python读取word的方法,Python读取Word(.docx)正文信息的方法
Python读取Word(.docx)正文信息的方法
本文介绍用Python简单读取*.docx文件信息,一些python-word库就是对这种方法的扩展。
介绍分两部分:
Word(*.docx)文件简述
Python提取Word信息
Word(*.docx)文件简述
大约在2008年以前,Office产品中Word用.doc文件格式,这种二进制格式很难与其他软件兼容。
为了跟上时代,微软采用类XML格式标准定义其新版Word文件.docx。
.docx实际上是一个zip的压缩文件,比如我们有一个test.docx的文件:

其内容如下:
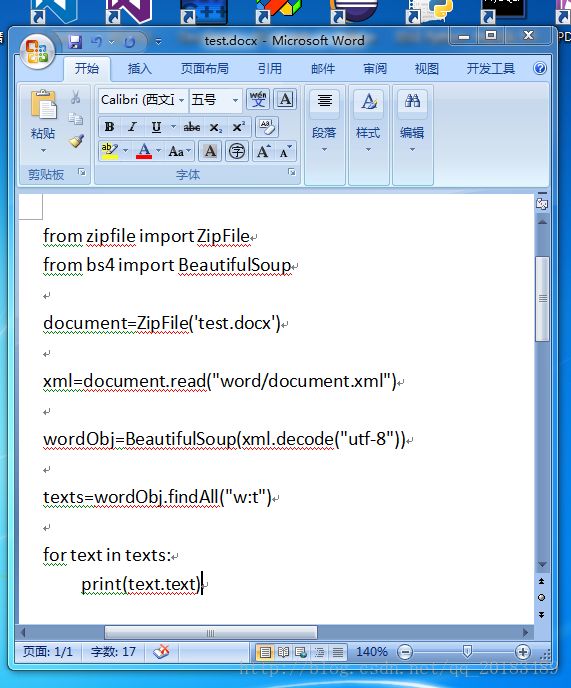
改变其后缀名为test.zip,然后解压,会得到如下文件:
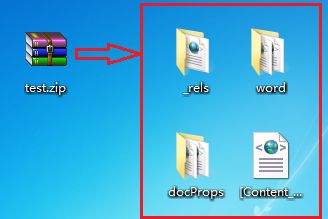
其中Word文件的正文内容被保持在word/document.xml中,我们可以打开查看:
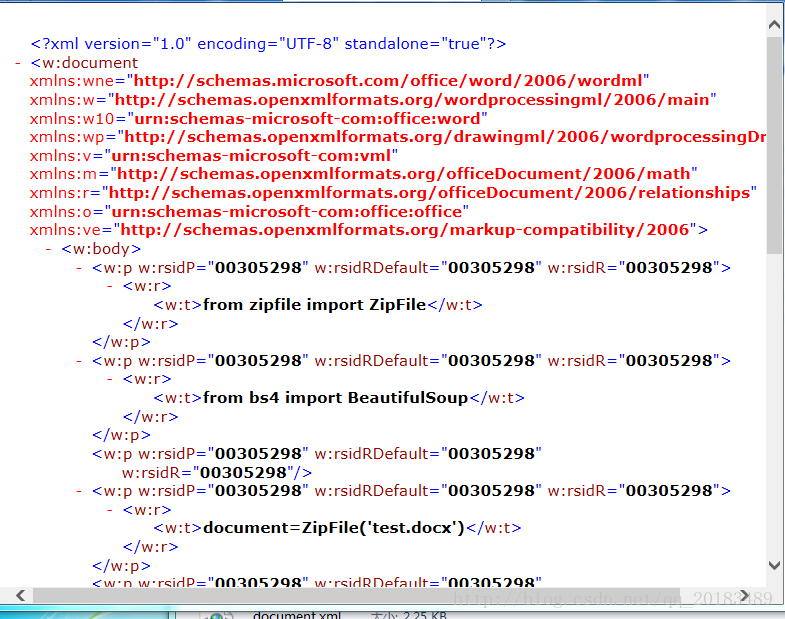
Python提取Word信息
根据Word(.docx)文件格式,我们遵循如下步骤进行正文信息的提取:
1 解压.docx文件
2 用BeautifulSoup解析word/document.xml提取正文信息
具体代码如下:
from zipfile import ZipFile
from bs4 import BeautifulSoup
document=ZipFile('test.docx')
xml=document.read("word/document.xml")
wordObj=BeautifulSoup(xml.decode("utf-8"))
texts=wordObj.findAll("w:t")
for text in texts:
print(text.text)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
您可能感兴趣的文章:
python读取word文档的方法
python实现在windows下操作word的方法
Python实现批量读取word中表格信息的方法
python启动办公软件进程(word、excel、ppt、以及wps的et、wps、wpp)
python批量提取word内信息
Python实现批量将word转html并将html内容发布至网站的方法
python的keyword模块用法实例分析
python实现登陆知乎获得个人收藏并保存为word文件
利用python程序生成word和PDF文档的方法
Python操作Word批量生成文章的方法
时间: 2018-03-14
单位收集了很多word格式的调查表,领导需要收集表单里的信息,我就把所有调查表放一个文件里,写了个python小程序把所需的信息打印出来 #coding:utf-8 import os import win32com from win32com.client import Dispatch, constants from docx import Document def parse_doc(f): """读取doc,返回姓名和行业 """ doc
本文实例讲述了Python实现批量将word转html并将html内容发布至网站的方法.分享给大家供大家参考.具体实现方法如下: #coding=utf-8 __author__ = 'zhm' from win32com import client as wc import os import time import random import MySQLdb import re def wordsToHtml(dir): #批量把文件夹的word文档转换成html文件 #金山WPS调用,抢先
复制代码 代码如下: #-*- coding:utf-8 -*- from win32com.client import Dispatch import time def start_office_application(app_name): # 在这里获取到app后,其它的操作和通过VBA操作办公软件类似 app = Dispatch(app_name) app.Visible = True time.sleep(0.5) app.Quit() if __name__ == '__main__
一.程序导出word文档的方法 将web/html内容导出为world文档,再java中有很多解决方案,比如使用Jacob.Apache POI.Java2Word.iText等各种方式,以及使用freemarker这样的模板引擎这样的方式.php中也有一些相应的方法,但在python中将web/html内容生成world文档的方法是很少的.其中最不好解决的就是如何将使用js代码异步获取填充的数据,图片导出到word文档中. 1. unoconv 功能: 1.支持将本地html文档转换为docx
这个程序其实很早之前就完成了,一直没有发出了,趁着最近不是很忙就分享给大家. 使用BeautifulSoup模块和urllib2模块实现,然后保存成word是使用python docx模块的,安装方式网上一搜一大堆,我就不再赘述了. 主要实现的功能是登陆知乎,然后将个人收藏的问题和答案获取到之后保存为word文档,以便没有网络的时候可以查阅.当然,答案中如果有图片的话也是可以获取到的.不过这块还是有点问题的.等以后有时间了在修改修改吧. 还有就是正则,用的简直不要太烂-鄙视下自己- 还有,现在是
本文实例讲述了Python实现批量读取word中表格信息的方法.分享给大家供大家参考.具体如下: 单位收集了很多word格式的调查表,领导需要收集表单里的信息,我就把所有调查表放一个文件里,写了个python小程序把所需的信息打印出来 #coding:utf-8 import os import win32com from win32com.client import Dispatch, constants from docx import Document def parse_doc(f):
本文实例讲述了python实现在windows下操作word的方法.分享给大家供大家参考.具体实现方法如下: import win32com from win32com.client import Dispatch, constants w = win32com.client.Dispatch('Word.Application') # 或者使用下面的方法,使用启动独立的进程: # w = win32com.client.DispatchEx('Word.Application') # 后台运行
本文实例讲述了python的keyword模块用法.分享给大家供大家参考.具体如下: Help on module keyword: NAME keyword - Keywords (from "graminit.c") FILE /usr/lib64/python2.6/keyword.py DESCRIPTION This file is automatically generated; please don't muck it up! To update the symbols

下面通过COM让Python与Word建立连接实现Python操作Word批量生成文章,具体介绍请看下文: 需要做一些会议记录.总共有多少呢?五个地点x7个月份x每月4篇=140篇.虽然不很重要,但是140篇记录完全雷同也不好.大体看了一下,此类的记录大致分为四段.于是决定每段提供四种选项,每段从四选项里随机选一项,拼凑成四段文字,存成一个文件.而且要打印出来,所以准备生成一个140页的Word文档,每页一篇. 需要用到win32com模块(下载链接: http://sourceforge.ne
本文实例讲述了python读取word文档的方法.分享给大家供大家参考.具体如下: 首先下载安装win32com from win32com import client as wc word = wc.Dispatch('Word.Application') doc = word.Documents.Open('c:/test') doc.SaveAs('c:/test.text', 2) doc.Close() word.Quit() 这种方式产生的text文档,不能用python用普通的r方
本文实例讲述了PHP读取word文档的方法.分享给大家供大家参考,具体如下: php开发 过程中可能会word文档的读取问题,这里可以利用com组件来完成此项操作 一.先开启php.ini的COM,操作如下 1. extension=php_com_dotnet.dll 2. com.allow_dcom = true 二.开启之后就可以试下如下操作 1.建立一个指向新COM组件的索引 $word = new COM("word.application") or die("C
在G:/PythonPractise文件夹下新建一个名为record.txt的文本文档,写入如下图所示四行内容并保存. 打开python3的idle,开始写代码. 方法一代码和运行结果如下: 如上面运行结果所示,上面的结果是省略end=的写法,等价于end="\n"(回车); 下面的结果是end=""(空字符串)的写法,等价于end="\r"(换行) 方法二代码和运行结果如下: 方法三代码结果如下: 比较三种方法,方法一先将该路径下的文件返回成一
表格内容如下: 1.实现批量导入word文档,取文档标题中的数字作为编号 2.除取上面打钩的内容需要匹配出来入库入库,其他内容全部直接入库mysql # wuyanfeng # -*- coding:utf-8 -*- # 读取docx中的文本代码示例 import docx import pymysql import re import os # 创建数据库链接 conn = pymysql.connect( host='rm-bp1vu5d84dg12c6d59o.mysql.rds.ali
第一种方法: 复制代码 代码如下: Response.ClearContent(); Response.ClearHeaders(); Response.ContentType = "Application/msword"; string s=Server.MapPath("C#语言参考.doc"); Response.WriteFile("C#语言参考.doc"); Response.Write(s); Response.Flush(); Re
目标 最近实验室里成立了一个计算机兴趣小组 倡议大家多把自己解决问题的经验记录并分享 就像在CSDN写博客一样 虽然刚刚起步 但考虑到后面此类经验记录的资料会越来越多 所以一开始就要做好模板设计(如下所示) 方便后面建立电子数据库 从而使得其他人可以迅速地搜索到相关记录 据说"人生苦短,我用python" 所以决定用python从docx文档中提取文件头的信息 然后把信息更新到一个xls电子表格中,像下面这样(直接po结果好了) 而且点击文件路径可以直接打开对应的文件(含超链接) 代码
一般文本文件 我们以日志文件.log文件为例: import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; public class File_Test { /** * @param args */ pub
Office办公软件,相信大家都已经很熟悉了.如何读取Word文档内容,相信大家也都知道.但是,笔者今天要说的是,易语言怎么读取Word文档内容呢? 1.首先,为了配合此次程序测试,我们事先准备好一个Word文件即Docx文件,为了使得软件能正确读取出其中内容,我们在Word文件中,输入"百度经验"作为测试标示.如图: 2.测试文件已就位,打开"易语言",在弹出的"新建工程文件"对话框中,选择"Windows窗口程序"并点击&
支持按照文件夹去批量处理,也可以单独一个文件进行处理,并且可以自定义标识符 最近在开发一个答题类的小程序,到了录入试题进行测试的时候了,发现一个问题,试题都是word文档格式的,每份有100题左右,拿到的第一份试题,光是段落数目就有800个.而且可能有几十份这样的试题. 而word文档是没有固定格式的,想批量录入关系型数据库mysql,必须先转成excel文档.这个如果是手动一个个粘贴到excel表格,那就头大了. 我最终需要的excel文档结构是这样的:每道题独立占1行,每1列是这道题的一项内
介绍 舍友从网上下载的word题库文档很乱,手动改了大半天才改了一点,想起python是大名鼎鼎的自动化脚本,于是乎开始了python对word的一顿瞎操作. 分析需求 对文档中的内容进行分析,只留下题目,选项,并且题号要从1开始. 编写代码 pip安装python-docx模块 读取word文档内容(如果是以.doc后缀的文件需另存为.docx文件!) from docx import Document # 打开文件 srcdocx = Document('src.docx') # 遍历所有段