Learning Cross-Modal Deep Representations for Robust Pedestrian Detection (学习跨模态深度表示以实现可靠的行人检测)
Learning Cross-Modal Deep Representations for Robust Pedestrian Detection
第一单位:University of Trento 引用量:102 CVPR 2017
code:https://github.com/danxuhk/CMT-CNN
贡献:提出了一种新颖的网络结构,包括 RGB-thermal 映射关系学习的重建网络和多尺度行人检测网络。主要思想是通过无监督方式学习 RGB 和 thermal 的映射关系(针对proposals),进而将重建网络的backbone(VGG-13)作为第二个检测网络的子网B,子网A和子网B共同构成检测网络的 backbone(双管道的VGG-13),检测网络可以通过重建网络使用到 thermal 信息(只使用RGB信息,thermal是重建出来的,进行concatenate,之后共同提取region of interest),完成多尺度行人检测任务。
views:本文的主要贡献在于使用thermal模态帮助RGB模态进行行人检测,但在测试阶段,只使用RGB,降低部署成本,更加实用和方便。网络结构方面感觉没有太多的新颖点,新颖点主要在于思想和以无监督方式学习RGB和thermal的映射关系。还有通过GAN网络学习RGB和thermal的关系,或者通过thermal染色等类似的想法。
但是,直觉上本文这种无监督学习方式的使用略显粗糙(虽然我对无监督的较少),无监督相关领域的发展肯定有着更好的方法,可以集成 end-to-end 网络进行学习,而不并使用两个网络,训练3次(一次是第一个重建网络,一次是除子网B的第二个网络训练,一次是包含子网B的网络fine-tuning),再进行整合。多个步骤的叠加,导致网络的适用性和收敛性难度增加。
ideas:本文总体的思路属于一种模态辅助另一种模态进行学习的范例,有一点点像我的毕设,本文使用ACF检测RGB的bbox,然后对应摘取thermal上的region,进行拟合学习。我毕设是采用双层神经网络直接拟合两种模态的bbox,但是由于相机的视差,导致对应图像中目标的bbox数量和位置有点对不上,我觉得这个问题在KAIST中也会存在(也就是之前那个顶会Improving Multispectral Pedestrian Detection by Addressing Modality Imbalanece Problems 指出的不平衡问题)(KAIST数据集的相位差很小)。
摘要:提出的方法主要包括了两个主要阶段,首先,在multi-modal dataset下,使用DCNN学习rgb和thermal的映射关系,然后,学习到的特征表示转移到second deep network,其中,输入为RGB,输出检测结果。在测试阶段,仅输入RGB。在具有挑战性的KAIST上实现SOTA,与Caltech上的方法同样具有竞争力。
1.Introduction
行人检测技术在挑战性情况下已得到广泛发展,如严重遮挡、小目标、背景杂乱。考虑新颖的传感器(thermal and depth cameras)可为不利照明条件下的行人检测提供新方案,但大多数监控系统仍是传统的RGB sensor。(引出主题,单独RGB在光照变化、阴影、低光照等条件下表现较差)
从cross-modal data中学习深度表示(deep representations)对检测和识别任务非常有益。行人检测的数据集容易收集(社区相机、汽车等方式),但有labeled multi-modal dataset很少。受unsupervised deep learning techniques启发,引入方法学习cross-modal representations且不需要行人边界框。具体来说,学习RGB和theramal的非线性映射来利用多模态信息。通过整合learned representations到second deep network,对RGB进行操作并有效利用多尺度信息进行建模。
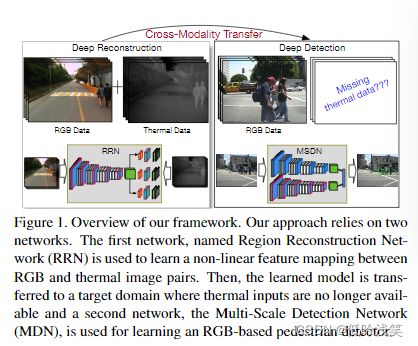

图1是整个方法的概述,图2展示了正例和负例,通过使用提出的方法利用多光谱数据,可以更容易区分彩色图像中的负样本(外观极似行人的柱子、树木)
Contributions:1>新颖的方法,用于学习和传递用于行人检测的cross-modal feature representation。来自thermal的数据被作为从RGB中学习CNN features的一种监督形式。两点优势:a. 测试阶段不需要thermal,部署容易,方便,b.thermal不需要label。 2>第一次专门解决CNN在adverse illumination(不利)条件下的行人检测问题,设计两个新颖网络,无监督交叉模态(cross-modal)特征学习和转移学习的表示形式。 3>验证我们方法在KAIST实验SOTA,并在流行Caltech上有着竞争力。
2.Related Work
Pedestrian Detection:针对速度和精度提出了很多行人检测方法。
Learning Cross-modal Deep Representation:但是,很少研究学习和转移cross-modal feature的问题。方法很多地方同【13】,主要不同是不需要任何注释,可利用大的多光谱数据集。
3.Learning and transferring cross-modal deep representations
3.1 Overview
两个不同的CNN分别用于reconstruction和detection任务。第一个为RRN(region reconstruction network),Fully convolutional network,在从RGB-thermal 图像对中 以无监督方式进行收集的 pedestrian proposal上进行训练,学习从RGB channel到thermal channel 的映射。第二个网络为MSDN(Multi-Scale Detection Network),只有RGB数据,并嵌入从RRN转移的参数实施行人检测。输入为RGB+大量pedestrian proposal,输出为带有置信度分数的bbox。
3.2 Region Reconstruction Network
本文中,使用预训练的行人检测器(如:ACF)生成大量RGB数据的proposals(包括true positives 和 false positives),并设计一个deep modal重建相关thermal information。RRN的目的是从相关的RGB图中重建thermal data。
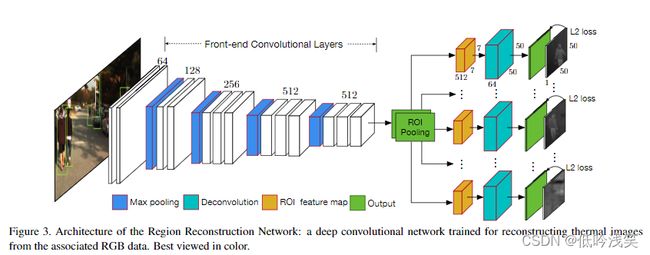
提出的RRN如图3所示,输入是3-channel RGB和大量相关的行人proposals(其实就是其它检测算法的结果图),RRN包括front-end convolutional subnetwork 和 back-end reconstruction subnetwork。其中,front-end network为VGG-13,后接ROI Pooling(摘取proposals),每个ROI生成512x7x7的特征图,考虑到特征图太小,使用deconvolutional layer恢复分辨率尺寸到50x50x64,减少到64 channels确保在训练中平滑收敛。反卷积层后跟Relu,然后,使用卷积层(kernel size:3,pad 1)生成相关于每个proposal的reconstruction maps。损失为平方损失。
不同于Fast/Faster R-CNN,在训练中使用动态的mini-batch size(不懂,但这个好像不重要的样子)。
3.3 Multi-Scale Detection Network
MSDN利用从RRN中学习的cross-modal representations在RGB中执行行人检测任务。引入了一种检测网络,融合了从ROI池层获得的多个特征图。

MSDN分为子网A和子网B,子网A13层,5block,Cm,n表示 m-th block 和 n个卷积层,5个block卷积层后跟着max pooling,每个卷积层后跟relu。ROI(Region of Interest)pooling layer 应用于最后的两个卷积块(convolutional block),为行人proposal提取512x7x7的特征图。考虑两个block是速度和精度的最佳折衷。sub-B同sub-A的结构,但它的目的是迁移cross-modality mid-level representations,它的13个卷积层参数(c'1,2 to c'5,3)来自于RRN。确实RRN的卷积产生了紧凑的特征表示形式(捕获了RGB和thermal的复杂关系(映射关系)),因此,将sub-B(RRN的13层卷积)嵌入,实现知识转移。(无奈了,就是这样进行跨模态信息的转移,我以为是什么高级的方式使用先前学习的特征表示)
将两个子网的RoI池化层中获得的特征图进行concatenate,另一个1024 channels的卷积层被使用。RoI feature maps尺寸调小,设卷积层为1(1x1卷积,改变channels)。之后是两个FC层(4096)。最后,使用两个同级层,一层输出softmax类别和置信度,一层为行人定位提供bbox offset。
3.4 Optimization
两个网络,两个培训过程。
第一阶段,RRN在multispectral data上训练。使用在ImageNet上预训练的VGG-16的前13层卷积初始化front-end convolutional layers。其余参数随机初始化,使用SGD学习。
第二阶段,在目标域中使用RGB数据和行人bbox优化MSDN参数,首先训练sub-net A通过添加MSDN的公共部分(从功能串联层到输出的两个同级别),串联和随后卷积层中的特征图大小分别为1024x7x7和512x7x7。子网A同样用预训练的VGG-16初始化,子网B卷积层使用RRN的相应参数进行初始化,然后,使用目标域的RGB执行fine-tuning,整个MSDN优化基于SGD
3.5 Pedestrian detection
在检测阶段,给定测试RGB图像。首先,类似于training阶段,提取region proposal,然后,将输入图像和proposals输入MSDN。 softmax层输出类别得分,边界框回归器估计图像坐标。为了减少proposl的重复性,根据每个propsoal的预测得分进行非最大抑制(NMS,non-maximum suppression),并设置联合交集(IoU)阈值δ(区分正负样本)。
4.experiments

5.Conclusion
提出新颖的方法,多尺度,整合在RGB-thermal图像对上预训练的子网学习cross-modal feature representations。在不利照明条件下,实现多光谱数据知识转移,并实现准确的检测。在KAIST和Caltech上实现SOTA性能。
这种cross-modal思想在其他应用中可能有着较大的作用。