GPGPU 架构
文章目录
- 前言
- intro
- programming model
- SIMT core内部架构
-
- instruction fetch loop
- two-loop approximation
- three-loop approximation
- cache 架构
前言
本文章来自general-purpose graphics processor units architecture
intro
首先GPGPU从传统上来说用于处理图形计算,但是随着时代的发展,GPGPU越来越用于其他的场景,比如高性能计算,比如人工智能领域,所以本不涉及图形层次
如果我们将苹果A8处理器拆出来看,会发现A8处理器的GPU区域已经大于CPU的区域,它不仅仅作图形运算,还做SIMD等类型的workload
进几十年来,一些computing system性能越来越高,为什么?因为器内部的晶体管的大小越来越小(工艺的提升),因为硬件架构的提升,因为编译器技术的提升,因为算法的提升,最主要是晶体管越来越小,但是从2005年开始盲目的增加晶体管的数量已经不是我们提升计算机架构的首选(dannard scaling rule失败了),一个非常关键的因素是时钟频率提升变慢(因为时钟频率越来越高,热量越来越大,热量越大散热变成非常大的一个难题),所以现在提升计算机架构的一个方法是找到一个更合适的硬件架构,比如我们将一些应用移到GPU上可能获得500X的能源效率提升,有的通过消除指令集的瓶颈获得了10X效率的提升
当前计算机架构的一个最主要的挑战是,找到一种计算机架构,这个架构使用了特殊的硬件架构获得了更好的性能,并且适用的应用也非常的广,目前流行的做法是设计一种专门为某种应用而运行的硬件,比如google的tensor processing unit,他专门用于深度神经网络
经常有一个疑问叫做GPU是否可以完全的代替CPU?就目前而言,这非常的难,因为目前GPU并不是一个可以stand-alone computing的设备,目前的GPU要么和CPU集成在一个芯片上,GPU或者插在主板上通过PCIE和CPU进行通讯(PCIE通讯速率也是GPU的瓶颈之一,因为PCIE传输对于GPU来说太慢了),CPU用于初始化计算,并且将数据传入到GPU中(通过PCIE总线),并且,目前为止CPU中有北桥可以访问主存,有中断器可以相应input设备,CPU还提供了一套API去访问IO,但是GPU虽然说做到这些不难, 但是还没有厂商实现,并且操作系统也是一个方面,我们的GPU一般并行处理数据,但是操作系统要求并行处理数据的场景比较少,所以操作系统也是一个问题,最终我们所考虑的形式是GPU和CPU进行交互
下面是CPU和GPU如何共存的overlay,左边是我们GPU直接插入PCIE插槽,右边是GPU和CPU集成成一个芯片(AMD的APU)
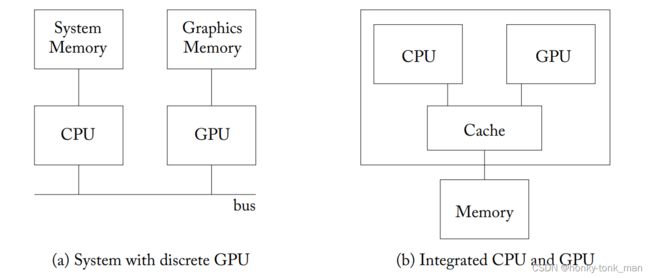
从某个方面来说GPU程序的初始化必须要由CPU来完成,比如我们将数据传到GPU的mem中,需要CPU来完成,我们的kernel(GPU程序)需要launch多少个线程(grim),CPU调用GPU的API,在GPU上分配内存,这些都要由CPU完成,然后将数据传输到GPU中,再由GPU运行
我们都知道GPU由非常多个SIMT Core Cluster组成,SIMT Core组成SIMT Core cluster,SIMT Core在nvidia中叫做streaming multiprocessors(SM),在AMD中叫做compute units(CU),每个SIMT Core有自己的data / instruction cache(这里后面会展开讲,我也会介个GPGPU-Sim的架构来介绍)
每个SIMT Core中真正SIMD的是一个叫做warp的东西,nVidia一般是32个线程组成一个warp,换句话将32个线程同一时间执行一个指令
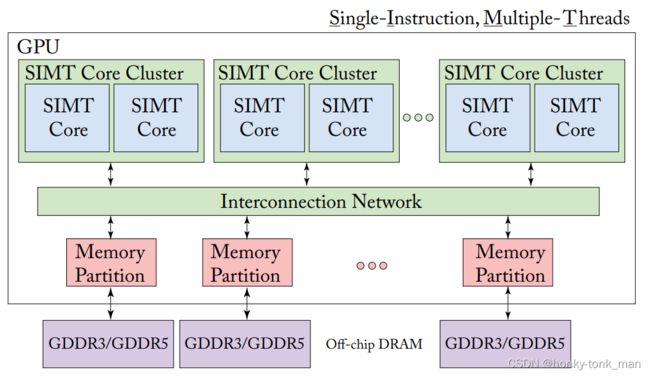
每个SIMT Core可以跑非常多的线程,我们上面提到SIMT Core中有自己的data cache自己的instruction cache,每个SIMT Core Cluster也有一个cache(last level cache)供本集群内所有的SIMT Core共享,每个SIMT Core通过on-chip的通道(cross bar也是上图的interconnection network)访问这个last-level cache,以上都是on-chip的cache,最后就是我们的显存AKA device memory,这个device memory其实是off-chip的
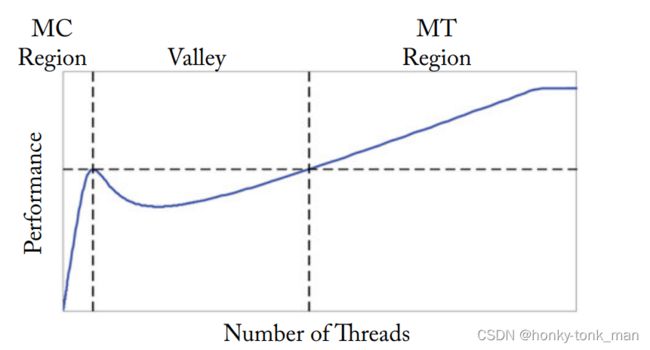
曾经在2009年Gus et al做了一个模型去分析GPU和CPU的性能,当大量的cache(on-cache)被小量的线程共享(模拟CPU,且cache是定量),然后慢慢的增加线程量,最后发现在cache不够hold整个work set的时候性能就会急剧下降(因为on-chip cache不够了会根据驱逐策略将一些内容“驱逐到”off-chip中)然后慢慢的上升(因为线程数量慢慢的增多慢慢的隐藏了off-chip的延迟),当线程增加到一定程度就变成GPU形式了,然后随着线程继续增加性能会再遇到一个瓶颈,如下图,MC(Multi Core表示模拟CPU),MT(Multithread表示模拟GPU)
programming model
CUDA的文章太多了这里就不详细的讲解CUDA怎么写,怎么使用shared_mem等知识,我们直接开始汇编
我们知道高级语言代码经过编译器翻译成汇编代码,且汇编代码本质上是处理器ISA规定了底层硬件接口的格式,汇编代码调用这些接口操作机器,但是我们GPU是另外的一个处理器,所以GPU也有自己的汇编语言,我们写cuda的时候kernel部分被nvcc翻译成PTX(或者叫做parallel thread execution ISA),也就是nvidia GPU的高级虚拟指令(high level virtual instructor),且这个汇编指令还是抽象的,因为nvidia产品线不同,每个GPU可能有着不同的"更底层的汇编"AKA SASS(streaming ASSembler),而PTX这个汇编语言是一个抽象的高级汇编语言可以适用于所有的GPU产品,PTX通过nvidia的汇编器翻译成"更底层的汇编语言"SASS
PTX和SASS打个比方,我们x86和MISP和RISC,ARM可能指令都不一样,因为要设计处理器,首先就需要有指令集,规定处理器相应操作,通过指令集去控制处理器实现相应功能。所以SASS可以看成MISP,RISC,ARM等不同指令架构的处理器,当然他们因为功能不同也有不同的汇编,那么此时我们想让我们的汇编可以跑在任何一个架构处理器上,需要抽象出一个高层次的汇编,这里PTX就是高层次的汇编
PTX汇编如下(向量相加)
1 .visible .entry _Z5saxpyifPfS_(
2 .param .u32 _Z5saxpyifPfS__param_0,
3 .param .f32 _Z5saxpyifPfS__param_1,
4 .param .u64 _Z5saxpyifPfS__param_2,
5 .param .u64 _Z5saxpyifPfS__param_3
6 )
7 {
8 .reg .pred %p<2>;
9 .reg .f32 %f<5>;
10 .reg .b32 %r<6>;
11 .reg .b64 %rd<8>;
12
13
14 ld.param.u32 %r2, [_Z5saxpyifPfS__param_0];
15 ld.param.f32 %f1, [_Z5saxpyifPfS__param_1];
16 ld.param.u64 %rd1, [_Z5saxpyifPfS__param_2];
17 ld.param.u64 %rd2, [_Z5saxpyifPfS__param_3];
18 mov.u32 %r3, %ctaid.x;
19 mov.u32 %r4, %ntid.x;
20 mov.u32 %r5, %tid.x;
21 mad.lo.s32 %r1, %r4, %r3, %r5;
22 setp.ge.s32 %p1, %r1, %r2;
23 @%p1 bra BB0_2;
24
25 cvta.to.global.u64 %rd3, %rd2;
26 cvta.to.global.u64 %rd4, %rd1;
27 mul.wide.s32 %rd5, %r1, 4;
28 add.s64 %rd6, %rd4, %rd5;
29 ld.global.f32 %f2, [%rd6];
30 add.s64 %rd7, %rd3, %rd5;
31 ld.global.f32 %f3, [%rd7];
32 fma.rn.f32 %f4, %f2, %f1, %f3;
33 st.global.f32 [%rd7], %f4;
34
35 BB0_2:
36 ret;
37 }
因为PTX是高级抽象汇编语言,所以其寄存器是无限量的,而SASS则不是
SASS汇编代码如下(nvidia fermi架构)
Address Dissassembly Encoded Instruction
2 ======== =============================================== ========================
3 /*0000*/ MOV R1, c[0x1][0x100]; /* 0x2800440400005de4 */
4 /*0008*/ S2R R0, SR_CTAID.X; /* 0x2c00000094001c04 */
5 /*0010*/ S2R R2, SR_TID.X; /* 0x2c00000084009c04 */
6 /*0018*/ IMAD R0, R0, c[0x0][0x8], R2; /* 0x2004400020001ca3 */
7 /*0020*/ ISETP.GE.AND P0, PT, R0, c[0x0][0x20], PT; /* 0x1b0e40008001dc23 */
8 /*0028*/ @P0 BRA.U 0x78; /* 0x40000001200081e7 */
9 /*0030*/ @!P0 MOV32I R5, 0x4; /* 0x18000000100161e2 */
10 /*0038*/ @!P0 IMAD R2.CC, R0, R5, c[0x0][0x28]; /* 0x200b8000a000a0a3 */
11 /*0040*/ @!P0 IMAD.HI.X R3, R0, R5, c[0x0][0x2c]; /* 0x208a8000b000e0e3 */
12 /*0048*/ @!P0 IMAD R4.CC, R0, R5, c[0x0][0x30]; /* 0x200b8000c00120a3 */
13 /*0050*/ @!P0 LD.E R2, [R2]; /* 0x840000000020a085 */
14 /*0058*/ @!P0 IMAD.HI.X R5, R0, R5, c[0x0][0x34]; /* 0x208a8000d00160e3 */
15 /*0060*/ @!P0 LD.E R0, [R4]; /* 0x8400000000402085 */
16 /*0068*/ @!P0 FFMA R0, R2, c[0x0][0x24], R0; /* 0x3000400090202000 */
17 /*0070*/ @!P0 ST.E [R4], R0; /* 0x9400000000402085 */
18 /*0078*/ EXIT; /* 0x8000000000001de7 */
因为我们说了nvidia不同的产品的底层SASS不同所以相同代码(向量相加),fermi架构如上,pascal架构的SASS如下
1 Address Dissassembly Encoded Instruction
2 ======== =============================================== ========================
3 /* 0x001c7c00e22007f6 */
4 /*0008*/ MOV R1, c[0x0][0x20]; /* 0x4c98078000870001 */
5 /*0010*/ S2R R0, SR_CTAID.X; /* 0xf0c8000002570000 */
6 /*0018*/ S2R R2, SR_TID.X; /* 0xf0c8000002170002 */
7 /* 0x001fd840fec20ff1 */
8 /*0028*/ XMAD.MRG R3, R0.reuse, c[0x0] [0x8].H1, RZ; /* 0x4f107f8000270003 */
9 /*0030*/ XMAD R2, R0.reuse, c[0x0] [0x8], R2; /* 0x4e00010000270002 */
10 /*0038*/ XMAD.PSL.CBCC R0, R0.H1, R3.H1, R2; /* 0x5b30011800370000 */
11 /* 0x081fc400ffa007ed */
12 /*0048*/ ISETP.GE.AND P0, PT, R0, c[0x0][0x140], PT; /* 0x4b6d038005070007 */
13 /*0050*/ @P0 EXIT; /* 0xe30000000000000f */
14 /*0058*/ SHL R2, R0.reuse, 0x2; /* 0x3848000000270002 */
15 /* 0x081fc440fec007f5 */
16 /*0068*/ SHR R0, R0, 0x1e; /* 0x3829000001e70000 */
17 /*0070*/ IADD R4.CC, R2.reuse, c[0x0][0x148]; /* 0x4c10800005270204 */
18 /*0078*/ IADD.X R5, R0.reuse, c[0x0][0x14c]; /* 0x4c10080005370005 */
19 /* 0x0001c800fe0007f6 */
20 /*0088*/ IADD R2.CC, R2, c[0x0][0x150]; /* 0x4c10800005470202 */
21 /*0090*/ IADD.X R3, R0, c[0x0][0x154]; /* 0x4c10080005570003 */
22 /*0098*/ LDG.E R0, [R4]; } /* 0xeed4200000070400 */
23 /* 0x0007c408fc400172 */
24 /*00a8*/ LDG.E R6, [R2]; /* 0xeed4200000070206 */
25 /*00b0*/ FFMA R0, R0, c[0x0][0x144], R6; /* 0x4980030005170000 */
26 /*00b8*/ STG.E [R2], R0; /* 0xeedc200000070200 */
27 /* 0x001f8000ffe007ff */
28 /*00c8*/ EXIT; /* 0xe30000000007000f */
29 /*00d0*/ BRA 0xd0; /* 0xe2400fffff87000f */
30 /*00d8*/ NOP; /* 0x50b0000000070f00 */
31 /* 0x001f8000fc0007e0 */
32 /*00e8*/ NOP; /* 0x50b0000000070f00 */
33 /*00f0*/ NOP; /* 0x50b0000000070f00 */
34 /*00f8*/ NOP; /* 0x50b0000000070f00 */
SIMT core内部架构
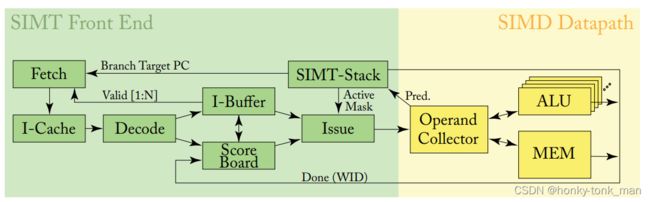
上述的pipeline可以分成2部分(绿色黄色),分别是Front-end,Back-end
我们要注意的是这里有3个“loop”
- instruction fetch loop
包括fetch指令,缓存指令到I-Cache中,decode I-Cache中的指令且缓存到I-Buffer中
- instruction issue loop
包含I-Buffer,score Board,SIMT-Stack,Issue
- register access scheduling loop
包含ALU,memory 等等
本章就围绕这三部分讲
instruction fetch loop
首先我们要明白GPU为了提升效率,其调度的最小单元是Warp,每个cycle GPU调度一个warp去执行,按照上面的图,我们知道指令被取值单元取后,缓存在I-Cache中,然后decode,decode后缓存到I-Buffer中。I-buffer中会round robin的为每一个decode后的指令分配warp,假如指令通过scoreboard的检测(检测WAW,RAW之类的问题)那么就会在I-Buffer的对应字段设置r(ready)
SIMT stack就是为了处理分支条件判断的情况而设计的,假如我们有以下的cuda代码
do{
t1 = tid*N; //A
t2 = t1 + i;
t3 = datal[t2];
t4 = 0;
if( t3 != t4 ){
t5 = data2[t2]; //B
if( t5 != t4 ){
x += 1; //C
}else{
y += 2; //D
}
}else{
z += 3; //F
}
i++; //G
}while( i < N )
上述代码的PTX汇编(做了改动,不是反编译后直接给你写上来)
A: mul.lo.u32 t1, tid, N; //tid * N存入到t1里面格式是u32,在local存储区域(每个线程独享)
add.u32 t2, t1, i;
ld.global.u32 t3, [t2];
mov.u32 t4, 0;
setp.eq.u32 p1, t3, t4;
@p1 bra F;
B: ld.global.u32 t5, [t2];
setp.eq.u32 p2, t5, t4;
@p2 bra D;
C: add.u32 x, x, 1;
bra E;
D: add.u32 y, y, 2;
E: bra G;
F: add.u32 z, z, 3;
G: add.u32 i, i, 1;
setp.le.u32 p3, i, N;
@p3 bra A;
参考下面的链接
https://docs.nvidia.com/cuda/parallel-thread-execution/index.html
https://downloads.ti.com/docs/esd/SLAU131L/Content/SLAU131L_HTML/assembler_directives.html
为什么nvidia指令会有.lo.u32这样的东西出现?首先指令后面的lo代表在local存储空间开辟.u32大小的空间存入数据,数据格式是u32大小,中间的.lo .global代表我们存放到那个cache中,最后的.u32 .b32代表我们最后存入的格式,cache类别如下
name description .reg Registers, fast. .sreg Special registers. Read-only; pre-defined; platform-specific. .const Shared, read-only memory. .global Global memory, shared by all threads. .local Local memory, private to each thread. .param Kernel parameters, defined per-grid; or Function or local parameters, defined per-thread. .shared Addressable memory, defined per CTA, accessible to all threads in the cluster throughout the lifetime of the CTA that defines it. .tex Global texture memory (deprecated).
首先根据上述的代码我们直接列出他们的分支图
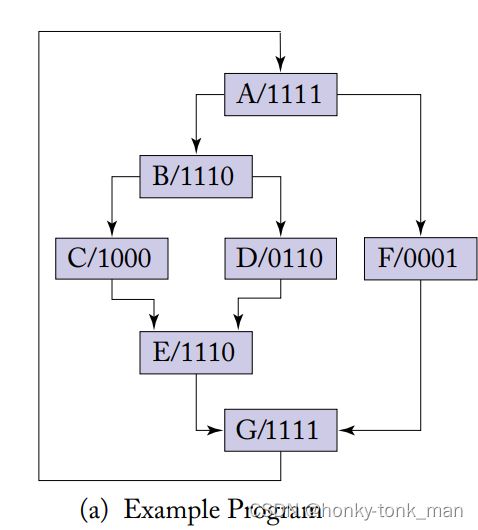
当我们执行完上述代码第六行的时候(第一个分支),SIMT stack如下
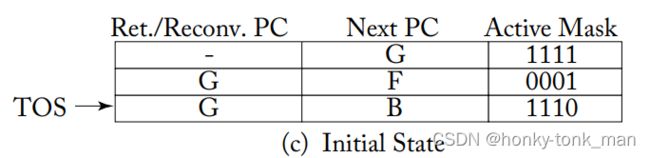
首先假设warp只有4个线程,TOS是栈顶,出栈是先从栈顶出,1110代表warp的4个线程block了最后一个,换句话说warp执行到这个分支的时候只会有前三个warp执行
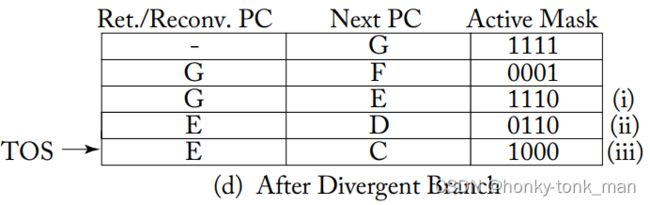
继续执行到第八行的时候又要遇到分支(此时第八行已经执行完毕),此时会弹出上图SIMT stack的TOS,然后又从TOS入栈,此时的SIMT stack如下Ⅰ,Ⅱ,Ⅲ都是新入栈的entire,第8行执行的时候要么走C,要么走D,C和D走完走E,所以TOS是C代表先走C
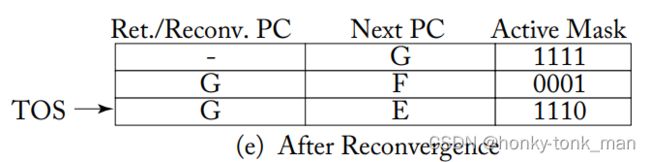
当C走完后代表着不用执行D了,那么SIMT stack连续出栈2次(POP C,D),最后SIMT Stack如下
小心SIMT死锁!
关于atomic的article看这里https://docs.nvidia.com/gameworks/content/developertools/desktop/analysis/report/cudaexperiments/kernellevel/memorystatisticsatomics.htm
我们接下来用的atomic函数是atomicCAS(A, B, num)这个是典型的自旋锁,他的意思是对比A和B假如A和B相等就讲num写入A中,这个是原子的,且返回A的原值,下面代码会引起deadlockmutex = 0; while(!atomicCAS(mutex, 0, 1)); // critical section automicExch(mutex, 0);为什么会发生死锁?,首先我们的warp执行到while的时候发现有一个atomic语句,则warp内所有的线程序列化的执行(这里不是lock-step,效率会变慢),当一个线程将mutex改为1的时候,此线程会执行while内部的语句(当然要等warp内其他的线程完成atomic操作),当其他的线程准备完成atomic操作的时候发现mutex不是等于0,而是等于1,此时其他的线程会跳过while里面的句子,执行下面的atomicExch
warp调度
假设我们在一个理想的的内存环境下,内存在某个固定的延迟下响应内存请求,那么我们可以设计充足的warp,用细颗粒读的多线程来隐藏这种延迟(当发生stall就开启一个新的warp来调度)
two-loop approximation
假设我们有2个指令A和B,B必须要先于A执行(因为A执行需要B的结果),此时B先issue给warp了,但是还没有执行完毕,A就执行了,此时在我们GPU架构中是万万不可得,因此在one-loop approximation中就这个问题解决,首先指令issue逻辑是我们只需要access这个warp的tid,还有address of next instruction,我们并不知道next instruction和这次执行的instruction是否相关,不知道着此执行的instruction是否执行完毕,所以在第一次fetch指令(从内存中)的时候dependency information就变得至关重要(假如拖到I-cache中就不好解决dependency的问题,因为此时已经将decoded的指令绑定了warp,此时只需要检查一些bit位是否合法就直接issue,scoreboard只检查WAW,RAW等问题),有了这些信息我们就知道这些hazards是否存在
在GPU中解决方法是我们搞了一个I-Buffer,I-Buffer在I-cache之前,I-Buffer有一个单独的调度器,这个调度器来决定,哪一些指令(I-Buffer中的指令)应该发布到余下的pipeline中,所以在I-Buffer的调度器中就解决了指令依赖的问题
一般来说I-Buffer是FLI(first-level instruction),I-buffer联合MSHRs来帮助我们用来降低i-cache的latency,对于I-Buffer的结构最通用的是一个warp对应多个instruction
那么我们如何探测一个warp中的instruction有依赖呢?在传统CPU架构上有2种方法
- scoreboard
- reservation stations
这里直接讲scoreboard,这个东西支持in-order excution和out of order execution(比如CDC 6600),另一方面,scoreboard对于单线程in-order CPU实现非常简单,CPU上的每个寄存器在scoreboard种都用单bit表示,当指令想写/读这个寄存器的时候,再set这个bit,当另一个instruction想写这个寄存器,必须等这个寄存器对应的bit clear后才能set(如果没有clear就stall),这样有效的预防了RAW,WAW等危害,但是在in-order multi warp就有了不小的挑战,挑战如下
- 假设一个寄存器分配一个bit,如果我们GPU每个warp有128个寄存器,一共64个warp(远远不止),那么我们一共有8192个寄存器,scoreboard为每一个寄存器分配一个bit那么就是8192个bit
- 还有一个是,假如A依赖B,只有B运行结束后,将其结果写入寄存器后,A才能访问B结果写入的寄存器,取其值使用,不然A会一直查找其操作数(operands),假设在多线程的环境下,那么多个线程可能早就被stall住,等待更早的指令完成(那么多线程怎么确定指令有没有完成呢?不断地探测scoreboard),此时问题来了,假设GPU支持64个warp,一个warp最多支持4个操作数(通常来说操作数存储在寄存器,内存中),那么scoreboard要有256个读取端口(让线程访问)
three-loop approximation
首先我们要隐藏延迟,我们应该支持单个core多warp,并且支持warp之间的切换,且我们要有一个大的register file,这个register file被分割成多个物理寄存器分配给每个warp,我们知道寄存器存储的有操作数,当我们在一个周期内一个指令想访问这个存器的操作数就需要一个端口(或者通道),但是每个周期不是只有一个指令访问一个寄存器,所以一个端口是远远不够的,但是端口做多了会使寄存器变得面积非常大,所以主流的做法是用multiple banks 模拟一个非常大数量的端口,比如operand collector如下图显示了一个原本架构的,下面的架构现实了递增的register file bandwidth
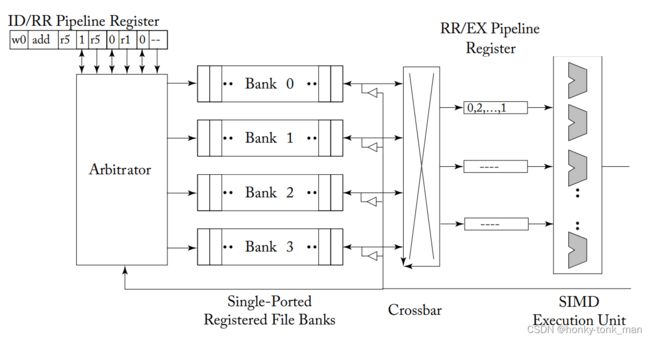
上图的register file由4个单port逻辑bank寄存器组成,注意这里写的是逻辑bank,他可能实际由非常多的物理bank组成,
- pipeline register是用来缓存operand,用于发送给SIMD执行单元的
- arbitrator用来访问每个单独的bank,并且route访问到的结果给对应的pipeline register
- bank(single-ported registerd file bank)就是我们传统意义上的寄存器
下图显示了bank的逻辑layout
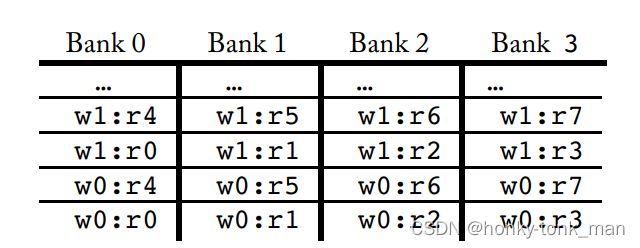
如上图register 4被warp1调用且存储在bank0中
这样设计有什么不好,我们假设有以下的2个指令
i1 mad r2, r5, r4, r6
i2 add r5, r5, r1
第一个指令是将r5(bank1中),r4(bank0),r6(bank2)都相加写入(write back)到r2(bank2)中
第二个指令是将r5(bank1中),r1(bank1)相加写入(write back)到r5中
假设decode的cycle如下,且warp操作和写回之间至少间隔一个周期(就是在没有stall的情况下从读寄存器到写回到寄存器最少3个cycle)

那么实际的执行cycle如下(一定要记住bank是单port,一个cycle只能有一个指令访问)

我们发现第一个cycle还挺正常,第一条指令完美的在bank0,bank1,bank2中执行访问,第二个周期就开始不正常了,第二个周期执行第二条指令(i2),要访问寄存器r5和r1,但是r5和r1都在bank1中,同一个cycle一个bank只能被一条指令访问,因为bank是single port的,所以指令只能访问bank1中的一个寄存器,那就r1,第三个周期访问bank1的第二个寄存器r5,并且在cycle3中第一条指令完成writeback进bank2的r2寄存器中(因为在周期3bank2的port是空的,所以可以访问)
综上所属,瓶颈就在存放寄存器的bank中,因为这4个bank,每个bank只允许在一个cycle中一个指令的操作(单端口),而bank又由多个register组成,假如操作同一个bank的不同register,则需要多个cycle
此时一种新的operand 架构由2008年提出来的如下图
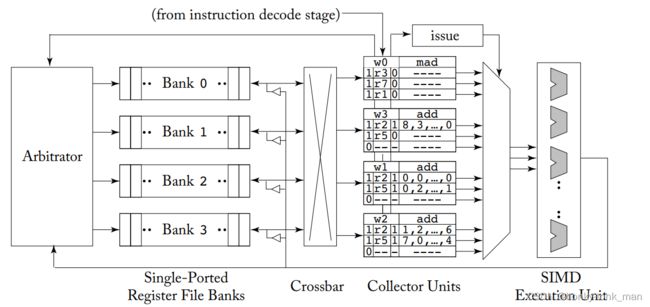
上图最大的改变是用于缓存即将发往SIMD 执行单元的operand的staging register改成了collector units,为了减少bank的冲突,还有一个ideal就是allocate equivalent register from different warps in different banks翻译成中文就是同一个register要分配给不同bank中的warp
为什么寄存器1 register1既可以存在bank1和bank2中?因为我们这里讨论的是逻辑寄存器,而非物理寄存器,逻辑寄存器根本上来说是逻辑的,他可能对应不同的物理寄存器,上述新ideal就是在一个bank中不同的逻辑寄存器不能分配给同一个warp(假设寄存器1分配给了warp1,那么后续在这个bank中寄存器1就不能再分配给warp1只能分配给不同的warp),这样大大的减少了不同warp访问同一个bank引发的冲突
如下图
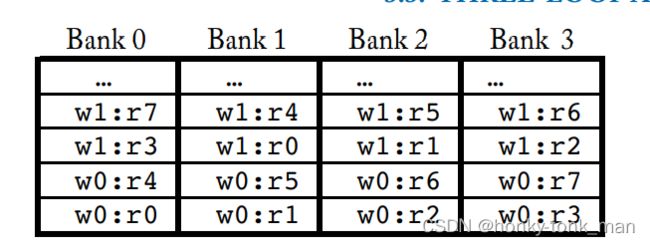
然后我们指令如下
i1: add r1, r2, r5
i2: mad r4, r3, r7, r1
我们指令的cycle如下

对应的bank访问如下
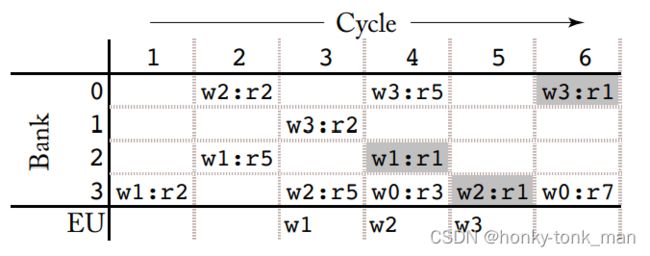
cache 架构
首先我们给出GPU的cache 组成架构,这个架构实现了shared memory和L1 data cache
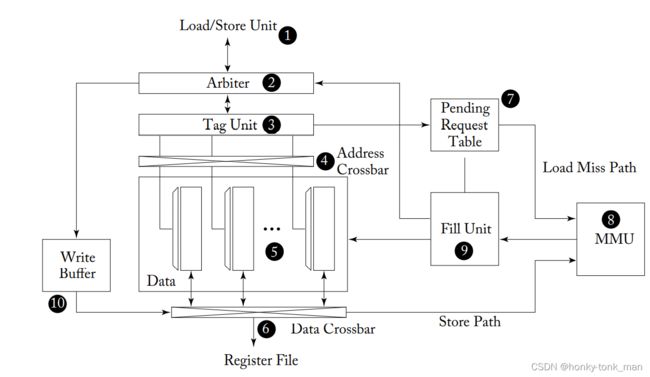
首先instruction pipeline的Load/Store unit(ldst)发送过来memory request,memory request是由多个memory 地址组成,
从上图中我们可以看到LDST单元发送过来的请求先给arbiter,arbiter先探测,LDST请求的地址会不会发生bank conflicts(因为有可能一个warp中不同的thread访问不同的线程)
这里详细说一下,我们在cuda编程的时候会提到coalesced和uncoalesced,这里coalesced就是一个warp内的所有线程都访问到一个L1data cache block中,不管命没命中,都是coalesced的,因为,命中万事大吉直接返回,没有命中就会让其中一个线程去L2cache或者global mem中取(MSHR!),假设一个warp中的所有thread访问的是不同的cache block,此时会形成多个memory access,这个就是uncoalesced
值得注意的是shared memory也会发生bank conflict,首先shared memory会被化成多个bank,这里注意的是每个bank只有一个读port,一个写port,一个cycle只允许一个thread读,写,假设多个thread同时写一个bank,或者读一个bank,那么就会发生bank conflict,发生了conflict会怎么办呢?讲其他的thread延后,放在后面的cycle执行
在写cuda的时候要避免bank conflict和uncoalesced
arbiter探测是否LDST单元发过来的一系列地址会发生shared memory bank conflict,假如发生了一个或者多个bank conflict,arbiter会讲请求split成2部分,首先的一部分是warp中thread所访问内存不会引起conflict的地址,这一部分的地址访问请求会发送给接下来的步骤,而第二部分也就是剩下的thread所需要访问的地址可能会引起bank conflict,这一部分的地址访问请求会被打回instruction pipeline中,并且要求重新执行,剩下已经被arbiter接收的shared mem 请求会在tag unit中寻找对应的shared mem是否被标记成bypass
tag unit还确定那个thread request map到了那个bank中,所以为了控制这些address crossbar(这些crossbar 分发访问地址到每个data array的bank中),且每一个data array中的ban都是32bit宽,且每个bank有自己的decoder,就是为了不相关的access不同的row in each bank,我们的数据从data crossbar中返回存储到register file中
我们的L1cache block假如有128bytes(fermi和kepler就是的,cache line就是cache block!!!),且被划分成4个32byte的sector,因为32bytes大小的sector对应着DRAM芯片(DDR5)一次最小读取的数量,且一个bank有32bit大小,一个L1 cache block有32个bank(一个sector8个bank)
LDST 单元负责warp的coalescing,LDST单元将warp的memory access 分成多个Coalescing access,然后交给arbiter,假设一些资源不可用那么arbiter就会reject,比如cache line busy(一个cycle只允许一个线程读或者写,因为cache data只有2个端口,一个负责读,一个负责写),且上图的pending request table满了(pending request table就是缓存请求),还有一个情况是cache data可用,但是cache miss,此时,arbiter会返回一些writeback到instruction pipeline的相应寄存器中,告诉instruction pipeline在未来再访问相同的数据需要花费固定的cycle才能cache hit,arbiter如何判定request会miss或者hit?通过tag unit…
当cache hit后上图的data array中会返回对应的row给instruction pipeline的register file
假设cache miss,首先由arbiter探测到,当cache miss发生后,arbiter会同时干2个事情,第一是informs LDST unit(通知LDST单元发生cache miss了),第二件事情是将请求的信息缓存到PRT(上图的pending request table),此时你会发现PRT有点像CPU中的MSHR(其实一些GPGPU架构中也有MSHR,比如GPGPU-Sim中就有…),在nvidia中关于这个PRT至少有2个版本,第一个有点像传统的MSHR
传统的MSHR每一个entries包含cache miss的那个cache block(cache line) address
下面开始将L1data cache,在学习L1data cache之前建议先看一下这篇微信公众号的文章,了解什么是VIVT,VIPT,PIPT等概念
CPU大多数的实现方式是VIPT,也就是Virtual Index Physical tag(取虚拟地址的index,然后转换成物理地址取tag),