【Dubbo原理】(一)Dubbo的微内核架构及SPI机制
文章目录
- Dubbo的微内核架构及SPI机制
-
- 1.什么是微内核架构
-
- 1.1.基本架构
- 1.2.设计关键点
- 2.Dubbo中的微内核架构
-
- 2.1.Dubbo的分层
- 2.2.Dubbo的插件模块
- 2.3.Dubbo的核心系统
- 3.Dubbo的SPI机制
-
- 3.1.什么是SPI机制
- 3.2.SPI加载实现类
- 3.3.Java中的SPI
- 3.4.Dubbo中的SPI
- 4.Dubbo的扩展点加载
-
- 4.1.指定名称加载
- 4.2.扩展点自适应加载
- 4.3.扩展点自动激活加载
- 5.扩展点在项目中的应用
-
- 5.1.配置文件路径的坑
- 5.2.自定义过滤器
Dubbo的微内核架构及SPI机制
最近在想系统的学习一下Dubbo的实现原理,本来想着平时使用最多的就是Dubbo的服务注册,就先从这一块着手去学习。但是在看源码的时候发现有的地方显得晦涩难懂,例如Dubbo在发布一个协议的时候,无法理解是Dubbo如何在多个协议中,自动的去找到一个最合适的协议的。
在这种情况下,决定先从Dubbo是如何加载插件入手进行学习,于是就有了这篇Dubbo的SPI机制。
在了解Dubbo的SPI机制之前,我们可以先了解一下什么叫做微内核架构,因为Dubbo的设计采用的就是采用 Microkernel + Plugin 模式,也就是核心系统 + 插件模块的微内核模式。
1.什么是微内核架构
微内核架构也被称为插件式架构,它是一种面向功能进行拆分的架构模式,除了我们接下来要聊的Dubbo以外,我们日常使用的IDEA、Eclipse这类IDE软件,操作系统,银行系统等都是采用了这种架构模式。
1.1.基本架构
微内核架构包含两类组件:核心系统和插件模块。
- 核心系统:负责加载插件,只包含使系统可运行的最少功能。
- 插件模块:独立存在的模块,包含特殊的处理逻辑,额外的功能等,用于强化和扩展核心系统,提供更多的能力。
架构示例图如下所示:

上图中的核心系统是相对比较稳定的,随着业务或需求的变化,我们只需要修改插件模块,或引入新的插件模块即可。将变化封装在插件里面,达到快速灵活的扩展的目的,而且也不会影响架构的整体稳定性。
1.2.设计关键点
微内核架构设计的关键点有三个:插件管理、插件连接、插件通信。
- 插件管理:核心系统需要知道从什么地方可以加载什么插件,常见的是插件注册表机制。
- 常见的插件注册表有:配置文件、代码、数据库等。
- 注册表里面应该包含:插件的名字、加载位置等。
- 插件连接:核心系统制定插件的加载机制,即如何加载去加载插件。
- 一般会使用IoC、Factory等方式管理插件模块的生命周期。
- 插件通信:涉及到多个插件的协作,但是插件之间没有直接联系,就需要核心系统提供插件的通信机制。
- 不过也不是绝对的没有联系,有的框架就直接在插件中注入插件。
2.Dubbo中的微内核架构
Dubbo在设计之初就保持一个原则,就是Dubbo的架构一定要有高度的扩展能力,方面使用者自行扩展,这也是为什么Dubbo选择使用微内核架构。
Dubbo的设计原则
对于Dubbo来说,它的功能都是通过扩展点来实现的,并且所有的扩展点都是可以被用户自定义替换的。
同时,使用URL来携带配置信息,贯穿Dubbo的整个生命周期,所有在Dubbo生命周期中使用到的扩展点,都会体现在URL上。
例如下面就是一个简单的Dubbo接口对应url。
dubbo://192.168.0.111:20882/com.ls.dubbo.api.HelloApi?anyhost=true&application=spi-provider&cluster=failfast&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=com.ls.dubbo.api.HelloApi&loadbalance=leastactive&metadata-type=remote&methods=sayHello&pid=5888&release=2.7.8&retries=1&revision=1.0&side=provider&threads=100×tamp=1642085450506&version=1.0
为了更清楚的显示配置的内容,下面把这个URL美化了一下:
dubbo://192.168.0.111:20882/com.ls.dubbo.api.HelloApi
anyhost=true
application=spi-provider
cluster=failfast
deprecated=false
dubbo=2.0.2
dynamic=true
generic=false
interface=com.ls.dubbo.api.HelloApi
loadbalance=leastactive
metadata-type=remote
methods=sayHello
pid=5888
release=2.7.8
retries=1
revision=1.0
side=provider
threads=100
timestamp=1642085450506
version=1.0
从上面至少可以看出使用的协议、IP端口号、接口地址、负载均衡策略等等,URL和后面要聊到的扩展点息息相关。
2.1.Dubbo的分层
下面是一张从官网的扒下来架构图,左边蓝色的部分是Consumer端使用的,右边绿色的部分是Provider端使用的,中轴线上则是两端共用部分。
重点看一下最右侧的两个标记:
API:指的是框架的使用者需要使用的部分,例如我们日常开发中写的接口,配置文件等。SPI:指的是框架的开发者或者拓展者使用的部分,例如负载均衡策略、集群容错策略、协议、序列化方式等等,属于SPI这部分的,就是可以拓展的拓展点。

为了更加直观的感受一下Dubbo的拓展点,我又扒了另外一张图调用链路图下来,在这张图中,目之所及的所有的绿色的节点,都是Dubbo的扩展点。

对Dubbo的扩展点有了一点感觉之后,我们现在可以尝试从微内核架构的两个角度 - 核心系统和插件模块去分析一下Dubbo。
2.2.Dubbo的插件模块
有了上面两幅图的基础,Dubbo的插件模块就十分好理解了,上述的所有的扩展点,就组成了Dubbo的插件模块。
接下来,我们重点分析一下Dubbo的核心系统。
2.3.Dubbo的核心系统
要分析Dubbo的核心系统,首选要找到Dubbo的核心功能是什么。
对于这个问题,我是这么理解的,Dubbo首先是一个RPC框架,它最主要的是RPC的远程调用功能,其次才是一个分布式治理框架,加入了许多分布式治理的插件。
那什么是RPC呢?
RPC翻译过来是远程过程调用,就体现在这个远程上,如果让我去实现一个最简单的RPC调用,不用考虑用户可以透明调用、容错、负载、传输性能等等。
那我完全可以直接创建一个TCP连接,用统一的通信协议,统一的序列化方式,把客户端和服务端连起来,然后就可以传输数据了。
远程调用使用到的传输协议,序列化方式等,对应Dubbo架构中的Protocol层,及Protocol层下面的Remoting部分包含的三层。
那对于Dubbo来讲,这个几层就是它的核心系统了吗?
对于Dubbo的核心层,官网上是这么说的:
在 RPC 中,Protocol 是核心层,也就是只要有 Protocol + Invoker + Exporter 就可以完成非透明的 RPC 调用
这句话中提到了3个概念:Protocol,Invoker, Exporter
- Protocol:指的是Dubbo的协议,常见的有
Dubbo,REST,HTTP,inJVM等等。 - Invoker:可以简单的理解为服务调用者的封装。
- Exporter:可以简单理解为对服务提供者的封装。
有了这几个概念的理解,那这句话的意思就很明白了,Dubbo最核心的层就是Protocol,远程连接、序列化等也不是必须要的。
因为Dubbo在设计时考虑了一个场景,即Provider和Consumer在同一个JVM中运行,这种情况下完全可以将远程调用直接转换成本地调用,这就是上面提到的inJVM协议的作用。
那Protocol就是Dubbo的核心系统吗?
我们再回过头看一下,核心系统的职责:负责加载插件,只包含使系统可运行的最少功能。
显然,Protocol并没有加载插件的能力,而且Protocol本身也是可以扩展的。
Dubbo的扩展能力是通过SPI机制来实现的,而它的核心系统应是下面我们聊到的Dubbo的扩展类加载器 - ExtensionLoader。
3.Dubbo的SPI机制
3.1.什么是SPI机制
SPI 全称为 Service Provider Interface,翻译为: 服务提供程序接口。
它是一种服务发现机制,本质就是将接口的实现类的完全限定名配置在文件中,服务在运行的过程中,可以通过加载器读取配置文件并加载实现类,从而达到在运行时动态的为接口替换实现。
如何更通俗的理解SPI?
其实SPI与我们日常工作中使用到的API接口是有相似之处的,我们不妨先看一看API的实现方式。
API的实现方式
API的实现方式对我们来说已经非常简单了,服务的提供方对外提供API接口,调用方直接引用接口进行调用。
下面是我撸了一张简图:
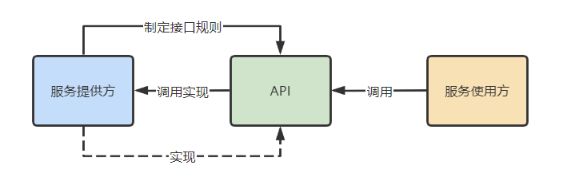
- 调用方:只关心接口的方法签名、出入参规则等,而不关心这个接口内部是如何实现的。
- 提供方:只需保证接口的数据传输的规则不变,实现逻辑、算法等可以任意进行替换。
我们接下来看SPI的实现方式,感受一下两者的区别与相似之处。
SPI的实现方式
用说人话的方式来描述,SPI就是服务的调用方定义接口规则,交由服务提供方去做实现。

-
调用方:只关系获取到的结果,而不关心接口内部如何实现的。
-
提供方:只需要按照服务使用方提供的规则进行实现即可。
综上,API和SPI都是服务调用方依赖接口而不依赖具体的实现,区别在于接口的规则是由提供方制定,还是由调用方制定。
3.2.SPI加载实现类
在提供方完成了SPI接口的实现之后,该如何交给调用方使用呢?
其实上面已经提到了,将实现类的完全限定名写在文件中,按照约定优于配置的原则,提供方将这个文件放到一个约定好的位置,调用方去扫描这个位置的文件,就可以获取到完全限定名,通过类加载器将实现类加载到服务中就可以使用了。
下面是几种常见的SPI实现机制。
3.3.Java中的SPI
简单的实现一个Java对SPI的应用,只需要4步。
- 提供一个Interface,定义规则。
- 实现Interface。
- 使用约定的配置文件格式,将Interface与实现关联起来。
- 通过
ServiceLoader加载此Interface下的所有实现。
其中,1、4是服务调用方做的,2、3由服务提供方实现,下面是一个简单的代码实现示例。
- Interface与实现类:
public interface JavaSpi {
void sayHello();
}
public class JavaSpiA implements JavaSpi {
@Override
public void sayHello() {
System.out.println("Hello! I'm JavaSpiA");
}
}
public class JavaSpiB implements JavaSpi {
@Override
public void sayHello() {
System.out.println("Hello! I'm JavaSpiB");
}
}
-
配置文件
在约定的位置
META-INF/services,按照Interface的完全限定名作为文件名,如com.ls.dubbo.consumer.spi.java.JavaSpi创建配置文件。在配置文件中填写实现类的完全限定名,如下:
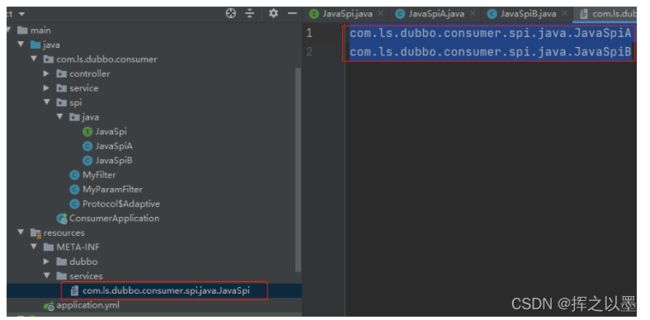
-
加载实现类
做完了上面的步骤之后,就可以使用
ServiceLoader加载了。@Test public void testJavaSpi() { ServiceLoader<JavaSpi> javaSpis = ServiceLoader.load(JavaSpi.class); System.out.println("Java SPI"); javaSpis.forEach(JavaSpi::sayHello); }最后打印出结果:

3.4.Dubbo中的SPI
Dubbo没有直接使用Java的SPI,而是在这基础上重新实现了一套功能更强的SPI机制。
为什么不直接使用Java的SPI呢?
Dubbo之所以不直接使用Java的SPI机制,主要是两个方面的考虑:
-
第一个是性能方面的考虑:
从上面的示例也看看出,
ServiceLoader一次性将JavaSpiA,JavaSpiB都加载出来,如果我只想使用JavaSpiA而恰好JavaSpiB的初始化过程又比较慢的时候,就会影响到对JavaSpiA的使用体验。我们可以以负载均衡策略来想象一下,在2.7.8版本中默认的负载均衡策略有5种,如果我在项目中只需要使用到默认的
random策略,其他4种策略是完全不需要初始化的。 -
第二个功能增强:
Dubbo对扩展点之间的通信提供了
IoC与AOP的增强,可以通过setter注入的方式来注入其他的扩展点。
Dubbo的SPI简单使用
与Java的SPI实现方式非常类似,同样也是4步:
- 提供一个Interface,加上
@SPI注解,标记为Dubbo的扩展点。 - 写两个实现类实现这个Interface。
- 在
META-INF/Dubbo目录下按照约定创建配置文件。 - 使用
ExtensionLoader加载扩展点。
实现如下:
-
扩展点代码实现
// Dubbo 的扩展点接口需要加上@SPI注解标记 @SPI public interface DubboSpi { void sayHello(); } public class DubboSpiA implements DubboSpi { @Override public void sayHello() { System.out.println("Hello! I'm DubboSpiA"); } } public class DubboSpiB implements DubboSpi { @Override public void sayHello() { System.out.println("Hello! I'm DubboSpiB"); } } -
配置文件
Dubbo的配置文件名还是接口的完全限定名,但填充的内容变成了
key,value的形式。

-
扩展点实现加载
优化了Java的SPI中一次性把接口下的实现全部加载的情况。
Dubbo的SPI可以根据配置文件中的
key按需加载,如图所谓,想加载哪个就加载哪个。

如何拓展Dubbo生命周期中的组件?
上边看到的是Dubbo的SPI的简单使用方式,但我们在日常开发中更加需要的可能是对Dubbo生命周期中的某个组件进行扩展和替换。
在上面2.1中,Dubbo的调用流程图中已经看到过了,那些绿色的节点就是Dubbo预留了扩展点接口,并且提供了一系列的默认实现,我们可以选择使用哪一个默认实现。如果这些默认实现都不满足要求,我们也可以根据扩展点接口做自定义实现。
Dubbo约定好配置文件的存放目录一共有3个:
META-INF/dubbo/internal:存放Dubbo内部已经定义好的扩展点实现META-INF/dubbo:存放用户自定义的扩展点实现META-INF/services:用于兼容Java的SPI
一般情况下,只有我们在做拓展的时候,才会使用到META-INF/dubbo这个文件路径,另外两个我们自己会用到的情况比较少。
再回到我们的主题,如何拓展Dubbo已有的生命周期组件。
其实非常简单,以负载均衡的拓展为例,先找到Dubbo提供的LoadBalance接口,然后按照上面的步骤做一遍就可以了。

聊到这里,问题来了,难道我们在日常开发中拓展的实现,还需要我们自己手动通过getExtension去加载吗?上图中的@Adaptive("loadbalance")又是什么意思呢?
我们接下来就去看一下,Dubbo对于扩展点的加载方式。
4.Dubbo的扩展点加载
在Dubbo中的扩展点一共有三种加载方式,分别为:
- 指定名称加载
- 扩展点自适应加载
- 扩展点自动激活加载
4.1.指定名称加载
就是上面代码中写的拓展点的加载方式,指定一个key去进行加载,例如:
ExtensionLoader.getExtensionLoader(LoadBalance.class).getExtension("random");
如何实现的呢?
上面的代码可以看到,获取扩展点的实现分为了两步:
- 通过扩展点接口,获取到这个接口对于的类加载器对象。
- 通过类加载器,以传入
key作为标识,获取扩展点实例。
获取extensionLoader:
尝试从缓存中获取类加载器,获取不到就创建一个。


可以看到,类加载器本身的也就通过ExtensionFactory这个类加载器来实现的,那么一定有一个默认的类加载器。
这里是通过getAdaptiveExtension()做扩展点自适应,来获取默认的ExtensionFactory的,这个后面再提。
获取扩展实例:
如果忽略缓存的逻辑,扩展实例对象的获取一共分为5个步骤:
- 使用扩展点接口的完全限定名找到配置文件,将里面的
key,value加载到一个Map中。 - 通过传入的
key获取到对应的实现类的完全限定名。 - 实例化扩展点。
- 执行依赖注入,将其他的扩展点注入到当前实例中。
- 如果有其他包装类型的扩展点包装了当前扩展点,则再做一下包装。

依赖注入是通过setter方法来注入的,获取到对应的setter方法的参数,通过参数获取到扩展点,再注入到当前的扩展点中。

以Protocol为例来解释一下包装,通过配置文件可以看到,Protocol这个扩展接口有包装类的实现,例如:

在ProtocolFilterWrapper中,使用构造方法做了一下包装,包装的目的就是为了增强结构的功能,例如这个Filter的包装就是为了在执行方法调用的时候,可以进入到过滤器链中。

通过以上的处理,就可以获取到一个扩展点的实例了。
一个简化的流程图如下所示:

4.2.扩展点自适应加载
扩展点自适应就是通过上下文信息,取自动的选择一个合适的扩展点进行加载。这里的上下文信息,其实就是Dubbo的URL。
扩展点要做到自适应,需要标记上@Adaptive注解,这个注解可以加在类上,也可以加载方法上。
-
加在类上:表示在使用
getAdaptiveExtension(),直接返回这个类的实例对象。我们在4.1中分析
getExtensionLoader源码的时候出现的扩展点自适应加载,就是这种类型。ExtensionLoader.getExtensionLoader(ExtensionFactory.class).getAdaptiveExtension();去查看
ExtensionFactory的实现有三个:

其中
AdaptiveExtensionFactory就是一个可以自适应的扩展点,所以上面的结果就是返回AdaptiveExtensionFactory的实例。

-
加在方法上:会在通过动态代理在运行时生成一个代理对象,重写打了
@Adaptive注解的方法,在重写的会解析URL,获取上下文参数中的key,再通过指定名称进行加载。以
Protocol接口为例,这个接口中两个方法标注了@Adaptive注解,分别是export和refer。@SPI("dubbo") public interface Protocol { @Adaptive <T> Exporter<T> export(Invoker<T> invoker) throws RpcException; @Adaptive <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException; }ExtensionLoader会创建一个代理对象:

将这个代码美化了一下,可以直观看到,扩展点的自适应加载就是在从
URL中获取协议的值,如果没有获取到就默认使用Dubbo协议,然后使用获取到的协议名称通过指定名称的加载方式来加载扩展点。

结合上面的流程图,就是这个样子:

4.3.扩展点自动激活加载
对于可以同时加载多个实现的集合类型的扩展点,使用扩展点的自动激活,可以起到简化配置的作用。
所谓的集合类型的扩展点,就是类似于Filter这样的接口,在一次请求中,需要执行的可能不是一个过滤器,而是过滤器链。我们就可以使用扩展点自动激活的方式去拓展这个过滤器链。
或获取一个可以自动激活的扩展点,只需要在扩展点的实现上加入@Activate注解就可以了,例如:
@Activate
public class MyActiveFilter implements Filter
有时候还需要区分过滤器是属于provider还是consumer端,可以使用group进行区分,例如标记一个只会在provider端自动激活的过滤器:
@Activate(group = PROVIDER)
public class MyActiveFilter implements Filter
除此之外,如果需要满足某个条件才能触发,还可以使用value进行标识,例如在URL中出现了myActiveFilter就自动激活:
@Activate(group = PROVIDER, value = "myActiveFilter")
public class MyActiveFilter implements Filter
如何剔除过滤器?
如果在某些场景下,我们自定义过滤器是为了替换Dubbo原有的默认过滤器,在配置文件中剔除即可,例如,在provider中剔除默认的exception过滤器,只需要在配置文件中加入:
dubbo.provider.filter=-excepton
- :表示剔除。
5.扩展点在项目中的应用
5.1.配置文件路径的坑
先说一个我在测试时遇到的坑,其实是Idea的锅。
我在创建META-INF/dubbo目录的时候,没有注意创建包路径与创建文件夹路径的区别,习惯性的创建。

在这种路径下放的配置文件,无论如何都加载不到,最后才发现的文件夹路径的问题,可以看一下Idea中的文件夹路径,正确的路径和错误的路径显示的一模一样:

在Idea上开发需要注意这一点。
5.2.自定义过滤器
以Filter为例,先创建一个扩展类实现。
import org.apache.dubbo.rpc.*;
/**
* @author liushuang
*/
public class MyFilter implements Filter {
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
System.out.println("方法调用前执行");
Result result = invoker.invoke(invocation);
System.out.println("方法调用后执行");
return result;
}
}
然后,新增配置文件:

此时,扩展点已经加入到Dubbo中了,此时可以写一个Dubbo接口的调用过程,在@Reference中指定filter
@Service
public class HelloService {
@DubboReference(version = "1.0", filter = {"myFilter"})
private HelloApi helloApi;
public String sayHello(String name) {
return helloApi.sayHello(name);
}
}
最后,去调用sayHello方法,从控制台输出的内容可以确定,已经进入了Myfilter做过滤操作。

扩展点自动激活的实现方式
对于Filter这种集合性质的扩展点,可以使用自动激活的方式,使用这种方式的话,在注解上都不需要加入标识了,例如在Provider端加入一个统计过滤器:
@Activate(group = PROVIDER)
@Component
public class MyActiveFilter implements Filter {
private MyCounter myCounter;
@Autowired
public void setMyCounter(MyCounter myCounter) {
this.myCounter = myCounter;
}
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
System.out.println("进入自定义过滤器");
if ("sayHello".equals(invocation.getMethodName())) {
myCounter.count();
}
return invoker.invoke(invocation);
}
}
然后在配置文件上写上,就可以生效了。