C++与协程
C++与协程
- 协程的起源
- 协程初识
-
- 协程与多线程
- 协程与函数
- 协程的分类
- 协程的调度
- 协程的切换
- 协程实现
-
- Duff's device(达夫设备)
- 封装一个简单的协程类
- 使用ucontext切换协程
- 基于共享栈的协程
协程的起源
协程存在的原因和解决的问题
当很多客户端连接到服务器,服务器使用epoll管理许多客户端长连接,代码框架如下:
while (1) {
int nready = epoll_wait(epfd, events, EVENT_SIZE, -1);
for (i = 0;i < nready;i ++) {
int sockfd = events[i].data.fd;
if (sockfd == listenfd) {
int connfd = accept(listenfd, xxx, xxxx);
setnonblock(connfd);
ev.events = EPOLLIN | EPOLLET;
ev.data.fd = connfd;
epoll_ctl(epfd, EPOLL_CTL_ADD, connfd, &ev);
} else {
handle(sockfd);
}
}
}
对于响应式服务器,所有的客户端的操作驱动都是来源于这个大循环。来源于epoll_wait的反馈结果。
对于服务器的IO处理,Handle(sockfd)实现方式有两种。
同步I/O框架
- handle(sockfd)函数内部对sockfd进行读写动作
int handle(int sockfd) {
recv(sockfd, rbuffer, length, 0);
parser_proto(rbuffer, length);
send(sockfd, sbuffer, length, 0);
}
- handle的io操作(send,recv)与epoll_wait是在同一个处理流程里面的。这就是IO同步操作。
优点:
1.sockfd管理方便。
2.操作逻辑清晰。
缺点:
1.服务器程序依赖epoll_wait的循环响应速度慢。
2.程序性能差
异步I/O框架 - handle(sockfd)函数内部将sockfd的操作,push到线程池中:
int thread_cb(int sockfd) {
// 此函数是在线程池创建的线程中运行。
// 与handle不在一个线程上下文中运行
recv(sockfd, rbuffer, length, 0);
parser_proto(rbuffer, length);
send(sockfd, sbuffer, length, 0);
}
int handle(int sockfd) {
//此函数在主线程 main_thread 中运行
//在此处之前,确保线程池已经启动。
push_thread(sockfd, thread_cb); //将sockfd放到其他线程中运行。
}
Handle函数是将sockfd处理方式放到另一个已经其他的线程中运行,如此做法,将io操作(recv,send)与epoll_wait 不在一个处理流程里面,使得io操作(recv,send)与epoll_wait实现解耦。这就叫做IO异步操作。
它是基于事件驱动的,当什么事件到来,就调用哪个回调进行处理;或者是回调判断发生了什么事件,再调用不同的函数处理。这与我们传统的思维不同,因此很大程度上,我们需要画状态机,才能很好地解释我们的软件逻辑。
优点:
1.子模块好规划。
2.程序性能高。
缺点:
正因为子模块好规划,使得模块之间的sockfd的管理异常麻烦。每一个子线程都需要管理好sockfd,避免在IO操作的时候,sockfd出现关闭或其他异常。
IO同步与IO异步的比较
epoll的IO异步操作与IO同步操作比较如下:
| 对比项 | IO同步操作 | IO异步操作 |
|---|---|---|
| Socket管理 | 管理方便 | 多个线程共同管理 |
| 代码逻辑 | 程序整体逻辑清晰 | 子模块逻辑清晰 |
| IO性能 | 响应时间长,性能差 | 响应时间短,性能好 |
有没有一种方式,有异步性能,同步的代码逻辑。来方便编程人员对IO操作的组件呢? 有,采用一种轻量级的协程来实现。协程拥有将一个异步过程转化为同步过程的非凡能力,大大减轻了我们的开发工作量。在每次send或者recv之前进行切换,再由调度器来处理epoll_wait的流程。
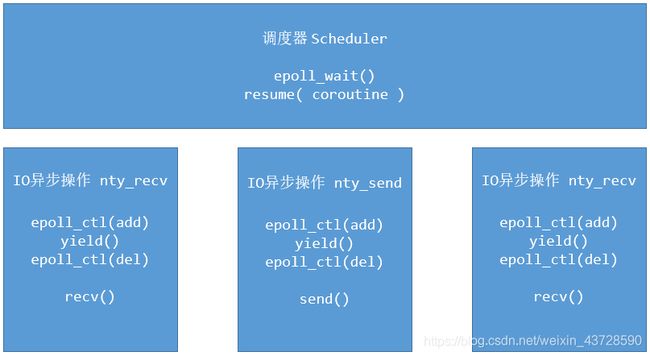
协程初识
协程与多线程
协程称为用户线程,微线程,可以将其理解为单个进程或线程中的多个用户态线程。实际上协程只有一个线程。
相比与多线程,协程没有内核态的上下文切换,近乎可以无限并发。协程在用户态进程显式的调度,可以把异步操作转换为同步操作,也意味着不需要加锁,避免了加锁过程中不必要的开销。多进程,多线程以及协程的设计都是为了并发任务可以更好的利用CPU资源,他们之间最大的区别在于CPU资源的使用上:
- 进程和线程的任务调度是由内核控制的,是抢占式的;
- 协程的任务调度是在用户态完成,需要代码里显式地将CPU交给其他协程,是协作式的。
由于我们可以在用户态调度协程任务,所以我们可以把一组相互依赖的任务设计为协程。这样当一个协程任务完成之后,可以手动的进行任务切换,把当前任务挂起(yield),切换到另一个协程区工作。由于我们可以控制程序主动让出资源,很多情况下将不需要对资源进行加锁。
协程与函数
相比于函数,协程避免了传统的函数调用栈,几乎可以无限地递归。协程与普遍函数调用区别在于协程会记录函数的执行状态,挂起再恢复会从挂起的状态执行起。所以,本质上协程是一种能记录函数执行状态的函数调用。
记录函数执行状态,最容易想到的就是静态局部变量。但是怎么记住函数的执行位置,并且回来的时候从这个位置继续执行?使用goto语句是一个办法,但从代码的可读性、维护性角度来说,并不推荐使用goto语句。另一个解决办法称作
协程的分类
按照传递控制机制
协程主要分为对称式(symmetric)、非对称(asymmetric)式两种(参见boost协程库),两者的主要区别在于:
1、对称协程只提供一种传递操作,用于在协程间直接传递控制,协程每次需要挂起时需要指定一个明确切换的目标协程,也就是说控制权只能在协程间跳转。
2、非对称协程提供调用和挂起两种操作,挂起时控制权返回给调用者。被调用的协程可以看成时从属于调用者,这种协程在日常使用中更常见。
按照栈实现分类
有栈协程
协程有运行栈,协程上下文保存在栈中,切换协程就是切换栈,然后恢复栈中的上下文,这种方法实现的协程更像是用户态的线程。
无栈协程
stackless无栈协程公用一个运行栈,协程切换的时候仅会将所需的上下文保存在堆中, 可以将部分无用局部变量提前释放,通常这需要编译器的支持。
同有栈协程相比,无栈协程具有以下优点:
- 切换时,不涉及内核态切换,类似于普通函数调用效率更高。
- 不用考虑有栈协程中的由于栈开辟空间太小导致的栈溢出的问题。
- 代码小巧,跨平台。
缺点在于:
由于无栈协程不保存上下文,函数栈内的零时变量都不会保存,只能依赖传递的参数再次恢复数据。
从头到尾理解有栈协程实现原理
有栈协程按照栈的实现不同又可分为以下几种:
stackcopy 共享栈协程
stackfull的缺点显而易见,十分浪费内存,当协程数量过多时会导致内存开销过大。stackcopy就是用来解决此问题的,所有协程公用一个运行栈,当协程发生切换的时候,将协程数据copy到自身的独立栈中,独立栈可以进行动态的扩充。
静态栈(Static Stack)
使用固定大小的栈,难以权衡固定栈的大小。过大容易浪费栈空间,过小可能不够使用出现栈溢出。
典型代表:libco,它设置了128KB大小的堆栈。
分段栈(Segmented Stack)
gcc提供的“黄金链接器”支持一种允许栈内存不连续的编译参数,实现原理是在每个函数调用开头都插入一段栈内存检测的代码,如果栈内存不够用了就申请一块新的内存,作为栈内存的延续。
这种方案本应是最佳的实现,但如果遇到的第三方库没有使用这种方式来编译,那就无法在其中检测栈内存是否需要扩展,栈溢出的风险很大。
拷贝栈(Copy Stack)
每次检测到栈内存不够用时,申请一块更大的新内存,将现有的栈内存copy过去,就像std::vector那样扩展内存。
在某些语言上是可以实现这样的机制,但C++ 是有指针的,栈内存的Copy会导致指向其内存地址的指针失效。
共享栈(Shared Stack)
所有协程公用一个足够大的运行栈,当协程发生切换的时候,将协程数据copy到自身的独立栈中,独立栈可以进行动态的扩充。。
这种方案极大程度上避免了内存的浪费,做到了用多少占多少,同等内存条件下,可以启动的协程数量更多。典型代表:libco。
但是这种方案的缺陷也同样明显:
- 协程切换慢:每次协程切换,都需要2次Copy协程栈内存,这个内存量基本上都在1KB以上,通常是几十kb甚至几百kb,这样的2次Copy要花费很长的时间;
- 栈上引用失效导致隐蔽的bug。
虚拟内存栈(Virtual Memory Stack)
Linux、Windows、MacOS三大主流操作系统都有这样一个虚拟内存机制:进程申请的内存并不会立即被映射成物理内存,而是仅管理于虚拟内存中,真正对其读写时会触发缺页中断,此时才会映射为物理内存。
比如:在进程中malloc了1MB的内存,但是不做读写,那么物理内存占用是不会增加的;当读写这块内存的第一个字节时,系统才会将这1MB内存中的第一页(默认页大小4KB)映射为物理内存,此时物理内存的占用会增加4KB,以此类推,可以做到用多少占多少,冗余不超过一个内存页大小。
基于这样一个机制,每个协程malloc 1MB的虚拟内存作为协程栈(这个值是可以定制化的);不做读写操作就不会占用物理内存,协程栈使用了多少才会占用多少物理内存,实现了与共享栈近似的内存使用率,并且不存在共享栈的两大弊端。
典型代表:libgo
协程的调度
协程调度的原理,可类比线程 / 进程的调度,可分抢占和非抢占两种了。
要实现抢占式很难,而且也没太大必要,因为花了很大力气实现抢占式的协程调度,反而失去了 “协程中没有同步问题” 这一优势了。
所以,针对 C/C++协程,最好的方式就是使用非抢占式调度,需要任务通过某些调用主动让出CPU使用权。
像操作系统的进程调度一样,非抢占式调度协程调度也有多种方案可选,也有公平调度和不公平调度之分。
栈式调度
栈式调度是典型的不公平调度:协程队列是一个栈式的结构,每次创建的协程都置于栈顶,并且会立即暂停当前协程并切换至子协程中运行,子协程运行结束(或其他原因导致切换出来)后,继续切换回来执行父协程;越是处于栈底部的协程(越早创建的协程),被调度到的机会越少;
典型代表:libco
星切调度(非对称协程调度)
调度线程 -> 协程A -> 调度线程 -> 协程B -> 调度线程 -> …
调度线程居中,协程画在周围,调度顺序图看起来就像是星星一样,因此称为星切。
将当前可调度的协程组织成先进先出的队列(runnable list),顺序pop出来做调度;新创建的协程排入队尾,调度一次后如果状态依然是可调度(runnable)的协程则排入队尾,调度一次后如果状态变为阻塞,那阻塞事件触发后也一样排入队尾,是为公平调度。
典型代表:libgo
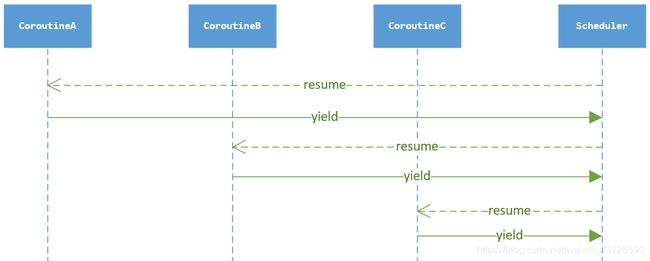
环切调度(对称协程调度)
调度线程 -> 协程A -> 协程B -> 协程C -> 协程D -> 调度线程 -> …
调度线程居中,协程画在周围,调度顺序图看起来呈环状,因此称为环切。
从调度顺序上可以发现,环切的切换次数仅为星切的一半,可以带来更高的整体切换速度;但是多线程调度、WorkSteal方面会带来一定的挑战。
协程的切换
协程上下文切换有很多种实现方式:
- 使用操作系统提供的api:ucontext、fiber
这种方式是最安全可靠的,但是性能比较差。(切换性能大概在200万次/秒左右)。
一般用ucontext实现的coroutine,切换基于glibc的swapcontext.S,主要保存和恢复以下部分:栈寄存器,浮点环境,signal mask。其中signal mask会进行system call,会陷入内核,从而引起内核态和用户态的上下文切换,这个是最主要的性能瓶颈。
//ucontext:
typedef struct ucontext {
struct ucontext *uc_link;
sigset_t uc_sigmask;
stack_t uc_stack;
mcontext_t uc_mcontext;
...
} ucontext_t;
void makecontext(ucontext_t *ucp, void (*func)(), int argc, ...);
int swapcontext(ucontext_t *oucp, ucontext_t *ucp);
int getcontext(ucontext_t *ucp);
int setcontext(const ucontext_t *ucp);
- 利用 C 语言的 setjmp 和 longjmp
先调用setjmp,用变量envbuf记录当前的位置,然后调用longjmp,返回envbuf所记录的位置,并使setjmp的返回值为val。使用longjmp后,envbuf的内容会被销毁。函数中使用 static local 的变量来保存协程内部的数据。代表作:libmill
int setjmp(jmp_buf envbuf);
void longjmp(jmp_buf envbuf, int val);
- 利用C语言语法switch-case的技巧来实现(Protothreads)
设置一个标识符,改变标识符的值,通过switch-case对标识符值的判断操纵各协程函数轮流执行。每个协程函数可配一个结构体,保存栈内容和状态机。 - 自己写汇编码实现
这种方式的性能可以很好,但是不同系统、甚至不同版本的linux都需要不同的汇编码,兼容性差,代表作:libco
基于汇编的 C/C++ 协程 - 切换上下文
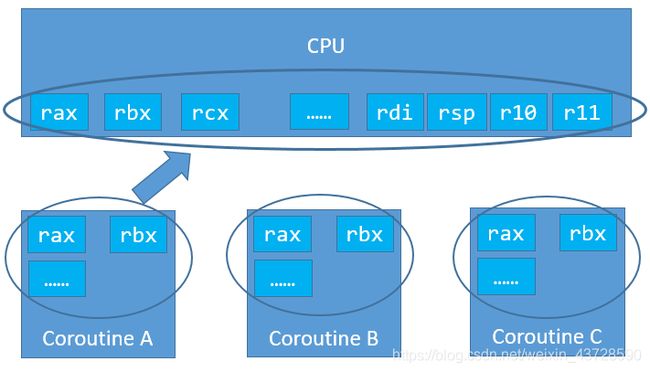
- 使用boost.coroutine
这种方式的性能很好,boost也帮忙处理了各种平台架构的兼容性问题,缺陷是这东西随着boost的升级,并不是向后兼容的,不推荐使用 - 使用boost.context
性能、兼容性很好。(切换性能大概在1.25亿次/秒左右)
协程实现
Duff’s device(达夫设备)
#include达夫设备,是C中switch语句最巧妙的实现。在第二次调用range函数时,由于静态变量state的值已为1,所以程序直接跳到case 1语句,进入了for循环的内部,使自增值i从上次结束的值开始i++,然后return返回。
封装一个简单的协程类
如果把静态变量改为参数传递,再把协程用类封装一下。很容易写出一个简单的协程类,代码如下:
//coroutine.h文件
#ifndef COROUTINE_H_
#define COROUTINE_H_
#include
typedef int (*FUNC)(void* pParam);
struct CrtParam
{
int key; //协程唯一识别标识
FUNC func; //处理函数
void* pParam; //参数
unsigned long yiledStart; //挂起开始时间
unsigned int yiledMillisecond; //挂起时长
CrtParam()
{
key = 0;
func = NULL;
pParam = NULL;
yiledStart = 0;
yiledMillisecond = 0;
}
};
enum CoroutineState
{
CS_FAILURE = -1,
CS_SUCCESS,
CS_YIELD,
CS_YIELD_Timer,
};
typedef std::map<int, CrtParam*> CrtParamMap;
typedef CrtParamMap::iterator CrtParamMapItr;
class MyCoroutine
{
public:
static void Init();
static int Execute(CrtParam* pCrtParam);
static CoroutineState Yiled();
static CoroutineState YiledTimer(unsigned int yiledMillisecond);
static void Resume(int key);
static int CreateKey();
static void HandleResumeTimer();
private:
static CrtParamMap s_CrtParamMap;
static int s_Key;
static unsigned int s_yiledMillisecond;
};
#define YILED() return MyCoroutine::Yiled();
#define YILEDTIME(yiledMillisecond) return MyCoroutine::YiledTimer(yiledMillisecond);
void ResumeTimerFunc(void* pParam);
#endif
//coroutine.cpp文件
#include "stdafx.h"
#include "coroutine.h"
#include "time.h"
#include "process.h"
#include "windows.h"
CrtParamMap MyCoroutine::s_CrtParamMap;
int MyCoroutine::s_Key = 0;
unsigned int MyCoroutine::s_yiledMillisecond = 0;
void MyCoroutine::Init()
{
_beginthread(&ResumeTimerFunc, 0, NULL);
}
int MyCoroutine::Execute(CrtParam* pCrtParam)
{
int result = CS_FAILURE;
if(NULL != pCrtParam && NULL != pCrtParam->func)
{
result = pCrtParam->func(pCrtParam->pParam);
if (CS_SUCCESS == result || CS_FAILURE == result)
{
CrtParamMapItr ite = s_CrtParamMap.find(pCrtParam->key);
if (ite != s_CrtParamMap.end())
{
s_CrtParamMap.erase(ite);
}
}
else
{
pCrtParam->key = CreateKey();
if(CS_YIELD_Timer == result)
{
pCrtParam->yiledStart = GetTickCount();
pCrtParam->yiledMillisecond = s_yiledMillisecond;
}
CrtParamMapItr ite = s_CrtParamMap.find(pCrtParam->key);
if (ite == s_CrtParamMap.end())
{
s_CrtParamMap[pCrtParam->key] = pCrtParam;
}
}
}
return result;
}
CoroutineState MyCoroutine::Yiled()
{
return CS_YIELD;
}
CoroutineState MyCoroutine::YiledTimer(unsigned int yiledMillisecond)
{
s_yiledMillisecond = yiledMillisecond;
return CS_YIELD_Timer;
}
void MyCoroutine::Resume(int key)
{
CrtParamMapItr ite = s_CrtParamMap.find(key);
if (ite != s_CrtParamMap.end())
{
Execute(ite->second);
}
}
int MyCoroutine::CreateKey()
{
return MyCoroutine::s_Key++;
}
void MyCoroutine::HandleResumeTimer()
{
CrtParamMap crtParamMapTemp = s_CrtParamMap;
for (CrtParamMapItr ite = crtParamMapTemp.begin(); ite != crtParamMapTemp.end(); ++ite)
{
if (ite->second->yiledStart > 0 && ite->second->yiledMillisecond > 0)
{
if (GetTickCount() >= ite->second->yiledStart + ite->second->yiledMillisecond)
{
ite->second->yiledStart = 0;
ite->second->yiledMillisecond = 0;
Execute(ite->second);
}
}
}
}
void ResumeTimerFunc(void* pParam)
{
while(true)
{
MyCoroutine::HandleResumeTimer();
Sleep(50);
}
}
struct Func1Param
{
int index;
int count;
Func1Param()
{
index = 0;
count = 10;
}
};
int func1(void* pParam)
{
Func1Param* pFunc1Param = (Func1Param*)pParam;
if (NULL == pFunc1Param)
{
return CS_FAILURE;
}
while(pFunc1Param->index < pFunc1Param->count)
{
printf("%d ", pFunc1Param->index);
++pFunc1Param->index;
if (pFunc1Param->index == pFunc1Param->count / 2)
{
YILED();
//YILEDTIME(2000);
}
}
return CS_SUCCESS;
}
//使用demo:
int main(int argc, char* argv[])
{
MyCoroutine::Init();
CrtParam crtParam1;
crtParam1.func = func1;
Func1Param func1Param1;
crtParam1.pParam = (void*)(&func1Param1);
CrtParam crtParam2;
crtParam2.func = func1;
Func1Param func1Param2;
func1Param2.count = 20;
crtParam2.pParam = (void*)(&func1Param2);
printf("fun1 Param1\n");
MyCoroutine::Execute(&crtParam1);
printf("\nfun1 Param2\n");
MyCoroutine::Execute(&crtParam2);
printf("\nfunc1 Param1 Resume\n");
MyCoroutine::Resume(crtParam1.key);
printf("\nfunc1 Param2 Resume\n");
MyCoroutine::Resume(crtParam2.key);
getchar();
return 0;
}
这里使用enum CoroutineState表示协程的状态;使用struct CrtParam来记录协程函数和函数参数,参数中包括了可以定位协程执行函数位置的变量;MyCoroutine协程类中Execute函数可以执行协程函数,Resume重新调用Execute执行协程函数。
协程类内部成员s_CrtParamMap是一个map变量,key为协程唯一标识id,value为自定义的struct CrtParam指针变量。传入协程的id给Resume,便能找到对应的struct CrtParam,从而获得协程函数参数和执行协程函数指针,继续协程函数的执行。Yiled在协程函数中被使用,挂起协程,返回enum CoroutineState中的CS_YIELD状态。在Execute中执行协程函数的时候,就可以根据返回的状态,决定下一步的操作。
可以看出,协程本质上来说,就是一个函数状态机。
使用ucontext切换协程
上节封装的协程类和达夫设备实现的协程,属于无栈协程,不保存局部变量,局部数据状态需要靠函数执行恢复,每次协程执行函数都能执行完成,return返回。如果把协程执行上下文完整保存,就有另一种方案,有栈协程,函数可以真正挂起。使用
//coroutine.h
#ifndef H_COROUTINE_H_
#define H_COROUTINE_H_
#include //coroutine.cpp
#include "coroutine.h"
#include
#include //测试demo
#include "coroutine.h"
#include 这里使用了ucontext提供的函数上下文切换功能,于是很方便地实现了一个简单的协程库。
上述实现的协程库,调度方式是星切调度,使用的是静态栈,每个协程都拥有自己固定大小的栈,协程上下文保存在自己的栈中,切换协程就是切换栈后恢复栈中的上下文。这种方式每个协程都要分配一个一定大小的栈空间,空间效率上可能比较低,不够轻量;运行效率上来说,swapcontext系列函数的执行效率如何也值得商榷。
基于共享栈的协程
云风coroutine协程库源码分析