却话文心一言(Chatgpt们),存算一体真能突破AI算力“存储墙”|“能耗墙”|“编译墙”?
文心一言折戟沉沙
作为国内搜索引擎巨头玩家,百度在中文语料领域拥有大量的积累,在算力基础设施等层面也拥有优势。
但是国产化AI芯片的处境其实很难。
这不是危言耸听,也不是崇洋媚外。这不,百度文心一言初战吃瘪。

图1. 文心一言发布会李彦宏展示文心一言
预热良久的文心一言发布会开始后,百度集团股价跌幅一度高达9%。甚至有人调侃,百度让股价涨起来的唯一办法是最后宣布,发布会上的李彦宏不是真人,其实是文心一言冒充的。
这种调侃之言看似玩笑,但文心一言所展示出的实际效果,与市场和百度高层预期相差甚远。
文心一言的功能表现,最精辟的莫过于:除了中文,没有亮点。
现场演示变成提前准备,直播了一次录播,可见文心一言并没有做好准备,在无法确定实时生成表现和排除Bug的情况下,选择了最保险也是最露怯的办法。
看看文心一言画图: 画作能力上可谓是画功了得,但理解能力真心差。

图2. 实际体验文心一言画图功能
chatGPT们算力需求
对百度而言,文心一言最重要的战略意义是为云计算铺路。这可能是百度着急要把产品公示的主要原因。
不过智能云搭上AI快车的前提是,百度能否扛下巨大的成本压力。
AI计算需要大规模采购GPU算力,据估算,一次完整的模型训练成本超过1200万美元。
为支持文心一言的超大规模计算需求,近期百度智能云频繁公布文心一言配套设施的准备情况,包括升级智算中心。
ChatGPT类应用铺开将驱动全球算力规模快速提升,并拉动关键底层AI芯片的需求同频增长。中国信息通信研究院等机构预测,至2030年全球算力规模将扩大到56 Zflops,对应2021-2030年CAGR~65%,且届时智能算力规模将占90%以上。
由ChatGPT引发的新一轮AI浪潮来袭,百度、阿里巴巴、腾讯、科大讯飞等科技企业都在加码推进自己的通用大模型。大模型训练对算力资源提出极大需求,根据OpenAI数据,GPT-3的参数量达到1750亿,预训练数据超过45TB,需要的算力资源达到3.14E23FLOPS。
这既是对算力, 也是对存储提出了极大的挑战。
ChatGPT们 AI算力瓶颈
ChatGPT们正提出“极为离谱、不切实际”的算力需求,而芯片们又陷入先进制程升级濒临极限、能效比提升受阻等困境,时代正呼吁着新鲜的血液注入AI大算力芯片。
算力本身就因摩尔定律失效在加速狂飙,每5-10个月就要翻倍
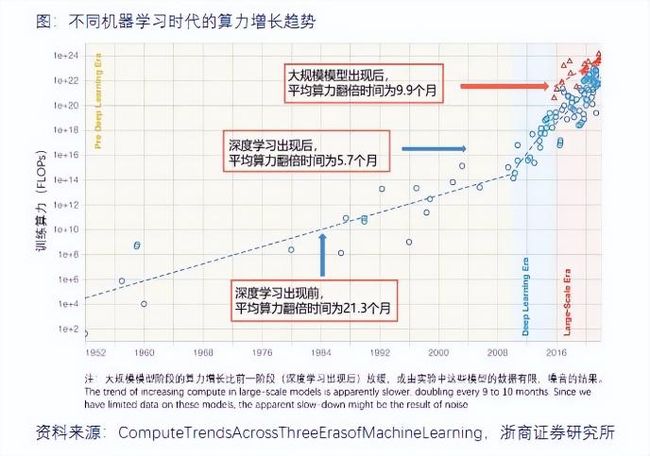
图3. 不同机器学习时代算力增长趋势
AI算力尤其是大算力出现困局。
在传统计算机的设定里,存储模块是为计算服务的,因此设计上会考虑存储与计算的分离与优先级。由于数据需要频繁地在存储、计算单元间来回跑,随着数据越增越多,“存储墙”、 “能耗墙”、“编译墙”等问题也愈发严重。
现如今,这“三堵墙”已导致大量算力无谓浪费:据统计,在大算力的AI应用中,数据搬运操作消耗90%的时间和功耗,数据搬运的功耗是运算的650倍。“存储墙”成为了数据计算应用的一大障碍。特别是,深度学习加速的最大挑战就是数据在计算单元和存储单元之间频繁的移动。
AI算力需求如脱缰的野马,但FPGA、ASIC、GPGPU等芯片本身,已苦于先进制程久矣。据芯粒说表示,目前芯片先进制程升级面临着性能极限、技术极限、成本极限。成本极限具体来说就是,到了5nm以下,建造一座先进制程的晶圆厂动辄需要上百亿美元的投入。在摩尔定律几近终结、ASIC、FPGA以及GPGPU架构能效比难以提升。
存算一体为AI 算力排忧
存算一体架构计算为AI大算力困局“排忧解难”
存算一体架构,将存储和计算的融合,能够打破传统架构下的三堵墙,彻底消除访存延迟,并极大降低功耗。同时,由于计算完全耦合于存储,因此可以开发更细粒度的并行性,获得更高的性能和能效。
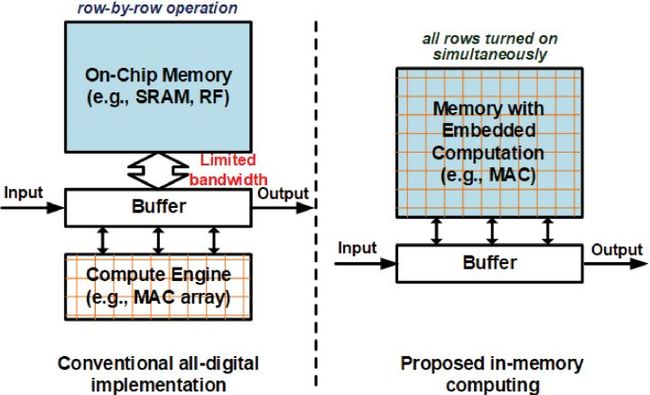
图4. 存算一体与传统计算架构区别
在最接近数据存储的地方进行计算。
存算一体的优势
存算一体的优势是打破存储墙,消除不必要的数据搬移延迟和功耗,并使用存储单元提升算力,成百上千倍的提高计算效率,降低成本。
存算一体属于非冯诺伊曼架构,在特定领域可以提供更大算力(1000TOPS以上)和更高能效(超过10-100TOPS/W),明显超越现有ASIC算力芯片。
核心优势包括:
减少不必要的数据搬运。(降低能耗至1/10~1/100)
使用存储单元参与逻辑计算提升算力。(等效于在面积不变的情况下规模化增加计算核心数)
存算技术路线演进
• 查存计算(Processing With Memory):GPU中对于复杂函数就采用了这种计算方法,是早已落地多年的技术。通过在存储芯片内部查表来完成计算操作。这是最早期的技术。
• 近存计算(Computing Near Memory):计算操作由位于存储区域外部的独立计算芯片/模块完成。这种架构设计的代际设计成本较低,适合传统架构芯片转入。将HBM内存(包括三星的HBM-PIM)与计算模组(裸Die)封装在一起的芯片也属于这一类。近存计算技术早已成熟,被广泛应用在各类CPU和GPU上。
• 存内计算(Computing In Memory):计算操作由位于存储芯片/区域内部的独立计算单元完成,存储和计算可以是模拟的也可以是数字的。这种路线一般用于算法固定的场景算法计算。
• 存内逻辑(Logic In Memory):这是较新的存算架构,典型代表包括TSMC(在2021 ISSCC发表)和千芯科技。这种架构数据传输路径最短,同时能满足大模型的计算精度要求。通过在内部存储中添加计算逻辑,直接在内部存储执行数据计算。
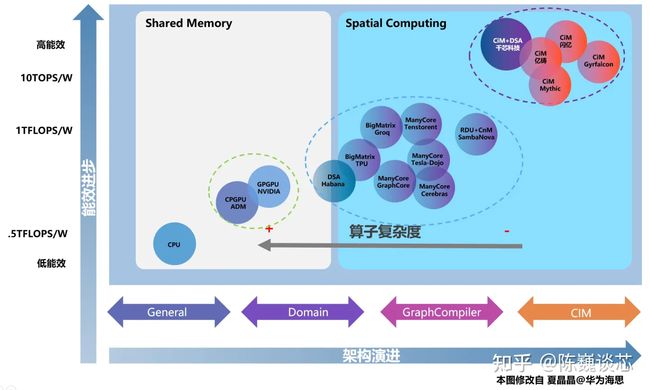
图5. 存算技术架构演进
存算一体怎么落地AI计算
通过使用存算一体技术,可将带AI计算的中大量乘加计算的权重部分存在存储单元中,在存储单元的核心电路上做修改,从而在读取的同时进行数据输入和计算处理,在存储阵列中完成卷积运算。由于大量乘加的卷积运算是深度学习算法中的核心组成部分,因此存内计算和存内逻辑非常适合人工智能的深度神经网络应用和基于AI的大数据技术。
结束语
一方面,ChatGPT等大模型的发展对算力提出了史无前例的要求,吞噬着算力与能源;
另一方面,ChatGPT也为存算一体架构、超异构等技术带来核级推动力。无论是大厂和初创公司,都在为突破算力瓶颈“奋力一搏”。
作为国内搜索引擎巨头玩家,百度在中文语料领域拥有大量的积累。文心一言生成式AI的爆发,引发的海量数据等为算力需求提出了新的挑战。要突破算力困境, 一方面要承受巨大的投入成本, 另一方面要从架构突破,存算一体是一个启发方向。
明天的明天是怎样, 交给时间吧~
参考:
[1] 李彦宏用力过猛,文心一言初战吃瘪_凤凰网财经_凤凰网 (ifeng.com)
[2] 对阵ChatGPT们,存算一体超异构突破算力天花板在即-商业-金融界 (jrj.com.cn)
[3] 算力板块走强 多股涨超5% 机构:ChatGPT类应用铺开驱动算力规模快速提升 _ 东方财富网 (eastmoney.com)
[4] 文心一言背后的语言大模型是如何炼成的?_财经网 - CAIJING.COM.CN
[5] 存算一体技术是什么?发展史、优势、应用方向、主要介质(收录于存算一体芯片赛道投资融资分析/20220517更新) - 知乎 (zhihu.com)