计算机视觉识别原理
图像在计算机中的表现形式

在计算机中,图像是一个三维数组组成的,在数组当中,每一个元素都是一个像素点。

例如上图,32 * 32 * 3
第一个32是图片的长度
第二个32是图片的宽度
最后的3代表图片的颜色通道,彩色的图片颜色通道为3,对应图片上某个像素点的RGB值(0-255),也可以理解为彩色的图片的厚度为3层,第一层对应图片上某个像素点的R值(0-255),第二层对应G值(0-255),第三层对应B值(0-255);黑白的图片颜色通道为1,对应图片上某个像素点的亮度值(0-255)
原本的彩色图片像素大小为32*32=1024个像素点,每个像素点的RGB值的表示方式为(xxx,xxx,xxx)。既然可以理解为彩色图片的厚度为3层,那可以认为每层均有32 * 32=1024个像素点。总共分为三层,总的像素点为32 * 32 * 3 = 3072个像素。
0~1024个像素对应每个像素的R值
1024~2048个像素对应每个像素的G值
2048~3072个像素对应每个像素的B值
得分函数
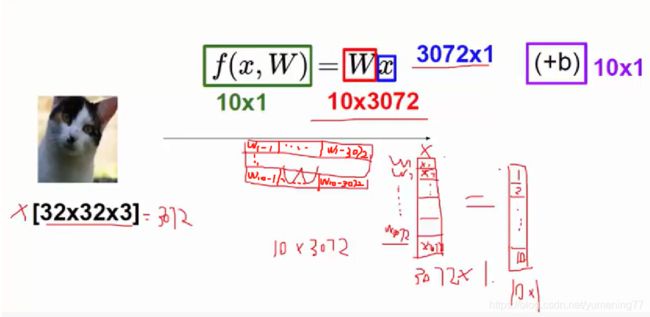
如上图所示,现在拥有了3072个x,把对应的X转为一个(3072,1)的二维矩阵。假设有10个分类,想要得到一个(10,1)的二维矩阵,每个值代表每个分类的得分。那需要用一个(10, 3072)的二维矩阵权重W点乘X,然后再加上一个(10,1)的二维矩阵b。就可以得到线性方程。
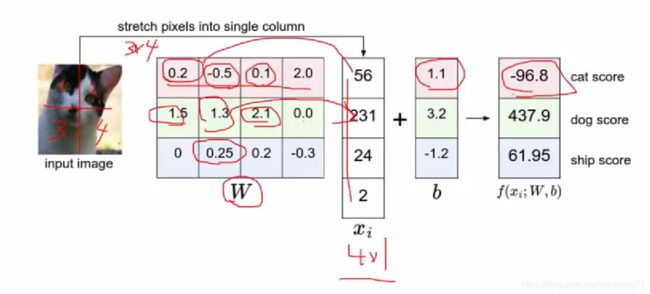
如上图所示,假设输入图片是4个像素点,而且只有一层(黑白图片),四个像素点对应的值分别为56、231、24、2。权重矩阵W和b也如上所示。那就可以得出最后的得分了。
cat的得分为:0.2 * 56 + (-0.5 * 231) + 0.1 * 24 + 2.0 * 2 + 1.1 = -96.8
dog的得分为:1.5 * 56 + 1.3 * 231 + 2.1 * 24 + 0.0 * 2 + 3.2 = 437.9
ship的得分为:0 * 56 + 0.25 * 231 + 0.2 * 24 + (-0.3) * 2 + (-1.2) = 61.95
最后对比哪个分类的得分值高,就判断为哪个分类。这里判断为dog。
SVM损失函数

如上图所示,假设第一张图片为cat,预测分类后的得分如下:
cat得分为:3.2
cat得分为:5.1
frog得分为: -1.7
根据SVM损失函数的公式:
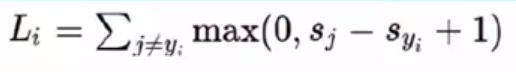
这里的Sj是某个误差分类的得分
Syi是正确分类的得分
1是容忍度的值,可以自定义
定义一个参数k = 预测的误差分类的得分 - 预测的正确分类得分 + 容忍度的值
当前误差分类的损失值为:k 于 0 两者取最大者。
k小于或等于0的情况下,损失函数等于0。k大于0的情况下,损失函数的值等于k。
其实相当于参数k经过神经网络的ReLu激活函数后得到损失函数的值。
损失函数的值就是所有误差分类的损失值总合。
得分函数与SVM损失函数的汇总
如果把得分函数和损失函数联合在一起,再经过N张图片去进行分类测试,得出一个平均的损失值,那么损失函数公式可以转换为:
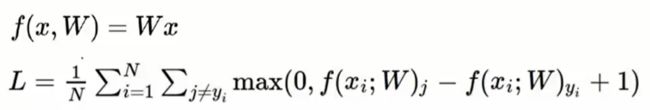
其中N代表测试的图片数量,xi是每一个像素点的特征值(在之前说过彩色图片分三层,第一层对应R特征值,第二层是G特征值,第三层是B特征值。所以像素点是图片实际像素点的三倍),W是对应的权重向量。1是容忍值(可自定义)。

如上图所示,假设某张黑白图片(一层)只有4个像素点,每个像素点的值都是1,对应上图中的x,假设要判断图片是否属于A分类,就需要计算图片属于A分类的得分。
现在要找出A分类对应的权重向量,这里假设有两组w可以进行选择,分别是w1=[1, 0, 0, 0]和w2=[0.25, 0.25, 0.25, 0.25]
根据w点乘x的转置,可以得出两组权重向量最后的得分都是1。由于得分相同,损失函数的值也相同。
但其实对比w1和w2可以发现,w1只考虑了第一个像素点特征值的情况,其他三个像素点对应的特征值,并不影响它最后的得分,这样其实是不太好的,因为容易出现过拟合的现象(在训练集的时候效果不错,但是测试集就不太理想),如果某些测试图片的第一个像素点的特征值和实际特征有一定的偏差,即使其他像素点的特征值都很贴近实际的特征值,也会直接导致最后的得分存在较大的误差。
而w2考虑了多个像素点的特征值,如果某些测试图片其中一个像素点的特征值和实际特征值有一定的偏差,而其他的像素点的特征值很贴近实际的特征值,那最后的得分也只会存在较小的误差。
所以我们会更倾向于选择w2模型。
正则化
由于两种模型的得分都相同,损失函数得出的loss值也相同,所以需要引入正则化惩罚项,对不同模型的loss值进行不同程度的增加,选出更理想的模型。
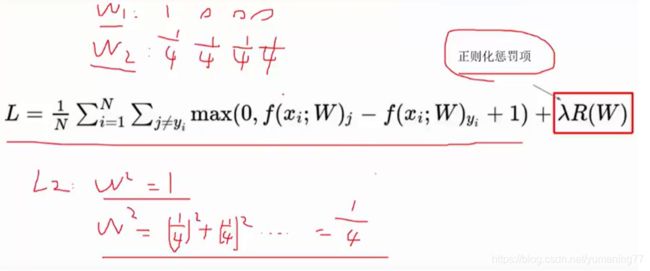
如上图所示,假设我们引入L2正则化,表达式如下:
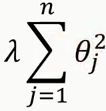
这里的θj对应w中的每个权重参数
假设λ = 1, w1=[1, 0, 0, 0]的L2正则化惩罚项的值为 1 * (1^2 + 0^2 + 0^2 + 0^2) = 1
w2=[0.25, 0.25, 0.25, 0.25]的L2正则化惩罚项的值为 1 * (0.25^2 + 0.25^2 + 0.25^2 + 0.25^2) = 0.25
所以,w1模型的损失函数的值后面会加上1,而w2模型的损失函数的值后面只会加上0.25。w1的损失函数值大于w2,这样,我们就能选择出损失函数较小的w2模型。
SVM分类器最终的损失函数表达式为:
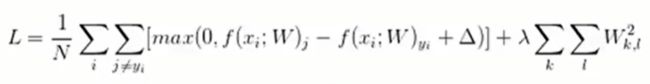
N是测试图片的数量,i表示当前图片,j是表示当前分类,yi表是正确的分类,Δ是容忍度,λ是正则化系数,k和ι分别表示W矩阵的行和列。
softmax分类器



如上图所示,得分情况如下:
cat 3.2
car 5.1
frog -1.7
把这几个分类的得分分别作为e的指数,保留一位小数,可以得到:
cat = e^3.2 = 24.5
car = e^5.1 = 164.0
frog = e^-1.7 = 0.18
再把上面的数据进行归一化, 就可以得到每个分类的概率,保留两位小数:
cat = 24.5/(24.5 + 164 + 0.18) = 0.13
car = 164/(24.5 + 164 + 0.18) = 0.87
frog = 0.18/(24.5 + 164 + 0.18) = 0.00
所以,softmax这种分类器,最终得到的是一个概率值
softmax的损失函数
softmax的损失函数需要用正确分类概率值p,去算出误差值,这里是让概率值经过函数-log ( p ),例如:
loss = -log(0.13) = 0.89
loss值随p值的增加的减小,当p等于1时,loss=0;当p=0时,loss为无穷大。
SVM和softmax对比
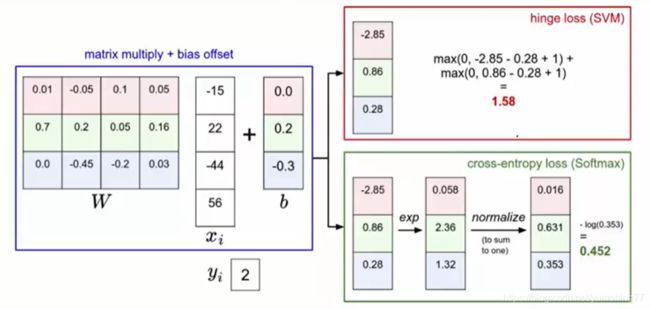
如上图所示,SVM的loss值为1.58,fostmax的loss值为0.452。可以看到两种分类器的误差值是不同的。
但是,如果在某些情况下,错误的分类得分很接近于正确分类的得分,假设两个错误的分类得分都是9,而正确分类的得分是10,容忍度是1。
SVM分类器:
loss = max(0, 9-10+1) + max(0, 9-10+1) = 0
其实分类的效果并不是很好,错误的分类得分比较接近正确的分类得分。但是因为loss已经为0,无法根据误差反向传递去优化模型。
softmax分类器:
e^9 = 8103
e^9 = 8103
e^10 = 22026
p = 22026 / (8103 + 8103 + 22026) = 0.58 #保留两位小数
loss = -log(0.58) = 0.237 #保留三位小数
由于loss不为0,在这种情况下,可以继续通过误差反向传递的方式继续优化模型。
只要真实分类的概率p不为1,softmax都可以得出一个损失值,所以softmax是一个永远不知道满足的分类器。
总结
首先把图像转为像素点,再提取每个像素点的RGB值(黑白图片则是亮度值),通过上述的得分函数WX + b 得到线性方程,再通过包含正则化惩罚项与任意一种分类器的损失函数得出对应的loss值,就可以通过误差反向传递的方式。得出最佳的W和b,这样就把一个图像分类的问题转化为了回归问题。