深度详解 Android S(12.0)屏幕刷新机制之 Choreographer
文章目录
- 简介
- 一、基础概念
- 二、Choreographer
-
- 1. 初探 Choreographer 的使用
- 2. 再探 Choreographer 的获取
- 3. Choreographer 构建
-
- 3.1 FrameHandler 异步消息处理
- 3.2 FrameDisplayEventReceiver 接收 VSync 脉冲信号
- 3.3 DisplayEventReceiver
- 3.4 回调队列 CallbackQueue
- 4. Choreographer 添加任务
-
- 4.1 Choreographer # doScheduleCallback()
- 4.2 Choreographer # scheduleFrameLocked()
- 4.3 Choreographer # scheduleVsyncLocked()
- 5 Native 层 NativeDisplayEventReceiver 构建及初始化
-
- 5.1 NativeDisplayEventReceiver 类结构
- 5.2 DisplayEventDispatcher 类结构
- 5.3 DisplayEventReceiver 类结构
-
- 5.3.1 获取 SurfaceFlinger 服务的代理
- 5.3.2 创建显示事件连接
- 5.3.3 应用层和 SurfaceFlinger 建立进程间通信的管道
- 5.4 NativeDisplayEventReceiver 初始化
- 6 Native 层 VSync 调度
-
- 6.1 DisplayEventDispatcher 调度 VSync
-
- 6.1.1 DisplayEventDispatcher 处理挂起事件
- 6.1.2 DisplayEventReceiver 请求 VSync 信号
- 6.2 EventThread 构建
- 6.3 EventThread 分发事件
- 6.4 DisplayEventDispatcher 执行回调事件
- 6.5 DisplayEventReceiver 分发事件
- 6.6 Choreographer 执行事件
- 6.6 ViewRootImpl 渲染视图
- 三、总结
简介
Android 的 UI 渲染性能是 Google 工程师们长期以来非常重视的,随着 Android 系统的不断演进和完善,Google 在 2012 年的 I/O 大会上宣布 Project Butter 计划,并在 Android 4.1 中正式开始实施,以优化 UI 渲染流畅性的问题。
Project Butter 对 Android Display 系统进行了重构优化,引入了三个核心元素,即 VSYNC、Triple Buffering 和 Choreographer,本文重点深入学习 Choreographer 有关的知识。
一、基础概念
- VSYNC 垂直同步
GPU 厂商开发用于防止屏幕撕裂的技术方案,全称 Vertical Synchronization,即垂直同步,可简单的把它理解为一种时钟中断。
- 刷新频率(Refresh Rate)
屏幕在一秒内刷新画面的次数,刷新频率取决于硬件的固定参数,单位:Hz(赫兹)。如常见的 60 Hz、144 Hz,即每秒钟刷新 60 次或 144 次。
- 逐行扫描
显示器并不是一次性将画面显示到屏幕上,而是从左到右边,从上到下逐行扫描显示,不过这一过程快到人眼无法察觉到变化。以 60 Hz 刷新率的屏幕为例,即 1000 / 60 ≈ 16ms。
- 帧速率 (Frame Rate)
表示 GPU 在一秒内绘制操作的帧数,单位:fps,全称 Frames Per Second,即每秒传输帧数。如在电影界采用 24 帧的速度足够使画面运行的非常流畅。而 Android 系统则采用更加流畅的 60 fps,即每秒钟绘制 60 帧画面。
二、Choreographer
Choreographer 直译为:舞蹈编导、编舞者,本质是一个 Java 类。简单来说,Choreographer 主要作用是协调输入、动画、和绘制等任务的执行时机,它从显示子系统接收定时脉冲(如垂直同步),然后安排渲染下一个显示 Frame 的部分工作。
还可以使用 Choreographer 来监测应用的帧率,结合自定义 FrameCallback 使用,在下一个显示 Frame 被渲染时将触发 FrameCallback 接口类获取渲染完成时间。
1. 初探 Choreographer 的使用
在分析学习 View 绘制流程有关的源码时,刷新 View 可以使用 View # invalidate() 方法 或 View # requestLayout() 方法,但不管调用哪一个方法,流程都会走到 ViewRootImpl # scheduleTraversals() 方法,看一下代码:
public final class ViewRootImpl implements ViewParent,
View.AttachInfo.Callbacks, ThreadedRenderer.DrawCallbacks {
final Choreographer mChoreographer;
public ViewRootImpl(Context context, Display display, IWindowSession session,
boolean useSfChoreographer) {
......
mChoreographer = useSfChoreographer
? Choreographer.getSfInstance() : Choreographer.getInstance();
......
}
@UnsupportedAppUsage
void scheduleTraversals() {
// 注意这个标志位,多次调用时只有这个标志位为 false 时才有效,保证同时有多次调用时只会执行一次
if (!mTraversalScheduled) {
mTraversalScheduled = true;
// 通过 MessageQueue # postSyncBarrier() 设置 Handler 的同步屏障消息
mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier();
// Choreographer 通过 postCallback 提交一个任务,mTraversalRunnable 是要执行的回调
// 注意这里 token 传值为 null
mChoreographer.postCallback(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
if (!mUnbufferedInputDispatch) {
scheduleConsumeBatchedInput();
}
notifyRendererOfFramePending();
pokeDrawLockIfNeeded();
}
}
}
ViewRootImpl # scheduleTraversals() 方法中首先通过 MessageQueue # postSyncBarrier() 方法为 Handler 的消息队列 MessageQueue 中添加同步屏障消息,然后通过 Choreographer # postCallback() 方法提交一个任务 TraversalRunnable。
这里 useSfChoreographer 默认传的是 false,因此这里 Choreographer 实例是在 ViewRootImpl 的构造方法中通过 Choreographer # getInstance() 方法获取的,而 ViewRootImpl 是在 Window 中添加 View 时创建的实例,这里不再详述,感兴趣的同学可自行查阅。
2. 再探 Choreographer 的获取
跟踪查看 Choreographer # getInstance() 方法的代码实现,如下:
public final class Choreographer {
// ThreadLocal 存储 Choreographer
private static final ThreadLocal<Choreographer> sThreadInstance =
new ThreadLocal<Choreographer>() {
@Override
protected Choreographer initialValue() {
// 获取当前线程的 Looper 对象
Looper looper = Looper.myLooper();
// 如果当前线程没有关联 Looper 则抛出异常提示
if (looper == null) {
throw new IllegalStateException("The current thread must have a looper!");
}
// 使用当前线程的 Looper 创建 Choreographer 实例,注意这里传的第二个参数 source 是 VSYNC_SOURCE_APP
// 这个值是 DisplayEventReceiver.VSYNC_SOURCE_APP 也就是 0
// 与 ISurfaceComposer.h 中的 VsyncSource.eVsyncSourceApp 值保持同步,代表的就是 AppEventThread
Choreographer choreographer = new Choreographer(looper, VSYNC_SOURCE_APP);
// 如果 Looper 是主线程的,则将 choreographer 赋值给 mMainInstance
if (looper == Looper.getMainLooper()) {
mMainInstance = choreographer;
}
return choreographer;
}
};
// Choreographer 静态实例
private static volatile Choreographer mMainInstance;
// 线程级单例,获取调用线程的 Choreographer 实例,必须由已关联有 Looper 的线程调用,否则抛出异常
public static Choreographer getInstance() {
return sThreadInstance.get();
}
}
Choreographer # getInstance() 方法中,调用 ThreadLocal # get() 方法获取当前调用线程的 Choreographer 实例,通过 ThreadLocal 实现 Choreographer 的线程级别单例,且当前调用线程必须有一个已关联的 Looper,因为 ThreadLocal # initialValue() 方法中创建 Choreographer 实例需要传入 Looper,这样 Choreographer 就具有处理当前线程消息循环队列的功能,后面会继续分析。
3. Choreographer 构建
public final class Choreographer {
public static final int CALLBACK_COMMIT = 4;
private static final int CALLBACK_LAST = CALLBACK_COMMIT;
private Choreographer(Looper looper, int vsyncSource) {
// 当前线程的 Looper
mLooper = looper;
// 创建 FrameHandler 处理消息
mHandler = new FrameHandler(looper);
// 是否启用 VSync,启用则创建 FrameDisplayEventReceiver 对象接收 VSync 脉冲信号
mDisplayEventReceiver = USE_VSYNC
? new FrameDisplayEventReceiver(looper, vsyncSource)
: null;
// 初始化上一个 frame 渲染的时间点
mLastFrameTimeNanos = Long.MIN_VALUE;
// getRefreshRate() 获取刷新率,Android 手机屏幕是 60Hz 的刷新频率
// 计算帧率,即渲染一帧的时间约等于 16666.66ns ≈ 16.6ms
mFrameIntervalNanos = (long)(1000000000 / getRefreshRate());
// 创建回调队列 CallbackQueue 默认容量大小是 5 的链表数组,存放要执行的输入、动画、绘制等任务
mCallbackQueues = new CallbackQueue[CALLBACK_LAST + 1];
for (int i = 0; i <= CALLBACK_LAST; i++) {
// 每个子元素为链表,用于存相同类型的任务:输入、动画、绘制等任务
//(CALLBACK_INPUT、CALLBACK_ANIMATION、CALLBACK_TRAVERSAL)
mCallbackQueues[i] = new CallbackQueue();
}
// b/68769804: For low FPS experiments.
setFPSDivisor(SystemProperties.getInt(ThreadedRenderer.DEBUG_FPS_DIVISOR, 1));
}
}
构建流程如下:
- 保存当前线程的 Looper,并使用该 Looper 创建 FrameHandler,Choreographer 的所有任务最终都会发送到该 Looper 所在的线程进行处理。
- 通过变量 USE_VSYNC 判断系统当前是否启用了 VSync 同步机制,该值是通过读取系统属性 debug.choreographer.vsync 来获取的,Android 在 4.1 之后默认启用该机制,则创建 FrameDisplayEventReceiver 对象用于请求并接收 VSync 脉冲信号。注意:上一步创建 Choreographer 实例时传入的 vsyncSource 是 VSYNC_SOURCE_APP,即 App 层请求的 VSync。
- 初始化上一个 frame 渲染的时间点,通过 Choreographer # getRefreshRate() 获取刷新率(Android 手机屏幕是 60Hz 的刷新频率),计算渲染一帧的时间约等于:16666.66ns ≈ 16.6ms。
- 创建回调队列 CallbackQueue 类型的链表数组,默认容量大小是 5,其每个子元素为链表,用于存相同类型的任务,如:输入(CALLBACK_INPUT)、动画(CALLBACK_ANIMATION)、绘制(CALLBACK_TRAVERSAL)等类型,将在下一帧开始渲染时回调。
接下来逐一分析 Choreographer 构建时几个关键的成员变量:
3.1 FrameHandler 异步消息处理
private final class FrameHandler extends Handler {
public FrameHandler(Looper looper) {
super(looper);
}
@Override
public void handleMessage(Message msg) {
switch (msg.what) {
case MSG_DO_FRAME:
// 如果启用 VSync 机制,当 VSync 信号到来时执行 doFrame 开始渲染下一帧
doFrame(System.nanoTime(), 0);
break;
case MSG_DO_SCHEDULE_VSYNC:
// 请求 VSync 信号,如当前需要绘制任务时
doScheduleVsync();
break;
case MSG_DO_SCHEDULE_CALLBACK:
// 请求执行延迟任务回调
doScheduleCallback(msg.arg1);
break;
}
}
}
3.2 FrameDisplayEventReceiver 接收 VSync 脉冲信号
private final class FrameDisplayEventReceiver extends DisplayEventReceiver
implements Runnable {
private boolean mHavePendingVsync; // 是否有待处理 VSync 信号
private long mTimestampNanos; // VSync 信号的时间戳
private int mFrame;
private VsyncEventData mLastVsyncEventData = new VsyncEventData
public FrameDisplayEventReceiver(Looper looper, int vsyncSource) {
super(looper, vsyncSource, 0);
}
// 接收到垂直同步脉冲时调用,最终调用 doFrame() 方法渲染一帧
@Override
public void onVsync(long timestampNanos, long physicalDisplayId, int frame,
VsyncEventData vsyncEventData) {
try {
if (Trace.isTagEnabled(Trace.TRACE_TAG_VIEW)) {
Trace.traceBegin(Trace.TRACE_TAG_VIEW,
"Choreographer#onVsync " + vsyncEventData.id);
}
long now = System.nanoTime(); // 系统当前时间
if (timestampNanos > now) {
// 校准 VSync 信号的时间戳,提示检查图形 HAL 是否使用正确的时基生成 VSync 时间戳
timestampNanos = now;
}
if (mHavePendingVsync) {
// 已经有一个待处理 VSync 事件,同一时间只能有一个
} else {
mHavePendingVsync = true;
}
// timestampNanos 是 VSync 信号的时间戳
mTimestampNanos = timestampNanos;
mFrame = frame;
mLastVsyncEventData = vsyncEventData;
// 获取的 Message 的回调 Callback 为当前对象
Message msg = Message.obtain(mHandler, this);
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, timestampNanos / TimeUtils.NANOS_PER_MS);
} finally {
Trace.traceEnd(Trace.TRACE_TAG_VIEW);
}
}
@Override
public void run() {
mHavePendingVsync = false;
doFrame(mTimestampNanos, mFrame, mLastVsyncEventData);
}
}
DisplayEventReceiver 是一个抽象类,FrameDisplayEventReceiver 是 DisplayEventReceiver 的实现类。FrameDisplayEventReceiver 接收到垂直同步脉冲时,调用其实现方法 onVsync(),在该方法中通过 Message # obtain() 方法获取到 Message,由 FrameHandler 发送消息并执行获取消息时传入的回调。由于获取消息时传入的回调是 FrameDisplayEventReceiver 本身,并且实现了 Runnable 接口,因此会回调 FrameDisplayEventReceiver # run() 方法,然后调用 Choreographer # doFrame() 方法。
3.3 DisplayEventReceiver
在 FrameDisplayEventReceiver 的构造方法中显式调用了父类 DisplayEventReceiver 的构造方法:
public abstract class DisplayEventReceiver {
// VSync 事件指定由应用程序 App 处理
public static final int VSYNC_SOURCE_APP = 0;
// VSync 事件指定由 Surface Flinger 处理
public static final int VSYNC_SOURCE_SURFACE_FLINGER = 1;
......
// native 层初始化 NativeDisplayEventReceiver 后返回给 Java 层的指针值
@UnsupportedAppUsage
private long mReceiverPtr;
// 消息队列
private MessageQueue mMessageQueue;
// 通过 JNI 调到 native 层创建 NativeDisplayEventReceiver
private static native long nativeInit(WeakReference<DisplayEventReceiver> receiver,
MessageQueue messageQueue, int vsyncSource, int configChanged);
private static native void nativeDispose(long receiverPtr);
@FastNative
private static native void nativeScheduleVsync(long receiverPtr);
......
public DisplayEventReceiver(Looper looper, int vsyncSource, int configChanged) {
if (looper == null) {
throw new IllegalArgumentException("looper must not be null");
}
mMessageQueue = looper.getQueue();
mReceiverPtr = nativeInit(new WeakReference<DisplayEventReceiver>(this), mMessageQueue,
vsyncSource, configChanged);
}
// 子类 FrameDisplayEventReceiver 实现,当接收到 VSync 时调用,并渲染一帧
// 同时调用 scheduleVsync() 来调度下一个 VSync
@UnsupportedAppUsage
public void onVsync(long timestampNanos, long physicalDisplayId, int frame,
VsyncEventData vsyncEventData) {
}
// 调度一个 VSync 在下一个显示帧开始时交付
@UnsupportedAppUsage
public void scheduleVsync() {
// 尝试调度一个 VSync,但显示事件接收器已被释放
if (mReceiverPtr == 0) {
Log.w(TAG, "Attempted to schedule a vertical sync pulse but the display event "
+ "receiver has already been disposed.");
} else {
// native 层调度,请求 VSync 信号,请求成功后回调 onVsync 方法
nativeScheduleVsync(mReceiverPtr);
}
}
}
DisplayEventReceiver 的构造方法中调用 nativeInit() 方法,由 native 层实现 NativeDisplayEventReceiver 的构建。当使用 Choreographer 添加任务时,通过 DisplayEventReceiver # scheduleVsync() 方法来调度一个 VSync 并在下一个显示帧开始时交付。当接收到 VSync 时,调用 DisplayEventReceiver 的实现类 FrameDisplayEventReceiver # onVsync() 方法,最终调用 Choreographer # doFrame() 方法渲染一帧。
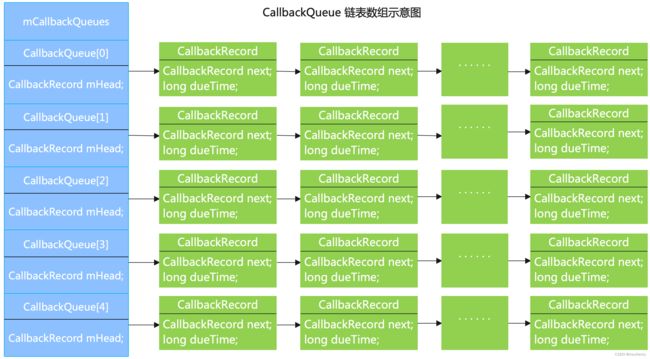
3.4 回调队列 CallbackQueue
通过 Choreographer 添加的回调任务保存在 CallbackQueue,Choreographer 中定义了 5 种类型的 Callback:
// 输入事件,首先执行
public static final int CALLBACK_INPUT = 0;
// 动画事件,在 CALLBACK_INSETS_ANIMATION 之前执行
public static final int CALLBACK_ANIMATION = 1;
// 插入更新动画事件,INPUT 和 ANIMATION 后面执行,TRAVERSAL 之前执行
public static final int CALLBACK_INSETS_ANIMATION = 2;
// 处理布局和绘制事件,在处理完上述异步消息之后运行
public static final int CALLBACK_TRAVERSAL = 3;
// 提交,和提交任务有关(在 API Level 23 添加),最后执⾏,遍历完成的提交操作,⽤来修正动画启动时间
public static final int CALLBACK_COMMIT = 4;
添加的回调任务最后会被封装成 CallbackRecord,同种类型的任务之间按照时间顺序以链表的形式保存在 CallbackQueue 内。当收到 VSync 信号时,Choreographer 按照任务优先级获取到 CallbackQueue,然后遍历执行其保存的 CallbackRecord 中封装的任务。
CallbackQueue 链表数组示意图如下:
4. Choreographer 添加任务
在 1. 初探 Choreographer 的使用 中,通过 Choreographer # postCallback() 方法添加任务,跟进源码查看:
@UnsupportedAppUsage
@TestApi
public void postCallback(int callbackType, Runnable action, Object token) {
// 继续调用 postCallbackDelayed(),注意 token 的入参前面传入的为 null
postCallbackDelayed(callbackType, action, token, 0);
}
@UnsupportedAppUsage
@TestApi
public void postCallbackDelayed(int callbackType,
Runnable action, Object token, long delayMillis) {
if (action == null) {
throw new IllegalArgumentException("action must not be null");
}
if (callbackType < 0 || callbackType > CALLBACK_LAST) {
// 判断 callbackType 是否在已定义的区间,不在则抛出异常
throw new IllegalArgumentException("callbackType is invalid");
}
// 继续调用 postCallbackDelayedInternal(),注意 token 的入参前面传入的为 null
postCallbackDelayedInternal(callbackType, action, token, delayMillis);
}
private void postCallbackDelayedInternal(int callbackType,
Object action, Object token, long delayMillis) {
......
synchronized (mLock) {
// 当前系统时间
final long now = SystemClock.uptimeMillis();
// 当前时间 + 需要延迟的时间
final long dueTime = now + delayMillis;
// 根据任务类型获取对应的 CallbackQueue,然后添加新的回调任务
mCallbackQueues[callbackType].addCallbackLocked(dueTime, action, token);
if (dueTime <= now) {
// 立即执行、请求 VSync 信号
scheduleFrameLocked(now);
} else {
// 延迟到指定时间运行,最终仍然会调用 scheduleFrameLocked
Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_CALLBACK, action);
// 根据 callbackType 在 mCallbackQueues 中查找回调任务并执行
msg.arg1 = callbackType;
// 设置为 异步消息
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, dueTime);
}
}
}
Choreographer 添加任务流程如下:
- 根据任务类型 callbackType 获取对应的 CallbackQueue,然后调用 CallbackQueue # addCallbackLocked() 方法把 dueTime、action、token 组装成 CallbackRecord 后按照 dueTime 的先后顺序存入 CallbackQueue 中,即添加新的回调任务。
- 判断任务是否需要延迟,无需延迟则立即执行 Choreographer # scheduleFrameLocked() 方法,否则发送事件类型为 MSG_DO_SCHEDULE_CALLBACK 的延迟任务消息到 FrameHandler 中处理,在其 handleMessage() 方法中根据事件类型调用 Choreographer # doScheduleCallback() 方法。
4.1 Choreographer # doScheduleCallback()
void doScheduleCallback(int callbackType) {
synchronized (mLock) {
if (!mFrameScheduled) {
final long now = SystemClock.uptimeMillis();
if (mCallbackQueues[callbackType].hasDueCallbacksLocked(now)) {
scheduleFrameLocked(now);
}
}
}
}
在该方法中,判断回调队列 mCallbackQueues 中对应任务类型 callbackType 的 CallbackQueue 中 mHead 不为空和执行时间小于当前时间 now 这两个条件同时满足时,调用 Choreographer # scheduleFrameLocked() 方法来调度执行下一帧。
4.2 Choreographer # scheduleFrameLocked()
private void scheduleFrameLocked(long now) {
if (!mFrameScheduled) {
// 开始调度帧,mFrameScheduled 标志位置为 true
mFrameScheduled = true;
// 判断是否启用 VSync
if (USE_VSYNC) {
......
// 判断当前执行的线程,是否是 mLooper 所在工作线程(即 UI 主线程)
if (isRunningOnLooperThreadLocked()) {
// 请求 VSYNC 信号
scheduleVsyncLocked();
} else {
// 如果不是 mLooper 所在工作线程(即 UI 主线程),发送消息到 FrameHandler 异步消息处理
// 流程最后也是调用 scheduleVsyncLocked() 方法
Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_VSYNC);
msg.setAsynchronous(true);
// 注意:这个消息是插到消息队列头部,这里可以理解为设置最高优先级,比较紧急的
mHandler.sendMessageAtFrontOfQueue(msg);
}
} else {
// 如果未启用 VSync 机制则发送消息到 FrameHandler,然后流程走到 doFrame() 方法
final long nextFrameTime = Math.max(
mLastFrameTimeNanos / TimeUtils.NANOS_PER_MS + sFrameDelay, now);
......
// 事件类型为 MSG_DO_FRAME 的消息
Message msg = mHandler.obtainMessage(MSG_DO_FRAME);
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, nextFrameTime);
}
}
}
void doScheduleVsync() {
synchronized (mLock) {
if (mFrameScheduled) {
scheduleVsyncLocked();
}
}
}
执行流程如下:
- 如果启用了 VSync 机制,则判断当前执行的线程是否是 mLooper 所在的工作线程(即 UI 主线程),如果是则调用 Choreographer # scheduleVsyncLocked() 方法请求 VSync 信号。
- 如果不是,则发送事件类型为 MSG_DO_SCHEDULE_VSYNC 的消息到 FrameHandler 所在线程中进行异步处理,在其 handleMessage() 方法中根据事件类型调用 Choreographer # doScheduleVsync() 方法,流程最后也是调用 Choreographer # scheduleVsyncLocked() 方法请求 VSync 信号。
- 如果未启用 VSync 机制,则发送事件类型为 MSG_DO_FRAME 的消息到 FrameHandler 中处理,此时流程会调用到 Choreographer # doFrame() 方法。
4.3 Choreographer # scheduleVsyncLocked()
@UnsupportedAppUsage
private void scheduleVsyncLocked() {
mDisplayEventReceiver.scheduleVsync();
}
mDisplayEventReceiver 是在 Choreographer 的构造方法中创建的,启用 VSync 机制时创建的是 FrameDisplayEventReceiver 实例。由于 FrameDisplayEventReceiver 没有重写其父类 DisplayEventReceiver 的 scheduleVsync() 方法,因此这里调用的是父类 DisplayEventReceiver 中的方法。
在 DisplayEventReceiver # scheduleVsync() 方法中,调用 native 层的 nativeScheduleVsync() 方法并传入构造方法中调用 nativeInit() 方法初始化的 NativeDisplayEventReceiver 实例的指针值。
Native 层源码可以通过下载系统源码然后做关联,也可以在线查看,这里推荐几个在线查看源码的网站:OPERSYS、AndroidXRef。那么接下来进入 Native 层,查看底层代码实现。
5 Native 层 NativeDisplayEventReceiver 构建及初始化
先看一下 DisplayEventReceiver 中初始化 native 层 NativeDisplayEventReceiver 实例的方法,将当前的 DisplayEventReceiver 以及队列 mMessageQueue 和 vsyncSource(VSYNC_SOURCE_APP) 传递给底层,代码如下:
// xref:/frameworks/base/core/jni/android_view_DisplayEventReceiver.cpp
static jlong nativeInit(JNIEnv* env, jclass clazz, jobject receiverWeak, jobject messageQueueObj,
jint vsyncSource, jint eventRegistration) {
// 将 Java 层的 MessageQueue 转为 native 层对应的 MessageQueue
sp<MessageQueue> messageQueue = android_os_MessageQueue_getMessageQueue(env, messageQueueObj);
if (messageQueue == NULL) {
jniThrowRuntimeException(env, "MessageQueue is not initialized.");
return 0;
}
// 创建 NativeDisplayEventReceiver 对象,建立 gui::BitTube 通信信道连接
sp<NativeDisplayEventReceiver> receiver =
new NativeDisplayEventReceiver(env, receiverWeak, messageQueue, vsyncSource,
eventRegistration);
// 初始化 NativeDisplayEventReceiver
status_t status = receiver->initialize();
if (status) {
String8 message;
message.appendFormat("Failed to initialize display event receiver. status=%d", status);
jniThrowRuntimeException(env, message.string());
return 0;
}
receiver->incStrong(gDisplayEventReceiverClassInfo.clazz); // retain a reference for the object
return reinterpret_cast<jlong>(receiver.get());
}
执行流程如下:
- 由 Java 层传入的 MessageQueue 获取 native 层对应的 MessageQueue。
- 构造 NativeDisplayEventReceiver 对象,并传入 Java 层 DisplayEventReceiver 的弱引用对象、消息队列 MessageQueue、VSync 信号源等。
- 初始化 NativeDisplayEventReceiver,并返回对应的初始化结果:成功、失败。
5.1 NativeDisplayEventReceiver 类结构
// xref:/frameworks/base/core/jni/android_view_DisplayEventReceiver.cpp
class NativeDisplayEventReceiver : public DisplayEventDispatcher {
public:
NativeDisplayEventReceiver(JNIEnv* env, jobject receiverWeak,
const sp<MessageQueue>& messageQueue, jint vsyncSource,
jint eventRegistration);
void dispose();
protected:
virtual ~NativeDisplayEventReceiver();
private:
jobject mReceiverWeakGlobal; // Java 层的 DisplayEventReceiver 的弱引用对象转为弱全局引用
sp<MessageQueue> mMessageQueue; // 消息队列
void dispatchVsync(nsecs_t timestamp, PhysicalDisplayId displayId, uint32_t count,
VsyncEventData vsyncEventData) override;
void dispatchHotplug(nsecs_t timestamp, PhysicalDisplayId displayId, bool connected) override;
void dispatchModeChanged(nsecs_t timestamp, PhysicalDisplayId displayId, int32_t modeId,
nsecs_t vsyncPeriod) override;
void dispatchFrameRateOverrides(nsecs_t timestamp, PhysicalDisplayId displayId,
std::vector<FrameRateOverride> overrides) override;
void dispatchNullEvent(nsecs_t timestamp, PhysicalDisplayId displayId) override {}
};
NativeDisplayEventReceiver::NativeDisplayEventReceiver(JNIEnv* env, jobject receiverWeak,
const sp<MessageQueue>& messageQueue,
jint vsyncSource, jint eventRegistration)
: DisplayEventDispatcher(messageQueue->getLooper(),
// 将 Java 层传入的 vsyncSource(0)强制转换为 VsyncSource.eVsyncSourceApp
static_cast<ISurfaceComposer::VsyncSource>(vsyncSource),
static_cast<ISurfaceComposer::EventRegistration>(eventRegistration)),
mReceiverWeakGlobal(env->NewGlobalRef(receiverWeak)),
mMessageQueue(messageQueue) {
ALOGV("receiver %p ~ Initializing display event receiver.", this);
}
执行流程如下:
- NativeDisplayEventReceiver 继承 DisplayEventDispatcher,调用 NativeDisplayEventReceiver 的构造方法时会调用 DisplayEventDispatcher 的构造方法来构造对象。
- 将 Java 层 DisplayEventReceiver 的弱引用对象转为弱全局引用,防止被虚拟机释放,不需要时则在对应的析构函数中需要手动释放,因为 Java 有垃圾回收器帮开发人员回收,C++ 需要开发人员主动回收。
- 同时将传入的消息队列 MessageQueue 赋值给 mMessageQueue 保存。
5.2 DisplayEventDispatcher 类结构
// xref:/frameworks/native/include/gui/DisplayEventDispatcher.h
class DisplayEventDispatcher : public LooperCallback {
public:
explicit DisplayEventDispatcher(
const sp<Looper>& looper,
ISurfaceComposer::VsyncSource vsyncSource = ISurfaceComposer::eVsyncSourceApp,
ISurfaceComposer::EventRegistrationFlags eventRegistration = {});
status_t initialize();
void dispose();
status_t scheduleVsync();
void injectEvent(const DisplayEventReceiver::Event& event);
int getFd() const;
virtual int handleEvent(int receiveFd, int events, void* data);
protected:
virtual ~DisplayEventDispatcher() = default;
private:
sp<Looper> mLooper; // Looper 对象用于消息循环
DisplayEventReceiver mReceiver; // 显示事件接收器
bool mWaitingForVsync; // 等待 VSync 信号的标识位
std::vector<FrameRateOverride> mFrameRateOverrides;
virtual void dispatchVsync(nsecs_t timestamp, PhysicalDisplayId displayId, uint32_t count,
VsyncEventData vsyncEventData) = 0;
virtual void dispatchHotplug(nsecs_t timestamp, PhysicalDisplayId displayId,
bool connected) = 0;
virtual void dispatchModeChanged(nsecs_t timestamp, PhysicalDisplayId displayId, int32_t modeId,
nsecs_t vsyncPeriod) = 0;
// AChoreographer-specific hook for processing null-events so that looper
// can be properly poked.
virtual void dispatchNullEvent(nsecs_t timestamp, PhysicalDisplayId displayId) = 0;
virtual void dispatchFrameRateOverrides(nsecs_t timestamp, PhysicalDisplayId displayId,
std::vector<FrameRateOverride> overrides) = 0;
bool processPendingEvents(nsecs_t* outTimestamp, PhysicalDisplayId* outDisplayId,
uint32_t* outCount, VsyncEventData* outVsyncEventData);
};
}
// xref:/frameworks/native/libs/gui/DisplayEventDispatcher.cpp
DisplayEventDispatcher::DisplayEventDispatcher(
const sp<Looper>& looper, ISurfaceComposer::VsyncSource vsyncSource,
ISurfaceComposer::EventRegistrationFlags eventRegistration)
: mLooper(looper), mReceiver(vsyncSource, eventRegistration), mWaitingForVsync(false) {
ALOGV("dispatcher %p ~ Initializing display event dispatcher.", this);
}
执行流程如下:
- 调用 DisplayEventDispatcher 的构造方法来构造对象,同时将传入的 Looper 赋值给头文件中的 mLooper 保存。
- 调用 DisplayEventReceiver 的构造方法,传入 VSync 信号源等参数,并将构建的 DisplayEventReceiver 赋值给 mReceiver。
- 将头文件中的 mWaitingForVsync 赋值为 false。
5.3 DisplayEventReceiver 类结构
// xref:/frameworks/native/libs/gui/include/gui/DisplayEventReceiver.h
class DisplayEventReceiver {
public:
explicit DisplayEventReceiver(
ISurfaceComposer::VsyncSource vsyncSource = ISurfaceComposer::eVsyncSourceApp,
ISurfaceComposer::EventRegistrationFlags eventRegistration = {});
......
status_t requestNextVsync();
private:
sp<IDisplayEventConnection> mEventConnection; // 显示事件连接
std::unique_ptr<gui::BitTube> mDataChannel; // 进程间通信的管道
};
// xref:/frameworks/native/libs/gui/DisplayEventReceiver.cpp
DisplayEventReceiver::DisplayEventReceiver(
ISurfaceComposer::VsyncSource vsyncSource,
ISurfaceComposer::EventRegistrationFlags eventRegistration) {
// 获取 SurfaceFlinger 代理端 BpSurfaceComposer,继承自 ISurfaceComposer
sp<ISurfaceComposer> sf(ComposerService::getComposerService());
if (sf != nullptr) {
// 创建显示事件连接
mEventConnection = sf->createDisplayEventConnection(vsyncSource, eventRegistration);
if (mEventConnection != nullptr) {
// 初始化空 gui::BitTube 对象
mDataChannel = std::make_unique<gui::BitTube>();
// 将 SurfaceFlinger 进程中服务端创建的 gui::BitTube 对象赋值给应用端空的 gui::BitTube 对象
mEventConnection->stealReceiveChannel(mDataChannel.get());
}
}
}
DisplayEventReceiver 是一个比较重要的类,其主要作用是建立与 SurfaceFlinger 的连接,接下来将对其每一个调用的方法都来进行详细的分析,调用流程如下:
- 获取 SurfaceFlinger 服务的代理对象 BpSurfaceComposer。
- SurfaceFlinger 进程中创建显示事件连接 IDisplayEventConnection,并返回代理对象 BpDisplayEventConnection 赋值给 mEventConnection。
- 初始化空 gui::BitTube 对象,将 SurfaceFlinger 进程中服务端创建的 gui::BitTube 对象赋值给应用进程端空的 gui::BitTube 对象,建立 app 应用进程和 SurfaceFlinger 进程之间的通道。
5.3.1 获取 SurfaceFlinger 服务的代理
// xref:/frameworks/native/libs/gui/include/private/gui/ComposerService.h
class ComposerService : public Singleton<ComposerService>
{
sp<ISurfaceComposer> mComposerService;
sp<IBinder::DeathRecipient> mDeathObserver;
Mutex mLock;
ComposerService();
bool connectLocked();
void composerServiceDied();
friend class Singleton<ComposerService>;
public:
// 获取 Composer Service 的连接,建立连接之前处于阻塞状态。如果权限被拒绝,则返回 null
static sp<ISurfaceComposer> getComposerService();
};
// xref:/frameworks/native/libs/gui/SurfaceComposerClient.cpp
/*static*/ sp<ISurfaceComposer> ComposerService::getComposerService() {
ComposerService& instance = ComposerService::getInstance();
Mutex::Autolock _l(instance.mLock);
if (instance.mComposerService == nullptr) {
if (ComposerService::getInstance().connectLocked()) {
ALOGD("ComposerService reconnected");
}
}
return instance.mComposerService;
}
ComposerService 是一个单例类,通过其 getComposerService() 方法获取保存在成员变量 mComposerService 中的 SurfaceFlinger 服务,这里返回的是 SurfaceFlinger 的 Binder 代理端的 BpSurfaceComposer 对象。如果获取不到则通过 connectLocked() 方法获取,代码如下:
// xref:/frameworks/native/libs/gui/SurfaceComposerClient.cpp
ComposerService::ComposerService()
: Singleton<ComposerService>() {
Mutex::Autolock _l(mLock);
connectLocked();
}
bool ComposerService::connectLocked() {
// 指定待获取服务为:SurfaceFlinger
const String16 name("SurfaceFlinger");
mComposerService = waitForService<ISurfaceComposer>(name);
if (mComposerService == nullptr) {
return false; // fatal error or permission problem
}
// 创建死亡监听器
class DeathObserver : public IBinder::DeathRecipient {
ComposerService& mComposerService;
virtual void binderDied(const wp<IBinder>& who) {
ALOGW("ComposerService remote (surfaceflinger) died [%p]", who.unsafe_get());
mComposerService.composerServiceDied();
}
public:
explicit DeathObserver(ComposerService& mgr) : mComposerService(mgr) { }
};
// 关联死亡监听器
mDeathObserver = new DeathObserver(*const_cast<ComposerService*>(this));
IInterface::asBinder(mComposerService)->linkToDeath(mDeathObserver);
return true;
}
指定待获取服务名称为 SurfaceFlinger,通过 ServiceManager 的 waitForService() 方法获取指定名称服务的代理对象,后将获取到的服务保存到 mComposerService,并为服务创建死亡监听器,如果远程服务挂掉,可以通过 Binder 的 linkToDeath 机制得到通知,并将重新建立连接。
// xref:/frameworks/native/libs/fakeservicemanager/ServiceManager.h
class ServiceManager : public IServiceManager {
public:
ServiceManager();
sp<IBinder> getService( const String16& name) const override;
sp<IBinder> checkService( const String16& name) const override;
status_t addService(const String16& name, const sp<IBinder>& service,
bool allowIsolated = false,
int dumpsysFlags = DUMP_FLAG_PRIORITY_DEFAULT) override;
Vector<String16> listServices(int dumpsysFlags = 0) override;
IBinder* onAsBinder() override;
sp<IBinder> waitForService(const String16& name) override;
......
private:
std::map<String16, sp<IBinder>> mNameToService; // map 保存所有已添加服务的键值对
};
// xref:/frameworks/native/libs/fakeservicemanager/ServiceManager.cpp
sp<IBinder> ServiceManager::checkService( const String16& name) const {
// map 中根据 key 值 服务名称查找对应的服务的代理 IBinder
auto it = mNameToService.find(name);
if (it == mNameToService.end()) {
return nullptr;
}
// 返回 map 中获取到实例的 value 值,first 指 key,second 指 value
return it->second;
}
sp<IBinder> ServiceManager::waitForService(const String16& name) {
return checkService(name);
}
ServiceManager 中使用 map 保存所有已添加服务的键值对,其中 key 值为服务名称,如 SurfaceFlinger 等,value 值为对应的服务的代理 IBinder。
5.3.2 创建显示事件连接
根据上面的分析,创建显示事件连接使用的是 SurfaceFlinger 服务的代理对象 BpSurfaceComposer,方法如下:
// xref:/frameworks/native/libs/gui/ISurfaceComposer.cpp
class BpSurfaceComposer : public BpInterface<ISurfaceComposer> {
......
sp<IDisplayEventConnection> createDisplayEventConnection(
VsyncSource vsyncSource, EventRegistrationFlags eventRegistration) override {
Parcel data, reply;
sp<IDisplayEventConnection> result;
int err = data.writeInterfaceToken(
ISurfaceComposer::getInterfaceDescriptor());
if (err != NO_ERROR) {
return result;
}
data.writeInt32(static_cast<int32_t>(vsyncSource));
data.writeUint32(eventRegistration.get());
err = remote()->transact(
BnSurfaceComposer::CREATE_DISPLAY_EVENT_CONNECTION,
data, &reply);
if (err != NO_ERROR) {
ALOGE("ISurfaceComposer::createDisplayEventConnection: error performing "
"transaction: %s (%d)", strerror(-err), -err);
return result;
}
result = interface_cast<IDisplayEventConnection>(reply.readStrongBinder());
// 返回代理对象 BpDisplayEventConnection,IDisplayEventConnection 在应用进程端的实现
return result;
}
......
}
status_t BnSurfaceComposer::onTransact(
uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags) {
switch(code) {
......
case CREATE_DISPLAY_EVENT_CONNECTION: {
CHECK_INTERFACE(ISurfaceComposer, data, reply);
auto vsyncSource = static_cast<ISurfaceComposer::VsyncSource>(data.readInt32());
EventRegistrationFlags eventRegistration =
static_cast<EventRegistration>(data.readUint32());
// 远程服务端构建 IDisplayEventConnection 的本地实现对象 BnDisplayEventConnection
sp<IDisplayEventConnection> connection(
createDisplayEventConnection(vsyncSource, eventRegistration));
reply->writeStrongBinder(IInterface::asBinder(connection));
return NO_ERROR;
}
......
}
熟悉 AIDL 的童鞋看到这里应该很熟悉,通过 Parcel 将数据从 app 应用进程传递到远程的 SurfaceFlinger 服务端进程,并调用 SurfaceFlinger # onTransact() 方法,在该方法内部调用 BnSurfaceComposer::onTransact() 方法,这里 BnSurfaceComposer 是与 BpSurfaceComposer 对应的服务端的本地实现,且 SurfaceFlinger 继承了 BnSurfaceComposer,在 BnSurfaceComposer # onTransact() 方法中找到 CREATE_DISPLAY_EVENT_CONNECTION 对应的 case 分支,获取 Parcel 传递过来的数据,后调用 SurfaceFlinger 服务端进程的 createDisplayEventConnection() 方法来创建显示事件连接。
// xref:/frameworks/native/services/surfaceflinger/SurfaceFlinger.h
class SurfaceFlinger : public BnSurfaceComposer,
public PriorityDumper,
private IBinder::DeathRecipient,
private HWC2::ComposerCallback,
private ISchedulerCallback {
// Implements ISurfaceComposer
sp<ISurfaceComposerClient> createConnection() override;
......
sp<IDisplayEventConnection> createDisplayEventConnection(
ISurfaceComposer::VsyncSource vsyncSource = eVsyncSourceApp,
ISurfaceComposer::EventRegistrationFlags eventRegistration = {}) override;
......
}
// xref:/frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
sp<IDisplayEventConnection> SurfaceFlinger::createDisplayEventConnection(
ISurfaceComposer::VsyncSource vsyncSource,
ISurfaceComposer::EventRegistrationFlags eventRegistration) {
// 应用进程传递的 vsyncSource 值为 0,不等于 eVsyncSourceSurfaceFlinger = 1
const auto& handle =
vsyncSource == eVsyncSourceSurfaceFlinger ? mSfConnectionHandle : mAppConnectionHandle;
return mScheduler->createDisplayEventConnection(handle, eventRegistration);
}
执行流程如下:
- 根据传入的 vsyncSource 类型,返回不同的 ConnectionHandle。由于传入的是 VSYNC_SOURCE_APP,即应用中注册的,因此返回 mAppConnectionHandle 应用程序使用的连接句柄。
- 调用 Scheduler 的 createDisplayEventConnection() 方法并传入返回的 mAppConnectionHandle 创建 App 应用程序使用的显示事件连接,这里 mScheduler 是在 SurfaceFlinger 的 init() 方法中,然后调用 processDisplayHotplugEventsLocked() 方法,最后在 initScheduler() 方法中创建的。
先查看下一步要使用的两个重要成员 ConnectionHandle 和 Scheduler 的初始化,代码如下:
// xref:/frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
void SurfaceFlinger::initScheduler(const DisplayDeviceState& displayState) {
......
mRefreshRateConfigs =
std::make_unique<scheduler::RefreshRateConfigs>(displayState.physical->supportedModes,
displayState.physical->activeMode
->getId(),
config);
const auto currRefreshRate = displayState.physical->activeMode->getFps();
mRefreshRateStats = std::make_unique<scheduler::RefreshRateStats>(*mTimeStats, currRefreshRate,
hal::PowerMode::OFF);
......
// start the EventThread
mScheduler = getFactory().createScheduler(*mRefreshRateConfigs, *this);
const auto configs = mVsyncConfiguration->getCurrentConfigs();
const nsecs_t vsyncPeriod = currRefreshRate.getPeriodNsecs();
// App 应用程序专属的连接句柄
mAppConnectionHandle =
mScheduler->createConnection("app", mFrameTimeline->getTokenManager(),
/*workDuration=*/configs.late.appWorkDuration,
/*readyDuration=*/configs.late.sfWorkDuration,
impl::EventThread::InterceptVSyncsCallback());
// SurfaceFlinger 服务专属的连接句柄
mSfConnectionHandle =
mScheduler->createConnection("appSf", mFrameTimeline->getTokenManager(),
/*workDuration=*/std::chrono::nanoseconds(vsyncPeriod),
/*readyDuration=*/configs.late.sfWorkDuration,
[this](nsecs_t timestamp) {
mInterceptor->saveVSyncEvent(timestamp);
});
......
mEventQueue->initVsync(mScheduler->getVsyncDispatch(), *mFrameTimeline->getTokenManager(),
configs.late.sfWorkDuration);
......
}
执行流程如下:
- 获取刷新率配置、当前刷新率和刷新率状态等值,使用初始化 SurfaceFlinger 时传入的 Factory,并调用该工厂的 createScheduler() 方法传入刷新率配置和当前的 SurfaceFlinger 自身来创建类型为 std::unique_ptr
的调度器 mScheduler。这里 unique_ptr 是一个独占式指针管理类。 - 通过调度器 mScheduler 的 createConnection() 方法创建 ConnectionHandle 对象并赋值给 mAppConnectionHandle。
// xref:/frameworks/native/services/surfaceflinger/Scheduler/Scheduler.cpp
Scheduler::ConnectionHandle Scheduler::createConnection(
const char* connectionName, frametimeline::TokenManager* tokenManager,
std::chrono::nanoseconds workDuration, std::chrono::nanoseconds readyDuration,
impl::EventThread::InterceptVSyncsCallback interceptCallback) {
// 构建 DispSyncSource
auto vsyncSource = makePrimaryDispSyncSource(connectionName, workDuration, readyDuration);
auto throttleVsync = makeThrottleVsyncCallback();
auto getVsyncPeriod = makeGetVsyncPeriodFunction();
// 构建管理 App 应用程序相关 VSync 信号的 EventThread
auto eventThread = std::make_unique<impl::EventThread>(std::move(vsyncSource), tokenManager,
std::move(interceptCallback),
std::move(throttleVsync),
std::move(getVsyncPeriod));
// 继续调用 createConnection 传入新建的 EventThread
return createConnection(std::move(eventThread));
}
Scheduler::ConnectionHandle Scheduler::createConnection(std::unique_ptr<EventThread> eventThread) {
// 构建 ConnectionHandle 即连接句柄
const ConnectionHandle handle = ConnectionHandle{mNextConnectionHandleId++};
ALOGV("Creating a connection handle with ID %" PRIuPTR, handle.id);
// 创建 EventThread 的 Connection 连接 EventThreadConnection
auto connection = createConnectionInternal(eventThread.get());
std::lock_guard<std::mutex> lock(mConnectionsLock);
// mConnections 是一个 Connection 的集合,将刚创建的 EventThreadConnection 保存到集合中
mConnections.emplace(handle, Connection{connection, std::move(eventThread)});
// 返回 app 应用进程的 ConnectionHandle
return handle;
}
std::make_unique 将参数转发给要创建对象的构造函数,再用 new 出来的原生指针,构造 std::unique_ptr 独占式智能指针。
std::move 将对象的状态或者所有权从一个对象转移到另一个对象,只是转移而没有内存拷贝。
接下来回到主流程继续看一下 Scheduler 的 createDisplayEventConnection() 方法创建显示事件连接,代码如下:
// xref:/frameworks/native/services/surfaceflinger/Scheduler/Scheduler.cpp
sp<IDisplayEventConnection> Scheduler::createDisplayEventConnection(
ConnectionHandle handle, ISurfaceComposer::EventRegistrationFlags eventRegistration) {
std::lock_guard<std::mutex> lock(mConnectionsLock);
RETURN_IF_INVALID_HANDLE(handle, nullptr);
// 根据入参 handle,这里是初始化时创建的 mAppConnectionHandle,获取 mConnections 保存的 EventThread
// mConnections 是 map 类型,key 值表示的是 ConnectionHandle 类型,这里是 mAppConnectionHandle
// 最终 mConnections[handle->id]->thread.get() 拿到的就是 AppEventThread
// 这个初始化上面已经分析过,创建 EventThread 时同步生成的
return createConnectionInternal(mConnections[handle].thread.get(), eventRegistration);
}
sp<EventThreadConnection> Scheduler::createConnectionInternal(
EventThread* eventThread, ISurfaceComposer::EventRegistrationFlags eventRegistration) {
// 将 resync() 函数包装成可调用实体,类似 kotlin 中传递的函数闭包,传递到 EventThread 的 createEventConnection
return eventThread->createEventConnection([&] { resync(); }, eventRegistration);
}
// 判断是否需要忽略延迟、时钟周期是否大于 0 等,决定是否重设 VSync 的时钟周期
void Scheduler::resync() {
static constexpr nsecs_t kIgnoreDelay = ms2ns(750);
const nsecs_t now = systemTime();
const nsecs_t last = mLastResyncTime.exchange(now);
if (now - last > kIgnoreDelay) {
resyncToHardwareVsync(false, mRefreshRateConfigs.getCurrentRefreshRate().getVsyncPeriod());
}
}
继续调用 EventThread 的 createEventConnection() 方法,跟进去查看:
// xref:/frameworks/native/services/surfaceflinger/Scheduler/EventThread.h
// 将一段可执行函数封装到 ResyncCallback 中
using ResyncCallback = std::function<void()>;
// xref:/frameworks/native/services/surfaceflinger/Scheduler/EventThread.cpp
sp<EventThreadConnection> EventThread::createEventConnection(
ResyncCallback resyncCallback,
ISurfaceComposer::EventRegistrationFlags eventRegistration) const {
return new EventThreadConnection(const_cast<EventThread*>(this),
IPCThreadState::self()->getCallingUid(),
std::move(resyncCallback), eventRegistration);
}
std::function 是 C++11 新特性,包含在头文件中,是一个函数包装器,用来包装任何类型的可调用实体,如普通函数,函数对象,lamda 表达式等。包装器可拷贝,移动等,并且包装器类型仅仅依赖于调用特征,而不依赖于可调用元素自身的类型。
方法代码不多,创建一个 EventThreadConnection 对象并返回,跟踪查看这个对象的构造函数:
// xref:/frameworks/native/services/surfaceflinger/Scheduler/EventThread.cpp
EventThreadConnection::EventThreadConnection(
EventThread* eventThread, uid_t callingUid, ResyncCallback resyncCallback,
ISurfaceComposer::EventRegistrationFlags eventRegistration)
: resyncCallback(std::move(resyncCallback)),
mOwnerUid(callingUid),
mEventRegistration(eventRegistration),
mEventThread(eventThread),
mChannel(gui::BitTube::DefaultSize) {}
调用 EventThreadConnection 的构造方法创建实例对象的时候,在 5.3 DisplayEventReceiver 类结构 头文件中可以看到成员变量 mEventConnection 是 sp<> 修饰的,这是在 Android 中 Google 实现的一种强引用的智能指针,并且 EventThreadConnection 类的最顶层父类是 RefBase 类,因此在 EventThreadConnection 初始化后将自动回调其实现的 onFirstRef() 方法,不了解 C++ 的同学可以自行查阅有关资料。
下面看一下 EventThreadConnection 的 onFirstRef() 方法,代码如下:
// xref:/frameworks/native/services/surfaceflinger/Scheduler/EventThread.cpp
void EventThreadConnection::onFirstRef() {
// NOTE: mEventThread doesn't hold a strong reference on us
// 将新构建的 EventThreadConnection 也就是把自己注册到 EventThread
mEventThread->registerDisplayEventConnection(this);
}
status_t EventThread::registerDisplayEventConnection(const sp<EventThreadConnection>& connection) {
std::lock_guard<std::mutex> lock(mMutex);
// this should never happen
auto it = std::find(mDisplayEventConnections.cbegin(),
mDisplayEventConnections.cend(), connection);
if (it != mDisplayEventConnections.cend()) {
ALOGW("DisplayEventConnection %p already exists", connection.get());
mCondition.notify_all();
return ALREADY_EXISTS;
}
// 将新建的连接放入到需要通知的列表 mDisplayEventConnections 中
mDisplayEventConnections.push_back(connection);
// 添加新的连接,唤醒等待的 AppEventThread 线程
mCondition.notify_all();
return NO_ERROR;
}
mCondition 是 condition_variable 类型的变量:等待线程和唤醒线程之间的同步操作都依赖该变量。
调用 EventThreadConnection 的构造方法创建实例对象的同时会保存、创建下面几个重要的成员:
- resyncCallback:包装的可调用函数实体。
- mOwnerUid:用户 ID,表明哪个用户拥有当前的连接通道 EventThreadConnection。
- mEventRegistration:注册与 SurfaceFlinger 关联的事件。
- mEventThread:管理 VSync 的 EventThread。
- mChannel:保存创建的 gui::BitTube 类型的管道用来进行进程间通信。
重点关注创建的 gui::BitTube 类型的管道,看一下其构造方法:
// xref:/frameworks/native/libs/gui/include/private/gui/BitTube.h
class BitTube : public Parcelable {
public:
// 创建一个未初始化的 BitTube
BitTube() = default;
// 创建一个带有指定发送和接收缓冲区大小的 BitTube
explicit BitTube(size_t bufsize);
// 创建一个带有默认(4KB)发送缓冲区的 BitTube
struct DefaultSizeType {};
static constexpr DefaultSizeType DefaultSize{};
explicit BitTube(DefaultSizeType);
private:
void init(size_t rcvbuf, size_t sndbuf);
......
mutable base::unique_fd mSendFd;
mutable base::unique_fd mReceiveFd;
static ssize_t sendObjects(BitTube* tube, void const* events, size_t count, size_t objSize);
static ssize_t recvObjects(BitTube* tube, void* events, size_t count, size_t objSize);
};
// xref:/frameworks/native/libs/gui/BitTube.cpp
BitTube::BitTube(size_t bufsize) {
// 初始化一个带有指定发送和接收缓冲区大小的 BitTube
init(bufsize, bufsize);
}
......
void BitTube::init(size_t rcvbuf, size_t sndbuf) {
int sockets[2];
if (socketpair(AF_UNIX, SOCK_SEQPACKET, 0, sockets) == 0) {
size_t size = DEFAULT_SOCKET_BUFFER_SIZE;
setsockopt(sockets[0], SOL_SOCKET, SO_RCVBUF, &rcvbuf, sizeof(rcvbuf));
setsockopt(sockets[1], SOL_SOCKET, SO_SNDBUF, &sndbuf, sizeof(sndbuf));
// since we don't use the "return channel", we keep it small...
setsockopt(sockets[0], SOL_SOCKET, SO_SNDBUF, &size, sizeof(size));
setsockopt(sockets[1], SOL_SOCKET, SO_RCVBUF, &size, sizeof(size));
fcntl(sockets[0], F_SETFL, O_NONBLOCK);
fcntl(sockets[1], F_SETFL, O_NONBLOCK);
// 建立描述符和 socket 之间的关联
mReceiveFd.reset(sockets[0]);
mSendFd.reset(sockets[1]);
} else {
mReceiveFd.reset();
ALOGE("BitTube: pipe creation failed (%s)", strerror(errno));
}
}
BitTube 其实是一个 socketpair 套接字的封装,用于传递消息,Buffer 默认大小是 4KB,有两个文件描述符:mSendFd 和 mReceiverFd,其中 mSendFd 用于发送,mReceiverFd 用于接收。
socketpair 用于创建一对无名的、相互连接的 socket 进行进程间通信,如果成功,则返回 0,创建好的 socket 分别是 sv[0] 和 sv[1],失败则返回 -1,感兴趣的同学可自行查阅。
在 BitTube 的构造方法中,调用 init() 方法通过 socketpair() 函数创建一对儿带有指定发送和接收缓冲区大小的 socket。这对 socket可以用于全双工通信,每一个 socket 既可以读也可以写,并且读、写操作可以位于同一个进程,也可以分别位于不同的进程。但需要注意:如果往一个 socket ( 如 sv[0] ) 中写入后,再从该 socket 读时会阻塞,只能在另一个 socket 中 ( sv[1] ) 上读才能成功。
通过 mReceiveFd.reset(sockets[0]) 和 mSendFd.reset(sockets[1]) 建立文件描述符和 socket 之间的关联,当 VSync 到来时通过 mSendFd 文件描述符写入消息,与之对应的 app 应用端通过监听 mReceiveFd 文件描述符来接收消息。注意,此时的mReceiveFd 依然还在 SurfaceFlinger 进程,app 应用进程端要使用则需要传递进来,接下来看一下 mReceiveFd 文件描述符是怎么传递到应用进程端的?
5.3.3 应用层和 SurfaceFlinger 建立进程间通信的管道
初始化空 gui::BitTube 对象,std::make_unique
在 5.3.2 创建显示事件连接 的开始处,分析可知返回的 IDisplayEventConnection 是服务端的代理对象 BpDisplayEventConnection,查看 BpDisplayEventConnection # stealReceiveChannel() 方法,代码如下:
// xref:/frameworks/native/libs/gui/IDisplayEventConnection.cpp
class BpDisplayEventConnection : public SafeBpInterface<IDisplayEventConnection> {
public:
explicit BpDisplayEventConnection(const sp<IBinder>& impl)
: SafeBpInterface<IDisplayEventConnection>(impl, "BpDisplayEventConnection") {}
......
status_t stealReceiveChannel(gui::BitTube* outChannel) override {
// callRemote 对 remote()->transact 的封装,具体有兴趣的同学可自行查阅
return callRemote<decltype(
&IDisplayEventConnection::stealReceiveChannel)>(Tag::STEAL_RECEIVE_CHANNEL,
outChannel);
}
......
void requestNextVsync() override {
callRemoteAsync<decltype(&IDisplayEventConnection::requestNextVsync)>(
Tag::REQUEST_NEXT_VSYNC);
}
};
status_t BnDisplayEventConnection::onTransact(uint32_t code, const Parcel& data, Parcel* reply,
uint32_t flags) {
if (code < IBinder::FIRST_CALL_TRANSACTION || code > static_cast<uint32_t>(Tag::LAST)) {
return BBinder::onTransact(code, data, reply, flags);
}
auto tag = static_cast<Tag>(code);
switch (tag) {
case Tag::STEAL_RECEIVE_CHANNEL:
// 调用服务端的本地方法实现
return callLocal(data, reply, &IDisplayEventConnection::stealReceiveChannel);
case Tag::SET_VSYNC_RATE:
return callLocal(data, reply, &IDisplayEventConnection::setVsyncRate);
case Tag::REQUEST_NEXT_VSYNC:
return callLocalAsync(data, reply, &IDisplayEventConnection::requestNextVsync);
}
}
callRemote 是对 remote()->transact 的封装,具体有兴趣的同学可自行查阅,因此将调用到远端 SurfaceFlinger 进程中IDisplayEventConnection 在服务端的本地实现 BnDisplayEventConnection 的 onTransact() 方法,然后根据 Tag 为STEAL_RECEIVE_CHANNEL,即 Binder 中的 code,查找对应方法的,callLocal 调用服务端的本地方法实现,这里会调用到 BnDisplayEventConnection 的实现类 EventThreadConnection 的 stealReceiveChannel() 方法,跟进去查看:
// xref:/frameworks/native/services/surfaceflinger/Scheduler/EventThread.h
class EventThreadConnection : public BnDisplayEventConnection {
public:
EventThreadConnection(EventThread*, uid_t callingUid, ResyncCallback,
ISurfaceComposer::EventRegistrationFlags eventRegistration = {});
virtual ~EventThreadConnection();
virtual status_t postEvent(const DisplayEventReceiver::Event& event);
status_t stealReceiveChannel(gui::BitTube* outChannel) override;
status_t setVsyncRate(uint32_t rate) override;
void requestNextVsync() override; // asynchronous
// Called in response to requestNextVsync.
const ResyncCallback resyncCallback;
VSyncRequest vsyncRequest = VSyncRequest::None;
const uid_t mOwnerUid;
const ISurfaceComposer::EventRegistrationFlags mEventRegistration;
private:
virtual void onFirstRef();
EventThread* const mEventThread;
gui::BitTube mChannel;
std::vector<DisplayEventReceiver::Event> mPendingEvents;
};
// xref:/frameworks/native/services/surfaceflinger/Scheduler/EventThread.cpp
status_t EventThreadConnection::stealReceiveChannel(gui::BitTube* outChannel) {
outChannel->setReceiveFd(mChannel.moveReceiveFd());
outChannel->setSendFd(base::unique_fd(dup(mChannel.getSendFd())));
return NO_ERROR;
EventThreadConnection 的 stealReceiveChannel() 方法中,获取 mChannel 中保存的接收、发送文件描述符后将值赋值给应用端初始化的空 gui::BitTube 对象中,这里 mChannel 即在 5.3.2 创建显示事件连接 的最后创建的 gui::BitTube 对象。
至此分析完毕 DisplayEventReceiver 的构建流程,结合代码总结如下:
- 获取 SurfaceFlinger 的 Bp 端对象 BpSurfaceComposer,以便与 SurfaceFlinger 进行 Binder 跨进程通信。
- 获取 IDisplayEventConnection 的 Bp 端对象 BpDisplayEventConnection,在 SurfaceFlinger 进程的服务端中创建 EventThread::EventThreadConnection 时创建 gui::BitTube 对象,在 gui::BitTube 的 init() 函数初始化中通过 socketpair 创建一对 socket,并建立 mReceiveFd,mSendFd 两个文件描述符和 socket 的关联,以便在监听 mReceiveFd 时能够收到 mSendFd 写入的消息。
- 在 app 应用进程端创建一个空的 gui::BitTube 对象,通过 EventThreadConnection::stealReceiveChannel() 方法将 app 应用进程端的 gui::BitTube 传递到 SurfaceFlinger 进程中,目的是将 SurfaceFlinger 进程中 gui::BitTube 对象的 mReceiveFd 和 mSendFd 这两个文件描述符传递到 app 应用进程端的 gui::BitTube 对象中,以此完成双向通道的建立。
5.4 NativeDisplayEventReceiver 初始化
分析完 NativeDisplayEventReceiver 的构建过程,接下来分析其 initialize() 方法,由于 NativeDisplayEventReceiver 本身没有该方法,所以去查看其继承的 DisplayEventDispatcher 类,代码如下:
// xref:/frameworks/native/libs/gui/DisplayEventDispatcher.cpp
status_t DisplayEventDispatcher::initialize() {
// 检查 DisplayEventReceiver 的 mDataChannel 是否为空
status_t result = mReceiver.initCheck();
if (result) {
ALOGW("Failed to initialize display event receiver, status=%d", result);
return result;
}
// 判断 mLooper 是否为空
if (mLooper != nullptr) {
// Looper 中添加文件描述符,this 是一个回调、是当前 DisplayEventDispatcher
// Looper::EVENT_INPUT 标识输入事件
int rc = mLooper->addFd(mReceiver.getFd(), 0, Looper::EVENT_INPUT, this, NULL);
if (rc < 0) {
return UNKNOWN_ERROR;
}
}
return OK;
}
// xref:/frameworks/native/libs/gui/DisplayEventReceiver.cpp
status_t DisplayEventReceiver::initCheck() const {
if (mDataChannel != nullptr)
return NO_ERROR;
return NO_INIT;
}
int DisplayEventReceiver::getFd() const {
if (mDataChannel == nullptr)
return NO_INIT;
return mDataChannel->getFd();
}
// xref:/frameworks/native/libs/sensor/BitTube.cpp
int BitTube::getFd() const
{
return mReceiveFd;
}
执行流程如下:
- 检查 DisplayEventReceiver 中的 mDataChannel 是否为空,从前面的分析可知 mDataChannel 的类型为 gui::BitTube。
- 判断 mLooper 是否为空,如不为空,则调用 Looper 的 addFd() 方法将 DisplayEventReceiver 中的 mDataChannel 的 mReceiveFd 加入到 mLooper 中,同时设置回调方法,用于监测事件。注意: addFd() 方法中第四个 this 是一个 LooperCallback 回调、这里传入当前 DisplayEventDispatcher,因为 DisplayEventDispatcher 继承 LooperCallback,当 mReceiveFd 有可读事件时将触发回调。
// xref:/system/core/libutils/Looper.cpp
int Looper::addFd(int fd, int ident, int events, Looper_callbackFunc callback, void* data) {
return addFd(fd, ident, events, callback ? new SimpleLooperCallback(callback) : nullptr, data);
}
int Looper::addFd(int fd, int ident, int events, const sp<LooperCallback>& callback, void* data) {
if (!callback.get()) {
......
} else {
ident = POLL_CALLBACK;
}
{ // acquire lock
AutoMutex _l(mLock);
Request request; // 创建一个 Request 实例对象
request.fd = fd; // 保存 fd
request.ident = ident; // 保存标识
request.events = events; // 保存事件
request.seq = mNextRequestSeq++;
request.callback = callback; // 保存回调 callback
request.data = data; // 保存自定义数据
if (mNextRequestSeq == -1) mNextRequestSeq = 0; // reserve sequence number -1
struct epoll_event eventItem;
request.initEventItem(&eventItem);
// 获取 requestIndex 判断该 Request 是否已经存在,mRequests 以 fd 作为 key 值
ssize_t requestIndex = mRequests.indexOfKey(fd);
if (requestIndex < 0) {
// 如果是新的文件描述符,则需要为 epoll 增加该 fd
int epollResult = epoll_ctl(mEpollFd.get(), EPOLL_CTL_ADD, fd, &eventItem);
......
// 保存 Request 到 mRequests 键值数组中
mRequests.add(fd, request);
} else {
int epollResult = epoll_ctl(mEpollFd.get(), EPOLL_CTL_MOD, fd, &eventItem);
if (epollResult < 0) {
if (errno == ENOENT) {
//如果之前已经添加过,那么就修改该监听文件描述符的一些信息
epollResult = epoll_ctl(mEpollFd.get(), EPOLL_CTL_ADD, fd, &eventItem);
......
scheduleEpollRebuildLocked();
} else {
ALOGE("Error modifying epoll events for fd %d: %s", fd, strerror(errno));
return -1;
}
}
mRequests.replaceValueAt(requestIndex, request);
}
} // release lock
return 1;
}
执行流程如下:
- 将要监测的文件描述符 fd、事件标识 events、回调函数指针 callback、一些额外参数 data 封装成一个 Request 对象。
- 调用 epoll_ctl 对文件描述符 fd 进行监测。
- 把 Request 对象添加到 mRequests 列表,其类型为:KeyedVector
6 Native 层 VSync 调度
分析完 Native 层 NativeDisplayEventReceiver 构建以及初始化,回头看 4.3 Choreographer # scheduleVsyncLocked() 的分析可知,流程走到 DisplayEventReceiver 的 scheduleVsync() 方法,代码如下:
// 在下一个显示帧开始时调度发送单个垂直同步脉冲
@UnsupportedAppUsage
public void scheduleVsync() {
if (mReceiverPtr == 0) {
Log.w(TAG, "Attempted to schedule a vertical sync pulse but the display event "
+ "receiver has already been disposed.");
} else {
nativeScheduleVsync(mReceiverPtr);
}
}
在该方法中,由于之前一节 Native 层的 nativeInit() 方法调用后已经构建并初始化 NativeDisplayEventReceiver,并返回给 Java 层指针值赋值给 mReceiverPtr,因此这里逻辑走到 nativeScheduleVsync() 方法并传入 mReceiverPtr 指针值。通过 JNI 调用 Native 层的方法,代码如下:
// xref:/frameworks/base/core/jni/android_view_DisplayEventReceiver.cpp
static void nativeScheduleVsync(JNIEnv* env, jclass clazz, jlong receiverPtr) {
sp<NativeDisplayEventReceiver> receiver =
reinterpret_cast<NativeDisplayEventReceiver*>(receiverPtr);
status_t status = receiver->scheduleVsync();
if (status) {
String8 message;
message.appendFormat("Failed to schedule next vertical sync pulse. status=%d", status);
jniThrowRuntimeException(env, message.string());
}
}
由 Java 层传递的 receiverPtr 指针值,通过 reinterpret_cast() 将其转为 Native 层创建的 NativeDisplayEventReceiver 对象,然后调用其 scheduleVsync() 方法。
6.1 DisplayEventDispatcher 调度 VSync
通过之前分析可知,NativeDisplayEventReceiver 继承自 DisplayEventDispatcher,查看其 scheduleVsync() 方法,代码如下:
// xref:/frameworks/native/libs/gui/DisplayEventDispatcher.cpp
status_t DisplayEventDispatcher::scheduleVsync() {
// 如果当前正在等待 VSync 信号,则直接返回,避免短时间内重复请求
if (!mWaitingForVsync) {
ALOGV("dispatcher %p ~ Scheduling vsync.", this);
// Drain all pending events.
nsecs_t vsyncTimestamp; // VSync 信号时间戳
PhysicalDisplayId vsyncDisplayId;
uint32_t vsyncCount;
VsyncEventData vsyncEventData;
// 处理挂起事件
if (processPendingEvents(&vsyncTimestamp, &vsyncDisplayId, &vsyncCount, &vsyncEventData)) {
ALOGE("dispatcher %p ~ last event processed while scheduling was for %" PRId64 "", this,
ns2ms(static_cast<nsecs_t>(vsyncTimestamp)));
}
// DisplayEventReceiver 请求下一个 VSync 信号
status_t status = mReceiver.requestNextVsync();
if (status) {
ALOGW("Failed to request next vsync, status=%d", status);
return status;
}
// 正在等待 VSync 信号标志位置为 true
mWaitingForVsync = true;
}
return OK;
}
执行流程如下:
- 处理挂起事件,内部根据具体事件类型分别处理。
- 通过 DisplayEventReceiver 请求下一个 VSync 信号。
6.1.1 DisplayEventDispatcher 处理挂起事件
// xref:/frameworks/native/libs/gui/DisplayEventDispatcher.cpp
// 每次从 DisplayEventDispatcher 管道读取的事件数。该值应足够大,以便我们只需几次较大读取即可快速读取完
static const size_t EVENT_BUFFER_SIZE = 100;
bool DisplayEventDispatcher::processPendingEvents(nsecs_t* outTimestamp,
PhysicalDisplayId* outDisplayId,
uint32_t* outCount,
VsyncEventData* outVsyncEventData) {
bool gotVsync = false;
DisplayEventReceiver::Event buf[EVENT_BUFFER_SIZE];
ssize_t n;
while ((n = mReceiver.getEvents(buf, EVENT_BUFFER_SIZE)) > 0) {
ALOGV("dispatcher %p ~ Read %d events.", this, int(n));
mFrameRateOverrides.reserve(n);
for (ssize_t i = 0; i < n; i++) {
const DisplayEventReceiver::Event& ev = buf[i];
switch (ev.header.type) {
case DisplayEventReceiver::DISPLAY_EVENT_VSYNC:
gotVsync = true; // 获取到 VSync 信号则将 gotVsync 标志位置为 true
// 因为是循环遍历 buf 中所有的 VSync,后来的 VSync 事件会覆盖之前事件的信息,只关心最近到来的 VSync 事件,
// 只会保存最新的那个 VSync 的 timestamp,displayId,count 等信息全部保存下来,
*outTimestamp = ev.header.timestamp;
*outDisplayId = ev.header.displayId;
*outCount = ev.vsync.count;
outVsyncEventData->id = ev.vsync.vsyncId;
outVsyncEventData->deadlineTimestamp = ev.vsync.deadlineTimestamp;
outVsyncEventData->frameInterval = ev.vsync.frameInterval;
break;
......
}
}
}
if (n < 0) {
ALOGW("Failed to get events from display event dispatcher, status=%d", status_t(n));
}
return gotVsync;
}
// xref:/frameworks/native/libs/gui/DisplayEventReceiver.cpp
ssize_t DisplayEventReceiver::getEvents(DisplayEventReceiver::Event* events,
size_t count) {
return DisplayEventReceiver::getEvents(mDataChannel.get(), events, count);
}
ssize_t DisplayEventReceiver::getEvents(gui::BitTube* dataChannel,
Event* events, size_t count)
{
return gui::BitTube::recvObjects(dataChannel, events, count);
}
// xref:/frameworks/native/libs/gui/include/private/gui/BitTube.h
// 发送对象,保证写入所有对象,否则调用失败
template <typename T> // 头文件中定义的类型模版
static ssize_t recvObjects(BitTube* tube, T* events, size_t count) {
return recvObjects(tube, events, count, sizeof(T));
}
// xref:/frameworks/native/libs/gui/BitTube.cpp
ssize_t BitTube::recvObjects(BitTube* tube, void* events, size_t count, size_t objSize) {
char* vaddr = reinterpret_cast<char*>(events);
// 调用 BitTube 的 read() 方法来读取数据
ssize_t size = tube->read(vaddr, count * objSize);
......
return size < 0 ? size : size / static_cast<ssize_t>(objSize);
}
ssize_t BitTube::read(void* vaddr, size_t size) {
ssize_t err, len;
do {
// 通过文件描述符 mReceiveFd 关联的 socket 管道从 vaddr 指定的缓冲区中
// 读取出 size 大小长度的数据,并返回实际发送的数据大小:len
len = ::recv(mReceiveFd, vaddr, size, MSG_DONTWAIT);
err = len < 0 ? errno : 0;
} while (err == EINTR);
if (err == EAGAIN || err == EWOULDBLOCK) {
// EAGAIN 表示有非阻塞输入/输出,但没有要读取的数据
return 0;
}
return err == 0 ? len : -err;
}
执行流程如下:
- 构建 DisplayEventReceiver::Event 类型的事件缓冲数组,大小为 EVENT_BUFFER_SIZE,用来接收缓冲数据流。
- 通过 DisplayEventReceiver 的 getEvents() 方法,读取管道内的数据流并缓存到 buf 数组中,同时返回实际接收到的数据流的长度,具体流程代码注释有分析。
- 遍历事件缓冲数组,获取数组中的 Event,根据事件类型分别交给指定的类来处理,如通过 JNI 调用交给 Java 层 DisplayEventReceiver 对应的方法来处理等。
Socket 套接字的 recv() 函数:int recv (SOCKET s, const char FAR * buf, int len, int flags); 第一个参数指定接收端套接字描述符,第二个参数指明一个缓冲区用来存放接收到的缓存数据,第三个参数指定 buf 缓存数据的长度,第四个参数一般置 0。
6.1.2 DisplayEventReceiver 请求 VSync 信号
// xref:/frameworks/native/libs/gui/DisplayEventReceiver.cpp
status_t DisplayEventReceiver::requestNextVsync() {
if (mEventConnection != nullptr) {
mEventConnection->requestNextVsync();
return NO_ERROR;
}
return NO_INIT;
}
mEventConnection 类型为 IDisplayEventConnection,在 NativeDisplayEventReceiver::nativeInit() 过程中通过 SurfaceFlinger 进程中的服务端创建并返回,在应用进程端其实现类为 BpDisplayEventConnection,并最终通过 Binder 跨进程调到 SurfaceFlinger 进程中 BnDisplayEventConnection 的实现类 EventThreadConnection 的 requestNextVsync() 方法,参考 5.3.3 应用层和 SurfaceFlinger 建立进程间通信的管道 的代码及解析。
// xref:/frameworks/native/services/surfaceflinger/Scheduler/EventThread.cpp
void EventThreadConnection::requestNextVsync() {
ATRACE_NAME("requestNextVsync");
// 调用 EventThread 的 requestNextVsync() 请求 VSync 信号
mEventThread->requestNextVsync(this);
}
继续调用 EventThread 的 requestNextVsync() 请求 VSync 信号,注意:当前处于 SurfaceFlinger 进程中,继续跟踪代码:
// xref:/frameworks/native/services/surfaceflinger/Scheduler/EventThread.h
enum class VSyncRequest {
None = -2, // 初始值
Single = -1, // 接下来的两帧中单独唤醒,以避免调度程序开销太大
SingleSuppressCallback = 0, // 下一帧只唤醒 SingleSuppressCallback
Periodic = 1, // 后续请求的是周期性信号
};
class EventThreadConnection : public BnDisplayEventConnection {
......
// Called in response to requestNextVsync.
const ResyncCallback resyncCallback;
VSyncRequest vsyncRequest = VSyncRequest::None;
const uid_t mOwnerUid;
const ISurfaceComposer::EventRegistrationFlags mEventRegistration;
private:
virtual void onFirstRef();
EventThread* const mEventThread;
gui::BitTube mChannel;
std::vector<DisplayEventReceiver::Event> mPendingEvents;
};
// xref:/frameworks/native/services/surfaceflinger/Scheduler/EventThread.cpp
void EventThread::requestNextVsync(const sp<EventThreadConnection>& connection) {
if (connection->resyncCallback) {
connection->resyncCallback();
}
std::lock_guard<std::mutex> lock(mMutex);
// vsyncRequest 默认值是 VSyncRequest::None,定义在 EventThread.h 文件
if (connection->vsyncRequest == VSyncRequest::None) {
// 当前是 None 时,将这个字段置为 Single
connection->vsyncRequest = VSyncRequest::Single;
// 唤醒所有等待的 EventThread 线程
mCondition.notify_all();
} else if (connection->vsyncRequest == VSyncRequest::SingleSuppressCallback) {
// 当前是 SingleSuppressCallback 时,将这个字段置为 Single
connection->vsyncRequest = VSyncRequest::Single;
}
}
回看上面的分析,通过 Scheduler 的 createDisplayEventConnection() 方法创建显示事件连接 EventThreadConnection 时,会将一段代码封装成 ResyncCallback,上面章节有介绍,这里 connection->resyncCallback 不为空,接着调用 resyncCallback() 函数,也即调用封装起来的代码回调,其作用是判断是否需要忽略延迟、时钟周期是否大于 0 等,决定是否重设 VSync 的时钟周期。
继续往下分析,VSyncRequest 定义在 EventThread.h 头文件中代表了当前 VSync 请求的状态:None 为初始值表示当前没有 VSync 请求、Single 表示这是一次性 VSync 请求(请求一次,接收一次)、SingleSuppressCallback 表示下一帧只唤醒 SingleSuppressCallback 类型,不会唤醒所有等待的线程、Periodic 表示这是周期性 VSync 请求(请求一次可以一直接收)。
当前 EventThreadConnection 的 VSyncRequest 类型为 None 时,则将其 VSyncRequest 类型设置为 Single(后续再有 VSync 请求则进不来该方法),然后唤醒所有等待的 EventThread 线程。
6.2 EventThread 构建
在前面的分析中,调用 SurfaceFlinger 的 init() 函数初始化时,流程会调用 EventThread 的构造函数构建管理 VSync 的 EventThread,跟踪看一下 EventThread 的构造函数,代码如下:
// xref:/frameworks/native/services/surfaceflinger/Scheduler/EventThread.h
class EventThread : public android::EventThread, private VSyncSource::Callback {
EventThread(std::unique_ptr<VSyncSource>, frametimeline::TokenManager*, InterceptVSyncsCallback,
ThrottleVsyncCallback, GetVsyncPeriodFunction);
......
void requestNextVsync(const sp<EventThreadConnection>& connection) override;
......
private:
......
using DisplayEventConsumers = std::vector<sp<EventThreadConnection>>;
void threadMain(std::unique_lock<std::mutex>& lock) REQUIRES(mMutex);
......
void dispatchEvent(const DisplayEventReceiver::Event& event,
const DisplayEventConsumers& consumers) REQUIRES(mMutex);
// Implements VSyncSource::Callback
void onVSyncEvent(nsecs_t timestamp, nsecs_t expectedVSyncTimestamp,
nsecs_t deadlineTimestamp) override;
std::thread mThread;
mutable std::condition_variable mCondition;
std::vector<wp<EventThreadConnection>> mDisplayEventConnections GUARDED_BY(mMutex);
std::deque<DisplayEventReceiver::Event> mPendingEvents GUARDED_BY(mMutex);
struct VSyncState { // 连接显示器的 VSync 状态
explicit VSyncState(PhysicalDisplayId displayId) : displayId(displayId) {}
const PhysicalDisplayId displayId;
// 显示器连接后,连接的 VSync 事件数
uint32_t count = 0;
// 熄屏时值为 true,亮屏时值为 false
bool synthetic = false;
};
std::optional<VSyncState> mVSyncState GUARDED_BY(mMutex);
// State machine for event loop.
enum class State {
Idle,
Quit,
SyntheticVSync,
VSync,
};
State mState GUARDED_BY(mMutex) = State::Idle;
};
// xref:/frameworks/native/services/surfaceflinger/Scheduler/EventThread.cpp
EventThread::EventThread(std::unique_ptr<VSyncSource> vsyncSource,
android::frametimeline::TokenManager* tokenManager,
InterceptVSyncsCallback interceptVSyncsCallback,
ThrottleVsyncCallback throttleVsyncCallback,
GetVsyncPeriodFunction getVsyncPeriodFunction)
: mVSyncSource(std::move(vsyncSource)),
mTokenManager(tokenManager),
mInterceptVSyncsCallback(std::move(interceptVSyncsCallback)),
mThrottleVsyncCallback(std::move(throttleVsyncCallback)),
mGetVsyncPeriodFunction(std::move(getVsyncPeriodFunction)),
mThreadName(mVSyncSource->getName()) {
......
// 将自己作为回调设置到 VSyncSource
mVSyncSource->setCallback(this);
// 创建 Thread 赋值给 mThread,定义在头文件中
mThread = std::thread([this]() NO_THREAD_SAFETY_ANALYSIS {
std::unique_lock<std::mutex> lock(mMutex);
// 调用 threadMain 函数
threadMain(lock);
});
pthread_setname_np(mThread.native_handle(), mThreadName);
pid_t tid = pthread_gettid_np(mThread.native_handle());
......
}
EventThread 继承 VSyncSource::Callback,调用其构造函数构建 EventThread 时,通过 VSyncSource 实例对象的 setCallback() 方法将 EventThread 自己作为回调设置给 VSyncSource,因此当有新的 VSync 信号到来并唤醒等待的 EventThread 线程时,VSync 事件会回调到 EventThread 实现的父类 VSyncSource::Callback 的 onVSyncEvent() 回调方法中。
EventThread 构造函数中创建了一个线程,线程启动并调用 threadMain() 函数,继续跟进代码看一下:
// xref:/frameworks/native/services/surfaceflinger/Scheduler/EventThread.cpp
void EventThread::threadMain(std::unique_lock<std::mutex>& lock) {
// consumers 表示即将消费事件的 connection 集合
DisplayEventConsumers consumers;
// 状态值不等于 State::Quit 则一直循环遍历,死循环
while (mState != State::Quit) {
std::optional<DisplayEventReceiver::Event> event;
// 确定下一个要调度的 Event
if (!mPendingEvents.empty()) {
event = mPendingEvents.front(); // 获取头部 Event
mPendingEvents.pop_front(); // 将头部 Event 弹出
// 根据 Event 类型分别对应处理
switch (event->header.type) {
case DisplayEventReceiver::DISPLAY_EVENT_HOTPLUG:
......
case DisplayEventReceiver::DISPLAY_EVENT_VSYNC:
// Event 类型为 DISPLAY_EVENT_VSYNC 即 VSync 信号
if (mInterceptVSyncsCallback) {
// mInterceptVSyncsCallback 不为空则执行 VSync 回调,传入事件的时间戳
mInterceptVSyncsCallback(event->header.timestamp);
}
break;
}
}
// 标志位:是否有 VSync 请求,默认 false
bool vsyncRequested = false;
// 循环遍历存储 EventThreadConnection 的 vector 容器 mDisplayEventConnections,查找要消费事件的连接
// begin()函数用于返回指向向量容器的第一个元素的迭代器
auto it = mDisplayEventConnections.begin();
while (it != mDisplayEventConnections.end()) {
if (const auto connection = it->promote()) { // promote 下面引用有介绍
// 如果有一个 connection 的 vsyncRequest 不为 None 则 vsyncRequested 为 true
vsyncRequested |= connection->vsyncRequest != VSyncRequest::None;
// event 不为空且 shouldConsumeEvent() 返回 true 则将 connection 加入到 consumers 等待消费 event
// shouldConsumeEvent() 方法作用:对于 VSync 类型的事件,只要 VSyncRequest 的类型不是 None 就返回 true
if (event && shouldConsumeEvent(*event, connection)) {
consumers.push_back(connection);
}
++it;
} else {
// 获取不到 connection 则从 mDisplayEventConnections 移除
it = mDisplayEventConnections.erase(it);
}
}
// consumers 不为空即当前 Event 有 EventThreadConnection 来消费
if (!consumers.empty()) {
// 调用 dispatchEvent() 方法遍历 consumers 为其每个 EventThreadConnection 分发事件
dispatchEvent(*event, consumers);
// 分发完清空
consumers.clear();
}
State nextState;
if (mVSyncState && vsyncRequested) { // 有 VSync 请求
// mVSyncState 声明在 EventThread.h 头文件中,通过其 synthetic 判断 nextState 是 SyntheticVSync 还是 VSync
// 屏幕亮屏时 synthetic 为 false,打开硬件 VSync,分发 VSync,熄屏时为 true,关闭硬件 VSync,停止分发 VSync
nextState = mVSyncState->synthetic ? State::SyntheticVSync : State::VSync;
} else {
ALOGW_IF(!mVSyncState, "Ignoring VSYNC request while display is disconnected");
// 显示器熄屏或没有连接、忽略 VSync 请求
nextState = State::Idle;
}
// mState 值默认为 State::Idle,与 nextState 不一致,则分情况讨论
if (mState != nextState) {
if (mState == State::VSync) {
// 当前状态为 State::VSync,则调用 mVSyncSource 的 setVSyncEnabled 并传入 false
mVSyncSource->setVSyncEnabled(false);
} else if (nextState == State::VSync) {
// nextState 状态为 State::VSync,则调用 mVSyncSource 的 setVSyncEnabled 并传入 true
mVSyncSource->setVSyncEnabled(true);
}
mState = nextState;
}
if (event) { // 还有事件则继续循环遍历
continue;
}
// 没有事件且当前状态为:State::Idle,则线程继续等待事件或客户端注册/请求
if (mState == State::Idle) {
mCondition.wait(lock);
} else {
// 如果没有事件并且当前状态不为空闲,为防止驱动程序停止,这种情况是硬件不知什么
// 原因没有发送 VSync 上来需要伪造 VSync 信号,频率为熄屏时 16ms,亮屏时 1000ms
const std::chrono::nanoseconds timeout =
mState == State::SyntheticVSync ? 16ms : 1000ms;
if (mCondition.wait_for(lock, timeout) == std::cv_status::timeout) {
......
// 将伪造的 VSync 放入 mPendingEvents 准备分发
mPendingEvents.push_back(makeVSync(mVSyncState->displayId, now,
++mVSyncState->count, expectedVSyncTime,
deadlineTimestamp, vsyncId));
}
}
}
}
promote() 是 wp 的一个函数,调用 attemptIncStrong ,返回一个对象的强引用。即通过 promote() 函数将弱引用变为强引用,强引用数+1,弱引用数+1。因为通过弱指针 wp,不能获取实际的对象,wp 并没有提供 sp 那样的存取操作 * 和 -> 的重载,由弱生强后,可以 sp 获取实际的对象。
threadMain() 函数比较长,结合注释总结一下执行流程:
- 声明消费 Event 的 EventThreadConnection 向量集合 consumers,开启死循环,如状态值不等于 State::Quit 则一直循环来处理 Event。
- 遍历双端队列 mPendingEvents,取出并确定下一个要调度的 Event。
- 遍历存储 EventThreadConnection 的 vector 容器 mDisplayEventConnections,查找消费事件的连接,并将符合条件的 EventThreadConnection 添加到 consumers 中。
- 调用 dispatchEvent(*event, consumers) 方法遍历 consumers 为其每个 EventThreadConnection 分发事件。
- 没有事件且当前线程状态为:State::Idle,则线程继续等待事件或客户端注册、请求,如果没有事件且线程状态不为:State::Idle 时则需要伪造 VSync 发送给请求者,防止驱动程序停止。
有同学会问 mPendingEvents 这个队列中的 Event 是哪里来的?
回答这个问题,首先得弄清楚 VSync 信号是哪里来的?VSync 信号是由 HWC 硬件模块根据屏幕刷新率(60Hz)产生。HWC 产生硬件 VSync 信号后经由 VSyncReactor、VSyncDispatchTimerQueue 等类的包装处理,最后 VSync 事件会回调到 EventThread::onVSyncEvent() 方法中,该方法通过 makeVSync() 方法把事件封装成 Event 后存到 mPendingEvents 双端队列中,并唤醒 EventThread::threadMain() 进行下一步处理。
6.3 EventThread 分发事件
通过上面的分析可知,应用层请求 VSync 的过程是通过条件变量 mCondition 的 notify_all() 函数,唤醒 EventThread 的 threadMain() 函数中陷入等待的死循环,然后从双端队列 mPendingEvents 中获取事件,之后调用 EventThread 的 dispatchEvent() 函数分发 Event 给 consumers 中每个 EventThreadConnection 连接。
// xref:/frameworks/native/services/surfaceflinger/Scheduler/EventThread.cpp
void EventThread::dispatchEvent(const DisplayEventReceiver::Event& event,
const DisplayEventConsumers& consumers) {
// 循环获取 DisplayEventConsumers 中保存每个 EventThreadConnection
for (const auto& consumer : consumers) {
DisplayEventReceiver::Event copy = event;
if (event.header.type == DisplayEventReceiver::DISPLAY_EVENT_VSYNC) {
// 获取 VSync 信号周期即:帧间隔
copy.vsync.frameInterval = mGetVsyncPeriodFunction(consumer->mOwnerUid);
}
switch (consumer->postEvent(copy)) {
case NO_ERROR:
break;
case -EAGAIN:
ALOGW("Failed dispatching %s for %s", toString(event).c_str(),
toString(*consumer).c_str());
break;
default:
// Treat EPIPE and other errors as fatal.
removeDisplayEventConnectionLocked(consumer);
}
}
}
循环获取 DisplayEventConsumers 中保存每个 EventThreadConnection,并调用其 postEvent() 方法,继续查看代码:
// xref:/frameworks/native/services/surfaceflinger/Scheduler/EventThread.cpp
status_t EventThreadConnection::postEvent(const DisplayEventReceiver::Event& event) {
constexpr auto toStatus = [](ssize_t size) {
return size < 0 ? status_t(size) : status_t(NO_ERROR);
};
if (event.header.type == DisplayEventReceiver::DISPLAY_EVENT_FRAME_RATE_OVERRIDE ||
event.header.type == DisplayEventReceiver::DISPLAY_EVENT_FRAME_RATE_OVERRIDE_FLUSH) {
mPendingEvents.emplace_back(event);
if (event.header.type == DisplayEventReceiver::DISPLAY_EVENT_FRAME_RATE_OVERRIDE) {
return status_t(NO_ERROR);
}
auto size = DisplayEventReceiver::sendEvents(&mChannel, mPendingEvents.data(),
mPendingEvents.size());
mPendingEvents.clear();
return toStatus(size);
}
auto size = DisplayEventReceiver::sendEvents(&mChannel, &event, 1);
return toStatus(size);
}
调用 DisplayEventReceiver::sendEvents() 方法通过之前建立的 socket 管道发送事件信息,代码如下:
// xref:/frameworks/native/libs/gui/DisplayEventReceiver.cpp
ssize_t DisplayEventReceiver::sendEvents(gui::BitTube* dataChannel,
Event const* events, size_t count)
{
return gui::BitTube::sendObjects(dataChannel, events, count);
}
// xref:/frameworks/native/libs/gui/include/private/gui/BitTube.h
// 发送对象,保证写入所有对象,否则调用失败
template <typename T> // 头文件中定义的类型模版
static ssize_t sendObjects(BitTube* tube, T const* events, size_t count) {
return sendObjects(tube, events, count, sizeof(T));
}
// xref:/frameworks/native/libs/gui/BitTube.cpp
ssize_t BitTube::sendObjects(BitTube* tube, void const* events, size_t count, size_t objSize) {
const char* vaddr = reinterpret_cast<const char*>(events);
// 调用 BitTube 的 write() 方法来写入数据
ssize_t size = tube->write(vaddr, count * objSize);
......
return size < 0 ? size : size / static_cast<ssize_t>(objSize);
}
ssize_t BitTube::write(void const* vaddr, size_t size) {
ssize_t err, len;
do {
// 通过文件描述符 mSendFd 关联的 socket 管道将数据发送到 vaddr 指定的一段
// size 大小的缓冲区中,并返回实际发送的数据大小:len
len = ::send(mSendFd, vaddr, size, MSG_DONTWAIT | MSG_NOSIGNAL);
err = len < 0 ? errno : 0;
} while (err == EINTR);
return err == 0 ? len : -err;
}
文件描述符在形式上是一个非负整数。实际上,它是一个索引值,用来指向被打开的文件,所有执行 I/O 操作的系统调用都会通过文件描述符。在 Linux 系统中,把一切都看做是文件,当进程打开现有文件或创建新文件时,内核向进程返回一个文件描述符,文件描述符就是内核为了高效管理已被打开的文件所创建的索引。
Socket 套接字的 send() 函数:int send (SOCKET s, const char FAR * buf, int len, int flags); 第一个参数指定接收端套接字描述符,第二个参数指明一个缓冲区用来存放缓存数据,第三个参数指定 buf 缓存数据的长度,第四个参数一般置 0。
6.4 DisplayEventDispatcher 执行回调事件
通过上面小节的分析,SurfaceFlinger 进程中请求到 VSync 信号,并且封装成 Event 事件后回调给 EventThread 进行分发,EventThread 将数据通过文件描述符 mSendFd 关联的 socket 管道发送到一段指定大小的缓冲区中,现在应用进程端需要通过文件描述符 mReceiveFd 关联的 socket 管道从指定的缓冲区中读取出数据。现在来查看一下从哪里、怎么读取到数据的?
在 5.4 NativeDisplayEventReceiver 初始化 小节中,分析可知在初始化的时候将先前构建的文件描述符 mReceiveFd 添加到 mLooper 中,并调用 epoll_ctl 方法对文件描述符进行监测,那么 Looper 怎么检测到文件描述符 mReceiveFd 中有可能读事件的,答案是在 Looper 的 pollInner 方法中,代码如下:
// xref:/system/core/libutils/Looper.cpp
int Looper::pollInner(int timeoutMillis) {
......// 根据 Native Message 的信息计算此次需要等待的时间
// 定义一个 epoll_event 数组,接收管道内写入的 Event 数据
struct epoll_event eventItems[EPOLL_MAX_EVENTS];
// 等待管道内有感兴趣的事件或超时发生,epoll_wait函数的返回值有如下含义:
// eventCount 大于0表示所监听的句柄上有事件发生;等于0表示等待超时;小于0表示等待过程中发生了错误
int eventCount = epoll_wait(mEpollFd.get(), eventItems, EPOLL_MAX_EVENTS, timeoutMillis);
......// 省略检测判断
for (int i = 0; i < eventCount; i++) {
int fd = eventItems[i].data.fd;
uint32_t epollEvents = eventItems[i].events;
if (fd == mWakeEventFd.get()) {
// 消息队列的事件
} else {
// 在前面添加 fd 时是将 fd 封装成 Request 然后放入 mRequests
// 是一个 KeyedVector,其中存储 fd 和 对应的 Request 结构体
ssize_t requestIndex = mRequests.indexOfKey(fd);
if (requestIndex >= 0) {
int events = 0;
// 将 epoll 返回的事件转换成上层 Looper 使用的事件
if (epollEvents & EPOLLIN) events |= EVENT_INPUT;
......
// 每处理一个 Request,就相应构造一个 Response 放到队列中,等for循环结束后统一处理
pushResponse(events, mRequests.valueAt(requestIndex));
}
......
}
}
// 调用挂起的消息回调--即处理 Request 外,还处理 Native 层自己的 Message
// 在处理逻辑上,Native Message 的优先级高于监控 fd 的优先级
......
// 统一调用所有 Response 回调
for (size_t i = 0; i < mResponses.size(); i++) {
Response& response = mResponses.editItemAt(i);
if (response.request.ident == POLL_CALLBACK) {
int fd = response.request.fd;
int events = response.events;
void* data = response.request.data;
// 调用每一个 callback 的 handleEvent 方法,
// 注意,在函数返回之前,文件描述符可能会被回调关闭(甚至可能被重用)清除文件描述符时需谨慎
int callbackResult = response.request.callback->handleEvent(fd, events, data);
if (callbackResult == 0) {
// callback->handleEvent 的返回值很重要,如果返回0,将把fd移除,表明不需要再次监视该文件句柄
removeFd(fd, response.request.seq);
}
// 清除 Response 结构中的回调引用
response.request.callback.clear();
result = POLL_CALLBACK;
}
}
return result;
}
该方法中调用 epoll_wait 方法等待管道内有感兴趣的事件写入或超时发生,当 socket 管道的 mSendFd 端有数据写入时,就会把与之对应的 mReceiveFd 有关的 Request 取出并收集起来,待 Native 层的 Message 处理完后,循环遍历收集起来的 Request,取出每个 Request 并调用其 callback 回调的 handleEvent() 方法。该回调就是向 Looper 中添加 fd 时作为 LooperCallback 回调一并传入的 DisplayEventDispatcher 实现类,查看实现类的 handleEvent() 方法,代码如下:
// xref:/frameworks/native/libs/gui/DisplayEventDispatcher.cpp
int DisplayEventDispatcher::handleEvent(int, int events, void*) {
if (events & (Looper::EVENT_ERROR | Looper::EVENT_HANGUP)) {
......
// 管道关闭或者出现了错误,则移除回调
return 0; // remove the callback
}
if (!(events & Looper::EVENT_INPUT)) {
......
// 收到未处理轮询事件的伪造事件 Event(前面分析过为了防止驱动程序停止),则保留回调
return 1; // keep the callback
}
// 清空所有挂起的事件,只保留最近一次 VSync 事件
nsecs_t vsyncTimestamp;
PhysicalDisplayId vsyncDisplayId;
uint32_t vsyncCount;
VsyncEventData vsyncEventData;
if (processPendingEvents(&vsyncTimestamp, &vsyncDisplayId, &vsyncCount, &vsyncEventData)) {
ALOGV("dispatcher %p ~ Vsync pulse: timestamp=%" PRId64
", displayId=%s, count=%d, vsyncId=%" PRId64,
this, ns2ms(vsyncTimestamp), to_string(vsyncDisplayId).c_str(), vsyncCount,
vsyncEventData.id);
// 获取到最近的 VSync 信息,将正在等待 VSync 标志位置为 false
mWaitingForVsync = false;
// 参见[5.1] 由于 DisplayEventDispatcher 类没有复写 dispatchVsync 方法
// 在其子类 NativeDisplayEventReceiver 中复写了该方法
dispatchVsync(vsyncTimestamp, vsyncDisplayId, vsyncCount, vsyncEventData);
}
return 1; // keep the callback
}
执行流程如下:
- 参见 6.1.1 DisplayEventDispatcher 处理挂起事件,通过 processPendingEvents() 方法获取最近到来的 VSync 事件,并保存最近的那个 VSync 的 timestamp,displayId,count 等信息。
- 参见 5.1 NativeDisplayEventReceiver 类结构,由于 DisplayEventDispatcher 类没有复写 dispatchVsync() 方法,其子类 NativeDisplayEventReceiver 中复写了该方法,因此这里调用 NativeDisplayEventReceiver::dispatchVsync() 方法来分发 VSync 事件信息。
// xref:/frameworks/base/core/jni/android_view_DisplayEventReceiver.cpp
void NativeDisplayEventReceiver::dispatchVsync(nsecs_t timestamp, PhysicalDisplayId displayId,
uint32_t count, VsyncEventData vsyncEventData) {
// 获取 JNI 上下文环境
JNIEnv* env = AndroidRuntime::getJNIEnv();
ScopedLocalRef<jobject> receiverObj(env, jniGetReferent(env, mReceiverWeakGlobal));
if (receiverObj.get()) {
ALOGV("receiver %p ~ Invoking vsync handler.", this);
// 通过 JNI 方法调用,调用 Java 层 DisplayEventReceiver 的 dispatchVsync() 方法,
// 参数传入对应的时间戳、显示屏 Id、VSync 个数、帧间隔等信息
env->CallVoidMethod(receiverObj.get(), gDisplayEventReceiverClassInfo.dispatchVsync,
timestamp, displayId.value, count, vsyncEventData.id,
vsyncEventData.deadlineTimestamp, vsyncEventData.frameInterval);
ALOGV("receiver %p ~ Returned from vsync handler.", this);
}
mMessageQueue->raiseAndClearException(env, "dispatchVsync");
}
执行流程如下:
- 获取 JNI 上下文环境,参见 5.1 NativeDisplayEventReceiver 类结构,mReceiverWeakGlobal 是 Java 层的 DisplayEventReceiver 的弱引用对象转化得到的弱全局引用,因此这里是从之前转化的弱全局引用获取本地引用 DisplayEventReceiver。
- 通过 JNIEnv 调用 JNI 函数,这里调用的是 Java 层 DisplayEventReceiver 的 dispatchVsync() 方法。
JNIEnv 是一个指针,指向 Jvm 中保存的 JNI 函数表,通过 JNIEnv 可以调用 JNI 函数。
注意:JNIEnv 是线程私有的,每个线程有独自的 JNIEnv。
JNIEnv 调用 Java 方法,使用 env->CallVoidMethod(jobject,“获取指定的 java 方法”,“输入参数”); 即调用 Java 层 jobject 的指定方法。
6.5 DisplayEventReceiver 分发事件
public abstract class DisplayEventReceiver {
public void onVsync(long timestampNanos, long physicalDisplayId, int frame,
VsyncEventData vsyncEventData) {
}
// Called from native code.
@SuppressWarnings("unused")
private void dispatchVsync(long timestampNanos, long physicalDisplayId, int frame,
long frameTimelineVsyncId, long frameDeadline, long frameInterval) {
onVsync(timestampNanos, physicalDisplayId, frame,
new VsyncEventData(frameTimelineVsyncId, frameDeadline, frameInterval));
}
}
DisplayEventReceiver 是一个抽象类,onVsync() 方法是一个空方法,因此需要进入其实现类 FrameDisplayEventReceiver 中查看,代码参见 3.2 FrameDisplayEventReceiver 接收 VSync 脉冲信号,通过上面代码以及解析可知,接收到垂直同步脉冲时,会回调 FrameDisplayEventReceiver # run() 方法,在回调方法中调用 Choreographer # doFrame() 方法。
6.6 Choreographer 执行事件
public final class Choreographer {
// Set a limit to warn about skipped frames.
// Skipped frames imply jank.
private static final int SKIPPED_FRAME_WARNING_LIMIT = SystemProperties.getInt(
"debug.choreographer.skipwarning", 30);
......
void doFrame(long frameTimeNanos, int frame,
DisplayEventReceiver.VsyncEventData vsyncEventData) {
final long startNanos;
final long frameIntervalNanos = vsyncEventData.frameInterval; // 帧间隔
try {
......
synchronized (mLock) {
......
// 设置将要处理的当前帧的时间戳
long intendedFrameTimeNanos = frameTimeNanos;
startNanos = System.nanoTime(); // 记录实际开始执行当前 frame 的时间
final long jitterNanos = startNanos - frameTimeNanos; // 计算时间差值
if (jitterNanos >= frameIntervalNanos) { // 时间差值大于等于帧间隔,即发生了跳帧
final long skippedFrames = jitterNanos / frameIntervalNanos; // 计算跳帧数
// 跳帧超过 30 打印日志提醒,SKIPPED_FRAME_WARNING_LIMIT 通过读取
// 系统属性 debug.choreographer.skipwarning 来获取的,默认是 30
if (skippedFrames >= SKIPPED_FRAME_WARNING_LIMIT) {
Log.i(TAG, "Skipped " + skippedFrames + " frames! "
+ "The application may be doing too much work on its main thread.");
}
// 计算实际开始当前 frame 的时间戳与帧间隔的偏移值
final long lastFrameOffset = jitterNanos % frameIntervalNanos;
......
// 修正偏移值,下一帧的时间戳开始值要减去计算得出的偏移值
frameTimeNanos = startNanos - lastFrameOffset;
}
if (frameTimeNanos < mLastFrameTimeNanos) {
......
traceMessage("Frame time goes backward");
// 当前帧的时间小于上一个帧的时间,可能是由于先前跳帧的缘故,申请并等待下一次 VSync 信号到来
scheduleVsyncLocked();
return;
}
if (mFPSDivisor > 1) {
long timeSinceVsync = frameTimeNanos - mLastFrameTimeNanos;
if (timeSinceVsync < (frameIntervalNanos * mFPSDivisor) && timeSinceVsync > 0) {
traceMessage("Frame skipped due to FPSDivisor");
// 由于 FPSDivisor 导致跳帧,继续申请并等待下一次 VSync 信号到来
scheduleVsyncLocked();
return;
}
}
// 记录当前 Frame 信息
mFrameInfo.setVsync(intendedFrameTimeNanos, frameTimeNanos, vsyncEventData.id,
vsyncEventData.frameDeadline, startNanos, vsyncEventData.frameInterval);
// 收到 VSync 信号当前帧调度完,mFrameScheduled 标志位重置为 false,以便下一轮请求使用
mFrameScheduled = false;
mLastFrameTimeNanos = frameTimeNanos; // 记录上一次 Frame 渲染的时间
mLastFrameIntervalNanos = frameIntervalNanos; // 记录上一次 Frame 渲染的帧间隔
mLastVsyncEventData = vsyncEventData; // 记录上一次 VSync 事件信息
}
// 动画锁定为当前线程的固定值
AnimationUtils.lockAnimationClock(frameTimeNanos / TimeUtils.NANOS_PER_MS);
// 按照事件类型的优先级执行 CallBack
mFrameInfo.markInputHandlingStart();
// 输入事件,首先执行
doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos, frameIntervalNanos);
mFrameInfo.markAnimationsStart();
// 动画事件,在 CALLBACK_INSETS_ANIMATION 之前执行
doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos, frameIntervalNanos);
// 插入更新动画事件,INPUT 和 ANIMATION 后面执行,TRAVERSAL 之前执行
doCallbacks(Choreographer.CALLBACK_INSETS_ANIMATION, frameTimeNanos, frameIntervalNanos);
// 处理布局和绘制事件,在处理完上述异步消息之后运行
mFrameInfo.markPerformTraversalsStart();
doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos, frameIntervalNanos);
// 提交,和提交任务有关(在 API Level 23 添加),最后执⾏,遍历完成的提交操作,⽤来修正动画启动时间
doCallbacks(Choreographer.CALLBACK_COMMIT, frameTimeNanos, frameIntervalNanos);
} finally {
AnimationUtils.unlockAnimationClock();
Trace.traceEnd(Trace.TRACE_TAG_VIEW);
}
......
}
......
}
执行流程如下:
- 调整、更新数据后,记录当前帧、上一帧的数据信息,如果发生跳帧则申请并等待下一次 VSync 信号到来,然后返回。
- 没有发生跳帧,则按照事件类型的优先级执行 CallBack 回调,并传入上一步记录的当前帧的数据信息。
public final class Choreographer {
......
void doCallbacks(int callbackType, long frameTimeNanos, long frameIntervalNanos) {
CallbackRecord callbacks;
synchronized (mLock) {
// 获取正在运行的 Java 虚拟机的当前时间,单位为纳秒,以此来确定回调何时执行
// 因为帧中的前期处理阶段可能会发布应在下一阶段运行的回调,例如导致动画启动的输入事件
final long now = System.nanoTime();
// 从数组链表 mCallbackQueues 中获取指定类型的链表
callbacks = mCallbackQueues[callbackType].extractDueCallbacksLocked(
now / TimeUtils.NANOS_PER_MS);
if (callbacks == null) { // 没有查找到 callbackType 对应的链表,则直接返回
return;
}
mCallbacksRunning = true;
// 对于 CALLBACK_COMMIT 类型的事件要更新调整其执行时间、不过多讨论
if (callbackType == Choreographer.CALLBACK_COMMIT) {
......
}
}
try {
Trace.traceBegin(Trace.TRACE_TAG_VIEW, CALLBACK_TRACE_TITLES[callbackType]);
// 遍历 callbacks 链表获取 CallbackRecord 对象
for (CallbackRecord c = callbacks; c != null; c = c.next) {
......
// 执行 CallbackRecord 对象的 run() 方法
c.run(frameTimeNanos);
}
} finally {
synchronized (mLock) {
mCallbacksRunning = false;
// 回收 callbacks,置空其内部 CallbackRecord 保存的信息,重组并赋值给 mCallbackPool 链表
do {
final CallbackRecord next = callbacks.next;
recycleCallbackLocked(callbacks);
callbacks = next;
} while (callbacks != null);
}
Trace.traceEnd(Trace.TRACE_TAG_VIEW);
}
}
......
}
执行流程如下:
- 获取正在运行的 Java 虚拟机的当前时间,单位为纳秒,然后从数组链表 mCallbackQueues 中获取指定类型的链表 CallbackQueue,之后调用 CallbackQueue # extractDueCallbacksLocked() 方法并传入刚才获取到的时间,来确定链表 CallbackQueue 中是否有 CallbackRecord 的执行时间已经到了。参见 3.4 回调队列 CallBackQueue 中的图示和介绍。
- 遍历获取到的 callbacks 链表获取 CallbackRecord 对象,然后执行 CallbackRecord 对象的 run() 方法。
public final class Choreographer {
......
private static final class CallbackRecord {
public CallbackRecord next; // 链表的下一个节点
public long dueTime; // 执行时间
public Object action; // Runnable or FrameCallback
public Object token; // 标志
@UnsupportedAppUsage
public void run(long frameTimeNanos) {
// 根据 token 判断当前回调类型
if (token == FRAME_CALLBACK_TOKEN) {
// 通过 postFrameCallback() 或 postFrameCallbackDelayed() 会执行这里,暂时不分析
((FrameCallback)action).doFrame(frameTimeNanos);
} else {
// 取出 Runnable 并执行其 run() 方法
((Runnable)action).run();
}
}
}
......
}
CallbackRecord 的 run() 方法中,根据 token 判断当前回调类型,这里暂时不分析 FRAME_CALLBACK_TOKEN 类型的,只分析 Runnable 并执行其 run() 方法,在 1. 初探 Choreographer 的使用 中通过 Choreographer # postCallback() 方法提交一个任务 TraversalRunnable,将任务 TraversalRunnable 和执行时间一起被封装成 CallbackRecord,因此这里执行的就是 TraversalRunnable 的 run() 方法。
6.6 ViewRootImpl 渲染视图
public final class ViewRootImpl implements ViewParent,
View.AttachInfo.Callbacks, ThreadedRenderer.DrawCallbacks,
AttachedSurfaceControl {
......
final class TraversalRunnable implements Runnable {
@Override
public void run() {
doTraversal();
}
}
void doTraversal() {
if (mTraversalScheduled) {
// mTraversalScheduled 标志位重新置为 false
mTraversalScheduled = false;
// 通过调用 removeSyncBarrier 方法移除同步屏障消息,传入 postSyncBarrier() 方法的返回值作为参数
// 标识需要移除哪个屏障,然后将该屏障消息会从队列中移除,以确保消息队列恢复正常操作,否则应用程序可能会挂起
mHandler.getLooper().getQueue().removeSyncBarrier(mTraversalBarrier);
......
// 执行 View 的绘制流程开始渲染新页面
performTraversals();
......
}
}
......
}
执行流程如下:
- 当我们调用到 ViewRootImpl # scheduleTraversals() 方法请求刷新 View 时,将 mTraversalScheduled 标志位置为 true,防止短时间内重复调用,View 开始绘制渲染新页面之前恢复该标志位为 false,以便下一次刷新操作可以正常执行。
- 调用 MessageQueue # removeSyncBarrier() 方法移除同步屏障消息,传入 MessageQueue # postSyncBarrier() 方法添加任务时的返回值作为参数标识需要移除哪个屏障,然后将该屏障消息会从队列中移除,以确保消息队列恢复正常操作,否则应用程序可能会挂起。
- 执行 View 的绘制流程开始渲染新页面,流程分析参考 View # invalidate() 流程源码分析 和 View # requestLayout() 流程源码分析 这两篇文章。
三、总结
这篇超长文章终于要完结了,笔者能力有限,C++ 的理解还需进一步修炼,但笔者尽力将 Native 层的源码流程梳理通顺,以便读者理解的更透彻。本文总体偏干货,读着或许会有点吃力,但对于理解 Choreographer 应该会有很大帮助的,如有分析错误或者别的理解,还望留言或者私信笔者讨论,共同学习。