或者失败,断路器都不会打开
@HystrixProperty(name = HystrixPropertiesManager.
CIRCUIT_BREAKER_REQUEST_VOLUME_THRESHOLD, value = "10"),
// 错误百分比阈值:当请求总数在快照内超过了阈值,且有一半的请求失败,这时断路器将会打开。默认50%
@HystrixProperty(name = HystrixPropertiesManager.
CIRCUIT_BREAKER_ERROR_THRESHOLD_PERCENTAGE, value = "50"),
// 快照时间窗口:断路器开启时需要统计一些请求和错误数据,统计的时间范围就是快照时间窗口,默认5秒
@HystrixProperty(name = HystrixPropertiesManager.
CIRCUIT_BREAKER_SLEEP_WINDOW_IN_MILLISECONDS, value = "5000")
},
fallbackMethod = "selectProductByIdFallBack"
)
@Override
public Product selectProductById(Integer id) {
System.out.println(Thread.currentThread().getName()+
LocalDateTime.now().format(DateTimeFormatter.ISO_LOCAL_TIME));
if (id == 1) {
throw new RuntimeException("模拟查询ID为1导致异常");
}
return productClient.selectProductById(id);
}
服务降级
开启条件
- 方法抛出HystrixBadRequestException异常
- 方法调用超时
- 熔断器开启拦截调用
- 线程池、队列、信号量跑满
方法服务降级
// 服务降级
@HystrixCommand(fallbackMethod = "selectProductByIdFallBack")
@Override
public Product selectProductById(Integer id) {
System.out.println(Thread.currentThread().getName()+
LocalDateTime.now().format(DateTimeFormatter.ISO_LOCAL_TIME));
if (id == 1) {
throw new RuntimeException("模拟查询ID为1导致异常");
}
return productClient.selectProductById(id);
}
类全局服务降级
在类中添加注解@DefaultProperties(defaultFallback = "selectProductByIdFallback")

在需要降级的方法上添加注解@HystrixCommand

创建一个全局fallbakc方法
public Product selectProductByIdFallback(){
return new Product(999, "undefined", 0, 0d);
}
Feign中使用断路器
当我们方法很多时,要是分别编写一个fallback估计也是崩溃的,虽然可以使用一个通用的fallback,但未进行特殊设置下,也是无法知道具体是哪个方法发生熔断的。
而对于Feign,我们可以使用一种更加优雅的形式进行。我们可以指定@FeignClient注解的fallback属性,或者是fallbackFactory属性,后者可以获取异常信息的。Feign是自带断路器的,在D版本的Spring Cloud中,它没有默认打开。
需要在配置文件中配置打开它,在配置文件加以下代码:
feign.hystrix.enabled=true
需要在FeignClient的SchedualServiceHi接口的注解中加上fallback的指定类就行了
@FeignClient(value = "service-hi",fallback = SchedualServiceHiHystric.class)
public interface SchedualServiceHi {
@RequestMapping(value = "/hi",method = RequestMethod.GET)
String sayHiFromClientOne(@RequestParam(value = "name") String name);
}
SchedualServiceHiHystric需要实现SchedualServiceHi 接口,并注入到Ioc容器中
@Component
public class SchedualServiceHiHystric implements SchedualServiceHi {
@Override
public String sayHiFromClientOne(String name) {
return "sorry "+name;
}
}
servcie-feign工程,浏览器打开http://localhost:8765/hi?name=forezp,注意此时service-hi工程没有启动,网页显示:
sorry forezp
打开service-hi工程,再次访问,浏览器显示:
hi forezp,i am from port:8762
这证明断路器起到作用了。
服务监控
除了实现服务容错之外,Hystrix还提供了近乎实时的监控功能,将服务执行结果、运行指标、请求数量、成功数量等这些状态通过Actuator进行收集,然后访问/actuator/hystrix.stream即可看到实时的监控数据。
实现方式
添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
添加配置
management:
endpoints:
web:
exposure:
include: hystrix.stream
启动类
添加@EnableHystrix注解
访问
http://localhost:9090/actuator/hystrix.stream
查看数据

监控中心
Hystrix提供的一套可视化系统,Hystrix-Dashboard,可以非常友好的看到当前环境中服务运行的状态。Hystrix-Dashboard是一款针对Hystrix进行实时监控的工具,通过Hystrix-Dashboard我们可以直观地看到各Hystrix Command的请求响应时间,请求成功率等数据。
实现过程
添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
启动类添加注解@EnableHystrixDashboard
// 开启数据监控
@EnableHystrixDashboard
// 开启熔断器
@EnableHystrix
// 开启缓存注解
@EnableCaching
@EnableFeignClients
@SpringBootApplication
public class ServiceConsumerApplication
{
public static void main( String[] args )
{
SpringApplication.run(ServiceConsumerApplication.class);
}
}
访问:http://localhost:9090/hystrix,控制中心界面如下:


聚合监控中心
实现过程
Turbine是聚合服务器发送事件流数据的一个工具,dashboard只能监控单个节点,实际生产环境中都为集群,因此可以通过Turbine来监控集群服务。
新建一个聚合监控项目,添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-turbine</artifactId>
</dependency>
添加配置文件
server:
port: 8181
spring:
application:
name: eureka-turbine
eureka:
instance:
prefer-ip-address: true
instance-id: ${spring.cloud.client.ip-address}:${server.port}
client:
service-url:
defaultZone: http://localhost:8761/eureka/,http://localhost:8762/eureka/
turbine: # 聚合监控
app-config: service-consumer,service-provider # 监控的服务列表
cluster-name-expression: "'default'" # 指定集群名称
启动类添加注解
@EnableTurbine
@EnableHystrix
@EnableHystrixDashboard
@SpringBootApplication
public class App
{
public static void main( String[] args )
{
SpringApplication.run(App.class);
}
}
访问http://localhost:8181/hystrix


Hystrix工作流程
- 构造一个HystrixCommand或者HystrixObservableCommand对象
- 执行command命令
- 结果是否缓存
- 熔断器是否打开
- 线程池、队列、信号量是否打满
- 执行对应的构造方法或者run方法
- 计算熔断器状态开启还是关闭
- 获取fallback返回
- 返回成功响应
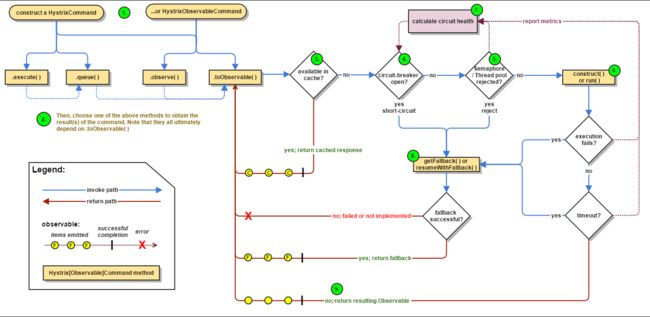
声明式服务调用
比如一个订单服务知道库存服务、积分服务、仓库服务在哪里了,同时也监听着哪些端口号了。但是新问题又来了:难道订单服务要自己写一大堆代码,建立连接、构造请求、接着发送请求过去、解析响应等等。
使用Feign组件直接就是用注解定义一个 FeignClient接口,然后调用那个接口就可以了。人家Feign Client会在底层根据你的注解,跟你指定的服务建立连接、构造请求、发起靕求、获取响应、解析响应,等等。这一系列脏活累活,人家Feign全给你干了。
对某个接口定义了@FeignClient注解,Feign就会针对这个接口创建一个动态代理,接着你要是调用那个接口,本质就是会调用 Feign创建的动态代理,这是核心中的核心,Feign的动态代理会根据你在接口上的@RequestMapping等注解,来动态构造出你要请求的服务的地址,最后针对这个地址,发起请求、解析响应。
API网关服务
请求拦截、服务分发、统一的降级、限流、认证授权、安全
关于业务网关,市场上也有蛮多的技术。一些大的公司一般选择定制化开发。但是从开发语言,可维护性上出发,能选的只有getway和zuul,但是zuul使用的阻塞IO,损失性能极大,虽然新版本有支持,但是spring并没有很好的支持升级后的zuul。gatway是spring做出来的,性能也比较好,支持长连接。

Spring Cloud Gateway明确区分了Router和Filter,位于请求接入:作为所有API接口服务请求的接入点
比如可以基于Header、Path、Host、Query自由路由。
gateway的组成
- 路由 : 网关的基本模块,有ID,目标URI,一组断言和一组过滤器组成
- 断言:就是访问该请求的访问规则,可以用来匹配来自http请求的任何内容,例如headers或者参数
- 过滤器:这个就是我们平时说的过滤器,用来过滤一些请求的,也可以自定义过滤器,但是要实现两个接口,ordered和globalfilter。
分布式配置中心
config配置中心
-
在分布式系统中,由于服务数量巨多,为了方便服务配置文件统一管理,实时更新,需要分布式配置中心组件。
-
支持配置服务放在配置服务的内存中(即本地),也支持放在远程Git仓库中。config 组件中,分两个角色,一是config server,二是config client。config-client可以从config-server获取配置属性。
消息总线
Bus数据总线:将分布式的节点用轻量的消息代理连接起来。它可以用于广播配置文件的更改或者服务之间的通讯,也可以用于监控。
应用场景:实现通知微服务架构的配置文件的更改。去代码仓库将foo的值改为“foo version 4”,即改变配置文件foo的值。如果是传统的做法,需要重启服务,才能达到配置文件的更新。我们只需要发送post请求:http://localhost:8881/bus/refresh,会发现config-client会重现肚脐配置文件,重新读取配置文件。
案例:当git文件更改的时候,通过pc端用post 向端口为8882的config-client发送请求/bus/refresh/;此时8882端口会发送一个消息,由消息总线向其他服务传递,从而使整个微服务集群都达到更新配置文件。
消息驱动
SpringCloud Stream:SpringBoot应用要直接与消息中间件进行信息交互的时候,由于各消息中间件构建的初衷不同,它们的实现细节上会有较大的差异性,通过定义绑定器作为中间层,完美地实现了应用程序与消息中间件细节之间的隔离。Stream对消息中间件的进一步封装,可以做到代码层面对中间件的无感知,甚至于动态的切换中间件(rabbitmq切换为kafka),使得微服务开发的高度解耦,服务可以关注更多自己的业务流程。
-
通过定义绑定器Binder作为中间层,实现了应用程序与消息中间件细节之间的隔离。
-
Binder可以生成Binding,Binding用来绑定消息容器的生产者和消费者,它有两种类型,INPUT和OUTPUT,INPUT对应于消费者,OUTPUT对应于生产者。
设计思想:Stream中的消息通信方式遵循了发布-订阅模式,Topic主题进行广播,在RabbitMQ就是Exchange,在Kakfa中就是Topic。
基础组件
- Binder: 很方便的连接中间件,屏蔽差异
- Channel:通道,是队列Queue的一种抽象,在消息通讯系统中就是实现存储和转发的媒介,通过Channel对队列进行配置
- Source和Sink: 简单的可理解为参照对象是Spring Cloud Stream自身,从Stream发布消息就是输出,接受消息就是输入。
分布式服务追踪
微服务架构上通过业务来划分服务的,通过REST调用,对外暴露的一个接口,可能需要很多个服务协同才能完成这个接口功能,如果链路上任何一个服务出现问题或者网络超时,都会形成导致接口调用失败。随着业务的不断扩张,服务之间互相调用会越来越复杂。一个 HTTP 请求会调用多个不同的微服务来处理返回最后的结果,在这个调用过程中,可能会因为某个服务出现网络延迟过高或发送错误导致请求失败,所以需要对服务追踪分析,提供一个可视化页面便于排查问题所在。
Sleuth 整合 Zipkin,可以使用它来收集各个服务器上请求链路的跟踪数据,并通过它提供的 REST API 接口来辅助查询跟踪数据以实现对分布式系统的监控程序,从而及时发现系统中出现的延迟过高问题。除了面向开发的 API 接口之外,它还提供了方便的 UI 组件来帮助我们直观地搜索跟踪信息和分析请求链路明细,比如可以查询某段时间内各用户请求的处理时间等。
Skywalking是本土开源的基于字节码注入的调用链路分析以及应用监控分析工具,特点是支持多种插件,UI功能较强,接入端无代码侵入。
CAT是由国内美团点评开源的,基于Java语言开发,目前提供Java、C/C++、Node.js、Python、Go等语言的客户端,监控数据会全量统计,国内很多公司在用,例如美团点评、携程、拼多多等,CAT跟下边要介绍的Zipkin都需要在应用程序中埋点,对代码侵入性强。
性能对比:skywalking探针对吞吐量影响最小,zipkin对吞吐量影响适中,pinpoint的探针对吞吐量影响最大。对于内存和cpu的使用,都差不多,相差在10%之内。
分布式事务
Seata 的架构
在 Seata 的架构中,一共有三个角色:
TC (Transaction Coordinator) - 事务协调者:维护全局和分支事务的状态,驱动全局事务提交或回滚。TC 为单独部署的 Server 服务端。
TM (Transaction Manager) - 事务管理器:定义全局事务的范围:开始全局事务、提交或回滚全局事务。TM为嵌入到应用中的 Client 客户端。
RM (Resource Manager) - 资源管理器:管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。RM 为嵌入到应用中的 Client 客户端。
存在的问题
性能损耗
一条Update的SQL,则需要全局事务xid获取(与TC通讯)、before image(解析SQL,查询一次数据库)、after image(查询一次数据库)、insert undo log(写一次数据库)、before commit(与TC通讯,判断锁冲突),这些操作都需要一次远程通讯RPC,而且是同步的。另外undo log写入时blob字段的插入性能也是不高的。每条写SQL都会增加这么多开销,粗略估计会增加5倍响应时间。
性价比
为了进行自动补偿,需要对所有交易生成前后镜像并持久化,可是在实际业务场景下,这个是成功率有多高,或者说分布式事务失败需要回滚的有多少比率?按照二八原则预估,为了20%的交易回滚,需要将80%的成功交易的响应时间增加5倍,这样的代价相比于让应用开发一个补偿交易是否是值得?
全局锁
热点数据
相比XA,Seata 虽然在一阶段成功后会释放数据库锁,但一阶段在commit前全局锁的判定也拉长了对数据锁的占有时间,这个开销比XA的prepare低多少需要根据实际业务场景进行测试。全局锁的引入实现了隔离性,但带来的问题就是阻塞,降低并发性,尤其是热点数据,这个问题会更加严重。
回滚锁释放时间
Seata在回滚时,需要先删除各节点的undo log,然后才能释放TC内存中的锁,所以如果第二阶段是回滚,释放锁的时间会更长。
死锁问题
Seata的引入全局锁会额外增加死锁的风险,但如果出现死锁,会不断进行重试,最后靠等待全局锁超时,这种方式并不优雅,也延长了对数据库锁的占有时间。
事务模式
Seata 将为用户提供了 AT、TCC、SAGA 和XA 事务模式,为用户打造一站式的分布式解决方案。AT模式是阿里首推的模式,阿里云上有商用版本的GTS。
XA 事务模式
基于XA协议的两阶段提交
XA是一个分布式事务协议,由Tuxedo提出。XA中大致分为两部分:事务管理器和本地资源管理器。其中本地资源管理器往往由数据库实现,比如Oracle、DB2这些商业数据库都实现了XA接口,而事务管理器作为全局的调度者,负责各个本地资源的提交和回滚。,XA协议比较简单,而且一旦商业数据库实现了XA协议,使用分布式事务的成本也比较低。但是,XA也有致命的缺点,那就是性能不理想,特别是在交易下单链路,往往并发量很高,XA无法满足高并发场景。XA目前在商业数据库支持的比较理想,在mysql数据库中支持的不太理想,mysql的XA实现,没有记录prepare阶段日志,主备切换回导致主库与备库数据不一致。许多nosql也没有支持XA,这让XA的应用场景变得非常狭隘。
XA 模式其实就是 Seata 底层利用了 XA 接口,在一阶段二阶段时自动处理。如一阶段时,XA 的 RM 通过代理用户数据源,创建 XAConnection,进行开启 XA 事务(XA start)和 XA-prepare(此时 XA 的任何操作都会被持久化,即便宕机也能恢复),在二阶段时,TC 通知 RM 进行 XA 分支的 Commit/Rollback 操作。
AT事务模式
AT模式的核心是对业务无侵入,是一种改进后的两阶段提交。
第一阶段
业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。核心在于对业务sql进行解析,转换成undolog,并同时入库。
业务 sql:update product set name = ‘GTS’ where name = ‘TXC’。
一阶段的执行过程对用户是无感知的,用户侧的业务 sql 保持不变,而 AT 模式下一阶段具体发生了什么?接下来,简单说下。
解析 sql 并查询得到前镜像:select id, name, since from product where name = ‘TXC’。
执行业务 sql。
查询执行后的数据作为后镜像:select id, name, since from product where id = 1。
第二阶段
分布式事务操作成功,则TC通知RM异步删除undolog。
分布式事务操作失败,TM向TC发送回滚请求,RM 收到协调器TC发来的回滚请求,通过 XID 和 Branch ID 找到相应的回滚日志记录,通过回滚记录生成反向的更新 SQL 并执行,以完成分支的回滚。
提交:仅需把事务相关信息删除即可(理论上不删除也没问题)。
回滚:取出前镜像进行回滚。
优点
Seata架构的亮点主要有几个:
- 应用层基于SQL解析实现了自动补偿,从而最大程度的降低业务侵入性;
- 将分布式事务中TC(事务协调者)独立部署,负责事务的注册、回滚;
- 通过全局锁实现了写隔离与读隔离。
通过上述简单的例子,其实可以发现,AT 模式就是自动补偿式事务,那 AT 具体都做了哪些呢?下文将会讲述。
AT 如何保证分布式事务一致性?

可能很多人刚看到上图会有疑问,其实这个就是无侵入式 AT 模式的做法示意图。首先用户还是从接口进入,到达事务发起方,此时对业务开发者来说,这个发起方入口就是一个业务接口罢了,一样地执行业务 sql,一样地 return 响应信息给客户端并没有什么改变。而背后就是用户的 sql 被 Seata 代理所托管,Seata-AT 模式能感知到用户的所有 sql,并对之进行操作,来保证一致性。
Seata-AT 是怎么做到无侵入的呢?
 应用启动时 Seata 会自动把用户的 DataSource 代理,对 JDBC 操作熟悉的用户其实对 DataSource 还是比较熟悉的,拿到了 DataSource,就等于掌握了数据源连接,也就能在背后做些“小动作”,此时对用户来讲也是无感知无入侵。
应用启动时 Seata 会自动把用户的 DataSource 代理,对 JDBC 操作熟悉的用户其实对 DataSource 还是比较熟悉的,拿到了 DataSource,就等于掌握了数据源连接,也就能在背后做些“小动作”,此时对用户来讲也是无感知无入侵。
之后业务有请求进来,执行业务 sql 时,Seata 会解析用户的 sql,提取出表元数据,生成前镜像,再通过执行业务 sql,保存执行 sql 后的后镜像(至于后镜像的介绍之后会讲到),生成行锁之后在注册分支时携带到 Seata-Server,也就是 TC 端。
到此为止,在 Client 端的一阶段操作就已经完成了,无感知、无入侵。此时如果思考下,会发现这里其实有一个行锁,这个行锁是干什么用的呢?这就是要接着讲到 Seata-AT 是如何保证分布式下的事务隔离性,这里直接拿官网的示例来说。
写隔离
一阶段本地事务提交前,需要确保先拿到全局锁 。
拿不到全局锁,不能提交本地事务。
拿全局锁的尝试被限制在一定范围内,超出范围将放弃,并回滚本地事务,释放本地锁。
以一个示例来说明:
两个全局事务 tx1 和 tx2,分别对 a 表的 m 字段进行更新操作,m 的初始值 1000。
tx1 先开始,开启本地事务,拿到本地锁,更新操作 m = 1000 - 100 = 900。本地事务提交前,先拿到该记录的全局锁,本地提交释放本地锁。tx2 后开始,开启本地事务,拿到本地锁,更新操作 m = 900 - 100 = 800。本地事务提交前,尝试拿该记录的全局锁,tx1 全局提交前,该记录的全局锁被 tx1 持有,tx2 需要重试等待**全局锁 **。
tx1 二阶段全局提交,释放全局锁 。tx2 拿到全局锁提交本地事务。
如果 tx1 的二阶段全局回滚,则 tx1 需要重新获取该数据的本地锁,进行反向补偿的更新操作,实现分支的回滚。
此时如果 tx2 仍在等待该数据的全局锁,同时持有本地锁,则 tx1 的分支回滚会失败。分支的回滚会一直重试,直到 tx2 的全局锁等锁超时,放弃全局锁并回滚本地事务释放本地锁,tx1 的分支回滚最终成功。
因为整个过程全局锁在 tx1 结束前一直是被 tx1 持有的,所以不会发生脏写的问题。
这个时候隔离性想必大家已经比较明白了,此时一阶段的大部分操作相信大家也比较明白了,接下来我们继续往下一阶段解析。
AT 模式二阶段处理
在二阶段提交时,TC 仅是下发一个通知 :把之前一阶段做记录的 undoLog 删除,并把相关事务信息如:行锁删除,之后让因为在竞争锁被阻塞的事务顺利进行。
而二阶段是回滚时,则要多做一些处理。
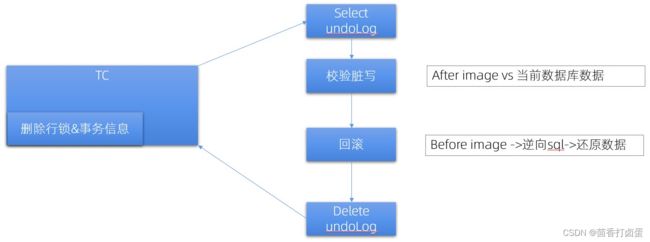 首先在 Client 端收到 TC 告知的二阶段是回滚时,会去查到对应的事务的 undolog,取出后镜像,对比当前的数据(因为 SeataAT 是从业务应用层面进行保护分布式事务,如果此时在数据库层面直接修改了库内信息,这个时候 SeataAT 的行锁不起隔离性作用),如果出现了在全局事务以外的数据修改,此时判定为脏写,而 Seata 因为无法感知这个脏写如何发生,此时只能打印日志和触发异常通知,告知用户需要人工介入(规范修改数据入口可避免脏写)。
首先在 Client 端收到 TC 告知的二阶段是回滚时,会去查到对应的事务的 undolog,取出后镜像,对比当前的数据(因为 SeataAT 是从业务应用层面进行保护分布式事务,如果此时在数据库层面直接修改了库内信息,这个时候 SeataAT 的行锁不起隔离性作用),如果出现了在全局事务以外的数据修改,此时判定为脏写,而 Seata 因为无法感知这个脏写如何发生,此时只能打印日志和触发异常通知,告知用户需要人工介入(规范修改数据入口可避免脏写)。
而如果没有发生脏写就比较简单了,拿出前镜像,众所皆知事务是需要有原子性的,要么一起发生,要么都不发生,此时前镜像记录了发生之前的数据,进行回滚后,就达到了类似本地事务那样的原子性效果。回滚后,再把事务相关信息,如 undolog,行锁进行删除。二阶段回滚算是告一段落了。
既然介绍完了 AT 模式的一阶段及二阶段的原理思想方式,那么 AT 在 Seata 的分布式事务框架下是怎么样的呢?
可以看到,AT 与其它事务模式在 Seata 事务框架中,会多出一个 undolog 的表(相对其它模式的入侵点),但是除此之外,对业务来说,几乎是零入侵性,这也就是为什么 AT 模式在 Seata 中受众广泛的原因。
AT 模式与 Seata 支持的其它二阶段模式区别
首先应该明白,目前为止,不存在有任何一种分布式事务的可以满足所有场景。
无论 AT 模式、TCC 模式还是 Saga 模式,这些模式的提出,本质上都源自 XA 规范对某些场景需求的无法满足。
目前分为 3 点来做出对比:
数据锁定
AT 模式使用全局锁保障基本的写隔离,实际上也是锁定数据的,只不过锁在 TC 侧集中管理,解锁效率高且没有阻塞的问题。
TCC 模式无锁,利用本地事务排他锁特性,可预留资源,在全局事务决议后执行相应操作。
XA 模式在整个事务处理过程结束前,涉及数据都被锁定,读写都按隔离级别的定义约束起来。
死锁(协议阻塞)
XA 模式 prepare 后(老版本的数据库中,需要 XA END 后,再下发 prepare <三阶段由来>),分支事务进入阻塞阶段,收到 XA commit 或 XA rollback 前必须阻塞等待。
AT 可支持降级,因为锁存储在 TC 侧,如果 Seata 出现 bug 或者其它问题,可直接降级,对后续业务调用链无任何影响。
TCC 无此问题。
性能
性能的损耗主要来自两个方面:一方面,事务相关处理和协调过程,增加单个事务的 RT;另一方面,并发事务数据的锁冲突,降低吞吐。其实主要原因就是上面的协议阻塞跟数据锁定造成。
XA 模式它的一阶段不提交,在大并发场景由于锁存储在多个资源方(数据库等),加剧了性能耗损。
AT 模式锁粒度细至行级(需要主键),且所有事务锁存储在 TC 侧,解锁高效迅速。
TCC 模式性能最优,仅需些许 RPC 开销,及 2 次本地事务的性能开销,但是需要符合资源预留场景,且是对业务侵入性较大(需要业务开发者每个接口分为 3 个,一个 try,2 个二阶段使用的 confirm 和 cancel )。
可能很多同学对 XA 和 AT 的锁 & 协议阻塞不是特别理解,那么直接来看下图:
可以试着猜一下是哪个是 XA?其实下图的是 XA,因为它带来的锁粒度更大,且锁定时间更久,导致了并发性能相对 AT 事务模型来说,差的比较多,所以至今XA模式的普及度都不很太高。
总结:关于seata是可以做到对项目代码无入侵,代价是需要部署和维护一个中间件,关于at和xa模式对比从概念上看很难区别,我的理解差异点在于AT模式的隔离就是靠全局锁来保证,粒度细至行级,锁信息存储在Seata-Server一侧。
XA模式的隔离性就是由本地数据库保证,锁存储在各个本地数据库中。由于XA模式一旦执行了prepare后,再也无法重入这个XA事务,也无法跟其他XA事务共享锁。因为XA协议,仅是通过XID来start一个xa事务,本身它不存在所谓的分支事务说法,它本事就是一个XA事务而已,也就是说它只管它自己。at模式的undolog就是把本地事务作用中的undolog,利用他的原理,做到了分布式事务中,来保证了分布式事务下的事务一致性。
目前使用:目前是结合sharding在使用,如xxljob跑任务会用到一些订单实时报价并修改用户订单概览等信息,需要与第三方系统交互,系统就需要保证数据的最终一致性。
流量控制
Sentinel 是面向分布式服务架构的高可用流量防护组件,主要以流量为切入点,从限流、流量整形、熔断降级、系统负载保护、热点防护等多个维度来帮助开发者保障微服务的稳定性。
实现原理
启动并且初始化Sentinel
Sentinel本质上只是一个运行在特殊模式下的Redis服务器,当一个Sentinel启动时,它需要执行以下步骤:
1)初始化服务器。
2)将普通Redis服务器使用的代码替换成Sentinel专用代码。
3)初始化Sentinel状态。
4)根据给定的配置文件,初始化Sentinel的监视主服务器列表。
5)创建连向主服务器的网络连接。
对于每个被Sentinel监视的主服务器来说,Sentinel会创建两个连向主服务器的异步网络连接:
❑一个是命令连接,这个连接专门用于向主服务器发送命令,并接收命令回复。
❑另一个是订阅连接,这个连接专门用于订阅主服务器的__sentinel__:hello频道。
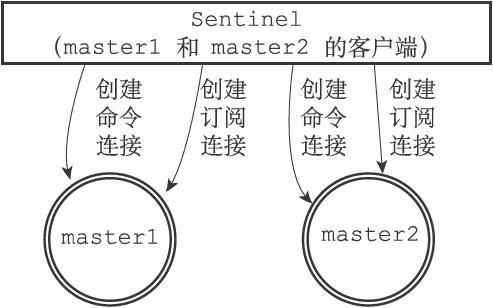
获取主服务器信息
通过分析主服务器返回的INFO命令回复,Sentinel可以获取以下两方面的信息:
❑一方面是关于主服务器本身的信息,包括run_id域记录的服务器运行ID,以及role域记录的服务器角色;
❑另一方面是关于主服务器属下所有从服务器的信息,每个从服务器都由一个"slave"字符串开头的行记录,每行的ip=域记录了从服务器的IP地址,而port=域则记录了从服务器的端口号。根据这些IP地址和端口号,Sentinel无须用户提供从服务器的地址信息,就可以自动发现从服务器。
获取从服务器信息

❑从服务器的运行ID run_id。
❑从服务器的角色role。
❑主服务器的IP地址master_host,以及主服务器的端口号master_port。
❑主从服务器的连接状态master_link_status。
❑从服务器的优先级slave_priority。
❑从服务器的复制偏移量slave_repl_offset。
向主服务器和从服务器发送信息,接收来自主服务器和从服务器的频道信息
对于监视同一个服务器的多个Sentinel来说,一个Sentinel发送的信息会被其他Sentinel接收到,这些信息会被用于更新其他Sentinel对发送信息Sentinel的认知,也会被用于更新其他Sentinel对被监视服务器的认知。
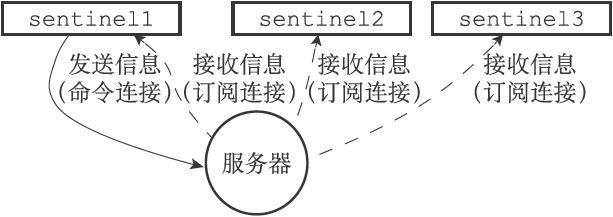
当Sentinel通过频道信息发现一个新的Sentinel时,它不仅会为新Sentinel在sentinels字典中创建相应的实例结构,还会创建一个连向新Sentinel的命令连接,而新Sentinel也同样会创建连向这个Sentinel的命令连接,最终监视同一主服务器的多个Sentinel将形成相互连接的网络:Sentinel A有连向Sentinel B的命令连接,而Sentinel B也有连向Sentinel A的命令连接。
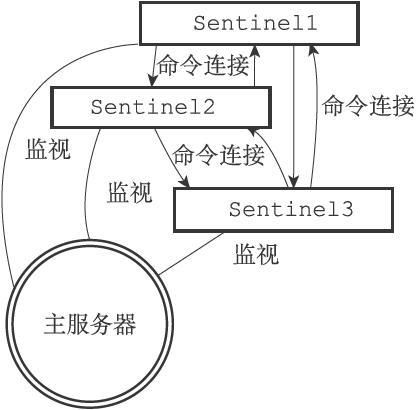
检测主观下线状态
Sentinel配置文件中的down-after-milliseconds选项指定了Sentinel判断实例进入主观下线所需的时间长度:如果一个实例在down-after-milliseconds毫秒内,连续向Sentinel返回无效回复,那么Sentinel会修改这个实例所对应的实例结构,在结构的flags属性中打开SRI_S_DOWN标识,以此来表示这个实例已经进入主观下线状态。多个Sentinel设置的主观下线时长可能不同
检查客观下线状态
当Sentinel将一个主服务器判断为主观下线之后,为了确认这个主服务器是否真的下线了,它会向同样监视这一主服务器的其他Sentinel进行询问,看它们是否也认为主服务器已经进入了下线状态(可以是主观下线或者客观下线)。当Sentinel从其他Sentinel那里接收到足够数量的已下线判断之后,Sentinel就会将从服务器判定为客观下线,并对主服务器执行故障转移操作。当认为主服务器已经进入下线状态的Sentinel的数量,超过Sentinel配置中设置的quorum参数的值,那么该Sentinel就会认为主服务器已经进入客观下线状态。不同Sentinel判断客观下线的条件可能不同。
选举领头的Sentinel
当一个主服务器被判断为客观下线时,监视这个下线主服务器的各个Sentinel会进行协商,选举出一个领头Sentinel,并由领头Sentinel对下线主服务器执行故障转移操作。
以下是Redis选举领头Sentinel的规则和方法:
❑所有在线的Sentinel都有被选为领头Sentinel的资格,换句话说,监视同一个主服务器的多个在线Sentinel中的任意一个都有可能成为领头Sentinel。
❑每次进行领头Sentinel选举之后,不论选举是否成功,所有Sentinel的配置纪元(configuration epoch)的值都会自增一次。配置纪元实际上就是一个计数器,并没有什么特别的。
❑在一个配置纪元里面,所有Sentinel都有一次将某个Sentinel设置为局部领头Sentinel的机会,并且局部领头一旦设置,在这个配置纪元里面就不能再更改。
❑每个发现主服务器进入客观下线的Sentinel都会要求其他Sentinel将自己设置为局部领头Sentinel。
❑当一个Sentinel(源Sentinel)向另一个Sentinel(目标Sentinel)发送SENTINEL is-master-down-by-addr命令,并且命令中的runid参数不是*符号而是源Sentinel的运行ID时,这表示源Sentinel要求目标Sentinel将前者设置为后者的局部领头Sentinel。
❑Sentinel设置局部领头Sentinel的规则是先到先得:最先向目标Sentinel发送设置要求的源Sentinel将成为目标Sentinel的局部领头Sentinel,而之后接收到的所有设置要求都会被目标Sentinel拒绝。
❑目标Sentinel在接收到SENTINEL is-master-down-by-addr命令之后,将向源Sentinel返回一条命令回复,回复中的leader_runid参数和leader_epoch参数分别记录了目标Sentinel的局部领头Sentinel的运行ID和配置纪元。
❑源Sentinel在接收到目标Sentinel返回的命令回复之后,会检查回复中leader_epoch参数的值和自己的配置纪元是否相同,如果相同的话,那么源Sentinel继续取出回复中的leader_runid参数,如果leader_runid参数的值和源Sentinel的运行ID一致,那么表示目标Sentinel将源Sentinel设置成了局部领头Sentinel。
❑如果有某个Sentinel被半数以上的Sentinel设置成了局部领头Sentinel,那么这个Sentinel成为领头Sentinel。举个例子,在一个由10个Sentinel组成的Sentinel系统里面,只要有大于等于10/2+1=6个Sentinel将某个Sentinel设置为局部领头Sentinel,那么被设置的那个Sentinel就会成为领头Sentinel。
❑因为领头Sentinel的产生需要半数以上Sentinel的支持,并且每个Sentinel在每个配置纪元里面只能设置一次局部领头Sentinel,所以在一个配置纪元里面,只会出现一个领头Sentinel。
❑如果在给定时限内,没有一个Sentinel被选举为领头Sentinel,那么各个Sentinel将在一段时间之后再次进行选举,直到选出领头Sentinel为止。
故障转移
1)在已下线主服务器属下的所有从服务器里面,挑选出一个从服务器,并将其转换为主服务器。
2)让已下线主服务器属下的所有从服务器改为复制新的主服务器。
3)将已下线主服务器设置为新的主服务器的从服务器,当这个旧的主服务器重新上线时,它就会成为新的主服务器的从服务器。
新的服务器是怎样挑选出来的?
领头Sentinel会将已下线主服务器的所有从服务器保存到一个列表里面,然后按照以下规则,一项一项地对列表进行过滤:
1)删除列表中所有处于下线或者断线状态的从服务器,这可以保证列表中剩余的从服务器都是正常在线的。
2)删除列表中所有最近五秒内没有回复过领头Sentinel的INFO命令的从服务器,这可以保证列表中剩余的从服务器都是最近成功进行过通信的。
3)删除所有与已下线主服务器连接断开超过down-after-milliseconds10毫秒的从服务器:down-after-milliseconds选项指定了判断主服务器下线所需的时间,而删除断开时长超过down-after-milliseconds10毫秒的从服务器,则可以保证列表中剩余的从服务器都没有过早地与主服务器断开连接,换句话说,列表中剩余的从服务器保存的数据都是比较新的。
之后,领头Sentinel将根据从服务器的优先级,对列表中剩余的从服务器进行排序,并选出其中优先级最高的从服务器。
如果有多个具有相同最高优先级的从服务器,那么领头Sentinel将按照从服务器的复制偏移量,对具有相同最高优先级的所有从服务器进行排序,并选出其中偏移量最大的从服务器(复制偏移量最大的从服务器就是保存着最新数据的从服务器)。
最后,如果有多个优先级最高、复制偏移量最大的从服务器,那么领头Sentinel将按照运行ID对这些从服务器进行排序,并选出其中运行ID最小的从服务器。
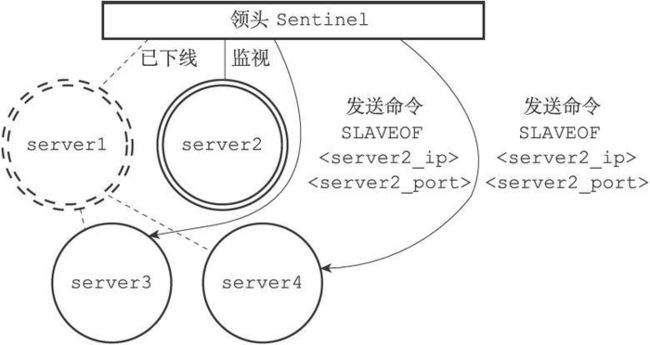
致歉
伙伴们,本来想将所有知识点都写到一篇文章里面,后面发现无法实现,单篇文章字数过多会导致丢失情况,咨询过官方客服,得到的答复是目前也没有其他解决办法,建议分为多篇发,不符合一开始总结成一篇文章的规划。
解决方法:
请移步到GitEE代码仓库查看,完整版地址:
https://gitee.com/java_wxid/java_wxid/blob/master/document/JavaKnowledgeDocument/Java%E9%9D%A2%E8%AF%95.md
作者求关注
用心写文章,希望大家多多关注我哈。
个人技术博客主页:欢迎大家来关注我哟:https://blog.csdn.net/java_wxid
个人开源项目主页:欢迎大家来评价(Star) :https://gitee.com/java_wxid/java_wxid