Mq(rabbitmq\kafka)异步、解耦、消峰
项目中用到mq的场景比较多,比如:短信验证码的发送,邮件通知,服务之间的异步调用,他能极大的提高系统的吞吐量,接口的响应时间,他能起到解耦的作用;我们现在都是微服务的方式去开发的,我们项目中有短信服务,邮件服务,业务的各种微服务,微服务的特点就是:高内聚,低耦合,服务之间通过接口去调用,通过mq起到一个异步、解耦的作用。Mq还可以缓冲请求,把请求压到mq队列,起到流量消峰的作用。
重复消费:
消息进入消息队列之后被消费者消费多次的情况。我们是通过redis 的setnx命令解决的重复消费的问题,我们发送消息的时候有个唯一的消息id,消息消费的时候通过setnx命令来拦截消息,一般设置过期时间是24小时或者更多。
消息丢失(消息补偿):
Spring Boot整合——RabbitMQ配置消息确认回调、消息转换以及消息异常处理
消息在发送过程中消息中间件都是有回调的,可以通过回调来确保消息是一定发送成功的。消息发送到mqserver之后,mqserver也会存储消息做相应的做持久化。
消息消费:消息的提交方式:自动提交(消费完成之后直接从消息队列中自动删除了)、手动提交(在完成业务逻辑之后进行手动提交(ack)才能从队列删除)如果消息没有正常消费,那么不会从队列删除。手动提交模式,消息的效率会大大降低,我们通过日志的方式来防止消息丢失的,在发送消息的时候向redis存了消息日志(消息内容、消息发送时间),消费完成之后会从redis删除,如果超过一定时间没有删除,定时任务会做补偿。
顺序消费:
消息堆积:
堆积的原因:消费者消费能力不足,或者是出错,通过增加多个消费者;消费者有推和拉两种模式,如果系统忙的话使用拉的模式比较好,如果不忙的时候,用推的效率会高一点。
Rabbitmq的消息机制:
Rabbitmq有生产者、消费者还有交换机和队列,当生产者发送消息的时候先发送给交换机,交换机路由到队列,然后由消费者去消费消息;
我们在项目中发送消息的时候需要指定交换机的名字和路由key,如果发送的路由key和 交换机和队列绑定的路由key匹配的时候会路由到相应的队列去,扇形交换机和路由key没有关系。
Rabbitmq有很多种交换机,比如有直连的交换机、扇形的交换机、还有主题的交换机等等,只有扇形交换机和路由key是没有关系的。
直连交换机:发送的路由key和绑定的路由key严格匹配才会路由到对应的队列。
扇形交换机:他和路由key没有关系哪个队列跟它关联,它就会发送到对应的队列,其实就是一个订阅模式。
主题交换机:支持 * # ,在交换机和队列绑定的时候路由key支持模糊匹配 * 匹配一个 #匹配零个或多个。
*(星号)可以替代一个单词。
#(hash)可以替换零个或多个单词。
我们在项目中使用直连的还有扇形的比较多,特别是扇形的交换机可以帮助我们项目解耦,使用特别方便。
Kafka架构原理:
Kafka支持主题模式,我们在创建主题时候可以指定分区和副本,消费者可以消费指定分区的数据,一个分区的数据可以有多个消费者去消费,项目中我们是通过zookeeper搭建的集群,zookeeper是3个结点,kafka也是3个结点
Kafka为什么快:面试问:Kafka 为什么速度那么快? - 知乎 (zhihu.com)
Kafka与rabbitmq的区别:
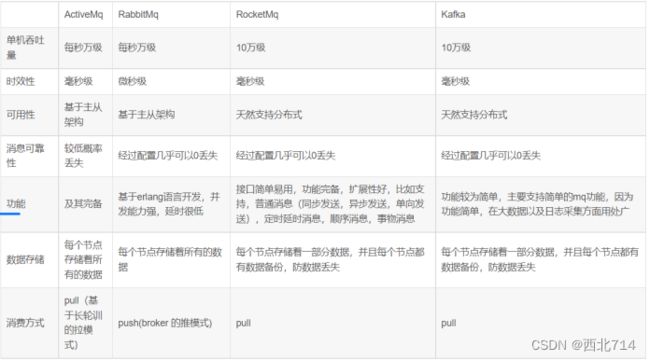
- 吞吐量不同kafka(每秒10万)比rabbitmq(每秒万级)高一个级别
- Kafka只支持主题模式,rabbitmq支持多种交换机
- Rabbitmq是通过quenes来做消息存储,kafka是把消息存入磁盘这也是
- Kafka的数据写到磁盘中,不会造成消息丢失。Kafka占用的内存小
kafka吞吐量大的原因
我们项目中使用到的有rabbitmq和kafka我们业务处理使用的rabbitmq比较多也使用过kafka,我们的日志系统是同过kafka+elk完成的。
Es
介绍:
Es是一个企业级的搜索服务,大量的应用在项目中,他提供了restful和tcp的接口供客户端使用;他是基于Lucene开发的,lucene其实是一个工具包,由于搜索业务通用性强,所以出现了solr、es这样的通用搜索服务。
应用场景:
搜索体验、搜索性能 对标mysql,对mysql大数据量查询的补充,es是支持天然集群的
财务报表、商品搜索、旅游线路
Es集群的分片和副本:
一般是有3个集群节点,三个分片,数据分片存储,三个分片存储在三个节点上,每个分片的副本在其他的两个节点上都有,也就是在任意一个节点上都能查到es的所有数据
在存储数据的时候,可以把请求发送到任意一个结点上,结点会把请求发送给主节点,主节点处理请求,然后写主分片,同步副本
在查询数据的时候,可以发送到任意一个结点上,结点查询分片中的数据,聚合分片数据,进行排序、分页等
集群中分片数量并不是越多越好,如果分片太多的话,查询性能会出现问题

客户端:查询
Spring-data,Java REST Client,在项目中使用的都是这两种客户端,我们使用spring-data操作es,他实现了elasticsearchRepository接口,可以完成简单的增删改查,rest Client做复杂查询更有优势(分组聚合)
ES查询语法 (qq.com) 模糊查询、分组、聚合
倒排索引(正排索引):
其实就是词和文档建立了关系,形成了一个倒排表,当我们向索引库添加一个文档的时候,首先对文档进行分词,然后词和文档建立关系,我们搜索的时候是通过词直接定位到文档,不需要像正排索引那样逐篇文档扫描,这就是es快的原因。
Elasticsearch数据同步