python-匿名函数、内置函数及递归
匿名函数和内置函数
- 函数高阶
-
- 匿名函数
-
- 用lambda定义函数的特点
- lambad函数用法
- lambda表达式的应用
- 内置函数
-
- map函数(映射)
- reduce函数(累积)
- filter函数(过滤)
- zip函数(打包)
- 递归
-
- Python递归深度
- 设置递归深度
- 递归应用---栈(先进后出)
复习可迭代对象、迭代器、生成器概念及其联系
函数高阶
匿名函数
匿名函数又称为lambda表达式。
匿名函数写法:lambda 参数1,参数2… : 返回值
def f(x):
return x +1
g = lambda x :x+1
print(f(1)) #2
print(g(1)) #2 #这两个是等价的
用lambda定义函数的特点
- 不需要定义函数名
- 传的参数和返回值离的很近,非常便于代码阅读
- lambda简化函数的书写形式,适用于短小的函数,在实际的代码中除了可以简化代码没有其他作用。
lambad函数用法
- 直接赋给一个变量,然后再像一般函数那样调用
c=lambda x,y,z:x*y*z
c(2,3,4)
24
当然,也可以在函数后面直接传递实参
(lambda x:x**2)(3)
9
-
将lambda函数作为参数传递给其他函数,比如说结合map、filter、sorted、reduce等一些Python内置函数使用
1)与filter函数搭配使用
filter(lambda x:x%3==0,[1,2,3,4,5,6])
[3,6]
2)与map函数搭配使用
squares = map(lambda x:x**2,range(5))
print("map&lambda", list(squares))
[0,1,4,9,16]
3)与sorted函数结合使用
比如:创建由元组构成的列表:
a = [('b', 3), ('a', 2), ('d', 4), ('c', 1)]
# 按照第一个元素排序
print("sorted&lambda", sorted(a, key=lambda x: x[0]))
[('a',2),('b',3),('c',1),('d',4)]
# 按照第二个元素排序
sorted(a,key=lambda x:x[1])
[('c',1),('a',2),('b',3),('d',4)]
4.与reduce函数结合使用
from functools import reduce
print("reduce&lambda", reduce(lambda a, b: '{},{}'.format(a, b), [1, 2, 3, 4, 5, 6, 7, 8, 9]))
1,2,3,4,5,6,7,8,9
- 嵌套使用将lambda函数嵌套到普通函数中,lambda函数本身做为return的值
def increment(n):
return lambda x:x+n
f=increment(4)
print(f(2)) # 结果是6
- 字符串联合,有默认值,也可以用x=(lambda…)这种格式
x = (lambda x='Boo', y='Too', z='Z00': x + y + z)
print(x('Foo')) # FooTooZ00
- 在tkinter中定义内联的callback函数
import sys
from tkinter import Button,mainloop
x=Button(text='Press me',command=(lambda :sys.stdout.write('Hello,World\n')))
x.pack()
x.mainloop()
- 判断字符串是否以某个字母开头有
Names = ['Anne', 'Amy', 'Bob', 'David', 'Carrie', 'Barbara', 'Zach']
B_Name= filter(lambda x: x.startswith('B'),Names)
for item in B_Name:
print(item)
['Bob', 'Barbara']
- 求两个列表元素的和
a = [1, 2, 3, 4]
b = [5, 6, 7, 8]
print(list(map(lambda x, y: x + y, a, b)))
[6,8,10,12]
- 求字符串每个单词的长度
sentence = "Welcome To Beijing!"
words = sentence.split()
lengths = map(lambda x: len(x), words)
print(list(lengths))
[7,2,8]
lambda表达式的应用
1.3.1 lambda表达式表示
def sort_test():
students = [
{'name': '张三', 'age': 22},
{'name': '李四', 'age': 26},
{'name': '王五', 'age': 19},
{'name': '小六', 'age': 21}
]
# sorted排序默认是升序,即reverse默认为False,reverse=False默认是缺省的
print(sorted(students, key=lambda stu: stu['age'], reverse=False))
if __name__ == '__main__':
sort_test() # 执行后按照年龄升序;如果要按照年龄降序则将reverse改为True
内置函数
map函数(映射)

map函数语法:map(函数名,可迭代对象)
会根据提供的函数对指定序列做映射。map(func,*iterables)–>映射对象,创建一个迭代器,该迭代器使用每一个Iterable。当最短的iterable用完时停止。
map函数第一个参数 是一个函数名(函数实现的功能是可迭代对象)。如果函数的实现比较简单的时候,可以用没有名字的函数——lambda表达式(匿名函数)
map函数第一个参数为函数名
示例1:把两个列表的值一一对应生成可迭代对象中是两个字典
def f(key, value):
# 此方法可以直接用匿名函数去实现
return {key: value}
def map_test(keys: list, values: list) -> Iterator:
# 返回的是一个可迭代对象
return map(f, keys, values)
# 匿名函数实现方法
#return map(lambda key,value:{key: value}, keys, values)
map_test(['a', 'b', 'c'], [1, 2, 3]) # [{'a':1},{'b':2},{'c':3}]
示例2: 把三个列表中的各个元素分别相加,把计算结果放到新的列表中
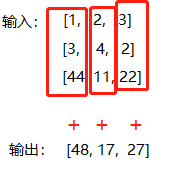
def f2(x, y, z):
return x + y + z
print(list(map(f2, [1, 2, 3], [3, 4, 2], [44, 11, 22])))
- map函数的结果是一个可迭代对象,可以使用list转换成列表打印也可以使用for遍历打印
- map函数中不管是使用lambda还是使用函数形式,map函数传参的格式都是map(lambda表达式/函数名,可迭代对象参数名(参数名可以是多个,但是要和lambda表达式和函数名中的参数数量一样))
reduce函数(累积)
语法:reduce(函数名,可迭代对象[, initializer])
reduce() 函数会对参数序列中元素进行累积。
函数将一个数据集合(链表,元组等)中的所有数据进行下列操作:用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。
reduce() 方法接收一个function作为累加器,可迭代对象中的每个值(从左
到右)开始缩减,最终计算为一个值。
示例:计算1 + 2 + 3 + … + 100
def reduce_test():
print(reduce(lambda x, y: x + y, range(1, 101)))
filter函数(过滤)
语法:filter(函数名,可迭代对象)
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
示例:li = [11,22,22,33,4,18], 把大于5的数据过滤出来
def work01(li):
return list(filter(lambda x: x > 5, li))
zip函数(打包)
语法:zip(可迭代对象1,可迭代对象2,…)
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
def zip_test():
a = ["a", "b", "c"]
b = [1, 2, 3]
print(zip(a, b)) # ,zip的结果是迭代器
print(list(zip(a, b))) # [('a', 1), ('b', 2), ('c', 3)]
递归
递归通俗来说就是自己调用自己。
递归是编程思想中比较重要的思维,可以将复杂问题简单实现。很多数学问题使用递归实现非常便捷。
Python递归深度
递归深度就是Python中默认的最大可循环次数,Python的递归深度为1000。
设置递归深度
import sys
def recursion_test():
print(sys.getrecursionlimit()) # 1000
sys.setrecursionlimit(9) # 设置递归深度为9
print(sys.getrecursionlimit()) # 9
if __name__ == '__main__':
recursion_test()
递归应用—栈(先进后出)
# 累加功能 1,100 return 1 + 2 + 3 + ... + 100
def demo02(x=100): # 递归是倒序求和
if x == 1: # 递归结束的条件,对此行断点调试看调用过程,将x改为5更快看过程
return 1 # 结束递归,return的值与要解决的问题有关,这里最后是加1所以为1
return demo02(x - 1) + x
# 递归调用核心,返回的是函数本身,函数并没有结束,除非跳出函数,函数才会结束
if __name__ == '__main__':
print(demo02()) # 5050