如何高效的阅读Python第三方库源码

本篇阅读时间约为 6 分钟。
1
前言
前几天拉个一个 Python 学习小组的群,有些小伙伴已经加进来了。其中有个小伙伴提了一个问题,这是一个比较好的问题,所以有必要单独拎出来写篇文章。
PS:如果还有想进群的小伙伴,可以公众号后台加下我的微信,拉你入群。
问题是这样的:

引出了今天要聊的主题,接下来咱们就来谈谈这个问题。以下方法,都是个人的做法,不一定适用于每一个人。但相信会有人和我一样,认为这样的方法比较高效,所以分享下。
2
有目标性的去学习
就像这位同学说到的,网上有人推荐去看各界大神 requests 的源码,学习其编程风格,然后揉入到自己的代码编写中,得以提升自己的编程境界。
但是往往有个问题,现成的第三库已经非常成熟,体系也异常庞大,哪里才是你应该去看的,去学习的点?
说出来不怕大家笑话,其实就连我自己也没有系统地看过 requests 库的源码。因为我觉得,无头苍蝇似的去看源代码,带来的记忆风格也是混乱的,而且往往记不住!
所以,就像上图中我的回答一样,虽然我不会系统的学习去看,但是在具体用到某一方法时,如果我对它的实现原理非常好奇,那此时,我会跟进去学习,原作者当时实现是一个怎样的思路。
但,什么时候才能产生好奇心?就是接下来要说的大前提。
3
前提条件,会用
产生好奇心的有个大前提,就是你得会用啊!
其实在上面聊天记录的下方,还有一个小伙伴给出了我想表述的大前提。

只有当你熟悉了一个东西的时候,有时候才会对它背后的原理感兴趣!
拿 requests 库的 get 请求方法来说,你都不知道它的作用是干什么的,去看源码学习,你知道最终你自己看的到底是为了实现什么功能嘛!对吧。。。
4
实战演示如何看源码
熟悉我的人都知道一点,能实战就实战,绝不多BB。(实战派!^_^)
给大家举个我写上篇文章时候的例子。PyQuery,这个库,当时我在看官方文档时,看到了这么一句话:

这句话什么意思呢?
上篇文章中,我们可以直接用 PyQuery 来构造模拟发出请求,大家还记得吧!文章中,我还特意写了一下,请求时它内部的机制代码。
为什么我会知道,它请求时内置的机制呢?一是看了官方文档,二是好奇心。
官方文档的 Scraping 部分,红框的意思是,默认使用了 python 原生的 urllib 库,如果你本地安装了 requests 库的话,它会直接使用 requests 库进行请求。
这是看了,官方文档得知的信息,但看完了,我依然是好奇,作者到底是如何在代码层面实现设计的。
下面请暂时记住这个问题,"官方文档说的这段话的代码具体是怎么实现的?"。带着这个问题继续往下看。
debug ,断点调试大法好!!
1. 好奇入口处打断点:

创建对象时,必经过 __init__ 方法,所以继续进去看看。PyCharm 直接 alt+鼠标点一下,就能调到底层源码。然后开启debug模式,F7 step into,进去。不会 debug ,看下之前写的这篇文章《
2. __init__ 里继续断点:

在判断 kwargs 之前,可以看到处理了一些操作,比如在 pq() 传参时,第一个参数默认给到形参 url 上。这些都是 Python 的一些基础,不会的话,需要自己恶补一下了!之前小课堂都有介绍。

可以看到 debug 到判断 kwargs 时, key 为 url ,value 则为我们创建对象时传入的地址。
继续往下看。

kwargs 本身是个 dict 类型,用 pop 方法把我们传入的地址赋值给了 url 变量。如果在 kwargs 没有 opener 这个key,则直接走到了我红框画的地方,并将 url 传进去。
继续进入这个方法看看:

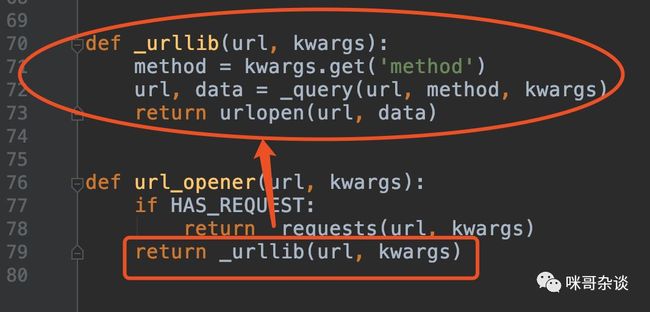
有个 HAS_REQUEST 变量,点一下看看:

看到了没,精华之处,很灵活的写法:
try:
import requests
HAS_REQUEST = True
except ImportError:
HAS_REQUEST = False通过抓取异常,来进行灵活库的判断。如果你有 requests 库,则变量 HAS_REQUEST = True,否则是 False。
这块的实现思想,是不是可以从原作者编写的代码中学习下,后续运用到自己的代码编写中。
最后,如果有 requests 库,就走到了相应的方法里,最终返回 requests 请求到的源代码。

反之,则用 Python 自带的 urllib 库去模拟请求。
5
总结
好了,简单的总结一下。
我个人推崇的方法是,携带着自己的具体问题去学习,看源码也是一个道理。
一步步的去从好奇点出发,逐步 debug 来挖到自己最关注的地方。然后学习作者的编程思维,加以记忆,利用到自己后续的代码编写中。
其实关于带着目标去学习这个方法,适用于大部分场景。还记得刚开始工作时,解决工作中问题,去学习编程,那段时间是我进步最快的时光。
嗯,到这里就结束了,看完本篇的你,有没有收获到什么呢?欢迎下方留言区留言交流呀!
