HDFS HA 架构
HA背景
对于HDFS、YARN的每个角色都是一个进程,
比如HDFS:NN/SNN/DN 老大是NN
YARN:RM/NM 老大是RM
对于上面,都会存在单点故障的问题,假如老大NN或者RM挂了,那么就不能提供对外服务了,会导致整个集群都不能使用。
大数据几乎所有的组建都是主从架构(master-slave)。比如hdfs的读写请求都是先经过NN节点。(但是hbase的读写请求不是经过老大的master)。
hdfs:由NN/SNN/DN组成,SNN每小时会做一次checkpoint的操作,如果NN挂了,只能恢复到上次checkpoint的那一刻,不能实时。现在如果把SNN的角色再提升一个等级,让它和NN一样,如果NN挂了,SNN能立即切换过来就好了。
HDFS HA 架构 有两个NN节点,一个是active活跃状态,一个是standby准备状态,Active NameNode对外提供服务,比如处理来自客户端的RPC请求,而Standby NameNode则不对外提供服务,仅同步Active NameNode的状态,对Active NameNode进行实时备份,以便能够在它失败时快速进行切换。
HA介绍
HDFS High Availability (HA)
假定:
NN1 active ip1
NN2 standby ip2
假如说在我们代码或者shell脚本里,写了:hdfs dfs -ls hdfs://ip1:9000/ ,那么如果NN1挂了,NN2切换到active状态了,但是在脚本里还是ip1,这个时候不可能手动去修改。肯定有问题。那么该怎么解决?
用命名空间来解决。命名空间不是进程。比如:命名空间的名称为:RUOZEG6
脚本里可以这样写:hdfs dfs -ls hdfs://RUOZEG6/
当代码执行到这一行时,它会去core-site.xml、hdfs-site.xml里面查找。在这两个配置文件里面,配置了RUOZEG6命名空间下挂了NN1和NN2。当它找到NN1,它会尝试着连接第一个机器NN1,如果发现它不是active状态,它会尝试着连接第二个机器NN2,如果发现NN1是active状态,就直接用了。
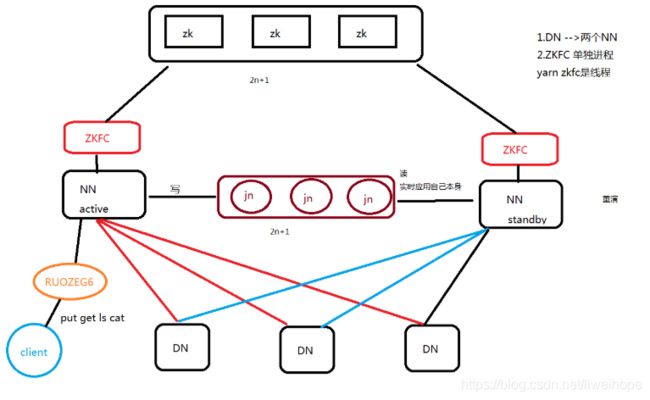
HA 进程:(假定我们现在有三台机器)
hadoop001:ZK NN ZKFC JN DN
hadoop002:ZK NN ZKFC JN DN
hadoop003:ZK JN DN
NN节点有fsimage、editlog(读和写请求的记录)两个文件,有专门的进程去管理的,这个进程是JN(journalnode)日志节点,要保证NN1和NN2能实时同步,需要JN这个角色。
如果NN1挂了,需要把NN2从standby状态切换到active状态,那它是怎么切换的呢?需要ZKFC。
ZKFC: 是单独的进程,它监控NN健康状态,向zk集群定期发送心跳,使得自己可以被选举;当自己被zk选举为active的时候,zkfc进程通过RPC协议调用使NN节点的状态变为active。对外提供实时服务,是无感知的。
所以在上面,需要在三台机器上都部署一下zookeeper,作为一个集群,ZK集群,是用于做选举的。选举谁来做老大(active),谁做standby。集群中ZK的个数是2n+1,这样能投票保证最后有一个胜出。
生产上zookeeper部署的个数经验:如果集群中有20台节点,那么可以在5台上部署zk。如果总共有七八台,也部署5台zk。如果总共有20~100台节点,可以部署7台/9台/11台 zk。如果大于100台,可以部署11台zk。如果有很多,比如上万台那看情况可以多部署几台。但是,不是说zk节点越多越好。因为做投票选举动作的时候,投票谁做active,谁做standby是需要时间的,时间间隔太长会影响对外服务,对外服务会很慢,对于即时性服务来说,这是不允许的。
对于大公司比如BAT公司,他们的集群有很多台,比如几百台几千台,zk部署的机器上就它一个进程,不部署其它进程了。在这里是学习或者机器很少,所以一台机器上部署多个进程。如果几百台节点,任务很重,如果部署zk的机器上有其它进程,那么它会消耗很多机器上的资源(无外乎cpu、内存、文件数、进程数),这都会影响zk响应的速度,所以一般都会把它独立出来。但是如果机器是256G内存,但是zk只用到32G,那其他的就浪费了,那么买机器的时候,可以单独给zk买32G内存的机器就可以了。
zk是最底层的,如果zk太繁忙,就可能导致standby状态不能切换到active状态,这个时候机器可能就会夯住。所以当机器夯住,standby不能切换到active的时候,有可能就是zk出问题了。
HDFS HA 架构图
官网:

翻译:
一个典型的HA集群,NameNode会被配置在两台独立的机器上,在任何时间上,一个NameNode处于活动状态,而另一个NameNode处于备份状态,活动状态的NameNode会响应集群中所有的客户端,备份状态的NameNode只是作为一个副本,保证在必要的时候提供一个快速的转移。
为了让Standby Node与Active Node保持同步,这两个Node都与一组称为JNS的互相独立的进程保持通信(Journal Nodes)。当Active Node上更新了namespace,它将记录修改日志发送给JNS的多数派。Standby noes将会从JNS中读取这些edits,并持续关注它们对日志的变更。Standby Node将日志变更应用在自己的namespace中,当failover发生时,Standby将会在提升自己为Active之前,确保能够从JNS中读取所有的edits,即在failover发生之前Standy持有的namespace应该与Active保持完全同步。
为了支持快速failover,Standby node持有集群中blocks的最新位置是非常必要的。为了达到这一目的,DataNodes上需要同时配置这两个Namenode的地址,同时和它们都建立心跳链接,并把block位置发送给它们。
任何时刻,只有一个Active NameNode是非常重要的,否则将会导致集群操作的混乱,那么两个NameNode将会分别有两种不同的数据状态,可能会导致数据丢失,或者状态异常,这种情况通常称为“split-brain”(脑裂,三节点通讯阻断,即集群中不同的Datanodes却看到了两个Active NameNodes)。对于JNS而言,任何时候只允许一个NameNode作为writer;在failover期间,原来的Standby Node将会接管Active的所有职能,并负责向JNS写入日志记录,这就阻止了其他NameNode基于处于Active状态的问题。
首先要部署三台zk,然后要两台NN节点,然后三台DN节点。两个NN节点之间的编辑日志需要jn来维护,做共享数据存储。
journalnode(jn): 部署多少合适?取决于HDFS请求量及数据量,比如说BT级的数据量,或者小文件很多,读写请求很频繁,那么journalnode就部署多一点,如果HDFS很悠闲,那就部署少一点,比如7个、9个这样,可以大致和zk部署的保持一致(见上面)。具体要看实际情况。(也是2n+1,可以看官网上介绍)

每个DataNode节点要向两个NameNode都发送心跳报告。(面试,为什么)
在这里ZKFC是进程,(但是在yarn ha 里,zkfc是线程)
进程:ps -ef 看到的就是进程,是由1个以上的线程组成。
线程:线程是进程的一部分
ZKFC:zookeeperfailovercontrol
客户端或者程序代码在提交的时候,去namespace找,找NN节点,如果第一次找的NN节点就是active,那么就用这个节点,如果发现它是standby,就到另外一台机器。
比如说客户端现在执行put、get、ls、cat命令,这些操作命令的记录,active NN节点会写到自己的edit log日志里面。这些操作记录,NN自己会写一份,同时,它会把这些操作记录,写给journalnode的node集群。
而另外的,standby NN节点,会实时的读journalnode的node集群,读了之后会把这些记录应用到自己的本身。这个大数据的专业名词叫做:重演。 相当于standby NN节点把active NN节点的active状态的操作记录在自己身上重演一遍。
journalnode:它是一个集群,就是用于active NN节点和standby NN节点之间同步数据的。它是单独的进程。
NN和ZKFC在同一台机器上面。
整个过程描述:当通过client端提交请求的时候,无论读和写,我们是通过命名空间RUOZEG6,去找谁是active状态,找到了就在那台机器上面,提交请求,然后就是HDFS的读写流程,读和写的操作记录,edit log,它自己会写一份,同时会把读写请求的操作记录,写一份到journalnode集群日志,进行同步之后,另外一个节点,standby 节点会把它拿过来实时的应用到自己的本身。专业的名称叫重演。同时每个DataNode会向NameNode节点发送心跳的块报告(心跳的间隔时间3600s,就是1小时,参数是什么(面试))。当active NN节点挂了,通过zk集群选举(它存储了NN节点的状态),通知ZKFC,把standby NN节点切换到active状态。ZKFC会定期的发送心跳。
ps:
HA是为了解决单点故障问题。
通过journalnode集群共享状态,也就是共享hdfs读和写的操作记录。
通过ZKFC集群选举谁是active。
监控状态,自动备援。
DN: 同时向NN1 NN2发送心跳和块报告。
ACTIVE NN: 读写的操作记录写到自己的editlog
同时写一份到JN集群
接收DN的心跳和块报告
STANDBY NN: 同时接收JN集群的日志,显示读取执行log操作(重演),使得自己的元数据和active nn节点保持一致。
接收DN的心跳和块报告
JounalNode: 用于active nn和 standby nn节点的数据同步, 一般部署2n+1
ZKFC: 单独的进程
监控NN监控健康状态
向zk集群定期发送心跳,使得自己可以被选举;
当自己被zk选举为active的时候,zkfc进程通过RPC协议调用使NN节点的状态变为active,只有是
active状态才能对外提供服务。
对外提供实时服务,是无感知的,用户是感觉不到的。