Kafka(三)、Kafka架构
Kafka架构
- 一、Kafka 基本介绍
-
- 1.1 什么是Kafka
- 1.2 Kafka特性
- 1.3 常见应用场景
- 二、Kafka 系统架构
-
- 2.1 基本概念
- 2.2 index / timeindex / log 文件
- 2.3 Kafka高效文件存储设计特点
- 三、日志清理策略
-
- 3.1 compact 压缩
- 四、消息数据可靠性
-
- 4.1 最少一次 / 最多一次
- 4.2 ISR 列表
- 4.3 仅有一次
-
- 1. 幂等性
- 2. 事务
- 五、ZooKeeper
-
- 5.1 ZK 中 Kafka 数据目录结构
- 六、Kafka Cluster Mirroring
- 七、Kafka 控制台
- 八、参考文献
一、Kafka 基本介绍
1.1 什么是Kafka
Kafka 是由 Apache 软件基金会开发的一个开源流处理平台,由 Scala 和 Java 编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,这使它作为企业级基础设施来处理流式数据非常有价值。此外,Kafka 可以通过 Kafka Connect 连接到外部系统(用于数据输入/输出),并提供了Kafka Streams —— 一个Java流式处理库。
1.2 Kafka特性
- 高吞吐、低延时:kafka 每秒可处理几十万条消息,它的延迟最低只有几毫秒,每个 topic 可以分为多个 partition ,消费者通过 Consumer group 对 partition 进行消费;
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息持久化到本地磁盘,并支持数据备份防止数据丢失
- 容错性:允许集群中 n-1 个节点宕机(n为partition副本数量)
- 高并发:支持数千个客户端同时读写
- 支持实时在线处理和离线处理:可以使用 Storm 这种实时流处理系统对消息进行实时处理,同时还支持 Hadoop 这种批处理系统进行离线处理
1.3 常见应用场景
Kafka 和其他消息中间件相比,具有消息持久化、高吞吐、分布式、多客户端支持、低延时等特性,适用于离线和在线的消息消费,如常规的消息收集、网站活性跟踪、聚合统计系统运维数据(监控数据)、日志收集等大量数据的互联网服务的数据收集场景。
- 日志收集:通过kafka收集各个服务的日志
- 消息系统
- 用户活动跟踪:用于记录 web用户 或者 app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动被各个服务发布到 kafka 的 topic 中,然后订阅者通过订阅 topic 来做实时监控分析,或者装载到 Hadoop、数据仓库中做离线分析和挖掘
- 运营指标:用于记录运营监控数据,包括收集各种分布式应用数据,生产各种操作的集中反馈,比如报警和报告
- 流式处理:如spark steaming、storm
二、Kafka 系统架构
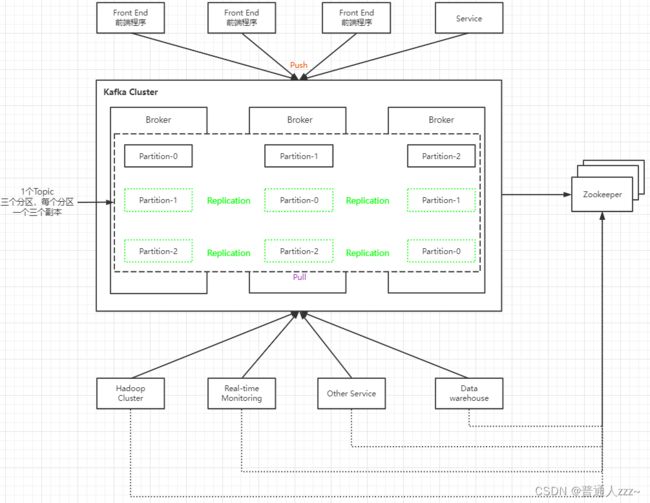
2.1 基本概念
-
Broker:Kafka 集群包含一个或多个服务实例,这些服务实例被称为 Broker。Kafka 支持 Broker 的水平扩展。一般 Broker 越多,集群的吞吐力就越强;
-
Topic:每条发布到 Kafka 集群的消息都有一个类别,这个类型被称为 Topic。Topic 也叫数据主题,是数据记录发布的地方,可以用来区分业务系统。Kafka 中的 Topics 总是多订阅者模式,一个 topic 可以拥有一个或者多个消费者来订阅它的数据;
-
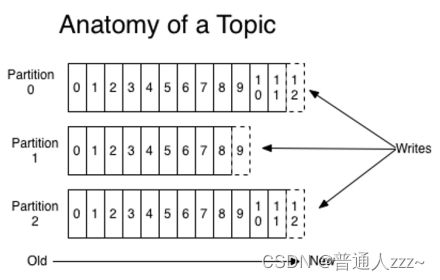
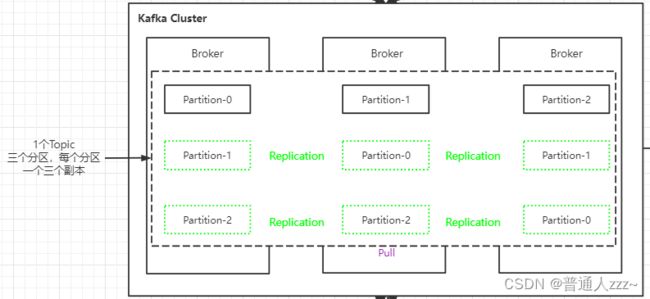
Partition:Kafka 将 Topic 分成一个或多个 Partition,每个 Partition 在物理上对应一个文件夹,该文件夹下存储这个 Partition 的所有消息。官方建议,Kafka 的分区数量应该是 Broker 数量的整数倍。其命名规则为
-
-
Segment:段,多个大小相等的 segment file (段) 组成了一个partition,通过offset进行命名,
segment file 由3大部分组成,以 .index 、.timeindex 结尾的索引文件,和以 .log 结尾的数据文件;可以使用 kafka 安装 bin 目录下的 kafka-run-class.sh 分别查看这些文件的内容:

# 查看log文件
./kafka-run-class.sh kafka.tools.DumpLogSegments --files /usr/local/app/kafka/kafka-logs/topic-test-0/00000000000000000000.log --print-data-log
# 查看index文件
./kafka-run-class.sh kafka.tools.DumpLogSegments --files /usr/local/app/kafka/kafka-logs/topic-test-0/00000000000000000000.index --print-data-log
# 查看timeindex文件
./kafka-run-class.sh kafka.tools.DumpLogSegments --files /usr/local/app/kafka/kafka-logs/topic-test-0/00000000000000000000.timeindex --print-data-log
-
Replication:每个 partition 还会被复制到其它服务器作为 replication,这是一种冗余备份策
略,用于Kafka集群节点挂掉后做数据恢复;副本以分区为单位,每个分区都有各自的主副本。主副本叫做Leader,从副本叫做Follower,处于同步状态的副本叫做In-Sync Replicas(ISR)。Follower 复制数据的线程叫做 ReplicaFetcher Thread,而 Kafka 的 Producer 和 Consumer 只与Leader 进行交互,不会与 Follower 进行交互。
-
Distribution:发布,Log 的分区被分布到集群中的多个服务器上,每个服务器处理它分到的分区,根据配置每个分区还可以复制到其他服务器作为备份容错。每个分区有一个 Leader,0 个或多个 Follower,Leader 负责处理此分区的的所有读写请求,而 Follower 只负责数据的复制(Pull)。如果 Leader 宕机,会从 Follower 中选举出新的 Leader。一台服务器可能同时是一个分区的 Leader,另一个分区的 Follower。这样可以平衡负载,避免所有的请求都只让一台或者某几台服务器处理;
-
Producer:负责发布消息到 Broker;
-
Consumer:消息消费者;
-
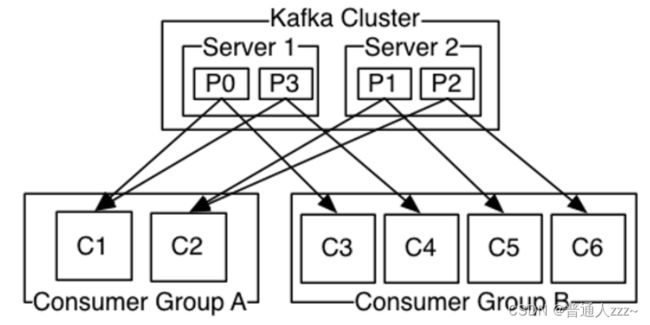
Consumer Group:消费组,每个 Consumer 都属于一个Consumer Group;如果所有的消费者实例在同一消费组中,消息记录会负载平衡到每一个消费者实例;如果所有的消费者实例在不同的消费组中,每条消息记录会广播到所有的消费者进程。
2.2 index / timeindex / log 文件
Kafka Segment 由 3 大部分组成,分别为 index / timeindex / log 文件如下,3 个 文件都是一一对应成对出现的,后缀 .index、.timeindex 和 .log 就分别表示为Segment的索引文件和数据文件,如下图所示。
Segment文件的命名规则是:Partition 全局的第一个 Segment 从 0 开始,后续每个 Segment 文件为上一个全局 Partition 的最大 offset,这个数据是64位的 long 型数据。如果没有数据就用 0 进行填充。通常把日志文件默认为 1G,当达到 1G 就会创建新的 Log 文件和 index文件。如果设置的参数过小,会产生大量的 log 文件和 index 文件,系统在启动的时候就需要加载大量的 index 到内存,占用大量的句柄。如果设置的太大,分段文件又比较少,不利于快速的查找。Kafka 就是通过索引实现快速的定位 message。

注意:Messagexxxx 抽象表示某条消息具体内容;.log 的第二列和 .index 的第一列表示数据文件中的绝对位置,也就是打开文件并移动文件指针需要指定的地方;
以索引文件中的 6,1407 为例,在数据文件中表示第 6 个 message(在全局 partition 表示第 368775 个 message),以及该消息的物理偏移地址为 1407。
- 通过索引信息可以快速定位message。
- 通过将index元数据全部映射到memory,可以避免segment file的index数据IO磁盘操作。
- 通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小。
- 稀疏存储:将原来完整的数据,只间隔的选择多条数据进行存储。
# 查看log文件
./kafka-run-class.sh kafka.tools.DumpLogSegments --files /usr/local/app/kafka/kafka-logs/topic-test-0/00000000000000000000.log --print-data-log
| offset: 1727 CreateTime: 1667112558102 keySize: 7 valueSize: 30 sequence: -1 headerKeys: [] key: Message payload: 你好,这是第728条数据
| offset: 1728 CreateTime: 1667112558102 keySize: 7 valueSize: 30 sequence: -1 headerKeys: [] key: Message payload: 你好,这是第729条数据
| offset: 1729 CreateTime: 1667112558102 keySize: 7 valueSize: 30 sequence: -1 headerKeys: [] key: Message payload: 你好,这是第730条数据
baseOffset: 1730 lastOffset: 1999 count: 270 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 77620 CreateTime: 1667112558147 size: 12148 magic: 2 compresscodec: none crc: 4063926212 isvalid: true
| offset: 1730 CreateTime: 1667112558102 keySize: 7 valueSize: 30 sequence: -1 headerKeys: [] key: Message payload: 你好,这是第731条数据
| offset: 1731 CreateTime: 1667112558102 keySize: 7 valueSize: 30 sequence: -1 headerKeys: [] key: Message payload: 你好,这是第732条数据
| offset: 1732 CreateTime: 1667112558102 keySize: 7 valueSize: 30 sequence: -1 headerKeys: [] key: Message payload: 你好,这是第733条数据
# 查看index文件
./kafka-run-class.sh kafka.tools.DumpLogSegments --files /usr/local/app/kafka/kafka-logs/topic-test-0/00000000000000000000.index --print-data-log
offset: 729 position: 16359
offset: 999 position: 32736
offset: 1365 position: 44884
offset: 1729 position: 61243
offset: 1999 position: 77620
# 查看timeindex文件
./kafka-run-class.sh kafka.tools.DumpLogSegments --files /usr/local/app/kafka/kafka-logs/topic-test-0/00000000000000000000.timeindex --print-data-log
timestamp: 1667111738845 offset: 723
timestamp: 1667111738864 offset: 939
timestamp: 1667112558059 offset: 1352
timestamp: 1667112558102 offset: 1724
timestamp: 1667112558147 offset: 1985
The following indexed offsets are not found in the log.
Indexed offset: 723, found log offset: 729
Indexed offset: 939, found log offset: 999
Indexed offset: 1352, found log offset: 1365
Indexed offset: 1724, found log offset: 1729
Indexed offset: 1985, found log offset: 1999
2.3 Kafka高效文件存储设计特点
(1)Kafka 把 topic 中一个 parition 大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
(2)通过索引信息可以快速定位 message 和确定 response 的最大大小。
(3)通过 index 元数据全部映射到 memory,可以避免 segment file 的 IO 磁盘操作。
(4)通过索引文件稀疏存储,可以大幅降低 index 文件元数据占用空间大小。
三、日志清理策略
# 开关
log.cleaner.enable=true
# 日志清除策略
log.cleanup.policy=delete-删除 / compact-压缩
# 执行日志检查周期,单位毫秒
log.retention.check.interval.ms=300000
过期delete-删除定义(时间或文件大小)
# 日志文件保留的最长时间
log.retention.hours=168
log.retention.minutes
log.retention.ms
# 每个Partition上日志文件能达到的最大字节数,-1 表示不限制
log.retention.bytes=-1
log.segment.bytes
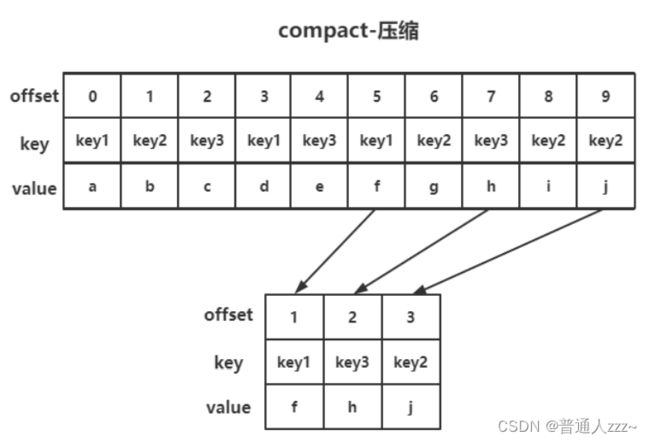
3.1 compact 压缩
compact 操作是保存每个消息的最新value值。
消息是顺序存储的,offset 大的为最新的数据。
四、消息数据可靠性
Kafka 所有消息都会被持久化到磁盘中,同时 Kafka 通过对 Topic Partition 设置 Replication 来保障数据可靠。
一般情况,消息在传输过程中,通常有以下三种可靠性保障:
- 最多一次(At Most Once):消息可能丢失;消息不会重复发送和处理。
- 最少一次(At Lease Once):消息不会丢失;消息可能会重复发送和处理。
- 仅有一次(Exactly Once):消息不会丢失;消息仅被处理一次。
4.1 最少一次 / 最多一次
最少一次 和 最多一次这两种可靠性保障,主要依赖与 kafka Producer 客户端的 acks 参数来保证的。acks 可选值存在三种,如下:
- 0:生产者发送消息后,不需要等待 kafka 应答。如果这是 kafka broker 宕机,很可能导致消息丢失 -------- 最多一次
- 1:生产者发送消息后,需等待 kafka partition 的 Leader 应答。如果数据在没有同步到 follower 时 leader 挂了,那么就可能导致已经提交的消息丢失 -------- 最多一次
- -1(all):生产者发送消息后,Partition Leader 接收到消息,还必须要求 ISR 列表里跟Leader 保持同步的那些 Follower 都要把消息同步之后,才返回应答。如果在 broker 返回ack之前 Leader 宕机,即消息实际是被成功接收,但 Producer 没有收到ack应答,会再次提交消息,最终造成重复提交。如果此时 ISR 列表只有 Leader 节点,此时会导致消息丢失。如果 ISR 中节点比较多,并且其中某个 follower 因为网络原因没有能及时返回 ack,那么会将这个 followe 踢出 ISR 列表,然后 broker 直接给 producer 返回 ack -------- 最少一次
所以,最少一次的条件为 acks=-1 + 分区副本数>=2 + ISR最小副本数量>=2。
4.2 ISR 列表
ISR 列表表示Kafka Partition Follower 与 Leader 保持同步的集合,包括 Leader,如果 Follower 长时间未向 Leader 发送通信请求或者数据同步,则该 Follower 会被踢出 ISR 列表。该时间阈值由 replica.lag.time.max.ms 参数设定,默认30s。这样保证了不会因为没有收到某个 Follower ack 而一直等待。
AR(Assigned Repllicas) = ISR(In-Sync Replicas)+ OSR(Out-Sync Relipcas)
4.3 仅有一次
对于一些非常重要的信息,比如和钱相关的数据,要求数据既不能重复也不丢失。Kafka 0.11版本以后,引入了幂等性和事务。
1. 幂等性
幂等性就是指 Producer 不论向 Broker 发送多少次重复数据,Broker 端都只会持久化一条,保证了消息不重复性。
kafka 通过了冥等性 和 最少一次,保证了消息仅有一次的特性。
重复数据的判断标准:
具有
Kafka 的幂等性只能保证的是在单分区单会话内不重复,所以在单分区中的,用于控制幂等的唯一 ID 是一个局部的,也就是说在不同分区唯一 ID 是互不干扰的。每个 Kakfa Producer 在初始化的时候,会向 Server 申请一个 PID,用于标识 Producer,因为对于同一个分区不同的客户端之前的幂等是互不干扰的。在申请了 PID 之后,那么 Producer 在向每个不同的分区提交消息的时候,需要携带这个 PID 和 sequence numbers,sequence numbers 只在当前 PID 下是生效的,是从 0 递增的。也就是说到 server 端接收到的消息后,会根据 PID 获取对应的 sequence numbers,然后判断 sequence numbers 是否大于当前保存的最大值,如果小于那就说名这个消息已经被提交过,从而丢弃掉当前消息,保证了消息的唯一性。
这也说明为什么 Kafka 的幂等是只支持单会话了,因为 PID 和 sequence numbers 信息是存储在 Producer 中的,会话丢失之后是无法获取之前的 PID 以及 sequence numbers 信息的,所以无法继续之前的处理,只能重新去申请 PID 并且开启新的sequence numbers。
如何使用幂等性
- 配置:
# 默认false-关闭
enable.idempotence=true
- 代码
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");
props.put("acks", "all");
2. 事务
幂等性只能解决单个会话内消息不重复,一旦 Producer 挂了重启后,就无法保证消息不重复。kafka事务就是为了实现跨分区跨会话、Topic-partition的消息不重复。
Kafka 事务引入了一个全局唯一的 TransactionID,并且将 producer 获得 pid 和 TransactionID 绑定,这样当 producer 重启后就可以通过正在运行的 TransactionID 获得原来的pid。
为了管理 Transaction,Kafka 引入了事务协调器 Transaction Coordinator,Producer 通过Transaction Coordinator 获得 transactionid 对应的任务状态。
Transaction Coordinator 还负责将事务所有写入到 kafka 内部的 __transaction_state topic,这样即使服务重启,运行中的事务也能得到恢复,从而继续运行。
如何开启事务
// 设置事务 id(必须),事务 id 任意
props.put("transactional.id", "transaction_id_0");
props.put("acks", "all");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
try {
// 初始化事务
producer.initTransactions();
// 开启事务
producer.beginTransaction();
for (int i = 0; i < 5; i++) {
// 发送消息
kafkaProducer.send(new ProducerRecord<>("topic-tran-test", "transaction message " + i));
}
producer.commitTransaction();
} catch (Exception e) {
// 异常终止
producer.abortTransaction();
} finally {
producer.close();
}
五、ZooKeeper
无论是kafka集群,还是 producer 和 consumer 都依赖于 zookeeper 来保证系统可用性集群保存一些 meta 信息。
Kafka 使用 zookeeper 作为其分布式协调框架,很好的将消息生产、消息存储、消息消费的过程结合在一起。同时借助 zookeeper,kafka 能够生产者、消费者和 broker 在内的所以组件在无状态的情况下,建立起生产者和消费者的订阅关系,并实现生产者与消费者的负载均衡。
5.1 ZK 中 Kafka 数据目录结构
通过 kafka 的 config/server.properties 指定 zookeeper 地址以及根目录,如下:
# ip:port/根路径
zookeeper.connect=127.0.0.01:2181/kafka
通过 zookeeper 可视化工具查看如下图所示:

-
admin/delete_topics:存储删除的topic

-
brokers
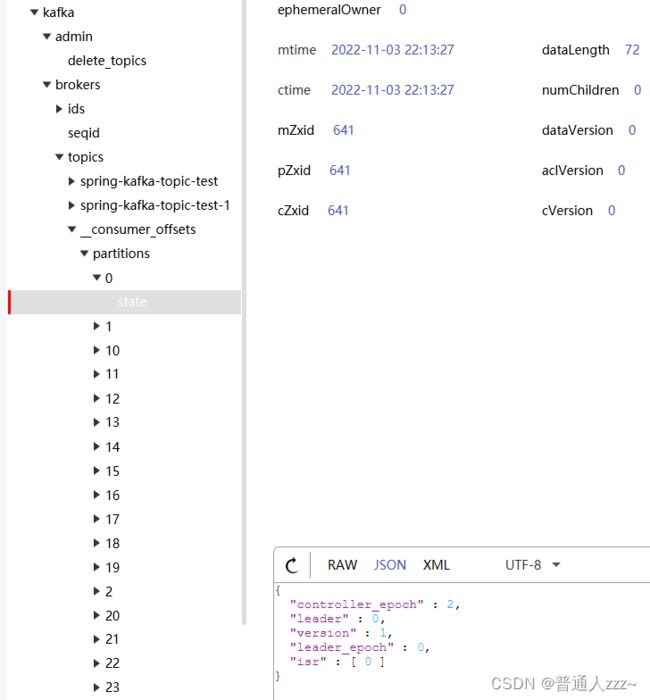
ids:集群中所有节点 id
seqid:
topics:存储 Topic 以及齐下的 Partition 信息,其中 partitions 下的 state 节点,存储了一些远数据信息,如下:
{
"controller_epoch" : 2, // controller 选举周期
"leader" : 0, // leader 节点在集群汇总的id
"version" : 1, // 版本号
"leader_epoch" : 0, // leader选举周期
"isr" : [ 0 ] // 当前Partition ISR 列表
}
-
cluster:kafka集群唯一标识
-
config:存储配置信息

-
consumers:老版本用于存储消费者信息,新的 kafka 版本将消费者的消费信息(offset)存储在kafka的 __consumer_offsets 主题下
-
controller:存储集群中 controller 节点id
{
"version" : 1,
"brokerid" : 0,
"timestamp" : "1667484694571"
}
- controller_epoch:存储 controller 选举周期
- feature
- isr_change_notifiaction:ISR 列表发生变更时候的通知,在 kafka 当中存在ISR列表变更的情况,为了保证 ISR 列表更新的及时性,定义了 isr_change_notification 这个节点,主要用于通知 Controller 来及时将 ISR 列表进行变更。
- latest_producer_id_block:用于幂等 producer。集群中所有 broker 启动时都会启动一个叫 TransactionCoordinator 的组件,该组件能够执行预分配 PID 块和分配 PID 的工作,而所有 broker 都通过 latest_producer_id_block 节点来保存 PID
- log_dir_event_notification:主要用于保存当broker当中某些LogDir出现异常时候,例如磁盘损坏,文件读写失败等异常时候,向ZK当中增加一个通知序号,controller监听到这个节点的变化之后,就会做出对应的处理操作。
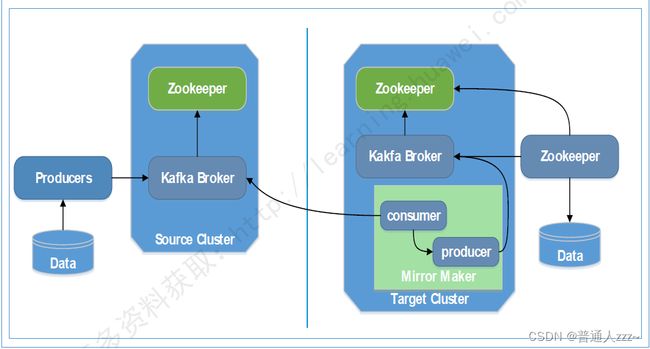
六、Kafka Cluster Mirroring
Kafka CLuster Mirroring 是Kafka跨集群数据同步方案,通过Kafka内置的 MirrorMaker 工具来实现。通过 Mirror Maker 工具中的 consumer 从源集群消费数据,然后再通过内置的Producer,将数据重新发布到目标集群,如下。
七、Kafka 控制台
- Kafka Tool:【https://www.kafkatool.com/download.html】
- Kafdrop:【https://github.com/obsidiandynamics/kafdrop】
八、参考文献
科普:Kafka是啥?干嘛用的?
Kafka (3) - Kafka消息的可靠性保障以及选举