论文阅读:CSPNet: A NEW BACKBONE THAT CAN ENHANCE LEARNING CAPABILITY OF CNN
文章目录
-
-
- 1、论文总述
- 2、深度可分离卷积的局限性
- 3、CSPNet用于目标检测时关注的3个问题
- 4、CSPNet用在denseNet上时的对比示意
- 5、Real-time object detector的现阶段发展情况
- 6、Partial Transition Layer的几种形式及效果对比
- 7、Apply CSPNet to Other Architectures
- 8、Exact Fusion Model(EFM)的结构及其效果
- 9、CSPNet在三种设备上的不同配置
- 10、CSPNet在COCO数据集上与其他模型的对比
- 11、COCO test-Dev上的sota模型
- 参考文献
-
1、论文总述
CSPNet全称是Cross Stage Partial Network
本篇论文的出发点是要提升CNN的学习能力,大致思想是减少反向传播时的梯度的重复(梯度组合更加丰富同时还能减少计算量),实现方式是通过将浅层的feature map一分为二(这个分就是CSP中的P:Partial ),一半去经历block,一半是直接concat到block的output;阅读论文时感觉有点晦涩,解释的不是很通俗,基于CSPnet-backbone的目标检测模型现在在COCO test-dev上的精度是第一位,但是论文中作者强调的是基于CSPNet的模型推理速度快(在GPU 1080Ti 以及 mobile GPU Nvidia Jeson TX2 以及 Intel CPU上),而且占用内存的带宽少 ,作者并没有用FLOPS这个假指标来验证提出的模型的推理速度和内存占用;作者是台湾中央研究院的团队,使用的框架是DarkNet,而且从论文中可以隐隐约约的感觉到作者是YOLO系列的粉丝或者和他们有合作,在论文中,作者也是比较重视模型在真实世界的实用性,也比较倾向于AP50这个指标,并不想用COCO的mAP(这个对定位要求很严格的指标)。
In this paper, we propose Cross Stage Partial Network (CSPNet) to mitigate the problem(推理速度慢) that previous
works require heavy inference computations from the network architecture perspective. We attribute
the problem to the duplicate gradient information within network optimization. The proposed
networks respect the variability of the gradients by integrating feature maps from the beginning and
the end of a network stage, which, in our experiments, reduces computations by 20% with equivalent
or even superior accuracy on the ImageNet dataset, and significantly outperforms state-of-the-art
approaches in terms of AP50 on the MS COCO object detection dataset.
In this study, we introduce Cross Stage Partial Network (CSPNet). The main purpose of designing CSPNet is to enable this architecture to achieve a richer gradient combination while reducing the amount of computation.
This aim is achieved by partitioning feature map of the base layer into two parts and then merging them through a proposed
cross-stage hierarchy. Our main concept is to make the gradient flow propagate through different network paths
by splitting the gradient flow. In this way, we have confirmed that the propagated gradient information can have a
large correlation difference by switching concatenation and transition steps. In addition, CSPNet can greatly reduce
the amount of computation, and improve inference speed as well as accuracy, as illustrated in Fig 1.
CSPNet在分类数据集和检测数据集上的效果图
注:分类上提升不大,检测数据集上提升比较明显

2、深度可分离卷积的局限性
Light-weight computing has gradually received
stronger attention since real-world applications usually require short inference time on small devices, which poses a serious challenge for computer vision algorithms. Although some approaches were designed exclusively for mobile
CPU [9, 31, 8, 33, 43, 24], the depth-wise separable convolution techniques they adopted are not compatible with industrial IC design such as Application-Specific Integrated Circuit (ASIC) for edge-computing systems.
3、CSPNet用于目标检测时关注的3个问题
1) Strengthening learning ability of a CNN
The accuracy of existing CNN is greatly degraded after lightweightening,
so we hope to strengthen CNN’s learning ability, so that it can maintain sufficient accuracy while being lightweightening.
2) Removing computational bottlenecks
Too high a computational bottleneck will result in more cycles to complete
the inference process, or some arithmetic units will often idle. Therefore, we hope we can evenly distribute the amount
of computation at each layer in CNN so that we can effectively upgrade the utilization rate of each computation unit (提升每个计算单元的利用率)
and thus reduce unnecessary energy consumption. It is noted that the proposed CSPNet makes the computational
bottlenecks of PeleeNet [37] cut into half.
3) Reducing memory costs
The wafer fabrication(晶片制造) cost of Dynamic Random-Access Memory (DRAM) is very expensive,
and it also takes up a lot of space. If one can effectively reduce the memory cost, he/she will greatly reduce the cost of ASIC. In addition, a small area wafer can be used in a variety of edge computing devices. In reducing the use of memory usage, we adopt cross-channel pooling [6] (MaxOut?)to compress the feature maps during the feature pyramid generating process.(可能就是后文提出的EFM?)
In this way, the proposed CSPNet with the proposed object detector can cut down 75% memory usage on PeleeNet when generating feature pyramids.
4、CSPNet用在denseNet上时的对比示意
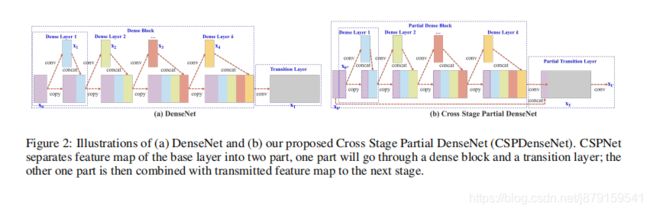
denseNet的前向传播和反向传播时的w权重更新:

denseNet的问题所在:
where f is the function of weight updating, and gi represents the gradient propagated to the ith dense layer. We can find that large amount of gradient information are reused for updating weights of different dense layers. This will result in different dense layers repeatedly learn copied gradient information.(问题所在:不同的层重复的学习同一份梯度信息)
Cross Stage Partial DenseNet:

5、Real-time object detector的现阶段发展情况
The most famous two real-time object detectors are YOLOv3 [29] and SSD [21]. Based on
SSD, LRF [38] and RFBNet [19] can achieve state-of-the-art real-time object detection performance on GPU.
Recently,anchor-free based object detector [3, 45, 13, 14, 42] has become main-stream object detection system. Two object detector of this sort are CenterNet [45] and CornerNet-Lite [14], and they both perform very well in terms of efficiency and efficacy.
For real-time object detection on CPU or mobile GPU, SSD-based Pelee [37], YOLOv3-based PRN [35](注:PRN的作者和本文的作者是同一个团队,而且文章的思想也很像),and Light-Head RCNN [17]-based ThunderNet [25] (旷视团队)all receive excellent performance on object detection.
6、Partial Transition Layer的几种形式及效果对比


7、Apply CSPNet to Other Architectures

8、Exact Fusion Model(EFM)的结构及其效果
注:EFM根据anchor-size进行特征融合
1)Looking Exactly to predict perfectly.
We propose EFM that captures an appropriate Field of View (FoV) for each
anchor, which enhances the accuracy of the one-stage object detector.
2)Aggregate Feature Pyramid.
The proposed EFM is able to better aggregate the initial feature pyramid. The EFM
is based on YOLOv3 [29], which assigns exactly one bounding-box prior to each ground truth object. Each ground truth bounding box corresponds to one anchor box that surpasses the threshold IoU. If the size of an anchor box is
equivalent to the FoV of the grid cell, then for the grid cells of the s
th scale, the corresponding bounding box will be
lower bounded by the (s-1)th scale and upper bounded by the (s + 1)th scale.
Therefore, the EFM assembles features from the three scales.(EFM这么设计的原因在此:根据anchor的感受野)
3)Balance Computation.
Since the concatenated feature maps from the feature pyramid are enormous, it introduces
a great amount of memory and computation cost. To alleviate the problem, we incorporate the Maxout technique to compress the feature maps.(注意:用了个Maxout骚操作,具体 用法请百度)
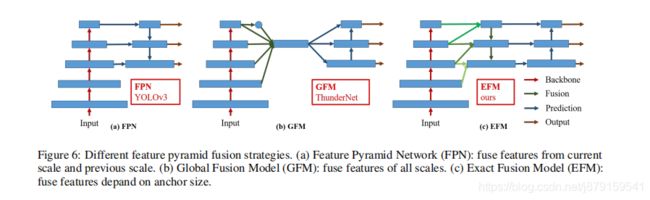
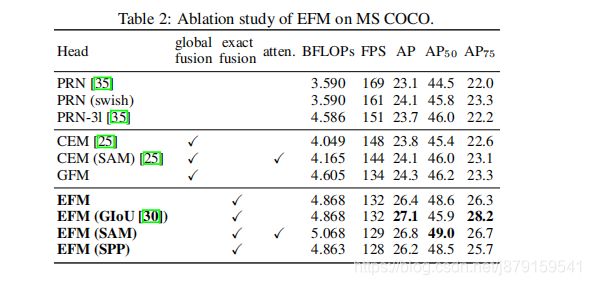
EFM在mobile GPU(TX2之类的)上有优势(所以EFM模块在mobileGPU上对比时才会使用,否则就是CSPNet加上PANet):
If we compare the inference speed executed on mobile GPU, our proposed EFM will be a good model to use. Since our proposed EFM can greatly reduce the memory requirement when generating feature pyramids, it is definitely beneficial
to function under the memory bandwidth restricted mobile environment.
For example, CSPPeleeNet Ref.-EFM (SAM) can have a higher frame rate than YOLOv3-tiny, and its AP50 is 11.5% higher than YOLOv3-tiny, which is significantly upgraded.
For the same CSPPeleeNet Ref. backbone, although EFM (SAM) is 62 fps slower than PRN (3l) on GTX 1080ti, it reaches 41 fps on Jetson TX2, 3 fps faster than PRN (3l), and at AP50 4.6% growth.
9、CSPNet在三种设备上的不同配置
In the task of object detection, we aim at three targeted scenarios:
(1) real-time on GPU: we adopt CSPResNeXt50 with
PANet (SPP) [20];
(2) real-time on mobile GPU: we adopt CSPPeleeNet, CSPPeleeNet Reference, and CSPDenseNet
Reference with the proposed EFM (SAM);
and (3) real-time on CPU: we adopt CSPPeleeNet Reference and CSPDenseNet Reference with PRN [35]. The comparisons between the above models and the state-of-the-art methods
are listed in Table 4. As to the analysis on the inference speed of CPU and mobile GPU will be detailed in the next subsection.
10、CSPNet在COCO数据集上与其他模型的对比
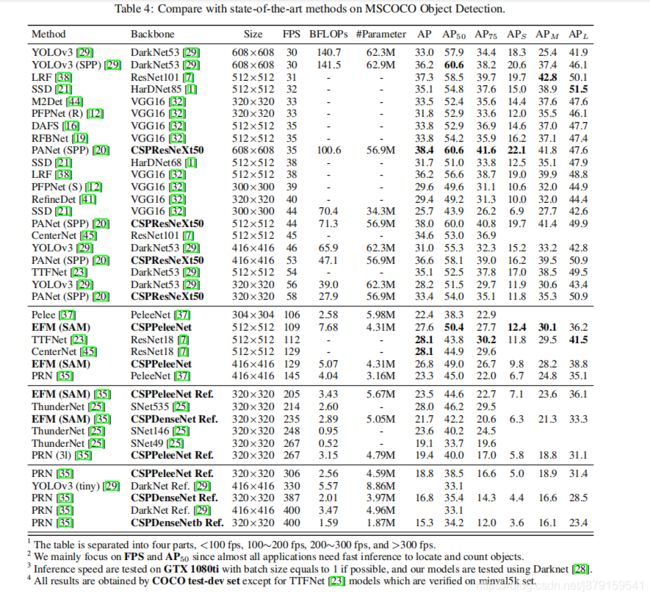
11、COCO test-Dev上的sota模型

参考文献
1、增强CNN学习能力的Backbone:CSPNet