最优传输问题与Sinkhorn算法
目录
- 1 引言
- 2 例子:分甜点
- 3 最优传输问题
- 4 Sinkhorn算法
-
- 4.1 Sinkhorn距离
- 4.2 算法流程
- 4.3 代码实验
1 引言
最近看到一篇特征匹配相关的论文,思想是将特征匹配问题转化为最优传输问题求解,于是我去学习了一下最优传输问题。
本文主要是对博文 Notes on Optimal Transport 的学习做一个记录总结,该博文写的不错,推荐阅读。
2 例子:分甜点
文章作者以一个简单的甜点分配例子引入了最优传输问题。
向量 r = [ 3 , 3 , 3 , 4 , 2 , 2 , 2 , 1 ] ⊤ \mathbf{r}=[3, 3, 3, 4, 2, 2, 2, 1]^{\top} r=[3,3,3,4,2,2,2,1]⊤ 表示 n = 8 n=8 n=8 个人需要的甜点数:
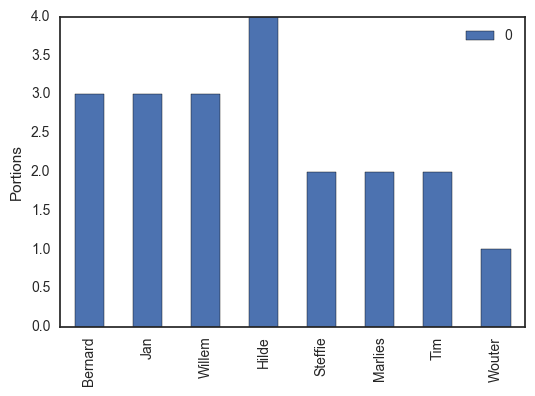
向量 c = [ 4 , 2 , 6 , 4 , 4 ] ⊤ \mathbf{c}=[4, 2, 6, 4, 4]^{\top} c=[4,2,6,4,4]⊤ 表示 m = 5 m=5 m=5 种甜点的数量:
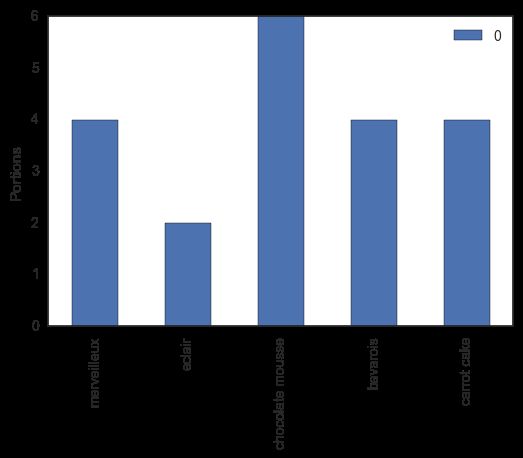
矩阵 M ∈ R 5 × 8 \mathbf{M}\in \mathbb{R}^{5\times 8} M∈R5×8 表示每个人对各种甜点的偏好,尺度区间 [ − 2 , 2 ] [-2, 2] [−2,2],-2表示非常不喜欢,2表示非常喜欢:
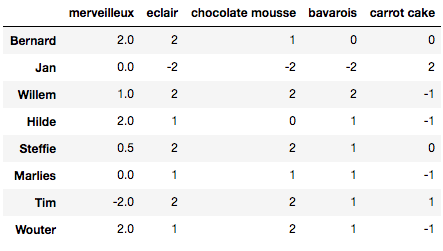
我们的目标,就是要根据甜点的数量,同时考虑每个人的需求和偏好,将所有甜点合理地分配到每个人手中。
3 最优传输问题
最优运输问题的目标就是以最小的成本将一个概率分布转换为另一个概率分布。上面的分甜点的目标,用最优传输问题的定义来说,就是将概率分布 c \mathbf{c} c 以最小的成本转换到概率分布 r \mathbf{r} r 。
这就需要我们求得一个分配方案,由矩阵 P ∈ R n × m P\in \mathbb{R}^{n\times m} P∈Rn×m 表示,存储每个人分得的每个甜点的情况。
根据现实条件,这个分配矩阵 P P P 显然具有以下约束:
- 分配的甜点数量不能为负数;
- 每个人的需求都要满足,即 P P P 的行和服从分布 r \mathbf{r} r;
- 每种甜点要全部分完,即 P P P 的列和服从分布 c \mathbf{c} c。
于是在分布 r \mathbf{r} r、 c \mathbf{c} c 约束下, P P P 的解空间可以做如下定义:
U ( r , c ) = { P ∈ R > 0 n × m ∣ P 1 m = r , P ⊤ 1 n = c } (1) U(\mathbf{r}, \mathbf{c})=\left\{P \in \mathbb{R}_{>0}^{n \times m} \mid P \mathbf{1}_{m}=\mathbf{r}, P^{\top} \mathbf{1}_{n}=\mathbf{c}\right\} \tag 1 U(r,c)={P∈R>0n×m∣P1m=r,P⊤1n=c}(1)
PS:这是博文的原公式,这里我有个疑问,为什么 P P P 的元素要求严格大于0,而不是大于等于0?希望有同学能够解答我的疑惑(感谢)
如前面所述,我们希望最小化转换成本,可以简单地反转偏好矩阵 M \mathbf{M} M 的符号,就可以得到成本矩阵(cost matrix)。于是就有了最优传输问题的公式化表示:
d M ( r , c ) = min P ∈ U ( r , c ) ∑ i , j P i j M i j (2) d_{M}(\mathbf{r}, \mathbf{c})=\min _{P \in U(\mathbf{r}, \mathbf{c})} \sum_{i, j} P_{i j} M_{i j} \tag 2 dM(r,c)=P∈U(r,c)mini,j∑PijMij(2)
标量 d M d_{M} dM 也被称为推土机距离(earth mover distance),因为它可以解释为至少移动多少“泥土”(成本)才能将一个土堆(分布)变成另一个土堆(分布)。
4 Sinkhorn算法
4.1 Sinkhorn距离
Sinkhorn距离是对推土机距离的一种改进,在其基础上引入了熵正则化项:
d M λ ( r , c ) = min P ∈ U ( r , c ) ∑ i , j P i j M i j − 1 λ h ( P ) (3) d_{M}^{\lambda}(\mathbf{r}, \mathbf{c})=\min _{P \in U(\mathbf{r}, \mathbf{c})} \sum_{i, j} P_{i j} M_{i j}-\frac{1}{\lambda} h(P) \tag 3 dMλ(r,c)=P∈U(r,c)mini,j∑PijMij−λ1h(P)(3)
其中 h ( P ) = − ∑ P i j log P i j h(P)=-\sum{P_{ij}\log{P_{ij}}} h(P)=−∑PijlogPij 称作 P P P 的信息熵(information entropy), P P P 分布越均匀,信息熵越大。
熵正则化参数 λ \lambda λ 负责调整信息熵的影响程度, λ \lambda λ 越大,信息熵的影响越小,最终结果受成本矩阵的影响更大,即更多地考虑每个人的喜好;反之,最终结果则更倾向于均匀分配,每种甜点将平均分配给每个人。
4.2 算法流程
新增的熵正则化项似乎让问题更加难以优化,但Sinkhorn算法提供了一种简单且有效的方法应对这一问题,Sinkhorn算法认为,最优分配矩阵 P λ ∗ P^*_\lambda Pλ∗ 的元素应该具有如下形式:
( P λ ∗ ) i j = α i β j e − λ M i j (4) (P^*_\lambda)_{ij}=\alpha_i \beta_j e^{-\lambda M_{ij}} \tag 4 (Pλ∗)ij=αiβje−λMij(4)
其中正是 α 1 , . . . , α n \alpha_1,...,\alpha_n α1,...,αn 和 β 1 , . . . , β n \beta_1,...,\beta_n β1,...,βn 使得 P ∗ P^* P∗ 满足分配矩阵的三个约束。如何推导出这一形式可以参考SuperGlue中的最优传输算法详解一文。
具体流程如下:
给定: 代价矩阵 M M M, 分布 r \mathbf{r} r, 分布 c \mathbf{c} c, 熵正则化参数 λ \lambda λ
初始化: 分配矩阵 P λ = e − λ M P_\lambda=e^{-\lambda M} Pλ=e−λM
重复:
- 缩放行,使得 P P P 的行和逼近分布 r \mathbf{r} r
- 缩放列,使得 P P P 的列和逼近分布 c \mathbf{c} c
直到: 收敛
4.3 代码实验
以下是Sinkhorn代码实现:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
r = np.array([3, 3, 3, 4, 2, 2, 2, 1])
c = np.array([4, 2, 6, 4, 4])
M = np.array(
[[2, 2, 1, 0, 0],
[0, -2, -2, -2, -2],
[1, 2, 2, 2, -1],
[2, 1, 0, 1, -1],
[0.5, 2, 2, 1, 0],
[0, 1, 1, 1, -1],
[-2, 2, 2, 1, 1],
[2, 1, 2, 1, -1]],
dtype=float)
M = -M # 将M变号,从偏好转为代价
def compute_optimal_transport(M, r, c, lam, eplison=1e-8):
"""
Computes the optimal transport matrix and Slinkhorn distance using the
Sinkhorn-Knopp algorithm
Inputs:
- M : cost matrix (n x m)
- r : vector of marginals (n, )
- c : vector of marginals (m, )
- lam : strength of the entropic regularization
- epsilon : convergence parameter
Outputs:
- P : optimal transport matrix (n x m)
- dist : Sinkhorn distance
"""
n, m = M.shape # 8, 5
P = np.exp(-lam * M) # (8, 5)
P /= P.sum() # 归一化
u = np.zeros(n) # (8, )
# normalize this matrix
while np.max(np.abs(u - P.sum(1))) > eplison: # 这里是用行和判断收敛
# 对行和列进行缩放,使用到了numpy的广播机制,不了解广播机制的同学可以去百度一下
u = P.sum(1) # 行和 (8, )
P *= (r / u).reshape((-1, 1)) # 缩放行元素,使行和逼近r
v = P.sum(0) # 列和 (5, )
P *= (c / v).reshape((1, -1)) # 缩放列元素,使列和逼近c
return P, np.sum(P * M) # 返回分配矩阵和Sinkhorn距离
我们来看看在不同 λ \lambda λ 下,得到的分配矩阵有什么特点:
lam = 0.1
P, d = compute_optimal_transport(M,
r,
c, lam=lam)
partition = pd.DataFrame(P, index=np.arange(1, 9), columns=np.arange(1, 6))
ax = partition.plot(kind='bar', stacked=True)
print('Sinkhorn distance: {}'.format(d))
ax.set_ylabel('portions')
ax.set_title('Optimal distribution ($\lambda={}$)'.format(lam))
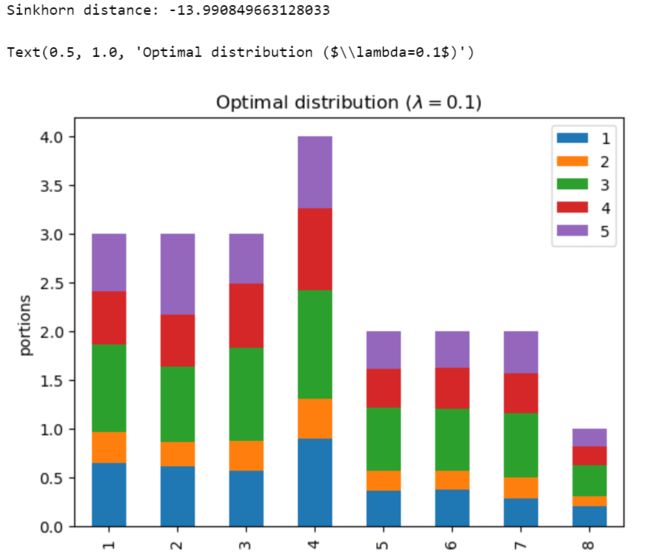
可以看到每个人分配得到的甜点基本上都符合初始甜点的分布比例 c = [ 4 , 2 , 6 , 4 , 4 ] ⊤ \mathbf{c}=[4, 2, 6, 4, 4]^{\top} c=[4,2,6,4,4]⊤ 。
试着调大 λ \lambda λ:
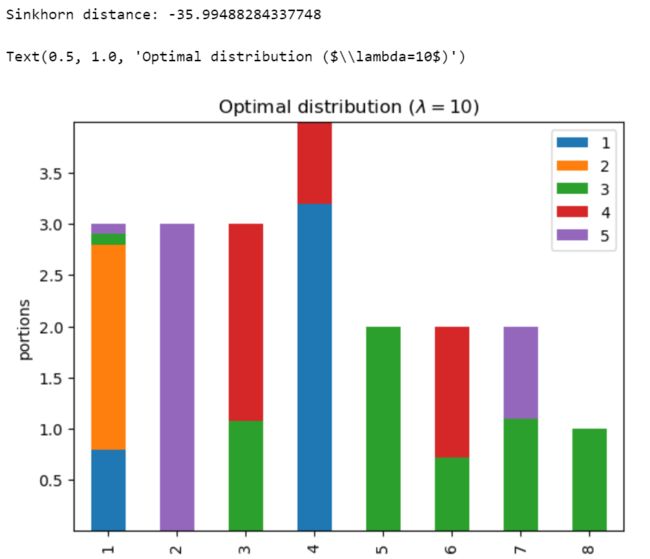
可以看到最终的分配向每个人的偏好靠拢了。