mitmproxy工具
目录
1、安装
2、Windows本机抓包初体验
(1)mitmdump抓包
(2)mitmproxy抓包
(3)mitmweb抓包
3、安装证书
(1)Windows安装证书抓取https包
(2)Android安装证书抓包
4、抓取get、post请求实战
(1)遇到问题
(2)实时打印请求入参和响应出参
(3)抓包情况保存在cvs文件中
5、启动
(1)mitmproxy自带启动API
(2)subprocess启动
(3)多进程方式
6、实际案例
(1)pytest + mitmproxy
(2)pytest + mitmproxy+selenium
(3)测试中试试mock请求
appium+mitmproxy
为什么要用这个工具
(1)比Charles、wireshark这些界面抓包工具,可以集成到代码中,python就有三方包
(2) 比Charles、wireshark这些界面抓包工具,可以实时的分析过滤加工数据
(3)支持的平台多
官网的使用例子:Examples
1、安装
pip install mitmproxy
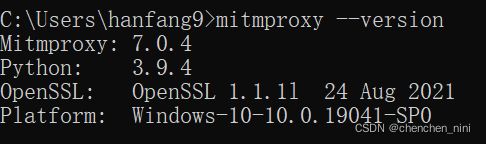
检查是否安装正确(三个工具的版本都能查看)
mitmproxy --version
mitmdump --version
mitmweb --version
2、Windows本机抓包初体验
(1)mitmdump抓包
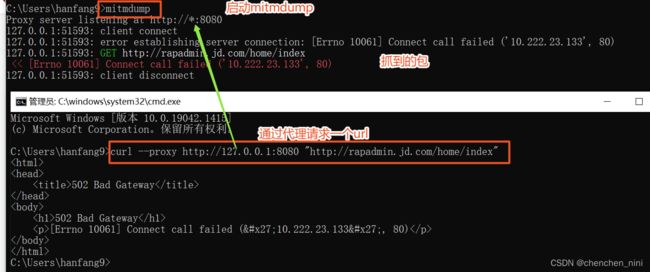
启动:mitmdump
# 默认启动的是8080端口
访问抓包:curl --proxy http://127.0.0.1:8080 "测试url"
 本机设置代理
本机设置代理
(1)整个网络设置代理

出现了!!!!


(2)只对一个浏览器做代理
谷歌:
(1)命令行方式
第一步:找到浏览器的安装位置:桌面浏览器右键打开文件所在位置
第二步:在CMD中启动浏览器,并设置代理,要代理生效,必须没有打开的浏览器才行(那就把所有的火狐浏览页面都关闭)
"C:\Users\Administrator\AppData\Local\Google\Chrome\Application\chrome.exe" --proxy-server=127.0.0.1:8080 --ignore-certificate-errors
(2)浏览器中设置:忽略,自行百度
火狐:
(1)命令行方式:
只百度到了,火狐的代理文件在哪里放着,但是我本地却没有这个代理文件,所以后面在说吧
(2)浏览器中设置:忽略,自行百度


(2)mitmproxy抓包
启动:mitmproxy
进入交互式界面,如上,对自己的Windows机处理好代理,使用比较少
参考文章:mitmproxy的使用详解 - 会跑的熊 - 博客园
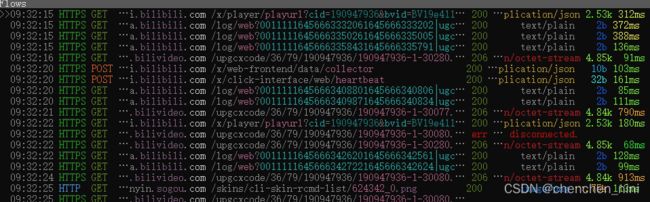
(3)mitmweb抓包
下面都是基于mitmweb做的,和Charles等界面抓包工具类似
启动:mitmweb
3、安装证书
(1)Windows安装证书抓取https包
用户的目录下(启动mitmdump就生成了)
官网也有解释Certificates
命令行请求如何带证书:
curl --proxy 127.0.0.1:8080 --cacert C:/Users\hanfang9/.mitmproxy/mitmproxy-ca-cert.p12 https://example.com/
curl -x 172.23.68.1:80 -X POST "http://smart-robot-pre.jd.com/callResultForCallId?callId=626a876a-d36f-123a-cf82-f000ac1976e6"
wget -e https_proxy=127.0.0.1:8080 --ca-certificate ~/.mitmproxy/mitmproxy-ca-cert.pem https://example.com/
再次刷新上面B站网页就好了,也抓到了https的包

(2)Android安装证书抓包
参考文章:手机app数据的爬取之mitmproxy安装教程 - BruceLong - 博客园
mitmproxy抓包工具!!! 从安装到简单使用_哔哩哔哩_bilibili
第一步:给手机配置代理

第二步:手机浏览器下载证书(我的手机是华为mate20 pro)
浏览器输入:mitm.it

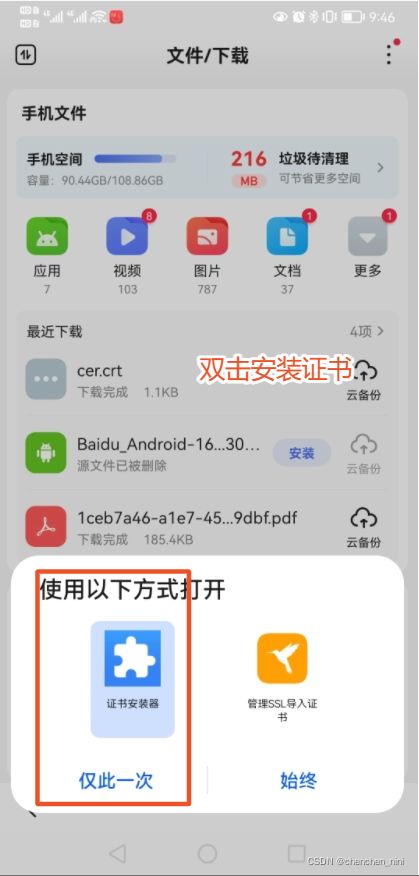

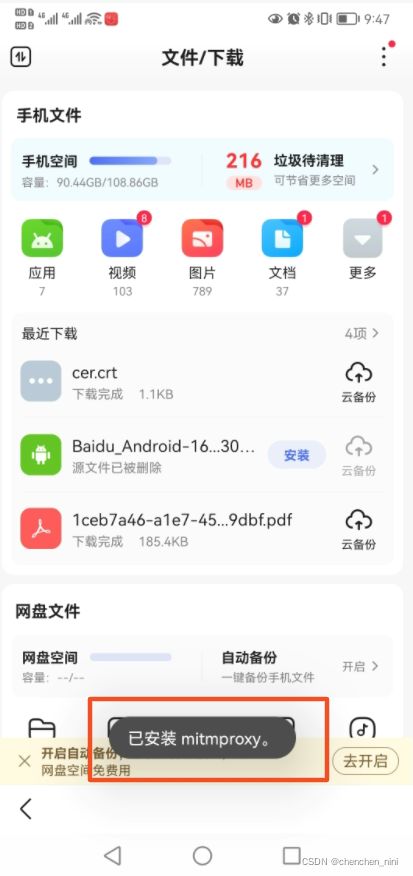
手机里面查看证书,也可以删除




4、抓取get、post请求实战
目的:抓取所有的入参和出参等信息

方法:mitmdump\mitmweb都可以 -s 指定脚本,实时处理请求,拦截下来请求入参和出参等信息
(1)遇到问题
这个接口没有拦截到post请求的入参

curl -X POST "http://测试url/callResultForCallId?callId=626a876a-d36f-123a-cf82-f000ac1976e6" -x 127.0.0.1:8080 -H "content-type: application/json; charset=UTF-8" -d '{"d":1}'

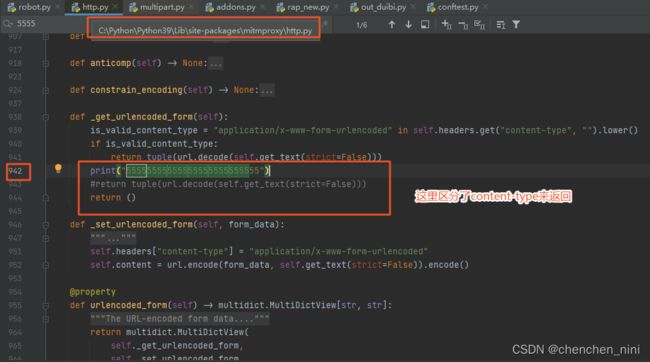
原因:mitmproxy代码分析了一波,我本身代码获取post的请求入参用的是urlencode_form的属性值,就有问题了,如图这样修改就在终端获取到了,虽然我不知道mitmweb展示的数据是怎么获取的,哈哈~~~(这里也可以照着urlencode_form创建一个属性值就不改变原有mitmproxy的逻辑了)
post请求入参有中文,编码格式(可以先看现象和解决,然后根据下面实时打印的代码试验)


原因:mitmproxy根据header中content-type的编码格式来解码请求参数,cmd中的编码格式和header中传的不一致就会有问题


试验:第一次不设置content-type
curl -X POST "http://smart-robot-pre.jd.com/callResultForCallId?callId=626a876a-d36f-123a-cf82-f000ac1976e6" -x 127.0.0.1:8080 -d '{"d":1,"f":"人民"}'


试验:第二次设置为utf-8
curl -X POST "http://smart-robot-pre.jd.com/callResultForCallId?callId=626a876a-d36f-123a-cf82-f000ac1976e6" -x 127.0.0.1:8080 -H "content-type: application/json; charset=utf-8" -d '{"d":1,"f":"人民"}'
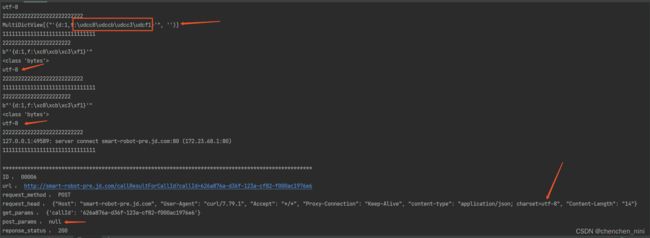
试验:第三次设置为gbk
下图:说明这次设置的匹配上了
curl -X POST "http://测试域名/callResultForCallId?callId=626a876a-d36f-123a-cf82-f000ac1976e6" -x 127.0.0.1:8080 -H "content-type: application/json; charset=gbk" -d '{"d":1,"f":"人民"}'
************************************************************************************************************
引发问题:修改cmd的编码格式,发现不太好使呢,我本来想变更cmd的是utf-8和header对应上,下面是cmd变更编码格式的文章
cmd 查看当前窗口的编码_lyw603267094的专栏-CSDN博客_cmd查看编码
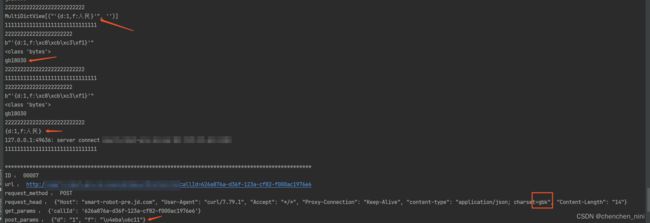

(2)实时打印请求入参和响应出参
代码robot.py:
import json
from mitmproxy import ctx, http
class Robot:
def request(self, flow: http.HTTPFlow):
if flow.request.host :
ctx.log.warn("*" * 100)
ctx.log.info("请求url: " + flow.request.url)
ctx.log.info("请求方法: " + flow.request.method)
ctx.log.info("请求headers: " + str(flow.request.headers))
# query抓取的是get的数据
get_p = flow.request.query
# ctx.log.info("请求get入参: " + str(get_p))
temp_json = {}
for k, v in get_p.items():
temp_json[k] = v
# ctx.log.info(k+" "+v) unicode的value单独打印是中文,下面整体打印就是Unicode字符串,如果校验姓名这样的带星星的在说
ctx.log.info("请求get入参: " + json.dumps(temp_json))
ctx.log.info("请求get入参: " + str(temp_json)) #和上一句话在遇到中文的时候不一样,conlse展示最好选择下面的
# post入参
post_p = flow.request.urlencoded_form
post_temp = ""
for k in post_p.keys():
post_temp = k
# with open("D://dd.txt", "a", encoding="utf-8") as f:
# f.write(k)
ctx.log.info("请求post入参: " + post_temp)
ctx.log.warn("*" * 100)
def response(self, flow: http.HTTPFlow):
if flow.request.host:
ctx.log.warn("-" * 100)
response = flow.response.content
response = response.decode("utf-8")
ctx.log.info("请求response: " + response)
ctx.log.warn("-" * 100)
![]()
代码addons.py:
import robot
addons = [
robot.Robot(),
](3)抓包情况保存在cvs文件中
代码robot.py:
import csv
import json
import os
import sys
import time
import urllib
from functools import reduce
from mitmproxy import http
headline = ["ID", "url", "request_method", "request_head", "get_params", "post_params", "reponse_status",
"response_text"]
class CsvUtils:
@staticmethod
def generate_name_current_time():
name = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime())
return name
@staticmethod
def write_csv_by_add(csv_path, text):
"""
:param csv_path: 文件路径
:param text: 要写入的信息,必须是字典
:return:
"""
try:
if text not in [None, ""]:
if isinstance(text, dict):
with open(csv_path, "a+", encoding="utf-8", newline="") as w:
csv.field_size_limit(2000000000)
csv_writer = csv.DictWriter(w, fieldnames=headline)
csv_writer.writerow(text)
with open(csv_path, "r", encoding="utf-8") as r:
csv_reader = csv.DictReader(r)
temp = [row for row in csv_reader]
if temp:
print()
print("*" * 100)
for k, v in temp[-1].items():
print(k, ":", v.replace('\0', ''))
print("*" * 100)
print()
else:
print("写入的text,不是列表格式")
else:
print("写入的text,不能为空")
except Exception as e:
print("%s写csv文件时发生未知异常" % e)
class MitmBasic:
def __init__(self):
# 刚才写的获取当前时间的工具,我们要习惯如果这个代码块常用我们就要把他写成一个工具类,方便日后调用
self.result = {}
self.count = 1
self.result_name = CsvUtils.generate_name_current_time()
self.result_path = os.path.dirname(os.path.realpath(__file__)) + "/../record_%s.csv" % self.result_name
CsvUtils.write_csv_by_add(self.result_path, {k: k for k in headline})
def request(self, flow: http.HTTPFlow):
if flow.request.host: # == "smart-robot-pre.jd.com"
headers = {k: v for k, v in flow.request.headers.items()}
query = {k: v for k, v in flow.request.query.items()}
for k, v in query.items():
if k == "productType":
print(v == "京东金条")
print(k, v)
post_param = None
if flow.request.urlencoded_form:
try:
post_p = eval(reduce(lambda x, y: x + y, flow.request.urlencoded_form.keys()))
post_param = {k: v for k, v in map(lambda x: x.split(":"), post_p[1:-1].split(","))}
except Exception:
pass
case_id = '{:0>5d}'.format(self.count) # 生成用例id
values = [case_id, urllib.parse.unquote(flow.request.url), flow.request.method, json.dumps(headers),
json.dumps(query), json.dumps(post_param)]
self.result = {k: v for k, v in zip(headline, values)}
print(self.result)
def response(self, flow: http.HTTPFlow):
if flow.request.host: # == "smart-robot-pre.jd.com":
response = flow.response
return_code = response.status_code
try:
content = response.content.decode("utf-8")
except UnicodeError:
content = response.content
self.result[headline[-2]] = return_code
self.result[headline[-1]] = content
CsvUtils.write_csv_by_add(self.result_path, self.result)
self.count += 1addons.py
import robot
addons = [
robot.MitmBasic(),
]效果:


5、启动
前言:我们命令行mitmdump、mitmweb是配置了C:\Python\Python39\Scripts这个path环境变量,所以找到了这个目录下的执行文件
在CMD下用tasklist命令可以查到mitmproxy的进程:
taskkill /F /PID 2148 (杀死进程)
tasklist|findstr "mitm" (查找)
cmd = r"C:\Python\Python39\Scripts\mitmweb.exe -s D:\mycode\gitpull\playwright_study\mitmproxy_hf\addons.py" subprocess.Popen(cmd, shell=True)
(1)mitmproxy自带启动API
这个版本支持的不是最新版本,需要降级到,我还没有找到最近的版本支持的config怎么配置

import asyncio
from mitmproxy import proxy, options, ctx
from mitmproxy.tools.dump import DumpMaster
from mitmproxy import http
class AdjustBody:
def response(self, flow: http.HTTPFlow) -> None:
if "google" in flow.request.url:
print("Before intercept: %s" % flow.response.text)
flow.response.content = bytes("This is replacement response", "UTF-8")
print("After intercept: %s" % flow.response.text)
def start():
add_on = AdjustBody()
opts = options.Options(listen_host='127.0.0.1', listen_port=8888)
proxy_conf = proxy.config.ProxyConfig(opts)
dump_master = DumpMaster(opts)
dump_master.server = proxy.server.ProxyServer(proxy_conf)
dump_master.addons.add(add_on)
try:
asyncio.ensure_future(stop())
dump_master.run()
except KeyboardInterrupt:
dump_master.shutdown()
async def stop():
# Sleep 10s to do intercept
await asyncio.sleep(10)
ctx.master.shutdown()
if __name__ == '__main__':
start()
(2)subprocess启动
cmd = r"C:\Python\Python39\Scripts\mitmdump.exe -s D:\mycode\gitpull\playwright_study\mitmproxy_hf\addons.py"
process = subprocess.Popen(cmd, creationflags=subprocess.CREATE_NEW_CONSOLE)
print(process.pid)
time.sleep(60)
process.terminate()(3)多进程方式
pass
6、实际案例
(1)pytest + mitmproxy
conftest.py文件内容
def pytest_addoption(parser):
parser.addoption("--mitm_path", action="store",
default="",
type=str,
help="--mitm_path:mitmproxy生成的cvs文件路径")
parser.addoption("--mitm_proxy", action="store",
default="127.0.0.1:8080",
type=str,
help="--mitm_proxy:mitmproxy设置代理")
@pytest.fixture(scope="session", autouse=True)
def set_env_mitm_path(request):
mitm_value = request.config.getoption("--mitm_path")
os.environ['mitm_path'] = mitm_value
print('\n --mitm_path参数值:', mitm_value)
return mitm_value
@pytest.fixture(scope="session", autouse=True)
def set_env_mitm_proxy(request):
mitm_proxy = request.config.getoption("--mitm_proxy")
os.environ['mitm_proxy'] = mitm_proxy
print('\n --mitm_proxy参数值:', mitm_proxy)
return mitm_proxy
@pytest.fixture(scope="session")
def setup_mitmdump():
# 获取 mitm保存cvs的文件名,没有设置就用用例做文件名
if not os.environ.get("mitm_path"):
caller = os.environ.get('PYTEST_CURRENT_TEST').split(':')[-1].split(' ')[0]
mitm_path = "./testdata/" + caller + ".csv"
os.environ["mitm_path"] = mitm_path
# 启动mitmproxy子进程,这里也可以通过命令行控制,这里就不处理了,参照mitm_cvs_name可以设置
cmd = r"mitmdump -s D:\mycode\gitpull\playwright_study\mitmproxy_hf\addons.py"
print("start mitm")
process = subprocess.Popen(cmd, creationflags=subprocess.CREATE_NEW_CONSOLE)
time.sleep(1)
yield
time.sleep(5)
print("stop mitm")
process.kill()
robot.py文件
import csv
import json
import os
import time
import urllib
from functools import reduce
from mitmproxy import http
headline = ["ID", "url", "request_method", "request_head", "get_params", "post_params", "reponse_status",
"response_text"]
class CsvUtils:
@staticmethod
def generate_name_current_time():
name = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime())
return name
@staticmethod
def write_csv_by_add(csv_path, text):
"""
:param csv_path: 文件路径
:param text: 要写入的信息,必须是字典
:return:
"""
if not os.path.isdir(os.path.split(csv_path)[0]):
os.makedirs(os.path.split(csv_path)[0])
try:
if text not in [None, ""]:
if isinstance(text, dict):
with open(csv_path, "a+", encoding="utf-8", newline="") as w:
csv.field_size_limit(2000000000)
csv_writer = csv.DictWriter(w, fieldnames=headline)
csv_writer.writerow(text)
with open(csv_path, "r", encoding="utf-8") as r:
csv_reader = csv.DictReader(r)
temp = [row for row in csv_reader]
if temp:
print()
print("*" * 100)
for k, v in temp[-1].items():
print(k, ":", v.replace('\0', ''))
print("*" * 100)
print()
else:
print("写入的text,不是列表格式")
else:
print("写入的text,不能为空")
except Exception as e:
print("%s写csv文件时发生未知异常" % e)
class MitmBasic:
def __init__(self):
# 刚才写的获取当前时间的工具,我们要习惯如果这个代码块常用我们就要把他写成一个工具类,方便日后调用
self.result = {}
self.count = 1
if os.environ.get("mitm_path"):
self.result_path = os.environ.get("mitm_path")
else:
self.result_name = "sys_" + CsvUtils.generate_name_current_time()
self.result_path = os.path.dirname(os.path.realpath(__file__)) + "/../record/%s.csv" % self.result_name
# subprocess 子进程设置的os.environ在主进程不能使用
# os.environ["mitm_cvs_path"] = self.result_path
# print(os.environ.get("mitm_cvs_path"))
CsvUtils.write_csv_by_add(self.result_path, {k: k for k in headline})
def request(self, flow: http.HTTPFlow):
if flow.request.host: # == "smart-robot-pre.jd.com"
headers = {k: v for k, v in flow.request.headers.items()}
query = {k: v for k, v in flow.request.query.items()}
post_param = None
if flow.request.urlencoded_form:
try:
post_p = eval(reduce(lambda x, y: x + y, flow.request.urlencoded_form.keys()))
post_param = {k: v for k, v in map(lambda x: x.split(":"), post_p[1:-1].split(","))}
except Exception:
pass
case_id = '{:0>5d}'.format(self.count) # 生成用例id
values = [case_id, urllib.parse.unquote(flow.request.url), flow.request.method, json.dumps(headers),
json.dumps(query), json.dumps(post_param)]
self.result = {k: v for k, v in zip(headline, values)}
print(self.result)
def response(self, flow: http.HTTPFlow):
if flow.request.host: # == "smart-robot-pre.jd.com":
response = flow.response
return_code = response.status_code
try:
content = response.content.decode("utf-8")
except UnicodeError:
content = response.content
self.result[headline[-2]] = return_code
self.result[headline[-1]] = content
CsvUtils.write_csv_by_add(self.result_path, self.result)
self.count += 1
addons.py文件
import robot
addons = [
robot.MitmBasic(),
]
测试文件
import csv
import os
import allure
import pytest
import requests
class TestDemo:
@pytest.mark.parametrize(
"name,assert_word",
[
pytest.param("1", "smart", id="第一个", marks=pytest.mark.skip("不想跑")),
pytest.param("2", "smart", id="第二个")
]
)
def test_002(self, setup_mitmdump, name, assert_word):
print("我是用例%s" % name)
url = "**********************" #这里是访问的url
params = {"d": 1}
headers = {"content-type": "application/json; charset=UTF-8"}
proxies = {'http': 'http://127.0.0.1:8080'} # 代理mitmproxy地址
option = requests.post(url=url, headers=headers, params=params, proxies=proxies)
print(option.status_code)
@pytest.mark.usefixtures("setup_mitmdump")
@pytest.mark.parametrize(
"name,assert_word",
[
pytest.param("1", "smart", id="第一个"),
pytest.param("2", "smart", id="第二个")
]
)
def test_003(self, name, assert_word):
print("我是用例test_%s" % name)
url = "**********************" #这里是访问的url
params = {"d": 1}
headers = {"content-type": "application/json; charset=UTF-8"}
proxies = {'http': 'http://%s' % os.environ.get("mitm_proxy")} # 代理mitmproxy地址
option = requests.post(url=url, headers=headers, params=params, proxies=proxies)
# 这里可以对抓包的结果处理:找到响应200的请求集合(断言部分)
def _get_uri():
if os.environ.get("mitm_path"):
mitm_cvs_name = os.environ["mitm_path"]
if os.path.isfile(mitm_cvs_name):
with open(mitm_cvs_name, "r", encoding="utf-8") as r:
csv_reader = csv.DictReader(r)
temp = [row for row in csv_reader]
for i in temp:
# 找到响应200的数据,可以写自己的数据了
if i["reponse_status"] == "200":
print()
print("%" * 100)
for k, v in i.items():
print(k, ":", v.replace('\0', ''))
print("%" * 100)
print()
return True
else:
return AssertionError("抓包结果路径不对:%s" % mitm_cvs_name)
else:
return AssertionError("没有找到抓包结果文件")
_get_uri()
执行效果:
pytest -s mitmproxy_hf\test1.py::TestDemo::test_003 --mitm_path="./tesss/newname.csv"
视频:mitmproxy结合pytest_哔哩哔哩_bilibili
(2)pytest + mitmproxy+selenium
提供下代码和效果(可以自己对已有selenium的用例加上抓包,检测数据加密传输,检查调用接口失败率什么的)
这里写入csv开销不小,在读取也有开销,讲从csv读取改为存入前print到conlse
robot.py
import csv
import json
import os
import time
import urllib
from functools import reduce
from mitmproxy import http, ctx
headline = ["ID", "url", "request_method", "request_head", "get_params", "post_params", "reponse_status",
"response_text"]
class CsvUtils:
@staticmethod
def generate_name_current_time():
name = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime())
return name
@staticmethod
def write_csv_by_add(csv_path, text):
"""
:param csv_path: 文件路径
:param text: 要写入的信息,必须是字典
:return:
"""
if not os.path.isdir(os.path.split(csv_path)[0]):
os.makedirs(os.path.split(csv_path)[0])
try:
if text not in [None, ""]:
if isinstance(text, dict):
with open(csv_path, "a+", encoding="utf-8", newline="") as w:
csv.field_size_limit(2000000000)
csv_writer = csv.DictWriter(w, fieldnames=headline)
csv_writer.writerow(text)
else:
print("写入的text,不是列表格式")
else:
print("写入的text,不能为空")
except Exception as e:
print("%s写csv文件时发生未知异常" % e)
class MitmBasic:
def __init__(self):
# 刚才写的获取当前时间的工具,我们要习惯如果这个代码块常用我们就要把他写成一个工具类,方便日后调用
self.result = {}
self.count = 1
if os.environ.get("mitm_path"):
self.result_path = os.environ.get("mitm_path")
else:
self.result_name = "sys_" + CsvUtils.generate_name_current_time()
self.result_path = os.path.dirname(os.path.realpath(__file__)) + "/../record/%s.csv" % self.result_name
CsvUtils.write_csv_by_add(self.result_path, {k: k for k in headline})
def request(self, flow: http.HTTPFlow):
if flow.request.host:
headers = {k: v for k, v in flow.request.headers.items()}
query = {k: v for k, v in flow.request.query.items()}
post_param = None
if flow.request.urlencoded_form:
try:
post_p = eval(reduce(lambda x, y: x + y, flow.request.urlencoded_form.keys()))
post_param = {k: v for k, v in map(lambda x: x.split(":"), post_p[1:-1].split(","))}
except Exception:
pass
case_id = '{:0>5d}'.format(self.count) # 生成用例id
values = [case_id, urllib.parse.unquote(flow.request.url), flow.request.method, json.dumps(headers),
str(query), str(post_param)]
self.result = {k: v for k, v in zip(headline, values)}
def response(self, flow: http.HTTPFlow):
if flow.request.host:
response = flow.response
return_code = response.status_code
try:
content = response.content.decode("utf-8")
except UnicodeError:
content = ""
self.result[headline[-2]] = return_code
self.result[headline[-1]] = content[:10]
ctx.log.info("*"*100)
for k, v in self.result.items():
ctx.log.info(k + " : " + str(v))
ctx.log.info("*" * 100)
CsvUtils.write_csv_by_add(self.result_path, self.result)
self.count += 1
conftest.py
import os
import subprocess
import time
import pytest
from mitmproxy_hf.pytest_mitm_selenium.rap_kanban import *
def pytest_collection_modifyitems(items):
"""
测试用例收集完成时,将收集到的item的name和nodeid的中文显示在控制台上
"""
for item in items:
item.name = item.name.encode("utf-8").decode("unicode_escape")
item._nodeid = item.nodeid.encode("utf-8").decode("unicode_escape")
if item.obj.__doc__:
item._nodeid += ":" + item.obj.__doc__.strip()
def pytest_addoption(parser):
parser.addoption("--mitm_path", action="store",
default="",
type=str,
help="--mitm_path:mitmproxy生成的cvs文件名称")
parser.addoption("--mitm_proxy", action="store",
default="127.0.0.1:8080",
type=str,
help="--mitm_proxy:mitmproxy设置代理")
@pytest.fixture(scope="session", autouse=True)
def set_env_mitm_path(request):
mitm_value = request.config.getoption("--mitm_path")
os.environ['mitm_path'] = mitm_value
print('\n --mitm_path参数值:', mitm_value)
return mitm_value
@pytest.fixture(scope="session", autouse=True)
def set_env_mitm_proxy(request):
mitm_proxy = request.config.getoption("--mitm_proxy")
os.environ['mitm_proxy'] = mitm_proxy
print('\n --mitm_proxy参数值:', mitm_proxy)
return mitm_proxy
@pytest.fixture(scope="session")
def setup_mitmdump():
if not os.environ.get("mitm_path"):
caller = os.environ.get('PYTEST_CURRENT_TEST').split(':')[-1].split(' ')[0]
mitm_path = "./testdata/" + caller + ".csv"
print(mitm_path)
os.environ["mitm_path"] = mitm_path
cmd = r"mitmdump -s D:\mycode\gitpull\playwright_study\mitmproxy_hf\pytest_mitm_selenium\addons.py"
#cmd = "mitmdump"
process = subprocess.Popen(cmd, creationflags=subprocess.CREATE_NEW_CONSOLE)
time.sleep(1)
yield
time.sleep(1)
print("stop mitm")
process.kill()
@pytest.fixture(scope="session")
def setup_driver():
my_driver = RAPDriver()
my_driver.login()
yield my_driver
my_driver.login_out()
selenium的demo文件rap_kanban.py
import os
import time
from datetime import datetime
from functools import reduce
import allure
from selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.support.ui import WebDriverWait
URL = "*******************" #被测试的url
USERNAME = "用户名"
PASSWORD = "密码"
def detection_time(func):
def wrap(*args, **kwargs):
start_time = time.time()
res = func(*args, **kwargs)
end_time = time.time()
print("耗时:%s" % (end_time - start_time - res))
return res
return wrap
class RAPDriver:
def __init__(self, url=URL, username=USERNAME, password=PASSWORD):
self.url = url
self.username = username
self.password = password
options = webdriver.ChromeOptions()
options.add_argument(r"user-data-dir=C:\Users\hanfang9\AppData\Local\Google\Chrome\User Data1")
options.add_argument("--proxy-server=http://%s" % os.environ.get("mitm_proxy"))
options.add_experimental_option("excludeSwitches", ['enable-automation', 'enable-logging'])
self.driver = webdriver.Chrome(options=options,
executable_path=r"C:\Program Files\Google\Chrome\Application\chromedriver.exe")
# driver.implicitly_wait(10) executable_path=''
self.title = None
self.wait = WebDriverWait(self.driver, 10000)
self.result = []
self.result_png = ''
# 时间戳控制结果
self.my_time = datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
@allure.step("登录")
def login(self):
with allure.step("用户名:{}---密码:{}".format(self.username, self.password)):
self.driver.get(self.url)
self.driver.maximize_window()
username = self.wait.until(lambda x: x.find_element(by="id", value="username"))
username.clear()
username.send_keys(self.username)
passworld = self.driver.find_element(by="id", value="password")
passworld.clear()
passworld.send_keys(self.password)
login_button = self.driver.find_element(by="id", value="formsubmitButton")
login_button.click()
print("-------------------------------------登录成功-------------------------------------")
@allure.step("登出")
def login_out(self):
self.driver.quit()
print("-------------------------------------登出成功-------------------------------------")
def check_page(self):
for w in range(10):
print("\t\t\t第%s次尝试点击下一页" % w)
try:
button_next = self.wait.until(lambda x: x.find_element(by="xpath",
value='//*/li[@title="下一页"]'))
button_next.click()
time.sleep(3)
# 滚动到浏览器顶部
js_top = "var q=document.documentElement.scrollTop=0"
self.driver.execute_script(js_top)
return
except Exception:
continue
def click_tu(self):
for w in range(10):
print("\t\t\t第%s次尝试获取查询的看板" % w)
tus = self.wait.until(lambda x: x.find_elements(by="class name", value="card-with-img___2zBnS"))
try:
for ru in tus:
ru.click()
time.sleep(1)
return
except Exception:
continue
def clear_headle(self):
time.sleep(10)
handles = self.driver.window_handles
handle_to = None
for handle in handles:
self.driver.switch_to.window(handle)
if self.driver.title != self.title:
try:
# 截图搞出来
temp = self.driver.current_url
self.screenshot(temp.split("/")[-1])
if "暂无数据" in self.driver.page_source:
time.sleep(1)
pass_url = []
if temp not in pass_url:
self.result.append(temp)
# temp = temp.split("/")[-1]
# self.screenshot(temp)
self.driver.close()
except Exception as e:
print("关闭失败")
continue
else:
handle_to = handle
self.driver.switch_to.window(handle_to)
def screenshot(self, png_name):
# 这个是二进制文件流
png_data = self.driver.get_screenshot_as_png()
allure.attach(png_data, png_name, allure.attachment_type.PNG)
@detection_time
def test_tu(self, test_data):
self.login()
# 看板查询按钮和输入看板名称输入框
input1 = self.wait.until(lambda x: x.find_element(by="xpath", value='//*[@id="advanced_search_name"]'))
search_button = self.wait.until(
lambda x: x.find_element(by="xpath", value='//*[@id="advanced_search"]/div/div[5]/button[1]/span'))
index = 0
self.title = self.driver.title
print(self.title)
for i in test_data:
try:
index += 1
print("查询第%s个数据: %s" % (index, i))
time.sleep(1)
# 输入查询的看板名称
input1.send_keys(Keys.CONTROL, 'a')
time.sleep(1)
input1.send_keys(i)
search_button.click()
time.sleep(3)
total_num = self.driver.find_element(by="xpath",
value='//*[@id="root"]/div/section/div/main/div/div[2]/div/div/div[1]/ul/li[1]')
total_num = total_num.text.split()[-2]
page_num = int(int(total_num) / 10) + 1
print("\t一共多少页:%s--%s" % (total_num, page_num))
for y in range(page_num):
print("\t\t第%s页" % (y + 1))
self.click_tu()
if y != page_num - 1:
self.check_page()
self.clear_headle()
except Exception as e:
print(e)
print("失败:%s" % i)
continue
self.login_out()
for i in self.result:
print(i)
@detection_time
@allure.step("测试方法入口")
def test_case(self, test_data):
res = []
res_index = 0 if len(self.result) == 0 else len(self.result)
# 看板查询按钮和输入看板名称输入框
input1 = self.wait.until(lambda x: x.find_element(by="xpath", value='//*[@id="advanced_search_name"]'))
search_button = self.wait.until(
lambda x: x.find_element(by="xpath", value='//*[@id="advanced_search"]/div/div[5]/button[1]/span'))
self.title = self.driver.title
try:
print("查询数据: %s" % test_data)
time.sleep(1)
# 输入查询的看板名称
input1.send_keys(Keys.CONTROL, 'a')
time.sleep(1)
input1.send_keys(test_data)
search_button.click()
time.sleep(3)
total_num = self.driver.find_element(by="xpath",
value='//*[@id="root"]/div/section/div/main/div/div[2]/div/div/div[1]/ul/li[1]')
total_num = total_num.text.split()[-2]
page_num = int(int(total_num) / 10) + 1
print("\t一共多少页:%s--%s" % (total_num, page_num))
for y in range(page_num):
print("\t\t第%s页" % (y + 1))
self.click_tu()
if y != page_num - 1:
self.check_page()
self.clear_headle()
except Exception as e:
print(e)
print("失败:%s" % test_data)
try:
res = self.result[res_index:]
result_url = reduce(lambda a, b: a + b,
map(lambda x: '{}'.format(x, x), res))
except Exception:
result_url = ""
if result_url:
html_content = """
- """ + result_url[:-4] + """
"""
print(result_url)
allure.attach(html_content, "查询失败的url", allure.attachment_type.HTML)
result_url_total = reduce(lambda a, b: a + b,
map(lambda x: '{} '.format(x, x),
self.result))
html_content_total = """
- """ + result_url_total[:-4] + """
"""
allure.attach(html_content_total, "查询失败的url_total", allure.attachment_type.HTML)
if result_url:
return False
else:
return True
if __name__ == '__main__':
driver = RAPDriver(URL, USERNAME, PASSWORD)
driver.test_tu(["测试"])
用例文件:
import allure
import pytest
testdata = ['智能坐席助手', '通过率', '互联网金融协会当日发起实时查询量']
@allure.feature("看板检查")
@pytest.mark.usefixtures("setup_mitmdump")
@pytest.mark.parametrize("test_data", testdata)
def test_kanban(test_data, setup_driver):
result = setup_driver.test_case(test_data)
assert result, "有查询失败数据"效果:mitmproxy+selenium+pytest+allure_哔哩哔哩_bilibili
pytest -v 路径\test_rap.py --alluredir=./report
allure generate ./report -o ./html
(3)测试中试试mock请求
工作中遇到问题:A. 外部依赖接口没有数据,不想等着找其他部门去找有数的情况
B.特定的入参才有数据的接口,需要实时修改入参
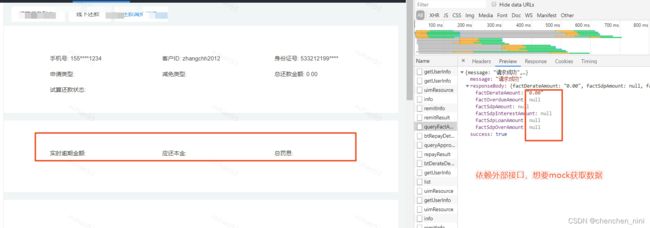
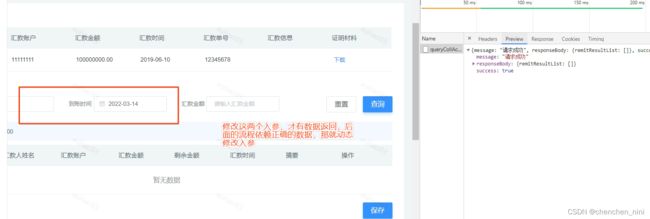
A问题
 B问题
B问题
这里的请求header中Content-Type:application/json
上面获取不到json的入参的时候我修改了urlencoded_form方法的代码,这里似乎不太好用了
我考虑欠佳

在上图代码下面添加
def _get_application_json(self):
is_valid_content_type = "application/json" in self.headers.get("content-type", "").lower()
if is_valid_content_type:
try:
return jsonpart.decode(self.headers, self.content)
except ValueError:
pass
return ()
def _set_application_json(self, value):
self.content = mitmproxy.net.http.jsonpart.encode(self.headers, value)
self.headers["content-type"] = "application/json"
@property
def application_json(self):
return multidict.MultiDictView(
self._get_application_json,
self._set_application_json
)
@application_json.setter
def application_json(self, value):
self._set_application_json(value)其实是仿照multipart_form写的

import re
import mimetypes
from urllib.parse import quote
from mitmproxy.net.http import headers
import json
def encode(head, l):
k = head.get("content-type")
if k:
k = headers.parse_content_type(k)
if k is not None:
return bytes(l[0],encoding="utf-8")
def decode(hdrs, content):
"""
Takes a multipart boundary encoded string and returns list of (key, value) tuples.
"""
v = hdrs.get("content-type")
if v:
v = headers.parse_content_type(v)
r = []
if content is not None:
r.append(content.decode("utf-8"))
return r
return []
然后自己的业务代码:

 使用方法:代码写好后,我启动了mitmdump后,启动一个浏览器设置代理,这样这个浏览器有代理,其他浏览器也不耽误使用,不必要吧所有访问都修改拦截
使用方法:代码写好后,我启动了mitmdump后,启动一个浏览器设置代理,这样这个浏览器有代理,其他浏览器也不耽误使用,不必要吧所有访问都修改拦截
appium+mitmproxy
(未更新完)
第一步:python能使用appium
(1)安装nodejs:Node.js
配置环境变量:D:\Program Files\nodejs(你的安装路径)
(2)安装appium:Appium: Mobile App Automation Made Awesome.
(3)安装安卓软件开发工具包:AndroidDevTools - Android开发工具 Android SDK下载 Android Studio下载 Gradle下载 SDK Tools下载
也可以通过Android Studio下载SDK:https://developer.android.com/studio/index.html?hl=zh-cn
配置环境变量:ANDROID_HOME=C:\Users\hanfang9\AppData\Local\Android\Sdk
PATH添加 %ANDROID_HOME%\tools
%ANDROID_HOME%\platform-tools
(4)JDK(省略)
(5)python和驱动
pip install Appium-Python-Client
(6)模拟器:MuMu模拟器官网_安卓模拟器_网易MuMu手游模拟器
*****************************************************************************************************
我的手机是华为的鸿蒙系统:还没有搞定
鸿蒙系统链接appium:appium学习笔记03-鸿蒙系统连接appium - Rookie_C - 博客园

adb命令链接模拟器:
adb connect 127.0.0.1:7555
adb devices
adb shell
dumpsys activity|grep mFocusedActivity






selenium+mitmproxy