大数据Kettle数仓工具快速入门
目录
前言
一、官方介绍
二、个人总结
三、 工具安装
1.1 下载方式
1.2 安装注意事项
四、命令介绍
2.1 Spoon命令
2.2 Pan命令
2.3 Kitchen命令
2.4 Carte命令
五、模块介绍
3.1 转换模块(Trans)
3.2 作业模块(Jobs)
六、实战操作
4.1 Excel导入数据到数据库
4.2 通过kettle解压文件
七、结束语
前言
在阅读该文档之前,我需要说明下,这个技术文档整理了我目前经历过的一些问题和踩过的坑,以及简单的几个demo教大家如何快速上手使用kettle,体会到kettle的便利之处。同时也希望能把我最近吸收到的知识分享给csdn大家庭,大家一起成长!
在理想的最美好世界中,一切都是为最美好的目的而设。 —— 伏尔泰
一、官方介绍
Kettle最早是一个开源的ETL工具,全称为KDE Extraction, Transportation, Transformation and Loading Environment。在2006年,Pentaho公司收购了Kettle项目,原Kettle项目发起人Matt Casters加入了Pentaho团队,成为Pentaho套件数据集成架构师 [1] ;从此,Kettle成为企业级数据集成及商业智能套件Pentaho的主要组成部分,Kettle亦重命名为Pentaho Data Integration [1-2] 。Pentaho公司于2015年被Hitachi Data Systems收购。 [3] (Hitachi Data Systems于2017年改名为Hitachi Vantara [4] )
Pentaho Data Integration以Java开发,支持跨平台运行,其特性包括:支持100%无编码、拖拽方式开发ETL数据管道;可对接包括传统数据库、文件、大数据平台、接口、流数据等数据源;支持ETL数据管道加入机器学习算法。
二、个人总结
简单的可以理解成,kettle就是一个水壶,所有不同来源,不同格式的数据都可以扔进去,最后处理完成后可以统一方式输出,熟悉操作后可以提升数据处理效率,降低开发成本。
比如从数据库抽取数据,然后定时生成Excel文件功能,或者定时导入Excel数据到数据库功能等等都可以利用工具快速实现。
kettle可以分为四个操作命令和两个模块,以及存储位置说明,具体我用3个思维导图来让大家快速了解。
- 1/3=>四个操作命令

- 2/3=>两个模块

- 3/3=>脚本存储位置

三、 工具安装
1.1 下载方式
Pentaho from Hitachi Vantara - Browse /Data Integration at SourceForge.netEnd to end data integration and analytics platform https://sourceforge.net/projects/pentaho/files/Data%20Integration/
https://sourceforge.net/projects/pentaho/files/Data%20Integration/

这边建议直接使用7.1版本,然后点击下载

1.2 安装注意事项
软件免安装,下载好了以后,直接解压出来即可使用了,可以看到有/data-integration这个文件夹。如果执行./spoon.sh有报错就看这里,没报错跳过这节。
出现报错的80%是缺少数据库mysql对应的jar包,还有10%是java环境的jdk版本原因,所以这里会给出这两个报错的解决办法。
1.2.1 缺少mysql的jar包问题解决方式
jar包下载链接参考这个博客:不同版本mysql-connector-java的jar包下载地址_kt1776133839的博客-CSDN博客_mysql-connector-java-5.1.32.jar https://blog.csdn.net/kt1776133839/article/details/124539192
https://blog.csdn.net/kt1776133839/article/details/124539192
根据自己需要链接的mysql版本,找到对应的mysql-connector-java.jar包,目前我们用mysql-connector-java-5.1.49.jar包基本上能解决我们的问题。下载好jar包后,把文件移动到 /data-integration/lib目录 即可解决问题。
1.2.2 JDK版本问题
这个是我踩了最久的坑了,我这边因为电脑一直更新最新版本的jdk,导致各种报错各种问题出现,尝试了好多种jdk版本都不行,最后发现,只有JDK8才能正常运行。
下载链接点这里 Download the Latest Java LTS Freehttps://www.oracle.com/java/technologies/downloads/

点击上面的对应系统和版本链接,下载安装即可。

命令行输入java -version 出现1.8.x即安装成功,如果是其他版本,说明你没安装成功,需要卸载掉原来的java版本,卸载方式见下面
1.2.3 卸载java方式
1、sudo rm -fr /Library/Internet\ Plug-Ins/JavaAppletPlugin.plugin
2、sudo rm -fr /Library/PreferencesPanes/JavaControlPanel.prefpane
3、ls /Library/Java/JavaVirtualMachines/ (查看安装的jdk版本)
输出:jdk-9.0.1.jdk
4、sudo rm -rf /Library/Java/JavaVirtualMachines/jdk-9.0.1.jdk
5、输入java -version提示安装Java就说明卸载成功。
四、命令介绍
提醒:由于我使用的是Linux和MacBook,所以以下都是用sh后缀的脚本作为示范,同时操作的位置都是在kettle的解压目录 /data-integration
2.1 Spoon命令
作用是启动图形界面,只需要在kettle的解压目录命令行输入 ./spoon.sh 即可,显示以下图形界面即表示启动成功。

2.2 Pan命令
用来处理转换模块(Trans)的命令,参数如下
- -rep = 资源库名称
- -user = 资源库用户名
- -trustuser = 资源库用户名
- -pass = 资源库密码
- -trans = 要启动的转换名称
- -dir = 目录(不要忘了前缀 /)
- -file = 要启动的文件名(转换所在的 XML 文件)
- -level = 日志等级 (基本, 详细, 调试, 行级, 错误, 没有)
- -logfile = 要写入的日志文件
- -listdir = 列出资源库里的目录
- -listtrans = 列出指定目录下的转换
- -listrep = 列出可用资源库
- -exprep = 将资源库里的所有对象导出到 XML 文件中
- -norep = 不要将日志写到资源库中
- -safemode = 安全模式下运行: 有额外的检查
- -version = 显示版本,校订和构建日期
- -param = 传递参数
= . For example -param:FOO=bar
参数很多吧?那看个最基础用法如下即可启动一个本地脚本了。
./pan -file=/PATH/trans.ktr -param:name='2021重返程序道路' -param:gender='男'2.3 Kitchen命令
用来处理作业(Jobs)模块的命令,参数和pan几乎一样,唯一不同的是pan命令参数有个-trans在这里就变成-job = 要启动的作业名称
2.4 Carte命令
启动一个常驻脚本,用来监听发送过来的job和trans任务,配合远程脚本存储使用比较适合,参数如下
-p 启动密码 (仅当需要停止服务时候才输入配置好的密码)
-u 启动用户 (仅当需要停止服务时候才输入配置好的用户)
-s 停止服务
注意:设置账号密码需要在/data-integration/pwd目录下的文件设置,启动命令并不是设置账号密码

./carte.sh 127.0.0.1 8080 这样就可以启动常驻服务了,浏览器访问127.0.0.1:8080,默认账号密码都是cluster

启动成功后,访问链接会要求输入账号密码,默认都是cluster,输入完毕后显示如下即表示成功
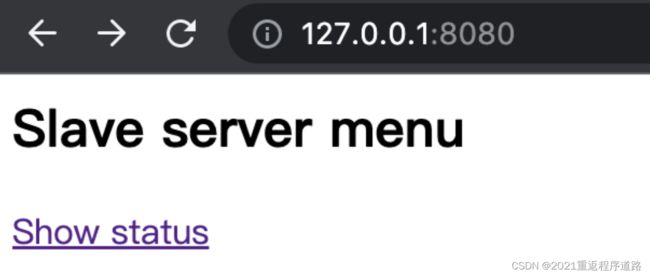
此时一个常驻服务就开启了,即使关闭终端也是能访问的。关闭carte服务的命令如下
./carte.sh 127.0.0.1 8080 -s -u cluster -p cluster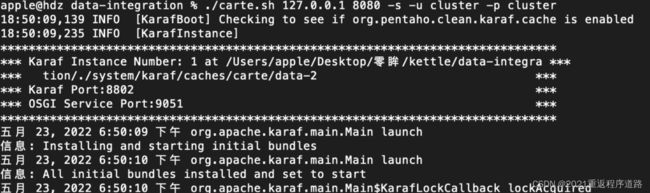 这样就成功关闭carte服务了,此刻访问127.0.0.1:8080提示错误。
这样就成功关闭carte服务了,此刻访问127.0.0.1:8080提示错误。
五、模块介绍
3.1 转换模块(Trans)
这个其实就是处理数据输入输出,过滤数据,数据分类筛选分析等等操作~
先上图形工具的转换模块界面图。双击点击这里就切换成转换模块,同时TAB会自动从 主对象树 跳转到核心对象

可以看到,转换里面有输入输出,streaming,转换等等功能。我们这里尝试拖拽一个输入Excel到右侧,如下图

是不是很酷? 这样就实现了从0到1的巨大进步了,其他功能就交给你去逐步摸索吧~ O(∩_∩)O
3.2 作业模块(Jobs)
这个模块主要是处理邮件收发,SFTP/FTP上传下载,文件增删改查等功能
模块功能清单如下

同样的我们可以拖拽一个功能到右侧画板里面

这样也踏出了作业模块定制的第一步了~ 接下来我将会在下一个收费章节里(bushi)(✿◡‿◡),通过几个案例教大家怎么来使用几个功能,从而达到理解整个操作流程。
六、实战操作
4.1 Excel导入数据到数据库
终于来到紧张的实战教学环节了
问: 现在你需要把一个带有学生信息的Excel导入到数据库中并且存在相同学号更新数据,利用kettle怎么做?
划重点,Excel录入到数据库,有2个要素,
- Excel数据输入功能。
- 数据库插入功能。
也就是说我们需要用到转换模块的输入功能来实现,接着往下看。
我们准备一个学生信息Excel如下

从转换里拖入一个Excel输入到右侧

然后我们双击右侧的Excel输入编辑好信息
 点击上方的增加按钮,把文件追加到下方选中的文件去
点击上方的增加按钮,把文件追加到下方选中的文件去

同时我们点击!字段选项,再点击获取来自头部数据的字段,就能够把表头给同步到kettle里了!
 我们给这个步骤写一个好辨认的名字吧
我们给这个步骤写一个好辨认的名字吧
 这样这就完成了读取Excel的功能了
这样这就完成了读取Excel的功能了

问题来了,那我们怎么把数据写入到数据库里面?别慌,看下面
我们找到左侧,输出-插入/更新,并且拖拽到右边

关键点来了,我们要把“读取学生信息表”和插入更新关联起来,就要用到连接线。

这样我们就把他们的关系链接起来了,接着我们双击插入/更新功能,编辑对应的数据库信息。
 点击测试显示连接成功,就可以点击确定返回“插入/更新”的编辑界面了,然后点击“获取字段”按钮就能自动获取前面Excel表的字段,下图“流里的字段”就是Excel读取的字段,“表字段”就是数据库的字段,现在我们的数据库是这么个结构
点击测试显示连接成功,就可以点击确定返回“插入/更新”的编辑界面了,然后点击“获取字段”按钮就能自动获取前面Excel表的字段,下图“流里的字段”就是Excel读取的字段,“表字段”就是数据库的字段,现在我们的数据库是这么个结构
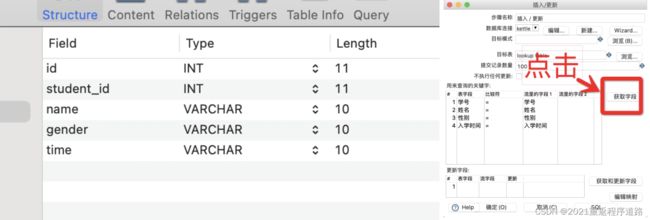
这里有一点需要注意的是,插入更新的编辑界面的“用来查询的关键字”那个区域,指的是搜索条件。
“更新字段”区域指的是根据搜索条件搜索到数据后,需要更新到数据库的字段。
我们现在需求是要把学生信息导入到数据库中并且根据学号做更新数据。
也就是说,用来查询的关键字是学号,更新的字段是“姓名”,“性别”,“入学时间”这三个。

配置成如上图即可达到我们的目的,点击确定,我们来测试下功能,是否正常。

作为程序员,这里我们通过命令行来测试哈。先按command+s保存脚本文件到指定路径。
我保存到这个路径 /Users/apple/Desktop/trans/info.ktr
然后打开终端,执行如下命令处理转换模块脚本
./pan.sh -file=/Users/apple/Desktop/trans/info.ktr 
看到这样就说明没有错误,成功执行完毕了,我们可以看到数据库表里已经增加了数据了。

4.2 通过kettle解压文件
问:如何通过kettle解压一个文件? 文件存储在 /Users/apple/Desktop/jobs/学生信息.zip
前面有提到过,处理文件的话,需要使用到作业模块(Jobs)来处理,所以这次我们就直接上手打开一个作业模块吧。
注意注意! 作业模块和转换模块有不一样的地方,就是作业模块必须要有 开始 和 成功(结束)!我们可以在 通用 里面找到。
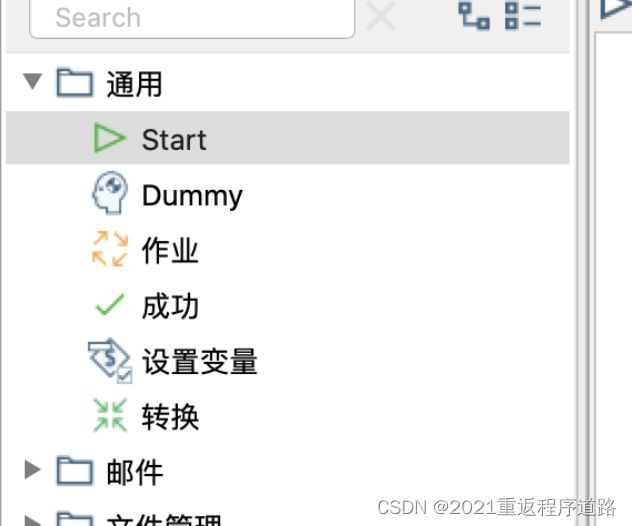
我们把Start和成功拖拽到右侧,然后找到 文件管理 - 解压缩文件 也拖拽到右侧并连线。
 双击 解压缩文件 功能,然后编辑信息如下图
双击 解压缩文件 功能,然后编辑信息如下图
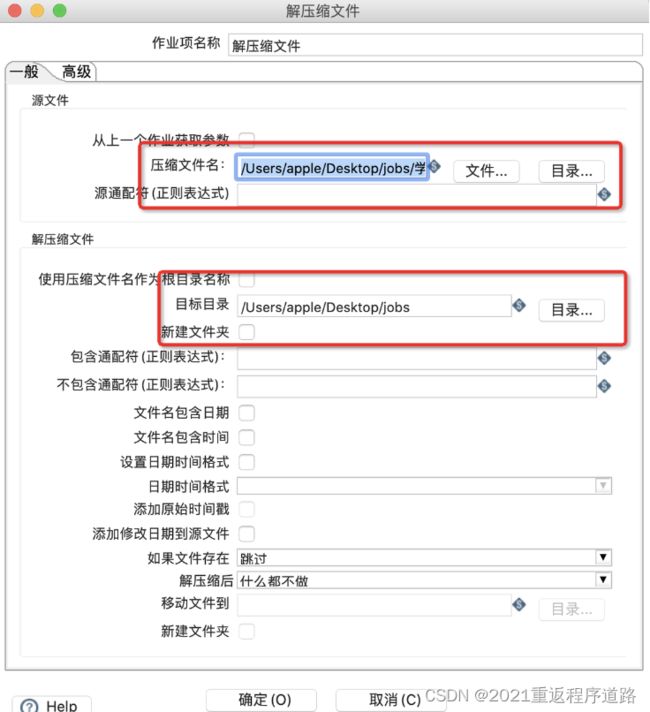
这时候我们可以保存运行一下看看效果,是否有被解压出来。
运行命令如下
./kitchen.sh -file=/Users/apple/Desktop/jobs/unzip.kjb
运行命令结束后,显示上面信息则表示脚本正常执行完毕了。我们可以看看下面文件夹前后对比。

左边是解压之前,右边是执行脚本解压后,明显看到 学生信息.xlsx 已经被解压出来了!
4.3 实现解压文件并把Excel更新到数据库
问: 如何把一个被压缩过的Excel文件,解压出来,并且数据更新到数据库?
这次就需要同时使用 作业模块 和 转换模块 搭配来实现功能了。
前面我们有实现过 解压功能 和 同步Excel数据到数据库功能 ,我们可以在那2个脚本基础上进行一些修改,即可实现这次的目的。
我们先编辑下之前的解压模块的脚本,添加一个转换功能到作业里面。
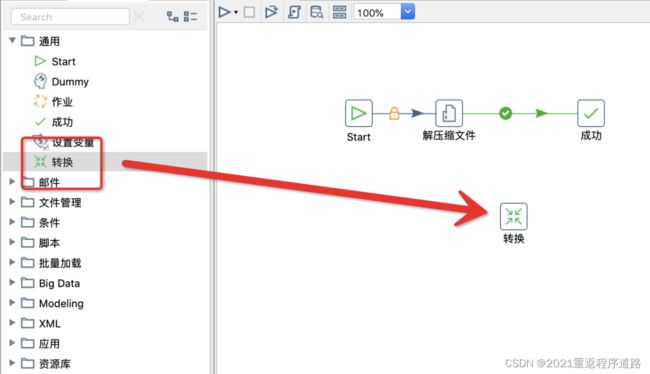
然后断开 解压缩文件 和 成功 的连接线,在线上面右键

最后按照这个顺序链接起来

这时候总体的执行流程就清晰明了了,但是还不够,我们还需要指定转换脚本,双击它!

这样就几乎完成了,但是有个细节需要注意的是,之前的转换脚本处理的是 /Users/apple/Desktop/trans/学生信息.xlsx 这个路径的文件,而我们的作业脚本是
解压到 /Users/apple/Desktop/jobs/学生信息.xlsx这个,所以还需要把文件移动到/trans/文件夹去。
添加如下功能到右侧

编辑如下信息
 确定保存后,执行下刚才的job命令,查看下效果
确定保存后,执行下刚才的job命令,查看下效果

命令执行成功!!文件成功解压出来并移动到指定文件夹,并且数据库插入了数据!
七、结束语
新手入门的操作就到这里了,如果你能够认真的看完这个入门教程并跟着做一遍,相信肯定很快就能够上手kettle这个工具的,当然学无止境,这只是开始,我也一样。如果遇到不懂的地方,可以留言发我信息,我很乐意解答(只要我会的话~)
Thanks♪(・ω・)ノ