关于Linux网络,必须知道这些
同 CPU、内存以及 I/O 一样,网络也是 Linux 系统最核心的功能。网络是一种把不同计算 机或网络设备连接到一起的技术,它本质上是一种进程间通信方式,特别是跨系统的进程 间通信,必须要通过网络才能进行。随着高并发、分布式、云计算、微服务等技术的普 及,网络的性能也变得越来越重要。
那么,Linux 网络又是怎么工作的呢?又有哪些指标衡量网络的性能呢?接下来,我们一起学习 Linux 网络的工作原理和性能指标。
网络模型
说到网络,我们肯定经常提起七层负载均衡、四层负载均衡,或者三层设备、二层设备等等。那么,这里说的二层、三层、四层、七层又都是什么意思呢?
实际上,这些层都来自国际标准化组织制定的开放式系统互联通信参考模型(Open System Interconnection Reference Model),简称为 OSI 网络模型。
为了解决网络互联中异构设备的兼容性问题,并解耦复杂的网络包处理流程,OSI 模型把网络互联的框架分为应用层、表示层、会话层、传输层、网络层、数据链路层以及物理层等七层,每个层负责不同的功能。其中:
- 应用层,负责为应用程序提供统一的接口。
- 表示层,负责把数据转换成兼容接收系统的格式。
- 会话层,负责维护计算机之间的通信连接。
- 传输层,负责为数据加上传输表头,形成数据包。
- 网络层,负责数据的路由和转发。
- 数据链路层,负责 MAC 寻址、错误侦测和改错。
- 物理层,负责在物理网络中传输数据帧。
但是 OSI 模型还是太复杂了,也没能提供一个可实现的方法。所以,在 Linux 中,我们实际上使用的是另一个更实用的四层模型,即 TCP/IP 网络模型。
TCP/IP 模型,把网络互联的框架分为应用层、传输层、网络层、网络接口层等四层,其中:
- 应用层,负责向用户提供一组应用程序,比如 HTTP、FTP、DNS 等。
- 传输层,负责端到端的通信,比如 TCP、UDP 等。
- 网络层,负责网络包的封装、寻址和路由,比如 IP、ICMP 等。
- 网络接口层,负责网络包在物理网络中的传输,比如 MAC 寻址、错误侦测以及通过网卡传输网络帧等。
为了帮你更形象理解 TCP/IP 与 OSI 模型的关系,画了一张图,如下所示:

当然了,虽说 Linux 实际按照 TCP/IP 模型,实现了网络协议栈,但在平时的学习交流中,我们习惯上还是用 OSI 七层模型来描述。比如,说到七层和四层负载均衡,对应的分别是 OSI 模型中的应用层和传输层(而它们对应到 TCP/IP 模型中,实际上是四层和三层)。
Linux 网络栈
有了 TCP/IP 模型后,在进行网络传输时,数据包就会按照协议栈,对上一层发来的数据进行逐层处理;然后封装上该层的协议头,再发送给下一层。
当然,网络包在每一层的处理逻辑,都取决于各层采用的网络协议。比如在应用层,一个提供 REST API 的应用,可以使用 HTTP 协议,把它需要传输的 JSON 数据封装到 HTTP 协议中,然后向下传递给 TCP 层。
而封装做的事情就很简单了,只是在原来的负载前后,增加固定格式的元数据,原始的负载数据并不会被修改。
比如,以通过 TCP 协议通信的网络包为例,通过下面这张图,我们可以看到,应用程序数据在每个层的封装格式。
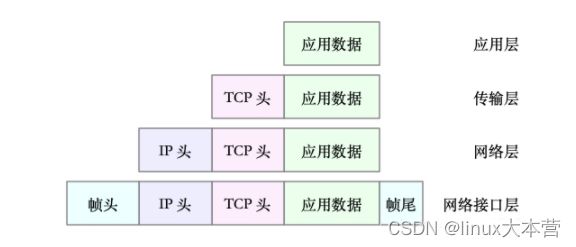
其中:
- 传输层在应用程序数据前面增加了 TCP 头;
- 网络层在 TCP 数据包前增加了 IP 头;
- 而网络接口层,又在 IP 数据包前后分别增加了帧头和帧尾。
这些新增的头部和尾部,都按照特定的协议格式填充,想了解具体格式,你可以查看协议 的文档。 比如,你可以查看这里,了解 TCP 头的格式。
这些新增的头部和尾部,增加了网络包的大小,但我们都知道,物理链路中并不能传输任意大小的数据包。网络接口配置的最大传输单元(MTU),就规定了最大的 IP 包大小。 在我们最常用的以太网中,MTU 默认值是 1500(这也是 Linux 的默认值)。
一旦网络包超过 MTU 的大小,就会在网络层分片,以保证分片后的 IP 包不大于 MTU 值。显然,MTU 越大,需要的分包也就越少,自然,网络吞吐能力就越好。
理解了 TCP/IP 网络模型和网络包的封装原理后,我们很容易能想到,Linux 内核中的网络栈,其实也类似于 TCP/IP 的四层结构。如下图所示,就是 Linux 通用 IP 网络栈的示意图:
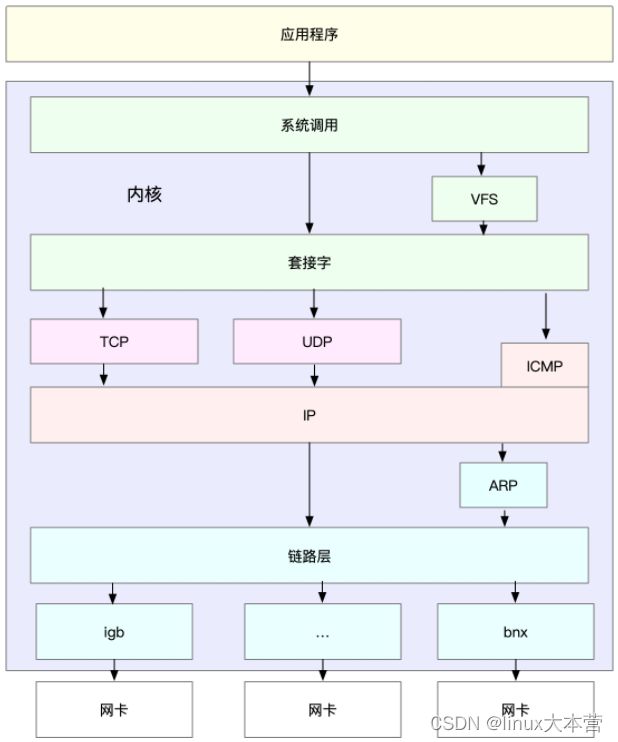
我们从上到下来看这个网络栈,可以发现:
- 最上层的应用程序,需要通过系统调用,来跟套接字接口进行交互;
- 套接字的下面,就是我们前面提到的传输层、网络层和网络接口层;
- 最底层,则是网卡驱动程序以及物理网卡设备。
网卡是发送和接收网络包的基本设备。在系统启动过程中,网卡通过内核中的网卡驱动程序注册到系统中。而在网络收发过程中,内核通过中断跟网卡进行交互。
再结合 Linux 网络栈,可以看出,网络包的处理非常复杂。所以,网卡硬中断 只处理最核心的网卡数据读取或发送,而协议栈中的大部分逻辑,都会放到软中断中处理。
相关视频推荐
4个小时搞懂tcp/ip协议栈,从tcp/ip协议栈原理到实现一个网络协议栈
10道面试必问的经典网络八股文,让你在面试中逼格满满
c++八股文重点,网络的posix api实现原理
免费学习地址:c/c++ linux服务器开发/后台架构师
需要C/C++ Linux服务器架构师学习资料加群812855908领取(资料包括C/C++,Linux,golang技术,内核,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等)

Linux 网络收发流程
了解了 Linux 网络栈后,我们再来看看, Linux 到底是怎么收发网络包的。
网络包的接收流程
我们先来看网络包的接收流程。
当一个网络帧到达网卡后,网卡会通过 DMA 方式,把这个网络包放到收包队列中;然后通过硬中断,告诉中断处理程序已经收到了网络包。
接着,网卡中断处理程序会为网络帧分配内核数据结构(sk_buff),并将其拷贝到 sk_buff 缓冲区中;然后再通过软中断,通知内核收到了新的网络帧。
接下来,内核协议栈从缓冲区中取出网络帧,并通过网络协议栈,从下到上逐层处理这个网络帧。比如:
- 在链路层检查报文的合法性,找出上层协议的类型(比如 IPv4 还是 IPv6),再去掉帧头、帧尾,然后交给网络层。
- 网络层取出 IP 头,判断网络包下一步的走向,比如是交给上层处理还是转发。当网络层确认这个包是要发送到本机后,就会取出上层协议的类型(比如CP 还是 UDP),去 掉 IP 头,再交给传输层处理。
- 传输层取出 TCP 头或者 UDP 头后,根据 < 源 IP、源端口、目的 IP、目的端口 > 四元 组作为标识,找出对应的Socket,并把数据拷贝到 Socket 的接收缓存中。
- 最后,应用程序就可以使用 Socket 接口,读取到新接收到的数据了。
为了更清晰表示这个流程,我们看下图,这张图的左半部分表示接收流程,而图中的粉色箭头则表示网络包的处理路径。

网络包的发送流程
了解网络包的接收流程后,就很容易理解网络包的发送流程。网络包的发送流程就是上图的右半部分,很容易发现,网络包的发送方向,正好跟接收方向相反。
- 首先,应用程序调用 Socket API(比如 sendmsg)发送网络包。
- 由于这是一个系统调用,所以会陷入到内核态的套接字层中。套接字层会把数据包放到 Socket 发送缓冲区中。
- 接下来,网络协议栈从 Socket 发送缓冲区中,取出数据包;再按照 TCP/IP 栈,从上到下 逐层处理。比如,传输层和网络层,分别为其增加 TCP 头和 IP 头,执行路由查找确认下 一跳的 IP,并按照 MTU 大小进行分片。
- 分片后的网络包,再送到网络接口层,进行物理地址寻址,以找到下一跳的 MAC 地址。 然后添加帧头和帧尾,放到发包队列中。这一切完成后,会有软中断通知驱动程序:发包 队列中有新的网络帧需要发送。
- 最后,驱动程序通过 DMA ,从发包队列中读出网络帧,并通过物理网卡把它发送出去。
性能指标
实际上,我们通常用带宽、吞吐量、延时、PPS(Packet Per Second)等指标衡量网络的性能。
- 带宽,表示链路的最大传输速率,单位通常为 b/s (比特 / 秒)。
- 吞吐量,表示单位时间内成功传输的数据量,单位通常为 b/s(比特 / 秒)或者B/s(字节 / 秒)。吞吐量受带宽限制,而吞吐量 / 带宽,也就是该网络的使用率。
- 延时,表示从网络请求发出后,一直到收到远端响应,所需要的时间延迟。在不同场景 中,这一指标可能会有不同含义。比如,它可以表示,建立连接需要的时间(比如 TCP 握手延时),或一个数据包往返所需的时间(比如 RTT)。
- PPS,是 Packet Per Second(包 / 秒)的缩写,表示以网络包为单位的传输速率。 PPS 通常用来评估网络的转发能力,比如硬件交换机,通常可以达到线性转发(即 PPS 可以达到或者接近理论最大值)。而基于 Linux 服务器的转发,则容易受网络包大小的影响。
除了这些指标,网络的可用性(网络能否正常通信)、并发连接数(TCP 连接数量)、丢包率(丢包百分比)、重传率(重新传输的网络包比例)等也是常用的性能指标。
网络配置
分析网络问题的第一步,通常是查看网络接口的配置和状态。你可以使用 ifconfig 或者 ip 命令,来查看网络的配置。推荐使用 ip 工具,因为它提供了更丰富的功能和更易用的接口。
ifconfig 和 ip 分别属于软件包 net-tools 和 iproute2,iproute2 是 net- tools的下一代。通常情况下它们会在发行版中默认安装。但如果你找不到 ifconfig 或者 ip 命令,可以安装这两个软件包。
以网络接口 eth0 为例,你可以运行下面的两个命令,查看它的配置和状态:
ifconfig eth0
eth0: flags=4163 mtu 1500
inet 172.31.36.80 netmask 255.255.240.0 broadcast 172.31.47.255
inet6 fe80::216:3eff:fe00:49c8 prefixlen 64 scopeid 0x20
ether 00:16:3e:00:49:c8 txqueuelen 1000 (Ethernet)
RX packets 214245377663 bytes 60324392337318 (54.8 TiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 214276251268 bytes 26576472133761 (24.1 TiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ip -s addr show dev eth0
2: eth0: mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:16:3e:00:49:c8 brd ff:ff:ff:ff:ff:ff
inet 172.31.36.80/20 brd 172.31.47.255 scope global dynamic noprefixroute eth0
valid_lft 303263442sec preferred_lft 303263442sec
inet6 fe80::216:3eff:fe00:49c8/64 scope link
valid_lft forever preferred_lft forever
RX: bytes packets errors dropped overrun mcast
60324394191655 214245383123 0 0 0 0
TX: bytes packets errors dropped carrier collsns
26576473025328 214276256966 0 0 0 0 可以看到,ifconfig 和 ip 命令输出的指标基本相同,只是显示格式略微不同。比如,它们都包括了网络接口的状态标志、MTU 大小、IP、子网、MAC 地址以及网络包收发的统 计信息。
这些具体指标的含义,在文档中都有详细的说明,不过,这里有几个跟网络性能密切相关的指标,需要特别关注一下。
第一,网络接口的状态标志。ifconfig 输出中的 RUNNING ,或 ip 输出中的 LOWER_UP ,都表示物理网络是连通的,即网卡已经连接到了交换机或者路由器中。如 果你看不到它们,通常表示网线被拔掉了。
第二,MTU 的大小。MTU 默认大小是 1500,根据网络架构的不同(比如是否使用了 VXLAN 等叠加网络),你可能需要调大或者调小 MTU 的数值。
第三,网络接口的 IP 地址、子网以及 MAC 地址。这些都是保障网络功能正常工作所必需 的,你需要确保配置正确。
第四,网络收发的字节数、包数、错误数以及丢包情况,特别是 TX 和 RX 部分的 errors、dropped、overruns、carrier 以及 collisions 等指标不为 0 时,通常表示出现 了网络 I/O 问题。其中:
errors 表示发生错误的数据包数,比如校验错误、帧同步错误等;
dropped 表示丢弃的数据包数,即数据包已经收到了 Ring Buffer,但因为内存不足等 原因丢包;
overruns 表示超限数据包数,即网络 I/O 速度过快,导致 Ring Buffer 中的数据包来不 及处理(队列满)而导致的丢包;
carrier 表示发生 carrirer 错误的数据包数,比如双工模式不匹配、物理电缆出现问题等;
collisions 表示碰撞数据包数。
套接字信息
ifconfig 和 ip 只显示了网络接口收发数据包的统计信息,但在实际的性能问题中,网络协议栈中的统计信息,我们也必须关注。可以用 netstat 或者 ss ,来查看套接字、网络 栈、网络接口以及路由表的信息。
更推荐,使用 ss 来查询网络的连接信息,因为它比 netstat 提供了更好的性能(速 度更快)。
比如,可以执行下面的命令,查询套接字信息:
#head-n3 表示只显示前面 3 行
# -l 表示只显示监听套接字
# -n 表示显示数字地址和端口 (而不是名字)
# -p 表示显示进程信息
netstat -nlp | head -n 3
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:4171 0.0.0.0:* LISTEN 27737/nsqadmin
# -l 表示只显示监听套接字
# -t 表示只显示 TCP 套接字
# -n 表示显示数字地址和端口 (而不是名字)
# -p 表示显示进程信息
ss -ltnp | head -n 3
State Recv-Q Send-Q Local Address:Port Peer Address:PortProcess
LISTEN 0 128 127.0.0.1:4171 0.0.0.0:* users:(("nsqadmin",pid=27737,fd=3))
LISTEN 0 128 0.0.0.0:5355 0.0.0.0:* users:(("systemd-resolve",pid=1069,fd=13)) netstat 和 ss 的输出也是类似的,都展示了套接字的状态、接收队列、发送队列、本地地 址、远端地址、进程 PID 和进程名称等。
其中,接收队列(Recv-Q)和发送队列(Send-Q)需要你特别关注,它们通常应该是 0。当发现它们不是 0 时,说明有网络包的堆积发生。当然还要注意,在不同套接字 态下,它们的含义不同。
当套接字处于连接状态(Established)时:
- Recv-Q 表示套接字缓冲还没有被应用程序取走的字节数(即接收队列长度)。
- 而 Send-Q 表示还没有被远端主机确认的字节数(即发送队列长度)。
当套接字处于监听状态(Listening)时:
- Recv-Q 表示 syn backlog 的当前值。
- 而 Send-Q 表示最大的 syn backlog 值。
而 syn backlog 是 TCP 协议栈中的半连接队列长度,相应的也有一个全连接队列 (accept queue),它们都是维护 TCP 状态的重要机制。
顾名思义,所谓半连接,就是还没有完成 TCP 三次握手的连接,连接只进行了一半,而服 务器收到了客户端的 SYN 包后,就会把这个连接放到半连接队列中,然后再向客户端发送 SYN+ACK 包。
而全连接,则是指服务器收到了客户端的 ACK,完成了 TCP 三次握手,然后就会把这个 连接挪到全连接队列中。这些全连接中的套接字,还需要再被 accept() 系统调用取走,这 样,服务器就可以开始真正处理客户端的请求了。
协议栈统计信息
类似的,使用 netstat 或 ss ,也可以查看协议栈的信息:
netstat -s
....
Tcp:
4138013 active connection openings
2699863 passive connection openings
238194 failed connection attempts
12231 connection resets received
109 connections established
214283494980 segments received
214307564519 segments sent out
3128429 segments retransmitted
141769 bad segments received
18919940 resets sent
InCsumErrors: 141765
....
ss -s
Total: 351
TCP: 138 (estab 110, closed 12, orphaned 0, timewait 7)
Transport Total IP IPv6
RAW 0 0 0
UDP 6 4 2
TCP 126 103 23
INET 132 107 25
FRAG 0 0 0 这些协议栈的统计信息都很直观。ss 只显示已经连接、关闭、孤儿套接字等简要统计,而 netstat 则提供的是更详细的网络协议栈信息。
比如,上面 netstat 的输出示例,就展示了 TCP 协议的主动连接、被动连接、失败重试、 发送和接收的分段数量等各种信息。
网络吞吐和 PPS
如何查看系统当前的网络吞吐量和 PPS。在这里,推荐使用我们的老朋友 sar,在 CPU、内存和 I/O 模块中,我们已经多次用到它。
给 sar 增加 -n 参数就可以查看网络的统计信息,比如网络接口(DEV)、网络接口错误 (EDEV)、TCP、UDP、ICMP 等等。执行下面的命令,你就可以得到网络接口统计信息:
# 数字 1 表示每隔 1 秒输出一组数据
sar -n DEV 1
19时53分23秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
19时53分24秒 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
19时53分24秒 docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
19时53分24秒 eth0 17.00 18.00 4.93 6.25 0.00 0.00 0.00 0.00
19时53分24秒 cni-podman0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00这儿输出的指标比较多,我们来看一下它们的含义:
- rxpck/s 和 txpck/s 分别是接收和发送的 PPS,单位为包 / 秒。
- rxkB/s 和 txkB/s 分别是接收和发送的吞吐量,单位是 KB/ 秒。
- rxcmp/s 和 txcmp/s 分别是接收和发送的压缩数据包数,单位是包 / 秒。
- %ifutil 是网络接口的使用率,即半双工模式下为 (rxkB/s+txkB/s)/Bandwidth,而全双 工模式下为 max(rxkB/s, txkB/s)/Bandwidth。
连通性和延时
最后,我们通常使用 ping ,来测试远程主机的连通性和延时,而这基于 ICMP 协议。比 如,执行下面的命令,你就可以测试本机到 114.114.114.114 这个 IP 地址的连通性和延时:
# -c3 表示发送三次 ICMP 包后停止
ping -c3 114.114.114.114
PING 114.114.114.114 (114.114.114.114) 56(84) bytes of data.
64 bytes from 114.114.114.114: icmp_seq=1 ttl=84 time=159 ms
64 bytes from 114.114.114.114: icmp_seq=2 ttl=86 time=152 ms
64 bytes from 114.114.114.114: icmp_seq=3 ttl=71 time=86.1 ms
--- 114.114.114.114 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2000ms
rtt min/avg/max/mdev = 86.086/132.440/159.290/32.915 msping 的输出,可以分为两部分。
第一部分,是每个 ICMP 请求的信息,包括 ICMP 序列号(icmp_seq)、TTL(生存时 间,或者跳数)以及往返延时。
第二部分,则是三次 ICMP 请求的汇总。
比如上面的示例显示,发送了 3 个网络包,并且接收到 3 个响应,没有丢包发生,这说明 测试主机到 114.114.114.114 是连通的;平均往返延时(RTT)是 159ms、152ms、86.1ms,也就是从发 送 ICMP 开始,到接收到 114.114.114.114 回复的确认,总共经历 159ms、152ms、86.1ms。
总结
多台服务器通过网卡、交换机、路由器等网络设备连接到一起,构成了相互连接的网络。 由于网络设备的异构性和网络协议的复杂性,国际标准化组织定义了一个七层的 OSI 网络 模型,但是这个模型过于复杂,实际工作中的事实标准,是更为实用的 TCP/IP 模型。
TCP/IP 模型,把网络互联的框架,分为应用层、传输层、网络层、网络接口层等四层,这也是Linux 网络栈最核心的构成部分。
应用程序通过套接字接口发送数据包,先要在网络协议栈中从上到下进行逐层处理,最终再送到网卡发送出去。
而接收时,同样先经过网络栈从下到上的逐层处理,最终才会送到应用程序。
我们通常使用带宽、吞吐量、延时等指标,来衡量网络的性能;相应的,你可以用 ifconfig、netstat、ss、sar、ping 等工具,来查看这些网络的性能指标。