学Python基础这一篇就够了
一、基础课程安排

| 序号 | 内容 | 目标 |
|---|---|---|
| 01 | LInux基础 | 让大家对Ubuntu的使用从很陌生到灵活操作 |
| 02 | Python基础 | 涵盖Python基础知识,让大家掌握基础的编程能力 |
| 03 | Python面向对象 | 介绍Python的面向对象开发,为开发项目做好铺垫和准备 |
pycharm:
设置一:
1、打开pycharm,然后进入“File→→Settings→→Editor→→File and code Templates”界面,然后点击“Python Script”.
2、在右侧输入框中设置以下代码,然后保存即可。
##!/usr/bin/python3
# -*- coding: utf-8 -*-
# @Time : ${DATE} ${TIME}
# @Author:未晞~
# @FileName: ${NAME}.py
# @Software: ${PRODUCT_NAME}

设置二:字体大小与颜色

如果想改为英文
依次点击:文件-设置-插件-上方的“已安装”-中文语言包右侧设置按钮-选择禁用-点击确定-弹窗选择重新启动。
1.1、anaconda+pycharm安装(思考再三,还是出一期安装教程)
1.1.1、anaconda安装
anaconda官方下载Anaconda | Anaconda Distribution。官网下载比较慢,给大家推荐清华源的下载地址: Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror 。
进入后选择最下方的Anaconda3,3的意思就是Python3以上的版本,如果是anaconda2则就是python2,此处推荐下载Anaconda3 注:x86是32位的,而x86_64就是64位的。
下载完成后运行安装:

同意用户协议:

选择为所用用户安装或只是为自己安装,选择All Users:

选择安装路径(路径不能有中文):

这里建议将第一个勾选(将Anaconda添加到环境变量中,不勾选的话后期要自己添加到环境变量):

开始安装:

安装完成,这里提示是否安装微软的VSCode 直接Skip跳过。

安装完成后在开始菜单中就会有anaconda程序。

1.1.2、pycharm安装
pycharm官方下载地址:Download PyCharm: Python IDE for Professional Developers by JetBrains 。
下载完成后开始运行安装

选择安装位置(不能有中文):

创建桌面启动图标,32位和64位的,可多选。下方关联.py文件的,建议不勾选。

点Install 开始安装。安装完成,启动PyCharm。
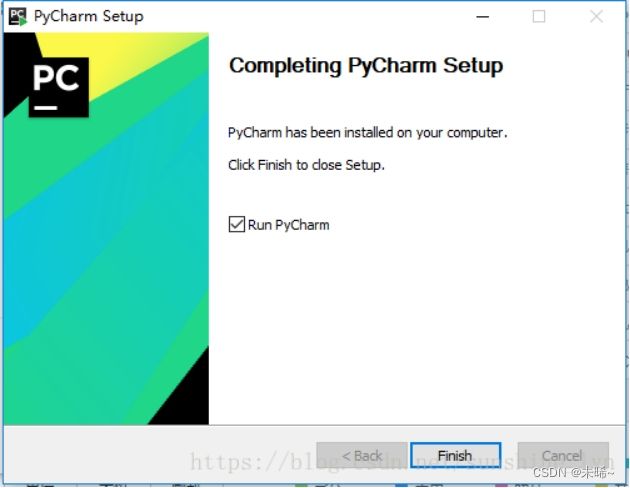
这里是提示导入PyCharm的设置,首次安装不需要导入,选择下面那个选项,点OK 。
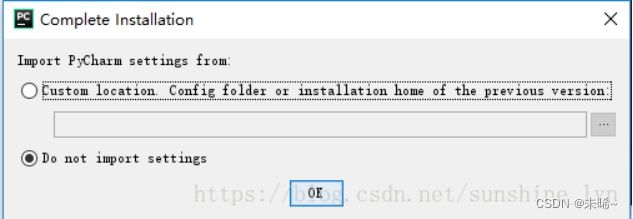
这里是Pycharm 的激活界面,专业版的可以免费试用30天,选择Evaluate for free ,然后点下面的Evaluate按钮。
这个位置就是告诉你Pycharm 的用户协议的地址。点Accept 接受就行了。

这个页面是选择页面风格,建议默认黑色就好。之后也可以设置的。

这里是选择安装插件,建议安装中间那个Markdown就可以(csdn上也有markdown编辑器,有时候可以直接复制粘贴过来,非常的方便)。安装完成后点右下角启动Pycharm。
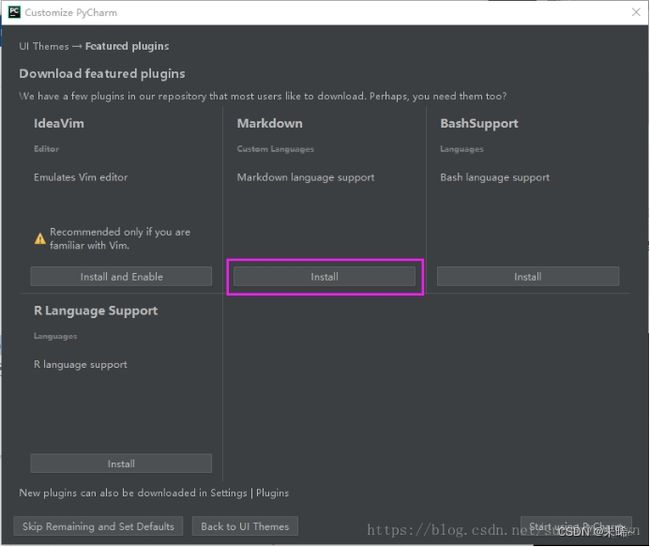
这里就是Pycharm 启动界面了,这里是选择创建一个项目还是打开一个项目:

选择创建一个项目,选择好项目目录,然后就可以进入Pycharm了。

这是Pycharm的每日提示,看不懂的话直接左下角取消勾选,然后Close 就行了。

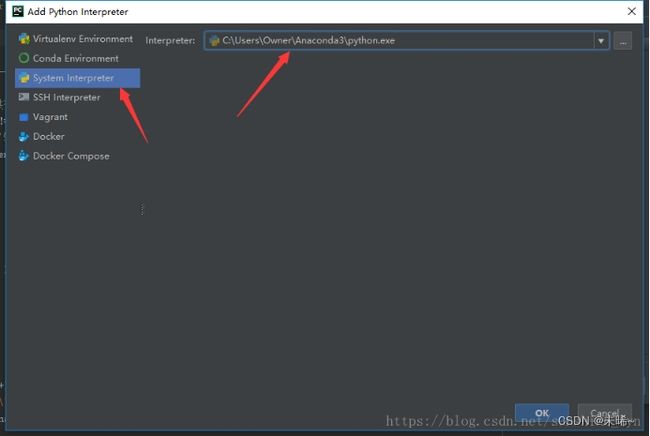
安装完Pycharm之后需要设置关联一下解释器才能正常工作。
运行PyCharm ,进入设置(Ctrl+Alt+S)
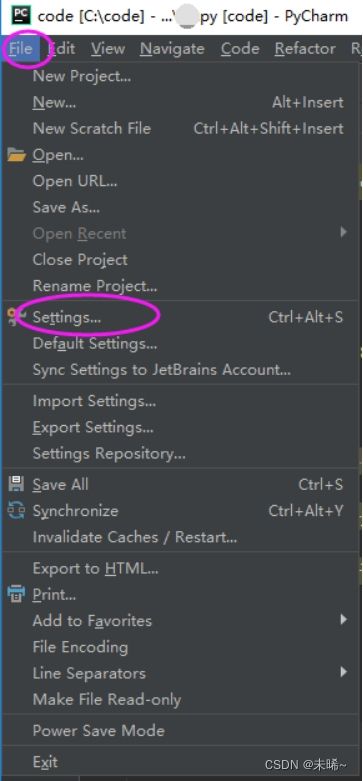
点击加号,在这里添加Anaconda安装目录下的Python.exe路径就可以了。

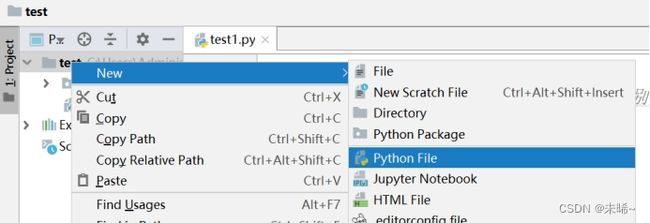
安装完成后,在新建项目中新建一个python文件:
运行以下代码进行测试,验证anaconda3是否可用,如果不可用会提示numpy包未加载:
**# -\*- coding: utf-8 -***** import numpy **as** np **#一般以np作为numpy的别名** **a = np.array([2, 0, 1, 5]) **#创建数组 **print(a) **#输出数组 **print(a[:3]) **#引用前三个数字(切片) **print(a.min()) **#输出a的最小值 **a.sort() **#将a的元素从小到大排序,此操作直接修改a,因此这时候a为[0, 1, 2, 5] **b= np.array([[1, 2, 3], [4, 5, 6]]) **#创建二维数组 **print(b*b)**#输出数组的平方阵,即[[1, 4, 9], [16, 25, 36]]**
1.1、什么是操作系统
1.2、不同应用领域的主流操作系统
-
桌面操作系统
-
Windows系列 用户群体大
-
macOS 适用于开发人员
-
Linux 应用软件少
-
服务器操作系统
-
Linux 安全、稳定、免费;占用率高
-
Window Serve 付费,占用率低
-
嵌入式操作系统 Linux 智能硬件,智能家居,智能机器人
-
移动设备操作系统 IOS Android (基于Linux)
1.3、虚拟机
虚拟机是指通过软件模拟的具有完整硬件系统功能的,运行在一个完全隔离环境中的完整计算机系统
-
虚拟系统通过生成现有操作系统的全新虚拟镜像,具有真实操作系统完全一样的功能
-
进入虚拟系统后,所有操作都是在这个全新的独立的虚拟系统里面进行,可以独立安装运行软件,保存数据,拥有自己的独立桌面,不会对真正的系统产生任何影响
-
而且能够在现有系统与虚拟镜像之间灵活切换的一类操作系统
2、Linux内核及发行版
2.1、Linux内核版本
-
内核(kernel)是系统的心脏,是运行程序和管理像磁盘和打印机等硬件设备的核心程序,它提供了一个在裸设备与应用程序间的抽象层。
-
Linux内核版本又分为 稳定版和开发版,两种版本是相互关联,相互循环
-
稳定版:具有工业强度,可以广泛应用和部署。新的稳定版相当于较旧的只是修改了一些bug或加入一些新的驱动程序。
-
开发版:由于要试验各种解决方案,所以变化得快
-

2.2、文件和目录
2.2.1、单用户操作系统和多用户操作系统(科普)
-
单用户操作系统:指一台计算机在同一时间 只能由一个用户使用,一个用户独自享用系统的全部硬件和软件资源。
-
Windows XP之前的版本都是单用户操作系统
Unix和Linux的设计初衷就是多用户操作系统
2.2.2、Windows和Linux文件系统区别

2.3、Linux主要目录速查表
-
/:根目录,一般根目录下只存放目录,在 linux 下有且只有一个根目录,所有的东西都是从这里开始
-
当在终端里输入
/home,其实是在告诉电脑,先从/(根目录)开始,再进入到home目录
-
-
/bin、/usr/bin:可执行二进制文件的目录,如常用的命令 ls、tar、mv、cat 等
-
/boot:放置 linux 系统启动时用到的一些文件,如 linux 的内核文件:
/boot/vmlinuz,系统引导管理器:/boot/grub -
/dev:存放linux系统下的设备文件,访问该目录下某个文件,相当于访问某个设备,常用的是挂载光驱
mount /dev/cdrom /mnt -
/etc:系统配置文件存放的目录,不建议在此目录下存放可执行文件,重要的配置文件有
-
/etc/inittab
-
/etc/fstab
-
/etc/init.d
-
/etc/X11
-
/etc/sysconfig
-
/etc/xinetd.d
-
-
/home:系统默认的用户家目录,新增用户账号时,用户的家目录都存放在此目录下
-
~表示当前用户的家目录 -
~edu表示用户edu的家目录
-
-
/lib、/usr/lib、/usr/local/lib:系统使用的函数库的目录,程序在执行过程中,需要调用一些额外的参数时需要函数库的协助
-
/lost+fount:系统异常产生错误时,会将一些遗失的片段放置于此目录下
-
/mnt: /media:光盘默认挂载点,通常光盘挂载于 /mnt/cdrom 下,也不一定,可以选择任意位置进行挂载
-
/opt:给主机额外安装软件所摆放的目录
-
/proc:此目录的数据都在内存中,如系统核心,外部设备,网络状态,由于数据都存放于内存中,所以不占用磁盘空间,比较重要的文件有:/proc/cpuinfo、/proc/interrupts、/proc/dma、/proc/ioports、/proc/net/* 等
-
/root:系统管理员root的家目录
-
/sbin、/usr/sbin、/usr/local/sbin:放置系统管理员使用的可执行命令,如 fdisk、shutdown、mount 等。与 /bin 不同的是,这几个目录是给系统管理员 root 使用的命令,一般用户只能"查看"而不能设置和使用
-
/tmp:一般用户或正在执行的程序临时存放文件的目录,任何人都可以访问,重要数据不可放置在此目录下
-
/srv:服务启动之后需要访问的数据目录,如 www 服务需要访问的网页数据存放在 /srv/www 内
-
/usr:应用程序存放目录
-
/usr/bin:存放应用程序
-
/usr/share:存放共享数据
-
/usr/lib:存放不能直接运行的,却是许多程序运行所必需的一些函数库文件
-
/usr/local:存放软件升级包
-
/usr/share/doc:系统说明文件存放目录
-
/usr/share/man:程序说明文件存放目录
-
-
/var:放置系统执行过程中经常变化的文件
-
/var/log:随时更改的日志文件
-
/var/spool/mail:邮件存放的目录
-
/var/run:程序或服务启动后,其 PID 存放在该目录下
-
2.4、Ubuntu图形界面入口
目标
-
熟悉
二、Python学习
1、第一个Python程序
-
第一个helloPython程序
-
Python 2.x与3.x版本简介
-
执行Python程序的三种方式
-
解释器——Python/python2
-
交互式——ipython
-
集成开发环境——PyCharm,anaconda
An error occurred while creating a new notebook.
解决方案:打开cmd,输入jupyter notebook,这样打开的jupyter就能新建python文件了。
-
1.1、Python源程序的基本概念
-
Python源程序就是一个特殊格式的文本文件,可以使用任意文本编辑软件做Python的开发
-
Python程序的文件扩展名是.py
1.2、print(‘helloworld’,’a+’)
print()函数:
-
功能:向目的地输出内容
-
输出的内容:数字、字符串、表达式
-
目的地:IDLE、控制台、文件
print(3 ** 3)
# 将数据输出文件中,注意点:1、所指定的盘符必须存在。2、使用file=fp
# 'a+'如果文件不存在就创建,如果文件存在就在文件内容的后面继续追加
fp=open('D:/text.txt','a+')
print('helloworld',file=fp)
fp.close()
# 不进行换行输出(输出内容在一行当中)
# 逗号会有空格
print('hello','world'+'python')
1.3、转义字符
1.3.1、什么是转义字符
就是反斜杠+想要实现的转义功能首字母
1.3.2、为什么需要转义字符
当字符中包括反斜杠、单引号和双引号等有特殊用途的字符时,必须使用反斜杠对这些字符进行转义(转换一个含义)
-
反斜杠:\ \
-
单引号:\ '
-
双引号:\ “
当字符串中包括换行、回车、水平制表符或退格等无法直接表示的转义字符时,也可以使用转义字符。
-
换行:\ n
-
回车 :\ r
-
水平制表符:\ t
-
退格: \b
# =========转义字符======================================================
print('hello\nworld')
print('hello\tworld')
print('hello\rworld') #回车,相当于后面一个将hello替换掉
print('hello\bworld')#/b表示退一格
print('子曰:\'学而时习之,不亦说乎\'')
# 原字符,不希望字符串中的转义字符起作用,就是用原字符,就是在字符串之前加上r或者R
print(r'子曰:’君子和而不同‘')
#注意:最后一个字符不能是反斜杠2、
Pycharm快捷键:
Alt + Enter 快速修正
Ctrl + Alt + L 代码格式化
Tab / Shift + Tab 缩进、不缩进当前行
Ctrl + Space 基本的代码完成(类、方法、属性)
Ctrl + Alt + Space 快速导入任意类
Ctrl + Shift + Enter 语句完成
Ctrl + P 参数信息(在方法中调用参数)
Ctrl + F12弹出文件结构
Tab+选中的内容 一起缩进 shift+tab 返回刚刚的缩进
ctrl+鼠标左键,进入builtins.py文件,如下图
2.1、二进制与字符编码
Unicode汉字编码表
ASCII码
因为不论英文还是中文,在程序中都叫做字符
print(chr(0b100111001011000))
print(ord('乘'))
2.2、Python中的标识符与保留字
2.2.1、保留字:
有一些单词,被python赋予了特定的含义,这些单词在Python中起任何名字时都不能使用
import keyword
print(key)
#得到保留字
['False', 'None', 'True', '__peg_parser__', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']2.2.2、标识符
-
变量、函数、类、模板和其他对象的起的名字就叫标识符
-
规则:
-
字母、数字、下划线_
-
不能以数字开头
-
不能是我的保留字
-
我是严格要求区分大小写的
-
2.3、Python中的变量与数据类型
变量是内存中一个带标签的盒子
2.3.1、变量的定义和使用
-
变量是由三部分组成
-
标识:表示对象所存储的内存地址,使用内置函数id(obj)来获取
-
类型:表示的是对象的数据类型,使用内置函数type(obj)来获取
-
值:表示对象所存储的具体数据,使用print(obj)可以将值进行打印输出
-
当变量被多次赋值之后,变量名会指向新的空间
2.3.2、数据类型
-
常见的数据类型
-
整数类型:int
-
整数的不同进制表示
-
十进制》默认的进制
-
二进制》以0b开头
-
八进制》以0o开头
-
十六进制》以0x开头
-
-
-
浮点数类型: float
-
浮点数由整数部分和小数部分组成
-
浮点数存储不精确性
-
使用浮点数计算的时候,可能会出现小数位数不确定的情况
print(1.1+2.2) #3.3000000000000003 print(1.2+1.2)#2.4
解决方案如下:引入decimal
# 解决方法 from decimal import Decimal print(Decimal('1.1')+Decimal('2.2') -
-
-
- 布尔类型: bool --True,False
-
字符串类型:str
-
字符串类型,字符串又被称为不可变的字符序列
-
可以使用单、双、三
-
单引号和双引号定义的字符串必须在一行,当然可以通过转义字符来转义掉那个空格,例如如下图:
-

-
三引号定义的字符串可以分布在连续的多行’‘’ ‘’‘或’‘’‘’‘ ’‘’‘’‘
-
-
2.3.3、数据类型转换
| 函数名 | 作用 | 注意事项 | 举例 |
|---|---|---|---|
| str() | 将其他数据类型转换成字符串 | 也可以用引号转化 | str(123) ‘123’ |
| int() | 将其他数据类型转换为整数 | 1、文字类和小数类字符串,无法转化为整数2、浮点数转化为整数,抹零取整 | int(‘123’)int(9.8) |
| float() | 将其他数据类型转化为浮点数 | 1、文字类无法转为整数2、整数转成浮点数 | float(9)float(‘9.9’) |
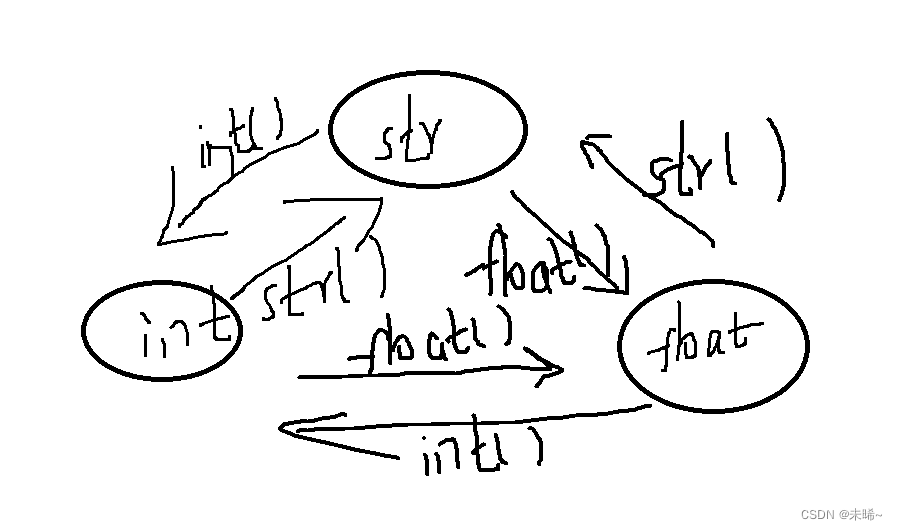
#python divmod() 函数把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b)。
print(divmod(20**22,7))
print(str(123),
int('123'),
int(9.8),
float(9),
float('9.9'))
s1 = '192.168'
s2 = '72'
s3=True
i = 98
print(type(s1),type(s2),type(s3),type(i))
print(float(s1),type(float(s1)))
print(float(s2),type(float(s2)))
print(float(s3),type(float(s3)))
print(float(i),type(float(i)))

2.4、Python中的注释
-
在代码中对代码的功能进行解释说明的标注性文字,可以提高代码的可读性
-
注释的内容会被解释器忽略
-
通常包括三种类型的注释
-
单行注释 ’#‘开头,直到换行结束
-
多行注释,并没有单独的多行注释标记,将一对三引号之间的代码称为多行注释
-
中文编码声明注释,在文件开头加上中文声明注释,用以指定源代码文件的编码格式
-
3、
3.1、Python的输入函数input()
-
作用:接收来自用户的输入
-
返回值类型:输入值的类型为str
-
值的存储:使用=对输入的值进行存储
present = input("孙冠楠想要什么礼物:")
print(present,type(present))
#从键盘上录入两个整数,计算两个整数的和。但是输入的数据都是字符串类型的,所以下面三行代码不能简单的实现加减功能
'''a=input()
b = input()
print(a+b)
'''
# 对上面的代码进行改进,
# 第一种改进
a = int(input())
b = int(input())
print(a+b)
# 第二种改进
a2 = input()
a2 = int(a2)
b2 =input()
b2 = int(b2)
print(a2+b2)3.2、Python中的运算符
-
算数运算符
-
标准算术运算符
-
取余运算符
-
幂运算符
-
-
赋值运算符
-
执行顺序:右→左
-
支持链式赋值:a=b=c=20 相当于引用,a,b,c都指向同一空间,所以id相同
-
支持参数赋值:+=、-=、*=、/=、//=、%=
-
支持系列解包赋值:a,b,c=20,30,40(注意:左右变量的个数和值的个数一定要对应) 优点:交换
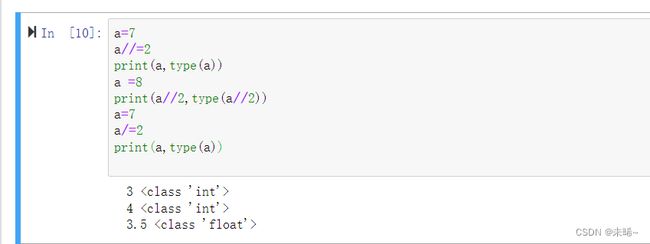
a=b=c=30 print(a) a = input() print(a) print(a,id(a)) print(b,id(b)) print(c,id(c)) #但是新输入的地址与之前赋值的地址不同,实验结果如下图 a,b,c = 20,30,40 print(a,b,c) a=7 a//=2 print(a,type(a)) a =8 print(a//2,type(a//2)) a=7 a/=2 print(a,type(a)) #交换 a,b = 10,20 print(a,b) a,b = b,a print(a,b)

-
-
比较运算符
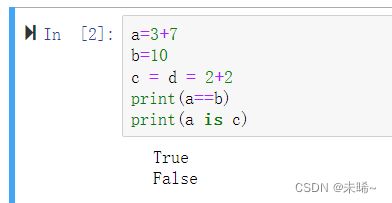
每个对象都相当于被封装在一个容器中,我们定义的变量就好像把他们指向数值本来的盒子,所以这个id是相同的,相当于共享
但是当是数组时,就不能这样了,(原因:如果两个数组使用一个id,那么一个数组的值改变,另一个也就改变,不具有唯一性),其实名字不同id不同。
实验结果如下图:
a==b:说明,a与b的value相等
a is b:说明,a与b的id标识相等

数组的实验:


-
布尔运算符
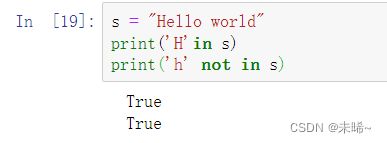
布尔运算符就是两个布尔值之间的运算,布尔运算符有如下几个:
and, or, not, in , not in
-
位运算符
将数据转成二进制进行计算
位运算符包括:
-
&, |, << (高位溢出舍弃,低位补0)左移, >>(低位溢出舍弃,高位补0)

-
Python一切皆对象,所有对象都有一个布尔值
-
获取对象的布尔值
-
使用内置函数bool()
-
-
-
以下对象的布尔值为False
-
False
-
数值0
-
None
-
空字符串
-
空列表
-
空元组
-
空字典
-
空集合
-
-
print(bool(False))#False
print(bool(0))#False
print(bool(None))#False
print(bool(''))#False
print(bool(""))#False
print(bool([]))#False
print(bool(list()))#False 空列表
print(bool(()))#空列表
print(bool(tuple()))#空元组
print(bool({}))#空字典
print(bool(dict()))#空字典
print(bool(set()))#空集合3.3、运算符的比较级
算术运算>>位运算>>比较运算>>布尔运算>>赋值运算
4、各种执行语句
4.1、选择结构
if单分支与双分支 if 执行的条件: 执行的语句2 else: 执行的语句2 典例1: a = int(input()) if a%2: print(a,"奇数") else: print(a,"偶数") if多分支结构 语法: if 条件表达式1: 条件执行语句 elif 条件表达式2: 条件执行语句2 elif 条件表达式3: 条件执行语句3 [else:] 执行语句典例2: b = int(input()) if b == 1: print(1) elif b>1: print("da") else: print("small")
4.2、pass语句
语句什么都不做,只是一个占位符,用在语法上需要语句的地方
-
什么时候使用:
先搭建语法结构,还没想好代码怎么写的时候
-
哪些语句一起使用
-
if语句的条件执行体
-
for-in语句的循环体
-
定义函数时的函数体
-
4.3、range()函数
-
用于生成一个整数序列
-
创建range对象的三种方式
-
range(stop)— 创建一个(0,stop)之间的整数序列,步长为1
-
range(start,stop)-- 创建一个(start,stop)之间的整数序列,步长为1
-
range(start,stop,step)– - 创建一个(start,stop)之间的整数序列,步长为step
-
-
返回值是一个迭代器对象
r = range(0,19)#默认从0开始,长度为19,步长为1
m = range(2)
print(r)#结果:range(0, 19)
#list 用于查看range对象中的整数序列,---list 是列表的意思
print(list(r))#[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18]
print(list(m))#[0, 1]-
range类型的优点:不管range对象表示的整数序列有多长,所有range对象占用的内存空间都是相同的,因为仅仅需要存储start,stop和step,只有当用到range对象时,才会去计算序列中的相关元素
-
in与not in 判断整数序列中是否存在(不存在)指定的整数
4.4、循环结构
-
反复做同一件事称为循环
-
循环的分类
-
while
-
for-in
-
4.4.1、while循环
-
语法结构
while条件表达式:
条件执行体(循环体)
-
选择结构的if与循环结构while 的区别
-
if是判断一次,条件为True执行一次
-
while是判断N+1次,条件为True判断N次
-
-
初始化变量 while条件判断 条件执行体(循环体) 改变变量 ==注==结束循环使用缩进来实现
#while循环 i=1 sum = 0 while i<=100: sum+=i i+=1 print(sum)
4.4.2、for-in循环
-
in表达从(字符串、序列等)中依次取值,又称为遍历
-
for - in遍历的对象必须是可迭代对象
-
语法结构
-
for 自定义的变量 in 可迭代对象:
循环体
-
-
循环体内不需要访问自定义变量,可以将自定义变量替换成下划线
#for-in循环
for item in 'Python':#第一次取出来的是P,将P赋值item,将item输出
print(item)
#'''
# P
# y
# t
# h
# o
# n
# '''
#range()产生一个整数序列,--》也是一个可迭代对象
for i in range(10):
print(i)
'''
0
1
2
3
4
5
6
7
8
9
'''
#当然,如果在循环体中不需要使用到自定义变量,可将自定义变量写成'_'
for _ in range(3):
print('I love Python')
'''
I love Python
I love Python
I love Python
'''
#练习:计算1到100的偶数和
sum = 0
for i in range(101):
if i%2:sum+=i
print(sum)
#25004.5、流程控制语句
4.5.1、break
用于结束循环结构,通常与分支结构if一起使用
4.5.2、continue
用于结束当前循环,进入下一次循环,通常与分支结构中的if一起使用
for item in range(1,51):
if item%5==0:
print(item)
print('--------------使用continue---------------------')
for item in range(1,51):
if item%5!=0:
continue
print(item)4.5.3、二重循环中的break和continue
二重循环中的break和continue用于控制本层循环
for item in range(3):
for j in range(1,11):
if j%2==0:
break
print(j,end='\t')
print()
///
1
1
1
for item in range(3):
for j in range(1,11):
if j%2==0:
continue
print(j,end='\t')
print()
1 3 5 7 9
1 3 5 7 9
1 3 5 7 94.6、else
与else语句配合使用的多种情况
# 只有3次都输入错误时,正常结束才会执行最后一个else
#python也是同理
for item in range(3):
pwd = input('请输入密码:')
if pwd=='8888':
print('密码正确')
break
else:
print('密码错误')
else:
print('对不起,三次密码均输入错误')
4.7、嵌套循环
外层循环执行一次,内层循环完整执行一轮
5、列表
变量存储的是一个对象的引用,就是这个变量指向那个对象的id


5.1、列表的创建与删除
5.1.1、列表的创建
列表需要使用中括号[],元素之间使用英文逗号进行分割
列表的创建方式:
-
使用中括号
-
使用内置函数list()
print('=========创建===================') #第一种 lst = ['hello','world',98] #第二种创建方式,使用内置函数list() lst2 = list(['hello','world',98]) print(id(lst2)) print(type(lst2)) print(lst2)
列表的特点
-
列表元素按顺序有序排列
-
索引映射唯一数据
-
列表可以存储重复数据
-
任何数据类型可以混存
-
根据需要动态分配和回收内存
列表组合
语法: 列表3 = 列表1 + 列表2
将列表1和列表2中的元素取出,组成一个新的列表并返回。
列表重复
语法: 列表2 = 列表1 * n
print(list*3)
#[1, True, False, 'hello', 1, True, False, 'hello', 1, True, False, 'hello']5.2、列表的查询操作
获取列表中指定元素的索引 index()
-
如查列表中存在N个相同元素,只返回相同元素中的第一个元素的索引
-
如果查询的元素在列表中不存在,则会抛出ValueError
-
还可以在指定的start和stop之间进行查找
lst = ['hello','world',98,'hello'] print(lst.index('hello'))#如果列表中有多个相同的元素,只返回列表中相同元素的第一个元素的索引 print(lst.index('Python')) #在指定范围内查找元素的索引 print(lst.index('hello',1,3)) #ValueError: 'hello' is not in list print(lst.index('hello',1,6))#3
获取列表中的单个元素
-
正向索引从0到N-1 举例:lst[0]
-
逆向索引从-N到-1,举例:lst[-N]
-
指定索引不存,抛出IndexError
print('=================获取单个元素=================')
lst = ['hello','world','my','china']
print(lst[1])
print(lst[-2])
print(lst[-4])
获取列表中的多个元素
语法格式
列表名[start:stop:step]
切片的结果:原列表片段的拷贝
切片的范围:[start,stop]
step默认为1:简写为[start:stop]
step为正数:(从start开始往后计算切片)
-
[:stop:step] :切片的第一个元素默认是列表的第一个元素
-
[start::step] : 切片的最后一个元素默认是列表的最后一个元素
step为负数:(从start开始往前计算切片)
-
[:stop:step] : 切片的第一个元素默认是列表的最后一个元素
-
[start::step] : 切片的最后一个元素默认是列表的第一个元素
print("==============获取列表的多个元素===========") lst =[1,2,3,4,5,6,78,9,10,22] print(lst[1:6:1])#开区间 lst2=lst[1:6:1] print('原列表id:',id(lst)) print('切片id:',id(lst2)) print("默认步长为1:",lst[1:6:]) print("默认步长为1,2:",lst[1:6]) print(lst[-1::]) print(lst[:-3:])

5.3、列表元素的增、删、改操作
这些方法只是在恰当的位置修改原来的列表。这意味着,它不是返回一个修改过的列表,而是直接修改原来的列表因此只要print(list.append(3))//输出none//
5.3.1、列表元素的增加操作
-
append():追加在列表的末尾添加一个元素,(因为是一个元素,所以另一个元素的左右两边的中括号都要加上)
-
append()中的值可以是列表也可以是普通元素
lst = [1,2,3,4] print('添加元素之前:', lst,id(lst)) lst.append(100) print('添加元素之后:',lst,id(lst)) print(list) lsti = ['yan','zi'] lst.append(lsti) print(lst) 添加元素之前: [1, 2, 3, 4] 2090082711488 添加元素之后: [1, 2, 3, 4, 100] 2090082711488[1, 2, 3, 4, 100, ['yan', 'zi']]
-
-
extend():延伸在列表的末尾至少添加一个元素
-
extend()中的值只能是列表/元组[一个可迭代对象(可加在for循环之后的)],打碎可迭代对象之后的元素再加入列表中,不能是元素
-
#=============extend====================
lst2 = [1,2,3,4,4,5,6,7]
lst3 = ['yan','zi']
lst4 = 'yan','zi'
print('添加元素前:',lst2) #添加元素前: [1, 2, 3, 4, 4, 5, 6, 7]
# lst2.extend(lst3)
# lst2.extend(lst3)
lst2.extend(lst3)
print('1添加元素之后:',lst2)
#1添加元素之后: [1, 2, 3, 4, 4, 5, 6, 7, 'yan', 'zi']
lst2.extend(lst4)
print('2添加元素之后:',lst2)
#2添加元素之后: [1, 2, 3, 4, 4, 5, 6, 7, 'yan', 'zi', 'yan', 'zi']
lst2.extend('yan')
print('3添加元素之后:',lst2)
#3添加元素之后: [1, 2, 3, 4, 4, 5, 6, 7, 'yan', 'zi', 'yan', 'zi', 'y', 'a', 'n']
lst2.append(lst3)
print('4append:',lst2)
#4append: [1, 2, 3, 4, 4, 5, 6, 7, 'yan', 'zi', 'yan', 'zi', 'y', 'a', 'n', ['yan', 'zi']]-
insert():在列表的任意位置添加一个元素
#在任意位置上添加一个元素 list = [1,2,3,4,5,6] print('插入前:',list)#插入前: [1, 2, 3, 4, 5, 6] list.insert(1,90) print('插入后::',list)#插入后:: [1, 90, 2, 3, 4, 5, 6] #在任意位置添加N个元素 list1 = [True,False,'hello'] #从1开始,到下标为3结束 list[0:]为全切 list[1:3] = list1 print(list)#[1, True, False, 'hello', 3, 4, 5, 6] list[1:4] = list1 print(list)#[1, True, False, 'hello', 4, 5, 6] list[1:] = list1 print(list)#[1, True, False, 'hello'] -
切片:在列表的位置添加至少一个元素
5.3.2、列表元素的删除操作
-
remove()
-
一次删除一个元素
-
重复元素
-
只删除第一个
-
元素不存在抛出ValueError
#remove list = [1,2,3,4,5,5,3,6] list.remove(3) print(list) #[1, 2, 4, 5, 5, 3, 6]
-
-
pop():根据索引移除元素
-
删除一个指定索引位置上的元素
-
指定索引不存在抛出IndexError
-
不指定索引,删除列表中最后一个元素
#pop() 根据索引移除元素 list.pop(0) print('加入索引:',list) list.pop() print('不添加索引,删除最后一个元素:',list)
-
-
切片:一次至少删除一个元素
print('==============切片操作-删除至少一个元素,将产生一个新的列表对象===================')
new_list = list[1:3]
print('原列表:',list)
print('切片后:',new_list)
'''不产生新的列表对象,而是删除原列表中的内容'''
print('使用空列表来进行替代')
list[1:3] = []
print(list)-
clear():清除列表中的所有元素
print('============================清空列表===============================')
list.clear()
print(list)-
del:删除列表
print('=================del语句将列表对象删除================')
lst=['1',2,3,4]
del lst
print(lst)#NameError: name 'lst' is not defined5.3.2、列表元素的改操作
为指定索引的元素赋予一个新值
为指定的切片赋予一个新值
lst = [10,220,30,40]
#一次修改一个值
lst[2] =100
print(lst)#[10, 220, 100, 40]
#就是将列表中指向30的指针断掉,重新指向100
lst[1:3] = [12,13,14,15]
print(lst)#[10, 12, 13, 14, 15, 40]5.4、列表元素的排序
列表元素的排序操作
-
调用sort()方法,列表中的所有元素默认按照从小到大的顺序进行排序,可以指定reverse = True,进行降序排序
lst = [20,40,90,15]
print('排序前的列表',lst,id(lst))
# 开始排序,调用列表对象的sort方法,升序排序
lst.sort()
print('排序后的列表',lst,id(lst))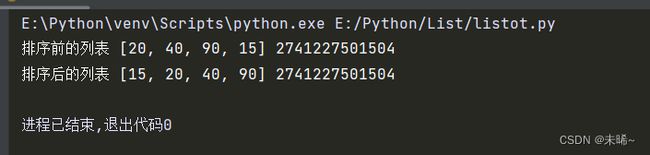
通过上图的实验结果可知,排序是在原列表的基础上进行的排序,因为id号没有发生变化
# 通过指定关键字参数,将列表中的元素进行降序排序
lst.sort(reverse=True)
print('降序排列的',lst)#降序排列的 [90, 40, 20, 15]
lst.sort(reverse=False)
print('升序排列的',lst)#升序排列的 [15, 20, 40, 90]-
调用内置函数sorted(),可以指定reverse = True,进行降序排序,原列表不发生改变
print('=----------------------------使用内置函数sorted()对列表进行排序,将产生一个新的列表对象----------------------------------=') lst=[1,2,5,4,7,12,23,32,322] print('以前的列表',lst,id(lst)) #开始排序 new_list = sorted(lst) print('新的列表对象',new_list,id(new_list)) #指定关键字参数,实现列表元素的降序排列 desc_list = sorted(lst,reverse=False) print(desc_list,id(desc_list)) =----------------------------使用内置函数sorted()对列表进行排序,将产生一个新的列表对象----------------------------------= 以前的列表 [1, 2, 5, 4, 7, 12, 23, 32, 322] 1726651271488 新的列表对象 [1, 2, 4, 5, 7, 12, 23, 32, 322] 1726650922944 [1, 2, 4, 5, 7, 12, 23, 32, 322] 1726650930048
5.5、列表推导式
5.5.1、列表生成式(简称:生成列表的公式)
列表生成式即List Comprehensions,是Python内置的非常简单却强大的可以用来创建list的生成式。
列表生成式的结构是在一个中括号里包含一个表达式,然后是一个for语句,然后是0个或多个for或者if语句。列表表达式可以是任意的。
返回结果将是一个新的列表,在这个以if和for语句位上下文的表达式运行完成之后产生。
注意事项:“表示列表元素的表达式”中通常包含自定义变量
例1: 生成一个列表,列表元素分别为 [11,22,33……nn],假设n = 10。
lis1 = []
for i in range(1,11):
lis1.append(i*i)
lis2 = [i*i for i in range(1,11)]
print(lis1)#[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
print(lis2)#[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]例2:基于例1,要求返回的序列中不存在偶数项
print('-----例2------------------------------------')
lis3 = []
for i in range(1,11):
if(i*i%2!=0):
lis3.append(i*i)
print(lis3)#[1, 9, 25, 49, 81]
#这个刚开始不会,注意奇数*奇数 = 奇数;偶数*偶数 = 偶数,所以i与i*i都差不多
list4 =[i*i for i in range(1,11) if i%2!=0]
print(list4)#[1, 9, 25, 49, 81]例3:字符串s1 ='ABC',字符串 s2 = '123',要求:生成序列 A1 A2 A3 B1 B2 B3 C1 C2 C3
print('-----例3------------------------------------')
lis5 = []
for i in 'ABC':
for j in '123':
lis5.append(i+j)
print(lis5)#['A1', 'A2', 'A3', 'B1', 'B2', 'B3', 'C1', 'C2', 'C3']
lis6 = [i+j for i in 'ABC' for j in '123']
print(lis6)#['A1', 'A2', 'A3', 'B1', 'B2', 'B3', 'C1', 'C2', 'C3']
# 列表中的元素的值为2,4,6,8,10
lst7 = [i*2 for i in range(1,6)]#记住这个地方是左闭右开
print(lst7)6、字典
-
Python内置的数据结构之一,与列表一样是一个可变序列
-
以键值对的方式存储数据,字典是一个无序的序列
-
字典的实现原理:字典的实现原理与查字典类似,查字典是现根据部首或者拼音查找对应的页码,Python中的字典是根据key(通过hash函数计算)查找value所在的位置
-
放在字典中的key必须是不可变序列(整数与字符串)
6.1、字典的创建
6.1.1、使用花括号 最常用
'''使用花括号'''
score={'张三':100,'李四':200,'王五':99}
print(score)
print(type(score))
{'张三': 100, '李四': 200, '王五': 99}
6.1.2、使用内置函数dict()
'''第二种方式使用dict()函数'''
student = dict(name = 'wangwu',age = 20)
print(student)
print(type(student))
'''创建空字典'''
student = {}
print(type(student))
{'name': 'wangwu', 'age': 20}
6.1.3、字典生成式
内置函数zip():
用于将可迭代的对象作为参数,将对象中对应的元素打包成一个元组,然后返回由这些元组组成的列表
items = ['Fruits','Books','Others']
prices = [96,97,99]
upper()是大写
d = {item.upper():price for item,price in zip(items,prices)}
print(d)#{'FRUITS': 96, 'BOOKS': 97, 'OTHERS': 99}
d = {item:price for item,price in zip(items,prices)}
print(d)#{'Fruits': 96, 'Books': 97, 'Others': 99}总结一下大小写:
-
.upper():所有都改为大写
-
.lower():所有都改为小写
-
.capitalize():首字母大写
-
.title():每个单词首字母都大写
6.2、字典的常用操作
6.2.1、字典中元素的获取
-
[]:抛出异常
-
get()方法:不会抛出异常
6.2.2、[]取值与使用get()取值的区别
-
[]如果字典中不存在指定的key,抛出keyerror异常
score={'张三':100,'李四':200,'王五':99}
'''第一种方法:'''
print(score['张三'])
100-
get()方法取值,如果字典中国不存在指定的key,并不会抛出KeyError异常而是返回None,可以通过参数设置默认的value,以便指定的key不存在时返回
'''第二种方法'''
print(score.get('李四'))
print(score.get('sun'))
print(score.get('yanzi',100))#当在查找‘yanzi’时所对应的value不存在,就返回默认值
200
None
1006.2.3、字典key的判断
-
in:指定的key在字典中返回True
-
not in :指定的key不在字典中返回True
'''key的判断'''
score = {'张三':100,'李四':200,'王5':99}
print('张三' in score)
print('王五' not in score)
6.2.4、字典元素的删除
del score['张三']#删除指定的key-value 对
# score.clear() #清空字典的元素
print(score)#{'李四': 200, '王5': 99}6.2.5、字典元素的新增
score['陈六'] = 99 #新增与修改元素
print(score)#{'李四': 200, '王5': 99, '陈六': 99}6.2.6、获取字典视图的三个方法
-
keys():获取字典中所有key
-
values():获取字典中所有value
-
items():获取字典中所有key,value对
keys = score.keys()
print(keys)
print(type(keys))
print(list(keys))
# 获取所有的value
values = score.values()
print(values)
print(type(values))
print(list(values))
# 获取所有键值对
items = score.items()
print(items)
print(list(items))#元组()。转换之后的列表元素是由元素组成
6.2.7、字典元素的遍历
score = {'张三':100,'李四':200,'王5':99}
# 字典元素的遍历
for items in score:
print(items)
for items in score:
print(items,score[items],score.get(items))
6.3、字典的特点
-
字典中的所有元素都是一个key-value对,key不允许重复,value可以重复
-
字典中的元素是无序的
-
字典中的key必须是不可变对象
-
字典也可以根据需要动态地伸缩
-
字典会浪费较大的内存,是一种使用空间换时间的数据结构
7、元组
7.1、什么是元组
元组是python内置的数据结构之一,是一个不可变序列
7.1.1、不可变序列与可变序列
-
不可变序列:字符串、元组
-
不可变序列:没有增、删、改操作,对象地址发生改变
-
-
可变序列:列表、字典
-
可变序列:可以对序列执行增、删、改操作,对象地址不发生更改
-
''' 可变序列,不可变序列 '''
''' 可变序列 :列表和字典 '''
lst = [10,20,45]
print(lst)
print(id(lst))
lst.append(300)
print(id(lst))
'''不可变序列 :字符串和元组'''
str = "hekkkoo"
print(id(str),str)
str += "sdsad"
print(id(str),str)
7.2、元组的创建方式
-
直接小括号
-
使用内置函数tuple()
-
只包含一个元祖的元素需要使用逗号和小括号
# 元组的创建方式
# 第一种使用()
t = ('Python','world',98)
print(t)
print(type(t))
print('第一种方法改进:')
t2 = 'Python','world',99#省略了小括号
print(t2)
print(type(t2))
print('需要注意的是:')
t3 = ('po')
print(t3)
print(type(t3))
#当只包含一个元组的元素需要使用逗号和小括号
print('出现上面这个问题的改进:')
t4 = ('sunguannan',)
print(t4)
print(type(t4))
# 第二种方式:使用内置函数tuple()
t1 = tuple(('Python','world',99))
print(t1)
print(type(t1))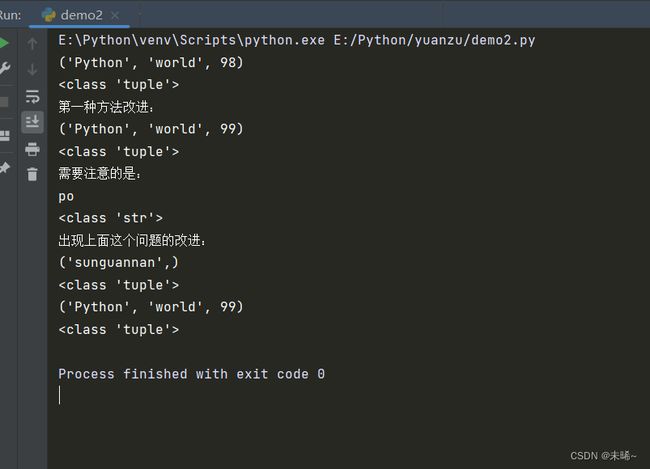
-
空列表的创建方式
# 空列表的创建方式
lst = []
lst1 = list()
print(type(lst),type(lst1))# -
空字典的创建方式
#空字典的创建方式
d = {}
d2 = dict()
print(type(d),type(d2))# -
空元组的创建方式
#空元组的创建方式
t5 = ()
t6 = tuple()
print(type(t5),type(t6))# print('空元组:',t5,t6)
print('空字典:',d,d2)
print('空列表:',lst,lst1)
#空元组: () ()
#空字典: {} {}
#空列表: [] []为什么要将元组设计成不可变序列
-
在多任务环境下,同时操作对象时不需要枷锁
-
因此,在程序中尽量使用不可变序列
-
注意事项: 元组中存储的是对象的引用
-
如果元组中对象本身不可变对象, 则不能再引用其他对象
-
如果元组中的对象时可变对象,则可变对象的引用不允许改变,但数据可以改变
-
7.3、元组的遍历
当不知道元组中有几个元素时,就不要使用索引,直接遍历
print('===========================遍历====================')
for item in t1:
print(item)
#Python
#world
#998、集合
8.1、什么是集合
-
Python语言提供的内置数据结构
-
与列表、字典一样都属于可变类型的序列
-
集合是没有value的字典
8.2、集合的创建
相当于set集合,不允许集合中的值重复
#集合的第一种创建方式,使用花括号
s = {2,3,4,5,6,7,8,9,9}
print(s)
print(type(s))
# 第二种创建方式,使用内置函数set()
s1 = set(range(6))
print(s1)
print(type(s1))
s2 = set([1,2,3,4,5,6,1])
print(s2)
print(type(s2))
s3 = set((1,2,43,2,4,65))#集合中的元素时无序的,并且不允许有重复的元素
print(s3)
print(type(s3))
s4 = set('python')
print(s4)
print(type(s4))
# 可以通过set()进行强制类型转换
s5 = set(())
s6 = set()
print(s5,s6)
print(type(s5),type(s6))
8.3、集合的增、删、改、查操作
8.3.1、集合元素的判断操作
in或not in
8.3.2、集合元素的新增操作
-
调用add()方法,一次添加一个元素
-
调用update()方法,至少添加一个元素
s = {1,2,3,4,5,6} print(12 in s) print(1 in s) print(12 not in s) print(1 not in s) # 集合的新增操作 s.add(10)#一次添加一个元素 print(s) s.update([12,13,14]) print(s) s.update((1,2,3,4,5,15,16,17)) print(s) s.update({1,2,18,19,20}) print(s)
8.3.3、集合元素的删除操作
-
调用remove()方法,一次删除一个指定元素,如果指定的元素不存在抛出KeyError
-
调用discard()方法,一次删除一个指定元素,如果指定的元素不存在不抛出异常
-
调用pop()方法,一次只删除一个任意元素
-
调用clear()方法,清空集合
print('=================集合中的删除===============')
s.remove(2)
print(s)
# s.remove(100)#KeyError: 100
# print(s)
s.discard(1)
print(s)
s.discard(100)
print(s)
s.pop()#由于集合本身是无序的,所有s.pop()确实随机删除一个元素,但是是删除哈希值最小的元素,对于字典和字符转换的集合是随机的
#且pop不能指定元素
s.pop()
print(s)
s.clear()
print(s)
{1, 3, 4, 5, 6, 10, 12, 13, 14, 15, 16, 17, 18, 19, 20}
{3, 4, 5, 6, 10, 12, 13, 14, 15, 16, 17, 18, 19, 20}
{3, 4, 5, 6, 10, 12, 13, 14, 15, 16, 17, 18, 19, 20}
{5, 6, 10, 12, 13, 14, 15, 16, 17, 18, 19, 20}
set()8.5、集合间的关系
-
两个集合是否相等
-
可以使用运算符==或!=进行判断
2.一个集合是否是另一个集合的子集
-
可以调用方法issubset进行判断
-
B是A的子集
3.一个集合是否是另一个集合的超集
-
可以调用方法issuperset进行判断
-
A是B的超集
4.两个集合是否没有交集
-
可以调用方法isdisjoint进行判断
# 一个集合是否是另一个集合的子集
s1 = {1,2,3,4,5}
s2 = {1,2,3}
s3 = {3,5,4}
print(s2.issubset(s1))
print(s3.issubset(s1))
print(s1.issubset(s2))
# 一个集合是否是另一个集合的超集(子集与超集对应相反)
print(s1.issuperset(s2))
print(s2.issuperset(s1))
# 两个集合是否含没有交集,
print(s1.isdisjoint(s2))
print(s2.isdisjoint(s3))
#交集
s1 = {10,20,30,40,50}
s2 = {20,30,40,50,60}
print(s1.intersection(s2))
print(s1 & s2) #intersection() == &
# 并集
print(s1.union(s2))
print(s1|s2)
# union 与 |等价,并集操作
# 差集操作
print(s1.difference(s2))
print(s1-s2)
# 对称差集(除了相同元素之外的)
print(s1.symmetric_difference(s2))
print(s1^s2)
8.6、集合生成式
用于生成集合的公式,因为元组是不可变序列,所以元组没有生成式
将{}修改为[]就是列表生成式了
lst = [i*i for i in range(6)]
print(lst)
[0, 1, 4, 9, 16, 25]
s = {i*i for i in range(6)}
print(s)#这是一个无序的序列
{0, 1, 4, 9, 16, 25}列表、元组、字典、集合总结
| 数据结构 | 是否可变 | 是否重复 | 是否有序 | 定义符号 |
|---|---|---|---|---|
| 列表(list) | 可变 | 可重复 | 有序 | [] |
| 元组(tuple) | 不可变 | 可重复 | 有序 | () |
| 字典(dict) | 可变 | key:不可重复;value:可重复 | 无序 | {key:value} |
| 集合(set) | 可变 | 不可重复 | 无序 | {} |
9、字符串
在Python中字符串是基本数据类型,是一个不可变的字符序列
9.1、字符串的驻留机制
9.1.1、驻留机制
仅保存一份相同且不可变字符串的方法,不同的值被存放在字符串的驻留池中,Python的驻留机制对相同的字符串只保留一份拷贝,后续创建相同字符串时,不会开辟新空间,而是把该字符串的地址赋给新创建的变量。
# 字符串的驻留机制
a = 'Python'
b = "Python"
c = '''Python'''
print(a ,id(a))
print(b,id(b))
print(c,id(c))9.1.2、驻留机制的几种情况(交互模式)
-
字符串的长度为0或1时
-
符合标识符的字符串‘abc’,而‘abc%’不是
-
字符串只在编译时进行驻留,而非运行时
-
[-5,256]之间的整数数字
sys中的intern方法强制2个字符串指向同一个对象

PyCharm对字符串进行了优化处理

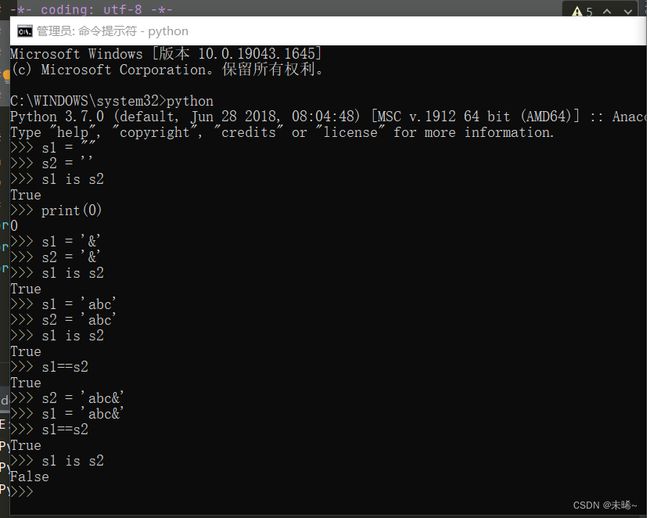
字符串驻留机制的优缺点
-
当需要值相同的字符串时,可以直接从字符串池里拿来使用,避免频繁的创建和销毁,提升效率和节约内存,因此拼接字符串和修改字符串是比较影响性能的
-
在需要进行字符串拼接时,建议使用str类型的join方法,而非+,因为join()方法是先计算出所有字符串中的长度,然后再拷贝,只new一次对象,效率要比“+”效率高
9.2、字符串的常用操作
| 功能 | 方法名称 | 作用 |
|---|---|---|
| 查询方法 | index() | 查找子串substr第一次出现的位置,如果查找的子串不存在时,则抛出ValueError异常 |
| 查询方法 | rindex() | 查找子串substr最后一次出现的位置,如果查找的子串不存在时,则抛出ValueError异常 |
| 查询方法 | find() | 查找子串substr第一次出现的位置,如果查找的子串不存在时,则返回-1 |
| 查询方法 | rfind() | 查找子串substr最后一次出现的位置,如果查找的子串不存在时,则返回-1 |
s = 'hello,hello'
print(s.index('lo'))#3
print(s.find('lo'))#3
print(s.rindex('lo'))#9
print(s.rfind('lo'))#9
# print(s.index('k'))#ValueError: substring not found
print(s.find('k'))#-1
# print(s.rindex('k'))#ValueError: substring not found
print(s.rfind('k'))#-1
字符串内容对齐操作的方法
| 方法名称 | 作用 |
|---|---|
| center() | 居中对齐,第1个参数指定宽度,第2个参数指定填充符,默认是空格,如果设置宽度小于实际宽度则返回原字符串 |
| ljust() | 左对齐,第1个参数指定宽度,第2个参数指定填充符,第2个参数是可选的,默认是空格,如果设置宽度小于实际宽度,则返回原字符串 |
| rjust() | 右对齐,第1个参数指定宽度,第2个参数指定填充符,第2个参数是可选的,默认是空格,如果设置宽度小于实际宽度,则返回原字符串 |
| zfill() | 右对齐,左边用0填充,该方法只接收一个参数,用于指定字符串的宽度,如果指定的宽度小于等于字符串的长度,则返回字符串本身 |
s = 'hello,Python'
a = s.center(20,'*')
print(a)
# 左对齐
print(s.ljust(19,'*'))
print(s.ljust(10))
print(s.ljust(22))
# 右对齐 rjust,zfill
print(s.zfill(10))
print(s.zfill(30))
****hello,Python****
hello,Python*******
hello,Python
hello,Python
hello,Python
000000000000000000hello,Python字符串劈分操作的方法
| 功能 | 方法名称 | 作用 |
|---|---|---|
| split() | 从字符串的左边开始劈分,默认的劈分字符是空格字符串,返回的值都是一个列表 | |
| 让通过参数sep指定劈分字符串式的劈分符 | ||
| 通过参数maxsplit指定劈分字符串时的最大劈分次数,在经过最大次劈分之后,剩余的子串会单独作为一部分 | ||
| rsplit() | 从字符串的右边开始劈分,默认的劈分字符是空格字符串,返回的值都是一个列表 | |
| 以通过参数sep指定劈分字符串的是劈分符 | ||
| 通过参数maxsplit指定劈分字符串时的最大劈分次数,在经过最大劈分之后,剩余的子串会单独作为一部分 |
# 字符串劈分操作的方法
s = 'hello world Python'
lst = s.split()
print(lst)
a = 'hello | world |Python'
print(a.split(sep='|'))
print(a.split(sep='|',maxsplit=1))
print(a.split())
'''rsplit()从右侧开始劈分'''
print(a.rsplit())
print(a.rsplit('|'))
print(a.rsplit(sep='|',maxsplit=1))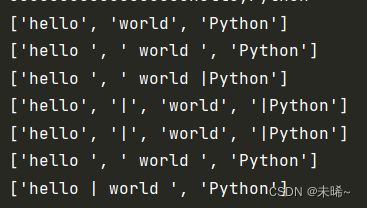
判断字符串操作的方法
| 功能 | 方法名称 | 作用 |
|---|---|---|
| 判断字符串的方法 | isidentifier() | 判断指定的字符串是不是合法的标识符 |
| isspace() | 判断指定的字符串是否全部由空白字符组成(回车、换行、水平制表符) | |
| isalpha() | 判断指定的字符串是否全部由字母组成 | |
| isdecimal() | 判断指定字符串是否全部由十进制的数字组成 | |
| isnumeric() | 判断指定的字符串是否全部由数字组成 | |
| isalnum() | 判断指定的字符串是否全部由字母和数字组成 |
s = 'hello,ppython'
print('1.',s.isidentifier())#1. False
print('2.','hello'.isidentifier())#2. True
print('3.','\t\h'.isidentifier())#3. False
print('4','张三——'.isidentifier())#4 False
print('4.','张三_123'.isidentifier())#4. True
print('5.','张三_'.isidentifier())#5. True
print('10',''.isspace())#10. False
print('2.','hello'.isspace())#2. False
print('7.','\t'.isalpha())#7. False
print('8.','AbcsuS'.isalpha())#8. True
print('9.',"Ab@".isalpha())#9. False
print('10','1021431'.isdecimal())#10 True
print('11','010110'.isdecimal())#11 True
print('12','ⅠⅡⅢⅣ'.isdecimal())#12 False
print('13','12340'.isnumeric())#13 True
print('14','ⅠⅡⅢⅣ'.isnumeric())#14 True
print('15','一二三'.isnumeric())#15 True
'''字母与数字'''
print('16','abc15 '.isalnum())#16 False
print('17','abc15'.isalnum())#17 True
print('18','张三1'.isalnum())#18 True
print('19','!ad'.isalnum())#19 False字符串操作的其它方法
| 功能 | 方法名称 | 作用 |
|---|---|---|
| 字符串替换 | replace() | replace(‘旧’,‘新’,‘最大替换次数’),即:第1个参数指定被替换的子串,第2个参数要换成的那个字符串,该方法返回替换后得到的字符串,替换前的字符串不发生变化,通过该方法时可以通过第3个参数指定最大替换次数。(问题:如何替换后两个,尝试用负数,它会将所有的都替换掉) |
| 字符串的合并 | join() | 将列表或元组中的字符串合并成一个字符串[] () |
注意:需要注意的是replace(),在十六进制与二进制这一块块需要注意一个问题。
我们想要将每一段特定长度对应的内容都要解析出来,当对这段报文进行解析编译的时候,可能会用到replace将已经解析过的部分过滤掉。
举个例子
result = []
message = 'AC260000374A5D'
messagelen = [4,2,4,2,2]
for i in range(len(messagelen)):
result.append(message[:messagelen[i]])
message = message.replace(message[:messagelen[i]],'',1)
print('right:',result)#right: ['AC26', '00', '0037', '4A', '5D']
result = []
message = 'AC260000374A5D'
messagelen = [4,2,4,2,2]
for i in range(len(messagelen)):
result.append(message[:messagelen[i]])
message = message.replace(message[:messagelen[i]],'')
print('error:',result)#error: ['AC26', '00', '374A', '5D', '']
分析: 如果不限定replace的次数是1的话,那么我们在提取第二个报文00之后,replace依然会继续替换,将0037的前面两个00也替换掉,报文的提取结果['AC26', '00', '374A', '5D', '']
lst = ['hello','java','haha']
print('|'.join(lst))#hello|java|haha
print(''.join(lst))#hellojavahaha
a = 'Hello,Python,Python,Python'
b = '123'
t = ('hekki','kkk')
print('*'.join(t))#hekki*kkk
print('-'.join(a))#H-e-l-l-o-,-P-y-t-h-o-n-,-P-y-t-h-o-n-,-P-y-t-h-o-n
print('0'.join(b))#102039.3、字符串的比较
-
运算符:> , < ,>= ,<=, == , !=
-
比较规则:首先比较两个字符串中的第一个字符,如果相等则依次比较下去,直到两个字符串中的字符不相等时,其比较结果就是两个字符串的比较结果,直到两个字符串中的所有后续字符将不再被比较
-
比较原理:两个字符串进行比较时,比较的是其ordinal value(原始值),调用内置函数ord可以得到指定字符的ordinal value。与内置函数ord对应的是内置函数chr,调用内置函数chr时指定ordinal value 可以得到其对应的字符
print('apple'>'apl')#True
print('apple'>'banana')#False
print(ord('a'))#97
print(ord('b'))#98
print(chr(97))#a
print(ord('杨'))#26472
print(chr(26472))#97
# is 是比较id是否相等
a = b = 'Python'
c = 'Python'
print(id(a))#2136950398448
print(id(b))#2136950398448
print(id(c))#2136950398448
print(a==b)#True
print(b==c)#True
print(a is b)#True
print(a is c)#True9.4、字符串的切片操作
字符串是不可变类型,不具备增删改等操作
切片操作将会产生新的对象,不再驻留
-
如果没有指定起始位置,所以从0号位置开始切
-
由于没有指定结束位置,所以切到字符串的最后一个元素
-
切片[start : end : step]
a = 'Hello,Python'
s1 = a[:6]
s2 = a[1:]
s3 = '!'
newstr = s1+s3+s2
print(s1)
print(s2)
print(newstr)
print('-----------------------------------切片----------------------------')
print(a[1:5:1])
print(a[::2])
print(a[::-1])
s4 = a[-6::1]
print(s4)
s5 = a[6:]
print(s5)
print(s4 is s5)
print(s4==s5)
print(id(s4),'111',id(s5))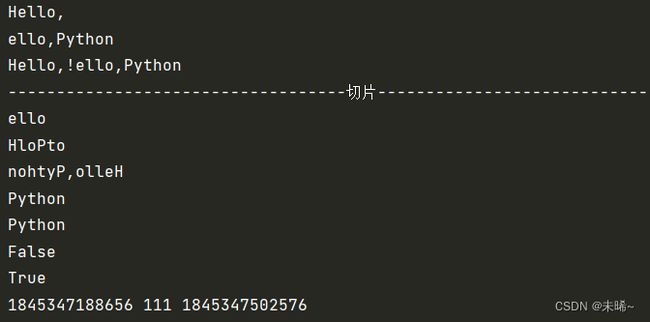
9.5、格式化字符串
-
%作为占位符
-
%i %d
-
-
{}作为占位符
name = 'Sylvia'
age = 18
# first %
print('我的名字%s,今年%d岁'%(name,age))
# second {}
print('我的名字叫:{0},今年{1}岁了,我真的叫:{0}'.format(name,age))
# third f-string
print(f'我叫{name},今年{age}岁')
# 表示精度与宽度
print('%d' %99)
print('%10d' %99)#10表示宽度
print('%f' % 3.1415926)
print('%.3f' % 3.1415926)
# 宽度为10,精度为3
print('%10.3f' % 3.1415926535)
print('{}'.format(3.1415926))
print('{1}'.format(3.141563,2132132))#0表示占位符的顺序
print('{0:.3f}'.format(3.1415926535))#.3表示的是一共是3位数
print('{0:10.3f}'.format(3.1415926535))#.3表示的是一共是3位数
9.6、字符串的编码转换
为什么需要字符串的编码转换
str在内存中以Unicode表示——> 编码——>byte字节传输——>解码——>在另一台计算机中显示
编码与解码的方式
-
编码:将字符串转换为二进制数据(bytes)
-
解码 :将bytes类型的数据转换成字符串类型
s= '他强任他强'
print(s.encode(encoding='GBK'))#在GBK这种编码格中,一个中文占两个字节
print(s.encode(encoding='Utf-8'))#在UTF-8这种编辑格式中,一个中文占三个字节
#要求编码的格式与解码的格式相同,否则解不出来,会报错
# 解码
# byte代表就是一个二进制数据(字节类型的数据)
byte = s.encode(encoding='GBK')#编码
print(byte.decode(encoding='GBK'))#解码
byte = s.encode(encoding='UTF-8')#编码
print(byte)
print(byte.decode(encoding='UTF-8'))#解码
# print('error',byte.decode(encoding='GBK')) 报错
encode()函数
描述:以指定的编码格式编码字符串,默认编码为‘utf-8’
语法:str.encode(encoding = ‘utf-8’,errors = ‘strict’) (获得bytes类型对象)
-
encoding 参数可选,即我们想要使用的编码,默认编码为‘utf-8’。字符串编码还有GBK,cp936,gb2312
-
errors参数可选,设置不同错误的处理方案。默认为‘strict’,意为编码错误引起一个UnicodeEncodeError。其他可能值还有‘ignore’,‘replace’,‘xmlcharrefreplace’以及通过codecs.register_error()注册其它的值。
str = '我爱Python'
print(str.encode(encoding='utf-8'))
print(str.encode(encoding='GBK'))#一个中文占两个字节
print(str.encode(encoding='cp936'))#一个中文占两个字节
print(str.encode(encoding='gb2312'))#一个中文占两个字节
string = '我爱你中国'
print(string.encode(encoding='utf-8'))
print('等价格式:',string.encode())
print('另一种等价格式:',string.encode('utf-8'))
print(string.encode(encoding='GBK'))
print(string.encode(encoding='cp936'))
print(string.encode(encoding='gb2312'))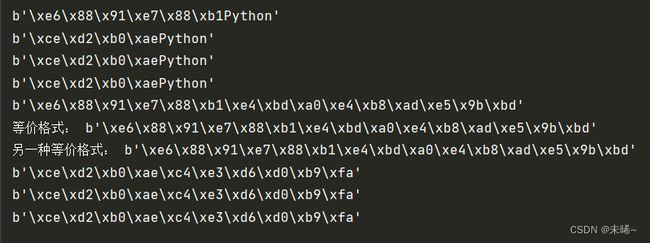
10、函数
what
函数 是执行特定任务和完成特点功能的一段代码
how
-
复用代码
-
隐藏实现细节
-
提高可维护性
-
提高可读性,便于调试
补充一个知识点
input()函数输入的内容会被转换成字符串,所以要进行强制类型转换
10.1、函数的创建和调用

10.2、函数的参数传递
-
位置实参
-
根据形参对应的位置进行实参传递
-
-
关键字实参
-
根据形参名称进行实参传递
区分实参与形参:
在10.1中,
def calc(a,b)中,a和b是形式参数,简称形参,形参的位置是在函数的定义处result = calc(a,b)处,里面的参数为实际参数的值,简称实参,实参的位置是函数的调用处而在
函数参数传递的内存分析
Python的高级类型变量改变之后,仍然指向原地址,可以理解为地址传递
def fun(arg1,arg2): print('arg1',arg1)#arg1 11 print('arg2',arg2)#arg2 [11, 22, 33, 44] arg1 = 100 arg2.append(10) print('arg1',arg1)#arg1 100 print('arg2',arg2)#arg2 [11, 22, 33, 44, 10] return n1 = 11 n2 = [11,22,33,44] print('n1:',n1)#n1: 11 print('n2:',n2)#n2: [11, 22, 33, 44] fun(n1,n2)#将位置传参,arg1,arg2,是函数定义处的形参,n1,n2是函数调用处的实参 #总结,实参名称与形参名称可以不一致 print('new n1:',n1)#new n1: 11 print('new n2:',n2)#new n2: [11, 22, 33, 44, 10]解析: 在函数调用过程中,要进行参数的传递
-
如果是不可变对象,在函数体的形参的修改不会影响实参的值
(int为不可变的,所以在函数内改变会创建一个函数内的局部变量接受变化的值)。例如本例中arg1从指向11改为指向100,但是n1还是指向11的,当函数结束之后,arg1就没有了,所以没有改变n1的值
例如:上例中 arg1 的修改,不会影响到n1的值
-
如果是可变对象,在函数体内的形参的修改,会影响到实参的值
n1,n2传的都是地址,在执行之后,n1,n2的地址都没有改变。n2是可变对象,通过append改变了对象本身,所以影响了n2的值
改进一下上一个例子,加上地址,会更好理解一下
def fun(arg1,arg2): print('arg1',arg1,id(arg1))#arg1 11 print('arg2',arg2,id(arg2))#arg2 [11, 22, 33, 44] arg1 = 100 arg2.append(10) print('arg1',arg1,id(arg1))#arg1 100 print('arg2',arg2,id(arg2))#arg2 [11, 22, 33, 44, 10] return arg1,arg2 n1 = 11 n2 = [11,22,33,44] print('n1:',n1,id(n1))#n1: 11 print('n2:',n2,id(n2))#n2: [11, 22, 33, 44] fun(n1,n2)#将位置传参,arg1,arg2,是函数定义处的形参,n1,n2是函数调用处的实参 #总结,实参名称与形参名称可以不一致 print('new n1:',n1,id(n1))#new n1: 11 print('new n2:',n2,id(n2))#new n2: [11, 22, 33, 44, 10] '''在函数调用过程中,进行参数的传递 如果是不可变对象,在函数体的修改不会影响实参的值 arg1 的修改,不会影响到n1的值 如果是可变对象,在函数体内的修改,会影响到实参的值'''
-
10.3、函数的返回值
10.3.1、函数有多个返回值时,结果为元组
def fun(num):
odd=[]
even = []
for i in num:
if i%2:
odd.append(i)
else:
even.append(i)
return odd,1,even
print(fun([1,2,3,4,5,6,7]))#([1, 3, 5, 7], 1, [2, 4, 6])解析:为什么要加中括号,原因是因为元组()是不可变的,而list[]是可变的,所以必须要加中括号
0的布尔值为False,非0的布尔值为True
10.3.2、如果函数没有返回值(函数执行完毕之后,不需要给调用处提供数据)return可以省略不写
def fun2():
print("hello,world")
fun2()#hello,world10.3.3、函数的返回值,如果是1个,直接返回类型
def fun3():
return 'hello','world'
print(fun3())#('hello', 'world')10.4、函数的参数定义
10.4.1、函数定义默认值参数
函数定义时,给形参设置默认值,只有与默认值不符的时候才需要传递实参
def fun(a,b = 100):
print(a,id(a),b,id(b))
# 函数调用
c = 100
fun(c)
print(id(c))
fun(0,1)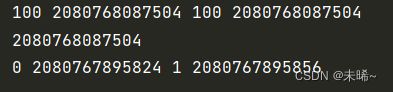
注意:
之前print()后面的默认值为换行,可以通过改变end值来进行修改到一行
print('hello',end='\t')
print(1)
#hello 110.4.2、个数可变的位置参数
-
定义函数时,可能无法事先确定传递的位置实参的个数时,使用可变的位置参数
-
使用
*定义个数可变的位置形参 -
结果为一个元组
def fun(*args):
print(args)
fun(10)
fun(10,100)
fun(11,13,14)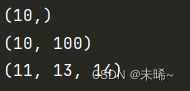
注意:位置可变的位置参数只能是一个,否则会报错

10.4.3、个数可变的关键字形参
-
定义函数时,无法事先确定传递的关键字实参的个数时,使用可变的关键字形参
-
使用
**定义个数可变的关键字形参 -
结果为一个字典
def fun1(**args): print(args) fun1(a = 10) fun1(a = 11,b = 100) fun1(a=13,v = 12,x=4)

注意:位置可变的关键字参数只能是一个,否则会报错

小结:在一个函数定义过程中,既有个数可变的关键字形参,也有个数可变的位置形参,要求,个数可变的位置形参放在个数可变的关键字形参之前


def fun(a,b,c):#a,b,c在函数的定义处,所以是形式参数
print('a=',a)
print('b=',b)
print('c=',c)
#函数的调用
fun(1,2,3)#函数调用时的参数传递,称为位置传参
lst = [11,12,13]
fun(*lst)#函数调用时,将列表中的每个元素都转换为位置实参传入
控制台:
a= 1
b= 2
c= 3
a= 11
b= 12
c= 13
print('------------------------------------')
fun(a = 100,b = 200,c = 2000)#函数的调用。所以是关键字实参
答案:
a= 100
b= 200
c= 2000
print('=================================================')
dict = {'a':111,'b':123,'c':145}
fun(*dict)
fun(**dict)#在函数调用时,将字典中的键值对都转换为关键字实参传入
输出结果:
a= a
b= b
c= c
a= 111
b= 123
c= 145
print('=++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++')
def main(a,b = 10):
print('a=',a)
print('b=',b)
def main1(*args1):
print(args1)
def main2(**args2):
print(args2)
main(1,12)
main1(10,29,12,13,14,15)
main2(a = 11,v = 22,c = 33)
def fun4(a,b,*,c,d):#从*之后的参数,在函数调用时,只能采用关键字参数传递
print('a =',a)
print('b=',b)
print('c = ',c)
print('d=',d)
#调用fun4函数
# fun4(10,11,13,14)#位置实参传递,报错
fun4(a= 10,b = 11,c = 12,d = 13)#关键字实参传递
fun4(12,13,c = 14,d = 15)#前两个参数,采用的是位置实参传递,而c,d采用的是关键字实参传递
'''需求,c,d只能采用关键字实参传递'''
'''函数定义时的形参的顺序问题'''
a= 1
b= 12
(10, 29, 12, 13, 14, 15)
{'a': 11, 'v': 22, 'c': 33}
a = 10
b= 11
c = 12
d= 13
a = 12
b= 13
c = 14
d= 1510.5、变量的作用域
-
程序代码能访问该变量的区域
-
根据变量的有效范围可分为:
-
局部变量
-
在函数定义并使用的变量,只在函数内部有效。局部变量使用global声明,这个变量就会成为全局变量
-
-
全局变量
-
函数体外定义的变量,可作用于函数内外
-
-
10.6、递归函数
如果在一个函数的函数体内调用了该函数本身,这个函数就成为递归函数
10.6.1、递归的组成部分
递归调用与递归终止的条件
10.6.2、递归的调用过程
-
每递归调用一次函数,都会在栈内存分配一个栈帧
-
每执行完一次函数,都会释放相应的空间
10.6.3、递归的优缺点
缺点:占用内存多,效率低下
优点:思路和代码简单
def fun(n):
if n==1:
return 1
else:
res = n*fun(n-1)
return res
print(fun(4))#2411、Bug
11.1、Bug的由来及分类
-
粗心导致的语法错误 SyntaxError
-
IndexError
-
append()方法,每次只能添加一个元素
11.2、不同异常类型的处理方式
11.3、异常处理机制(被动掉坑)
Python提供了异常处理机制,可以在异常出现时及时捕获,然后内部“消化”,让程序继续运行。
11.3.1、一个except结构
try:+可能会出异常的代码
except+异常类型:异常处理代码(报错后执行的代码)
try:
a = int(input('请输入一个整数:'))
b = int(input('请输入第二个整数:'))
result = a/b
print('结果为:',result)
except ZeroDivisionError:
print("除数不能为0")
except ValueError:
print('只能输入数字串')
print('程序结束')
11.3.2、多个except结构
捕获异常的顺序按照先子类后父类的顺序,为了避免遗漏可能出现的异常,可以在最后增加BaseException
try:
a = int(input('请输入一个整数:'))
b = int(input('请输入第二个整数:'))
result = a/b
print('结果为:',result)
except ZeroDivisionError:
print("除数不能为0")
except ValueError:
print('只能输入数字串')
except BaseException as e:
print(e)
print('程序结束')11.3.2.1、try…except…else
try:
a =int(input('请输入第一个整数:'))
b = int(input('请输入第二个整数:'))
result = a/b
except BaseException as e:
print('出错了',e)
else:
print('计算结果为:',result)11.3.2.2、try…except…else…finally
finally块无论是否发生异常都会被执行,能常用来释放try块中申请的资源
try:
a = int(input('请输入第一个整数:'))
b = int(input('请输入第二个整数:'))
result = a/b
except BaseException as e:
print('出错了',e)
else:
print('结果为:',result)
finally:
print('无论是否产生异常,总会被执行的代码')
print('程序结束')
常见的异常类型(可以使用traceback模块打印异常信息)
| 序号 | 异常类型 | 描述 |
|---|---|---|
| 1 | ZeroDivision Error | 除(或取模)零(所有数据类型) |
| 2 | IndexError | 序列中没有此索引(index) |
| 3 | KeyError | 映射中没有这个键 |
| 4 | NameError | 未声明/初始化对象(没有属性) |
| 5 | SyntaxError | Python语法错误 |
| 6 | ValueError | 传入无效的参数 |
int(1/0)

# int(1/0)
import traceback
try:
print('======================')
print(1/0)
except:
traceback.print_exc()
11.4、PyCharm的调试模式
11.4.1、断点
程序运行到此处,暂时挂起,停止执行。此时可以详细观察程序的运行情况,方便做出进一步的判断
11.4.2、进入调试视图
进入调试视图的三种方式
-
单击工具栏上的按钮
-
右键单击编辑区:点击:debug’模块名’
-
快捷键:shift+F9
12、面向对象
类名:由一个或者多个单词组成,每个单词首字母大写,其余小写