Centos7配置hadoop
Centos7配置hadoop
下载Centos7
Index of /apache/hadoop/common (cnnic.cn)
这里下载最新版hadoop-3.3.0
配置网卡
规划ip地址
master 192.168.197.140/24
slave1 192.168.197.141/24
slave2 192.168.197.142/24
使用nat方式(静态IP地址)
在三台虚拟机中
cd /etc/sysconfig/network-scripts
vi ifcfg-ens33
修改网卡内容(这是其中一台,其余两台除了ip地址不一样,其余地方都一样)
TYPE=Ethernet
BOOTPROTO=static #将dhcp改为static
DEFROUTE=yes
PEERDNS=yes
PEERROUTES=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_PEERDNS=yes
IPV6_PEERROUTES=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=51581610-8015-41d6-bf88-5cef4f3a7f74 #默认生成即可
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.197.140 #添加或修改对应的ip地址,按照一个ip master两个ip slave
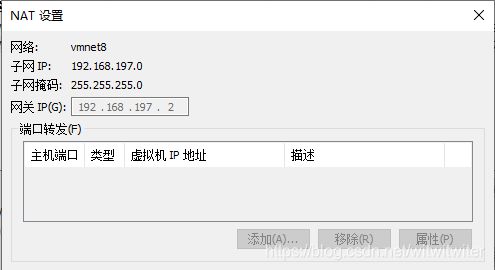
GATEWAY=192.168.197.2 #相应的网关地址,可以在虚拟网络编辑器中的VM8的nat设置中看
NETMASK=255.255.255.0
DNS1=114.114.114.114
网络配置
设置主机名
hostnamectl set-hostname master
修改/etc/hosts文件
vi /ect/hosts
添加如下内容
192.168.197.140 master
192.168.197.141 slave1
192.168.197.142 slave2
最后重启网络
systemctl restart network
配置时间同步
Master节点
yum install chrony
vi /etc/chrony.conf
底部添加修改如下内容
local stratum 10
allow 192.168.197.0/24
Slave节点
yum install chrony
vi /etc/chrony.conf
添加如下内容
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
#上面三个有就不用加
server master iburst
设置自动重启
systemctl enable chronyd.service
systemctl restart chronyd.service
查看配置结果
chronyc sources
配置java(三台虚拟机都要配,包括一个master两个slave)
在VM中安装Centos7的GUI版本后,使用root账号进行java环境配置
查看本地是否带有java环境
yum list installed |grep java
使用root账户卸载掉原装的java
yum -y remove java-1.8.0-openjdk*
yum -y remove tzdata-java*
编辑环境变量
vi /etc/profile
添加如下内容
export JAVA_HOME=/usr/lib/jvm/java-1.8.0
export JRE_HOME=$JAVA_HOME/jre
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
保存退出后输入
source /etc/profile
使配置生效。
验证java是否配好了使用如下指令查看
java -version
若正常弹出版本号则证明安装好了。
安装hadoop
创建hadoop用户(root账号且仅在master做)
useradd -m hadoop -s /bin/bash # 创建新用户hadoop
passwd hadoop #设置密码
给予hadoop权限
visudo
找到root ALL=(ALL) ALL 这行
在下面加上
hadoop ALL=(ALL) ALL #(ALL)后面一个Tab
将hadoop压缩包使用xftp上传到 /opt/hadoop 目录在这个目录打开命令行
tar -zxvf hadoop-3.3.0.tar.gz
mv hadoop-3.3.0 hadoop
配置env(root账号且仅在master做)
vi /opt/hadoop/hadoop/etc/hadoop/hadoop-env.sh
找到 export JAVA_HOME
将前面的 # 去掉然后在后面加上 /usr/lib/jvm/java-1.8.0
最终效果为
export JAVA_HOME=/usr/lib/jvm/java-1.8.0
配置核心文件(root账号且仅在master做)
vi /opt/hadoop/hadoop/etc/hadoop/core-site.xml
需要加入的代码
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
/opt/hadoop/hadoopdata
内容的放置位置
将内容放在这里
配置文件系统(root账号且仅在master做)
vi /opt/hadoop/hadoop/etc/hadoop/hdfs-site.xml
需要加入的代码
dfs.replication
1
内容的放置位置
将内容放在这里
配置 yarn-site.xml 文件(root账号且仅在master做)
vi /opt/hadoop/hadoop/etc/hadoop/yarn-site.xml
需要加入的代码
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.address
master:18040
yarn.resourcemanager.scheduler.address
master:18030
yarn.resourcemanager.resource-tracker.address
master:18025
yarn.resourcemanager.admin.address
master:18141
yarn.resourcemanager.webapp.address
master:18088
内容的放置位置
将内容放在这里
配置MapReduce计算框架文件(root账号且仅在master做)
vi /opt/hadoop/hadoop/etc/hadoop/mapred-site.xml
需要加入的代码
mapreduce.framework.name
yarn
内容的放置位置
将内容放在这里
配置master的slaves文件(root账号且仅在master做)
vi /opt/hadoop/hadoop/etc/hadoop/slaves
需要加入的代码
slave1
slave2
复制master上的Hadoop到slave节点(root账号且仅在master做)
scp -r /opt/hadoop root@slave1:/opt
scp -r /opt/hadoop root@slave2:/opt
Hadoop集群的启动-配置操作系统环境变量(三个虚拟机都要做)
cd /opt/hadoop
vi ~/.bash_profile
进入文件后将下面的内容加到文件底部
#HADOOP
export HADOOP_HOME=/opt/hadoop/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
保存退出后执行
source ~/.bash_profile
使改动生效
创建Hadoop数据目录(root账号且仅在master做)
mkdir /opt/hadoop/hadoopdata
格式化文件系统(root账号且仅在master做)
hadoop namenode -format
定义用户(root账号且仅在master做)
进入Hadoop安装目录下找到sbin文件夹
1、对于start-dfs.sh和stop-dfs.sh文件,添加下列参数:
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
2、对于start-yarn.sh和stop-yarn.sh文件,添加下列参数:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
开启SSH服务(hadoop需要用到ssh,root账号且仅在master做)
systemctl start sshd.service
启动和关闭Hadoop集群(root账号且仅在master做)
cd /opt/hadoop/hadoop/sbin #安装主目录
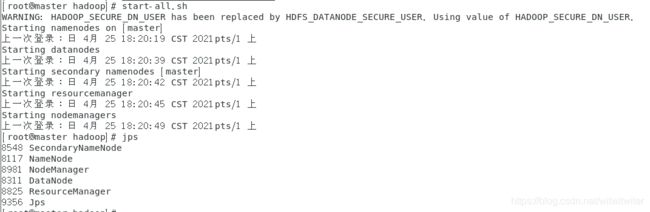
start-all.sh #开启
stop-all.sh #关闭
验证是否启动
jps
如果显示:SecondaryNameNode、 ResourceManager、 Jps 和NameNode这四个进程,则表明主节点master启动成功
进入Web端
http://master:9870

总结
配置hadoop在一开始要把网络规划好,master以及slave。一定要java8以及相关环境,使用hadoop一定要开启ssh。没有定义用户的话可能会报错。web页面的端口,HDFS为9870,YARN为18088。