1. 预备知识
2. 容器技术原理
1. 什么是容器
- 容器:一个视图隔离、资源可限制、独立文件系统的进程集合。
- 镜像:运行容器所需要的所有文件集合,build once, run anywhere。
- Docker:开源的应用容器引擎,Docker跟传统的虚拟化方式相比具有系统资源高效利用、快速启动、快速交付部署和简单管理等优势。
- 革命性优势:使我们应用具有一个完整的、自包含的定义方式,从而能够敏捷的、可扩展、可复制的方式发布在云上,发挥出云的能力。
2. Docker的技术原理

- 资源视图隔离:namespace
- 控制资源使用率:cgroup
- 独立的文件系统:chroot
2.1 Namespaces
命名空间(namespaces)是 Linux 为我们提供的用于分离进程树、网络接口、挂载点以及进程间通信等资源的方法。我们没有运行多个完全分离的服务器的需要,但是希望运行在同一台机器上的不同服务能做到完全隔离。Docker 其实就通过 Linux 的 Namespaces 对不同的容器实现了隔离。
# 进程
- Linux的上帝进程 idle 创建出来两个进程,pid=1 的 /sbin/init 进程,负责执行内核的一部分初始化工作和系统配置;pid=2的 kthreadd 进程,负责管理和调度其他的内核进程。
 Linux系统进程
Linux系统进程
 Docker系统进程
Docker系统进程- 创建新进程时传入 CLONE_NEWPID ,使用命名空间实现进程的隔离,Docker 容器内部的任意进程都对宿主机器的进程一无所知。当我们每次运行 docker run 或者 docker start 时,都会在下面的方法中创建一个用于设置进程间隔离的 Spec。
func (daemon *Daemon) createSpec(c *container.Container) (*specs.Spec, error) {
s := oci.DefaultSpec()
// ...
if err := setNamespaces(daemon, &s, c); err != nil {
return nil, fmt.Errorf("linux spec namespaces: %v", err)
}
return &s, nil
}
# 网络
- Docker 可以通过宿主机的网络与整个互联网相连,提供了四种不同的网络模式,Host、Container、None 和 Bridge 模式。
默认的网络模式是网桥模式, Docker在主机上启动之后会创建新的虚拟网桥 docker0,随后在该主机上启动的全部服务在默认情况下都与该网桥相连。docker0 会为每一个容器分配一个新的 IP 地址并将 docker0 的 IP 地址设置为默认的网关。网桥 docker0 通过 iptables 中的配置与宿主机器上的网卡相连,所有符合条件的请求都会通过 iptables 转发到 docker0 并由网桥分发给对应的机器。
 网桥模式
网桥模式
 容器内部端口的数据包转发
容器内部端口的数据包转发容器的网络模型由 Sandbox、Endpoint 和 Network组件组成。每一个容器内部都包含一个 Sandbox,其中存储着当前容器的网络栈配置,包括容器的接口、路由表和 DNS 设置,Linux 使用网络命名空间实现这个 Sandbox,每一个 Sandbox 中都可能会有一个或多个 Endpoint,在 Linux 上就是一个虚拟的网卡 veth。
 容器的网络模型
容器的网络模型为了避免Docker容器中的进程能够访问或者修改宿主机器上的其他目录,我们需要在新的进程中创建隔离的挂载点命名空间需要在 clone 函数中传入 CLONE_NEWNS,这样子进程就能得到父进程挂载点的拷贝(如果不传入这个参数子进程对文件系统的读写都会同步回父进程以及整个主机的文件系统)。
如果一个容器需要启动,那么它一定需要提供一个根文件系统(rootfs),容器需要使用这个文件系统来创建一个新的进程,同时挂载几个特定的目录,并建立一些符号链接保证系统 IO 不会出现问题。
 rootfs中挂载的特定目录
rootfs中挂载的特定目录
 符号链接
符号链接- 在 Linux 系统中,系统默认的目录就都是以 / 也就是根目录开头的,chroot 的使用能够改变当前的系统根目录结构,通过改变当前系统的根目录,我们能够限制用户的权利,在新的根目录下并不能够访问旧系统根目录的结构个文件,也就建立了一个与原系统完全隔离的目录结构;
2.2 Control Groups
 命名空间不能为我们提供物理资源上的隔离
命名空间不能为我们提供物理资源上的隔离
CGroup 是 Control Groups 的缩写,是 Linux 内核提供的一种可以限制、记录、隔离进程组 (process groups) 所使用的物力资源 (如CPU、内存、磁盘 I/O 和网络带宽等等) 的机制。每一个 CGroup 都是一组被相同的标准和参数限制的进程,不同的 CGroup 之间是有层级关系的,也就是说它们之间可以从父类继承一些用于限制资源使用的标准和参数。
 从父类继承用于限制资源使用的标准和参数
从父类继承用于限制资源使用的标准和参数所有的资源控制都是以 CGroup 作为单位实现的,每一个进程都可以随时加入一个 CGroup 也可以随时退出一个 CGroup。9c3057f 其实就是我们运行的一个 Docker 容器,启动这个容器时,Docker 会为这个容器创建一个与容器标识符相同的 CGroup,在当前的主机上 CGroup 就会有以下的层级关系:
 CGroup的层级关系
CGroup的层级关系- 每一个 CGroup 下面都有一个 tasks 文件,其中存储着属于当前控制组的所有进程的 pid,作为负责 cpu 的子系统,cpu.cfs_quota_us 文件中的内容能够对 CPU 的使用作出限制,如果当前文件的内容为 50000,那么当前控制组中的全部进程的 CPU 占用率不能超过 50%。当我们使用 Docker 关闭掉正在运行的容器时,Docker 的子控制组对应的文件夹也会被 Docker 进程移除。
$ docker run -it -d --cpu-quota=50000 busybox
53861305258ecdd7f5d2a3240af694aec9adb91cd4c7e210b757f71153cdd274
$ cd 53861305258ecdd7f5d2a3240af694aec9adb91cd4c7e210b757f71153cdd274/
$ ls
cgroup.clone_children cgroup.event_control cgroup.procs cpu.cfs_period_us cpu.cfs_quota_us cpu.shares cpu.stat notify_on_release tasks
$ cat cpu.cfs_quota_us
50000
2.3 Union FileSystem
- Docker 镜像本质就是一个压缩包。Docker 使用了一系列不同的存储驱动管理镜像内的文件系统并运行容器,Docker 中的每一个镜像都是由一系列只读的层组成的,Dockerfile 中的每一个命令都会在已有的只读层上创建一个新的层,当镜像被 docker run 命令创建时就会在镜像的最上层添加一个可写的层,也就是容器层,所有对于运行时容器的修改其实都是对这个容器读写层的修改。
 一个拥有四层 layer 的镜像
一个拥有四层 layer 的镜像每一个镜像层都是建立在另一个镜像层之上的,同时所有的镜像层都是只读的,只有每个容器最顶层的容器层才可以被用户直接读写,所有的容器都建立在一些底层服务(Kernel)上,包括命名空间、控制组、rootfs 等等,这种容器的组装方式提供了非常大的灵活性,只读的镜像层通过共享也能够减少磁盘的占用。
 组装过程
组装过程容器和镜像的区别就在于,所有的镜像都是只读的,而每一个容器其实等于镜像加上一个可读写的层,也就是同一个镜像可以对应多个容器。
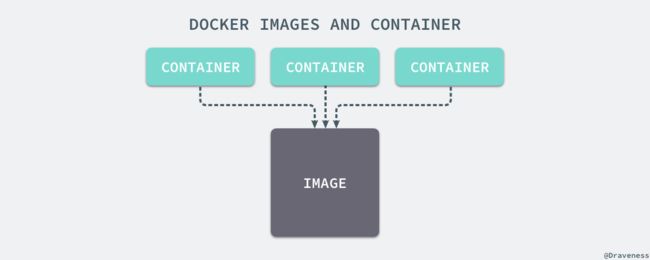 容器和镜像的区别
容器和镜像的区别
3. 容器的部署
容器部署时代: 容器具有轻量级的隔离属性,可以在应用程序之间共享操作系统(OS),具有自己的文件系统、CPU、内存、进程空间等。由于它们与基础架构分离,因此可以跨云和 OS 分发进行移植。主要优势:
- 敏捷应用程序的创建和部署:与使用 VM 镜像相比,提高了容器镜像创建的简便性和效率。
- 持续开发、集成和部署:通过快速简单的回滚 (由于镜像不可变性),提供可靠且频繁的容器镜像构建和部署。
- 关注开发与运维的分离:在构建/发布时而不是在部署时创建应用程序容器镜像,从而将应用程序与基础架构分离。
- 可观察性不仅可以显示操作系统级别的信息和指标,还可以显示应用程序的运行状况和其他指标信号。
- 跨开发、测试和生产的环境一致性:在便携式计算机上与在云中相同地运行。
- 云和操作系统分发的可移植性:可在 Ubuntu、RHEL、CoreOS、本地、Google Kubernetes Engine 和其他任何地方运行。
- 以应用程序为中心的管理:提高抽象级别,从在虚拟硬件上运行 OS 到使用逻辑资源在 OS 上运行应用程序。
- 松散耦合、分布式、弹性、解放的微服务:应用程序被分解成较小的独立部分,并且可以动态部署和管理 - 而不是在一台大型单机上整体运行。
- 资源隔离:可预测的应用程序性能。
- 资源利用:高效率和高密度
4. Kubernetes的技术原理
Kubernetes是一款开源容器化编排系统,目标旨在消除编排物理 / 虚拟计算,网络和存储基础设施的负担,并使应用程序运营商和开发人员完全将重点放在以容器为中心的原语上进行自助运营。本质是应用的生命周期管理,具体来说就是部署和管理(扩缩容、自动恢复、发布),为微服务提供了可扩展、高弹性的部署和管理平台。
Kubernetes 在容器编排的成功不止得益于 Google 的光环和 CNCF(云原生计算基金会)的努力运作。背后是其在 Google Borg 大规模分布式资源调度和自动化运维领域的沉淀和升华。
Kubernetes提供:
- 服务发现和负载均衡
Kubernetes 可以使用 DNS 名称或自己的 IP 地址公开容器,如果到容器的流量很大,Kubernetes 可以负载均衡并分配网络流量,从而使部署稳定。 - 存储编排
Kubernetes 允许您自动挂载您选择的存储系统,例如本地存储、公共云提供商等。 - 自动部署和回滚
您可以使用 Kubernetes 描述已部署容器的所需状态,它可以以受控的速率将实际状态更改为所需状态。例如,您可以自动化 Kubernetes 来为您的部署创建新容器,删除现有容器并将它们的所有资源用于新容器。 - 自动二进制打包
Kubernetes 允许您指定每个容器所需 CPU 和内存(RAM)。当容器指定了资源请求时,Kubernetes 可以做出更好的决策来管理容器的资源。 - 自我修复
Kubernetes 重新启动失败的容器、替换容器、杀死不响应用户定义的运行状况检查的容器,并且在准备好服务之前不将其通告给客户端。 - 密钥与配置管理
Kubernetes 允许您存储和管理敏感信息,例如密码、OAuth 令牌和 ssh 密钥。您可以在不重建容器镜像的情况下部署和更新密钥和应用程序配置,也无需在堆栈配置中暴露密钥
4.1 整体架构
4.2 集群与组件
一个 Kubernetes 集群由一组被称作节点的机器组成。这些节点上运行 Kubernetes 所管理的容器化应用。集群具有至少一个工作节点。每个节点包含运行 Pods 所需的服务,这些节点由控制面负责管理。
# 控制面组件
控制平面的组件对集群做出全局决策(比如调度),以及检测和响应集群事件(例如,当不满足部署的 replicas 字段时,启动新的 pod)。控制平面组件可以在集群中的任何节点上运行。 然而,为了简单起见,设置脚本通常会在同一个计算机上启动所有控制平面组件, 并且不会在此计算机上运行用户容器。
- kube-apiserver,API 服务器负责提供 HTTP API,使你可以查询和操纵 Kubernetes API 中对象(例如:Pod、Namespace、ConfigMap 和 Event)的状态。大部分操作都可以通过 kubectl 命令行接口或 类似 kubeadm 这类命令行工具来执行, 这些工具在背后也是调用 API。
- etcd,兼具一致性和高可用性的键值数据库,可以作为保存 Kubernetes 所有集群数据的后台数据。
- kube-scheduler,负责监视新创建的、未指定运行节点(node)的 Pods,选择节点让 Pod 在上面运行。调度决策考虑的因素包括单个 Pod 和 Pod 集合的资源需求、硬件/软件/策略约束、亲和性和反亲和性规范、数据位置、工作负载间的干扰和最后时限。
- kube-controller-manager,从逻辑上讲,每个控制器都是一个单独的进程, 但是为了降低复杂性,它们都被编译到同一个可执行文件,并在一个进程中运行。这些控制器包括:
- 节点控制器(Node Controller): 负责在节点出现故障时进行通知和响应
- 任务控制器(Job controller): 监测代表一次性任务的 Job 对象,然后创建 Pods 来运行这些任务直至完成
- 端点控制器(Endpoints Controller): 填充端点(Endpoints)对象(即加入 Service 与 Pod)
- 服务帐户和令牌控制器(Service Account & Token Controllers): 为新的命名空间创建默认帐户和 API 访问令牌
- cloud-controller-manager,云控制器管理器使得你可以将你的集群连接到云提供商的 API 之上, 并将与该云平台交互的组件同与你的集群交互的组件分离开来。
Node组件
- kubelet,是集群中每个节点上运行的代理。 它保证容器都运行在 Pod 中。kubelet 接收一组通过各类机制提供给它的 PodSpecs,确保这些 PodSpecs 中描述的容器处于运行状态且健康。 kubelet 不会管理不是由 Kubernetes 创建的容器。
- kube-proxy,是集群中每个节点上运行的网络代理, kube-proxy 维护节点上的网络规则。这些网络规则允许从集群内部或外部的网络会话与 Pod 进行网络通信。
- 容器运行时,容器运行环境是负责运行容器的软件。Kubernetes 支持多个容器运行环境: Docker、 containerd、CRI-O 以及任何实现 Kubernetes CRI (容器运行环境接口)。
OCI规范(Open Container Initiative 开放容器标准),该规范包含两部分内容:容器运行时标准(runtime spec)、容器镜像标准(image spec);
OCI规范
4.3 Pod
Pod(就像在鲸鱼荚或者豌豆荚中)是一组(一个或多个) 容器,是在 Kubernetes 中创建和管理的、最小的可部署的计算单元。
- 运行单个容器的 Pod。"每个 Pod 一个容器"模型是最常见的 Kubernetes 用例; 在这种情况下,可以将 Pod 看作单个容器的包装器,并且 Kubernetes 直接管理 Pod,而不是容器。
- 运行多个协同工作的容器的 Pod。 Pod 可能封装由多个紧密耦合且需要共享资源的共处容器组成的应用程序。 这些位于同一位置的容器可能形成单个内聚的服务单元 —— 一个容器将文件从共享卷提供给公众, 而另一个单独的“边车”(sidecar)容器则刷新或更新这些文件。 Pod 将这些容器和存储资源打包为一个可管理的实体。
说明:重启 Pod 中的容器不应与重启 Pod 混淆。 Pod 不是进程,而是容器运行的环境。 在被删除之前,Pod 会一直存在。
# 标签(Label)和选择算符(Selector)
标签是附加到 Kubernetes 对象(比如 Pods)上的键值对。 标签旨在用于指定对用户有意义且相关的对象的标识属性,但不直接对核心系统有语义含义。 标签可以用于组织和选择对象的子集。与名称和UID不同,标签不支持唯一性。通常,我们希望许多对象携带相同的标签。
- 例1:Pod 要选择指定节点,选择带有标签 "
accelerator=nvidia-tesla-p100"的节点。
apiVersion: v1
kind: Pod
metadata:
name: cuda-test
spec:
containers:
- name: cuda-test
image: "k8s.gcr.io/cuda-vector-add:v0.1"
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
accelerator: nvidia-tesla-p100
- 例2:通过 REST 客户端用于 list 或者 watch 资源,基于等值、基于集合均可。
kubectl get pods -l 'environment in (production),tier in (frontend)'
# 生命期
Pod 是相对临时性(而不是长期存在)的实体。 Pod 会被创建、赋予一个唯一的 ID(UID), 并被调度到节点,并在终止或删除之前一直运行在该节点。一旦调度器将 Pod 分派给某个节点,kubelet 就通过 容器运行时 开始为 Pod 创建容器。 容器的状态有三种:Waiting(等待)、Running(运行中)和 Terminated(已终止)。
| 取值 | 描述 |
|---|---|
| Pending(悬决) | Pod 已被 Kubernetes 系统接受,但有一个或者多个容器尚未创建亦未运行。此阶段包括等待 Pod 被调度的时间和通过网络下载镜像的时间 |
| Running(运行中) | Pod 已经绑定到了某个节点,Pod 中所有的容器都已被创建。至少有一个容器仍在运行,或者正处于启动或重启状态。 |
| Succeeded(成功) | Pod 中的所有容器都已成功终止,并且不会再重启。 |
| Failed(失败) | Pod 中的所有容器都已终止,并且至少有一个容器是因为失败终止。也就是说,容器以非 0 状态退出或者被系统终止。 |
| Unknown(未知) | 因为某些原因无法取得 Pod 的状态。这种情况通常是因为与 Pod 所在主机通信失败。 |
资源的控制器能够处理副本的管理、上线,并在 Pod 失效时提供自愈能力。
如果一个节点失败,控制器注意到该节点上的 Pod 已经停止工作, 就可以创建替换性的 Pod。调度器会将替身 Pod 调度到一个健康的节点执行。如果容器中的进程能够在遇到问题或不健康的情况下自行崩溃,则不一定需要存活探针;kubelet 将根据 Pod 的restartPolicy 自动执行正确的操作。失败的容器由 kubelet 以五分钟为上限的指数退避延迟(10秒,20秒,40秒...)重新启动。
Pod 的
spec中包含一个restartPolicy字段(适用于 Pod 中的所有容器),其可能取值包括 Always、OnFailure 和 Never。默认值是 Always。
- 存活探针,如果您希望容器在探测失败时被杀死并重新启动,那么请指定一个存活探针,并指定
restartPolicy为 Always 或 OnFailure。存活探针由 kubelet 来执行,因此所有的请求都在 kubelet 的网络命名空间中进行。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- args:
- /server
image: k8s.gcr.io/liveness
livenessProbe:
httpGet:
# when "host" is not defined, "PodIP" will be used
# host: my-host
# when "scheme" is not defined, "HTTP" scheme will be used. Only "HTTP" and "HTTPS" are allowed
# scheme: HTTPS
path: /healthz
port: 8080
httpHeaders:
- name: X-Custom-Header
value: Awesome
initialDelaySeconds: 15
timeoutSeconds: 1
name: liveness
- 就绪探针,如果要仅在探测成功时才开始向 Pod 发送流量,请指定就绪探针。
# 网络模型
- Kubernetes的三种IP
- Node IP:是Kubernetes集群中节点的物理网卡IP地址(一般为内网),属于这个网络的服务器之间都可以直接通信,所以Kubernetes集群外要想访问Kubernetes集群内部的某个节点或者服务,肯定得通过Node IP进行通信。
- Pod IP:一个 Pod 一个 IP,它是Docker Engine根据docker0网桥的IP地址段进行分配的。你不需要处理容器端口到主机端口之间的映射。 这将形成一个干净的、向后兼容的模型。
- Cluster IP:是一个虚拟的IP,仅仅作用于Kubernetes Service这个对象,由Kubernetes自己来进行管理和分配地址,当然我们也无法ping这个地址,他没有一个真正的实体对象来响应,他只能结合Service Port来组成一个可以通信的服务,相当于VIP地址,来代理后端服务。
- Kubernetes 强制要求所有网络设施都满足以下基本要求:
- 节点上的 Pod 可以不通过 NAT 和其他任何节点上的 Pod 通信
- 节点上的代理(比如:系统守护进程、kubelet)可以和节点上的所有 Pod 通信
- Pod 是非隔离的,它们接受任何来源的流量。Pod 在被某 NetworkPolicy 选中时进入被隔离状态。 一旦名字空间中有 NetworkPolicy 选择了特定的 Pod,该 Pod 会拒绝该 NetworkPolicy 所不允许的连接。
4.4 服务
Service 定义了这样一种抽象:逻辑上的一组 Pod,一种可以访问它们的策略(通常称为微服务)。一个Serivce下面包含的Pod集合一般是由Label Selector来决定的。
Endpoint是可被访问的服务端点,即一个状态为running的pod,它是service访问的落点,只有service关联的pod才可能成为endpoint。Endpoints则是一个Service对应的所有Pod副本的访问地址。
Pod重启时IP地址可能会改变,只要服务中的 Pod 集合发生更改,Endpoints 就会被更新。服务发现的中间件会在Pod销毁或者重启后,把这个Pod的地址注册到这个服务发现中心去。Service的这种抽象就可以帮我们达到这种解耦的目的。
Service在多个后台Pod之间提供透明的负载均衡,会将请求分发给其中的任意一个。通过每个Node上运行的代理(kube-proxy)完成。
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
上述配置将创建一个名称为 “my-service” 的 Service 对象,它会将请求代理到使用 TCP 端口 9376,并且具有标签 "app=MyApp" 的 Pod 上。这个 Service 会被分配一个唯一的 IP 地址(也称为 clusterIP)。这个 IP 地址与一个 Service 的生命周期绑定在一起,当 Service 存在的时候它也不会改变。
4.5 Ingress/Egress(入站/出站)
Ingress 公开了从集群外部到集群内服务的 HTTP 和 HTTPS 路由。 流量路由由 Ingress 资源上定义的规则控制。
下面是一个将所有流量都发送到同一 Service 的简单 Ingress 示例:
image.png
# 简单扇出
一个扇出(fanout)配置根据请求的 HTTP URI 将来自同一 IP 地址的流量路由到多个 Service。 Ingress 允许你将负载均衡器的数量降至最低。例如,这样的设置:
将需要一个如下所示的 Ingress:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: simple-fanout-example
spec:
rules:
- host: foo.bar.com
http:
paths:
- path: /foo
pathType: Prefix
backend:
service:
name: service1
port:
number: 4200
- path: /bar
pathType: Prefix
backend:
service:
name: service2
port:
number: 8080
# 基于名称的虚拟托管
基于名称的虚拟主机支持将针对多个主机名的 HTTP 流量路由到同一 IP 地址上。
以下 Ingress 让后台负载均衡器基于host 头部字段 来路由请求。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: name-virtual-host-ingress
spec:
rules:
- host: foo.bar.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service1
port:
number: 80
- host: bar.foo.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: service2
port:
number: 80
4.6 日志采集方式
K8S的日志采集方式
- 原生方式
使用 kubectl logs 直接在查看本地保留的日志,或者通过docker engine的 log driver 把日志重定向到文件、syslog、fluentd等系统中。原生方式相对功能太弱,一般不建议在生产系统中使用,否则问题调查、数据统计等工作很难完成。- DaemonSet方式
在K8S的每个node上部署日志agent,由agent采集所有容器的日志到服务端。资源占用要小很多,但扩展性、租户隔离性受限,比较适用于功能单一或业务不是很多的集群。- Sidecar方式
一个POD中运行一个sidecar的日志agent容器,用于采集该POD主容器产生的日志。资源占用较多,但灵活性以及多租户隔离性较强,建议大型的K8S集群或作为PAAS平台为多个业务方服务的集群使用该方式。
DaemonSet、Sidecar这两种模式均基于Logtail实现,日志服务客户端Logtail目前已有百万级部署,每天采集上万应用、数PB的数据,历经考验。可以参考:采集标准Docker容器日志
Reference
https://draveness.me/docker/
https://kubernetes.io/zh/docs/concepts/overview/what-is-kubernetes/
http://omerio.com/2015/12/18/learn-the-kubernetes-key-concepts-in-10-minutes/
https://kubernetes.io/zh/docs/concepts/overview/components/
https://philcalcado.com/2017/08/03/pattern_service_mesh.html
Kubernetes 架构