从大神Alex Smola与李沐离职AWS创业融资顺利,回看ChatGPT大模型时代“底层武器”演进...
图文原创:亲爱的数据
“We're building something big ... stay tuned. Talk to me if you want to work on scalable foundation models.”
“我们正在建造一个大项目……请继续关注。如果你想在可扩展基础模型上工作,请告诉我。”
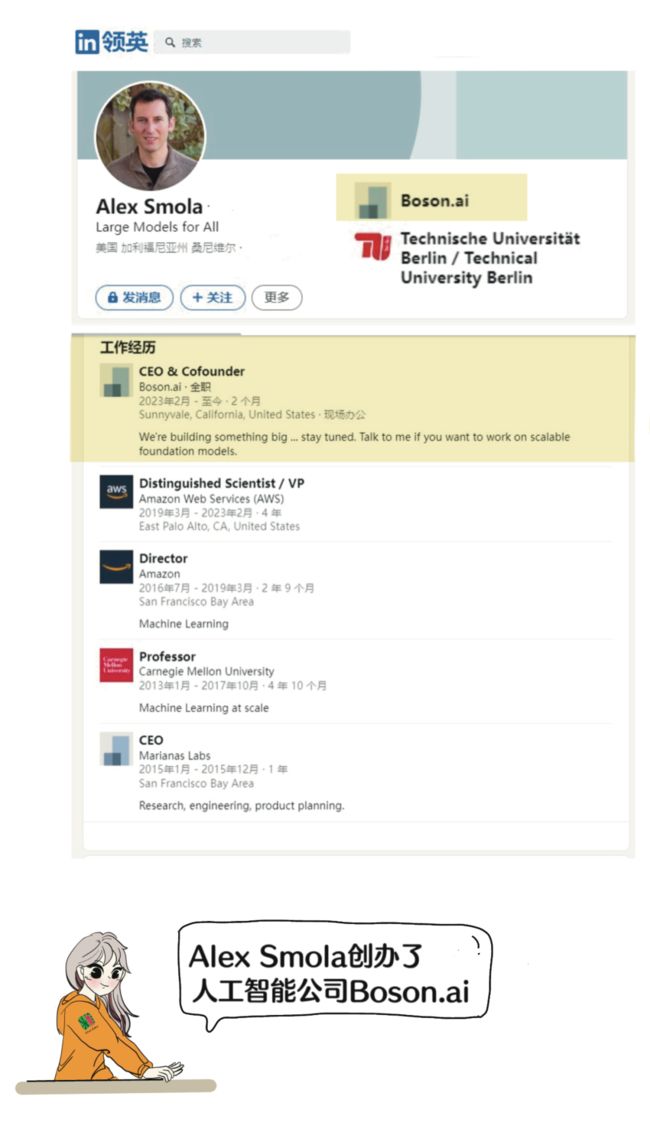
“参数服务器之父” Alex Smol教授已于2023年2月从美国著名公有云厂商亚马逊云科技(AWS)离职,创办了一家名为Boson.ai的人工智能公司。
公元2023年的春天,显然也是人工智能的又一春。
Alex Smol教授重新出发并在领英公布了新目标:
“scalable foundation models”(可扩展基础模型)。
这类厂商可被视为ChatGPT跟随者,说是挑战者也行。
不久之前,或者说一周前,他的就职宣言是:“我很高兴地告诉大家,我将在 Boson.ai 开始担任首席执行官兼联合创始人的新职务!”
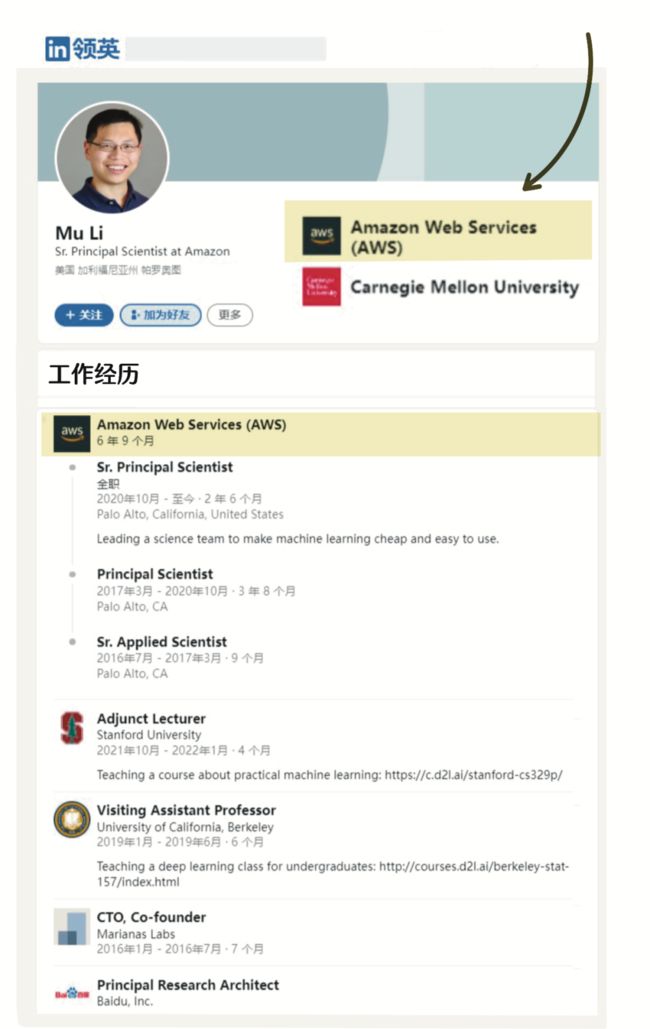
官宣语不惊人,实则不然,大神李沐也会加入,一同创业。
李沐既没有官宣离旧职,也没有官宣入新职。
业内人士对我说的原话是:“一起创业。”
更进一步的消息是:“融资也很顺利。”
两位神级AI科学家同期离职,共同创业。
有什么事情能感召AI大佬离开顶级大厂创业,那非ChatGPT这样的大模型机会莫属。
AI从不缺惊喜,一路走来都是惊喜,缺的是惊艳。AI已经好久没有新的神秘力量了,AI的尊严都被ChatGPT一把给找回来了。
多年观察,这两位大神师生的故事让我既感慨,又羡慕。
他们大约相识于2012年前后,计划读博的学生几乎都会提前和导师有所沟通。第一次的接触无处可考,可以确定的是2012年8月左右,李沐收到了美国卡内基梅隆大学(CMU)的入学通知。
人人都有万里路,只看你与谁同行。
此后的岁月里,大厂组队,一起写书,一起创业。
那本《动手学深度学习》被业内视为入门深度学习的优秀教材(虽然作者不止他俩)。
2021年2月,我曾在《搞深度学习框架的那帮人,不是疯子,就是骗子》一文中写过他们的部分经历:
“谈起亚马逊和MXNet框架的缘分,就不得不提起一位美国卡内基梅隆大学(CMU)的高人,Alex Smola教授,他也是李沐在CMU的博士导师。2016年7月,Alex Smola教授重返工业界,加入亚马逊AWS担任副总裁级别的科学家(职级为Distinguished Scientist/VP)。大半年后,2017年3月,李沐加入AWS,直接向老师Alex Smola汇报。 师徒同框,双手比V。”
此后,李沐大神洪水般的流量从知乎冲到B站,技术从业者追捧指数业界首屈一指。
“车库教学”“论文精讲”“师从李沐”……说实话,别说初学者、资深工程师、硕博牛人在看,连谭老师我也一连看了好几集,不仅弹幕欢乐,而且回味无穷。
7年光阴转眼间。
虽然Alex Smola是美国名校教授,前AWS高管,但是很多人对他还比较陌生。“参数服务器之父”的名头也不甚响亮。
参数服务器已经是“上古神器”,很早以前没有别的方法,只有它这一种。当年深入观察之后,至今令我印象深刻的,是其思路的巧妙。
这里一定要讲讲参数服务器的前世今生,以及一些AI训练方法上的演进。
一切糟心事的根源都在于模型在变大。
往哪里存,往哪里放,是其中的关键。
除了参数,还有样本抽取的输入,中间结果等等。这些东西,哪样搞坏搞错了,结果都承受不起。
模型小、单机单卡的情况下,信息都在一台机器上,一人闯天下。
要团队,就要分工。分布式训练中,信息要被多人分享。分享效率低,工作就会排队,排队就会浪费时间。
3个人分工,和300人分工,3000人分工,事情不是一个性质。
算力已经很厉害了,于是,AI计算呼唤高性能高带宽的存储和网络。
此时,Alex Smola教授的参数服务器就大有用处。如果你要问其本质是什么,我的答案是:分布式存储和分布式计算。
两者的占比关系是,分布式存储占大头,分布式计算占少量。
参数服务器是一个冲锋队,有领队(server),有分工队员(worker)。专业一点的说法是,分布式训练集群中的节点被分为两类:parameter server和worker。
说worker是分工队员似乎也不是很准确,因为worker这个程序,不是参数服务器的一部分,大家一起协同而已。
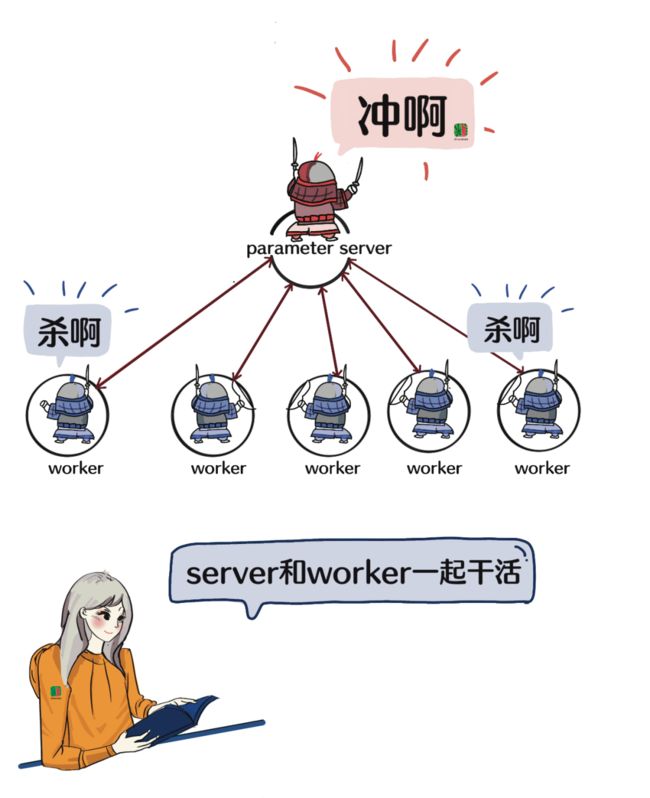
总之,server和worker一起干活,server存放模型参数,汇总完了再更新给worker。worker认真干活,server不停地给worker同步“消息”。
这样看上去server像职场里消息灵通的保管员。
除了存储,那一小部分计算是什么?是参数汇总和参数更新的策略等等。
简单原理如上。
一个底层软件层面的巧妙设计,让模型的扩展性战斗指数狂飙起来了。
假如没有参数服务器呢?那么,模型大的压力,就只剩硬件解决方案在硬抗。
比如,工程师做个两级或者三级存储,一部分放显存,一部分放内存,一部分放硬盘。
如此这般,还只是考虑了存储,把计算结果同步的事情搁置在一旁。
于是,我们会说参数服务器对深度学习模型训练的性能和效果的影响都很大。
AI时代,任何影响性能和效果的事情,都是天大的事情。模型靠这个吃饭,干砸了碗就砸了。
AI领域有难题,永远不缺乏解决问题的人。
这时候,超级计算机里的一个技术被拿来解决AI的问题。这个技术就是已经用在并行计算架构里的通信机制。
标志性的里程碑是Ring All reduce,出自2016年百度公司的一篇论文,技术是从“隔壁”借鉴而来的。这事从论文标题一眼就能看出来——《将高性能计算技术引入深度学习》。All Reduce翻译为规约,Ring是环状的意思。
原理就不讲了,Ring All reduce“表现”优秀,使用者越来越多。
或者我们调侃一句:“人工智能的臭毛病,让高性能计算治好了。”
再后来,谷歌和IBM等大公司又不断地拿出新思路。
很难知道OpenAI公司支撑ChatGPT大模型的类似技术是什么思路。
但我们知道,难题在产生,也在被攻克。
比如,大模型分布式存储需要支持1T到10T级别的存储量。
前面也提过,计算(训练)过程里,模型大,中间量(中间变量,优化器状态,参数更新频次和频次表,还有其他变量等等)的体量可能会膨胀4倍。
原来一室一厅够住了,现在高低得整个四室一厅。
这里只谈了一部分工作,协同训练是很有挑战的技术难题。
世事不难,吾辈何用。
在分布式上怎么把算力调动起来这件事远没有止境,并且正在持续吸引更多才俊加入到这个领域里来。
谈了很多都是陈年旧事,而人工智能方法上的提高从来没有停止,我只考古了其中几步。
重要之处在于,正是有了底层软件支持,才有了上层大模型的繁荣与爆发。
Alex Smola教授和李沐是这个领域里的大神,他们的实力和眼光都是世界一流的。
ChatGPT火了,在AI应用层急切呼唤惊艳产品的当下,硅谷著名风投A16Z说“基础设施提供商是这个市场中的最大赢家”。
我认为把AI平台、AI框架和AI芯片一起打包定义为“AI基础设施”较为合适。
AI芯片的赢面所有人都已看见,我认为在可预见的将来,Alex Smola教授在本文开头谈到的 “scalable foundation models” ,也就是基础大模型,会成为AI基础设施的一部分。
美国公司OpenAI的基础模型已经足够强大,对它进行改造和再加工的成本很低(相对于从头开发)。

如此一来,云计算厂商即将决胜的战场就是基础大模型能力,有则PaaS层胜出,无则惨败。
在“大模型一出,谁与争锋”的宏大背景音乐里,独立软件公司只要做得足够好,机会就在招手。我想Alex Smola教授和李沐大神选择加入这场战役的原因在于此。
他日“得AI框架者得天下”,
今朝“得基础大模型者得天下”。
大神们独立门户,有决心,有梦想,有市场机会,有资本支持,有对技术的热忱与投入,时不我待。
回忆几年前,好几家云计算厂商对大模型的投入,都想瞅着他人情况行事,没有投入的决心。甚至有的厂商,哪个技术中干开会提要做大模型,老板就当场痛骂谁。
这样也没错,谁不是扛着业绩边擦泪边奔跑。
只是跟随者这把椅子有时候坐着舒服,有时候不舒服。
此地彼方,唏嘘不已。
(完)

更多阅读
AI框架系列:
1.搞深度学习框架的那帮人,不是疯子,就是骗子(一)
2.搞AI框架那帮人丨燎原火,贾扬清(二)
漫画系列
1. 解读硅谷风投A16Z“50强”数据公司榜单
2. AI算法是兄弟,AI运维不是兄弟吗?
3. 大数据的社交牛逼症是怎么得的?
4. AI for Science这事,到底“科学不科学”?
5. 想帮数学家,AI算老几?
6. 给王心凌打Call的,原来是神奇的智能湖仓
7. 原来,知识图谱是“找关系”的摇钱树?
8. 为什么图计算能正面硬刚黑色产业薅羊毛?
9. AutoML:攒钱买个“调参侠机器人”?
10. AutoML:你爱吃的火锅底料,是机器人自动进货
11. 强化学习:人工智能下象棋,走一步,能看几步?
12. 时序数据库:好险,差一点没挤进工业制造的高端局
13. 主动学习:人工智能居然被PUA了?
14. 云计算Serverless:一支穿云箭,千军万马来相见
15. 数据中心网络:数据还有5纳秒抵达战场
16. 数据中心网络“卷”AI:迟到不可怕,可怕的是别人都没迟到
17. ChatGPT大火,如何成立一家AIGC公司,然后搞钱?
18. ChatGPT:绝不欺负文科生
DPU芯片系列:
1. 造DPU芯片,如梦幻泡影?丨虚构短篇小说
2. 永远不要投资DPU?
3. DPU加持下的阿里云如何做加密计算?
4. 哎呦CPU,您可别累着,兄弟CIPU在云上帮把手
长文系列:
1. 我怀疑京东神秘部门Y,悟出智能供应链真相了
2. 超级计算机与人工智能:大国超算,无人领航
3. 售前,航空母舰,交付,皮划艇:银行的AI模型上线有多难?

最后,再介绍一下主编自己吧,
我是谭婧,科技和科普题材作者。
为了在时代中发现故事,
我围追科技大神,堵截科技公司。
偶尔写小说,画漫画。
生命短暂,不走捷径。
个人微信:18611208992
原创不易,多谢转发
还想看我的文章,就关注“亲爱的数据”。