分布式系统中协调和复制技术的原理
分布式系统需要管理大规模服务器,软件需要运行在海量服务器上。管理的服务器越多,越需要在系统中提供协调(Coordination)的仲裁服务,从而让运行在多台服务器上的软件达成共识(Consensus)、形成一致(Agreement),典型如对象存储核心元数据。
协调服务本身也是由运行在多台服务器上的软件组成,当某台服务器发生故障并且无法修复时,还需要继续提供服务。
此时,引入复制(Replication)技术将数据在多台服务器之间复制,即使某台服务器发生故障也能快速、无缝地切换到其他服务器,从而继续提供仲裁服务,最终让客户端无感知地调用仲裁功能。
01
协调和复制技术发展前世今生
下面先通过一张图来看一下协调和复制技术的发展史。

图1 协调和复制技术发展史
协调和复制问题,最先由产业界的实际场景引出,从双机高可用集群逐步演进到大规模分布式集群。
20世纪60年代从研究项目转化为Datapoint ARCnet商用产品,它逐步发展为DEC VAXcluster,从此之后学术界开始大规模研究。
1975年,学术界首次提出两组匪徒通信的问题。
1978年,Jim Gray正式提出两将军问题,描述在不可靠通信环境中如何协调达成共识。
1982年,Leslie Lamport提出拜占庭将军问题,解决拜占庭故障下的共识问题。
1985年,Birman Kenneth提出组播(Broadcast)技术,构建了组播协议基础。
1988年,Brian Oki和Barbara Liskov提出Viewstamped Replication(VR)技术。
1989年,Leslie Lamport首次发表文章Paxos island in Greece,抛出PAXOS协议。
经过学术界的深入研究,诸多大牛(Gray、Lamport、Liskov都是图灵奖获得者)的理论验证,协调和复制进入成熟阶段,所以20世纪90年代,产品界的IBM、HP、Oracle、RedHat、Microsoft、Veritas大规模应用相关技术到产品。
随着互联网的兴起,Google和Yahoo分别推出了业界闻名的Chubby和Zookeeper。
2013年,Diego Ongaro和John Ousterhout在RAFT论文中将复杂的PAXOS用更简单的方式描述,同时参考VR的工程落地性。同年,CoreOS 发布 ETCD(基于RAFT)开源软件。
02
产业界技术概览
20世纪90年代,随着业务的迅速增长,多个厂家都发布了支持超过两个节点的高可用集群产品。例如,IBM的PowerHA SystemMirror产品 、HP的Serviceguard产品、Oracle的Solaris Cluster产品、Red Hat的Cluster产品、Microsoft的MSCS(Microsoft Cluster Server)产品,以及Veritas公司的VCS(Veritas Cluster Server)产品等等。
特别是VCS 产品,它引入了原子广播技术实现全局成员服务和与原子广播(Global membership services and Atomic Broadcast,GAB)模块,提供了集群仲裁和共识服务。
全局成员服务和与原子广播模块运行在专有网络中,与数据访问路径的业务网络隔离。
该专有网络的交换机提供集群节点间通信和协调的能力,实现独立的控制网络,保证控制平面的服务质量,如图-2(A)所示。
但是,该网络存在交换机异常时集群出现脑裂(Split Brain)的问题,此时某些服务器之间无法通信协调,但是数据通路都是正常的,如果所有服务器都继续写入数据,那么很可能出现数据一致性问题,为此引入IO Fencing 技术,如图-2(B)所示。

图2 产业界相关技术
在IO Fencing处理过程中,分裂的子集群会选取一个代表参与竞争(通常加入集群的服务器会分配ID,此时选择ID 较小的服务器作为代表),避免子集群的多台服务器同时去竞争,导致竞争算法成功率降低。这种基于优先级的选取法,类似王位继承优先级顺序。
21世纪初,随着互联网的大规模应用,互联网厂家将学术界的成果进行工程化应用。
Google在2006年发表的论文The Chubby lock service for loosely coupled distributed systems,详细描述基于通用服务器实现经过学术界严格证明的PAXOS协调共识算法,如图-3(A)所示。
2008年,Yahoo以Chubby为参考,在开源Apache社区发布以原子广播(Atomic Broadcast)原理为基础的ZooKeeper,如图-3(B)所示。从2013年开始,CoreOS开始用Go语言实现基于RAFT原理的ETCD,如图-3©所示。
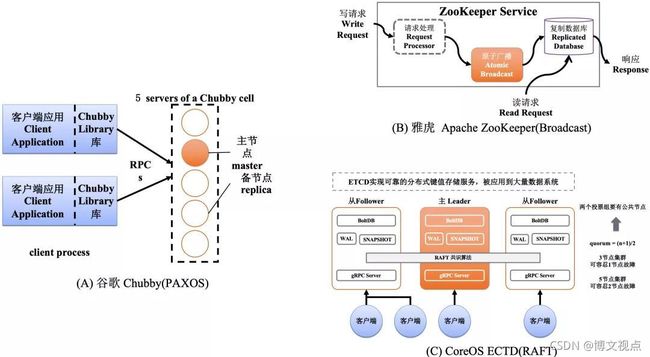
图3 互联网相关技术
03
学术界技术概览
针对协调问题,学术界Jim Gray首先抽象了在不可靠通信环境中如何达成共识的两将军问题,Lamport扩展该问题到拜占庭将军问题。
拜占庭将军的难题在于拜占庭故障,即通信兵可能被敌军俘获并且叛变,从而传递错误信息,并且将军也有可能成为叛徒。
为了实现在不可靠通信环境、甚至存在拜占庭故障的场景下达成共识,学界通过原子广播、视图复制(VR)、PAXOS、RAFT等相关论文深入研究共识和复制技术,其核心是解决状态机运行、投票、故障后的选主等工作,如图4所示。

图4 学术界相关原理
VR的正式发表时间比PAXOS早一年,某些文章介绍两位图灵奖获得者Liskov和Lamport各自独立发表,并未相互借鉴。
不过从工程理解维度看,VR是设计完备度非常好的高质量论文,甚至可以直接指导开发工作,这可能和Liskov擅长编程和计算机科学,而Lamport更擅长理论研究有关,毕竟Liskov因其面向对象编程的杰出贡献而获得图灵奖,著名的里氏替换原则(Liskov Substitution Principle)就是她的杰作。从笔者的角度看,VR绝对是被低估的论文,值得认真研究和分析。
而在不同的服务器节点间复制数据时,存在基于主复制协议(Primary Based Protocols)和客户端写复制(Client Replicate Write Protocols)两种方案,如图5所示。

图5 数据复制方案
其中基于主复制协议完成请求至少需要2跳,第1跳由客户端发送请求给主(Primary),第2跳由主并行将请求发给多个副本。客户端写复制协议完成请求需要1跳,客户端并行发送请求给多个副本。因此客户端写复制协议的时延更短,但在并发冲突时代价很大。而基于主复制协议增加了时延,但是高效地解决了并发冲突问题。

04
实际应用示例
通过学术和产业两个角度的介绍及算法分析可以看出,共识算法解决的核心问题是,系统成员正常时,如何解决多个请求提案的顺序处理问题,并保证每个提案能够被系统成员投票达成一致;以及系统成员异常时,如何重新选取成员并让系统重新进入正常状态。
现实生活中, “罗伯特议事规则”就是解决共识的经典方案,团队开会也是简单的共识解决方法。
会议的N位成员正常时的议题处理方法。会议秘书收集议题,秘书会按顺序编号议题,对于相同的议题进行合并或排序。会议主持人发出评审议题X,参会人对该议题反馈同意/反对,然后主持人根据会议成员的投票结果(如多于一半的成员同意)给出议题的结论。评审完议题X,再次评审下个议题,直到所有议题结束。
会议的N 位成员异常时的议题处理方法。如果成员出现异常,如主持人请假、参会人请假、新增参会人等,就必须形成新的会议投票机制。
若主持人请假,则需要选出新的主持人。需要有机制、流程选出新的主持人,新主持人必须能掌握会议运作机制和投票机制(如成员变为N-1位)。
若参会人调整(如参会人请假、新增参会人),则需要调整新的投票机制。假设有1人请假,那么新的会议成员为M位,M=N-1。若投票时,超过一半(≥M/2)成员同意,则该议题通过。
1.状态机运行
共识在成员正常时,采用主来控制议题的顺序性,并且由主来推动成员的投票,就像会议的主持人推动参会人投票议题,并按议题顺序推进会议,直到议题结束。
2.投票
若想要请求在共识的多个成员中达成一致,则需要采用投票机制进行决策。类似会议主持人要求参会人投票,对议题X达成同意/反对的结论。成员投票只是给出反馈,还需要以下决策方案。
同等权重决策。成员每人1票,权重相同,假设总分为N,那么只有同意的结论分大于或等于N/2时,该议题才能被同意。
不同权重决策。成员每人1票,权重不相同,如主持人为3分,参会人为1分,假设总分为M;那么只有同意的结论分大于或等于M/2时,该议题才能被同意。
3.故障类型
共识协议能实现故障的容错,分布式系统中典型的故障如下。
崩溃故障(Crash Failure,也叫作Fail-Stop)。成员在发生故障后会停止运行(Fail Stop)。例如,服务器直接崩溃重启,由于及时从系统中离开,所以让状态机的后续运行更简单。对于会议投票成员来说,直接请假离开就类似崩溃故障。
拜占庭故障。成员发生故障但并不停止运行,进入不稳定状态,甚至给出错误的反馈。例如,扮演成员的进程因系统繁忙偶发挂住(Hang),时而响应,时而不响应,甚至返回错误的消息。由于成员处于亚健康状态,会干扰系统的状态机运行,所以更难处理。对于会议投票成员来说,对同一议题犹豫不决,时而同意、时而反馈,类似捣乱一样,此时就像拜占庭故障。
4.选主
共识协议中的成员发生故障时,特别是主成员发生故障时需要进行选主动作,如会议主持人请假,就需要重新选取主持人。通常来说,选主有以下解决方案。
基于投票选举。参与选主的成员进行投票,按照投票的半数得分决策原则选主。
优先级(Priority)选举。参与选主的成员被指定优先级ID,比如由ID号最小的成员优先作为主,就像王位的顺位继承,该方法决策速度快。
05
小结
两将军问题首先提出不可靠网络的共识问题,然后逐步演化为存在拜占庭故障的拜占庭将军问题,通过对问题的分析提出原子广播解决方案,鉴于原子广播无法支撑数据持久化能力,学术界提出改进优化的VR和PAXOS,鉴于PAXOS的理论复杂度,业界又提出RAFT,它将PAXOS 用更简单的方式描述,同时参考VR的工程实现优化,如图6(A)所示。
共识技术要支持数据持久化能力会用到日志复制技术。而分布式存储系统需要做数据冗余,也需要实现数据复制。数据复制需要基于一致性模型设计,分为客户端一致性模型、数据副本一致性模型。一致性模型的需求影响数据复制协议的实现,复制协议分为两类:基于主复制协议和客户端写复制协议,如图6(B)所示。

图6 协调共识和复制小结
共识技术和复制技术存在的关联性,就是基于主复制协议。
同时复制协议也影响一致性,并和CAP 理论有关联,值得深入的分析和研究。
▼
本文节选自《对象存储实战指南》一书,更多的深入讨论,请参考此书第2章。

▊《对象存储实战指南》
罗庆超 著
国际资深存储技术专家专著
详解对象存储的历史由来、技术细节、实战操作、未来展望
本书权威详解了对象存储的历史由来(从块存储到文件存储,再到对象存储);存储技术架构(存储区域网络架构、网络附加存储架构、对象存储架构,以及公共云对象存储服务实现架构);对象存储的技术细节(协调和复制、命名和同步、容错和数据完整性、元数据索引设计);对象存储的操作和使用(快速上手、迁移数据到对象存储、安全与合规、数据保护、应用与实践);对象存储的未来展望(数据湖存储、混合云存储、移动网络5G存储、人工智能存储、存储新技术趋势)。
本书适合云计算开发、使用和运维人员,或作为资深技术专家全面分析对象存储的参考书,还适合信息管理专业技术人员、IT经理人等专业人士、技术专家、高校学生,以及更多愿意了解和投入存储事业的人们参考阅读。

(京东满100减50,快快扫码抢购吧!)