基于云原生架构的ckman和clickhouse-sinker应用实战
目录/contents
01 为什么我们选择把擎创科技的ckman和clickhouse-sinker在kubernetes上进行部署
02 ckman通过kubernetes部署过程说明
03 clickhouse-sinker通过kubernetes部署过程说明
04 ckman和clickhouse-sinker基于kubernetes的管理参考
05 未来基于kubernetes部署的技术展望
01
为什么我们选择把擎创科技的ckman和clickhouse-sinker在kubernetes上进行部署
ckman和clickhouse-sinker是当前非常优秀的ClickHouse周边生态开源工具。
笔者所在的公司和项目上,所有自研的应用系统都使用了kubernetes进行部署。经过对工具的分析,我们认为ckman和clickhouse-sinker可以作为无状态的服务部署在kubernetes集群上,快速集成和具备kubernetes云原生的各类特性,降低运维风险,提升运维效率。
-
使用kubernetes部署,给我们带来的价值和提升:
-
添加简单的配置文件,就可以快速在kubernetes上部署。
-
资源的优化,可以和现有基础资源无缝集成,运行环境隔离性好。
-
应用的自愈功能,减少运维工作量。
-
clickhouse-sinker应用的基于gitops的管理,提升数据同步脚本的管理能力。
-
无需添加配置文件,快速集成运维监控工具。
02
ckman通过kubernetes部署过程说明
ckman使用go作为开发语言,go程序有非常好的跨平台运行的能力,编译后生成的是可一键运行的可执行文件,同时执行效率和垃圾回收机制是公认当前云原生开发的事实标准语言,强大的kubernetes编排工具就是使用go语言开发的。
以下是一个ckman应用通过kubernetes部署的全过程。
ckman的镜像获取工作
由于是企业内部使用,考虑到网络安全,拉取镜像后,进行tag,在harbor仓库建立项目(例如bigdata),推送镜像到公司内部的harbor仓库。
docker pull quay.io/housepower/ckman:v2.2.3docker tag quay.io/housepower/ckman:v2.2.3 harbor.abc.com/bigdata/ckman:v2.2.3docker push harbor.abc.com/bigdata/ckman:v2.2.3
配置文件的修改
我们使用挂载configmap,ckman已经对数据库密码加密,如果是需要发布到生产,请使用secret。
这里我们使用的kubenetes对象包含,deployment,service,ingress,configmap。使用挂载外部数据库mysql。
-
deployment:发布ckman go应用的无状态应用的对象。因为我们使用了外部数据库,所以对于kubernetes来讲是无状态的应用。
-
service:ckman的服务发现,这里使用kubernetes的标准的服务注册的模式。
-
ingress:访问ckman的域名,kubernetes的service通过nginx-ingress对kubernetes集群外部的进行服务暴露。前提:你的企业需要对kubernetes的worker节点进行泛域名的配置,例如配置*.abc.com给到所有的worker节点的ip。
-
configmap:因为使用了mysql的配置,所以需要修改并覆盖原始的ckman.yaml配置内容
apiVersion: apps/v1kind: Deploymentmetadata:name: ckmannamespace: housepowerlabels:app: ckmanspec:replicas: 1selector:matchLabels:app: ckmantemplate:metadata:labels:app: ckmanspec:containers:- name: ckmanimage: harbor.abc.com/bigdata/ckman:v2.2.3imagePullPolicy: Alwaysresources:limits:memory: 1500Mirequests:memory: 1500Miports:- containerPort: 8808volumeMounts:- name: ckmanmountPath: "/etc/ckman/conf/ckman.yaml"subPath: ckman.yamlreadOnly: truevolumes:- name: ckmanconfigMap:name: ckmanitems:- key: "ckman.yaml"path: "ckman.yaml"---apiVersion: v1kind: Servicemetadata:name: ckmannamespace: housepowerspec:selector:app: ckmanports:- protocol: TCPport: 8808targetPort: 8808---apiVersion: networking.k8s.io/v1kind: Ingressmetadata:name: ckmannamespace: housepowerspec:rules:- host: "ckman.abc.com"http:paths:- pathType: Prefixpath: "/"backend:service:name: ckmanport:number: 8808---kind: ConfigMapapiVersion: v1metadata:name: ckmannamespace: housepowerdata:ckman.yaml: |-server:id: 1port: 8808https: falsepprof: truesession_timeout: 3600persistent_policy: mysqllog:level: INFOmax_count: 5max_size: 10max_age: 10persistent_config:mysql:host: xx.xx.xx.xxport: 3306user: rootpassword: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxdatabase: ckmannacos:enabled: falsehosts:- 127.0.0.1port: 8848user_name: nacospassword: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx#namespace:
注意事项
-
由于kubernetes有标准的应用重启功能,并且ckman的访问不会像业务系统那样很大的使用量,所以我们只使用了1个副本,并且没有使用nacos的集群模式。
-
ckman的数据库密码一定要执行加密操作,之前直接输入了数据库密码,导致部署异常。
-
有对应用可用性有要求的同学,可以加入kubernetes的健康检查探针,ckman swagger可以作为探针方式,首先修改ckman.yaml文件中的swagger_enable: true,然后参考 https://kubernetes.io/zh/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/ 添加到以上的kubernetes配置文件中。
-
泛域名的访问变成了80端口,ckman.xxx.com。如果需要https的访问模式,需要在ingress中添加tls信息。此外,对于没有泛域名的企业,可以使用kubenetes nodeport的功能进行配置,最后生成的访问地址是任意的worker节点ip加自动生成的3xxxx端口号。
-
无论是生产环境,测试环境,还是开发环境,都建议使用镜像的具体版本号,请不要使用latest;imagePullPolicy: Always这个设置也可以保证每次会去harbor仓库请求最新的镜像,无论kubernetes集群本地是否有一样tag的镜像。
-
注意configmap的内容的排版缩进。
正式通过kubernetes部署ckman
直接把上一节的文件(命名ckman-deployment),复制到可以执行集群kubectl命令的节点上,直接执行。
kubectl create ns housepowerkubectl apply -f ckman-deployment.yaml
等待镜像拉取和kubernetes对象资源发布成功。
kubectl get po -n housepowerNAME READY STATUS RESTARTS AGEckman-7b89797b77-r9dvk 1/1 Running 0 27mkubectl get deployment -n housepowerNAME READY UP-TO-DATE AVAILABLE AGEckman 1/1 1 1 27mkubectl get svc -n housepowerNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEckman ClusterIP 10.43.131.1748808/TCP 28m kubectl get ingress -n housepowerNAME CLASS HOSTS ADDRESS PORTS AGEckmanckman.abc.com xx.xx.xx.xxx 80 28m kubectl get cm -n housepowerNAME DATA AGEkube-root-ca.crt 1 36mckman 1 29m
浏览器访问域名ckman.abc.com或者ip端口,并且检查mysql数据库是否自动建表。
使用强大的argocd进行部署。这种模式适合大规模的生产环境开发的自助发布应用。argocd是当前cncf基金会的核心项目,是gitops的最佳实践工具。这里简述部署过程,首先在公司内部gitlab上建立一个工程(也可以用现有的工程),可以任意的建一个目录,并且把刚才的kubernetes部署文件git push上去,后续步骤就可以完全使用argocd强大的页面进行部署。这里列举部分关键信息的录入。
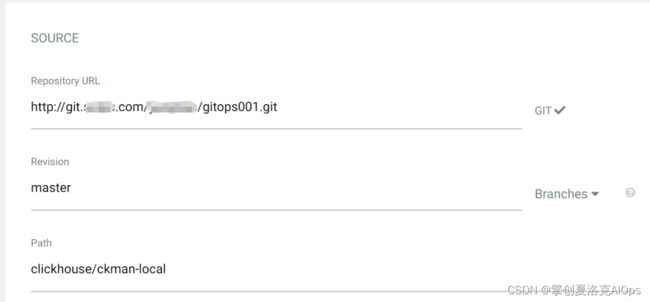
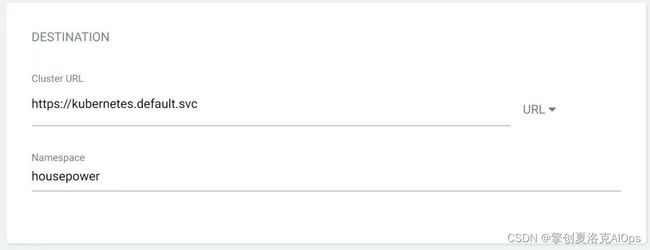
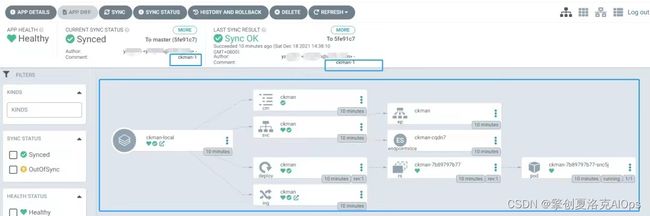
对,就是这么简单,然后点击create,在点击sync就自动发布了。上图中,下方的蓝色框是所有发布的kubernetes资源,上方2个蓝色框是git commit的信息。
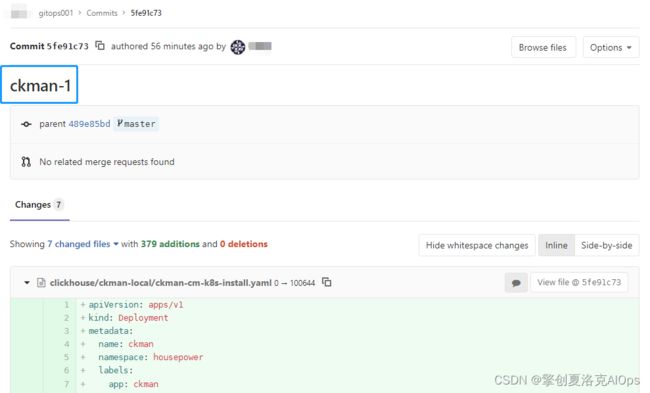
这样我们的完整的manifest放入了git,并且和发布过程完美的匹配起来了。
03
clickhouse-sinker通过kubernetes部署过程说明
clickhouse-sinker的整个过程和ckman大部分是类似的,主要是镜像构建上,需要单独对sinker进行操作。
在可以构建docker镜像的主机上执行https://github.com/housepower/clickhouse_sinker/releases/download/v2.3.0/clickhouse_sinker_2.3.0_Linux_arm64.tar.gz。其他版本可以在https://github.com/housepower/clickhouse_sinker/tags中进行选择。解压到当前目录。
docker镜像构建的细节主要参考了项目原生的代码https://github.com/housepower/clickhouse_sinker/blob/master/Dockerfile
FROM alpine:3.15.0RUN sed -i 's/dl-cdn.alpinelinux.org/mirrors.aliyun.com/g' /etc/apk/repositoriesRUN apk --no-cache add ca-certificates tzdataRUN echo "Asia/shanghai" > /etc/timezoneRUN cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtimeADD ./clickhouse_sinker /home/ADD ./nacos_publish_config /home/WORKDIR /home
docker build harbor.abc.com/bigdata/clickhouse-sinker:v2.3.0 .docker push harbor.abc.com/bigdata/clickhouse-sinker:v2.3.0
注意事项
-
国内的用户,在dockerfile中建议加上时区的设置,有可能部署后,时区显示是UTC。
-
配置s/dl-cdn.alpinelinux.org/mirrors.aliyun.com/g源,加快镜像的构建速度。
-
我们和clickhouse-sinker项目原生代码一样,都使用了alpine,主要考虑alpine的基础镜像非常小,最终构建好的镜像在几十兆左右。
clickhouse-sinker部署到kubernetes集群的配置文件明细。
apiVersion: apps/v1kind: Deploymentmetadata:name: sinker-tablenamenamespace: housepowerlabels:app: sinker-tablenamespec:replicas: 1selector:matchLabels:app: sinker-tablenametemplate:metadata:labels:app: sinker-tablenamespec:containers:- name: clickhouse-sinkerimage: harbor.abc.com/bigdata/clickhouse-sinker:v2.3.0imagePullPolicy: Alwayscommand: ["/home/clickhouse_sinker", "--local-cfg-file", "/home/config/config.json"]resources:limits:memory: 2000Micpu: 2000mrequests:memory: 2000Micpu: 2000mvolumeMounts:- name: sinker-tablenamemountPath: "/home/config/config.json"subPath: config.jsonreadOnly: truevolumes:- name: sinker-tablenameconfigMap:name: sinker-tablenameitems:- key: "config.json"path: "config.json"---kind: ConfigMapapiVersion: v1metadata:name: sinker-tablenamenamespace: housepowerdata:config.json: |-{"clickhouse": {"cluster": "cluster","hosts": [["192,168.1.11","192,168.1.12"],["192,168.1.13","192,168.1.14"]],"port": 9000,"username": "default","password": "default","db": "default","secure": false,"insecureSkipVerify": false,"retryTimes": 0,"maxOpenConns": 4},"kafka": {"brokers": "kafka-1:9092,kafka-2:9092,kafka-3:9092","tls": {"enable": false,"caCertFiles": "/etc/security/ca-cert","clientCertFile": "","clientKeyFile": ""},"sasl": {"enable": false,"mechanism": "PLAIN","username": "","password": "","gssapi": {"authtype": 0,"keytabpath": "","kerberosconfigpath": "","servicename": "","username": "","password": "","realm": "","disablepafxfast": false}},"version": "2.1.0"},"task": {"name": "table-1","kafkaClient": "kafka-go","topic": "topic","earliest": true,"consumerGroup": "table-1","parser": "json","tableName": "table-1","dims": [{ "name": "COLOR", "type": "UInt8", "sourceName": "color"},{ "name": "DATE", "type": "UInt8", "sourceName": "date"}],"autoSchema" : false,"excludeColumns": [],"dynamicSchema": {"enable": false,"maxDims": 1024,"whiteList": "^[0-9A-Za-z_]+$","blackList": "@"},"shardingKey": "","shardingStripe": 0,"flushInterval": 10,"bufferSize": 262114,"timeZone": "Asia/Shanghai","timeUnit": 1.0},"logLevel": "debug"}
注意事项
-
和ckman部署的方式一样,可以选择命令行直接kubectl apply -f,或者使用argocd进行gitops方式的部署。
-
不同的sinker任务,建议把文件中出现sinker-tablename修改,使用helm或者kustomize可以实现配置文件参数化的功能。
-
内存和cpu的设置可以根据实际使用的场景或需求进行修改。
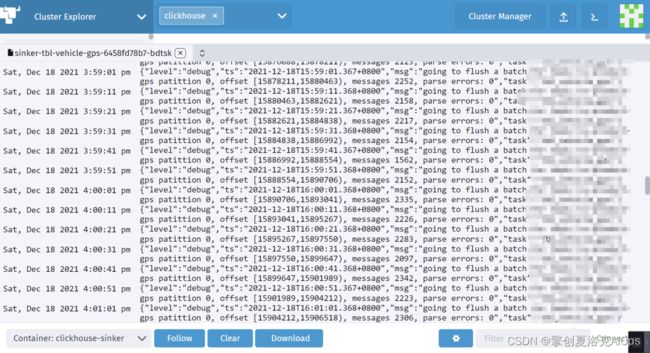
这里我们展示一个部署在生产环境kubernetes集群的clickhouse-sinker应用日志截图。和普通虚拟机物理机日志没有区别。
04
ckman和clickhouse-sinker基于kubernetes的管理参考
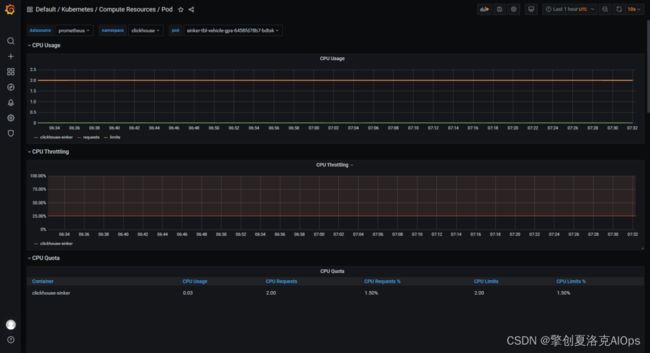
得益于kubernetes强大的生态,部署好的应用可以直接开启prometheus监控。我们发现clickouse-sinker应用,每10秒消费2万条数据的时候,cpu和内存占有率非常优秀,都小于1个虚拟cpu,小于1G内存。
kubernetes默认就可以实现应用重启功能,我们遇到过clickhouse集群异常无法插入数据,kubernetes部署的clickhouse-sinker程序在一直重启。
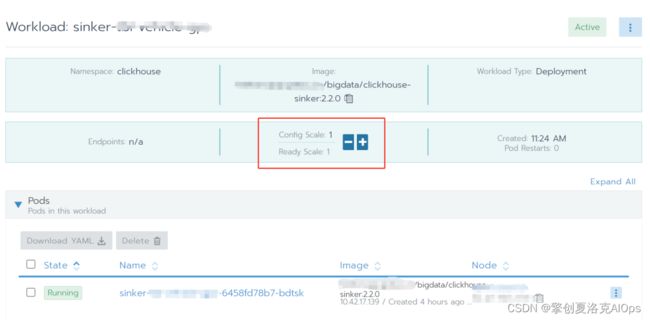
可以改变副本为0,实现临时中断clickhouse-sinker的场景,我们使用rancher ui对kubernetes进行管理,只需要点击鼠标,把副本数修改为0就可以轻松实现。重新上线只需要再变为1。
对于大数据量的场景,还是建议物理机或者配置高的虚拟机部署clickhouse-sinker,网络高负载会影响到kubernetes集群其他应用的正常运行。z
05
未来基于kubernetes部署的技术展望
可以使用高性能的集群来部署大规模的clickhouse-sinker应用。例如可以直接使用高配置的物理机,配置100Gb的网卡。针对高吞吐量的同步任务,可以使用nodeSelector强制把任务调度在某一个物理机上,独享网络资源,减少运行瓶颈。
同一个topic的分布式消费场景是可以在kubernetes上实验和推广的场景,这类模式和spark flink类似,可以实现上百个节点的高速和精准数据消费和插入。
ckman和clickhouse-sinker整个部署的过程可以实现基于产品的界面化配置,推广成公有云、私有云、混合云的ETL工具包。