HDFS架构及原理
HDFS架构及原理
1、HDFS架构及存储
HDFS 采用Master/Slave的架构来存储数据,这种架构主要由四个部分组成,分别为HDFS Client、NameNode、DataNode和Secondary NameNode。一个HDFS集群是由一个NameNode和一定数目的DataNode组成的。NameNode是一个中心服务器,负责管理文件系统的名字空间 (Namespace )及客户端对文件的访问。集群中的DataNode一般是一个节点运行一个DataNode进程,负责管理它所在节点上的存储。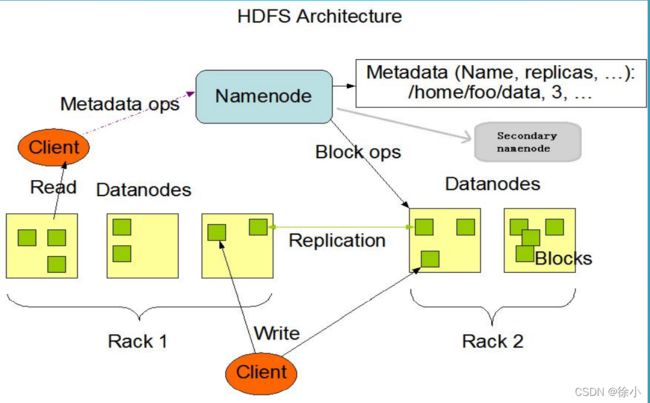
(1)、Client:就是客户端。
文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储。
与 NameNode 交互,获取文件的位置信息。
与 DataNode 交互,读取或者写入数据。
Client 提供一些命令来管理 HDFS,比如启动或者关闭HDFS。
Client 可以通过一些命令来访问 HDFS。
(2)、NameNode:就是 master,它是一个主管、管理者。
管理 HDFS 的名称空间
管理数据块(Block)映射信息
配置副本策略
处理客户端读写请求。
(3)、DataNode:就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
存储实际的数据块。
执行数据块的读/写操作。
(4)、Secondary NameNode:并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
辅助 NameNode,分担其工作量。
定期合并 fsimage和fsedits,并推送给NameNode。
在紧急情况下,可辅助恢复 NameNode。
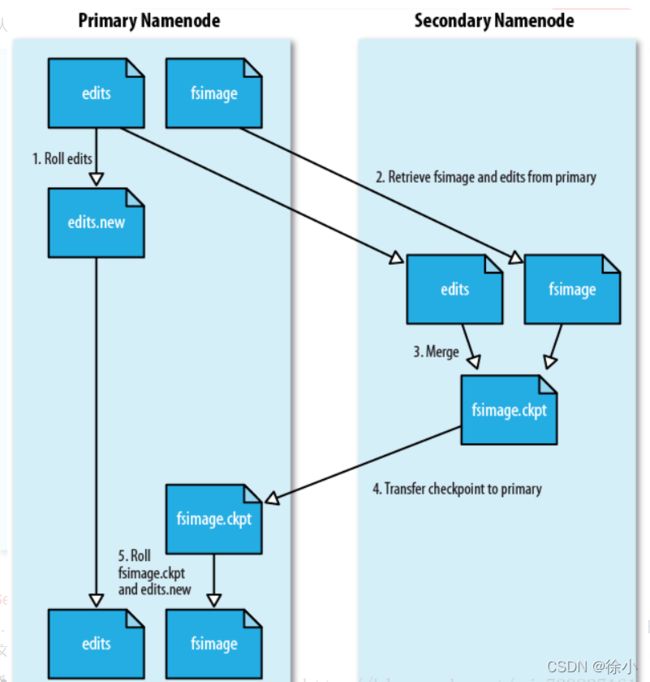
SecondaryNameNode的工作情况:
(1). SecondaryNameNode会定期和NameNode通信,请求其停止使用EditLog文件,暂时将新的写操作写到一个新的文件edit.new上来,这个操作是瞬间完成,上层写日志的函数完全感觉不到差别;
(2). SecondaryNameNode通过HTTP GET方式从NameNode上获取到FsImage和EditLog文件,并下载到本地的相应目录下;
(3). SecondaryNameNode将下载下来的FsImage载入到内存,然后一条一条地执行EditLog文件中的各项更新操作,使得内存中的FsImage保持最新;这个过程就是EditLog和FsImage文件合并;
(4). SecondaryNameNode执行完(3)操作之后,会通过post方式将新的FsImage文件发送到NameNode节点上
(5). NameNode将从SecondaryNameNode接收到的新的FsImage替换旧的FsImage文件,同时将edit.new替换EditLog文件,通过这个过程EditLog就变小了
除了这个自带的备份操作,还需要进行人工的备份,把一份fsimage到多个地方进行备份,万一namenode的节点坏了呢。
2、HDFS读流程
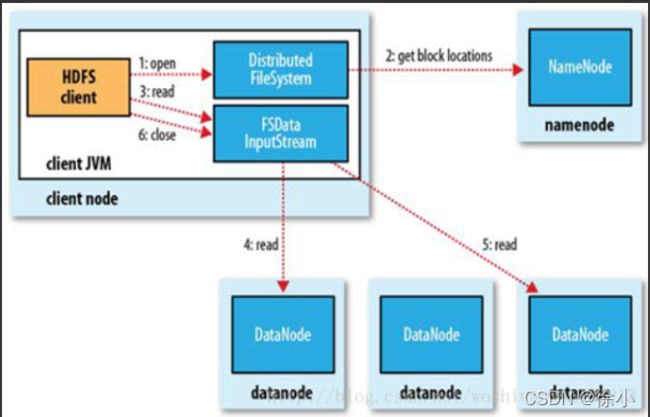
HDFS的文件读取原理,主要包括以下几个步骤:
(1)首先调用FileSystem对象的open方法,其实获取的是一个DistributedFileSystem的实例。
(2) DistributedFileSystem通过RPC(远程过程调用)获得文件的第一批block的locations,同一 block按照重复数会返回多个locations,这些locations按照hadoop拓扑结构排序,距离客户端近的排在前面。
(3) 前两步会返回一个FSDataInputStream对象,该对象会被封装成 DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流。客户端调用read方法,DFSInputStream就会找出离客户端最近的datanode并连接datanode。
(4) 数据从datanode源源不断的流向客户端。
(5)如果第一个block块的数据读完了,就会关闭指向第一个block块的datanode连接,接着读取下一个block块。这些操作对客户端来说是透明的,从客户端的角度来看只是读一个持续不断的流。
(6)如果第一批block都读完了,DFSInputStream就会去namenode拿下一批blocks的location,然后继续读,如果所有的block块都读完,这时就会关闭掉所有的流。
3、HDFS写流程
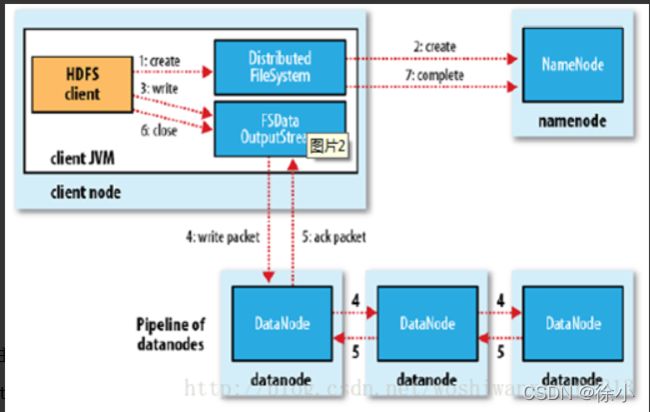
HDFS的文件写入原理,主要包括以下几个步骤:
(1)客户端通过调用 DistributedFileSystem 的create方法,创建一个新的文件。
(2)DistributedFileSystem 通过 RPC(远程过程调用)调用 NameNode,去创建一个没有blocks关联的新文件。创建前,NameNode 会做各种校验,比如文件是否存在,客户端有无权限去创建等。如果校验通过,NameNode 就会记录下新文件,否则就会抛出IO异常。
(3)前两步结束后会返回 FSDataOutputStream 的对象,和读文件的时候相似,FSDataOutputStream 被封装成 DFSOutputStream,DFSOutputStream 可以协调 NameNode和 DataNode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成一个个小packet,然后排成队列 data queue。
(4)DataStreamer 会去处理接受 data queue,它先问询 NameNode 这个新的 block 最适合存储的在哪几个DataNode里,比如重复数是3,那么就找到3个最适合的 DataNode,把它们排成一个 pipeline。DataStreamer 把 packet 按队列输出到管道的第一个 DataNode 中,第一个 DataNode又把 packet 输出到第二个 DataNode 中,以此类推。
(5)DFSOutputStream 还有一个队列叫 ack queue,也是由 packet 组成,等待DataNode的收到响应,当pipeline中的所有DataNode都表示已经收到的时候,这时akc queue才会把对应的packet包移除掉。
(6)客户端完成写数据后,调用close方法关闭写入流。
(7)DataStreamer 把剩余的包都刷到 pipeline 里,然后等待 ack 信息,收到最后一个 ack 后,通知 DataNode 把文件标示为已完成。
4、常用命令
1.hadoop fs
hadoop fs -ls /
hadoop fs -lsr
hadoop fs -mkdir /user/hadoop
hadoop fs -put a.txt /user/hadoop/
hadoop fs -get /user/hadoop/a.txt /
hadoop fs -cp src dst
hadoop fs -mv src dst
hadoop fs -cat /user/hadoop/a.txt
hadoop fs -rm /user/hadoop/a.txt
hadoop fs -rmr /user/hadoop
hadoop fs -text /user/hadoop/a.txt
hadoop fs -copyFromLocal localsrc dst 与hadoop fs -put功能类似
hadoop fs -moveFromLocal localsrc dst 将本地文件上传到hdfs,同时删除本地文件
2.hadoop fsadmin
hadoop dfsadmin -report
hadoop dfsadmin -safemode enter | leave | get | wait
hadoop dfsadmin -setBalancerBandwidth 1000
3.hadoop fsck 健康检查
4.start-balancer.sh 多节点数据平衡
5.hdfs diskbalancer 单节点多块磁盘数据平衡
5、MapReduce流程
WordCount运行和详解
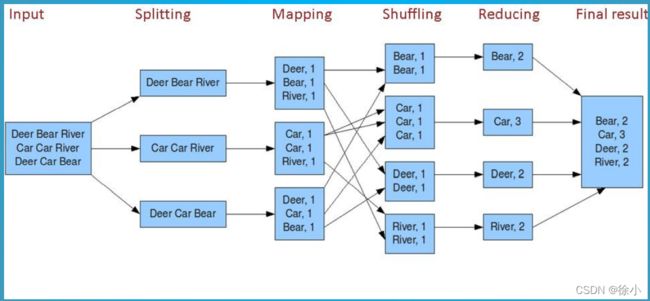
WordCount运行和详解
1.创建输入文件夹和wc.txt
[root@hadoopnn-01 ~]# hadoop fs -mkdir /input
[root@hadoopnn-01 ~]# vi wc.txt
Deer Bear River
Car Car River
Deer Car Bear
2.上传wc.txt至hdfs
[root@hadoopnn-01 ~]# hadoop fs -put wc.txt /input
3.运行wordcount
[root@hadoopnn-01 ~]# hadoop jar
$HADOOP_HOME/share/hadoop/mapreduce/hadoop- mapreduce-examples-2.7.2.jar wordcount /input /
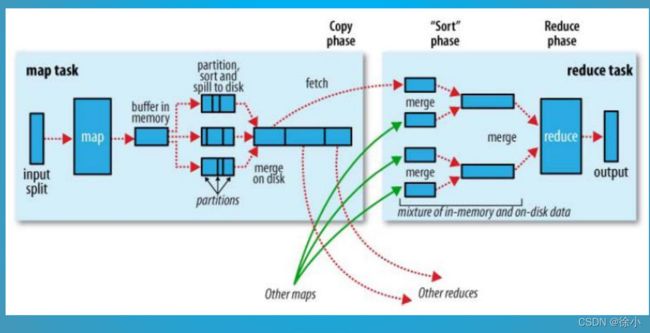
Map Task的整体流程:
1)Read:Map Task通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value。
2)Map:该阶段主要将解析出的key/value交给用户编写的map()函数处理,并产生一系列的key/value。
3)Collect:在用户编写的map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输入结 果。在该函数内部,它会将生成的key/value分片(通过Partitioner),并写入一个环形内存缓冲区中。
4)Spill:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并,压缩等操作。
5)Merge:当所有数据处理完成后,Map Task对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
Reduce的整体流程:
1)Shuffle:也称Copy阶段。Reduce Task从各个Map Task上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阀值,则写到磁盘上,否则直接放到内存中。
2)Merge:在远程拷贝的同时,Reduce Task启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或者磁盘上文件过多。
3)Sort:按照MapReduce语义,用户编写的reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一 起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现了对自己的处理结果进行了局部排序,因此,Reduce Task只需对所有数据进行一次归并排序即可。
4)Reduce:在该阶段中,Reduce Task将每组数据依次交给用户编写的reduce()函数处理。
5)Write:reduce()函数将计算结果写到HDFS。
6、Yarn架构及作业流程
YARN是Hadoop2.0版本新引入的资源管理系统,直接从MR1演化而来。
核心思想:将MP1中JobTracker的资源管理和作业调度两个功能分开,分别由ResourceManager和ApplicationMaster进程来实现。主要由ResourceManager和ApplicationMaster、NodeManager、ApplicationMaster和Container等组件组成
1)ResourceManager:负责整个集群的资源管理和调度。
2)ApplicationMaster:负责应用程序相关的事务,比如任务调度、任务监控和容错等。
YARN的出现,使得多个计算框架可以运行在一个集群当中。
1)每个应用程序对应一个ApplicationMaster。
2)目前可以支持多种计算框架运行在YARN上面比如MapReduce、Storm、Spark、Flink等。
架构
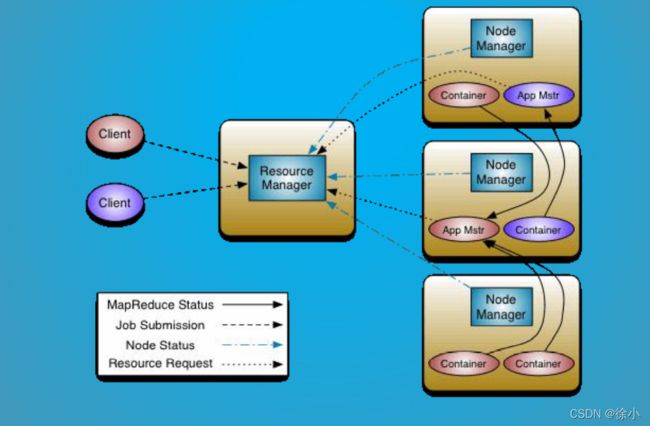 ●ResourceManager(RM):负责对各NM上的资源进行统一管理和调度。将AM分配空闲的Container运行并监控其运行状态。对AM申请的资源请求分配相应的空闲Container。主要由两个组件构成:调度器和应用程序管理器。
●ResourceManager(RM):负责对各NM上的资源进行统一管理和调度。将AM分配空闲的Container运行并监控其运行状态。对AM申请的资源请求分配相应的空闲Container。主要由两个组件构成:调度器和应用程序管理器。
● 调度器(Scheduler):调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序。调度器仅根据各个应用程序的资源需求进行资源分配,而资源分配单位是Container,从而限定每个任务使用的资源量。Shceduler不负责监控或者跟踪应用程序的状态,也不负责任务因为各种原因而需要的重启(由ApplicationMaster负责)。总之,调度器根据应用程序的资源要求,以及集群机器的资源情况,为应用程序分配封装在Container中的资源。调度器是可插拔的,例如CapacityScheduler、FairScheduler。
● 应用程序管理器(Applications Manager):应用程序管理器负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动AM、监控AM运行状态并在失败时重新启动等,跟踪分给的Container的进度、状态也是其职责。
● NodeManager(NM):NM是每个节点上的资源和任务管理器。它会定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态;同时会接收并处理来自AM的Container 启动/停止等请求。
● ApplicationMaster(AM):用户提交的应用程序均包含一个AM,负责应用的监控,跟踪应用执行状态,重启失败任务等。ApplicationMaster是应用框架,它负责向ResourceManager协调资源,并且与NodeManager协同工作完成Task的执行和监控。MapReduce就是原生支持的一种框架,可以在YARN上运行Mapreduce作业。有很多分布式应用都开发了对应的应用程序框架,用于在YARN上运行任务,例如Spark,Storm等。如果需要,我们也可以自己写一个符合规范的YARN application。
● Container:是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container 表示的。 YARN会为每个任务分配一个Container且该任务只能使用该Container中描述的资源
工作流程

●1:用户向YARN中提交应用程序,其中包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等。
● 2:ResourceManager为该应用程序分配第一个Container,并与对应的Node-Manager通信,要求它在这个Container中启动应用程序的ApplicationMaster。
● 3:ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7。
● 4:ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源。
● 5:一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务。
● 6:NodeManager为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
● 7:各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster查询应用程序的当前运行状态。
● 8:应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己。
当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:
a. 第一个阶段是启动ApplicationMaster;
b. 第二个阶段是由ApplicationMaster创建应用程序,为它申请资源,并监控它的整个运行过程,直到运行完成
MapReduce on YARN
a、MapReduce on TARN
1)YARN负责资源管理和调度;
2)ApplicationMaster负责任务管理。
b、MapReduce ApplicationMaster
1)MRAppMaster;
2)每个MapReduce启动一个MRAppMaster;
3)MRAppMaster负责任务切分、任务调度、任务监控和容错。
c、MRAppMaster任务调度
1)YARN将资源分配给MRAppMaster;
2)MRAppMaster进一步将资源分配给内部任务。
d、MRAppMaster容错
1)MRAppMaster运行失败后,由YARN重新启动;
2)任务运行失败后,由YARN重新申请资源。
资源管理
在YARN中,资源管理由ResourceManager和NodeManager共同完成,其中,ResourceManager中的调度器负责资源的分配,而NodeManager则负责资源的供给和隔离。
ResourceManager将某个NodeManager上资源分配给任务(这就是所谓的资源调度)后,NodeManager需按照要求为任务提供相应的资源,甚至保证这些资源应具有独占性,为任务运行提供基础的保证,这就是所谓的资源隔离
Memory资源的调度和隔离
基于以上考虑,YARN允许用户配置每个节点上可用的物理内存资源,注意,这里是“可用的”,因为一个
节点上的内存会被若干个服务共享,比如一部分给YARN,一部分给HDFS,一部分给HBase等,YARN配置的
只是自己可以使用的,配置参数如下:
(1)yarn.nodemanager.resource.memory-mb表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量。
(2)yarn.nodemanager.vmem-pmem-ratio任务每使用1MB物理内存,最多可使用虚拟内存量,默认是2.1。
(3) yarn.nodemanager.pmem-check-enabled是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
(4) yarn.nodemanager.vmem-check-enabled是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
(5)yarn.scheduler.minimum-allocation-mb单个任务可申请的最少物理内存量,默认是1024(MB),如果一个任务申请的物理内存量少于该值,则该对应的值改为这个数。
(6)yarn.scheduler.maximum-allocation-mb单个任务可申请的最多物理内存量,默认是8192(MB)。默认情况下,YARN采用了线程监控的方法判断任务是否超量使用内存,一旦发现超量,则直接将其杀死。由于Cgroups对内存的控制缺乏灵活性(即任务任何时刻不能超过内存上限,如果超过,则直接将其杀死或者报OOM),而Java进程在创建瞬间内存将翻倍,之后骤降到正常值,这种情况下,采用线程监控的方式更加灵活(当发现进程树内存瞬间翻倍超过设定值时,可认为是正常现象,不会将任务杀死),因此YARN未提供Cgroups内存隔离机制
CPU资源的调度和隔离
目前的CPU被划分成虚拟CPU(CPU virtual Core),这里的虚拟CPU是YARN自己引入的概念,初衷是,考虑到不同节点的CPU性能可能不同,每个CPU具有的计算能力也是不一样的,比如某个物理CPU的计算能力可能是另外一个物理CPU的2倍,这时候,你可以通过为第一个物理CPU多配置几个虚拟CPU弥补这种差异。用户提交作业时,可以指定每个任务需要的虚拟CPU个数。在YARN中,CPU相关配置参数如下:
(1)yarn.nodemanager.resource.cpu-vcores表示该节点上YARN可使用的虚拟CPU个数,默认是8,注意,目前推荐将该值设值为与物理CPU核数数目相同。如果你的节点CPU核数不够8个,则需要调减小这个值,而YARN不会智能的探测节点的物理CPU总
数。
(2) yarn.scheduler.minimum-allocation-vcores单个任务可申请的最小虚拟CPU个数,默认是1,如果一个任务申请的CPU个数少于该数,则该对应的值改为这个数。
(3)yarn.scheduler.maximum-allocation-vcores单个任务可申请的最多虚拟CPU个数,默认是32。默认情况下,YARN是不会对CPU资源进行调度的,你需要配置相应的资源调度器
http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_design.html