numpy入门及matplotlib数据可视化
目录
一、环境搭建
1.Anaconda简介及安装
2.使用jupyter notebook
3.notebook设置代码自动补全
4.notebook入门
(1)创建文件
(2)界面简介
(3)notebook常用快捷键(windows)
二、numpy入门
1.numpy简介
2.创建和使用numpy数组
(1)数组属性
(2)创建数组对象ndarray
(3)创建空矩阵/零矩阵/全一矩阵/单位矩阵
(4)使用数字序列/随机数创建矩阵
(5)矩阵(数组)合并
3.numpy的矩阵运算 - universal function
4.numpy中的聚合操作(统计函数)
5.numpy中的索引取值
三、matplotlib初探
1.matplotlib.pyplot简介及入门
2.数据加载及数据探索
一、环境搭建
1.Anaconda简介及安装
Anaconda(官方下载地址)就是可以便捷获取包且对包能够进行管理,同时对环境可以统一管理的发行版本。Anaconda包含了conda、Python在内的超过180个科学包及其依赖项。
——Anaconda官方网站
Anaconda可以看作一个集成了大量进行数据分析、机器学习所需要的python包的开发环境。使用Anaconda进行开发,开发者不必陷于依赖包的安装、环境管理等琐碎的操作中,因为Anaconda提供了conda这一比pip更强大的包和环境管理器。
如果你需要的包要求不同版本的Python,你无需切换到不同的环境,因为conda同样是一个环境管理器。仅需要几条命令,你可以创建一个完全独立的环境来运行不同的Python版本,同时继续在你常规的环境中使用你常用的Python版本。
——conda官方网站
具体安装教程请看:https://blog.csdn.net/ITLearnHall/article/details/81708148。安装非常简单。
Anaconda更换国内下载源:https://blog.csdn.net/dream_allday/article/details/80344511
2.使用jupyter notebook
Jupyter Notebook是基于网页的用于交互计算的应用程序。其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。
——Jupyter Notebook官方介绍
Jupyter Notebook实时展示代码效果与matplotlib可视化库结合简直不要太爽。而且Jupyter Notebook可以进行markdown编辑,对知识点的理解再也不用写成注释了,学习必备利器!
安装完Anaconda之后,在命令行中输入jupyter notebook,或者在运行窗口中输入jupyter notebook,即可启动服务,注意不要关闭服务窗口,让其在后台运行。



打开notebook之后的界面如下图所示,推荐将其添加到书签栏方便以后打开哦。

3.notebook设置代码自动补全
刚安装的notebook界面可能与上图界面有一点小小的区别,就是菜单栏中没有“Nbextensions”选项卡,这个选项卡是用来设置代码自动补全的。
具体操作命令如下,需要注意的是执行下述命令时要 提前关闭jupyter服务。
python -m pip install jupyter_contrib_nbextensions
jupyter contrib nbextension install --user --skip-running-check执行过程需要等待一小会儿,执行完成之后打开jupyter notebook

至此,一个舒服的开发环境就算搭建好啦。
4.notebook入门
(1)创建文件
(2)界面简介

(3)notebook常用快捷键(windows)
<1>命令行模式
选中语句块后 按Esc进入命令行模式
a:在当前语句块上方插入语句块
b:在当前语句块下方插入语句块
d:删除当前语句块
m:进入markdown编辑模式
y:进入python代码编辑模式
ctrl+A:选中所有语句块
<2>插入编辑模式
shift+enter :执行并选中下一语句块
alt+enter :执行并在下方插入空语句块
ctrl+enter :仅执行当前语句块
<3>其他
- run命令:

- timeit和time命令:
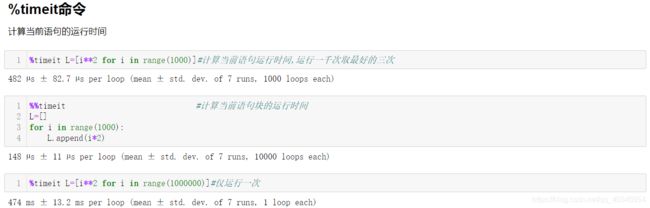
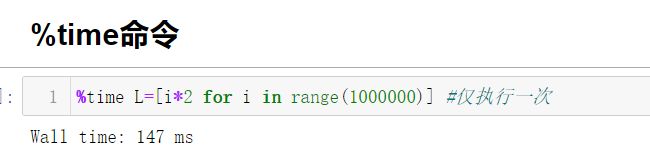
- 使用“ ?”获取函数/属性说明

二、numpy入门
1.numpy简介
numpy 是一个运行速度非常快的数学库,主要用于数组计算,包含:
- 一个强大的N维数组对象 ndarray
- 广播功能函数
- 整合 C/C++/Fortran 代码的工具
- 线性代数、傅里叶变换、随机数生成等功能
Anaconda中已经包含了numpy,只需要使用import导入即可。
2.创建和使用numpy数组
(1)数组属性
(2)创建数组对象ndarray
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引。
ndarray 对象是用于存放同类型元素的多维数组(与python的list不同)。ndarray 中的每个元素在内存中都有相同存储大小的区域。
import numpy
# numpy中的数组ndarray
list_numpy= np.array([i for i in range(10)]) # array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
# python自带list
list_python = [i for i in range(10)] # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# list 转换为 ndarray
list_to_ndarray = np.array(list_python) # array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
(3)创建空矩阵/零矩阵/全一矩阵/单位矩阵
import numpy
nplist = np.zeros(10,dtype=complex)
#array([0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j, 0.+0.j,0.+0.j, 0.+0.j])
nplist = np.ones(10,dtype=int)
#array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
nplist.reshape(2,5) #reshape()详解见ndarray数组属性
#array([[1, 1, 1, 1, 1],
# [1, 1, 1, 1, 1]])
np.eye(5, M=5, k=0, dtype=int)
# array([[1, 0, 0, 0, 0],
# [0, 1, 0, 0, 0],
# [0, 0, 1, 0, 0],
# [0, 0, 0, 1, 0],
# [0, 0, 0, 0, 1]])
npmatrix=np.full(shape=(2,4),fill_value=9) #指定矩阵元素
# array([[9, 9, 9, 9],
# [9, 9, 9, 9]])
np.empty([3,2], dtype = int)
# array([[ 6917529027641081856 ,5764616291768666155],
# [ 6917529027641081859 ,-5764598754299804209],
# [ 4497473538 , 844429428932120]])(4)使用数字序列/随机数创建矩阵
<1>使用数字序列
import numpy as np
x = np.arange(10)
# arange(start=None, stop, step=None, , dtype=None)
# [0 1 2 3 4 5 6 7 8 9]
x=np.linspace(0,10,11,retstep=True,dtype=int)
# 根据区间长度和元素个数返回一个等差数列
# def linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None, axis=0)
# (array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]), 1.0)
<2>使用随机数
import numpy as np
x=np.random.random(10)
# 返回指定个数的[0.0, 1.0)区间内的随机数
x=np.random.randint(0,100,15).reshape(5,3)
# 返回[0,100)内15个随机整数,并重塑为5*3矩阵
# [[53 62 33]
# [50 89 99]
# [37 8 30]
# [94 8 53]
# [47 50 83]](5)矩阵(数组)合并
<1>concatenate((a1, a2, ...), axis=0, out=None)
concatenate()函数根据指定的维度,对一个元组、列表中的list或者ndarray进行连接,函数原型:
numpy.concatenate((a1, a2, ...), axis=0)
先来看几个例子,一个2*2的数组和一个1*2的数组,在第0维进行拼接,得到一个3*2的数组:
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6]])
np.concatenate((a, b), axis=0)
输出为:
array([[1, 2],
[3, 4],
[5, 6]])
进一步,一个2*2的数组和一个2*1的数组,在第1维进行拼接,得到一个2*3的数组:
np.concatenate((a, b.T), axis=1)
输出为:
array([[1, 2, 5],
[3, 4, 6]])
上面两个简单的例子中,拼接的维度的长度是不同的,但是其他维度的长度必须是相同的,这也是使用concatenate()函数的一个基本原则,违背此规则就会报错,例如一个2*2的数组和一个1*2的数组,在第1维进行拼接:
np.concatenate((a, b), axis=1)
上面的代码会报错:
ValueError: all the input array dimensions except for the concatenation axis must match exactly
<2>stack((a1, a2, ...), axis=0, out=None)
翻看了很多对stack函数进行解析的帖子,都没有找到一个很好的解释,要么不知所云,要么太过复杂,于是不得不自己动手实验一下。
首先,用于stack的数组或者矩阵必须是同形的,也就是shape属性相同。
Ⅰ.一维数组的stack合并
import numpy as np
a = np.array([1,2,3])
b = np.array([2,3,4])
x = np.stack([a,b],axis=0)
print(x.shape)a b的shape都是(3,)而按照axis=0合并之后的shape是(2,3),因此stack函数是将参数数组都加上一个axis指定的维度,再在这个维度上进行concatenate()。因此上述代码中的stack函数若将axis参数改为1,合并之后的shape=(3,2)
Ⅱ.二维数组的stack合并
二维数组与一维数组同理
import numpy as np
a = np.array([[1,2,3]])
b = np.array([[2,3,4]])
c = np.array([[2,3,4]])
x = np.stack([a,b,c],axis=0)
print(x.shape)
# 下述代码与上述代码作用相同
a= a.reshape(-1,1,3)
b= b.reshape(-1,1,3)
c= c.reshape(-1,1,3)
x = np.concatenate((a,b,c),axis=0)
print(x.shape)输出结果:

<3>vstack(tup)
相当于stack(axis=0),行堆叠
<4>hstack(tup)
相当于stack(axis=1),列堆叠
3.numpy的矩阵运算 - universal function
ufunc是universal function的缩写,意思是这些函数能够作用于narray对象的每一个元素上,而不是针对narray对象操作,numpy提供了大量的ufunc的函数。这些函数在对narray进行运算的速度比使用循环或者列表推导式要快很多,但请注意,在对单个数值进行运算时,python提供的运算要比numpy效率高。
详情请见:python科学计算之numpy——ufunc函数
注意:numpy的universal function操作符如 A+2、A*2(A是二维数组),针对ndarray数组对象才有用,对python的list对象没用。
注意:由于A*B等操作,是对数组元素进行运算,并非矩阵乘法,因此对于这种情况应使用np.dot(A,B)-矩阵乘法等函数。
矩阵运算详情请见:numpy矩阵运算
4.numpy中的聚合操作(统计函数)
NumPy 提供了很多统计函数,用于从数组中查找最小元素,最大元素,百分位标准差和方差等。
详情请见:numpy中的统计函数
5.numpy中的索引取值
(1)初级索引和切片
import numpy as np
#一维数组切片
a = np.arange(10) # [0 1 2 3 4 5 6 7 8 9]
print(a)
print(a[7:2:-1]) # [7 6 5 4 3]
print(a[2:8:2]) # [2 4 6]
print(a[3:]) # [3 4 5 6 7 8 9]
print(a[:5]) # [0 1 2 3 4]
indexs=[1,5,9] # 使用索引数组进行取值
print(a[indexs]) # [1 5 9]
# 二维数组切片
A = np.arange(12).reshape(3,4)
# A
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
print(A[2,3]) # 11
print(A[1:3,...])
# [[ 4 5 6 7]
# [ 8 9 10 11]]
print(A[:,:2])
# [[0 1]
# [4 5]
# [8 9]]
print(A[...,:2])
# [[0 1]
# [4 5]
# [8 9]]
# 使用索引数组进行索引
indexs = [0,2]
print(A[indexs])
# [[ 0 1 2 3]
# [ 8 9 10 11]]
rows = [0,1]
cols = [1,3]
print(A[rows,cols]) # [1 7] 第1、2行和第2、4列的交点元素
rows = [[0,0],[1,1]]
cols = [[0,2],[0,2]]
print(A[rows,cols])
# [[0 2]
# [4 6]](2)高级索引-布尔比较索引
在实际应用中,我们可能会遇到这样的情况,一组m*n的二维数组,存放着m个对象的各自的n维特征值数据,还有一个一维数组存放着m个对象的标签,这m个标签数据的次序与二维数组中的数据的行的顺序是相同的。那我们如果想提取出具有相同标签的的对象的特征值数据该怎么办呢?布尔比较索引可以很好的解决这个问题。
numpy中的universal function不仅提供了加、减、乘、除、模这样的运算,而且提供了布尔运算。如一维数组x>5的返回值是一个与x等长一维bool数组,元素值为bool类型
print(np.arange(5))
print(np.arange(5)>2)
# [ 0 1 2 3 4 ]
# [False False False True True]numpy中的数组可以通过传入一个布尔数组进行取值,返回布尔值为True的对应位置元素
# 布尔比较
A = np.arange(16).reshape((4,4))
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]
# [12 13 14 15]]
print(A>5)
# [[False False False False]
# [False False True True]
# [ True True True True]
# [ True True True True]]
print(A[A>5])
# [ 6 7 8 9 10 11 12 13 14 15]三、matplotlib初探
1.matplotlib.pyplot简介及入门
本文使用matplotlib中的pyplot模块进行可视化编程,pyplot可以快速的绘制函数图像或者散点图,可以设置图像的颜色、形状(虚线、实线)、控制坐标轴数据范围等。
2.数据加载及数据探索
本文使用的数据集是sklearn的鸢尾花数据集
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets
#导入鸢尾花数据
iris = datasets.load_iris() # iris类似一个字典
print(iris.keys())
# dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])
print(iris.data)
# data: 150*4的二维数组,存放着150株鸢尾花的特征数据[花萼的长,花萼的宽,花瓣的长,花瓣的宽]
print(iris.target)
# target: 一维数组,与data中数据一一对应,反映data中某一行数据所属花的种类。0:Setosa鸢尾花、1:Versicolour鸢尾花、2:Virginica鸢尾花
print(iris.target_names)
# target_names:['setosa', 'versicolor', 'virginica']
print(iris.feature_names)
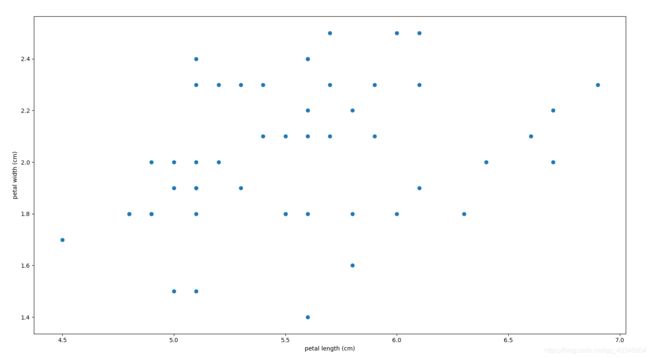
# feature_names:['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']将Virginica鸢尾花的数据提取出来,并将其花瓣的长和宽绘制成散点图。
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets
#导入鸢尾花数据
iris = datasets.load_iris() # iris类似一个字典
x=iris.data[iris.target==2,2] #提取花瓣长数据
y=iris.data[iris.target==2,3] #提取花瓣宽数据
plt.scatter(x,y)
plt.xlabel("petal length (cm)")
plt.ylabel("petal width (cm)")
plt.show()
为了查看三种不同的鸢尾花之间的差别,将4个特征数据两两组合,绘制出6个散点图。
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets
#导入鸢尾花数据
iris = datasets.load_iris() # iris类似一个字典
def drawScatter(data,plt,target,xind,yind):
gs=[] #存放3个散点图,用于添加图例
for i,samble,color in zip([0,1,2],"ox^",['red','yellow','blue']):
g = plt.scatter(data[target==i,xind],data[target==i,yind],marker=samble,c=color)
gs.append(g)
plt.xlabel(iris.feature_names[xind]) #添加x轴标签
plt.ylabel(iris.feature_names[yind]) #添加y轴标签
plt.title(iris.feature_names[xind]+" and "+iris.feature_names[yind]) #添加标题
plt.legend(gs,iris.target_names) #显示图例
num=1;# 计数,当前是第num个图
for i in range(4):
for j in range(i+1,4):
plt.subplot(2,3,num) # 共有2*3=6个图,将窗口分为2行3列
drawScatter(iris.data,plt,iris.target,i,j)
num=num+1
plt.show()
致谢与说明
首先,感谢直接或间接帮助我写完这篇文章的博主表示感谢,由于参考文章过多就不一一列举了。
其次,笔者刚刚开始进入机器学习,写作本文的目的也主要是帮助自己理解知识,同时也希望能够帮助同样刚刚开始学习机器学习的小伙伴。
最后,由于笔者刚刚开始学习,文章中难免有错误的地方,请读者不吝指出。