AST:Audio Spectrogram Transformer
文章目录
- 0. Abstract
- 1. Introduction
- 2. Audio spectrogram transformer
-
- 2.1 Model architecture
- 2.2 ImageNet Pretraining
- 3. Experiments
-
- 3.1 AudioSet Experiments
-
- 3.1.1 Dataset and Training Details
- 3.1.2 AudioSet Results
- 3.1.3 Ablation Study

0. Abstract
该文发表于Interspeech2021。
进来,CNN网络作为主要模块,广泛应用于端到端的语音分类模型中,旨在学习从音频频谱图到对应标签的直接映射。为了更好地捕获远距离全局依赖性(上下文),最近的发展趋势是在CNN之上增加自注意力机制,形成CNN-注意力混合模型。但是,目前尚不清楚单独的使用CNN模型或者注意力网络模型就足以在音频分类中获得良好的性能。
本文的主要工作就是提出了首个无卷积、 单纯基于注意力机制的音频分类模型(借鉴ViT那套做法),本文在多个音频分类任务上进行了评测,均实现了SOTA性能。
1. Introduction
本文提出了AST: Audio Spectrogram Transformer, a convolution-free, purely attention-based model。
AST模型的优势:
- AST模型在多个分类任务和数据集上获得了最佳性能;
- AST支持可变长度的输入,并且可以在不改变网络架构的情况下应用于不同的任务;
- 与当前性能最好的CNN-attention混合模型相比,AST具有更简单的架构,更少的参数量,在训练中收敛更快。
2. Audio spectrogram transformer
2.1 Model architecture
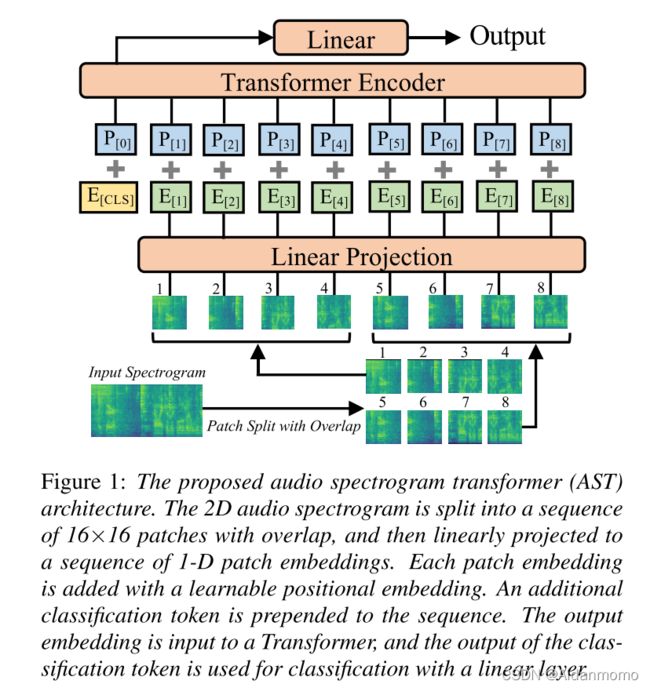
图1展示了AST网络架构,首先将t秒时长的语音片段转换为128维的log梅尔谱特征,采用Hamming窗,窗长25ms,hop_size为10ms。得到大小为128 X 100t的谱图,输入到AST中。之后,将谱图分割成N个大小为16 X 16的patches,在时间和频率维度上的重叠打下为6,得到 N = 12 ⌈ ( 100 t − 16 ) / 10 ⌉ N=12 \lceil (100t-16)/10 \rceil N=12⌈(100t−16)/10⌉。本文通过线性映射层,将16X16的patch 展平为大小为768的一维embedding特征,此外,本文增加了一个可训练的位置编码特征(大小同样是768)到每一个patch embedding上,使得其能获得二维音频谱图的空间结构信息。
本文在序列的开始位置增加了一个[CLS]标记,特征信息输入到Transformer中。AST中仅仅使用encoder部分,用于分类任务。Transformer的网络模型架构可以参照【Attention is all you need】这篇经典论文,本文的transformer的embedding维度为768,包含12层,12个头。transformer的输出用做音频频谱图的特征表示,其经过带有sigmoid激活的线性层将音频谱图映射到用于分类的标签。
2.2 ImageNet Pretraining
transformer方法相对CNNs架构方法的劣势是,前者需要更多的数据进行训练。论文【11】的作者提到,Transformer方法在图像分类任务中,只有当数据量超过1400万时才开始优于CNN模型。但是语音数据集通常没有如此巨大的规模,因此,本文尝试将跨模态迁移学习应用于AST,因为图像和音频频谱图具有相似的格式。从视觉任务到音频任务的迁移工作已经有很多【23, 24, 25, 8】,但都是基于CNN模型,其中经过与训练的ImageNet CNN网络参数用于对语音分类的CNN网络模型参数进行初始化。本文尝试将off-the-shelf(现成的)预训练ViT模型用于AST。
[11] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” in ICLR, 2021.
进行迁移之前,本文进行了一些适应性改动:
- ViT的输入是3通道的图片,而AST的输入为单通道的频谱,因此,本文对三个通道的参数进行计算平均之后应用到AST中,此外,本文将输入音频频谱进行归一化,均值和方差为0和0.5。
- ViT模型的输入是固定的(224X224,或者384X384),与常用音频谱图输入不同,这里主要涉及对位置编码信息的更改。本文提出了一种截断和双线性插值(Cut and bi-linear interplolate)的方法来解决该问题,例如,对于一个输入图像大小为384x384,使用16x16 patch大小的ViT,patch的数量和位置编码的大小为24x24=576。而AST对于10s长度的音频,共有12x100个patches,,每个patch需要一个位置编码,因此对ViT中24x24的位置编码的第一个维度进行截断,第二个维度进行插值操作,得到可以在AST中使用的12x100大小。
- ViT和AST的分类任务不同,这里直接将ViT的最后一层进行重新初始化,以适应AST的任务需求。
本文使用DeiT预训练模型【12】,该模型使用CNN知识蒸馏训练,输入数据大小384x384,参数大小为87M,在ImageNet 2012上实现了85.2%的top-1准确率。
[12] H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. J´egou, “Training data-efficient image transformers & distillation through attention,” arXiv preprint arXiv:2012.12877, 2020.
3. Experiments
- AudioSet数据集:该数据集是弱标注语音时间分类数据集,分别进行主要工作测试和ablation实验。
- ESC-50数据集
- Speech Commands V2数据集
3.1 AudioSet Experiments
3.1.1 Dataset and Training Details
AudioSet包含两百万条10秒长度音频片段,527个类别。balanced training, full training, evaluation set分别包含22k,2M和20k个样本。本文用到了预训练模型,平衡抽样,数据增强(混合【28】和spectrogram masking【29】)和模型融合方法(包括weight averaging【30】 和 ensemble【31】)。本文将batch_size设置为12,Adam优化器,二元交叉熵损失函数。对于balanced 数据集实验,初试学习率为5e-5,共训练25个epochs。对于full 数据集实验,初试学习率为1e-5,共训练5个epoch。
3.1.2 AudioSet Results
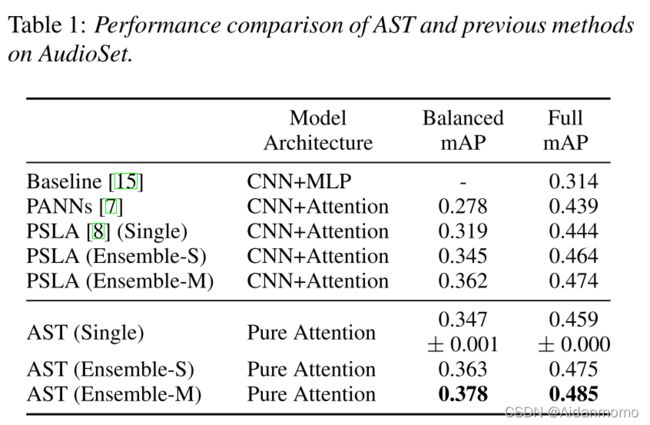
与文献【8】中设置相同,使用weight averaging和ensemble策略提升网络性能。
Ensemble-S:使用相同的设置对网络训练三次,但是使用不同的随机种子,之后对每次运行的最后一个checkpoint模型的输出进行平均,得到ensemble模型的结果。
Ensemble-S:用到了ensemble-S中的三个模型和另外的三个网络设置不同的模型(使用不同的patch)。
3.1.3 Ablation Study
本文进行了多种消融实验对模型的各个trick进行验证。
-
ImageNet预训练模型的影响
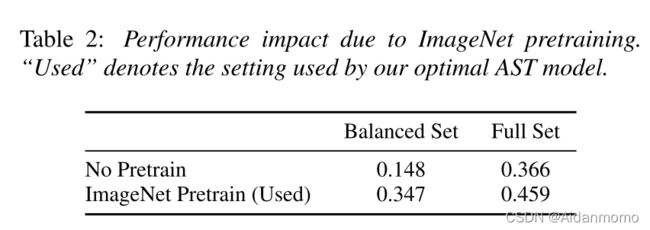
本文比较了是否使用预训练模型对AST的性能影响,如图2所示。
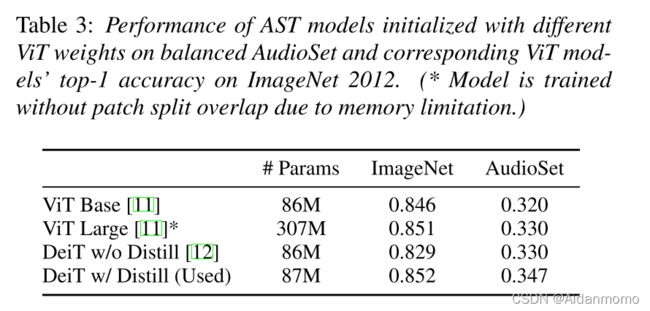
本文进一步探究了使用不同预训练模型对AST性能的影响,如表3所示。 -
位置编码适应性调整策略的影响:
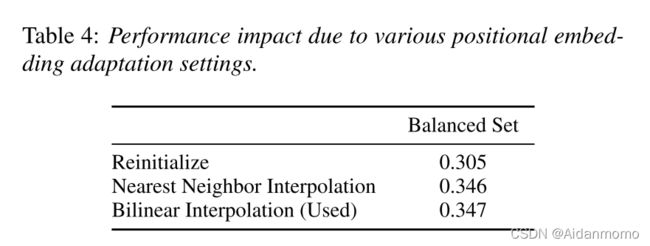
本文比较了三种不同的策略,结果如表4所示。 -
Patch分块重叠大小的影响:
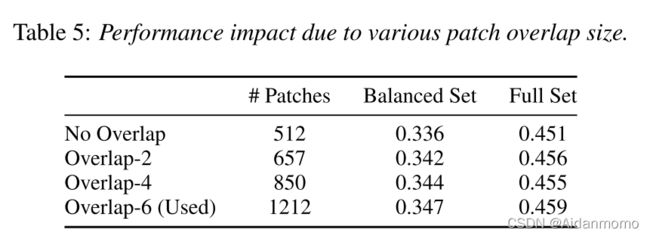
结果如表5所示。 -
patch块形状和大小的影响:
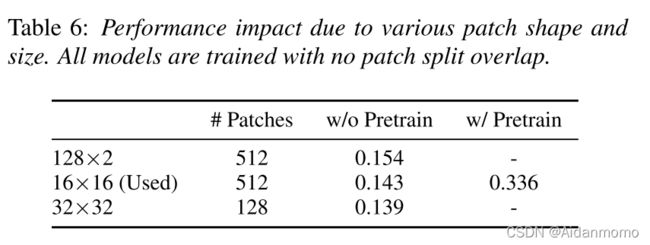
该文发现,使用128x2大小的patch能够获得更优的性能,但是因为没有相对应的ImageNet预训练模型,因此本文选用了16x16大小的patch。
本文剩余实验部分就不再进行记录了,有兴趣可以关注原文。