高曝光率词汇之一:Attention Mechanism 注意力机制
深度学习高频词汇解析:
- 高曝光率词汇之一:Attention Mechanism
Attention Mechanism,注意力机制,目前已经广泛应用在图像分类(Image Classification)、图像问答(Visual Question Answering)、机器翻译(Machine Translation)、语音识别(Voice Recognition)以及文本分类(Text Classification)等研究领域。翻开新近发表的深度学习相关的论文,Attention 一词几乎处处可见。下面我将试图介绍注意力机制的基本原理、变体以及一些经典应用。功力有限,文字拙劣,如有错误与不足,欢迎指正。
Attention Mechanism 最早出现在神经科学领域。科学家发现,当人眼捕捉到一个画面时,不会将整个画面全部传递给大脑进行处理,而是从画面中的某一子区域开始传递。我们日常生活中有很多类似的场景:面对一幅图像,总是最先注意到面积较大、颜色较艳丽的部分;面对一个陌生人,会有一个打量对方的顺序。由于我们的大脑处理能力有限,所以我们的眼睛需要按照一定的顺序对图像分块传递。传递顺序因人而异,与观察者的个人习惯、个人喜好等背景信息有关。写到这里,注意力机制的要素就都出现了:观察对象整体,整体的子部分,处理顺序,背景信息。
通俗地讲,注意力机制是指在理解一个对象时,根据背景信息,将各个子部分按相关度区分对待,更好地理解该对象。在图像问答中,对象可能是一张图片,子部分就是图像的划分区域,背景信息对应问题含义。在自动问答场景中,对象可能是一段候选答案文本,子部分就是文本中的一个词或词组,背景信息便是问题文本的含义。
-
以图像问答为例
图像问答即根据图像内容回答相关问题。在该场景下,需要计算机理解问题文本和目标图像,然后回答与图像内容相关的问题,如是与否的判定问题、颜色判别、计数、物体识别等等。下图是图像问答的例子(图片来自参考文献[1])。

要回答关于图像的问题,首先需要理解问题,即搞清楚问题在问什么,问题理解可以通过提取问题文本的特征 q ~q~ q 表示来完成。其次还需要理解图像,搞清楚图像里有什么内容,可以通过提取图像的特征 v = [ v 1 , v 2 , . . . , v m ] ~v=[v_1, v_2, ..., v_m]~ v=[v1,v2,...,vm] 来完成。只知道图像整体的信息还不足以得出正确答案,毕竟和问题紧密相关的可能只是图像的一小部分。所以我们还需要知道答案包含在图像的哪一部分。到这里,一个注意力机制的应用场景就浮现出来了:问题文本表征 q ~q~ q 是背景信息,图像的各个子区域重要性存在差异,与问题越相关的子区域对回答问题越重要,在最终的图像特征中应占有更大比重。下图是 VQA 场景下注意力机制的过程示意图以及[1]中注意力机制的效果展示图。
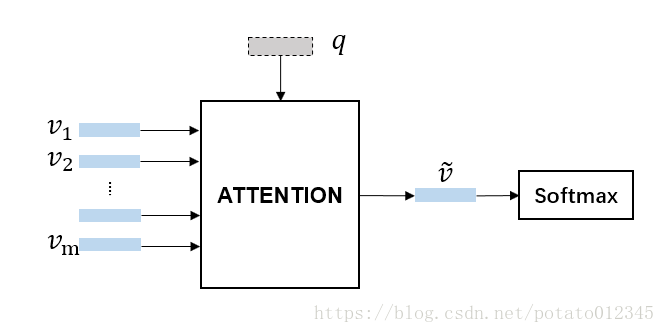

-
基本原理
注意力机制已经衍生出了很多种版本,这里介绍基础版注意力机制的原理。虽然Attention计算方法众多,但基本思想都是相通的。注意力机制的详细流程示意图如下:
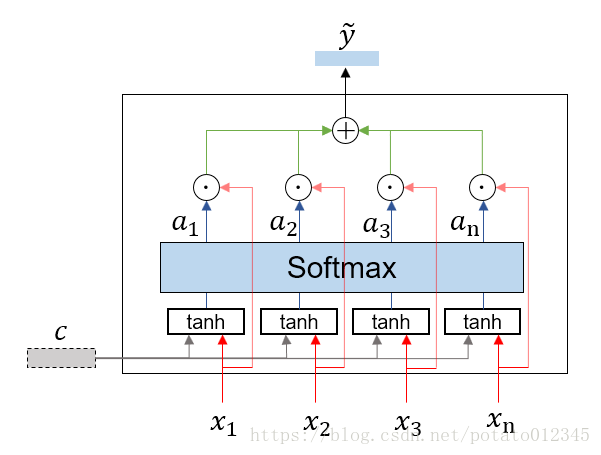
模块输入包括:背景信息表征 c ~c~ c ,需要进行处理的输入序列 x = [ x 1 , x 2 , . . . , x n ] ~x=[x_1, x_2, ..., x_n]~ x=[x1,x2,...,xn] 。模块输出为序列 x ~x~ x 的汇总特征 y ~y~ y ,即考虑了输入序列各部分与背景信息关联程度的汇总特征。下面详细介绍各步骤所包含的计算。
(1)衡量背景信息与子部分的相关性。
h i = t a n h ( W c c + W x x i ) h_i= tanh(W_cc+W_xx_i) hi=tanh(Wcc+Wxxi)
(2)将得到的相关性向量汇总,利用Softmax计算相关性的相对大小。
a = s o f t m a x ( W h h + b ) a = softmax(W_hh+b) a=softmax(Whh+b)
其中, h = [ h 1 , h 2 , . . . , h n ] h=[h_1, h_2, ..., h_n] h=[h1,h2,...,hn], a ∈ R n a\in R^n a∈Rn。
(3)以 a i a_i ai为权重,对所有输入向量加权求和。
y ~ = ∑ i = 1 n a i x i \tilde{y}=\sum_{i=1}^{n}{a_ix_i} y~=i=1∑naixi
注意力机制计算完成。
-
Soft attention VS Hard attention
所谓 Soft Attention 是指不因子部分与背景信息关联性很小便不将该部分纳入最终的特征中,即 a i ~a_i~ ai 可能很小,但不会等于0.而与之相对的 Hard Attention 则是根据关联性排序或随机抽取的方式,将一些子部分排除——将一些 a i ~a_i~ ai 设为0.
显然,上边介绍的基础版本属于 Soft Attention。两种类型的Attention各有优劣之处。不过在实际应用中,Soft Attention也更常见。因为Soft Attention中所有步骤都是可导的,求解更有优势。
-
Co-Attention 机制
注意力机制是利用特定的背景信息指导与之相关的内容的理解。Co-Attention(互注意力)机制则是将两种关联的内容分别作为对方的背景信息,相互指导对方的理解过程。在[1]中,作者提出了两种Co-Attention的方式:alternative(交替)方式和parallel(平行)方式。下图是[1]中绘制的两种方式的结构示意图。
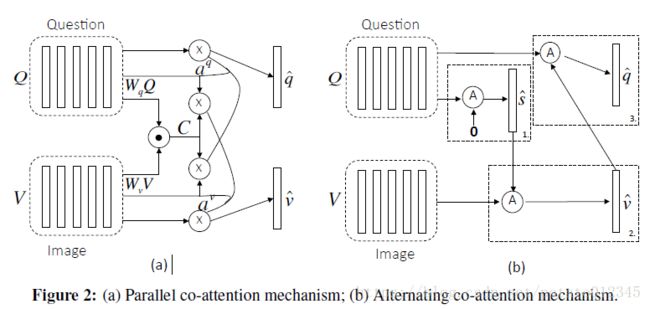
在[1]中,Co-Attention机制被用做 VQA 应用场景中问题文本和图像的理解:图像中每个子区域的重要性是不同的,同时文本中的每个词也是不同。两者相互关联,且子部分的重要性都具有差异性。详细的计算过程可以参考[1]. 另外,[1]中的对比实验表明,在参数设置相同的情况下,alternative 和 parallel方式在性能上差异不大,但alternative方式的训练过程收敛更快。
除了VQA,Co-Attention还可以应用在其他具有相似输入数据的场景中。如多模态微博客的理解[2]等.
-
Self attention
在经典的Attention框架中,需要两种输入信息:背景信息和待理解信息。然而在有些应用场景中,这两种输入信息属于同一种信息。在同一种信息内部进行注意力学习的过程称为 Self attention。如机器翻译中的文本理解[3][4],图片描述中的图像理解[5]等。
-
一些应用
Attention 机制起源于机器翻译[6],经过若干年的发展演化,已经成为了深度学习领域非常流行并且有用的工具,在许多领域都有应用。
除了机器翻译、VQA和Hashtag推荐,在文本分类[7]、图像分类[8]、图片描述生成[5]等领域中, 注意力机制的身影也随处可见。几乎所有涉及对象表示学习的场景中都可以使用Attention机制来使表示更准确。
至此,关于注意力机制的介绍已接近尾声。囿于水平有限,部分概念不得不浅尝则止,感兴趣的读者可以参考以下博文:
Attention 基本原理
Attention发展脉络及应用现状
参考材料
[1] Lu, Jiasen, et al. “Hierarchical question-image co-attention for visual question answering.” Advances In Neural Information Processing Systems. 2016.
[2] Qi Zhang, et al. Hashtag Recommendation for Multimodal Microblog Using Co-Attention Network, The 26th International Joint Conference on Artificial Intelligence. 2017.
[3]Cheng, Jianpeng, Li Dong, and Mirella Lapata. “Long short-term memory-networks for machine reading.” arXiv preprint arXiv:1601.06733 (2016).
[4] Vaswani, Ashish, et al. “Attention is all you need.” Advances in Neural Information Processing Systems. 2017.
[5] Xu, Kelvin, et al. “Show, attend and tell: Neural image caption generation with visual attention.” International conference on machine learning. 2015.
[6] Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. “Neural machine translation by jointly learning to align and translate.” arXiv preprint arXiv:1409.0473 (2014).
[7] Yang, Zichao, et al. “Hierarchical attention networks for document classification.” Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2016.
[8]Xiao, Tianjun, et al. “The application of two-level attention models in deep convolutional neural network for fine-grained image classification.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015.