Python正则表达式中的re模块学习笔记
官方教程 https://docs.python.org/zh-cn/3.9/library/re.html
参考资料:
01-https://www.runoob.com/python/python-reg-expressions.html
02-Python 3.7.1 模块 文本处理 正则表达式
什么叫正则表达式?正则表达式是一个特殊的字符序列,它能帮助我们方便的检查一个字符串是否与某种模式(格式)匹配。
目录
- 01-正则表达式中的的元字符
- 02-Python正则表达式(re模块)的核心函数
- 03-方法re.match(pattern,string)
- 04-Match对象的属性(Attribute)
- 05-Match对象的方法(Method)
-
- 05-01-Match.group([group1, …])
- 04-re模块各方法中的参数flags的取值及意义
01-正则表达式中的的元字符
所谓元字符就是指那些在正则表达式中具有特殊意义的专用字符,如下表所示:

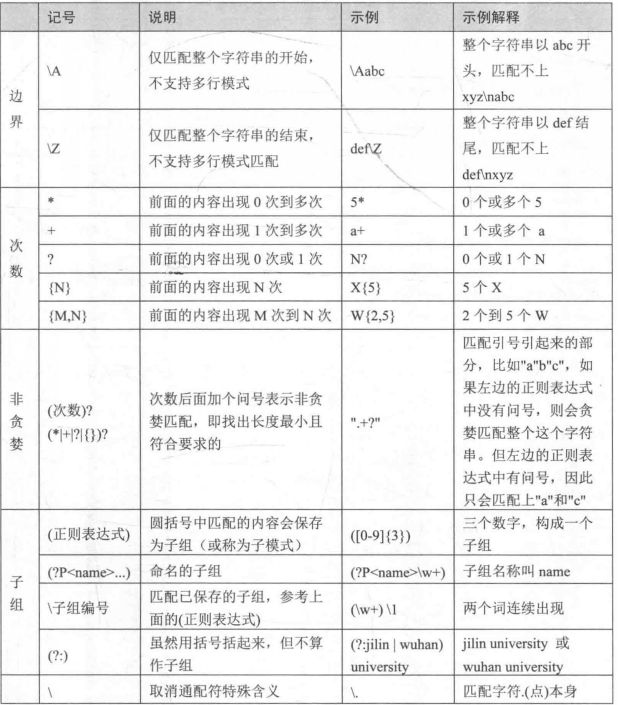
上面表中的内容先大概浏览一遍即可,后面会结合Python的正则表达式操作进行实例使用学习。
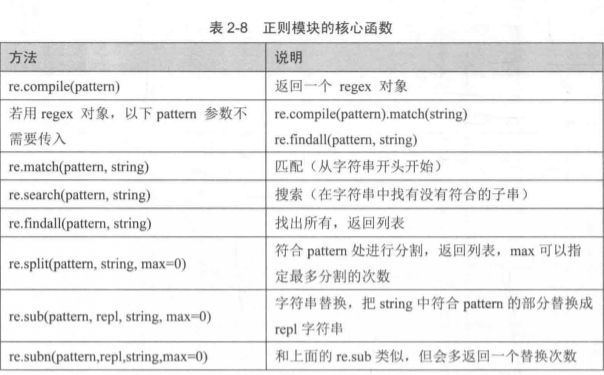
02-Python正则表达式(re模块)的核心函数
03-方法re.match(pattern,string)
re.match() 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match() 就返回 none。
语法如下:
re.match(pattern, string, flags=0)
参数意义如下:
pattern—匹配的正则表达式
string—要匹配的字符串。
flags—标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。其具体可选值见本文第??点。
示例代码如下:
import re
match1 = re.match('blog', 'blog.csdn.net')
match2 = re.match('net', 'blog.csdn.net')
运行结果如下:
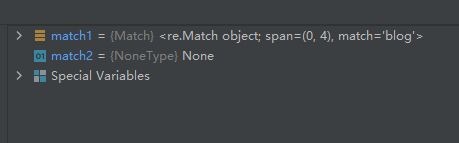
结果分析:
在语句
match1 = re.match('blog', 'blog.csdn.net')
中,看字符串’blog.csdn.net’从开头开始能否匹配模式’blog’。字符串’blog.csdn.net’的前四个字符就匹配到了模式’blog’,所以match1并不为None,而是一个Match对象,其中记录了与匹配相关的信息。关于Match对象的属性和方法见??点。
在语句
match2 = re.match('net', 'blog.csdn.net')
中,看字符串’blog.csdn.net’从开头开始能否匹配模式’net’。字符串’blog.csdn.net’的第一个字符为b,显然和模式’net’不匹配,所以mathc2得到的是None对象。
04-Match对象的属性(Attribute)
我们根据下面这个例子来看Match对象的属性有哪些。
import re
match1 = re.match('blog', 'blog.csdn.net')
我们可以通过观察match1对象来学习Match对象的属性。
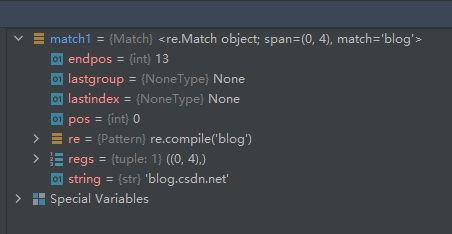
属性endpos—刚好是待匹配字符串的长度,这实际上告诉了re模块在匹配时不能超过这个索引值,即字符的索引应小于这个值。
属性lastgroup—从上面的运行看不出这个值的含义,参考第三方资料,意思为最后匹配的捕获组的名称,如果组没有名称,或者根本没有匹配的组返回None。
属性lastindex—从上面的运行看不出这个值的含义,参考第三方资料,意思为返回最后匹配的组的整数索引,如果根本没有匹配的组,返回None。
属性pos—从待匹配字符串的哪个索引位置开始去匹配。
属性re—这是一个Pattern对象,详见 ??
属性regs—这里面似乎记录了待匹配字符串里是从哪个位置到哪个位置匹配成功的,并且是左闭右开区间
属性string—这里面是待匹配的字符串。
05-Match对象的方法(Method)
05-01-Match.group([group1, …])
功能:返回匹配到的一个或多个子组。
示例代码如下:
match1 = re.match(r"(\w+) (\w+)", "Isaac Newton, physicist")
str1 = match1.group(0)
str2 = match1.group(1)
str3 = match1.group(2)
str4 = match1.group(1, 2)
运行结果如下:

代码分析:
首先看正则表达式语句
r"(\w+) (\w+)"
r是何义?见博文 https://blog.csdn.net/wenhao_ir/article/details/125396412的“09-字符串原始化”。
print(r'i love you \n\r')
print(R'i hate you \n\r')
运行结果如下:
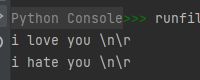
所以我们可以看出,正则表达式中的“\w”等元字符我们希望解释器按本义解释,所以通常我们都要加上r前缀。
正则表达式中的每一个小括号代表一个分组。
\w 表示匹配字母、数字及下划线,和\W反义,\W表示匹配非字母数字及下划线。
这里可以专让写一篇博文介绍正则表达式的元字符。
04-re模块各方法中的参数flags的取值及意义

说明:本篇博文对re模块的记录并不完整,如需完整学习,请参阅其它资料。