Apache Doris 为分析而生:Doris 架构
开篇:Apache Doris —— 为分析而生
从诞生之日起,Doris的每一步都是为了解决切实的业务痛点,每一次转变都是在面对不同的业务挑战。一路上,Doris砥砺前行,凝结了众多前辈的心血。Apache Doris是一个现代化的MPP分析性数据库产品。仅需要亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。Doris可以满足多种数据分析需求。相信未来,Doris还会有更多的新鲜血液加入。
所以现在我们一起来学习Doris,今天分享开篇:Doris 架构。
底层架构
Doris =
Google Mesa(数据模型)
+
Apache Impala(MPP Query Engine)
+
Apache ORCFile (存储格式,编码和压缩)
Google Mesa(数据模型)
Mesa满足一系列复杂且具有挑战性的用户和系统需求,包括接近实时的数据提取和查询能力,以及针对大数据和查询量的高可用性,可靠性,容错性和可伸缩性。但是Mesa本身不提供SQL查询引擎所以借鉴了下面。
Apache Impala(MPP Query Engine)
Impala是一个非常好的MPP SQL查询引擎,做更多的查询优化,在速度上做到了很好。但是缺少比较完美的分布式存储引擎,所以需要集成下面。
Apache ORCFile (存储格式,编码和压缩)
只访问查询涉及的列,能大量降低系统I/O;列数据相对来说比较类似,压缩比更高;每一列由一个线索来处理,更有利于查询的并发处理。
系统架构
Doris的系统架构组成主要有:
BackEnd(后端节点),简称BE。
FrontEnd(前端节点),简称FE。
bdbje(BerkekeyDB Java Edition),负责元数据操作日志的持久化、FE 高可用等功能。
架构图
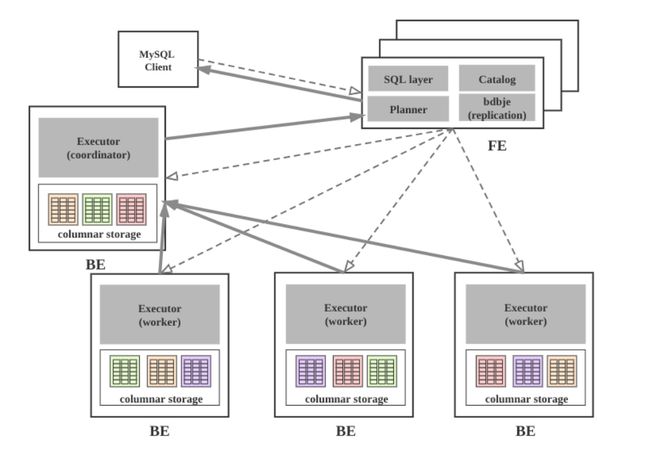
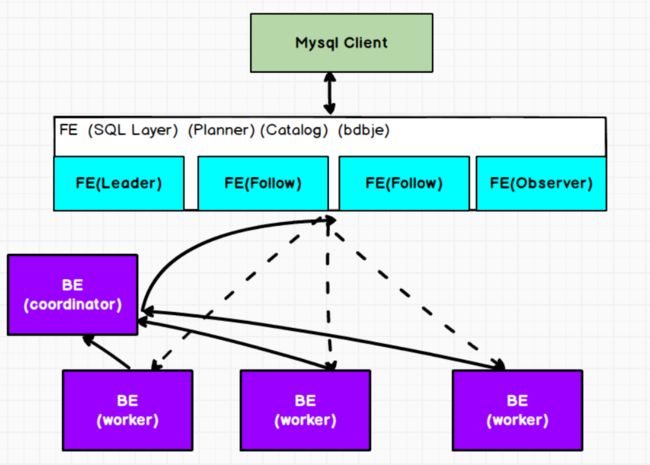
组件作用与功能
Mysql client充当什么角色
可以使用MySQL客户端访问Doris集群。即FE接收MySQL客户端的连接, 解析并执行SQL语句。
FE
主要负责查询的编译,分发和元数据管理。
(1)管理元数据(库, 表, 分区, tablet副本等信息), 执行SQL语句命令。
(2)FE高可用部署, 使用复制协议选主和主从同步元数据, 所有的元数据修改操作, 由FE Leader节点完成, FE Follower节点可执行读操作。 元数据的读写满足顺序一致性。 FE的节点数目采用2n+1, 可容忍n个节点故障。当FE Leader故障时, 从现有的Follower节点重新选主, 完成故障切换。
Observer节点仅从 Leader节点进行元数据同步,不参与选举。能够横向扩展以提供元数据的读服务的扩展性。
(3)FE的SQL layer对用户提交的SQL进行解析, 分析, 语义分析和关系代数优化, 生产逻辑执行计划。
(4)FE的Planner负责把逻辑计划转化为可分布式执行的物理计划, 分发给一组BE。
(5)FE监督,管理BE的上下线, 根据BE的健康状态和存活数, 维持tablet副本的数量。
(6)FE协调数据导入, 保证数据导入的一致性。
BE
主要负责数据的存储、以及查询计划的执行
(1)BE管理tablet副本, tablet是table经过分区分桶形成的子表, 采用列式存储。
(2)BE受驱动FE, 创建或删除子表。
(3)BE接收FE分发的物理执行计划并指定BE coordinator节点, 在BE coordinator的调度下, 与其他BE worker共同协作完成执行。
(4)BE读取本地的列存储引擎获取数据,并通过索引和谓词下沉快速过滤数据。
(5)BE后台执行compact任务, 减少查询时的读放大。
(6)数据导入时, 由FE指定BE coordinator,将数据以fanout的形式写入到tablet多副本所在的BE上。
参考
Doris 简史 - 为分析而生的 11 年
DorisDB企业版文档