Hive架构
Hive架构
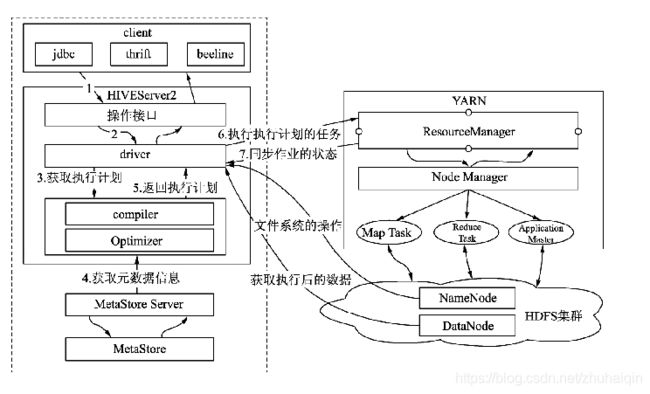
客户端提交SQL作业到HiveServer2,HiveServer2会根据用户提交的SQL作业及数据库中现有的元数据信息生成一份可供计算引擎执行的计划。每个执行计划对应若干MapReduce作业,Hive会将所有的MapReduce作业都一一提交到YARN中,由YARN去负责创建MapReduce作业对应的子任务,并协调它们的运行。YARN创建的子任务会与HDFS进行交互,获取计算所需的数据,计算完成后将最终的结果写入HDFS或者本地。
Hive自身主要包含如下3个部分:
第一部分是客户端(client)。Hive支持多种客户端的连接,包括beeline、jdbc、thrift和HCatalog。早期的Hive Command Line(CLI)由于可以直接操作HDFS存储的数据,权限控制较为困难,支持的用户数有限,已经被废弃。
第二部分是HiveServer2。替代早期的HiveServer,提供了HTTP协议的Web服务接口和RPC协议的thrift服务接口,使得Hive能够接收多种类型客户端的并发访问,并将客户端提交的SQL进行编译转化可供计算引擎执行的作业。 在实际使用中需要注意HiveServre2服务Java堆大小的设置,默认情况下是50MB,在查询任务增多的情况下,容器发生内存溢出,导致服务崩溃,用户访问不了Hive。
第三部分是元数据及元数据服务。Hive的元数据记录了Hive库内对象的信息,包括表的结构信息、分区结构信息、字段信息及相关的统计信息等。
Hive元数据
Hive的元数据保存在Hive的metastore数据中,里面记录着Hive数据库、表、分区和列的一些当前状态信息,通过收集这些状态信息,可以帮助我们更好地监控Hive数据库当前的状态,提前感知可能存在的问题;可以帮助基于成本代价的SQL查询优化,做更为正确的自动优化操作。
在Hive 3.0以后,可以在Hive的sys数据库中找到元数据表。
Hive的元数据主要分为5个大部分:数据库相关的元数据、表相关的元数据、分区相关的元数据、文件存储相关的元数据及其他。
数据库的元数据
DBS:描述Hive中所有的数据库库名、存储地址(用字段DB_LOCATION_URI表示)、拥有者和拥有者类型。Hive可以通过命令“desc database库名”来查询DBS的信息
DATABASE_PARAMS:描述数据库的属性信息(DBPROPERTIES)
create database db_test_pro with dbproperties('key_a'='value_a');
在Hive中可以使用命令“desc database extended db_test_pro;”来查询DBPROPERTIES的信息。
DB_PRIVS:描述数据库的权限信息。
FUNCS:记录用户自己编写的函数信息(UDF),包括该函数的函数名、对应的类名和创建者等信息。用户可以通过命令“create function函数名…”来创建自定义函数。
FUNCS_RU:记录自定义函数所在文件的路径,例如使用Java编写Hive的自定义函数,FUNCS_RU表会记录该函数所在JAR包的HDFS存储位置,以及该JAR包引用的其他JAR包信息。
表的元数据
TBLS:记录Hive数据库创建的所有表,包含表所属的数据库、创建时间、创建者和表的类型(包括内部表、外部表、虚拟视图等)。在Hive中使用命令“desc formatted表名”,查看Detailed Table Information一节的信息。
TABLE_PARAMS:表的属性信息,对应的是创建表所指定的TBLPROPERTIES内容或者通过收集表的统计信息。收集表的统计信息可以使用如下的命令:
Analyze table表名compute statistics
表的统计信息一般包含表存储的文件个数(numFiles)、总文件大小(totalSize)、表的总行数(numRows)、分区数(numPartitions)和未压缩的每行的数据量(rawDataSize)等。
TAB_COL_STATS:表中列的统计信息,包括数值类型的最大和最小值,如LONG_LOW_VALUE、LONG_HIGH_VALUE、DOUBLE_HIGH_VALUE、DOUBLE_LOW_VALUE、BIG_DECIMAL_LOW_VALUE、BIG_DECIMAL_HIGHT_VALUE、空值的个数、列去重的数值、列的平均长度、最大长度,以及值为TRUE/FALSE的个数等。
TBL_PRIVS:表或者视图的授权信息,包括授权用户、被授权用户和授权的权限等。
TBL_COL_PRIVS:表或者视图中列的授权信息,包括授权用户、被授权的用户和授权的权限等。
PARTITION_KEYS:表的分区列。
IDXS:Hive中索引的信息,Hive 3.0已经废弃。
分区的元数据
PARTITIONS:存储分区信息,包括分区列,分区创建的时间。
·PARTITION_PARAMS:存储分区的统计信息,类似于表的统计信息一样。
·PART_COL_STATS:分区中列的统计信息,类似于表的列统计信息一致。
·PART_PRIVS:分区的授权信息,类似于表的授权信息。
PART_COL_PRIVS:分区列的授权信息,类似于表的字段授权信息。
·PARTITION_KEY_VALS:分区列对应的值
数据存储的元数据
SDS:保存数据存储的信息,包含分区、表存储的HDFS路径地址、输入格式(INPUTFORMAT)、输出格式(OUTPUTFORMAT)、分桶的数量、是否有压缩、是否包含二级子目录。
CDS、COLUMN_V2:表示该分区、表存储的字段信息,包含字段名称和类型等。
SORT_COLS:保存Hive表、分区有排序的列信息,包括列名和排序方式等。
·BUCKETING_COLS:保存Hive表,分区分桶列的信息、列名等。
·SERDES:保存Hive表、分区序列化和反序列化的方式。
·SERDES_PARAMS:保存Hive,分区序列化和反序列化的配置属性,例如行的间隔符(line.delim)、字段的间隔符(filed.delim)。
·SKEWED_COL_NAMES:保存表、分区有数据倾斜的列信息,包括列名。
·SKEWED_VALUES:保存表、分区有数据倾斜的列值信息。
·SKEWED_COL_VALUE_LOC_MAP:保存表、分区倾斜列对应的本地文件路径。
·SKEWED_STRING_LIST、SKEWED_STRING_LIST_VALUES:保存表,分区有数据倾斜的字符串列表和值信息。
其他
Hive的元数据还包含很多内容,例如Hive的事务信息、锁信息及权限相关的信息等。在优化的时候比较少用到,