elk6.4.3安装部署指导手册
前言
介绍
lucene是是搜索引擎库,Elasticsearch是一个分布式的RESTful风格的全文搜索引擎,基于lucene封装, 操作简化,分布式集群,高可用。Elasticsearch是面向文档(document oriented)的,这意 味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。
功能
1.分布式搜索和分析引擎
2.全文搜索,结构化搜索,数据分析
3.海量数据实时处理
交互方式
1.curl
2.es-header
3.kibana
restful
GET 用来获取资源
POST 用来新建资源(也可以用于更新资源)
PUT 用来更新资源
- 简述
本文总结了Elasticsearch的安装及使用中部分插件的安装,我们常听到的ELK是Elasticsearch、logstast、kabana的简称,EFK是指Elasticsearch、filebeat、kabana的简称,其中logstast、filebeat、kabana不是必须的,根据使用实际情况进行选择性安装。
- 系统环境要求
2.1. 安装介质
本次编译安装方式使用的版本为6.4.3
elasticsearch-6.4.3.tar.gz
elasticsearch-head-master.tar.gz
kibana-6.4.3-linux-x86_64.tar.gz
filebeat-6.4.3-linux-x86_64.tar.gz
logstash-6.4.3.tar.gz
node-v14.15.4-linux-x64.tar.xz
若要安装其他版本请到官网自行下载,下载地址查考如下:
elasticsearch
https://www.elastic.co/guide/en/elasticsearch/reference/index.html
elasticsearch-head
https://github.com/mobz/elasticsearch-head
Kibana
https://www.newbe.pro/Mirrors/Mirrors-Kibana/
Filebeat
https://www.newbe.pro/Mirrors/Mirrors-Filebeat/
Logstash
https://repo.huaweicloud.com/logstash/
Node
http://nodejs.cn/download/
2.2. 服务器准备
Linux系统版本在Redhat7或者Centos7版本及以上,本次安装以下面为例
| 服务器地址 | 服务器主机名 | 操作系统版本 |
|---|---|---|
| 192.168.139.130 | elk-master | Redhat7.6 |
| 192.168.139.131 | elk-node1 | Redhat7.6 |
| 192.168.139.132 | Elk-node2 | Redhat7.6 |
2.3. 用户和组
组规划
| 组名 | 组ID | 描述 |
|---|---|---|
| es | 2000 | es启停用户组 |
用户规划
| 用户 | 用户ID | 主属组 | 主目录 | 描述 |
|---|---|---|---|---|
| es | 2000 | es | /home/es | es启停用户 |
2.4. 系统参数调整
#修改每个进程最大同时打开文件数太小
vim /etc/security/limits.conf
#用户可以打开的最大的文件数量
* soft nofile 65536
* hard nofile 65536
#用户可以打开的最大进程数
* soft nproc 4096
* hard nproc 4096
#上述4条命令的“*”可以替换成要使用的实际用户es,该参数最小为4096,根据机器性能进行调整
#修改每个进程最大/etc/security/limits.d/20-nproc.conf
* soft nproc 4096
root soft nproc unlimited
#锁定内存
* hard memlock unlimited
* soft memlock unlimited
#修改文件/etc/systemd/system.conf
DefaultLimitNOFILE=65536
DefaultLimitNPROC=32000
DefaultLimitMEMLOCK=infinity
#修改/etc/sysctl.conf文件
vm.max_map_count=655360
#该参数最小为655360,根据机器性能进行调整
#生效
sysctl -p
2.5. 文件系统
软件文件系统
| *文件系统* | *大小* | *说明* |
|---|---|---|
| /home/es | 100G | 根据业务需要自行定义 |
ElasticSearch日志文件系统
对于安装的Elasticsearch,acess、error及转发应用的debug等日志需要输出到/home/es/elasticsearch/log目录下,如果有公用的应用日志文件系统,如已有应用日志文件系统/xxxxlog,可以在/xxxxlog下创建elasticsearch的日志和数据目录,即/xxxxlog/elasticsearch/(logs/data),另外,应用设计人员需要考虑定期备份和清理相关日志和数据信息。
2.6. 监听端口
| 产品 | 端口 |
|---|---|
| Elasticsearch | 9200 |
| Elasticsearch-head | 9100 |
| Kabane | 5601 |
- JDK环境及安装包准备
3.1. JDK环境安装
Elasticsearch是基于jdk环境开发,所以在使用时必须存在jdk环境,本次使用jdk1.8环境
安装包为:jdk-8u271-linux-x64.tar.gz
将安装包分别上传到三台服务器中,进行解压,并配置JDK环境
#将安装包解压在/usr/local下
tar -zxvf jdk-8u271-linux-x64.tar.gz -C /usr/local

#修改/etc/profile文件
#输入: vi /etc/profile
#在当前界面输入:Shift+g #定位到文件末尾,增加如下参数,进行保存。
export JAVA_HOME=/usr/local/jdk1.8.0_271
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH:$HOME/bin
输入:source /etc/profile
注意:当前修改的为系统全局变量,若要只更改es启动用户变量,则修改es用户的~/.bash_profile文件

3.2. 把下载好的安装包,拖拽到/software目录中。这里的software目录是我新建的
命令:mkdir /tmp/software
3.3. 解压包
解压文件,把解压好的文件移到home/es文件夹中。注意一下这里下载的压缩包zip格式的只能在本目录下解压后在移动,其它格式的直接在后面写上 -C /home/es可直接移动到/home/es文件夹下,其中node-v14.15.4-linux-x64.tar.xz是安装需要的依赖包,直接安装在/usr/local下。
输入:tar -zxf elasticsearch-6.4.3.tar.gz -C /home/es
输入:tar -zxf elasticsearch-head-master.tar.gz -C /home/es
输入:tar -zxf kibana-6.4.3-linux-x86_64.tar.gz -C /home/es
输入:tar -zxf logstash-6.4.3.tar.gz -C /home/es
输入:tar -zxvf filebeat-6.4.3-linux-x86_64.tar.gz -C /home/es/
输入:tar -xf node-v14.15.4-linux-x64.tar.xz -C /usr/local/
- Elasticsearch安装配置
4.1. 修改主机名
输入:vi /etc/hosts
把原来的内容删掉写入新的主机名,我的改为bigdata01。(更改之后不要忘了保存, 后面也是)

4.2. 配置Elasticsearch的参数
192.168.139.130为master节点,在该服务器上执行如下操作
输入:vi /home/es/elasticsearch-6.4.3/config/elasticsearch.yml,按shift+g,快速定位到尾行,按i在下一行插入以下内容:
# 增加或更改以下内容
# 集群中的名称
cluster.name: master-node
# 该节点名称
node.name: elk-master
# 意思是该节点为主节点
node.master: true
# 表示这不是数据节点
node.data: false
#修改data存放的路径,可以不配置使用默认数据路径:$es_home/date
path.data: /home/es/es-data/data
#修改logs日志的路径,可以不配置使用默认日志路径:$es_home/logs
path.logs: /home/es/es-data/logs
#配置内存使用用交换分区
bootstrap.memory_lock: true
# 监听全部ip,在实际环境中应设置为一个安全的ip
network.host: 0.0.0.0
# es服务的端口号
http.port: 9200
# 配置自动发现
discovery.zen.ping.unicast.hosts: ["192.168.139.130", "192.168.139.131", "192.168.139.132"]
#上述配置可以在该文件中找到直接修改,也可以直接添加在末尾,上述参数配置完成后,新增如下两个参数,为es_head配置做准备
http.cors.enabled: true
http.cors.allow-origin: "*"
分别在131/132上执行文件备份
cp -a elasticsearch.yml elasticsearch.yml_bak
拷贝上述elasticsearch.yml到被关节点192.168.139.131/132
scp /home/es/elasticsearch-6.4.3/config/elasticsearch.yml 192.168.139.131:/home/es/elasticsearch-6.4.3/config/
scp /home/es/elasticsearch-6.4.3/config/elasticsearch.yml 192.168.139.132:/home/es/elasticsearch-6.4.3/config/
192.168.139.131
分别在131/132上对拷贝过来的elasticsearch.yml文件进行修改,修改参数如下
node.name: elk-node1
node.master: false
node.data: true
192.168.139.132
node.name: elk-node2
node.master: false
node.data: true
4.3. 启动Elasticsearch服务
进入es安装路径/home/es/elasticsearch-6.4.3/bin
执行:sh elasticsearch,查看输出结果如下表示启动成功(若要进行后台启动,请执行nohup ./elasticsearch >/dev/null 2 > &1 & 该执行不会产生nohup.out日志,启动日志请查看elasticsearch输出日志)

4.4. 启动报错案例及处理方法
#1、在日志发现如下内容,这样也会导致启动失败
[2021-01-30T19:19:01,641][INFO ][o.e.b.BootstrapChecks] [elk-1] bound or publishing to a non-loopback or non-link-local address, enforcing bootstrap checks
[2021-01-30T19:19:01,658][ERROR][o.e.b.Bootstrap ] [elk-1] node validation exception
[1] bootstrap checks failed
[1]: system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk
#解决:修改配置文件,在配置文件添加一项参数
vim /etc/elasticsearch/elasticsearch.yml
bootstrap.system_call_filter: false
#2、在日志发现如下内容,这样也会导致启动失败
max number of threads [2048] for user [elk] is too low, increase to at least [4096]
#解决
该处错误是因为elk在启动的时候需要的最小max user processes的值要在4096以上,修改其大小,然后重启服务即可
具体方法修改
vim /etc/security/limits.d/20-nproc.conf
#将里面的1024改为4096(ES最少要求为4096)
* soft nproc 4096
#(注意:有时候按照上面方式修改重启也不会修改成功,这个时候我们还要加上如下参数,若修改了limit.conf文件,首先修改limit.conf文件内容具体如下:
* hard nproc 4096
#3、在日志发现如下内容,启动报错
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
#说明是vm.max_map_count值太小。
#解决方法
#切换到root用户
#执行命令:
sysctl -w vm.max_map_count=262144
#查看结果:
sysctl -a|grep vm.max_map_count
#显示:
vm.max_map_count = 262144
#上述方法修改之后,如果重启虚拟机将失效,所以:
#解决办法:
#在 /etc/sysctl.conf文件最后添加一行
vm.max_map_count=262144
#即可永久修改
4.5. 测试服务是否启动成功
方法一:在当前Linux系统中执行下列语句看输出结果,若能正常访问则如下截图
curl 192.168.139.130:9200

方法二:在可以访问该Linux服务器的任意一台windows主机上访问,若能正常访问则如下截图 http://192.168.139.130:9200

- Head-master及node的安装配置
elasticsearch-head是一个界面化的集群操作和管理工具,可以对集群进行傻瓜式操作。你可以通过插件把它集成到elasticsearch(5.0版本后不支持此方式),也可以安装成一个独立webapp。elasticsearch-head插件是使用JavaScript开发的,依赖Node.js库,使用Grunt工具构建,所以等会我们要安装elasticsearch-head,还需要先安装Node.js和Grunt。 elasticsearch-head主要的作用有以下这些方面:
显示集群的拓扑,并且能够执行索引和节点级别操作
搜索接口能够查询集群中原始json或表格格式的检索数据
能够快速访问并显示集群的状态
有一个输入窗口,允许任意调用RESTful API。这个接口包含几个选项,可以组合在一起以 产生不同的结果;
请求方法(get、put、post、delete),查询json数据,节点和路径
支持JSON验证器
支持重复请求计时器
支持使用javascript表达式变换结果
elasticsearch-head有两种部署方式:
编译安装
插件安装
下面总结了两种部署方式的优缺点,建议使用编译安装方式进行部署。
| 安装方式 | 优点 | 缺点 |
|---|---|---|
| 编译安装 | 无论何时何地只要能连接到部署es-head的任何主机均可以直接访问。 | 安装过程复杂,安装时要借助的依赖包较多,网络限制较多 |
| 插件安装 | 安装方便,只需将插件解压到本地即可使用。 | 使用时需要在当前要连接的主机中安装es-head插件 |
下面介绍下编译安装
5.1. 配置node环境
Head-master安装前需要使用cnpm命令,该命令包含在node加载包中,所以在安装前需要先对该环境进行配置。(一般情况下Head-master只需要一台服务器即可,该配置只要执行在安装的服务器上即可)
输入:vi /etc/profile 按shift+g定位到底部,然后按i在下一行插入以下内容:
#添加node_home变量
NODE_HOME=/usr/local/node-v14.15.4-linux-x64
#把node_home变量添加到环境变量中
PATH=$PATH:$NODE_HOME/binexport
PATH NOTH_HOME
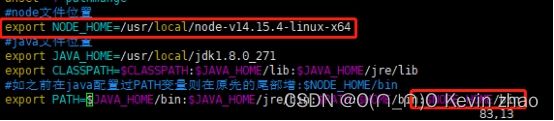
修改后别忘记保存,保存后执行:source /etc/profile,是配置生效。
node -v #验证node.js是否安装成功,如果能查看到版本号说明安装成功
npm -v #验证npm工具是否安装成功,如果能查看到版本号说明安装成功
cnpm -v #验证npm工具是否安装成功,如果能查看到版本号说明安装成功

注意:当前修改的为系统全局变量,若要只更改es启动用户变量,则修改es用户的~/.bash_profile文件
5.2. 安装grunt工具
#进入elasticsearch-head插件的源码目录,此处将elasticsearch-head-master安装包名字改成了es-head。
cd /home/es/es-head
#安装grunt工具,由于在国内连接国外的镜像速度奇慢无比,所以我们使用了国内taobao的镜像。
npm install -g grunt --registry=https://registry.npm.taobao.org
#使用npm编译es-head源码,但是建议大家不要用这个这种方式安装,因为使用npm编译源码会下载很多依赖,这些依赖默认到国外镜像下载,所以速度会很慢,可以使用下列国内镜像
npm install
#看下面的命令,安装cnpm,这是链接中国的镜像。
npm install -g cnpm --registry=https://registry.npm.taobao.org
#使用cnpm代替npm编译es-head源码 编译好后es-head根目录下会出现一个叫node_modules的目录,该目录就是存放源码编译后的可执行文件。
cnpm install
#需要了解的是:以上两种方法都可以安装完成,只是在安装速度上有所差异
通过以上执行操作,在安装看到node_modules则说明我们的elasticsearch-head-master安装完成

5.3. elasticsearch-head-master插件配置修改
5.3.1. 设置插件管理界面跨主机访问
插件默认是只有本机的IP才能访问的,也就是127.0.0.1,这样我们就无法跨主机访问head 插件的管理界面,所以需要把它改成所有IP地址都能访问。该配置在head插件安装目录根目录下,文件名为Gruntfile.js。在该配置文件中connect-server-options下添加hostname: ‘0.0.0.0’,注意最后的“,”这个配置,这样就不限制IP地址的访问了,具体看以下配置文件截图:
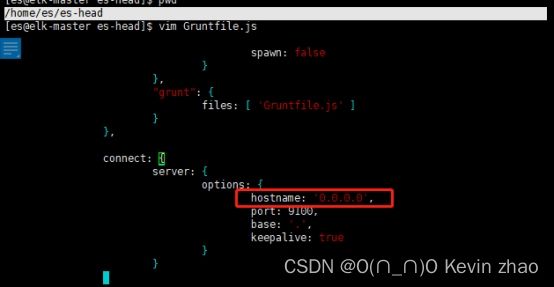
注意:要把主机防火墙9100的端口打开,这里就不写出打开防火墙端口的命令了,之前也说过很多了。
5.3.2. 设置连接elasticsearch的地址
head插件默认是连接本机的elasticsearch的,如果你的elasticsearch和head插件是安装在同一台主机上,那么就不需要修改配置,如果不是安装在同一台主机的,就必须修改配置了,配置文件在head插件安装目录的_site目录下,文件名为app.js。
#编辑app.js文件
vi /home/es/es-head/_site/app.js
#编辑app.js文件把this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://localhost:9200" 这行配置中的localhost改成你elasticsearch服务所在IP地址(如果安装在同一台主机就不需要修改)
示例如下:
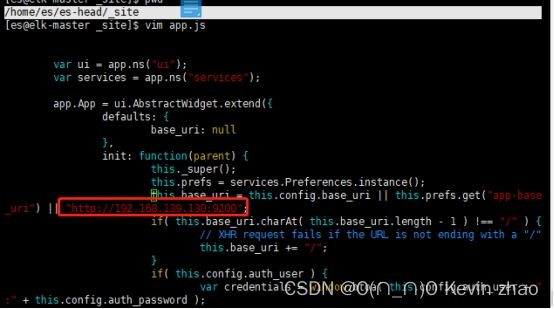
5.4. elasticsearch配置允许跨域访问
#进入elasticsearch存放配置文件的目录
cd /home/es/elasticsearch-6.4.3/config
#编辑elasticsearch配置文件
vi elasticsearch.yml
#在elasticsearch.yml配置文件中最末尾添加如下两个属性,使head插件可以访问elasticsearch
http.cors.enabled: true
http.cors.allow-origin: "*"
具体看以下配置文件截图:

注意:若在安装elasticsearch时,配置了该参数,此步可以省略。
5.5. 运行Head插件及验证
若我们是在elasticsearch启动时执行的4.4步骤,则需要重启elasticsearch服务
5.5.1. 运行head插件
#先进入到head插件的安装目录根目录
cd /home/es/es-head
#使用刚刚安装的grunt工具运行head插件,该方法是前台启动。
grunt server
#后台启动方法,并不做启动日志保留
nohup grunt server >/dev/null 2 > &1 &
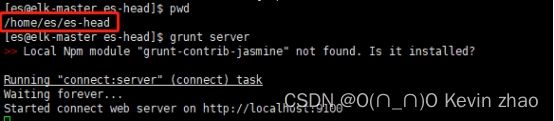
若要停止es-head服务,采用前台启动直接“Ctrl+c”即可,若后台启动则查询head的进程号,直接kill pid即可。
5.5.2. 查询es-head进程号
es-head监听端口为9100,所以可以直接通过端口来查进程号,下面显示89996即为es-head的进程号

5.5.3. 启动验证
在Linux服务器中可以使用curl命令进行验证
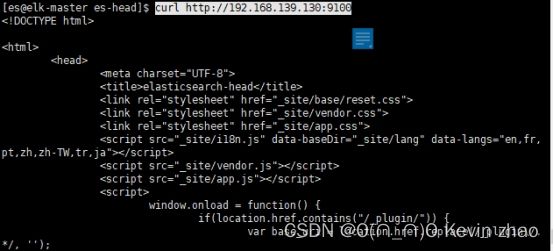
在windows中可以直接访问该地址,显示如下,则配置成功
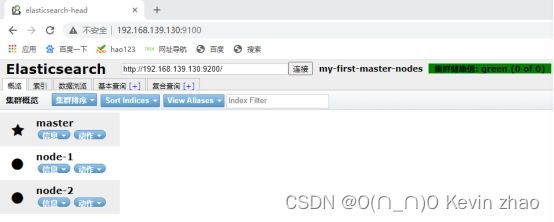
- Filebeat 安装及配置
Filebeat 是一款轻量型日志收集工具,可转发汇总日志、文件等内容。
其主要特点为:
a. 断点续传。(如遇日志转发过程中网络中断,会在恢复后从断开的点继续转发)
b. 自适应转发速率。(当logstash 处理内容满载时会通知filebeat 转发率减少,当 logstash 处于轻松状态,Filebeat则加大转发)
6.1. Filebeat安装
Filebeat是免安装插件,直接下载其压缩包,进行解压后,对相应的配置文件进行配置即可使用
6.2. 修改filebeat.yml配置文件
进入到安装路径下,将源filebeat.yml文件备份,然后新建filebeat.yml文件,文件内容如下:
#进入filebeat安装路径
cd /home/es/filebeat-6.4.3-linux-x86_64
#创建filebeat使用的配置文件filebeat.yml
vim filebeat.yml
#文件内容如下#引用文件类型
filebeat.inputs:
- type: log
enabled: true
paths:
- /usr/local/nginx/logs/*.log
#kibana输出地址
setup.kibana:
host: "localhost:5601"
#elasticsearch输出地址
output.elasticsearch:
hosts: ["localhost:9200"]
6.3. 后台启动 filebeat
启动时指定启动引用文件,启动后无报错,证明启动成功
nohup ./filebeat -c filebeat.yml &
6.4. 补充
Filebeat一般与elasticsearch和kibana配合使用,组成EFK使用,使用Kibana对elasticsearch进行监控。在kibana上可以进行图形化展示,使elasticsearch使用过程中的系统的使用情况更好的展示出来。
- Logstash安装及配置
7.1. 配置Logstash
进入到解压好的源码包filebeat-6.4.3-linux-x86_64的conf文件夹下,找到logstash的配置文件logstash.yml
#配置文件修改
vim /home/es/logstash-6.4.3/config/logstash.yml
#设置节点名称,一般写主机名
node.name: elk-master
#创建logstash 和插件使用的持久化目录
path.data: /home/es/logstash-6.4.3/plugin-data
#开启配置文件自动加载
config.reload.automatic: true
#定义配置文件重载时间周期
config.reload.interval: 3s
#定义访问主机名,一般为域名或IP
http.host: "192.168.139.130"
7.2. 创建持久化目录
mkdir -p /home/es/logstash-6.4.3/plugin-data
7.3. 配置logstash 从Filebeat 输入、过滤、输出至elasticsearch(logstash 有非常多插件,详见官网,此处不列举)
7.3.1. 安装logstash-input-jdbc 和logstash-input-beats-master 插件
#安装logstast-input-jdbc
/home/es/logstash/bin/logstash-plugin install logstash-input-jdbc
#下载logstast-plugins文件
wget https://github.com/logstash-plugins/logstash-input-beats/archive/master.zip -O /tmp/software/master.zip
#解压文件到指定文件夹
unzip -o /tmp/software/master.zip -d /home/es/logstash /opt/master.zip

7.3.2. 配置logstash input 段
#创建from_beat.conf文件
vim /usr/local/logstash/from_beat.conf
#from_beat.conf文件内容
input {
beats {
port => 5044
}
}
output {
stdout { codec => rubydebug }
}
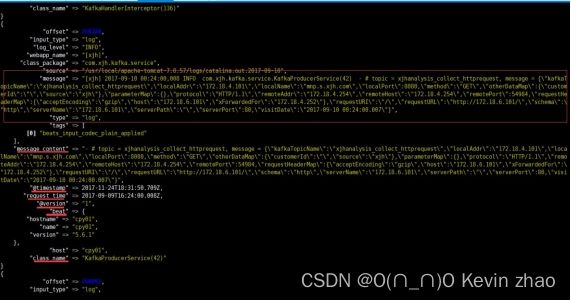
启动logstash 看是否能接收到filebeat 传过来的日志内容,要确保filebeat 在日志节点上启动正常。此时只测试传入是否正常,并未对原始日志进行过滤和筛选
/usr/local/logstash/bin/logstash -f /usr/local/logstash/config/from_beat.conf
启动后如果没有报错需要等待logstash 完成,此时间可能比较长

7.3.3. 配置 logstash filter 段,修改/usr/local/logstash/from_beat.conf 为以下内容,配置完成后再次启动logstash,此时如果成功,输出内容应该是自己正则表达式捕获后的字段切分内容。
input {
beats {
port => 5044
}
}
filter {
#过滤access 日志
if ( [source] =~ "localhost\_access\_log" ) {
grok {
match => {
message => [ "%{COMMONAPACHELOG}" ]
}
}
date {
match => [ "request_time", "ISO8601" ]
locale => "cn"
target => "request_time"
}
#过滤tomcat日志
} else if ( [source] =~ "catalina" ) {
#使用正则匹配内容到字段
grok {
match => {
message => [ "(?\[\w+\])\s+(?\d{4}\-\d{2}\-\d{2}\s+\w{2}\:\w{2}\:\w{2}\,\w{3})\s+(?\w+)\s+(?[^.^\s]+(?:\.[^.\s]+)+)\.(?[^\s]+)\s+(?.+)" ]
}
}
#解析请求时间
date {
match => [ "request_time", "ISO8601" ]
locale => "cn"
target => "request_time"
}
} else {
drop {}
}
}
output {
stdout { codec => rubydebug }
}
7.3.4. 配置 过滤后内容输出至elasticsearch,修改from_beat.conf 文件为以下内容:
input {
beats {
port => 5044
}
}
filter {
#过滤access 日志
if ( [source] =~ "localhost\_access\_log" ) {
grok {
match => {
message => [ "%{COMMONAPACHELOG}" ]
}
}
date {
match => [ "request_time", "ISO8601" ]
locale => "cn"
target => "request_time"
}
#过滤tomcat日志
} else if ( [source] =~ "catalina" ) {
#匹配内容到字段
grok {
match => {
message => [ "(?\[\w+\])\s+(?\d{4}\-\d{2}\-\d{2}\s+\w{2}\:\w{2}\:\w{2}\,\w{3})\s+(?\w+)\s+(?[^.^\s]+(?:\.[^.\s]+)+)\.(?[^\s]+)\s+(?.+)" ]
}
}
#解析请求时间
date {
match => [ "request_time", "ISO8601" ]
locale => "cn"
target => "request_time"
}
} else {
drop {}
}
}
output {
if ( [source] =~ "localhost_access_log" ) {
elasticsearch {
hosts => ["cpy04.dev.xjh.com:9200"]
index => "access_log"
}
} else {
elasticsearch {
hosts => ["cpy04.dev.xjh.com:9200"]
index => "tomcat_log"
}
}
stdout { codec => rubydebug }
}
- kabana安装及配置
Kibana 是一款开源的数据分析和可视化平台,它是 Elastic Stack 成员之一,设计用于和 Elasticsearch 协作。您可以使用 Kibana 对 Elasticsearch 索引中的数据进行搜索、查看、交互操作。您可以很方便的利用图表、表格及地图对数据进行多元化的分析和呈现。
Kibana 可以使大数据通俗易懂。它很简单,基于浏览器的界面便于您快速创建和分享动态数据仪表板来追踪 Elasticsearch 的实时数据变化。
8.1. 修改kibana.yml配置文件
#进入安装路径:
cd /home/es/kibana-6.4.3-linux-x86_64
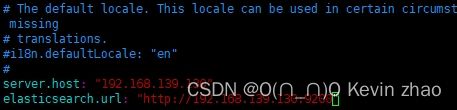
#修改kibana.yml配置文件内容,按shift+g跳转到行末,按i增加以下内容:
vi config/kibana.yml
#kabana服务器IP地址
server.host: "192.168.139.130"
#elasticsearch访问地址
elasticsearch.url: "http://192.168.139.130:9200"
8.2. 启动kabana服务
进入kabana安装目录的bin文件夹下
执行:sh kabana,输出如下表示启动成功

8.3. 验证kabana功能
在windows界面打开网页,输入http://192.168.139.130:5601/

到处安装完成,关于Elasticsearch的调优和日常运维相关请参考其他相关文档。