【SDG精读与代码复现】More Control for Free Image Synthesis with Semantic Diffusion Guidance【SDG】
【SDG精读与代码复现】More Control for Free! Image Synthesis with Semantic Diffusion Guidance【SDG】
- 一、前言
- 二、论文介绍
-
- 1、文章主旨思想背景介绍
- 2、方法
- 3、实验
- 三、复现模块:
-
- 1、复现指引
- 2、复现结果
- 总结:
- 四、Reference:
- 五、bug解决模块
-
- 遇到的bug1
- 遇到的bug2
- 遇到的bug3
- 遇到的bug4
- 六、评价指标
一、前言
论文地址:Liu_More_Control_for_Free_Image_Synthesis_With_Semantic_Diffusion_Guidance_WACV_2023_paper
代码地址:https://github.com/xh-liu/SDG_code
文章核心思想:多模态的引导扩散模型进行采样。直接用训练好的非条件的扩散模型,无需重复训练。文字guided是用一个微调的CLIP模型,数据集无需文本注释。数据集是FFHQ和LSUN在这篇文章介绍了。
本文主要分为三个模块:
第一个是论文介绍模块,以更通俗易懂的方式帮助大家理解论文。
第二个是复现模块,代码的复现引导。
第三个是复现过程的代码解决方案模块,复现过程遇到有bug的可以看看。
后续写代码的分析模块,感兴趣的可以收藏一下此文章,后续放上链接。
二、论文介绍
效果:
1、文章主旨思想背景介绍
文章基于DDPM,IDDPM,DDIM和classifier guided diffusion model以及score-base model。
好在大部分的知识都是来自:classifier guided diffusion model
ideal:
- 然而,以往的文本-图像合成方法大多需要图像-文本对进行训练,不能推广到没有文本注释的数据集。 我们的文本引导合成方法可以应用于没有相关文本注释的数据集。 例如DALL-E,GLIDE需要成对的图像-文本注释,这将应用限制在特定的数据集上,或者需要大量的数据和计算资源进行训练。 我们提出的框架能够在给出详细文本提示的情况下在多个域上生成图像,既不需要来自这些域的图像-文本配对数据,也不需要大量计算来训练文本引导的图像合成模型。
- 多模态的guidance
- 当前的图像调节合成技术要么仅将参考图像的“风格”转移到目标图像[21,3],要么被限制在具有明确定义的结构的域,例如人类或动物面部[21,53]。它们不能基于单个参考图像生成具有各种姿势、结构和布局的多样图像。
- 我们的方法显示了更好的可控性,因为提出了不同类型的
图像引导,用户可以通过使用不同types和scales的引导来决定保留多少语义(semantic)、结构(structural)或风格(style)信息,而不需要重新训练无条件扩散模型。
文本guidance:
具体地说,我们的语言指导是基于Clip[41]对噪声图像进行精细处理所预测的图像-文本匹配分数。
我们提出了一种无文本注释的自监督算法来优化CLIP图像编码器,从而以最小的代价获得引导模型。图像guidance
至于图像指导,根据我们在图像中寻找的信息,我们定义了两个选项:内容和风格指导。
图像和文本可以单独进行guidance或者一起。
- Clip[41]是一个在大规模图像和文本上训练的强大的视觉-语言联合嵌入模型。 它的表示已经被证明是鲁棒和通用的,足以在不同的数据集上执行零镜头分类和各种视觉语言任务。 StyleClip[39]和StyleGan-Nada[12]已经证明,Clip能够实现文本引导的图像处理和图像生成的域自适应,而无需特定域的图像-文本对。
算法:


2、方法
- Language Guidance
具体来说,给定图像X和文本提示L,该模型分别使用图像编码器EI和文本编码器EL将它们嵌入到联合嵌入空间中。 将嵌入EI(x)和EL(l)之间的相似度作为余弦距离计算出来,并利用余弦距离构造语言引导函数。
其中图像编码器EI需要将时间步长t并入作为输入,并且还需要在不同时间步长处对噪声图像进行进一步训练。然后将有时间步t输入的图像编码器记为: E I ′ ( x t , t ) E^\prime_I(x_t,t) EI′(xt,t)
==最后,语言指导功能可以定义为: ==
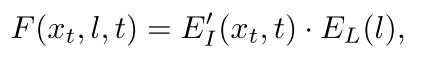
- Image Guidance
分为Image Content Guidance和Image Style Guidance
其中:
Image Content Guidance【例如姿势,角度和布局,结构属性】
图像内容引导旨在基于参考来控制所生成图像的内容(具有或不具有结构约束),并且被公式化为图像特征嵌入的余弦相似度。令x′ 0表示无噪声参考图像。我们根据等式2扰动x′ 0以得到x′ t。然后,在时间步长t处的引导信号是:(公式2是扩散过程的前行公式)
使用图像编码器进行引导的一个有趣的特性是,可以控制从参考图像中保持多少结构信息,例如姿态和视点。例如,上述等式中使用的嵌入不具有空间维度,导致样本在姿态和布局上具有很大变化。
然而,通过利用空间特征图并强制对应空间位置中的特征之间的对准,我们可以引导所生成的图像额外地与参考图像共享类似结构,如下所述:
其中E′ I()j ∈ RCj×Hj×Wj表示图像编码器E′ I的第j层的空间特征图。
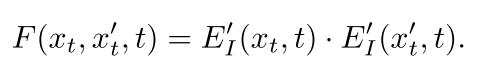

Image Style Guidance【风格】
图像风格引导允许从参考图像进行风格转移。其被类似地公式化,除了中间特征图的格拉姆矩阵之间的对齐被强制执行:
其中,G′ I()j是图像编码器E′ I的第j层特征图的格拉姆矩阵[22]。
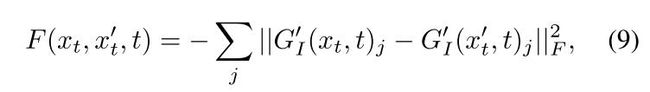
- Multimodel Guidance
就是上面两个等式的一个加权求和,用到了缩放因子s。公式如下:
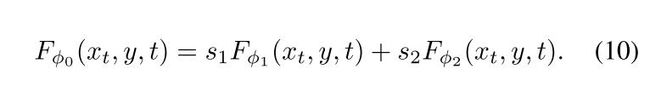
通过调整每个模态的加权因子,用户可以在语言和图像引导之间取得平衡。
4.无文本注释的CLIP自监督微调
CLIP [41]是一个强大的视觉和语言模型,在大规模图像-文本数据上训练。我们利用其语义知识,实现可控的扩散模型的合成。为了充当指导功能,期望CLIP在任何时间步长t处理噪声图像xt。我们对CLIP图像编码器EI进行较小的架构改变,以通过将批归一化层转换为自适应批归一化层来接受附加输入t,其中尺度和偏置项的预测以t为条件。我们将该修改的CLIP图像编码器表示为fEI。fEI的参数由预训练的CLIP模型EI的参数初始化,除了用于自适应批量归一化层的参数之外。
为了微调fEI,我们提出了一种自我监督的方法,在该方法中,我们强制从干净和噪声图像中提取的特征之间的对齐。形式上,给定一批N对干净和有噪声的图像 { x 0 i , x t i i } i = 1 N \left \{{x^i_0,x^i_{t_i}}\right \} ^N_{i=1} {x0i,xtii}i=1N,其中ti是针对控制噪声量的第i个图像采样的时间步长,我们分别用EI和fEI对x10和x1 ti进行编码。我们依靠CLIP的对比目标==(contrastive objective),以最大限度地提高余弦相似性的N个积极的对,同时最大限度地减少剩余的负对的相似性。我们确定EI的参数,并使用对比目标(contrastive objective)==来微调fEI的参数。
通过我们的微调CLIP模型,扩散模型可以由用户提供的图像或语言信息指导。此外,CLIP模型以自我监督的方式进行微调,而不需要目标数据集的任何语言数据。
3、实验
数据集是FFHQ和LSUN在这篇文章介绍了。
有趣的是这些基本都是利用openai/guided-diffusion训练好的模型。其模型在下面有讲到。
参数设置:
我们使用[10,8]中的无条件DDPM,并对每个数据集的噪声图像使用微调CLIP [41] RestNet 50×16模型,初始学习率为10−4,权重衰减为 1 0 − 3 10^{−3} 10−3,批量为256。当用我们的SDG合成图像时,缩放因子是一个超参数,我们可以针对每个引导手动调整,这将在第4.3.节中讨论。默认缩放因子对于图像引导为100,对于语言引导为120。
- 定量评价
评价设置:
由于我们的SDG是第一种将文本指导和图像指导统一起来进行图像合成的方法,因此以前没有关于图像和语言指导的图像合成的工作。因此,我们分别对语言引导的图像合成和图像引导的图像合成进行了评价,以便与以前的工作进行比较.我们评估了FFHQ数据集上的语言引导生成。为此,我们根据CelebAAttributes [32]中的性别和面部属性的组合定义了400条文本指令。例如,“一张戴眼镜的微笑男子的照片”。我们为每个文本查询生成25个图像,总共生成10,000个图像。我们将我们的语言引导生成与StyleGAN+CLIP进行比较,后者使用CLIP [41]损失来优化StyleGAN [24]的随机初始化潜在代码,以用于文本引导图像合成。StyleGAN+CLIP删除了StyleCLIP [24]的GAN反转模块,因此它可以应用于基于语言的图像合成。由于我们的模型不需要文本注释进行训练,因此我们的文本引导图像合成实验在没有配对文本注释的仅图像数据集上进行。因此,我们的方法不能直接与其他基于文本的图像合成方法进行比较,这些方法必须在文本图像配对数据集上进行训练。
评价图像引导图像合成:
我们从每个数据集中随机选择10,000幅图像作为引导,并基于引导图像合成新图像。我们将我们的图像引导结果与ILVR [8]进行比较。
结果:

可见提升还是比较大的。
评价指标放最后介绍,感兴趣的可以翻下去。
2. 消融研究
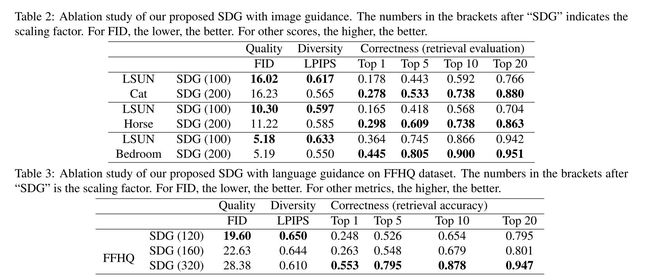
如3.1节和算法1所示,比例因子S是一个用户可控的超参数,它控制制导的强度。 我们在表2和表3中探索缩放因子的影响。 附录中显示了不同缩放因子的效果的可视化示例。 我们观察生成图像的语义正确性和多样性之间的权衡。 随着缩放因子的增大,引导信号对生成结果有更多的控制,与引导的语义一致性增加。 而较大的比例因子也会导致生成图像的多样性较低。 用户可以调整缩放因子来控制他们期望生成的图像的多样性。
3. 定性结果
文本引导和图像引导合成结果 :
我们的模型将语言和图像引导结合在一个统一的框架中,易于适应各种应用。 在图3中,我们展示了带有图像内容指导的合成结果(公式7)。 通过图像导引扩散,该模型能够合成具有不同结构的新图像,并与导引图像的语义相匹配。

图4显示了语言引导的扩散区域,其中我们的模型能够处理复杂而精细的描述,例如“一个微笑的棕色卷发和口红的女人”,或者“一个有木质壁橱和墙上画的卧室”。

我们还可以将语言和图像引导联合起来,如图5所示。 图像和语言指导提供了互补的信息,我们的语义扩散指导能够生成与两者一致的图像。 例如,我们可以生成一个类似于指导卧室图像但带有窗户的卧室,或者根据指导图像生成一个女人,但带有定义语言指导的新属性(例如,“微笑”或“短发”或“太阳镜”)。

与先前工作的比较 :
由于之前还没有将文本和图像引导结合在同一统一框架中的工作,我们将我们的方法与以前的文本引导和图像引导合成工作进行了比较。 在图像引导合成中,与我们的工作最相关的是ILVR[8]。如图所示 6(a),我们的模型可以生成不同姿态和结构的图像,而ILVR只能生成相同姿态和结构的图像。 我们将我们的语言引导图像合成与图的StyleGan+Clip进行了比较 6(b). 虽然StyleGan+Clip能够生成高质量的图像,但其结果缺乏多样性,而我们的模型能够基于语言指令生成高质量和多样性的结果。

其他应用 :
在图 7(a,b),我们证明了风格(方程9)和结构保持(方程8)图像制导的结果。 有了风格指导,在LSUN卧室训练的模特能够以看不见的风格合成卧室。 通过保留结构的内容指导,合成的图像保留了参考图像的结构、姿态和布局。 图 7©表明,该模型能够以域外图像作为引导,合成出与引导卡通图像语义相似的真实感图像。

三、复现模块:
1、复现指引
- 在这里面https://github.com/xh-liu/SDG_code下载好代码。
- 安装环境:
git clone https://github.com/xh-liu/SDG_code
cd SDG
pip install -r requirements.txt
pip install -e .
requirements.txt其中的:
pip install git+https://github.com/openai/CLIP.git
可能需要魔法。
3. 下载预训练模型到models/
其中models文件夹是需要新建的。一般下载两个,我是下载了ffhq_baseline.pt和clip_ffhq.pt。
DDPM的预训练模型是来自https://github.com/openai/guided-diffusion和https://github.com/jychoi118/ilvr_adm也就是说拿来用即可,不需要自己训练。
为了语义引导,作者微调了CLIP在噪声图像的图片编码器。
4.最后是用语义扩散指导进行采样
要从这些模型中采样,您可以使用脚本/sample.py。
对于Lsun Cat,Lsun马和Lsun卧室,模型旗被定义为:
MODEL_FLAGS="--attention_resolutions 32,16,8 --class_cond False --diffusion_steps 1000 --dropout 0.1 --image_size 256 --learn_sigma True --noise_schedule linear --num_channels 256 --num_head_channels 64 --num_res_blocks 2 --resblock_updown True --use_fp16 False --use_scale_shift_norm True --model_path models/lsun_bedroom.pt"
对于FFHQ数据集,模型标志定义为:
MODEL_FLAGS="--attention_resolutions 16 --class_cond False --diffusion_steps 1000 --dropout 0.0 --image_size 256 --learn_sigma True --noise_schedule linear --num_channels 128 --num_head_channels 64 --num_res_blocks 1 --resblock_updown True --use_fp16 False --use_scale_shift_norm True --model_path models/ffhq_10m.pt"
采样标志:
SAMPLE_FLAGS="--batch_size 8 --timestep_respacing 100"
使用图像内容(语义)进行采样指南:
GUIDANCE_FLAGS="--data_dir ref/ref_bedroom --text_weight 0 --image_weight 100 --image_loss semantic --clip_path models/CLIP_bedroom.pt"
CUDA_VISIBLE_DEVICES=0 python -u scripts/sample.py --exp_name bedroom_image_guidance --single_gpu $MODEL_FLAGS $SAMPLE_FLAGS $GUIDANCE_FLAGS
使用图像样式指导进行抽样:
GUIDANCE_FLAGS="--data_dir ref/ref_bedroom --text_weight 0 --image_weight 100 --image_loss style --clip_path models/CLIP_bedroom.pt"
CUDA_VISIBLE_DEVICES=0 python -u scripts/sample.py --exp_name bedroom_image_style_guidance --single_gpu $MODEL_FLAGS $SAMPLE_FLAGS $GUIDANCE_FLAGS
使用语言和图像指导进行抽样:
GUIDANCE_FLAGS="--data_dir ref/ref_bedroom --text_weight 160 --image_weight 100 --image_loss semantic --text_instruction_file ref/bedroom_instructions.txt --clip_path models/CLIP_bedroom.pt"
CUDA_VISIBLE_DEVICES=0 python -u scripts/sample.py --exp_name bedroom_image_language_guidance --single_gpu $MODEL_FLAGS $SAMPLE_FLAGS $GUIDANCE_FLAGS
附上我的脚本,我用的预训练的model在上面说了。
其中MODEL_FLAGS是我们用的扩散模型的预训练模型,一般确定了就不需要改。
SAMPLE_FLAGS也同样如此,
一般需要改的是GUIDANCE_FLAGS的–text_instruction_file ref/gold.txt即指导的文字,还有–exp_name ffhqhat(即输出文件夹的名字)您可能需要调整 text_weight 和 image_weight 以获得更好的生成样本的视觉质量。
MODEL_FLAGS="--attention_resolutions 16 --class_cond False --diffusion_steps 1000 --dropout 0.0 --image_size 256 --learn_sigma True --noise_schedule linear --num_channels 128 --num_head_channels 64 --num_res_blocks 1 --resblock_updown True --use_fp16 False --use_scale_shift_norm True --model_path models/ffhq_baseline.pt"
SAMPLE_FLAGS="--batch_size 8 --timestep_respacing 100"
# GUIDANCE_FLAGS="--data_dir ref/ref_ffhq --text_weight 160 --image_weight 100 --image_loss semantic --text_instruction_file ref/ffhq.txt --clip_path models/clip_ffhq.pt"
# CUDA_VISIBLE_DEVICES=0 python -u scripts/sample.py --exp_name ffhq_image_language_guidance --single_gpu $MODEL_FLAGS $SAMPLE_FLAGS $GUIDANCE_FLAGS
# GUIDANCE_FLAGS="--data_dir ref/ref_ffhq --text_weight 160 --image_weight 0 --text_instruction_file ref/lanffhq.txt --clip_path models/clip_ffhq.pt"
# CUDA_VISIBLE_DEVICES=0 python -u scripts/sample.py --exp_name ffhqridehorse --single_gpu $MODEL_FLAGS $SAMPLE_FLAGS $GUIDANCE_FLAGS
# GUIDANCE_FLAGS="--data_dir ref/ref_ffhq --text_weight 160 --image_weight 0 --text_instruction_file ref/sunglass.txt --clip_path models/clip_ffhq.pt"
# CUDA_VISIBLE_DEVICES=0 python -u scripts/sample.py --exp_name ffhqsunglass --single_gpu $MODEL_FLAGS $SAMPLE_FLAGS $GUIDANCE_FLAGS
GUIDANCE_FLAGS="--data_dir ref/ref_ffhq --text_weight 160 --image_weight 0 --text_instruction_file ref/gold.txt --clip_path models/clip_ffhq.pt"
CUDA_VISIBLE_DEVICES=0 python -u scripts/sample.py --exp_name ffhqhat --single_gpu $MODEL_FLAGS $SAMPLE_FLAGS $GUIDANCE_FLAGS
2、复现结果
我这里只试验了ffhq的文字和图像guidance的效果。用到的模型是:ffhq_baseline.pt和clip_ffhq.pt。
为了更好的展示,我将图片裁剪为128x128,并且只展示3张效果图。(大家快去试试吧!)
-
文字guidance:A photo of a woman with curly hair
图片guidance:
效果:


-
文字guidance:A photo of a woman with a big gold chain
效果:


-
文字guidance:A photo of a woman wearing a hat
效果:


-
文字guidance:A photo of a woman riding a horse
效果:


-
文字guidance:A photo of a woman wearing a sunglass
效果:


总结:
局限性:
- 显然ffhq的文字guidance仅限于头发,眼镜,帽子,表情等。如果加上其他一些难的词语生成效果就不好,例如骑马…
- 生成效果在多样性和准确性之间进行了一个trade-off
优点:
- 多模态的guidance
- 文字guidance无需图片-文本配对的数据集
- 直接使用DDPM的训练模型,只是在采样阶段进行guidance
目前只想到这么多,有错误恳请批评斧正,后续会补充修改,欢迎收藏评论!
四、Reference:
https://github.com/xh-liu/SDG_code/blob/main/scripts/sample.py
https://arxiv.org/abs/2112.05744
五、bug解决模块
遇到的bug1
Traceback (most recent call last):
File "/mnt/SSD_1T/zhouzikang/project/SDG/scripts/sample.py", line 5, in <module>
import blobfile as bf
ModuleNotFoundError: No module named 'blobfile'
解决方案:
pip install blobfile
遇到的bug2
Traceback (most recent call last):
File "/mnt/SSD_1T/zhouzikang/project/SDG/scripts/sample.py", line 12, in <module>
from sdg.parser import create_argparser
ModuleNotFoundError: No module named 'sdg'
解决方案:在scripts/sample.py中加入:
其中是你项目的绝对地址,即sdg的上级目录。
import sys
sys.path.append('/mnt/SSD_1T/-----/project/SDG/')
查看绝对地址的命令:
pwd -P
遇到的bug3
Traceback (most recent call last):
File "/mnt/SSD_1T/zhouzikang/project/SDG/scripts/sample.py", line 31, in <module>
from tools.get_text import get_ffhq_text
ModuleNotFoundError: No module named 'tools'
解决方案:
pip install tools
遇到的bug4
Traceback (most recent call last):
Traceback (most recent call last):
File "/mnt/SSD_1T/zhouzikang/project/SDG/scripts/sample.py", line 31, in <module>
from tools.get_text import get_ffhq_text
ModuleNotFoundError: No module named 'tools.get_text'
解决方案:
提交Issues,然后作者直接删掉了这一行代码…
from tools.get_text import get_ffhq_text

也就是说这个问题修复了以后的同学应该不会遇到了。
六、评价指标
有三个:
- 用于图像质量评价的FID。
我们报告了对每个数据集的10,000张图像计算的FID评分[18],以评估生成图像的质量。较低的FID指示较好的生成质量。我们的SDG在图像引导合成和语言引导合成方面都优于同类方法。
- 用于多样性评估的LPIPS。
如表1所示,我们计算了从相同图像引导或相同文本引导生成的配对图像之间的LPIPS评分[58]。较高的LPIPS指示更多的多样性。与以前的工作ILVR [8]和StyleGAN+CLIP相比,我们的模型生成了
更多样化的图像。ILVR生成的图像遵循相同的结构和布局,但在细节上有所变化。虽然我们的方法能够生成具有不同姿势、结构和布局的各种图像,如图6(a)所示。由StyleGAN+CLIP生成的图像也遭受低多样性,如图6(b)所示。StyleGAN+CLIP的高FID分数也是因为生成的图像多样性低。
3.检索准确性,以评价与指南的一致性。Retrieval accuracy to evaluate consistency with guid-
ance.
我们使用文本到图像检索或通过原始CLIP ResNet50×16模型进行图像检索,而不进行精细调整来评估生成的图像与指导的匹配程度。 对于一幅文本引导生成的图像,我们从训练集中随机选取99幅真实图像作为负向图像,并对文本到图像的检索性能进行评价。
类似地,对于与参考图像合成的图像,我们使用参考图像从随机选择的99幅真实图像中检索生成的图像1。 StyleGan+Clip具有非常高的检索性能,因为StyleGan模型的潜在代码被直接优化,以使用于检索的Clip模型计算的Clip得分最小化。 因此,StyleGan+Clip的高检索性能是以低生成多样性为代价的,高FID和低LPIPS得分表明了这一点。
至此结束,感谢阅读^ - ^!
如果觉得有帮助的话,希望点赞收藏评论加关注支持一下吧。
你的支持是我创作的最大动力!!!
所选择的负片图像与我们用于合成图像的指导图像是不相交的。 ↩︎