Java集合常见面试题
Java集合
-
-
- 1.集合关系
- 2.什么是集合?集合和数组的区别?
- 3.List、Set、Map的区别
- 4.集合底层数据结构
- 5.Java集合的快速失败机制 “fail-fast”?
- 6.List常用方法
- 7.List 的三种遍历方式
- 8.ArrayList扩容
- 9.Vector扩容
- 10.Set常用方法
- 11.HashSet是如何保证数据不重复的?
- 12.HashMap的底层实现原理
- 13.HashMap的put原理
- 14.关于hash函数
- 15.HashMap的数组长度为什么要取2的整数幂
- 16.如何解决hash冲突?
- 17.Map扩容机制
- 18.Map扩容后的元素位置是怎么确定的?
- 19.JDK1.7的HashMap死循环知道吗
- 20.说一说LinkedHashSet
- 21.Map接口的特点
- 22.Map的遍历方式
- 23.说一说Hashtable
- 24.说一说Properties
- 25.说一说红黑树
- 26.HashMap 和 ConcurrentHashMap的区别
- 27.TreeMap
- 28.Collections工具类
- 29.集合底层的具体实现类
-
本文是参考:集合容器面试题(2021优化版)及自己的集合学习笔记整理(基于jdk1.8)
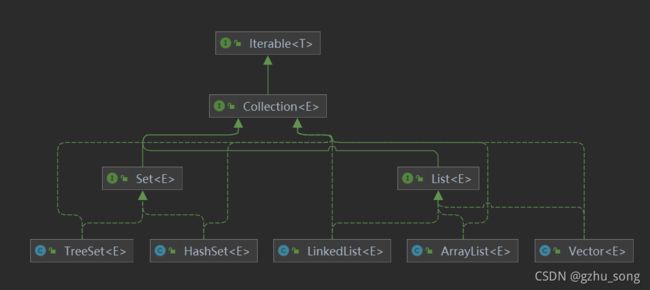
1.集合关系
单列集合:
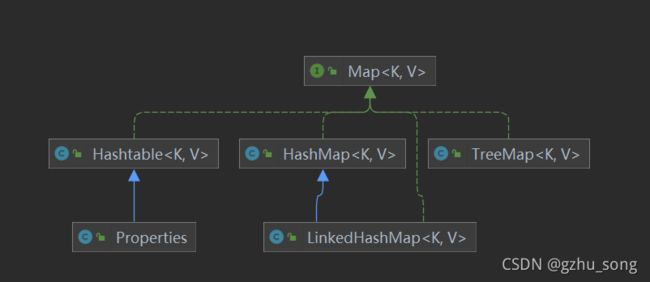
双列集合:
2.什么是集合?集合和数组的区别?
集合:用于存储数据的容器
集合和数组的区别
-
数组是固定长度的;集合是可变长度的
-
数组可以存储基本数据类型,也可以存储引用数据类型;集合只能存储引用数据类型(类、接口、数组),例如储存数字1实际上先进行装箱了
-
数组是Java语言中内置的数据类型,是线性排列的,执行效率和类型检查都比集合快,集合提供了众多的属性和方法,方便操作
联系:通过集合的toArray()方法可以将集合转换为数组,通过Arrays.asList()方法可以将数组转换为集合
Arrays.asList()适用于对象型数据类型,不适用于基本数据类型,而且用这种方法得到的集合长度是不可变的,不支持add()、remove()、clear()等方法
public class AsList {
public static void main(String[] args) {
String[] array = new String[] {"pig", "dog", "hello"};
// String数组转List集合,asList只适用于引用数据类型
List<String> mlist = Arrays.asList(array);
System.out.println(mlist);
List<String> list = new ArrayList<>();
list.add("zhang");
list.add("liu");
list.add("wang");
// List转成数组,用toArray()
String[] arr = mlist.toArray(new String[0]);
for (int i = 0;i < arr.length;i++){
System.out.println(arr[i]);
}
}
}
3.List、Set、Map的区别
List:一个有序(元素存入集合的顺序和取出的顺序一致)容器,元素可以重复,可以插入多个null元素,元素都有索引。常用的实现类有 ArrayList、LinkedList 和 Vector。ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;Vector 使用了 synchronized 来实现线程同步,是线程安全的
面试:ArrayList、LinkedList、Vector 有何区别?
-
数据结构实现:ArrayList 和 Vector 是动态数组的数据结构实现,而 LinkedList 是双向链表的数据结构实现
-
随机访问效率:ArrayList 和 Vector 比 LinkedList 在根据索引随机访问的时候效率要高,因为 LinkedList 是链表数据结构,需要移动指针从前往后依次查找
-
增加和删除效率:在非尾部的增加和删除操作,LinkedList 要比 ArrayList 和 Vector 效率要高,因为 ArrayList 和 Vector 增删操作要影响数组内的其他数据的下标,需要进行数据搬移。因为 ArrayList 非线程安全,在增删元素时性能比 Vector 好
-
内存空间占用:一般情况下LinkedList 比 ArrayList 和 Vector 更占内存,因为 LinkedList 的节点除了存储数据,还存储了两个引用,分别是前驱节点和后继节点
-
线程安全:ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;Vector 使用了 synchronized 来实现线程同步,是线程安全的
-
扩容:ArrayList 和 Vector 都会根据实际的需要动态的调整容量,只不过在 Vector 扩容每次会增加 1 倍容量,而 ArrayList 只会增加 50%容量
-
使用场景:在需要频繁地随机访问集合中的元素时,推荐使用 ArrayList,希望线程安全的对元素进行增删改操作时,推荐使用Vector,而需要频繁插入和删除操作时,推荐使用 LinkedList
Set:一个无序(存入和取出顺序有可能不一致)容器,不可以存储重复元素,只允许存入一个null元素,必须保证元素唯一性。常用实现类有 HashSet、LinkedHashSet 以及 TreeSet
Queue/Deque,则是 Java 提供的标准队列结构的实现,除了集合的基本功能,它还支持类似先入先出(FIFO, First-in-First-Out)或者后入先出(LIFO,Last-In-First-Out)等特定行为。常用实现类有ArrayDeque、ArrayBlockingQueue、LinkedBlockingDeque
队列的实现:Queue<> queue = new LinkedList<>();
入队:queue.offer("a"); 出队:queue.poll();
双端队列的实现 :Deque deque = new ArrayDeque<>();
addLast()、addFirst()、pollLast()、poolFirst()
Map是一个键值对集合,存储键和值之间的映射。Key无序,唯一;value 不要求有序,允许重复。Map没有继承Collection接口,从Map集合中检索元素时,只要给出键对象,就能返回对应的值对象。常用实现类有HashMap、LinkedHashMap、ConcurrentHashMap、TreeMap、HashTable
Map遍历
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<>();
map.put("CHN",1);
map.put("USA",2);
map.put("ABC",3);
map.forEach((key,value)->{
System.out.println("K="+key+" "+"V="+value);
});
}
4.集合底层数据结构
List
-
Arraylist:Object数组
-
LinkedList:双向链表
-
Vector:Object数组
Set
- HashSet(无序,唯一):基于 HashMap 实现,底层采用 HashMap 的key来保存元素
- LinkedHashSet:LinkedHashSet 继承于 HashSet,并且其内部是通过 LinkedHashMap 来实现的
- TreeSet(有序,唯一):红黑树(自平衡的排序二叉树)
Map
-
HashMap:JDK1.8之前HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8),但是数组长度小于64时会首先进行扩容,否则会将链表转化为红黑树,以减少搜索时间
-
LinkedHashMap:LinkedHashMap 继承自 HashMap,它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得LinkedHashMap可以保持键值对的插入顺序。
-
HashTable:数组+链表组成的,数组是 HashTable 的主体,链表则是主要为了解决哈希冲突而存在的
-
TreeMap:红黑树(自平衡的排序二叉树)
5.Java集合的快速失败机制 “fail-fast”?
fail-fast 机制是java集合(Collection)中的一种错误机制。当多个线程对同一个集合的内容进行操作时,就可能会产生 fail-fast 事件。例如:当某一个线程A通过 iterator 去遍历某集合的过程中,若该集合的内容被其他线程所改变了;那么线程A访问集合时,就会抛 ConcurrentModificationException 异常,产生 fail-fast 事件
原因:迭代器在遍历时,ArrayList的父类AbstarctList中有一个modCount变量,每次对集合进行修改时都会modCount++,而foreach的实现原理其实就是Iterator,ArrayList的Iterator中有一个expectedModCount变量,该变量会初始化和modCount相等,每当迭代器使用hashNext()/next()遍历下一个元素之前,都会检测modCount的值和expectedmodCount的值是否相等,如果集合进行增删操作,modCount变量就会改变,就会造成expectedModCount!=modCount,此时就会抛出ConcurrentModificationException异常
解决办法:在遍历过程中,所有涉及到改变modCount值的地方全部加上synchronized。
当然,不仅是多个线程,单个线程也会出现 fail-fast 机制,包括 ArrayList、HashMap 无论在单线程和多线程状态下,都会出现 fail-fast 机制,即上面提到的异常。在单线程下,在使用迭代器进行遍历的情况下,如果调用 ArrayList 的 remove 方法,此时会报 ConcurrentModificationException 的错误,从而产生 fail-fast 机制
6.List常用方法
public class ListTest {
@SuppressWarnings("all")
public static void main(String[] args) {
List<String> list = new ArrayList();
// 1.List有序且可以重复
list.add("kun");
list.add("kun");
list.add("song");
list.add("guangzhou");
System.out.println(list);
// remove 多个重复移除第一个
list.remove("kun");
// List支持索引添加
list.add(0,"zhang");
System.out.println(list);
// Object remove(int index):移除指定 index 位置的元素
list.remove(0);
System.out.println("list=" + list);
// 批量索引添加
List<String> list2 = new ArrayList();
list2.add("liu");
list2.add("yao");
list.addAll(0,list2);
System.out.println(list);
// containsAll:查找多个元素是否都存在
System.out.println(list.containsAll(list2));//T
// removeAll:删除多个元素
list.removeAll(list2);
System.out.println("list=" + list);
// int indexOf(Object obj):返回 obj 在集合中首次出现的位置
System.out.println(list.indexOf("song"));
// int lastIndexOf(Object obj):返回 obj 在当前集合中末次出现的位置
System.out.println(list.lastIndexOf("kun"));
// Object get(int index):获取指定 index 位置的元素
System.out.println(list.get(2));
// Object set(int index, Object ele):设置指定 index 位置的元素为 ele , 相当于是替换.
list.set(1, "hao");
System.out.println("list=" + list);
//contains:查找元素是否存在
System.out.println(list.contains("kun"));//T
// isEmpty:判断是否为空
System.out.println(list.isEmpty());//F
// List subList(int fromIndex, int toIndex):返回从 fromIndex 到 toIndex 位置的子集合 // 注意返回的子集合
// fromIndex <= subList < toIndex
List returnlist = list.subList(0, 2);
System.out.println("returnlist=" + returnlist);
// 集合大小
System.out.println(list.size());
// clear:清空
list.clear();
}
}
7.List 的三种遍历方式
①.iterator迭代器遍历
1.Iterator对象称为迭代器,主要用于遍历Collection集合中的元素。
2.所有实现了Collection接口的结合都会有一个iterator()方法,用以返回一个实现了Iterator接口的对象,即可以返回一个迭代器。
3.Iterator仅用于遍历集合,本身并不存在对象。
该方法位于Iterable接口内
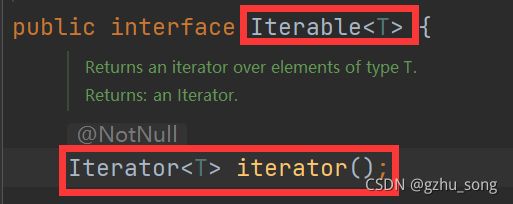
Iterator接口有三个方法,分别是
hasNext():判断是否有下一个元素
next():返回下一个元素值
remove():在删除元素时不破坏遍历
在调用Iterator.next()方法之前必须调用iterator.hasNext()进行检测,不调用则下一条记录无效并抛出异常
初始状态:
迭代器演示:
package com.gzhu.collection;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class CollectionIterator {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("a");
list.add("b");
list.add("c");
// 实例化迭代器
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
// 读取当前集合数据元素
String str=iterator.next();
if("b".equals(str)){
// 使用集合当中的remove方法对当前迭代器当中的数据元素值进行删除操作(注:此操作将会破坏整个迭代器结构)使得迭代器在接下来将不会起作用
// 但迭代器中的remove不会破坏遍历
iterator.remove();
}else{
System.out.println( str+" ");
}
}
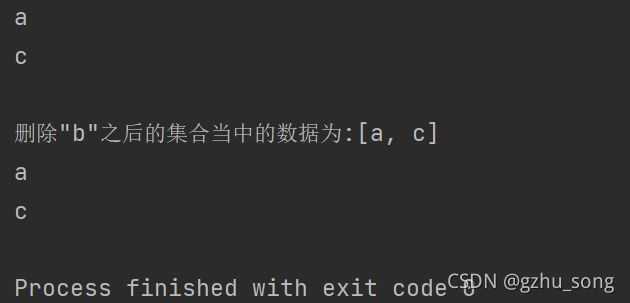
System.out.println("\n删除\"b\"之后的集合当中的数据为:"+list);
// 如果希望再次遍历,需要重置我们的迭代器 iterator = list.iterator()
iterator = list.iterator();
while(iterator.hasNext()){
//读取当前集合数据元素
String str=iterator.next();
System.out.println( str+" ");
}
}
}
②.增强for
public class CollectionFor {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("a");
list.add("b");
list.add("c");
for(String item : list){
System.out.printf(item);
}
}
}
③.普通for
8.ArrayList扩容
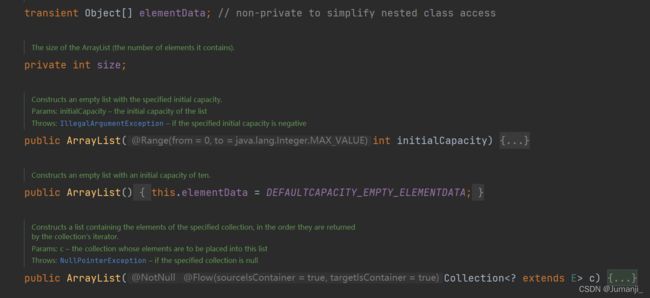
通过ArrayList源码可以看到,ArrayList维护了一个Object类型的数组elementData,transient是Java语言的关键字,用来表示一个成员变量不是该对象序列化的一部分。当一个对象被序列化的时候,transient型变量的值不包括在序列化的结果中。 ArrayList 实现了 Serializable 接口,这意味着 ArrayList 支持序列化。transient 的作用是不希望 elementData 数组被序列化,重写了 writeObject 实现:每次序列化时,先调用 defaultWriteObject() 方法序列化 ArrayList 中的非 transient 元素,然后遍历 elementData,只序列化已存入的元素,这样既加快了序列化的速度,又减小了序列化之后的文件大小
ArrayList的扩容机制
ArrayList有三个构造器,当创建ArrayList对象时,如果使用无参构造器,则初始elementData容量为0,第一次添加,则扩容为10,如需再次扩容,则扩容elemnetData为原始的1.5倍,如果扩充完还不够,就使用需要的长度作为elementData的长度
public boolean add(E e) {
// 添加元素前确保容量足够
ensureCapacityInternal(size + 1); // Increments modCount!!
// 添加元素
elementData[size++] = e;
return true;
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
// 初始化返回DEFAULT_CAPACITY = 10
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
// 初始化minCapacity = 10
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code 初始化10 - 0 > 0
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
// 初始化oldCapacity=0,newCapacity = 0
// 第二次扩容oldCapacity = 10
int oldCapacity = elementData.length;
// 第二次扩容oldCapacity = 10 + 10/2 = 15
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 初始化0 - 10 < 0
if (newCapacity - minCapacity < 0)
// newCapacity = 10,初始化完成
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
// 扩容数组
elementData = Arrays.copyOf(elementData, newCapacity);
}
如果使用指定大小的构造器,则初始elementData大小为指定大小,如需再次扩容,则直接扩容1.5倍
9.Vector扩容
Vector如果无参,默认是10,扩容2倍扩容。如果指定大小,满后2倍扩容。
可以通过有参构造器修改capacityIncrement(默认是0)来改变扩容的大小
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
10.Set常用方法
Set常用方法和List一样,不再赘述
public class SetTest {
public static void main(String[] args) {
HashSet<Object> set = new HashSet<>();
set.add(1);
set.add(2);
set.add(null);
set.add(null);
set.add("song");
set.add(new HashSet<>());
System.out.println(set);
// 方式1.迭代器遍历
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println("obj=" + obj);
}
set.remove(null);
// 方式 2: 增强 for
System.out.println("=====增强 for====");
for (Object o : set) {
System.out.println("o=" + o);
}
// set 接口对象,不能通过索引来获取
}
}
// 结果:[null, song, [], 1, 2]
// 不能存放重复元素,可以存一个null,存取顺序不一样
11.HashSet是如何保证数据不重复的?
HashSet会先计算对象的hashcode值来判断对象加入的位置,同时也会和其他加入的对象的hashcode值作比较,如果没有相同的hashcode,HashSet会假设对象没有重复出现,但是如果发现有相同的hashcode值的对象,这时候会调用equals方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让加入操作成功,我们可以重写equals方法~
12.HashMap的底层实现原理
在Java中,保存数据有两种比较简单的数据结构:数组和链表。数组的特点是:寻址容易,插入和删除困难;链表的特点是:寻址困难,但插入和删除容易;所以我们将数组和链表结合在一起,发挥两者各自的优势,使用一种叫做拉链法的方式可以解决哈希冲突。相比于之前的版本,jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8),但是数组长度小于64时会首先进行扩容,否则会将链表转化为红黑树,以减少搜索时间,当红黑树节点小于6时会转化成链表
13.HashMap的put原理
1.判断table是否为空,为空进行初始化,第一次添加元素时,table数组扩容到16,临界值threshold是16 * 0.75=12
HashMap的初始化问题
一般如果new HashMap() 不传值,默认大小是16,负载因子是0.75(负载因子是0.75的时候,空间利用率比较高,而且避免了相当多的Hash冲突,使得底层的链表或者是红黑树的高度比较低,提升了空间效率), 如果自己传入初始大小k,初始化大小为大于k的2的整数次方,例如如果传10,大小为16
2.不为空,通过hash(key)计算k的hash值,通过(table.length - 1) & hash(key)计算应当存放在table中的下标 index
3.查看 table[index] 是否存在数据,没有数据就构造一个Node节点存放在 table[index] 中
4.存在数据,说明发生了hash冲突(存在两个节点key的hash值一样), 继续判断key是否相等或者equals返回真,用新的value替换原数据(onlyIfAbsent为false)
p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))
5.如果不相等,判断当前节点类型是不是树型节点,如果是树型节点,创造树型节点插入红黑树中
if (p instanceof TreeNode) e = ((TreeNode
6.如果不是树型节点,循环比较链表,都不相同,创建普通Node加入链表尾;判断链表长度是否大于 8, 并且table的大小>=64,都满足就会进行红黑树转化,否则仍采用数组扩容机制
14.关于hash函数
hash函数的设计
hash函数是先拿到通过key的hashcode,是32位的int值,然后让hashcode的高16位和低16位进行异或操作,hashcode和hashcode无符号右移16位异或
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
函数的好处
①能降低hash碰撞
②采用位运算高效,提升效率
为什么要这样设计hash函数,直接用自带的hash函数不行吗?
肯定不行的,key.hashCode()函数调用的是key键值类型自带的哈希函数,返回int型散列值。int值范围为-2147483648~2147483647,前后加起来大概40亿的映射空间。只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个40亿长度的数组,内存是放不下的
右位移16位,正好是32bit的一半,在低16位,自己的高半区和低半区做异或(a,b进行位运算,有4种可能 00,01,10,11 a或b计算 结果为1的几率为3/4,0的几率为1/4 a与b计算 结果为0的几率为3/4,1的几率为1/4, a亦或b计算 结果为1的几率为1/2,0的几率为1/2 所以,进行亦或计算,得到的结果肯定更为平均,不会偏向0或者偏向1,更为散列),就是为了混合原始哈希码的高位和低位,使32位全部参与运算,变相保留高位的信息,以此来加大低位的随机性,同时前16位与0000 0000 0000 0000进行异或,保证结果为0的几率为1/2,1的几率为1/2,也是平均的
15.HashMap的数组长度为什么要取2的整数幂
首先我们要知道,真正的table下标是经过return hash(key) & (length-1);得来的,这样(数组长度-1)正好相当于一个“低位掩码”。&操作的结果就是散列值的高位全部归零,只保留都是1的低位值,这样hash(key)只要有一位发生了变化,都会对散列结果有影响,以此来减少冲突。例如:16-1=15,2进制表示是00000000 00000000 00001111,和某散列值做&操作如下,结果就是截取了最低的四位值,由于经过hash(key)的运算加大了低位的随机性,所以会使散列的更为随机
16.如何解决hash冲突?
1.使用拉链法(使用散列表)来链接拥有相同hash值的数据
2.使用2次扰动函数(hash函数)来降低哈希冲突的概率,使得数据分布更平均
3.引入红黑树进一步降低遍历的时间复杂度,使得遍历更快
17.Map扩容机制
HashSet底层是HashMap,第一次添加元素时,table数组扩容到16,临界值threshold是16 * 0.75=12。如果table中有12个元素这里的12并不是说16个位置用了12个,而是指整个table添加了12个元素!!++size>threshold或者某一个table[i]的链表节点个数 > 8,就会扩容到16 * 2=32,新的临界值就是32*0.75=24,以此类推(特别,如果链表节点数量为9,扩容一次,下一次又加了一个节点,会接着再次扩容)。在Java8中,如果一条链表的元素个数超过了8,并且table的大小>=64,就会进行红黑树转化,否则仍采用数组扩容机制
18.Map扩容后的元素位置是怎么确定的?
jdk1.8,是根据在同一个桶的位置中进行判断(e.hash & oldCap)是否为0,为0,停留在原始位置,不为0,移动到原始位置+旧容量的位置
19.JDK1.7的HashMap死循环知道吗
由于1.7使用头插法,所以单线程扩容后元素位置会倒置,这时候是没有问题的,原则:扩容后本来我的next却指向我(结合图片,明白这句话,死循环发生的根本原因)
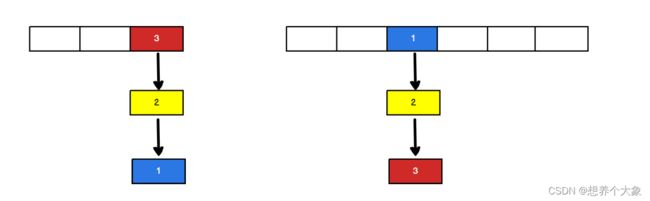
当有两个线程都要都要扩容时,就会发生死循环,有两个线程T1和T2都指向3,其next都指向2,假设在这时线程T2的时间片用完了,休眠了,而线程T1正常扩容,扩容后变成了第二张图的样子
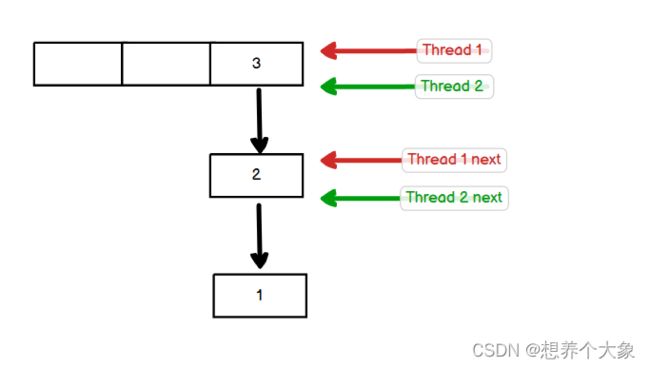
线程T2对线程T1的操作不可知,因此T2的指针指向并没有改变!

那此时T2首先执行3节点,因为3的next是2,所以下一次2指向3,插入2以后,2的next是3,所以3又指向了2,死循环就来了
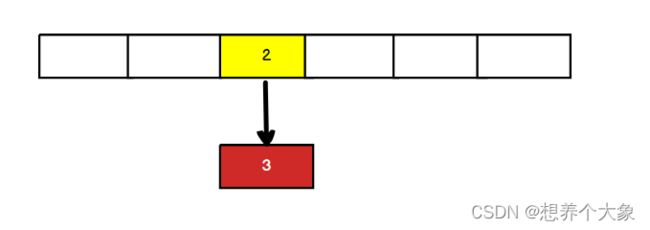
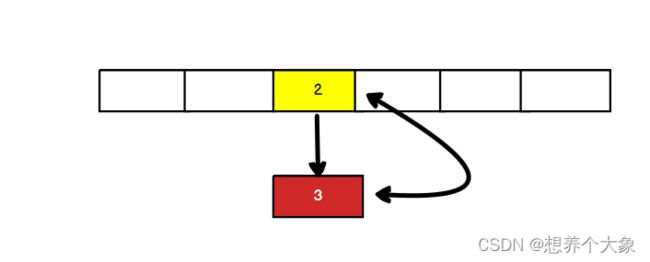
解决办法:使用ConcurrentHashMap或者HashTable(性能低)
20.说一说LinkedHashSet
LinkedHashSet是HashSet的子类,底层是一个LinkedHashMap,底层是一个Entry类,保留了HashMap的Node内部类,实现了数组+链表/红黑树的方式,同时有before、after实现双链表保证有序。LinkedHashSet根据hashCode值来决定元素的存储位置,同时使用双链表维护元素的次序,这样使得元素看起来是以插入顺序保存的。LinkedHashSet在迭代访问Set中的全部元素时,性能比HashSet好,但是插入时性能稍微逊色于HashSet

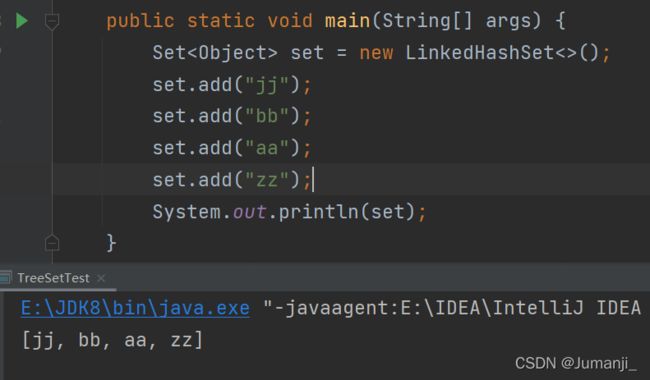
21.Map接口的特点
1.Map 与 Collection 并列存在。用于保存具有映射关系的数据:Key-Value(双列元素)
2. Map 中的 key 和 value 可以是任何引用类型的数据,会封装到 HashMap$Node 对象中
3. Map 中的 key 不允许重复,原因和 HashSet 一样
4. Map 的 key 可以为 null, value 也可以为 null ,注意 key 为 null, 只能有一个,value 为 null ,可以多个
6. 常用 String 类作为 Map 的 key
7. key 和 value 之间存在单向一对一关系,即通过指定的 key 总能找到对应的 value
22.Map的遍历方式
public class MapFor {
public static void main(String[] args) {
Map map = new HashMap();
map.put(1,"清华大学");
map.put(2,"北京大学");
map.put(3,"上海交通大学");
map.put(4,"浙江大学");
// 方式1.先取出所有的key,通过key获取对应的value
Set keySet = map.keySet();
for (Object key:keySet) {
System.out.println(key + "-" +map.get(key));
}
// 2.迭代器
Iterator iterator = keySet.iterator();
while (iterator.hasNext()){
Object key = iterator.next();
System.out.println(key + "-" + map.get(key));
}
// 3.取出所有的value
Collection values = map.values();
for (Object value : values
) {
System.out.println(value);
}
// 4.通过EntrySet 来获取 k-v
Set entrySet = map.entrySet();
for (Object entry : entrySet
) {
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey()+ "-" + m.getValue());
}
}
}
entrySet集合存放entry,entry类型为Map.Entry。Entry是一个接口,里面有getKey()和getValue()方法
23.说一说Hashtable
Hashtable存放的也是k-v键值对,但是和HashMap不同的,其键和值都不能为null,且Hashtable是线程安全的
底层:底层有一个table数组,类型为Entry数组+链表的方式,初始化大小为11,threshold = 11 * 0.75 = 8。扩容newCapacity = (oldCapacity << 1) + 1
put方法的主要逻辑如下:先获取synchronized锁(该锁是全表锁,即会锁定整个table),put方法不允许null值,如果发现是null,则直接抛出异常。计算key的哈希值和index,遍历对应位置的链表,如果发现已经存在相同的hash和key,则更新value,并返回旧值。如果不存在相同的key的Entry节点,则调用addEntry方法增加节点
24.说一说Properties
Properties继承Hashtable,所以存放的键值对不能为null
25.说一说红黑树
想要了解红黑树,我们必须先了解2-3-4树,为什么叫2-3-4树?因为对于这棵树的任意一个节点,它的子节点只能2个或者3个或者4个,2节点,也就是有两个子节点,但它本身只是一个单独的节点。3节点,也就是有3个子节点,但它本身包含2个树节点。4节点,也就是有4个子节点,但它本身只包含3个节点,看图就明白了
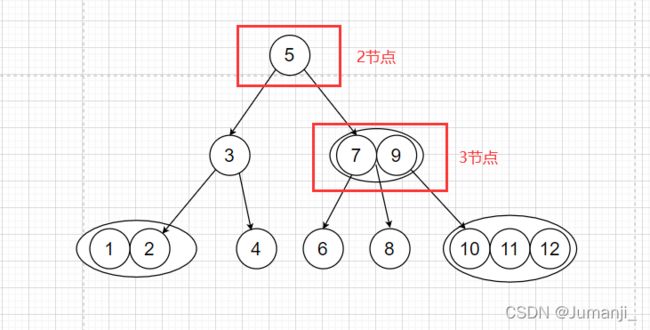
红黑树就是由2-3-4树转化而来,对于2-3-4树的单个节点,对应红黑树的单个节点。对于三节点,四节点对应关系如下。如果一个节点想加入四节点,只能发生裂变
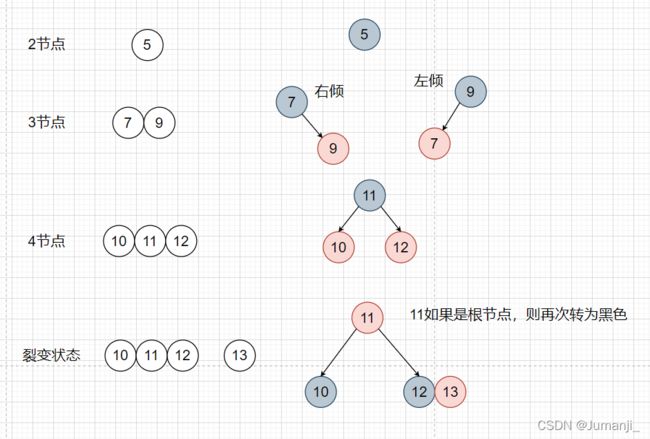
关于红黑树的插入删除操作,详情: 简单了解红黑树
26.HashMap 和 ConcurrentHashMap的区别
1.HashMap的键值对允许有null,但是ConCurrentHashMap都不允许
2.jdk1.8中,ConcurrentHashMap也是用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized + CAS来操作,整个看起来就像是优化过且线程安全的HashMap,ConcurrentHashMap使用的是分段锁,不同于Hashtable的全表锁,而HashMap是线程不安全的
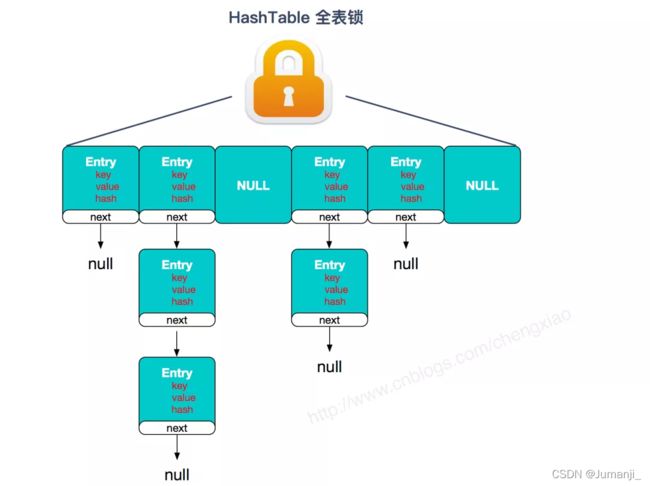
ConcurrentHashMap的分段锁
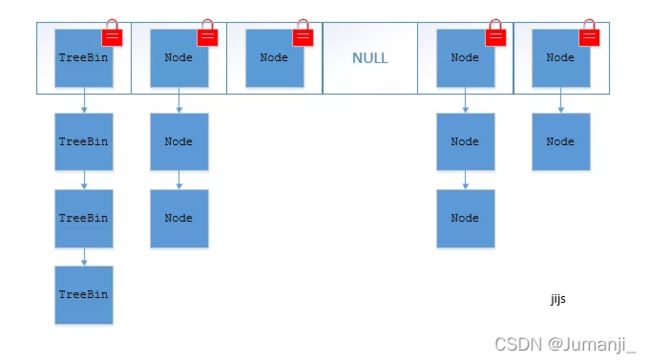
27.TreeMap
TreeSet底层是TreeMap,只不过K对应的V是一个固定的对象,用K来保存数据,不再赘述
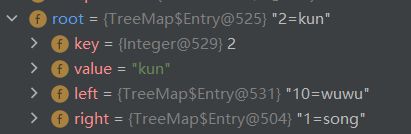
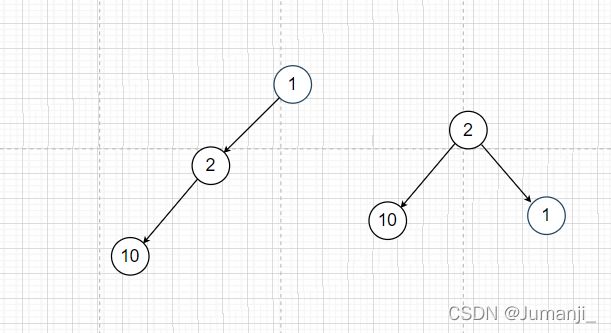
TreeMap底层是一个红黑树,添加的第一个节点即为root节点,节点类型为Entry类型,TreeMap最大的特点就是可以进行元素的排序,这是由红黑树决定的,那它内部是怎么比较的呢?TreeMap() 使用默认构造函数构造TreeMap的时候,使用默认的比较器来进行key的比较,对TreeMap进行升序排序。TreeMap(Comparator comparator) 带比较器(comparator)的构造函数,用户可以自定义比较器,按照自己的需要对TreeMap进行排序,如下,如果我们按顺序放入如下K-V键值对<1,“zhang”>,<2,"kun”> , <10, “wuwu”>,使用默认比较器时输出{1=zhang,2=kun,10=wuwu}升序排序,如果使用如下比较器,则输出{10=wuwu,2=kun,1=zhang},具体怎么实现的,通过源码,如果比较器返回<0,则为左子树,如果比较器返回>0,则为右子树。所以我们来叙述一下是怎么实现降序排序输出的,首先1插入,因为只有一个节点,1和自己比较1-1=0,作为根节点,当输入2时,1-2=-1,所以2作为1的左节点,当输入10时,10首先和1比较1-10=-9,又和2比较,2-10=-8,所以10应该作为2的左节点,此时不满足红黑树定义,需要进行调整,如图,中序遍历输出接得到了10,2,1的降序
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
TreeMap treeMap = new TreeMap<>(new Comparator(
) {
@Override
public int compare(Object o1, Object o2) {
// o1是要添加的元素, o2是集合中现有的元素。
// 根据第一个参数小于、等于或大于第二个参数分别返回负整数、零或正整数。
return (Integer) o2 - (Integer) o1;
}
});
xxx
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
}
xxx
28.Collections工具类
reverse 反转List集合

sort 排序

swap 交换
![]()
max 返回集合中最大的元素

frequency 统计集合中某个元素出现的次数
![]()
copy 拷贝集合
![]()
replaceAll 用X替代Y
![]()
29.集合底层的具体实现类
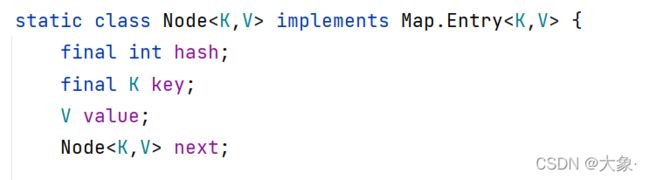
Entry是Map中的一个内部类,用于存储Map具体实现类的元素数据
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
①HashMap.Node是Map.Entry的具体实现类,记录节点hash,key,value,next,用于存储单向链表数据结构的数据
②Hashtable.Entry
private static class Entry<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Entry<K,V> next;
protected Entry(int hash, K key, V value, Entry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
@SuppressWarnings("unchecked")
protected Object clone() {
return new Entry<>(hash, key, value,
(next==null ? null : (Entry<K,V>) next.clone()));
}
// Map.Entry Ops
public K getKey() {
return key;
}
public V getValue() {
return value;
}
public V setValue(V value) {
if (value == null)
throw new NullPointerException();
V oldValue = this.value;
this.value = value;
return oldValue;
}
public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
return (key==null ? e.getKey()==null : key.equals(e.getKey())) &&
(value==null ? e.getValue()==null : value.equals(e.getValue()));
}
public int hashCode() {
return hash ^ Objects.hashCode(value);
}
public String toString() {
return key.toString()+"="+value.toString();
}
}
Hashtable.Entry是Map.Entry的具体实现类,和HashMap.Node一样记录hash,key,value,next,用于存储单向链表数据结构的数据,区别于HashMap.Node的是,Hashtable.Entry的setValue(V value)方法value不能为null,两者 hashCode()实现方法不同,HashMap.Node的hashCode()是Objects.hashCode(key) ^ Objects.hashCode(value),Hashtable.Entry的hashCode()是hash ^ Objects.hashCode(value)
③LinkedHashMap.Entry
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
LinkedHashMap.Entry是在HashMap.Node基础上做的改进,区别于HashMap.Node,维护了一个双向链表的数据结构
④TreeMap.Entry
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
/**
* Make a new cell with given key, value, and parent, and with
* {@code null} child links, and BLACK color.
*/
Entry(K key, V value, Entry<K,V> parent) {
this.key = key;
this.value = value;
this.parent = parent;
}
/**
* Returns the key.
*
* @return the key
*/
public K getKey() {
return key;
}
/**
* Returns the value associated with the key.
*
* @return the value associated with the key
*/
public V getValue() {
return value;
}
/**
* Replaces the value currently associated with the key with the given
* value.
*
* @return the value associated with the key before this method was
* called
*/
public V setValue(V value) {
V oldValue = this.value;
this.value = value;
return oldValue;
}
public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
return valEquals(key,e.getKey()) && valEquals(value,e.getValue());
}
public int hashCode() {
int keyHash = (key==null ? 0 : key.hashCode());
int valueHash = (value==null ? 0 : value.hashCode());
return keyHash ^ valueHash;
}
public String toString() {
return key + "=" + value;
}
}
TreeMap.Entry区别于以上Map的Entry的是,维护了一个红黑树的数据结构,除了原有的key,value还有左右节点,父节点信息和自身的颜色