Flink学习笔记(4)——Flink运行架构
目录
一、Flink运行时架构
1.1 系统架构
1.1.1 整体构成
1.1.2 作业管理器(JobManager)
1.1.3 任务管理器(TaskManager)
1.2 作业提交流程
1.2.1 高层级抽象视角
1.2.2 独立模式(Standalone)
1.2.3 YARN集群
1.3 一些重要概念
1.3.1 数据流图(Dataflow Graph)
1.3.2 并行度(Parallelism)
1.3.3 算子链
1.3.4 作业图(JobGraph)与执行图(ExecutionGraph)
1.3.5 任务(Tasks)和任务槽(Task Slots)
1.4 本章总结
一、Flink运行时架构
我们已经对 Flink 的主要特性和部署提交有了基本的了解,那它的内部又是怎样工作的, 集群配置设置的一些参数又到底有什么含义呢?
接下来我们就将钻研 Flink 内部,探讨它的运行时架构,详细分析在不同部署环境中的作 业提交流程,深入了解 Flink 设计架构中的主要概念和原理。
1.1 系统架构

1.1.1 整体构成
Flink 的运行时架构中,最重要的就是两大组件:作业管理器(JobManger)和任务管理器 (TaskManager)。对于一个提交执行的作业,JobManager 是真正意义上的“管理者”(Master), 负责管理调度,所以在不考虑高可用的情况下只能有一个;而 TaskManager 是“工作者” (Worker、Slave),负责执行任务处理数据,所以可以有一个或多个。Flink 的作业提交和任务 处理时的系统如图 4-1 所示。


1.1.2 作业管理器(JobManager)
JobManager 是一个 Flink 集群中任务管理和调度的核心,是控制应用执行的主进程。也就 是说,每个应用都应该被唯一的 JobManager 所控制执行。当然,在高可用(HA)的场景下,可能会出现多个 JobManager;这时只有一个是正在运行的领导节点(leader),其他都是备用 节点(standby)。 JobManger 又包含 3 个不同的组件,下面我们一一讲解。

1.1.3 任务管理器(TaskManager)
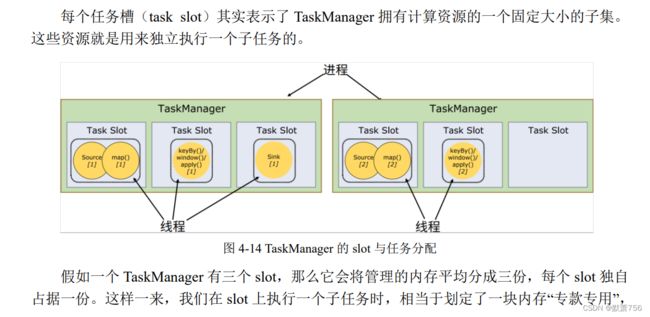
TaskManager 是 Flink 中的工作进程,数据流的具体计算就是它来做的,所以也被称为 “Worker”。Flink 集群中必须至少有一个 TaskManager;当然由于分布式计算的考虑,通常会 有多个 TaskManager 运行,每一个 TaskManager 都包含了一定数量的任务槽(task slots)。Slot是资源调度的最小单位,slot 的数量限制了 TaskManager 能够并行处理的任务数量。
启动之后,TaskManager 会向资源管理器注册它的 slots;收到资源管理器的指令后,TaskManager 就会将一个或者多个槽位提供给 JobMaster 调用,JobMaster 就可以分配任务来执 行了。在执行过程中,TaskManager 可以缓冲数据,还可以跟其他运行同一应用的 TaskManager交换数据。
1.2 作业提交流程
了解了 Flink 运行时的基本组件和系统架构,我们再来梳理一下作业提交的具体流程。
1.2.1 高层级抽象视角
Flink 的提交流程,随着部署模式、资源管理平台的不同,会有不同的变化。首先我们从 一个高层级的视角,来做一下抽象提炼,看一看作业提交时宏观上各组件是怎样交互协作的。

如图 4-2 所示,具体步骤如下:
(1) 一般情况下,由客户端(App)通过分发器提供的 REST 接口,将作业提交给
JobManager。
(2)由分发器启动 JobMaster,并将作业(包含 JobGraph)提交给 JobMaster。
(3)JobMaster 将 JobGraph 解析为可执行的 ExecutionGraph,得到所需的资源数量,然后 向资源管理器请求资源(slots)。
(4)资源管理器判断当前是否由足够的可用资源;如果没有,启动新的 TaskManager。
(5)TaskManager 启动之后,向 ResourceManager 注册自己的可用任务槽(slots)。
(6)资源管理器通知 TaskManager 为新的作业提供 slots。
52
(7)TaskManager 连接到对应的 JobMaster,提供 slots。
(8)JobMaster 将需要执行的任务分发给 TaskManager。
(9)TaskManager 执行任务,互相之间可以交换数据。
如果部署模式不同,或者集群环境不同(例如 Standalone、YARN、K8S 等),其中一些步 骤可能会不同或被省略,也可能有些组件会运行在同一个 JVM 进程中。比如我们在上一章实 践过的独立集群环境的会话模式,就是需要先启动集群,如果资源不够,只能等待资源释放, 而不会直接启动新的 TaskManager。
接下来我们就具体介绍一下不同部署环境下的提交流程。
1.2.2 独立模式(Standalone)
在独立模式(Standalone)下,只有会话模式和应用模式两种部署方式。两者整体来看流 程是非常相似的:TaskManager 都需要手动启动,所以当 ResourceManager 收到 JobMaster 的 请求时,会直接要求 TaskManager 提供资源。而 JobMaster 的启动时间点,会话模式是预先启 动,应用模式则是在作业提交时启动。提交的整体流程如图 4-3 所示。

我们发现除去第 4 步不会启动 TaskManager,而且直接向已有的 TaskManager 要求资源, 其他步骤与上一节所讲抽象流程完全一致。
1.2.3 YARN集群
接下来我们再看一下有资源管理平台时,具体的提交流程。我们以 YARN 为例,分不同 的部署模式来做具体说明。
1. 会话(Session)模式
在会话模式下,我们需要先启动一个 YARN session,这个会话会创建一个 Flink 集群

这里只启动了 JobManager,而 TaskManager 可以根据需要动态地启动。在 JobManager 内部,由于还没有提交作业,所以只有 ResourceManager 和 Dispatcher 在运行,如图 4-4 所示。

接下来就是真正提交作业的流程,如图 4-5 所示:
(1)客户端通过 REST 接口,将作业提交给分发器。
(2)分发器启动 JobMaster,并将作业(包含 JobGraph)提交给 JobMaster。
(3)JobMaster 向资源管理器请求资源(slots)。
(4)资源管理器向 YARN 的资源管理器请求 container 资源。
(5)YARN 启动新的 TaskManager 容器。
(6)TaskManager 启动之后,向 Flink 的资源管理器注册自己的可用任务槽。
(7)资源管理器通知 TaskManager 为新的作业提供 slots。
(8)TaskManager 连接到对应的 JobMaster,提供 slots。
(9)JobMaster 将需要执行的任务分发给 TaskManager,执行任务。
可见,整个流程除了请求资源时要“上报”YARN 的资源管理器,其他与 4.2.1 节所述抽 象流程几乎完全一样。
2. 单作业(Per-Job)模式
在单作业模式下,Flink 集群不会预先启动,而是在提交作业时,才启动新的 JobManager。
具体流程如图 4-6 所示。
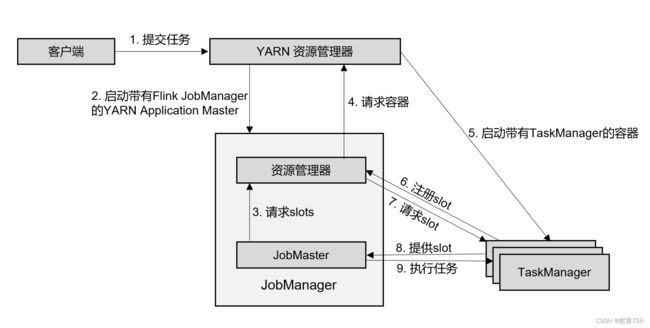
(1)客户端将作业提交给 YARN 的资源管理器,这一步中会同时将 Flink 的 Jar 包和配置 上传到 HDFS,以便后续启动 Flink 相关组件的容器。
(2)YARN 的资源管理器分配 Container 资源,启动 Flink JobManager,并将作业提交给
JobMaster。这里省略了 Dispatcher 组件。
(3)JobMaster 向资源管理器请求资源(slots)。
(4)资源管理器向 YARN 的资源管理器请求 container 资源。
(5)YARN 启动新的 TaskManager 容器。
(6)TaskManager 启动之后,向 Flink 的资源管理器注册自己的可用任务槽。
(7)资源管理器通知 TaskManager 为新的作业提供 slots。
(8)TaskManager 连接到对应的 JobMaster,提供 slots。
(9)JobMaster 将需要执行的任务分发给 TaskManager,执行任务。
可见,区别只在于 JobManager 的启动方式,以及省去了分发器。当第 2 步作业提交给
JobMaster,之后的流程就与会话模式完全一样了。
3. 应用(Application)模式
应用模式与单作业模式的提交流程非常相似,只是初始提交给 YARN 资源管理器的不再 是具体的作业,而是整个应用。一个应用中可能包含了多个作业,这些作业都将在 Flink 集群 中启动各自对应的 JobMaster。
1.3 一些重要概念
我们现在已经了解 Flink 运行时的核心组件和整体架构,也明白了不同场景下作业提交的具体流程。但有些细节还需要进一步思考:一个具体的作业,是怎样从我们编写的代码,转换成TaskManager 可以执行的任务的呢?JobManager 收到提交的作业,又是怎样确定总共有多 少任务、需要多少资源呢?接下来我们就从一些重要概念入手,对这些问题做详细的展开讲解。
1.3.1 数据流图(Dataflow Graph)




1.3.2 并行度(Parallelism)
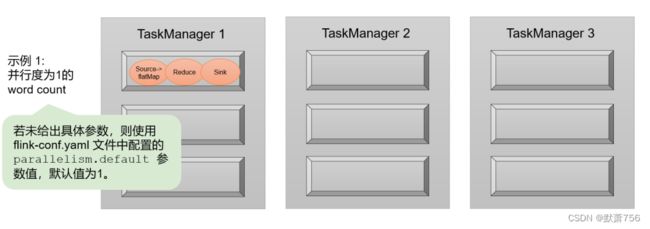
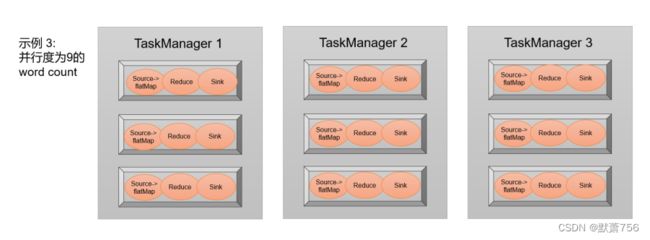
我们已经清楚了算子和数据流图的概念,那最终执行的任务又是什么呢?容易想到,一个 算子操作就应该是一个任务。那是不是程序中的算子数量,就是最终执行的任务数呢?





1.3.3 算子链

1. 算子间的数据传输
回到上一小节的例子,我们先来考察一下算子任务之间数据传输的方式。


2. 合并算子链
在 Flink 中,并行度相同的一对一(one to one)算子操作,可以直接链接在一起形成一个 “大”的任务(task),这样原来的算子就成为了真正任务里的一部分,如图 4-11 所示。每个 task
60
会被一个线程执行。这样的技术被称为“算子链”(Operator Chain)。

1.3.4 作业图(JobGraph)与执行图(ExecutionGraph)




1.3.5 任务(Tasks)和任务槽(Task Slots)












1.4 本章总结
在这一章,我们在之前部署运行的基础上,深入介绍了 Flink 的系统架构和不同组件,并 进一步针对不同的部署模式详细讲述了作业提交和任务处理的流程。此外,通过展开讲解架构 中的一些重要概念,解答了 Flink 任务调度的核心问题,并对分布式流处理架构的设计做了思 考分析。
本章内容不仅是 Flink 架构知识的学习,更是分布式处理思想的入门。我们可以通过 Flink
这样一个经典框架的学习,触摸到分布式架构的底层原理。 Flink 流处理架构设计还涉及事件时间、状态管理以及检查点等重要概念,保证分布式流 处理系统的低延迟、时间正确性和状态一致性。我们将在后面的章节对这些内容做详细展开。